
面向Agent的规范驱动开发:从 URD 到 llm-wiki 的分析框架、实证证据与研究议程
执行摘要
本文讨论的“面向 Agent 的规范驱动开发”并不是一个已经在公开文献中被统一命名、统一缩写的现成标准,而更像是一条把若干成熟传统重新编排后的工程路线:前段来自需求工程、形式化方法与公理设计,中段来自模块化与模型驱动工程,后段来自测试、仓库级检索、代码代理与持久知识库。公开研究已经足以支撑这样一个判断:如果将规范、测试、设计依据与执行路径都作为一等工件来管理,Agent 的代码生成与修改质量通常会更稳定、更可解释,也更容易被回放、审计和纠错;反过来,如果让 Agent 直接在模糊需求与松散上下文上“即兴发挥”,效果往往依赖偶然的提示、模型版本和脚手架细节。citeturn36view0turn8view0turn32view0turn27search3turn33view0
过去五年里,研究重心显著向“仓库级、多步、可调用工具”的软件工程 Agent 移动,但需求与设计前段仍明显薄弱。一个 2026 年 AIware 论文在回顾 2024 年一项综述时指出,当时 LLM4SE 研究中,针对需求工程的只有 3.9%,针对软件设计的只有 0.92%,而 56.65% 集中在代码生成,22.71% 集中在维护与重构;到 2025 年的 RE 系统综述中,研究数量已快速增至 74 篇,但大多仍停留在受控环境,且以 GPT 系模型、零样本或少样本提示为主。与此同时,面向软件工程的 LLM Agent 综述在更新版中已汇总到 124 篇工作,说明后端执行能力增长远快于前端规范能力。citeturn12view0turn37view0turn10search9turn9search13
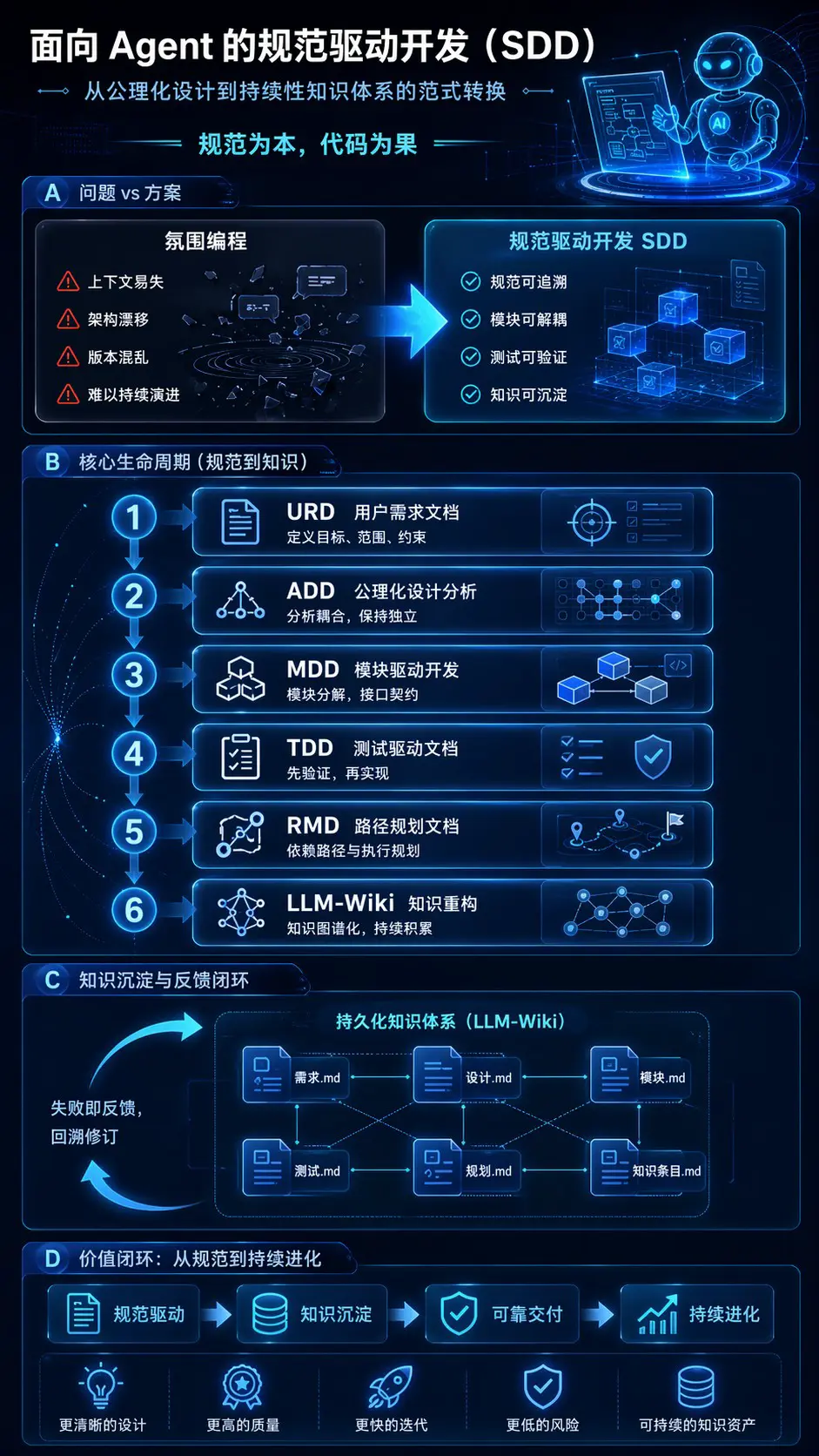
因此,本文的核心结论不是“让 Agent 写代码更快”,而是:对复杂项目,更合理的工程单位不再是单条 prompt,而是一个分层规范栈。本文将其精确定义为:URD 捕获用户意图与约束,ADD 做公理级语义分解与耦合检查,MDD 把设计收敛为模块与契约,TDD 把可执行验收和回归保护前置成文档,RMD 则把实施路径、依赖顺序、停止条件与回滚策略写清楚;在此基础上,再用 llm-wiki 模式把文档“编译”为持续更新的 wiki,使 Agent 面对的不是散落原文,而是可检索、可交叉引用、可追溯的中间知识层。做不动、做歪或出现矛盾时,不是继续堆 prompt,而是沿追溯链回到最早失真的工件,通常从 URD 重新改起。citeturn28view0turn28view1turn28view3turn42search11turn38search0
概念界定与精确定义
本文把 SDD 定义为一种面向 Agent 的规范驱动开发方法:它以“分层规范栈”而不是“单次提示”作为系统控制面,让 Agent 的规划、生成、修改与验证都受到明确工件的约束,并通过追溯关系把需求、设计、模块、测试、执行路径、代码改动和失败日志连接起来。这个定义借鉴了形式化需求工程、assured LLMSE、promptware engineering、仓库级检索增强生成与 Agent 评测研究,但将它们重新压缩成一条文档—执行—回溯闭环。citeturn36view0turn8view0turn32view0turn33view0
更具体地说,本文采用以下术语。需要强调的是:这些缩写是本文为便于工程讨论而作的精确定义,并非公开社区已经完全收敛的统一术语。其中,MDD 在本文中指“模块拆分文档”,不是通常意义上的“模型驱动开发”;TDD 在本文中指“测试驱动文档”,不是经典意义上的“先写测试再写代码”的编程流程;RMD 也不是已有标准缩写,而是本文定义的实施路径工件。citeturn36view0turn26view1turn18view0turn32view0
| 工件 | 本文定义 | 核心输入 | 核心输出 | 最低通过条件 |
|---|---|---|---|---|
| URD | User Requirements Document。记录目标、场景、约束、非目标、验收条件、术语和变更触发器 | 利益相关者输入、业务规则、法规、现有系统上下文 | 结构化需求、假设、边界、验收标准 | 术语一致、非目标明确、关键约束可检验 |
| ADD | Axiomatic Design Decomposition。将功能需求映射到设计参数,检查独立性与耦合 | URD、领域知识、架构约束 | FR/DP 分解、设计矩阵、设计理由、冲突列表 | 关键 FR 有对应 DP,耦合显式化,冲突被记录 |
| MDD | Module Decomposition Document。把 ADD 收敛为模块边界、接口、状态、依赖和不变量 | ADD、现有代码/系统边界 | 模块清单、接口契约、依赖图、状态/数据模型 | 模块职责单一,接口输入输出可枚举,依赖有方向 |
| TDD | Test-Driven Documentation。把验收标准翻译成可执行测试、夹具、失败预期和覆盖目标 | URD、MDD、历史缺陷 | 测试规格、样例、反例、覆盖目标、oracle 说明 | 测试能区分正确与错误行为,覆盖关键路径 |
| RMD | Route Map Document。定义实现顺序、任务分解、停止条件、回滚与升级路径 | MDD、TDD、资源与依赖条件 | 实施路径、任务 DAG、风险门、升级规则 | 路径可执行、依赖闭合、失败后能定位回滚点 |
| llm-wiki | 用 LLM 将原始文档“编译”为持久、可交叉引用的 wiki 层,供 Agent 检索和更新 | URD/ADD/MDD/TDD/RMD 原文与代码库 | 主题页、实体页、模块页、测试页、追溯页、索引页 | 页面间链接完整,版本可追踪,矛盾能被标记 |
