

# Jan Linden:不拘泥于传统的频率调节:人工智能带来更好的聆听

Whisper.ai工程部负责人,23年言语处理和语音信号领域研发经验
我们先从人工智能的发源开始谈起,它和互联网的发展是息息相关的。让我们回到1995年,互联网可以用来做很多事情。直到今天,互联网无处不在。
人工智能AI同样也无处不在。比如我们最常用的语音助手Siri和谷歌助手,就运用到了人工智能的技术。同样经过精心设计的算法(原文Smart algorithm)也能帮助解决需求,但在一些领域,这类算法还无法完全解决需求,例如听力健康。
都说人工智能将能够真正改善听力服务体验,但环顾整个行业,目前还没有人真正实现了这一点。所以我们放低我们对人工智能的高要求,在特定问题的解决上,人工智能还是能发挥它的作用。
HHTF
人工智能的关键概念:学习周期

Whisper.Ai在使用人工智能技术时,遵循学习周期Learning Cycle进行。
第一步, AI算法 AI algorithms。用于解决复杂问题的强大工具。
第一步, 改进性能 improved performance。AI的目的在于确保最终用户体验到性能得到改善的更好的产品。
第三步, 新数据New data。在循环中我们努力解决以前无法解决的挑战,更伟大的是学习中获得的新数据,这些数据可以反馈再对人工智能算法进行训练。
这样的循环就能让产品性能得到越来越好的表现。
把数据用于改进算法,Whisper.ai相信这一点,也做到了。我想谈谈我们是如何做到这一点的。
学习周期Learning Cycle中的算法是一个很好的开始,但能够训练他们(AI)和升级系统更为关键。这也是Whisper.Ai设计的核心环节: 可升级化。这才是一切的核心,通过对系统不断提高和改进,让用户得到更好的体验。
HHTF
传统的信号处理方法V.S.基于AI的信号处理方法
你我都非常熟悉传统助听器的信号处理方法,但这种方法的迭代速度总是缓慢的。
尤其对于经典的诉求——噪音下的言语处理,传统信号处理方法总是做的还不够好。
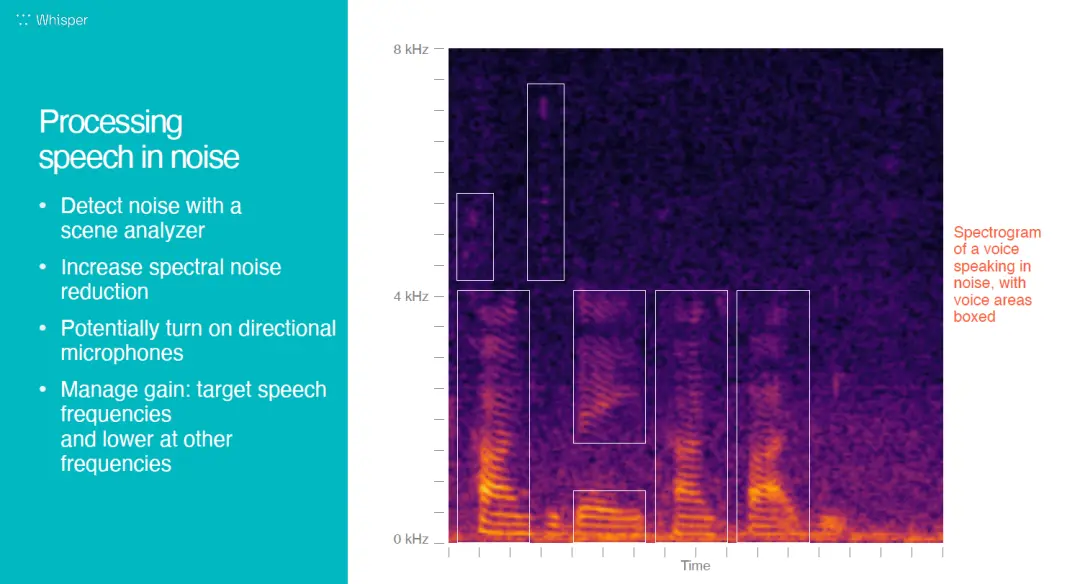
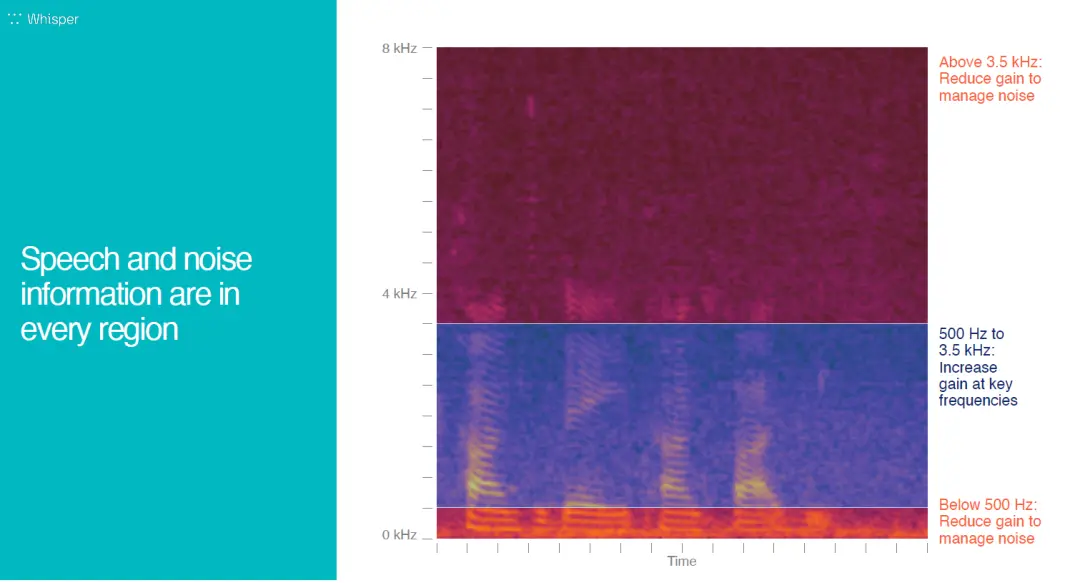
