
现在流行“氛围编程”,各种“用AI一句话完成某某任务”。在生物医药领域,最常见的计算任务就是各种统计学假设检验了。那么能否将问题直接丢给AI,让它来做假设检验呢?
题目构造
首先,我们构造一个简单的统计学题目。
问题描述
背景:
一家生物制药公司研发了三种新的候选药物:药物A、药物B和药物C。为了评估这些药物的有效性,研究人员进行了一项临床前试验。
实验设计:
研究人员选择了98只生理指标水平相似的实验小鼠,并将它们随机分为四组:
- A组 (n=23):服用药物A。
- B组 (n=25):服用药物B。
- C组 (n=28):服用药物C。
- 对照组 (n=22):服用生理盐水(安慰剂)。
在给药2小时后,测量并记录每只小鼠的某特定生理指标水平。
研究问题:
与对照组相比,药物A、B、C中,有哪些药物能够显著降低实验小鼠的某特定生理指标水平水平?(显著性水平 α = 0.05)
数据假设:
- 各组样本数据均独立。
- 我们无法知道某特定生理指标水平是否是正态分布的。
实验数据
以下是本次实验记录的各组小鼠某特定生理指标水平,数据已经过整理:
对照组 (Control Group)
-
样本量 (n): 22
-
数据:
8.5, 9.1, 7.8, 8.8, 9.5, 7.2, 8.3, 9.9, 8.0, 7.6, 9.2, 8.4, 8.9, 7.1, 9.7, 8.6, 8.1, 7.9, 9.3, 8.7, 9.0, 7.5
A组 (Group A) -
样本量 (n): 23
-
数据:
8.2, 7.5, 9.0, 7.9, 8.8, 7.1, 8.4, 9.4, 7.7, 8.1, 8.9, 7.3, 8.6, 9.2, 7.0, 8.5, 7.8, 9.6, 8.3, 7.6, 9.1, 8.0, 8.7
B组 (Group B)
- 样本量 (n): 25
- 数据:
9.3, 8.0, 8.8, 7.7, 9.7, 8.4, 7.2, 8.9, 9.5, 8.1, 7.5, 9.1, 8.6, 7.9, 9.9, 8.3, 7.0, 9.2, 8.5, 7.8, 9.6, 8.2, 7.6, 9.0, 8.7
C组 (Group C)
- 样本量 (n): 28
- 数据:
6.9, 7.8, 6.2, 7.5, 8.1, 6.5, 7.9, 5.8, 7.1, 8.4, 6.7, 7.3, 8.0, 6.0, 7.6, 8.2, 6.8, 7.7, 5.9, 7.2, 8.5, 6.4, 7.0, 8.3, 6.6, 7.4, 6.3, 8.6
答案解析:
先说这道题的答案:由于不能确定数据是否是正态分布是否方差齐性,所以应当进行的是:
- 总体差异检验:首先,使用 克鲁斯卡尔-沃利斯检验(Kruskal-Wallis H-test) 来判断所有四个组(A, B, C, 对照组)的总体分布是否存在显著差异。这个检验是单向方差分析(One-way ANOVA)的非参数替代方法。如果这个检验结果不显著,我们通常就认为各组之间没有差异,无需进一步分析。如果结果显著,则说明至少有一组与其他组不同,需要进行后续的两两比较。
- 两两比较:在确定了总体存在差异后,我们需要进行两两比较,以找出具体是哪个药物组与对照组有差异。这里我们将使用 曼-惠特尼U检验(Mann-Whitney U test),它是独立样本t检验的非参数替代方法。
- 多重比较校正:由于我们进行了三次独立的比较(A vs 对照组, B vs 对照组, C vs 对照组),这会增加犯第一类错误(即错误地拒绝原假设,出现假阳性)的概率。为了控制这个风险,我们需要对显著性水平 α 进行校正。最常用且简单的方法是 邦弗朗尼校正(Bonferroni correction)。
- 校正方法:将原始显著性水平 α (0.05) 除以比较的次数 (k=3)。
- 新的显著性水平 α' = α / k = 0.05 / 3 ≈ 0.0167。
- 在进行两两比较时,只有当p值小于0.0167时,我们才认为差异是统计显著的。
