![[译] - 理解多模态](https://images.quaily.com/kyCgoaeV8vih946BeqFGda2BUPxFtVyS2YYbf3nsh2g/rs:fill:868:536:1:0/f:webp/dpr:2/plain/https://static.quail.ink/media/vzpzbzy7y.webp)
#LLM/翻译
原文:https://magazine.sebastianraschka.com/p/understanding-multimodal-llms
在过去的两个月里,人工智能研究领域再次迎来显著进展,不仅有两项诺贝尔奖颁发给了人工智能相关研究,还涌现出诸多引人瞩目的研究成果。
其中,Meta AI 发布了最新的 Llama 3.2 模型,包括参数规模为 10 亿和 30 亿的开源大语言模型版本,以及两款多模态模型。
在本文中,我将深入浅出地解释多模态大型语言模型 (LLM) 的工作原理。此外,我还会回顾和总结近几周发布的十几篇其他多模态论文和模型(包括 Llama 3.2),并对它们各自的方法进行比较。
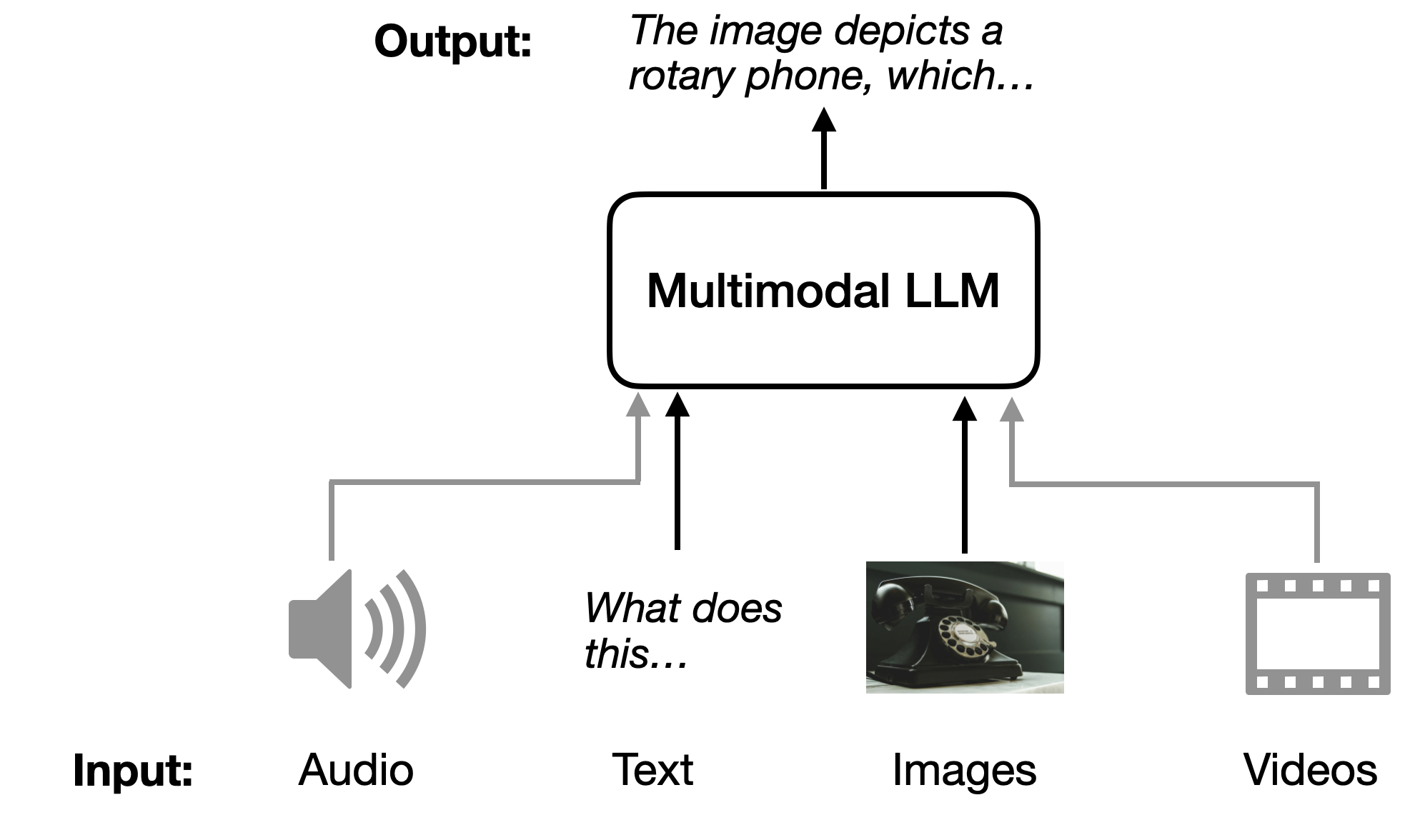
一个多模态 LLM 的示意图,它可以接收不同的输入模态(音频、文本、图像和视频),并以文本作为输出模态。
1. 多模态 LLM 的应用场景
何谓多模态 LLM? 顾名思义,多模态 LLM 是能够处理多种输入类型的大型语言模型。“模态” 指的是特定的数据类型,例如文本(传统 LLM 的输入)、音频、图像、视频等等。为了便于理解,本文将主要聚焦于图像和文本模态的输入。
图像描述生成是多模态 LLM 经典且直观的应用:用户输入图像,模型生成相应的文本描述,示例如下图所示。

