Agent を書くということは、本質的にはファイルの読み書き、ネットワーク通信、さらにはシェル実行までできるものを作り、その舵取りを、プロンプトに影響され、間違いを犯し、誤導される可能性のある存在に委ねるということです。
だから私は、Agent を「プロンプトエンジニアリング」ではなく、「権限システムエンジニアリング」として捉える方が良いと思っています。
最近ずっと自分の AI Agent —— mistermorph を作っていて、安全性を中心にいくつかのトレードオフを検討しました。OS/コンテナに任せる部分、アプリケーション層で行う部分、プロンプト内で遮断する部分……そして mistermorph をどのように実装したか。
この記事は経験の共有であり、学術論文ではありません。完全防御の方法は説明しません(そもそも不可能です)。
詳細な実装については mistermorph のセキュリティドキュメント をご覧ください。
いくつかの原則
- LLM に秘密(token、API key、秘密鍵)を見せない
- LLM に自由に HTTP リクエストを組み立てさせない(秘密を持ち出すから)
- bash の手綱をしっかり握る
- OS/コンテナで解決できることは他の層で再発明しない
- アプリケーション層は OS では表現しにくい機能のみ保持する:内容のマスキング、ワークフローの承認、通信先の許可リストなど
- 最小権限の原則
以上です ✨
脅威モデル
Agent のリスクは三種類あります:
- 外部流出:情報を送ってはいけない場所へ送ってしまうこと
- 機密漏洩:key/token などの機密をプロンプト、ログ、ツールのパラメータ、履歴などに書き込んでしまうこと
- 越権行為:想定していない行動(ファイル削除、上書き、シェル実行など)をしてしまうこと
これらを防ぐには、まずシステムの境界を明確にする必要があります。
境界が定まれば、プロンプトインジェクションによる被害の上限も下がります。たとえ LLM が騙されたとしても、衝突(制限)にぶつかります。
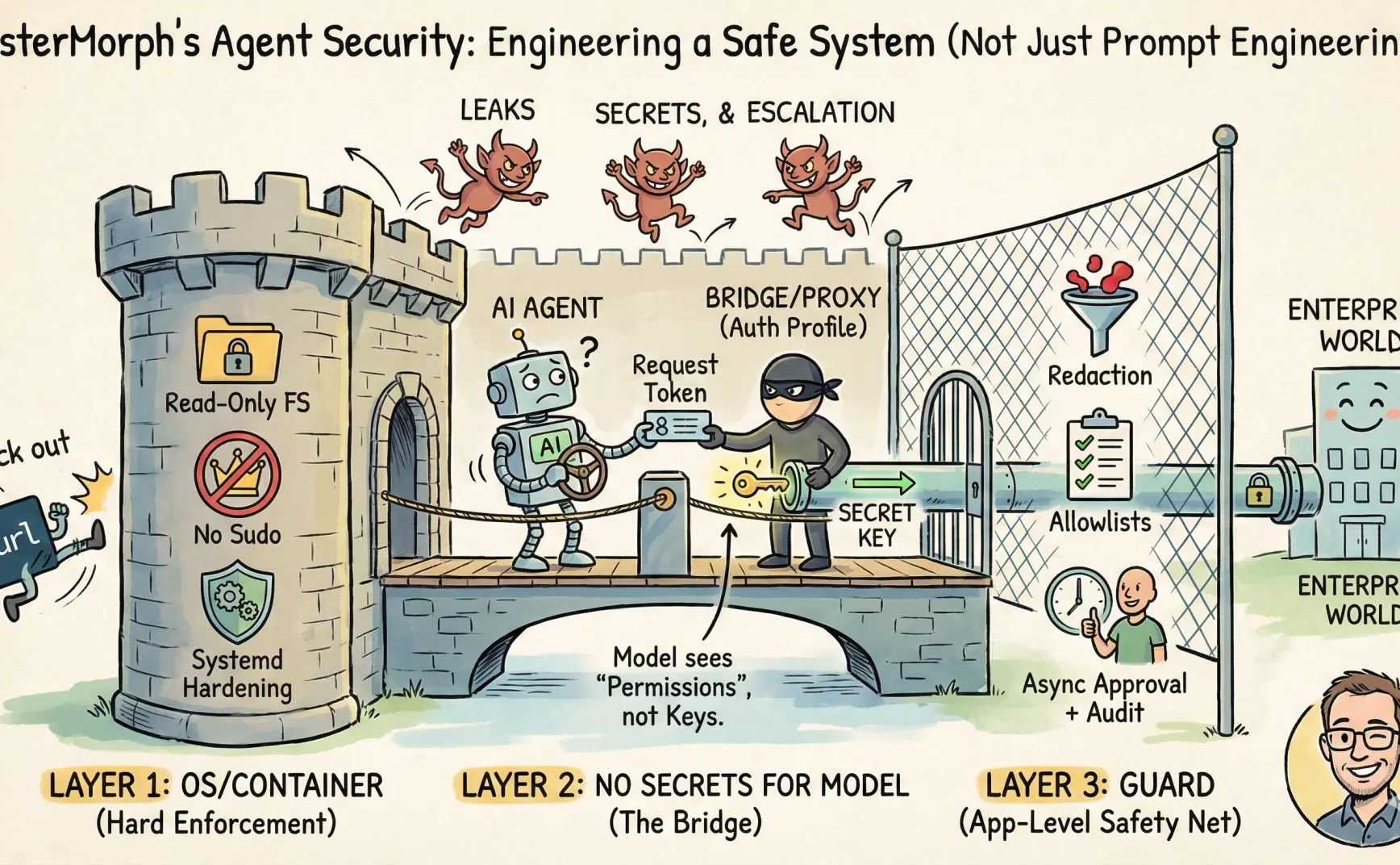
第一層:OS/コンテナが担う「できる/できない」
一部の戦略は OS/コンテナ(あるいは systemd)に任せる方が適しています。なぜなら強制力があるからです。
- サービスプロセスに sudo 権限を与えず、一般ユーザー権限にする
- rootfs を読み取り専用にし、書き込み可能ディレクトリを制限する(プロンプトに sensitive_path や denylist を書かない)
- systemd のハードニングオプションで権限範囲を絞る:
ProtectSystem、ProtectHome、NoNewPrivileges、PrivateTmpなど - システムから curl などを削除し、内蔵の
url_fetchツールのみ許可する
プロンプト層に期待するのは明確です:それはサンドボックスではありません。あくまで「内容/ワークフロー」上のリスクを最小化するものです。もし企業内ネットワークで Agent を動かすなら、ネットワーク出口制御(egress control)もコンテナ層やネットワーク層へ可能な限り移すべきです。
私が mistermorph を運用するときの実践:
systemd + 一般ユーザー + 基本的なアクセス制御
(詳しくはこちら)
第二層:モデルに秘密を触れさせない
基本的な考え方は、外部との連携で必要な鍵などをプロンプト内に絶対に出さないこと。代わりに別の仕組みで保持させます。
具体策はいくつもあり、例えば MCP が橋渡し役になる方法があります。ネットワーク層でパケット分解・置換する方法も可能です。
mistermorph の Skill に対して私が設計したのは auth_profile です。
実装の仕組みはこうです:Agent 自身が橋になり、鍵を保持します。Skill は Agent の提供するツール(例:url_fetch)のみ呼び出し可能。Agent はその中で鍵を注入します(例:url_fetch が Authorization ヘッダーへ注入)。
mistermorph には情報マスキング(redaction)用のガード機構もありますが、これは後処理であり、そもそも問題を発生させない方が良いです。