注:表中概念是本文对公开研究传统的综合定义;其理论来源主要对应形式化需求工程、公理设计、模型驱动/领域建模辅助、assured LLMSE、prompt 工程生命周期,以及 llm-wiki/DeepWiki 一类持久知识层思路。citeturn36view0turn26view1turn26view2turn18view0turn32view0turn28view0turn28view1turn28view3
下面的流程图给出本文主张的闭环。关键不是线性“五步法”,而是失败时的上游回写规则:如果冲突出在模块实现,就先回到 MDD/TDD;如果冲突出在语义目标、术语或验收标准,就必须回到 URD 重新改。citeturn8view0turn33view0turn42search11
flowchart TD
A[URD 用户需求文档] --> B[ADD 公理设计分解]
B --> C[MDD 模块拆分文档]
C --> D[TDD 测试驱动文档]
D --> E[RMD 实施路径文档]
E --> F[llm-wiki 编译层]
F --> G[Agent 上下文打包]
G --> H[代码生成与修改]
H --> I[CI 执行与验证]
I -->|通过| J[合并与发布]
I -->|失败或冲突| K[问题单与TAR日志]
K --> L{最早失真工件}
L -->|需求歧义| A
L -->|设计耦合| B
L -->|模块边界问题| C
L -->|oracle不足| D
L -->|路径不可行| E
理论基础
这条路线的第一根支柱是公理设计。就软件设计语境而言,它最有价值的部分不是“再起一个新名词”,而是把需求—设计—过程分成不同层,并要求开发者显式写出从功能需求到设计参数、再到过程变量的映射关系,同时用设计矩阵观察耦合。2025 年系统工程研究已经把 AD 与 DSM 融合进 MBSE,用来提高接口管理与概念阶段的一致性;2026 年的 Axiomatic Software Design 论文则把这一点直接拉回到 GenAI 场景,指出需求与设计阶段仍显著落后于代码生成阶段,AD 的现实意义在于帮助人类与设计型 Agent 共同维持关注点独立、跨抽象层追溯和受控分解。citeturn11search2turn12view0turn26view2
第二根支柱是规范优先而非提示优先。Assured LLMSE 给出的定义非常直接:带保证的 LLMSE 不是单纯生成代码,而是让输出携带某种可验证的效用声明;形式化验证是最强保证,但测试、静态分析、lint、过滤器与重提示同样构成较弱而可实施的保证层。2025 年的 Promptware Engineering 进一步把“提示启用系统”视为一种新的软件范式,主张把 prompt 当作一等软件工件,纳入需求、设计、测试、演化与监控全生命周期。形式化需求工程与 LLM 的“两条路线图”则从另一侧补上了这一点:一方面用形式方法约束 LLM 的需求产物,另一方面用 LLM 降低形式方法的门槛。三者合起来,正好对应本文的 URD→ADD→TDD 路径。citeturn8view0turn32view0turn36view0
第三根支柱是面向 Agent 的软件工程。2024—2025 年多篇综述已经把这一领域从“能不能自动修个 bug”推进到“如何组织感知、记忆、行动、协作和评测”。一项综述在正式出版版本中汇总了 124 篇面向软件工程的 LLM Agent 论文;另一项研究把软件工程 Agent 抽象成 perception、memory、action 三个核心模块;Agent Design Pattern Catalogue 则归纳出 18 个架构模式,并给出模式选择模型。这些工作共同说明:如果没有稳定的记忆层和可解释的行动痕迹,多 Agent 并不会天然优于单 Agent;它需要可分解任务、可共享工件和可分析轨迹。citeturn10search9turn9search13turn27search3
第四根支柱是持久知识编译层。由 entity["people","Andrej Karpathy","ai researcher"] 提出的 llm-wiki 模式,最关键的主张不是“把文档喂给 RAG”,而是让 LLM 在原始文档与查询之间维护一层持续累积、持续修订、可交叉链接的 wiki,使知识不必在每次问答时从头重拼。这一点与仓库级代码理解研究是吻合的:RepoCoder、GraphCoder、RepoHyper 与 AST/图谱型 Graph-RAG 工作都在证明,跨文件、跨模块、跨调用链的问题不能只靠局部 snippet 相似度来解决,系统需要更稳定的结构化上下文。citeturn28view0turn23view0turn23view1turn22search17turn30search0turn30search8
文献失衡本身就说明,为什么面向 Agent 的 SDD 必须把规范前端补起来。下面这张图展示的是一个常被忽略的现实:公开论文里,设计与需求仍是薄层。citeturn12view0
pie showData
title LLM4SE 文献任务分布
"软件开发" : 56.65
"软件维护" : 22.71
"需求工程" : 3.90
"软件设计" : 0.92
"其他" : 15.82
近五年前沿研究综述
从近五年的主线看,相关研究大致形成了四个层次。第一层是需求与形式化前端。2025 年的形式化需求工程路线图指出,LLM 在 RE 任务上已经表现出潜力,但正确性、公平性与可信性仍是主要瓶颈;同年的 RE 系统综述则显示,LLM 已被用于需求引出、验证、测试生成等任务,且研究对象正在从传统需求规格扩展到 issue、法规与技术手册,但行业环境中的复杂工作流整合仍很弱。2026 年中文期刊《计算机研究与发展》已经出现《基于大语言模型的需求歧义检测方法》以及同专题的多智能体嵌入式代码生成与非连续代码重构论文,说明中文同行评议研究开始迅速跟进。citeturn36view0turn37view0turn31search0turn31search6turn31search8