多模态 LLM 解释 meme 的应用示例。
多模态 LLM 的应用远不止于此。例如,我个人非常喜欢的一个应用是从 PDF 表格中提取信息,并将其转换为 LaTeX 或 Markdown 格式。
2. 实现多模态 LLM 的常用方法
构建多模态 LLM 主要有两种技术路径:
A. 统一嵌入解码器架构 (Unified Embedding Decoder Architecture)
B. 跨模态注意力机制架构 (Cross-modality Attention Architecture)
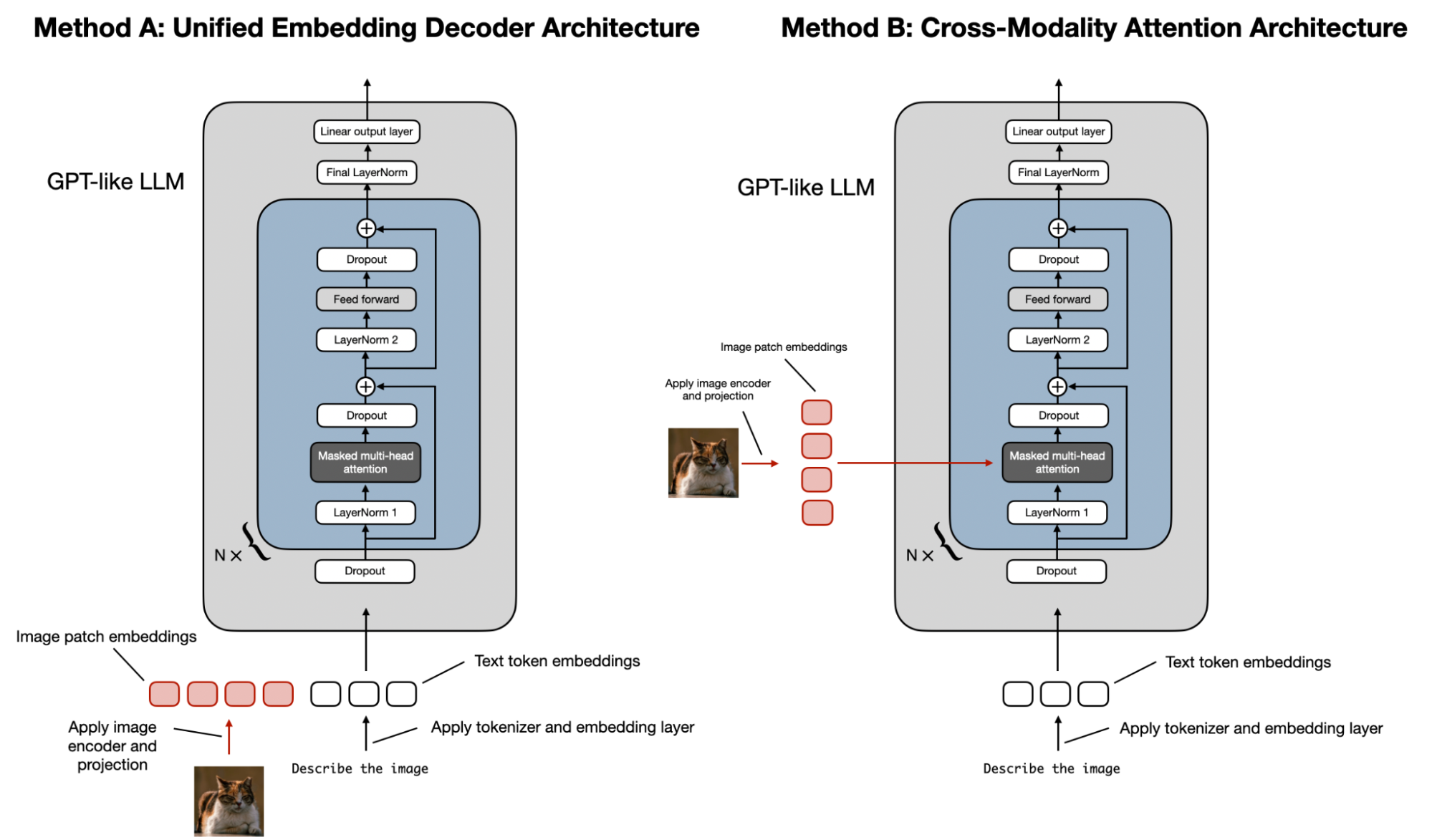
多模态 LLM 架构的两种主流实现方法。
统一嵌入解码器架构 采用单一解码器模型,与 GPT-2 或 Llama 3.2 等 unmodified LLM 架构异曲同工。 此方法将图像转化为与文本 token 具备相同 embedding 大小的 tokens,从而使 LLM 能够一并处理文本和图像输入 tokens。
跨模态注意力机制架构 则利用跨注意力 (cross-attention) 机制,将图像和文本 embeddings 直接整合至 attention 层。
后续章节我们将从概念上探讨这些方法的工作原理。 之后,我们将回顾最新的多模态 LLM 研究工作,了解它们在实践中的应用。
2.1 方法A:统一嵌入解码器架构
首先介绍统一嵌入解码器架构,具体结构如下图所示。
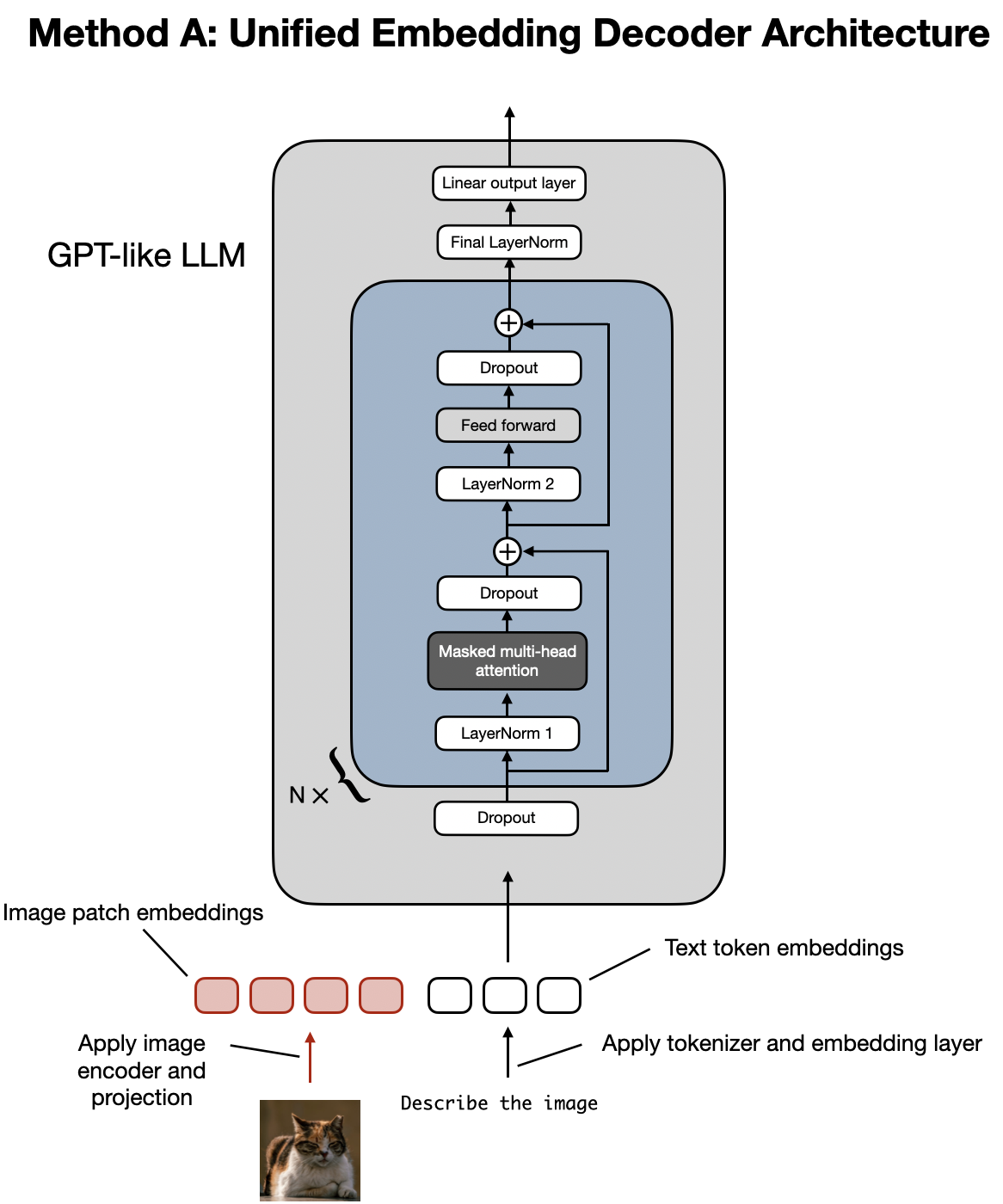
统一嵌入解码器架构的示意图。该架构基于标准的解码器型语言模型(如GPT-2、Phi-3、Gemma或Llama 3.2),其输入由图像嵌入和文本嵌入组成。