- 单侧检验:研究问题是“药物能否显著降低生理指标水平”,这是一个有方向性的问题。因此,在进行曼-惠特尼U检验时,我们需要进行单侧检验(one-tailed test)。
计算结果:
--- Kruskal-Wallis H-test ---
H-statistic: 28.6862
P-value: 0.0000
结论: 各组之间存在显著差异,可以进行两两比较。
--- Mann-Whitney U Tests (与对照组比较) ---
原始显著性水平 α = 0.05
邦弗朗尼校正后显著性水平 α' = 0.0167
药物A vs. 对照组:
U-statistic: 213.5
P-value (one-tailed): 0.1878
结论: 不显著 (p >= 0.0167)
药物B vs. 对照组:
U-statistic: 273.5
P-value (one-tailed): 0.4915
结论: 不显著 (p >= 0.0167)
药物C vs. 对照组:
U-statistic: 88.0
P-value (one-tailed): 0.0000
结论: 显著 (p < 0.0167)
备选AI
我常用的国内AI分别是通义千问、清华的GLM和豆包,前两者的模型都很出色,豆包则在应用实现上见长。对于DeepSeek,虽然它名声响亮,但其过去有很高的幻觉率并且缺乏对话之外的功能实现,所以我通常只用deepseek来写小说。但这次我也可以一并评测。
我们这次使用的都是各自的网页版,而不是手机版。这种涉及大量数据的,手机屏幕操作起来实在麻烦。
- 通义千问 Qwen3-VL-235B-A22B : https://chat.qwen.ai/
- GLM4.6: https://chat.z.ai/
- 豆包: https://www.doubao.com/
- DeepSeek: https://chat.deepseek.com/
初步测试
我们可以使用一个简单的prompt:"请选择合适的统计学假设检验方法,判断药物A,B,C的有效性。并解释选择该方法的原因。",再附上上述题目(别把答案一并给了)。我们需要验证的项目:
- 统计学方法是否选择正确:用Kruskal-Wallis H-test和Mann-Whitney U Tests,并进行校正
- 结论是否正确:A,B与对照组相同,C有差异。这里有个容易钻空子的地方,C组的均值明显小一点,很容易猜出其有效
- 计算结果是否正确:
- H-statistic: 28.6862
- A vs 对照: U-statistic: 213.5,P-value (one-tailed): 0.1878
- B vs 对照: U-statistic: 273.5,P-value (one-tailed): 0.4915
- C vs 对照: U-statistic: 88.0, P-value (one-tailed): 0.0000
初步测试结果:
- Qwen3: 统计方法选择正确;结论正确;未进行计算。Qwen3 很诚实,没算就是没算,把python程序列出来了,但没有执行出结果
- GLM4.6: 统计方法选择正确;结论正确;未进行计算。GLM 4.6也很诚实。
- 豆包:统计方法选择正确;结论正确;给出了计算结果,
- A 组 vs 对照组:U=227.5,p=0.182(>0.0167,不显著);
- B 组 vs 对照组:U=252.0,p=0.365(>0.0167,不显著);
- C 组 vs 对照组:U=58.0,p<0.001(<0.0167,显著)。
- DeepSeek: 统计方法选择正确;结论正确;计算结果几乎正确。
- A vs 对照组:U = 213.5,z值 ≈ -0.896,p值 ≈ 0.185,p值 > 0.0167,不显著。
- B vs 对照组:U = 273.5,z值 ≈ -0.032,p值 ≈ 0.487,p值 > 0.0167,不显著。
- C vs 对照组:U = 88,z值 ≈ -4.299,p值 < 0.0001(远小于0.0167),p值 < 0.0167,显著。