第二层是设计与建模中段。领域建模辅助研究表明,LLM 可以在模型尚未闭合时给出有用建议,但价值不只看“建议对不对”,还要看是否缩短时间、是否真正嵌入最终模型、是否压制创意。MAGDA 研究把这三者都测了出来;另一项用例模型生成研究则显示,LLM 辅助可以把用例建模时间压缩约 60%,而质量基本持平。与此同时,Axiomatic Software Design 这类工作重新强调:设计阶段不是简单的“自然语言翻译”,而是抽象分解、冲突协调和结构选择,因此更需要显式设计依据。citeturn19view1turn19view3turn20view0turn12view0
第三层是代码库理解、文档生成与执行后端。RepoCoder、GraphCoder、RepoHyper 把仓库级代码完成从单文件补全推进到跨文件检索、代码图检索和迭代检索—生成;RepoAgent 把“文档生成”从 README 级别推进到 repository-level 主动维护;CompileAgent 则把“能不能把真实仓库编译起来”做成了专门 benchmark,并且把 repo-level compilation success 从 10% 提升到 71%。这里最重要的变化不是某个分数,而是研究对象终于开始面对真实仓库中的依赖、构建脚本、编译报错、工具调用和多轮修复。citeturn23view1turn23view0turn22search21turn8view5turn8view6
第四层是统一 Agent 与评测方法。USEagent 把 coding、testing、patching 混到 1271 个仓库级任务的 USEbench 中,试图逼近“AI 软件工程师”而不是单任务工具;与之同步,2026 年的评测方法论文则指出,当前 18 篇高水平会议论文里,只有 1 篇真正与相关 SOTA Agent baseline 做比较,绝大多数实验缺少 prompt、温度、模型精确版本、完整轨迹等可复现信息。换言之,Agent 系统的能力增长很快,但解释框架和评测规范还在补课。citeturn46view3turn33view0
如果把这些研究映射到本文的 SDD 链条,可以得到下面的比较。它说明:URD→ADD→MDD→TDD→RMD 不是凭空发明的新流程,而是把分散在不同研究传统里的“前端规范—中段设计—后端执行—统一评测”重新串成一条控制链。citeturn36view0turn12view0turn18view0turn8view0turn23view0turn33view0
| 方法族 | 主要工件 | 主要控制机制 | 对面向 Agent 的 SDD 的启发 | 当前薄弱点 |
|---|---|---|---|---|
| 形式化需求工程 + LLM | 需求、形式规格、验证脚本 | 语义澄清、形式约束、可证明性 | 对应 URD 与 ADD 的上游语义净化 | 形式化成本仍高,行业落地有限 |
| 公理设计 + MBSE | FR/DP/PV、设计矩阵、DSM | 关注点独立、分层映射、耦合观察 | 对应 ADD 的核心分析框架 | 软件领域端到端证据仍少 |
| 领域/模型建模辅助 | UML/领域模型、建议记录 | 交互式建议、模型完成、结构化引导 | 对应 MDD 的模块边界形成 | 关系推理与语法/语义一致性仍脆弱 |
| 仓库级 RAG 与代码图 | 代码片段、调用图、依赖图 | 检索增强、结构感知、跨文件上下文 | 对应 MDD→TDD→编码阶段的上下文供给 | 对长期记忆与文档变更协同支持不足 |
| Repo 文档/知识编译 | README、架构页、模块页、Wiki | 文档生成、摘要、交叉引用、检索 | 对应 llm-wiki 的中间知识层 | 新鲜度、冲突合并、标准评测不足 |
| Agent 执行与统一评测 | TAR 轨迹、工具调用、仓库任务 | 多轮行动、反思、工具集成、基准评测 | 对应 RMD 与闭环回写 | 可复现性、基线公平性、成本分析不足 |
注:表中“启发”与“薄弱点”为本文综合判断;各方法族的基础事实来自近五年综述、原始论文与官方基准说明。citeturn37view0turn27search3turn18view0turn23view0turn8view5turn46view3turn33view0
工具、平台与文档到代码基础设施
把 SDD 真正落到 Agent 开发中,关键不在“选最强模型”,而在把工具栈按工件分层。最低限度,需要四类设施:一类负责生成与修订文档,一类负责把文档与代码库编译成可检索知识层,一类负责调用 shell、测试、静态分析与构建工具,一类负责记录 Thought–Action–Result 轨迹供复盘。没有这四层,URD/ADD/MDD/TDD/RMD 很容易沦为文件夹里的静态文档,而不是 Agent 的运行时控制面。citeturn28view0turn28view1turn33view0turn42search2
在这方面,llm-wiki 更应该被看成一种架构模式而不是单一产品。entity["company","Cognition","ai company"] 的 DeepWiki 已经把这种模式产品化:自动索引仓库、生成架构图、文档与源码链接,并允许用 .devin/wiki.json 显式指定 wiki 页面;OpenDeepWiki 则把这一思路开源化,并补上代码分析、知识图谱和 MCP 接口;llm-wiki 原始描述则强调,中间 wiki 层的目的在于把原始知识“编译一次、持续累积”,而不是每次靠 RAG 临时拼装。对于 public entity["company","GitHub","developer platform"] 仓库,这尤其适合做 Agent 的持久上下文层。citeturn28view0turn28view1turn28view2turn28view3