在统一嵌入解码器架构中,图像会被转换为嵌入向量,这一过程与标准文本LLM将输入文本转换为嵌入的过程类似。
对于典型的标准文本LLM,输入文本通常会先进行标记化(例如使用Byte-Pair Encoding),然后通过嵌入层,具体流程见下图。
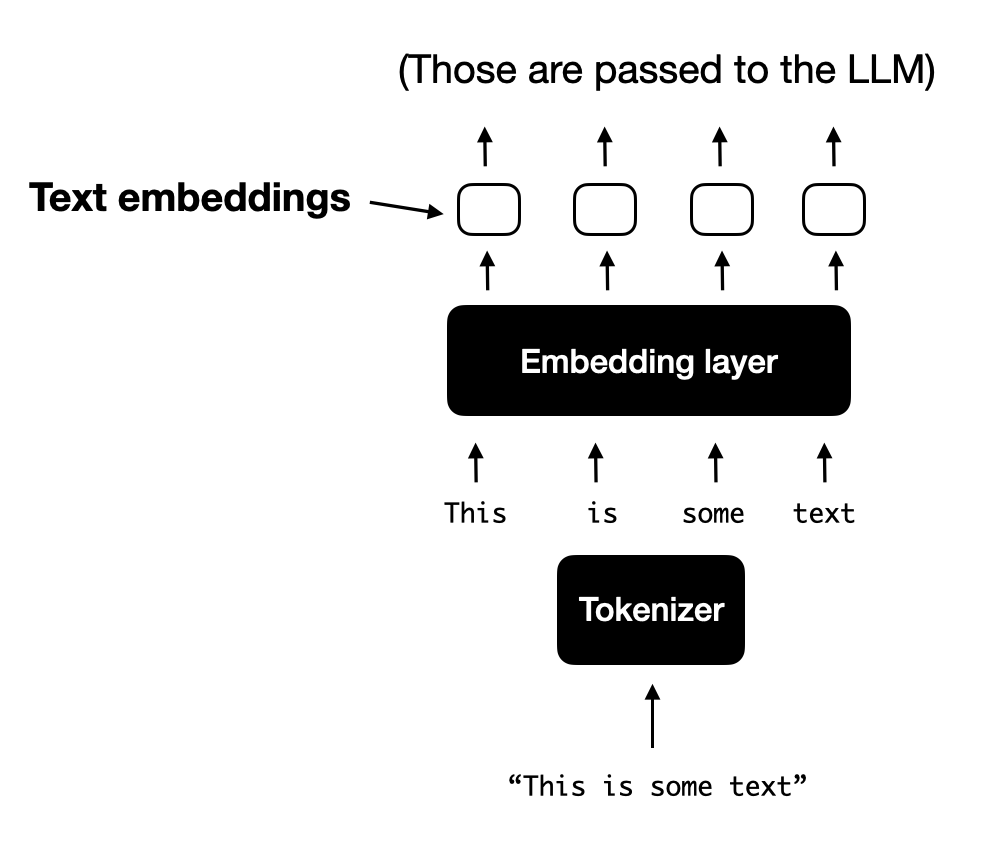
文本标记化及生成嵌入向量的标准流程示意图。生成的嵌入向量将在训练和推理过程中传递给LLM。
2.1.1 理解图像编码器
与文本的标记化和嵌入类似,图像嵌入通过图像编码器模块生成,如下图所示。
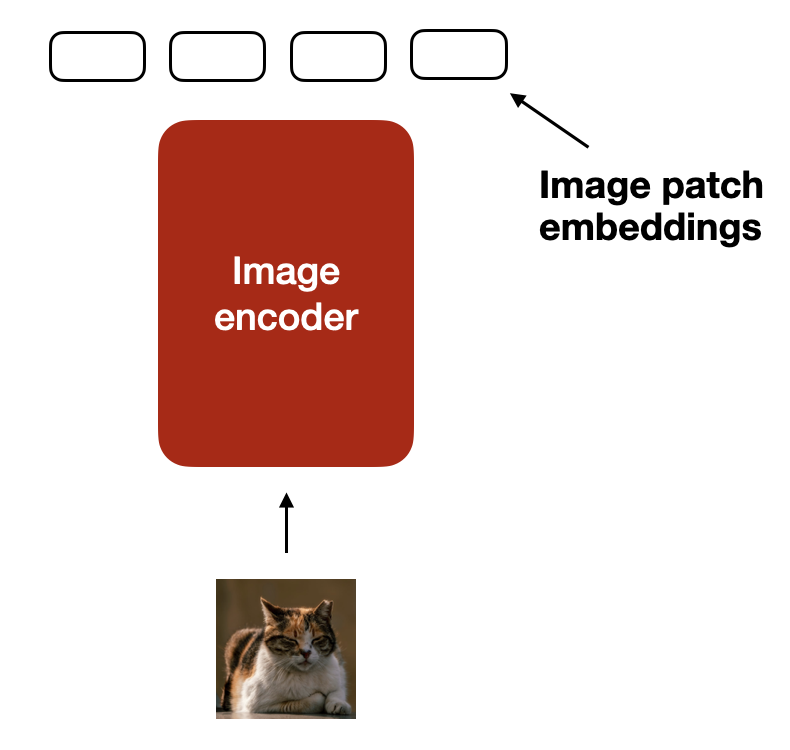
将图像分割为小块并生成嵌入向量的过程示意图。
那么,图像编码器内部是如何工作的呢?为了处理图像,首先将其划分为若干小块,这一过程类似于在文本标记化中将单词拆分为子单元(subwords)。这些小块随后由预训练的视觉Transformer(ViT)进行编码,具体流程见下图。
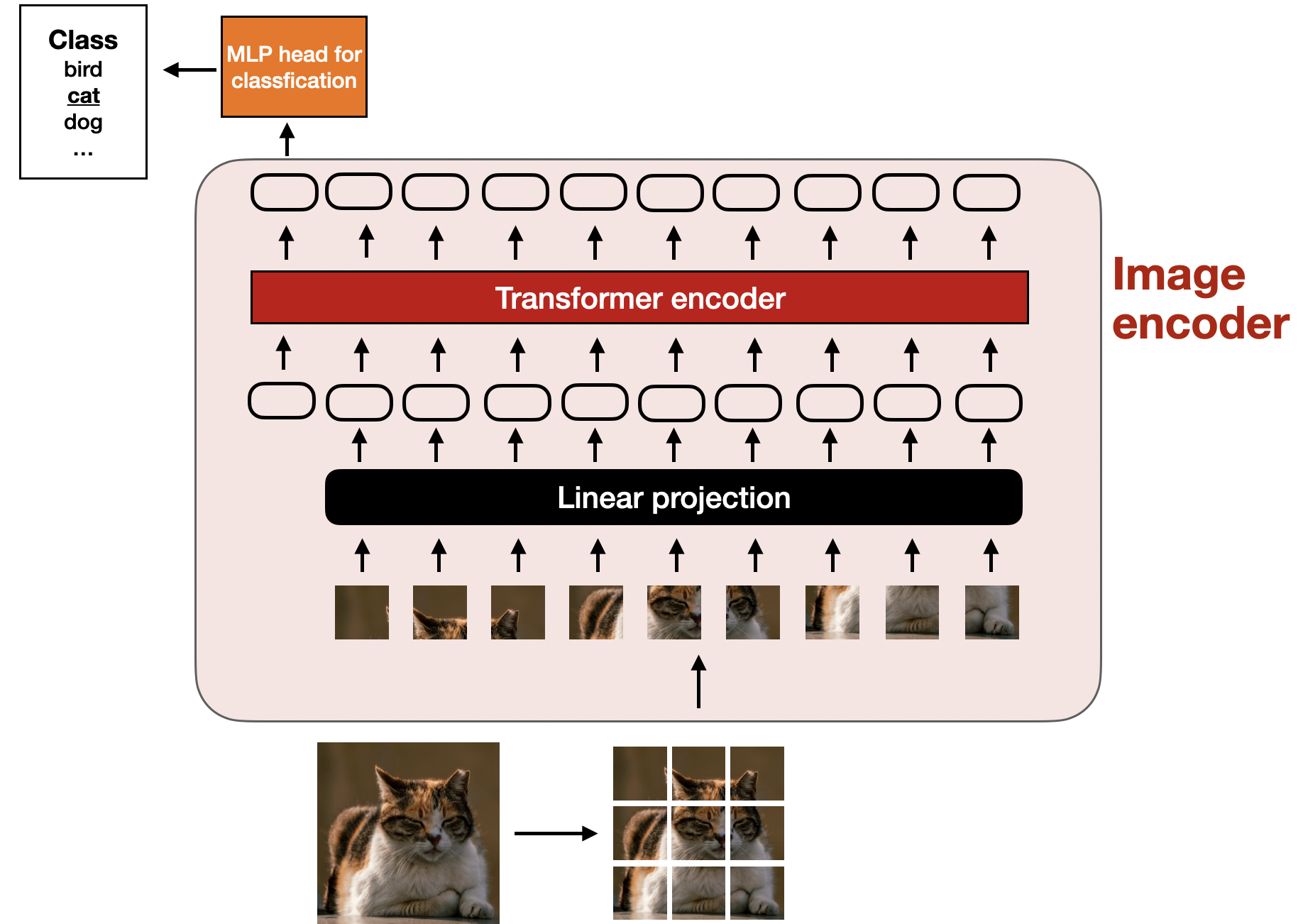
经典视觉Transformer(ViT)架构的示意图。该架构源自论文《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》(https://arxiv.org/abs/2010.11929)。
值得注意的是,ViTs通常用于分类任务,因此上图中包含了分类头部分。不过,本文仅关注图像编码器的功能。
2.1.2 线性投影模块的作用