这是传统的信号处理方法处理过的语谱图。显示了言语声和一些背景噪音。我们可以看到复杂的语音环境,传统处理方法的处理能力遇到了局限。在噪声比言语声多的高频区(3.5KHz以上),我们降低增益,却也损失了言语信号。
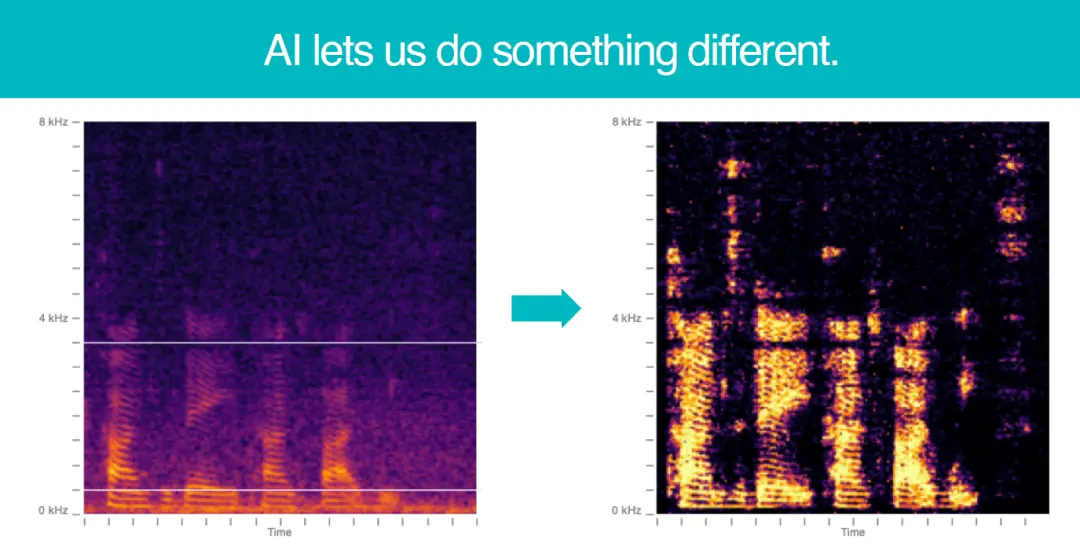
对比下,运用AI技术处理的语谱图,背景噪音得到了非常有效的抑制,甚至高频部分原来丢失的一些言语声又回来了。
HHTF
AI的特长:应对声音的复杂性
我们从声音的来源和所处的环境来分析声音的复杂性。
声音的来源有许多,或来自于人声,汽车轰鸣声,又或者是扩音喇叭。同样即使是一样的声源,因为发声环境的不同,也会让声音有所不同。这就是所谓声音的复杂性。
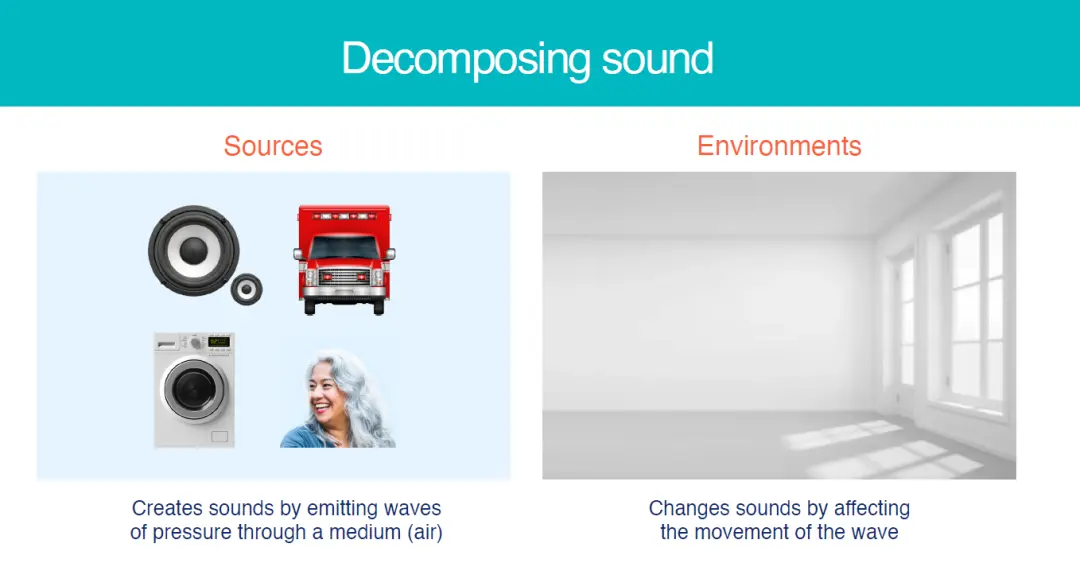
我们试图用一些可量化的参数来定义声源的特征。
-
音调,频率
-
音量,强度,振幅
-
谐波,音色
-
发声模式,声音重复
-
变化幅度,声源的固定性
同样在定义发声的环境,也有其多样性。
例如房间的大小,构造,墙面和地面的材质,又或者是空间内存在的物件。