从代码知识库角度看,纯向量检索已经不够。GraphCoder 的结论是:图结构的 coarse-to-fine 检索能把 repository-level completion 的 code match EM 和 identifier match EM 平均分别提升 6.06 和 6.23 个点;更近一步,面向代码库的 Graph-RAG 研究显示,基于 AST 的确定性知识图比由 LLM 抽取的知识图在覆盖率、成本和多跳架构问答上更可靠。这对本文很重要,因为 llm-wiki 如果只有摘要页、没有结构边,很容易退化成“更漂亮的长文档”;而当 wiki 页面能够绑定模块依赖、测试覆盖和设计矩阵时,它才真能服务于 Agent 的定位、改动与回溯。citeturn23view0turn30search0turn30search3turn30search8
下面这张关系图给出本文建议的知识设施形态:原始文档不是直接喂给 Agent,而是先经过 wiki 编译、追溯链接和索引生成,随后再按任务类型打包上下文。这样,Agent 面对的是“编译后的项目知识”,不是原始材料堆。citeturn28view0turn28view1turn28view3turn42search11
erDiagram
RAW_SPEC ||--o{ WIKI_PAGE : compiles_to
RAW_SPEC ||--o{ TRACE_LINK : yields
WIKI_PAGE ||--o{ TRACE_LINK : contains
WIKI_PAGE ||--o{ MODULE_CONTRACT : describes
WIKI_PAGE ||--o{ TEST_SPEC : grounds
WIKI_PAGE ||--o{ ROUTE_STEP : plans
MODULE_CONTRACT ||--o{ CODE_ARTIFACT : implements
TEST_SPEC ||--o{ CODE_ARTIFACT : verifies
ROUTE_STEP ||--o{ AGENT_TASK : instantiates
AGENT_TASK ||--o{ TAR_LOG : produces
TAR_LOG ||--o{ ISSUE_NOTE : explains
ISSUE_NOTE }o--|| RAW_SPEC : may_reopen
从工程成熟度看,可以把当前工具分成下表几类。值得注意的是,表中很多系统并不互斥,而是最适合被串联成一条流水线:repo-grounded retrieval 给模块上下文,wiki 给长期记忆,agent harness 给执行轨迹,规范文档给行动边界。citeturn23view1turn23view0turn8view5turn28view1turn28view3turn33view0
| 设施层 | 代表系统或模式 | 典型能力 | 更适合的 SDD 阶段 | 主要风险 |
|---|---|---|---|---|
| 规范工件层 | Promptware 工程、形式化 RE | 把 prompt/需求纳入生命周期 | URD、ADD、TDD | 规范写得像 prompt,而不是像可检验工件 |
| 持久 wiki 层 | llm-wiki、DeepWiki、OpenDeepWiki | 主题页、架构页、源码链接、知识图谱、MCP 暴露 | 全阶段,尤其是 RMD 之后的执行期 | 文档过时、冲突页未合并、缺少统一评测 |
| 仓库检索层 | RepoCoder、GraphCoder、RepoHyper | 跨文件检索、代码图检索、迭代检索—生成 | MDD、TDD、编码 | 只检索局部相似代码,忽略全局语义 |
| 文档生成层 | RepoAgent | 仓库级文档生成、维护、更新 | MDD→wiki 编译 | 文档正确性高于可读性时,人工校验成本上升 |
| 图谱知识层 | DKB/AST Graph-RAG、CGM | 结构覆盖、多跳依赖、架构问答 | MDD、RMD、定位根因 | 构图代价、跨语言统一建模仍难 |
| 执行与评测层 | mini-SWE-agent、USEbench、TAR/CodeTracer | 统一脚手架、可比较评测、轨迹分析 | RMD、执行闭环 | 环境细节影响大,难以公平比较 |
注:表中“更适合的阶段”是本文的工程归纳;系统能力与限制依据原始论文、官方文档与基准摘要。citeturn32view0turn28view0turn28view1turn28view3turn8view5turn23view1turn23view0turn30search0turn46view3turn42search2
实证证据、评测指标与基准
如果只看“代码能不能跑”,会低估面向 Agent 的规范驱动开发的价值。更合适的看法是:规范前置的收益,通常先体现在时间、可追溯性、建议采用率、测试质量与失败可诊断性上,然后才体现在最终的 patch resolution 上。现有实证研究虽然分散,但已经勾勒出较稳定的经验图景。citeturn19view1turn20view0turn41search0turn8view6turn13search0
最有代表性的证据有五类。其一,领域建模辅助能降低前端建模时间:MAGDA 用户研究中,自动建议模式把平均完成时间从 10 分 23 秒降到 8 分 07 秒,约缩短 22%;同时,Automatic 模式的建议接受率为 0.33、贡献率为 0.56,均显著高于“结束后再给建议”的模式。其二,用例建模辅助能显著加速:五位专业工程师的探索性研究报告约 60% 的时间下降,质量基本持平。其三,规范约束能提高下游建议被采纳的概率:SGCR 在工业代码评审环境中将建议采纳率从 22% 提升到 42%,相对增幅 90.9%。其四,带工具的 repo-level agent 能把“真实仓库能否编译”从 10% 拉高到 71%。其五,工业测试生成不仅可行,而且可以规模化运转:entity["organization","Meta","technology company"] 的 TestGen 已向生产环境落地 518 个测试,在 CI 中累计执行 9,617,349 次,发现 5,702 个故障;从 4,361 个可靠端到端测试中切片时,生成测试覆盖到至少 86% 的相关类,并在 16 个 Kotlin Instagram 启动阻塞任务中提前拦下 13 个。citeturn19view1turn19view3turn20view0turn41search0turn8view6turn13search0