前文图中所示的“线性投影”由一个单层线性层(即全连接层)构成。该层的作用是将展平为向量的图像块投影到与Transformer编码器兼容的嵌入维度。下图展示了线性投影的过程。图像块被展平成256维向量后,会被上投影到768维向量。
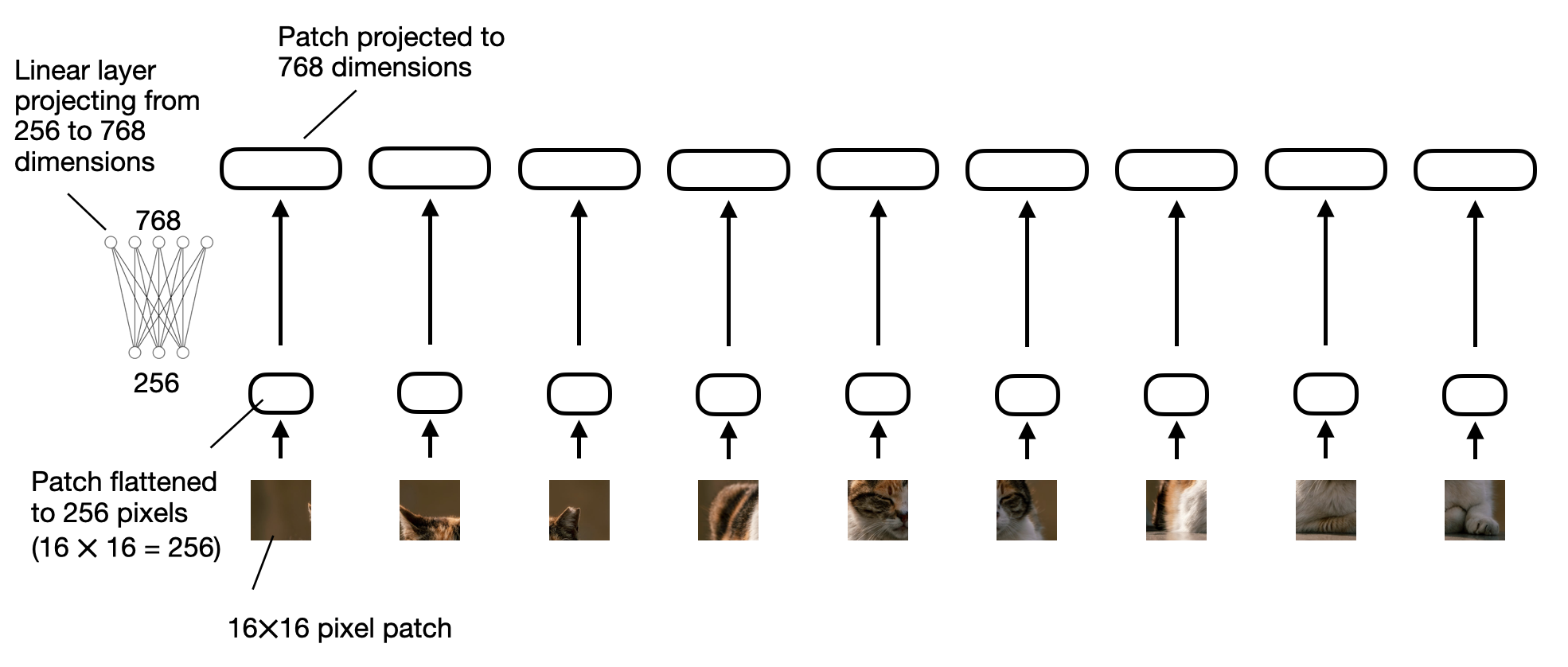
线性投影层示意图:将展平的图像块从256维投影到768维嵌入空间。
对于喜欢代码示例的读者,以下是在 PyTorch 中实现图像块线性投影的代码:
import torch
class PatchProjectionLayer(torch.nn.Module):
def __init__(self, patch_size, num_channels, embedding_dim):
super().__init__()
self.patch_size = patch_size
self.num_channels = num_channels
self.embedding_dim = embedding_dim
self.projection = torch.nn.Linear(
patch_size * patch_size * num_channels, embedding_dim
)
def forward(self, x):
batch_size, num_patches, channels, height, width = x.size()
x = x.view(batch_size, num_patches, -1) # Flatten each patch
x = self.projection(x) # Project each flattened patch
return x
# Example Usage:
batch_size = 1