评估讨论
- 各大AI对统计学方法的选择是很统一的,这一点其实就已经很有帮助。可以把AI当作一个见多识广的师兄弟,在统计学方法上可以多多请教。如果不确认,可以多问几个AI,大家互相同行评议。
- 豆包并没有真正计算,就是蒙了个数字,还不说自己是蒙出来的,最为恶劣。
- DeepSeek可以展开看思考过程,我发现它居然手工计算了一遍U值。这里的错误是在p值的计算上,虽然大方向是对的,猜测的误差也很小,但能够看出来是猜的。DeepSeek的手算虽然精神可嘉,而且自己手算了三遍,但如果数据量大起来,恐怕并不可靠。
- Qwen3和GLM4.6虽然诚实,但并未解决问题。
可以看出DS最接近完成,但具体数据仍然有误差,所以更好的方式是令AI能够调用自己写好的代码,借助程序来计算结果。
此处还有一个问题,我们在判断DS不可靠时,是将其与预先计算好的结果相比较。但如果你并没有提前算好的结果,那应该怎么办?一个可行的方法是,新开一个对话页面,把问题再问一遍,看计算结果,如果算法中没有随机抽样的过程(如本例),那么计算结果一定是相同的,如果两次或者多次的结果有差异,说明它没有真正计算,是猜的。
AI代码运行能力
显然各大AI是不可能预装SPSS的,要让它们计算,需要运行程序源代码。常用在统计学上的计算机语言有R和Python,但不一定AI供应商提供了这种语言的运行环境。因为这相当于该供应商要给用户提供一个类似于虚拟电脑的东西,分配计算资源,这是相对小众的需求,要实现起来有一定成本,AI供应商不一定愿意。
除了R和python,有很多AI还会进行网页的撰写,在网页运行时也有一种能够计算的语言叫做Javascript,它实际上是在浏览器中运行的,其实并不占AI供应商的运算能力,所以这部分很有可能提供。
为了测试各AI是否具有代码运行能力。我请Gemini设计了这样的prmopt:
- 请使用Python的SciPy库,帮我计算标准正态分布在x=1.234处的概率密度函数(PDF)值,小数点后保留8位精度,并给出代码。
- 请使用R语言(例如,使用内置的stats包),帮我计算标准正态分布在 x=1.234 处的概率密度函数(PDF)值,小数点后保留8位精度,并给出代码。
- 请使用JavaScript,并调用一个从CDN(例如 jsDelivr 或 cdnjs)加载的流行统计库(例如 jStat.js),帮我计算标准正态分布在 x=1.234 处的概率密度函数(PDF)值。请小数点后保留8位精度,并给出一个完整的HTML文件示例代码。如果CDN调用错误,应该检测并告知用户
这里的SciPy, stats和jStat.js都是各语言用于统计学分析的专用工具包,这些工具包通常是开源的,已经接受了很多的审核。这样做比让AI自己去写假设检验的算法更可靠。其中JavaScript需要从外部网站(内容分发网络,简称CDN)调用这个工具包。
这道题的正确答案是:0.18631499
还有一个禁止AI使用外部统计库的测试prmopt:
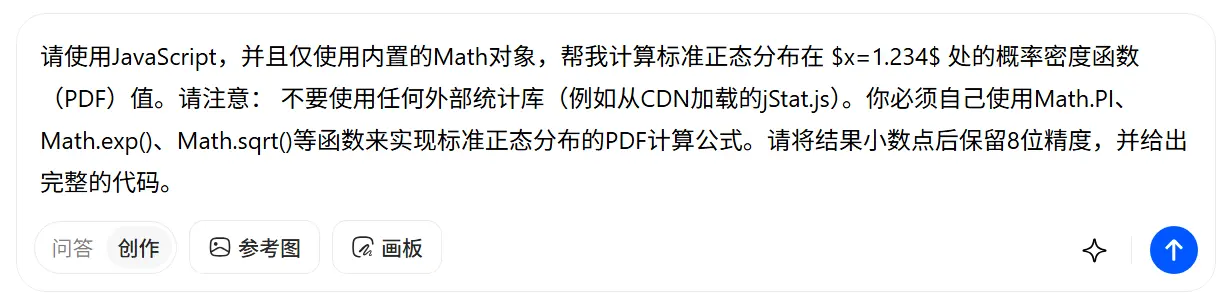
请使用JavaScript,并且仅使用内置的Math对象,帮我计算标准正态分布在 $x=1.234$ 处的概率密度函数(PDF)值。请注意: 不要使用任何外部统计库(例如从CDN加载的jStat.js)。你必须自己使用Math.PI、Math.exp()、Math.sqrt()等函数来实现标准正态分布的PDF计算公式。请将结果小数点后保留8位精度,并给出完整的代码。
AI代码运行能力测试结果
- Python(SciPy)和R语言的测试:全军覆没! Qwen3, GLM4.6, 豆包, DeepSeek没有一个能做对的。这种到小数点后8位的精度验证就可以找出滥竽充数的AI。】=
- 【修订: GLM如果开启了“Full-Stack”,则它会以python作为“后端”,进行“全栈开发”,此时是可以用Scipy的】
- JavaScript调用jStat.js的测试:全军覆没!