| 场景 | 数据与环境 | 主要结果 | 对 SDD 的含义 |
|---|---|---|---|
| 领域建模辅助 MAGDA | 30 名参与者,来自加拿大与西班牙 | 自动模式较无辅助缩短约 22%;接受率 0.33;贡献率 0.56 | 支持 ADD/MDD 阶段“过程内建议”,不支持“做完再补建议” |
| 用例模型生成 | 5 位专业软件工程师 | 建模时间下降约 60%,质量基本持平 | 说明从 URD 到结构化分析模型的迁移可显著加速 |
| SGCR 规范约束代码评审 | 工业实环境部署 | 建议采纳率 42%,高于基线 22% | 说明“规范落地到审查规则”比裸 prompt 更可信 |
| CompileAgent | Repo-level compilation benchmark | 编译成功率从 10% 提升到 71% | 说明 RMD + 工具调用 + 错误恢复对真实仓库任务有效 |
| TestGen | 生产级移动端工程环境 | 518 个测试落地,CI 执行 961 万次,发现 5702 个故障 | 说明 TDD 文档若可转为自动测试流水线,可带来长期收益 |
注:这些研究的任务类型、评测环境和模型设置不同,不能把百分比直接横向当作统一排行榜;但它们共同支持“规范前置、过程内反馈、工具闭环、可回放轨迹”这四个设计判断。citeturn19view1turn19view3turn20view0turn41search0turn8view6turn13search0
下面这张图把 MAGDA 的平均完成时间可视化。它最重要的信息不是“自动模式是否统计显著领先于按需模式”,而是“端态建议明显最差,过程内建议整体更有效”。citeturn19view1turn19view3
xychart-beta
title "不同建模辅助模式的平均完成时间"
x-axis ["无辅助","按需建议","自动建议","结束后建议"]
y-axis "分钟" 0 --> 14
bar [10.4, 8.5, 8.1, 13.4]
评测基准方面,现状也很清楚:社区已经从单函数补全,走到 repo-level issue resolution、repo-level retrieval、issue reproduction test generation、test-first benchmark 和统一 software engineering agent bench。SWE-bench 正集仍是 2294 个真实 GitHub issue;SWE-bench Verified 是与 entity["company","OpenAI","ai company"] 合作整理的 500 个经人工核验的子集;RepoBench 把 repository-level 自动补全拆成 Retrieval、Completion、Pipeline 三个任务;SWT-Bench 把 issue repair 转换为 reproducing test generation,并给出 1700+ 个样本;TDD-Bench Verified 提供 449 个 test-first issue;USEbench 则把 SWE-bench、SWT-bench 和 REPOCOD 混成 1271 个仓库级任务;SWE-rebench 进一步把评测做成时间滚动窗口,以减轻污染问题。citeturn35view1turn43view0turn45view1turn46view0turn46view3turn35view2
| 基准 | 主要任务 | 规模 | 适合评估的 SDD 阶段 | 主要局限 |
|---|---|---|---|---|
| SWE-bench | 真实仓库 issue 修复 | 2294 | RMD、执行闭环 | 静态公开集,存在污染与泄漏风险 |
| SWE-bench Verified | 人审子集 issue 修复 | 500 | RMD、执行闭环 | 仍主要面向修复,不覆盖规范前端 |
| RepoBench | Retrieval / Completion / Pipeline | Python/Java 多子集;如 RepoBench-P 约 1.06–1.09 万样本/语言 | MDD、上下文检索 | 偏自动补全,不直接评估需求与测试工件 |
| SWT-Bench | issue reproduction test generation | 1700+ | TDD、执行验证 | 目前主要是 Python,且有历史污染风险 |
| TDD-Bench Verified | test-first issue test generation | 449 | TDD | 仍偏 issue 级,缺少更高层设计语义 |
| USEbench | 统一 coding/testing/patching | 1271 | RMD、统一 Agent 能力 | 仍属于组合基准,前端规范评估较弱 |
| SWE-rebench | 滚动、去污染 issue 评测 | 每时间窗约几十题 | 泛化与时效性 | 可比性与复现实验成本更高 |