num_patches = 9 # Total patches per image
patch_size = 16 # 16x16 pixels per patch
num_channels = 3 # RGB image
embedding_dim = 768 # Size of the embedding vector
projection_layer = PatchProjectionLayer(
patch_size, num_channels, embedding_dim
)
patches = torch.rand
(batch_size, num_patches, num_channels, patch_size, patch_size
)
projected_embeddings = projection_layer(patches)
print(projected_embeddings.shape)
# This prints
# torch.Size([1, 9, 768])
如果您曾阅读过我的著作 Machine Learning Q and AI (机器学习问答与人工智能),或许了解 linear layers 可以用数学上等价的 convolution operations 替代。 在此情境下,这种替代方案尤为便捷,因为我们可以将 patches 创建与 projection 合并为两行代码:
layer = torch.nn.Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16))
image = torch.rand(batch_size, 3, 48, 48)
projected_patches = layer(image)
print(projected_patches.flatten(-2).transpose(-1, -2).shape)
# 输出结果
# torch.Size([1, 9, 768])
2.1.3 图像与文本 Tokenization 对比
现在我们已经简要讨论了图像编码器的作用(以及作为编码器一部分的线性投影),让我们回到之前文本 tokenization 的类比,并排观察文本和图像的 tokenization 与嵌入过程,如下图所示。
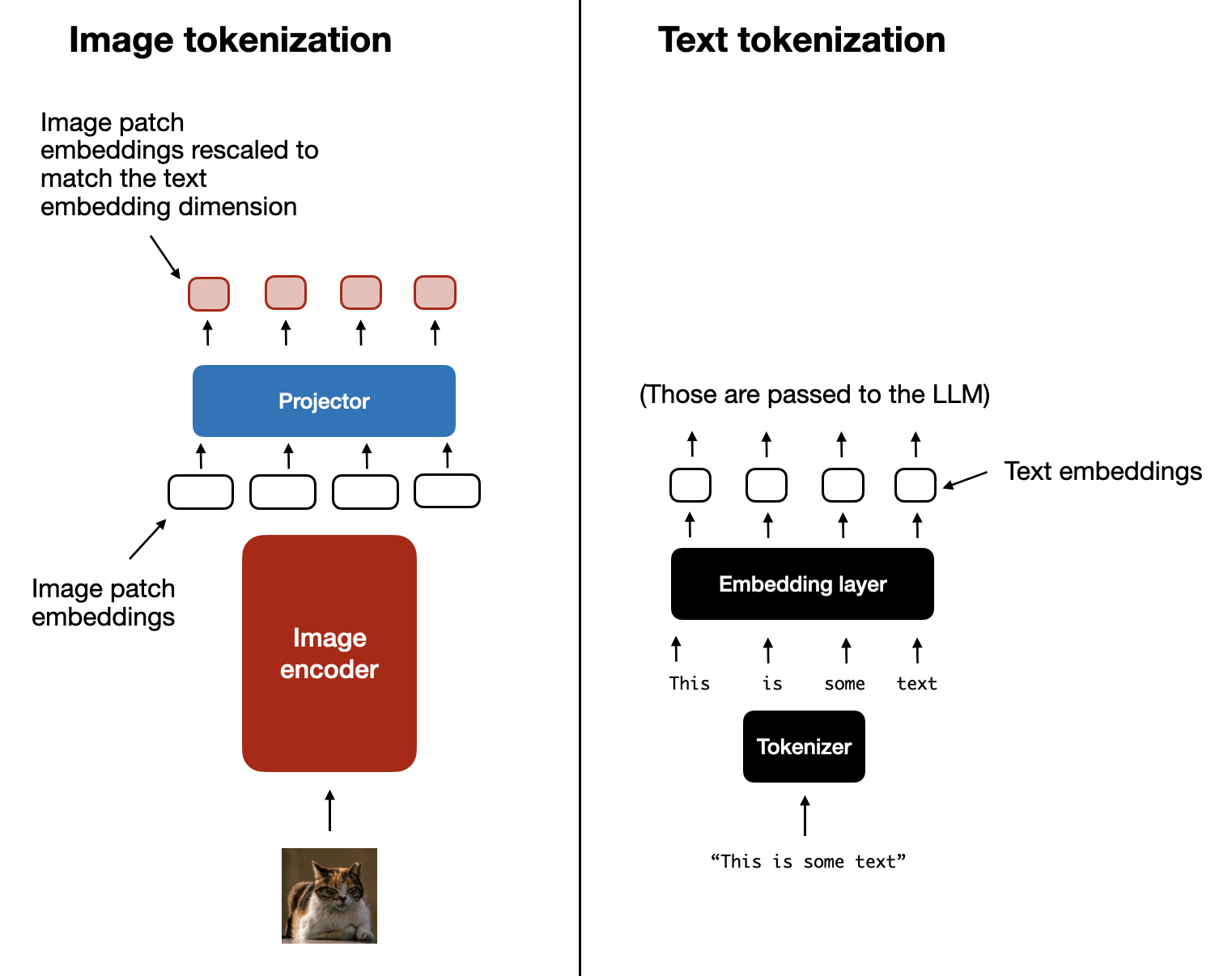
图像 tokenization 和嵌入(左)与文本 tokenization 和嵌入(右)的并排对比。
正如你在上图中看到的,图像编码器之后添加了一个额外的 projector(投影器)模块。这个 projector 通常只是另一个 线性投影 层,与前面解释的类似。其目的是将图像编码器的输出投影到一个维度,使其与嵌入后的文本 tokens 的维度相匹配,如下图所示。(正如我们稍后将看到的,projector 也常被称为 adapter、adaptor 或 connector。)
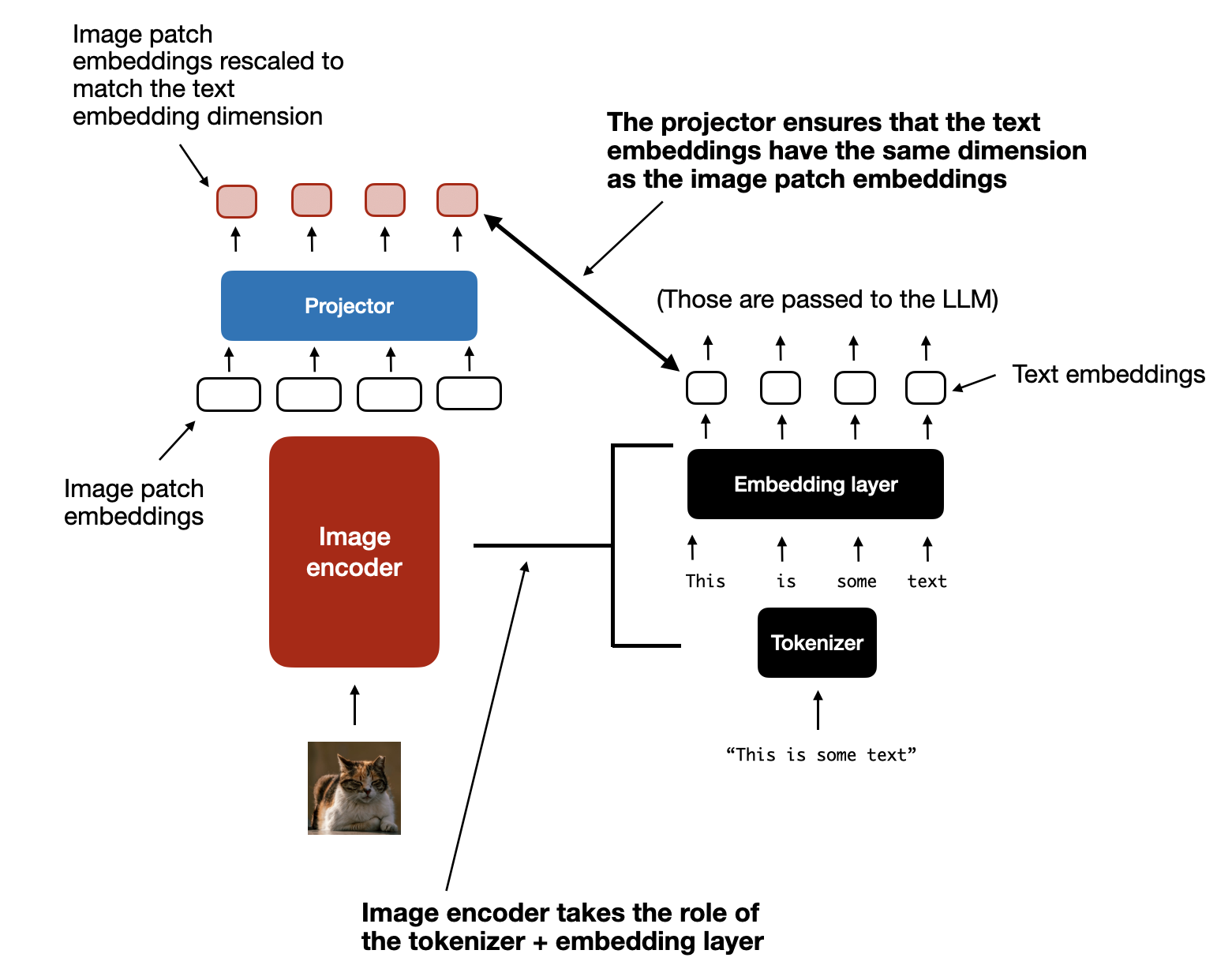
图像 tokenization 和文本 tokenization 的另一个并排对比,其中 projector 的作用是匹配文本 token 嵌入的维度。
现在图像 patches 的嵌入维度与文本 token 嵌入的维度相同了,我们可以简单地将它们连接起来,作为 LLM 的输入,如下图所示,该图位于本节的开头。为了方便参考,下面再次展示了同一张图。