所以在纷杂的声音中,再使用传统的方法,用量化的特征值去定位到我们感兴趣的声音,是非常具有挑战的。所以换个思路,用AI来实现言语声的分离,会是更有效的方法。

基于AI的处理方法不再是基于简单的频率分析,反而是运用所有的知识,通过对复杂声源和环境的一次次训练,搞清楚用户感兴趣的言语信号是哪些,并可以增强相应区域的信号强度。
当然了, AI并不是处理这类问题的唯一解决方法。在面对复杂的多重任务下,人工智能更善于处理需要大量运算的任务。而传统处理能力的低功耗运算能力同样非常重要。当将 两种处理信号结合运用,我们才能获得我们想象中最好的聆听表现。
HHTF
助听器的第二个人大脑:Whipser Brain

Whisper.AI的整套助听方案,由两块组成。一是按照传统高级助听器该有的样式和功能进行设计的助听器产品。你能想到的压缩管理、反馈管理和方向性功能它都具备。其二,也是Whisper真正不同于传统助听器的,我们把AI技术嵌入到我们的Whisper Brain中。言语分离技术的运行都在这独立设备上完成。


在常规的安静环境下,单独的Whisper助听器就能满足用户的聆听需求。当面对较为复杂的聆听环境时,再用Whisper Brain来改善聆听效果。 可分可合,是我们这套方案最绝妙的设计。
HHTF
独立的Whisper Brain存在的意义
为什么不把AI技术直接嵌入到助听器中?让我们看看两种技术所需要的芯片运算能力的差距有多大。
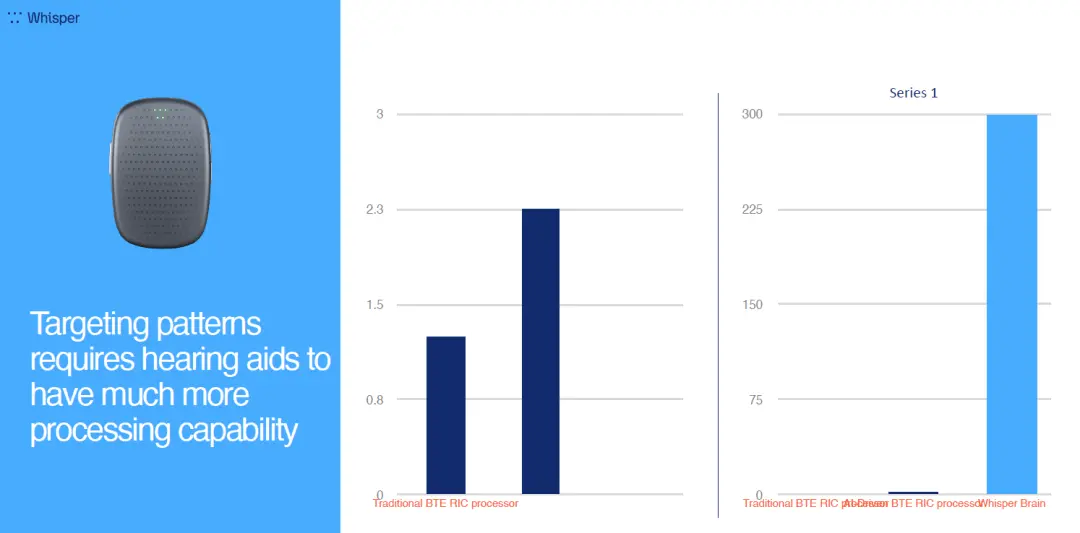
传统的助听器处理芯片,可达到每秒几百万次的操作。虽然伴随芯片制程和工艺技术的改进,这个运算速度还在不断提升。但是相较于AI运算所需要的运算速度,就显得相形见绌。
我们的Whisper Brain已经达到了每秒3000亿次运算。只有这样的运算速度,才能让AI技术在助听运算中发挥更有效的作用。
HHTF
践行学习周期的几个关键要素

-
一个强大的 运算引擎。通过Whisper Brain的超强算力可以实现。
-
产品的改进,更多是通过助听器和手机应用程序的无线连接,从而实现系统的迭代和更新
-
而 数据的收集和运用,则都会传递到Whisper Brain进行存储和再训练。
我们非常关注用户数据的保密性。在不录制声音,隐藏敏感信息的前提下Whisper Brain依旧能正常进行声源和环境的学习。

谈论到数据,Whisper最关心三种数据。一是 患者的佩戴体验和操作体验数据,虽然这并不直接影响AI算法本身,却是用来评估系统性能是否得到提升的有效数据。其次,是 声源和环境数据,我们可以利用用户真实的聆听体验,训练出一个更好的模型。
HHTF
更积极更开放的Whisper
Whisper懂得数据的重要性,也乐于分享。我们已经发表了多篇相关学术论文,并将部分数据以开放源代码的方式向外界公开。

与此同时,我们持续努力争取越来越好和更有代表性的数据,以提升我们Whisper产品的表现。

这是Whisper联合创始人在旧金山街头进行言语分离技术的实地测试
归根结底,我们只关心各种技术对用户是否带来正面的影响。一切都围绕着我们的用户。
Whisper.Ai的联系邮箱: [email protected](请备注信息来源于HHTF健康听力技术论坛)


扫码查看回放
健康听力技术论坛
往期回顾

随着TWS耳机的飞速发展、辅听产品技术的日新月异,以及美国FDA发布OTC助听器草案的政策驱动下,未来五年,助听产品和辅听产品的跨界与整合将成为主流趋势。
在行业变革时代背景下,北京听力协会主办了「健康听力技术论坛」,长期为大家提供发声的平台。论坛持续以每期两位嘉宾、不固定更新上线的形式长期举办。
期待声学领域、TWS领域、辅听及助听领域的专家、学者,以及产业供应链上中下游多方代表积极参与论坛并发表演讲。我们希望通过论坛的举办,搭建行业平台,促进产品变革,推动技术发展,为轻中度听损人士及健听人士提供更合适的听力保护及听力辅助方案,实现「全民健康听力」这一终极目标。

作者:Jan Linden
编辑:皇甫甜
排版:皇甫甜
「行业报告」
「案例沙龙」
「小儿听力学」
「临床听力师」
「技术论坛」
论坛资讯、 论坛回顾
「合作联系」