注:RepoBench 的规模以公开论文给出的 Python/Java 子任务统计为准;SWT-Bench 的公开摘要给出“1700+”;SWE-rebench 会随时间窗变化。citeturn35view1turn43view0turn45view1turn46view0turn46view3turn35view2
不过,分数正在变高,并不意味着问题已经解决。SWE-Bench+ 的经验分析指出,SWE-Agent+GPT-4 原先 12.47% 的成功率,在过滤 solution leakage 和弱测试后会掉到 3.97%;其中 32.67% 的“成功补丁”涉及泄漏,31.08% 属于可疑补丁,且超过 94% 的 issue 早于模型知识截止时间。与此同时,SWE-bench 官方页面已经将 Verified 定义为 500 个 hand-validated 实例,但私人子集与滚动基准常显著更难,SWE-rebench 甚至按月份窗口重建问题集来压制污染。对 SDD 而言,这意味着别把 leaderboard 当成充分证据,更不能拿它替代自身的测试和追溯体系。citeturn8view7turn35view1turn35view2turn25search13
因此,面向 SDD 的评测指标也不该只剩下“Resolved %”。更合理的是把指标分成规范质量、追溯质量、执行质量和经济性四组。citeturn42search11turn45view1turn33view0turn42search2
| 指标 | 含义 | 更适合的阶段 | 公开实践对应 |
|---|---|---|---|
| 需求覆盖率 | 被 MDD/TDD/RMD 明确覆盖的 URD 条目比例 | URD→MDD | 需求工程与追溯研究 |
| 追溯精确率 / 召回率 | 需求—设计—代码—测试链接的正确性与完整性 | 全阶段 | RE traceability、LiSSA/LLM traceability 研究 |
| 设计耦合密度 | 设计矩阵中非对角依赖比例或关键耦合数 | ADD | 公理设计/DSM 思路 |
| 建议接受率 / 贡献率 | 模型建议被采纳比例、最终工件中由建议贡献的比例 | ADD、MDD | MAGDA |
| Fail-to-pass rate | 测试在修复前失败、修复后通过的比例 | TDD | SWT-Bench、TDD-Bench Verified |
| Patch coverage | 生成测试覆盖到真实修改区域的程度 | TDD | SWT-Bench、TDD-Bench Verified |
| Code/Identifier EM | 代码级和标识符级精确匹配 | MDD→编码 | GraphCoder、RepoBench |
| Resolved % | 仓库级任务被真正解决的比例 | RMD、执行闭环 | SWE-bench/USEbench |
| 轨迹可解释性 | TAR 日志是否能定位失败起点与反模式 | RMD、执行闭环 | TAR/CodeTracer |
| 成本与时延 | token、总费用、步数、CI 时长 | 全阶段 | Agent 评测方法论文 |
注:表中部分指标来自公开 benchmark,部分是本文基于这些 benchmark 所作的生命周期映射。对面向 Agent 的 SDD 来说,最好同时记录质量、性能、追溯和成本四类指标。citeturn19view3turn23view0turn45view1turn46view0turn33view0turn42search2
可复现流程、模板、假设与实验议程
要让这套方法真正“可复现”,最好的做法不是再造一个巨型平台,而是把原始规范、wiki 编译、上下文打包、Agent 轨迹和 CI 验证做成一条可以在版本库中回放的流水线。当前评测研究已经明确建议公开 prompt、温度、模型版本,以及 Thought–Action–Result 轨迹;llm-wiki 和 DeepWiki 一类系统又表明,文档层最好先被编译成结构化 wiki,而不是在运行时从散文中临时找答案。结合这两点,最稳妥的做法是:**把文档当源码,把 wiki 当中间表示,把 TAR 当运行日志。**citeturn33view0turn28view0turn28view1turn42search2
一个可直接落地的仓库布局可以是下面这样。它故意把规范、wiki、Agent 配置和证据包拆开,避免互相污染。这个布局不是公开标准,而是本文基于现有研究提出的最小可复现实现。
repo/
specs/
urd/
URD-0001-product-scope.md
URD-0002-acceptance.md
add/
ADD-0001-fr-dp-matrix.md
ADD-0002-design-rationale.md
mdd/
MDD-0001-module-map.md
MDD-0002-interface-contracts.md
tdd/
TDD-0001-acceptance-tests.md
TDD-0002-regression-oracles.md
rmd/
RMD-0001-implementation-route.md
RMD-0002-risk-gates.md
wiki/
index.md
glossary.md
traceability.md
decisions/
modules/
tests/
routes/
issues/
agent/
system-prompt.md
retrieval-policy.yaml
escalation-policy.yaml
evidence/
tar/
ci/
benchmarks/
在这个布局上,最实用的模板不是长篇文档,而是能被机器检查的 front-matter。下面给出一组最小模板。它们的价值在于结构,而不在于字段多少。
# URD 最小模板
id: URD-0001
title: 用户目标与边界
stakeholders: [product, ops, developer]
goals:
- ...