在将图像 patch tokens 投影到与文本 token 嵌入相同的维度后,我们可以简单地将它们连接起来,作为标准 LLM 的输入。
顺便说一句,我们在本节中讨论的图像编码器通常是预训练的 vision transformer(视觉 Transformer)。CLIP 或 OpenCLIP 是常见的选择。
然而,也存在一些 Method A 的变体直接作用于图像 patches,例如 Fuyu,如下图所示。
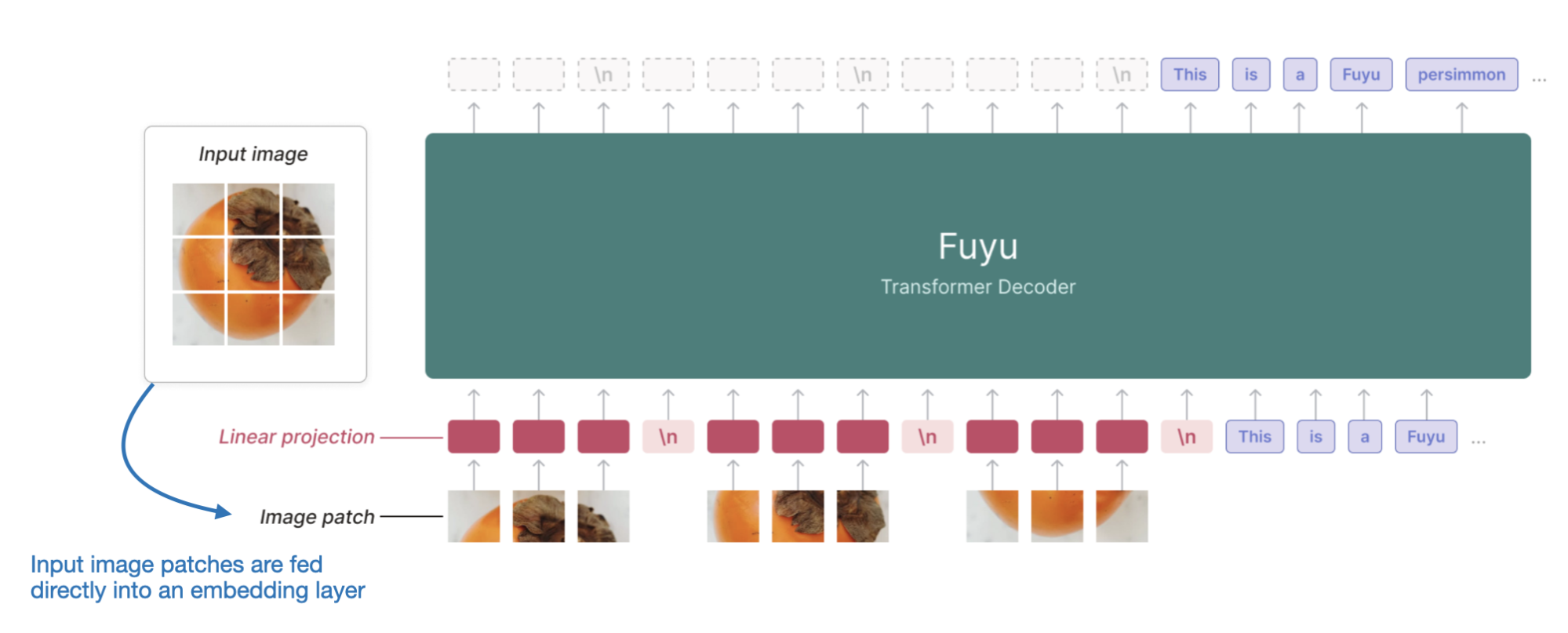
Fuyu 多模态 LLM 的注释图,它直接对图像 patches 进行操作,无需图像编码器。(注释图来自 https://www.adept.ai/blog/fuyu-8b。)
如上图所示,Fuyu 模型将输入的图像 patches 直接传递到一个线性投影层(或嵌入层),以学习其自身的图像 patch 嵌入,而不是像其他模型和方法那样依赖额外的预训练图像编码器。这大大简化了架构和训练设置。
2.2 方法 B:跨模态注意力架构
继之前讨论了构建多模态 LLM 的统一嵌入解码器架构方法,并理解了图像编码的基本概念之后,现在让我们探讨另一种实现多模态 LLM 的替代方法:跨模态注意力架构,如下图所示。
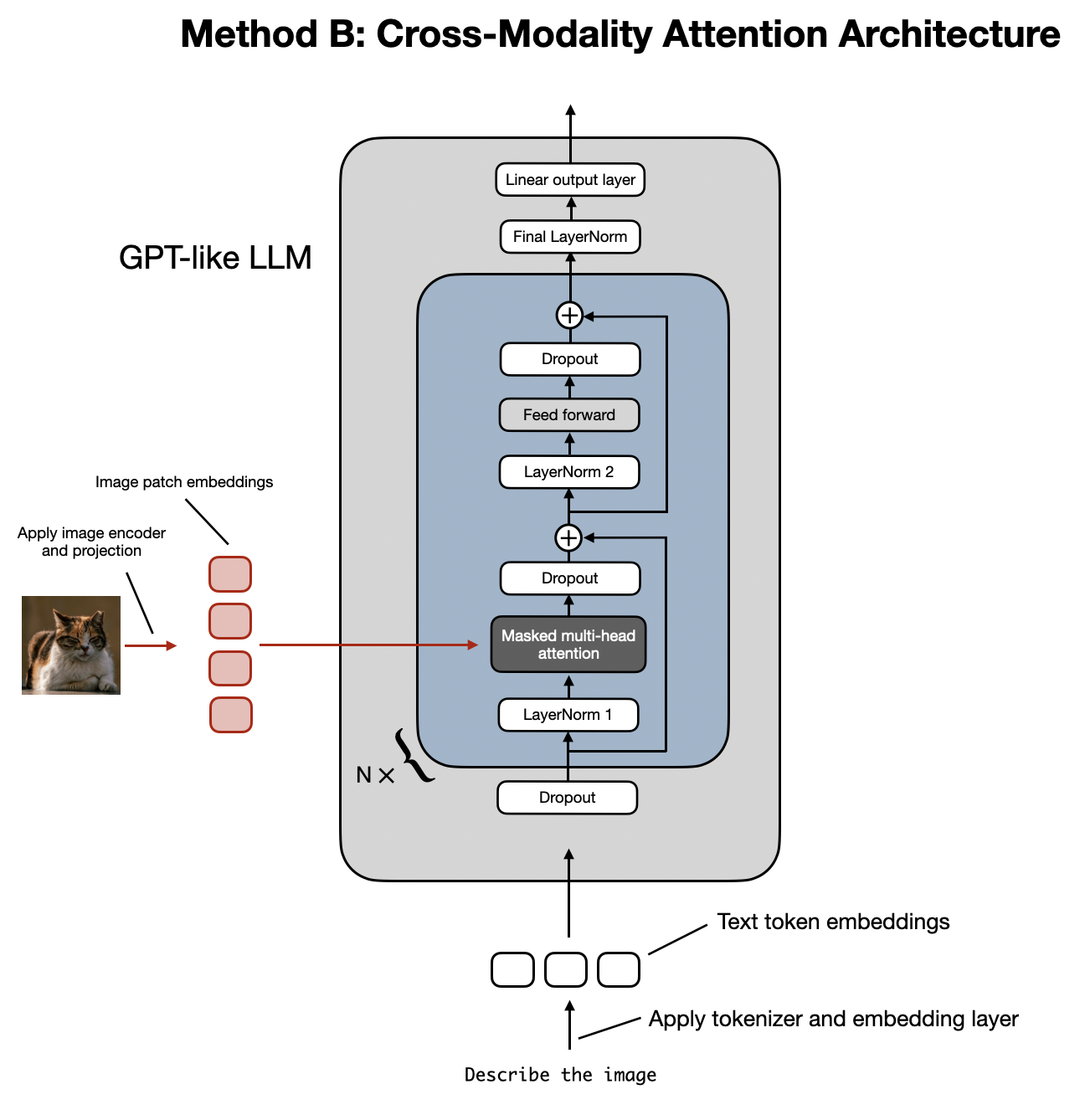
构建多模态 LLM 的跨模态注意力架构方法示意图。
在图中所示的跨模态注意力架构方法中,我们仍然采用之前讨论过的图像编码器设置。然而,与直接将图像块 (patches) 编码为 LLM 的输入不同,我们通过交叉注意力机制将输入的图像块连接到多头注意力层。