- 【修订1: Qwen3又能用了通过了,不确定是否是测试当时CDN出错】
- 【修订2:仔细分析豆包的代码后发现这几个AI会把代码中jState.js写成jstat.js,导致计算出错,如果强调“注意jStat.js的大小写”,则可以通过。这种细微的小坑对新手太难了,不要指望你能发现。】
- 【修订3: GLM表现是无显示,追问后得到:“问题在于我创建了一个独立的HTML文件,但Next.js项目需要通过页面组件来显示内容。”然后再修改后可以正确加载】
- 【简单地说,上述修订后能通过的情形,对于一个编程新手来说,几乎是仍然无法通过的。】
注意在使用js进行计算时,要令AI以为自己在做网页,
- 在Qwen3,叫“网页开发”

- 在GLM4.6,叫“Full-Stack”

- 在豆包,叫“创作”
- DeepSeek没有选项
单纯使用js内置Math对象的测试:
- Qwen3:通过
- GLM4.6:通过
- 豆包:通过,但要点击一下“运行”按钮,豆包自己的文字回答在瞎掰
- DeepSeek:错误,不能执行代码。DS自己胡诌了一个答案。
讨论
看来只有让这些AI以做网页的形式来计算统计学问题了,而且不能依赖外部现成的统计学工具包,只能让它们自己写假设检验函数。
完整测试
这次我们使用更确切的计算prompt:
“
请选择合适的统计学假设检验方法,判断药物A,B,C的有效性。并解释选择该方法的原因。
请使用JavaScript进行计算分析,并且仅使用内置的Math对象,请注意: 不要使用任何外部统计库(例如从CDN加载的jStat.js)。你必须自己使用Math.PI、Math.exp()、Math.sqrt()等函数来实现。
最终给出完整的计算结果和分析报告。
”
这一次的测试,各个AI其实不仅仅是在做计算,还需要设计出一个完整的网页来展示答案,所以耗时相当长。如果发现页面不动了,可以刷新一下。
- Qwen3: Kruskal-Wallis H-test未做。Mann-Whitney U Tests结果不正确
- 页面展示:没部署成功
- GLM 4.6: Kruskal-Wallis H-test计算结果不正确,Mann-Whitney U Tests计算结果不正确。
- 页面展示:https://s0tv28fckh50-deploy.space.z.ai/
- 豆包: Kruskal-Wallis H-test计算结果不正确,Mann-Whitney U Tests计算结果不正确。
- 页面展示:https://www.doubao.com/share/code/6de9d0fc5de865d9
- DeepSeek:根本没算,自己胡编了答案。
【补充修订】
- Qwen3后来不知为啥又可以用jStat了,但计算结果仍有微小差异
- GLM4.6在全栈模式下,可以使用python当作后端,能够调用scipy。但一开始按双侧检验计算的,如果提出质疑,则能够计算出正确结果。
讨论
要让AI自动完成统计学假设检验。需要通过几个关卡:
- 选择正确的假设检验方法。这一点大多数AI都可以做到,其实已经给了很大的帮助。当不确定时可以多问几个AI,让他们之间互相同行评议。
- AI要能够调用计算工具进行高精度的计算。实测后发现,调用外部统计学工具包很困难,当前似乎只能用Javascript的内置Math对象进行计算。
- AI应当使用经过验证的统计学工具包,以避免其自行编写假设检验函数时出错。由于调用外部CDN总是出错,所以其实也无法达成。
- AI在编写程序时应当注意不要引入新的误差,例如由于样本量不同,如果将所有数据放入一张数据表进行操作(例如Python的Pandas),就有可能遇到空值填充的问题,如果填充方式不正确,就会导致运算结果出错。这一层的问题需要有足够的编程能力。
就当前的测试,国内AI没有能够通过这些关卡的。实际上我也测试了国外AI,目前能够免费使用的版本中,只有Google的AIstudio可以正确完成所有计算,并且不出错,这次的题目也是由它进行的计算。
【修订1:补充讨论】
在发现CDN可用之后,再次对Qwen3进行了测试,这次的答案中U值计算正确,但对应的p值计算大约翻倍,于是质问Qwen3是否应当使用单侧分析,Qwen3发现问题所在,重新计算。计算后的p值仍然有微小的差异。将代码交给AI studio(Gemini 2.5 pro)分析。可以看出如果不使用专业的统计包和正确的设置,要完全取得正确答案仍然是非常困难的。
以下为报告:
附注:关于不同统计工具计算结果差异的说明
在本次分析中,我们注意到若使用不同的统计软件或库(例如Python的scipy库与某些在线JavaScript计算器),可能会得到略有差异的p值。例如,本报告采用scipy计算药物A和B相对于对照组的p值分别为0.1878和0.4915,而一个基础的JavaScript实现给出的p值为0.1849和0.4872。
经过验证,Python scipy库的结果更为准确和可靠。这种差异主要源于scipy在执行曼-惠特尼U检验时,默认包含了两个重要的统计校正:
- “结”校正 (Tie Correction):当数据中存在多个相同的值时(即“结”),此校正会调整检验统计量的方差,使得结果更加精确。我们的实验数据中存在大量的“结”,因此该项校正非常必要。
- 连续性校正 (Continuity Correction):在使用连续的正态分布来近似离散的U统计量分布时,该校正可以提高近似的准确性,通常会使结果更为保守。
由于网页版的基础脚本未执行这些标准的校正,其结果存在微小偏差。因此,本报告完全采信经过专业统计库scipy计算得出的p值作为最终判断依据,以确保分析的严谨性和准确性。
结论
- 如果你不具备一定的编程能力和足够的统计学知识,当前国内AI还不足以完成自动化的统计学假设检验分析。
- 如果有一定的编程经验和统计学知识,Qwen3和GLM4.6 是好帮手,使用得当时很可能得到正确结果。
本次评测仅仅代表当前时间(2025年10月19日)和当前运行环境下的评测。AI发展很快。
【更新】
- 后来我换了AI友好的统计学方法,成功了。具体参考用AI进行统计学假设验证分析(这次成功了)