non_goals:
- ...
constraints:
- ...
acceptance_criteria:
- id: AC-01
statement: ...
assumptions:
- ...
ambiguities_to_resolve:
- ...
# ADD 最小模板
id: ADD-0001
functional_requirements:
- id: FR-01
text: ...
design_parameters:
- id: DP-01
text: ...
mapping:
- fr: FR-01
dp: DP-01
couplings:
- fr: FR-02
dp: DP-01
decision_rationale:
- ...
# MDD 最小模板
id: MDD-0001
module: billing
responsibility: ...
inputs: [...]
outputs: [...]
invariants:
- ...
depends_on:
- auth
- ledger
public_interfaces:
- name: CreateInvoice
preconditions: [...]
postconditions: [...]
# TDD 最小模板
id: TDD-0001
target_requirement: AC-01
scenario: ...
fixtures: [...]
oracle:
before_fix: fail
after_fix: pass
coverage_targets:
- module: billing
lines: critical-path
negative_cases:
- ...
# RMD 最小模板
id: RMD-0001
goal: deliver feature X
ordered_steps:
- step: localize modules
- step: implement contract
- step: run acceptance tests
stop_conditions:
- unresolved ambiguity in URD
- coupling violates ADD
rollback_points:
- after interface stub
escalation:
- on_requirement_conflict: reopen_URD
在 llm-wiki 编译阶段,建议不要按“原文章节”切 wiki,而要按“Agent 真正需要的检索单元”切。更实用的 page type 通常是:术语页、需求页、决策页、模块页、接口页、测试页、路径页、问题页、追溯页。尤其是“问题页”不可省,因为它是“搞不定就回 URD”的落点:当 Agent 遇到矛盾、语义缺失、模块边界不清或 oracle 不足时,先产出 wiki/issues/PROB-xxxx.md,然后由规则决定回写到 URD、ADD、MDD 还是 TDD,而不是让 Agent 在局部上下文里继续试错。这个设计与 llm-wiki 的“持续更新中间知识层”、DeepWiki 的“可定向生成 specific pages”、以及评测研究提倡的 TAR 轨迹公开是高度一致的。citeturn28view0turn28view1turn33view0
把这些工件串成流水线时,可以采用下面的规则:先对 URD 做术语和歧义 lint;再在 ADD 中生成 FR/DP 矩阵并标记耦合;随后由 MDD 导出模块图和接口契约;然后由 TDD 为每个 AC 生成 fail-to-pass 测试规格和回归用例;RMD 再根据依赖和风险门生成实施序列;最后由 wiki 编译器生成索引页与任务上下文包。对于 bugfix 任务,上下文包应该优先装入模块页、测试页、相关决策页和最近失败页;对于 feature 任务,优先装入 URD、ADD、MDD、RMD;对于 refactor,优先装入设计矩阵、接口契约、回归测试与性能约束。citeturn42search11turn45view1turn23view0turn33view0
这套方案建立在几个明确假设上:目标系统主要是多文件软件项目而不是纯算法题;规范与图表可被文本化并放入版本库;测试和 CI 可运行;Agent 具备 shell、搜索、测试等工具调用,但默认无权直接修改生产环境;最终合并仍有人工责任人。相应地,它也有明确局限:URD/ADD/MDD/TDD/RMD 这套命名尚未成为行业标准;公开证据对前端需求与设计的支持仍弱于后端编码与修复;主流 benchmark 偏向公开开源仓库和 Python;结果高度依赖模型版本、脚手架和环境约束;llm-wiki/DeepWiki 一类系统尚无统一 benchmark 来评估页面正确性、新鲜度与冲突合并质量。citeturn37view0turn33view0turn8view7turn35view2turn28view1turn28view3
研究缺口也很集中。第一,需求质量本身会显著影响后续 traceability 与生成质量,RE 研究已开始报告 requirements smells 会明显拖低 LLM 在 traceability 任务上的表现,这意味着“从 URD 重改”不是保守主义,而是必要的上游修复。第二,规范往往仍停留在文本,不足以形成强约束;VeriSpecGen、VeriEquivBench 与 vericoding 基准说明,形式化规格合成和可验证代码正在快速进步,但离通用工程化还有距离。第三,评测仍缺少细粒度解释;CodeTracer 这类工作已经开始把异构 Agent 日志统一成层级化 trace,并提供成千上万条带标注轨迹,这正是未来 SDD 评测所需要的中层证据。citeturn39search12turn47search0turn47search5turn47search6turn42search2
如果要把本文主张变成可以验证的研究计划,最值得优先做的实验有四组。其一,端到端消融实验:比较 Direct Prompt、URD→MDD、URD→ADD→MDD→TDD→RMD、再到加上 llm-wiki 的完整链条,测 resolved%、回归缺陷数、trace coverage、人工审查时长和 token 成本。其二,知识层消融实验:比较原始 RAG、vector-only RAG、graph RAG、wiki+graph hybrid,对模块定位、多跳问答和 patch 成功率进行对照。其三,规范强度阶梯实验:比较“只有测试”“契约+测试”“形式规格+测试”,测 fail-to-pass、patch coverage、过拟合率和缺陷回流率。其四,失败回写实验:比较“局部修补直到通过”与“按追溯链回到最早失真工件”的两种策略,观察后续迭代中的返工、回滚和 reviewer 信任差异。所有实验都应公开模型版本、prompts、环境镜像、TAR 轨迹与成本日志。citeturn30search0turn33view0turn45view1turn42search2turn47search15
综合来看,面向 Agent 的 SDD 最值得坚持的不是某个缩写本身,而是一个更朴素的工程原则:文档不是附属品,文档是 Agent 的控制面;wiki 不是知识库皮肤,wiki 是规范的中间表示;测试不是开发收尾,测试是规范的可执行部分;一旦 Agent 失败,真正需要修的常常不是最后那段代码,而是更上游的需求、设计或路径工件。 现有研究还不足以宣布这条路线已经定型,但已经足以说明,它比“对着大模型堆 prompt 写完整产品”更接近一条能长期工作的工业方法。citeturn8view0turn28view0turn42search11turn33view0