例えば moltbook の場合、もともとの SKILL.md に記述されている権限管理は、存在していると言い難いレベルでした。
そこで mistermorph では、moltbook の SKILL.md 内に次のような設定を書く必要があります。auth_profile の名前は moltbook:
auth_profiles: ["moltbook"]
requirements:
- http_client
- file_io
さらに、config.yaml には次を記述します:
secrets:
enabled: true
allow_profiles: ["moltbook"]
require_skill_profiles: true
auth_profiles:
moltbook:
credential:
kind: api_key
secret_ref: MOLTBOOK_API_KEY
allow:
url_prefixes:
- "https://www.moltbook.com/api/v1/"
methods: ["GET", "POST", "PATCH", "PUT", "DELETE"]
follow_redirects: false
allow_proxy: false
deny_private_ips: true
bindings:
url_fetch:
inject:
location: header
name: Authorization
format: bearer
このように設定することで、moltbook の Skill が外部へアクセスできる範囲は指定ドメイン・指定メソッドのみに制限され、API Key を扱う必要はありません。Agent が注入を担当するためです。
ちなみに moltbook の SKILL.md も大幅に簡略化しました。
この設計の副作用として、設定が「権限リスト」に近くなり、「モデル入力」ではなくなります。しかしこれは狙った副作用です。
さらに、秘密情報(secrets)の管理方法もアップグレード可能です。環境変数から AWS KMS への移行など。
第三層:Guard
Guard モジュールとは、いわば「後始末」のためのものです。そして後始末には多くの紙(ルール)が必要です。しかし最後の一枚を使う前に、それが最後だとは気づかないものです。
理由は単純で、セキュリティポリシーの組み合わせ(笛卡尔積)はシステムの複雑性を爆発させます。例えば:
- 各 tool に個別のポリシー
- 各ポリシーを method/body/headers/path ごとに細分化
- さらにプロンプト内容検査、文脈監査、IDS ルールなどを追加……
結果として、強そうに見えるが維持困難なシステムができます。
そのため MisterMorph の Guard は次の三つだけを保持しています:
1. Outbound allowlist
典型的な例は allow_dirs や allow_url_prefixes など。mistermorph にも多くあります。プロンプト内の安全境界やコードレベルの制限として存在します。
2. Redaction
入出力すべてに対して、可能な限りルールを用いて既知の高リスク情報をマスクします。
3. 非同期承認 + 監査(Async approvals + audit)
人手確認が必要な操作は保留状態(pending)にし、外部システムで承認を処理します。また、全てのリスク行動を監査可能にします。
例えば mistermorph でリモート Skill をインストールする際には、まずユーザーにソースコードのプレビューを求め、LLM による審査を行い、その後確認のうえでインストールします。
要するに、Guard はアプリケーション内の安全フェンスであり、真の境界線は OS/コンテナ側で描くべきものです。
最後に
過度な自信も悲観も危険です。いくつかのプロンプトルールを足しただけで十分と考えてもいけませんし、問題を恐れて電源を切るだけなのも間違いです。私はエンタープライズ環境で Agent を動かして利益を出す必要があります。
Agent に鍵を渡す前に、少なくとも確認しましょう。
ドアはいくつあるのか/どのドアが鉄製なのか/どのドアに承認が必要なのか/誰がドアの前で記録を取っているのか。