参考文献
- Assured LLM-Based Software Engineering. InteNSE / ICSE Workshop, 2024. citeturn8view0
- Formal requirements engineering and large language models: A two-way roadmap. Information and Software Technology, 2025. citeturn36view0
- Promptware Engineering: Software Engineering for Prompt-Enabled Systems. ACM TOSEM, 2025/2026 版本公开稿。citeturn32view0
- Large Language Model-Based Agents for Software Engineering: A Survey. 2024 预印本,后续正式发表。citeturn10search9
- Agents in Software Engineering: Survey, Landscape, and Vision. Automated Software Engineering, 2025. citeturn9search13
- Agent Design Pattern Catalogue: A Collection of Architectural Patterns for Foundation Model based Agents. Journal of Systems and Software, 2025. citeturn27search3
- On the Utility of Domain Modeling Assistance with Large Language Models. ACM TOSEM, 2025. citeturn18view0turn19view1turn19view3
- Leveraging Large Language Models for Use Case Model Generation from Software Requirements. ISE@ASE, 2025. citeturn20view0
- RepoAgent: An LLM-Powered Open-Source Framework for Repository-level Code Documentation Generation. 2024. citeturn8view5
- RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation. EMNLP, 2023. citeturn23view1
- GraphCoder: Enhancing Repository-Level Code Completion via Code Context Graph-based Retrieval and Language Model. ASE, 2024. citeturn23view0
- REPOBENCH: Benchmarking Repository-Level Code Auto-Completion Systems. ICLR, 2024. citeturn43view0
- CompileAgent: Automated Real-World Repo-Level Compilation with Tool-Integrated LLM-based Agent System. 2025. citeturn8view6
- Observation-based Unit Test Generation at Meta. FSE Industry, 2024. citeturn13search0
- SWT-Bench: Testing and Validating Real-World Bug-Fixes with Code Agents. 2024. citeturn45view1
- TDD-Bench Verified: Can LLMs Generate Tests for Issues Before They Get Resolved? 2024. citeturn46view0turn46view1
- Unified Software Engineering Agent as AI Software Engineer. ICSE 2026 预印本。citeturn46view3turn46view4
- Reproducible, Explainable, and Effective Evaluations of Agentic AI for Software Engineering. FSE Companion, 2026. citeturn33view0
- SWE-bench Verified 官方说明与 leaderboard 文档。citeturn35view1turn35view0
- SWE-Bench+: Enhanced Coding Benchmark for LLMs. 2024. citeturn8view7
- SWE-rebench: A Continuously Evolving and Decontaminated Benchmark for Software Engineering LLMs. 2025–2026 在线基准。citeturn35view2
- Reliable Graph-RAG for Codebases: AST-Derived Graphs vs LLM-Extracted Knowledge Graphs. 2026. citeturn30search0
- Intent-aligned Formal Specification Synthesis via Traceable Refinement. 2026. citeturn47search0
- VeriEquivBench: An Equivalence Score for Ground-Truth-Free Evaluation of Formally Verifiable Code. 2025. citeturn47search5turn47search13
- A Benchmark for Vericoding: Formally Verified Program Synthesis from Formal Specifications. 2026. citeturn47search2turn47search6
- CodeTracer: Towards Traceable Agent States. 2026. citeturn42search2
- LLM Wiki. 2026 idea file / gist. citeturn28view0
- DeepWiki 官方文档与产品说明。citeturn28view1turn28view2turn29view0
- OpenDeepWiki 项目说明。citeturn28view3
- 《基于大语言模型的需求歧义检测方法》. 《计算机研究与发展》, 2026. citeturn31search0turn31search6