这个想法与 2017 年 “Attention Is All You Need” 论文中提出的原始 Transformer 架构相关,并可追溯至该架构,如下图所示。
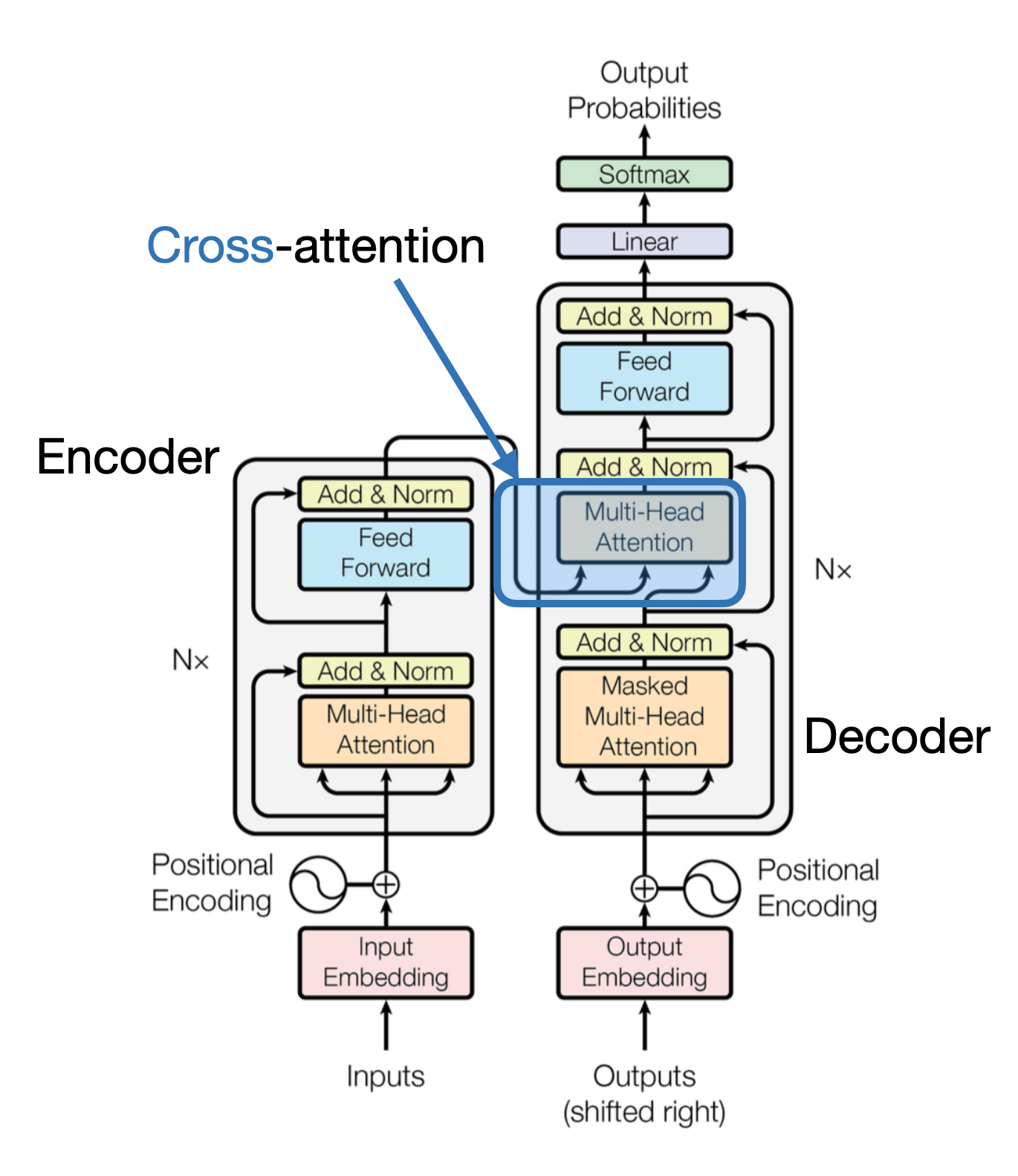
原始 Transformer 架构中使用的交叉注意力机制的概要示意图。(注释图来自 “Attention Is All You Need” 论文:https://arxiv.org/abs/1706.03762。)
请注意,上图所示的原始 “Attention Is All You Need” Transformer 最初是为语言翻译而开发的。因此,它包含一个文本编码器(图的左侧部分),负责接收待翻译的句子;以及一个文本解码器(图的右侧部分),负责生成译文。在多模态 LLM 的背景下,编码器是图像编码器而非文本编码器,但基本思想是相同的。
交叉注意力是如何工作的呢?让我们看一下常规自注意力机制内部工作原理的概念图。
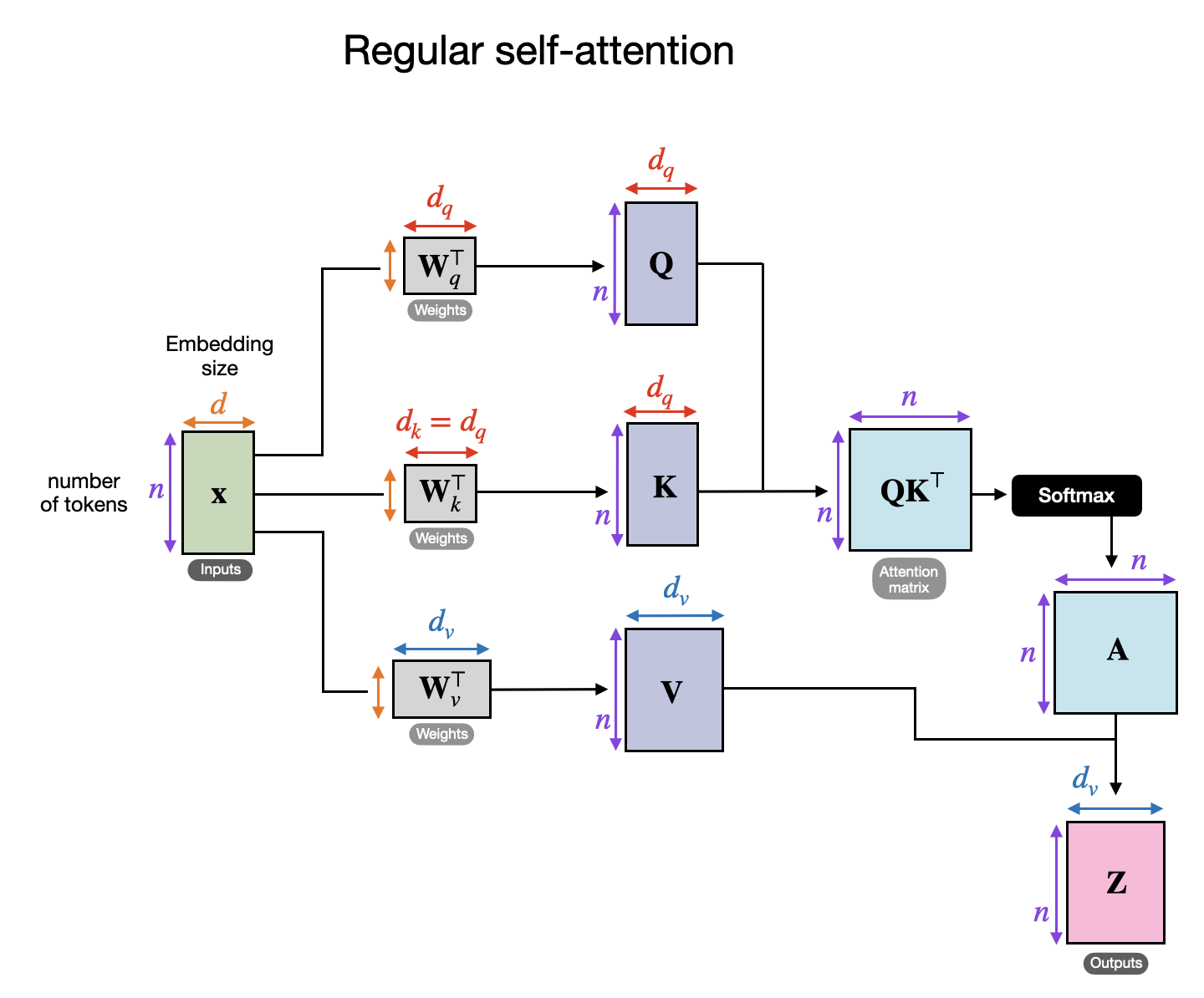
常规自注意力机制的概要。(此流程图描绘了常规多头注意力模块中的一个头。)
在上图中,x 代表输入,Wq 是用于生成查询 ( Q ) 的权重矩阵。类似地,K 代表键 (keys),V 代表值 (values)。A 代表注意力得分矩阵,Z 是输入 (x) 经转换后得到的输出上下文向量。(如果您对此感到困惑,可以在我的著作《从零开始构建大型语言模型》的第 3 章中找到全面介绍;或者,您也可以参考我的文章 理解和编码 LLM 中的自注意力、多头注意力、交叉注意力和因果注意力,这可能会有所帮助。)
相比之下,在交叉注意力中,我们有两个不同的输入源,如下图所示。
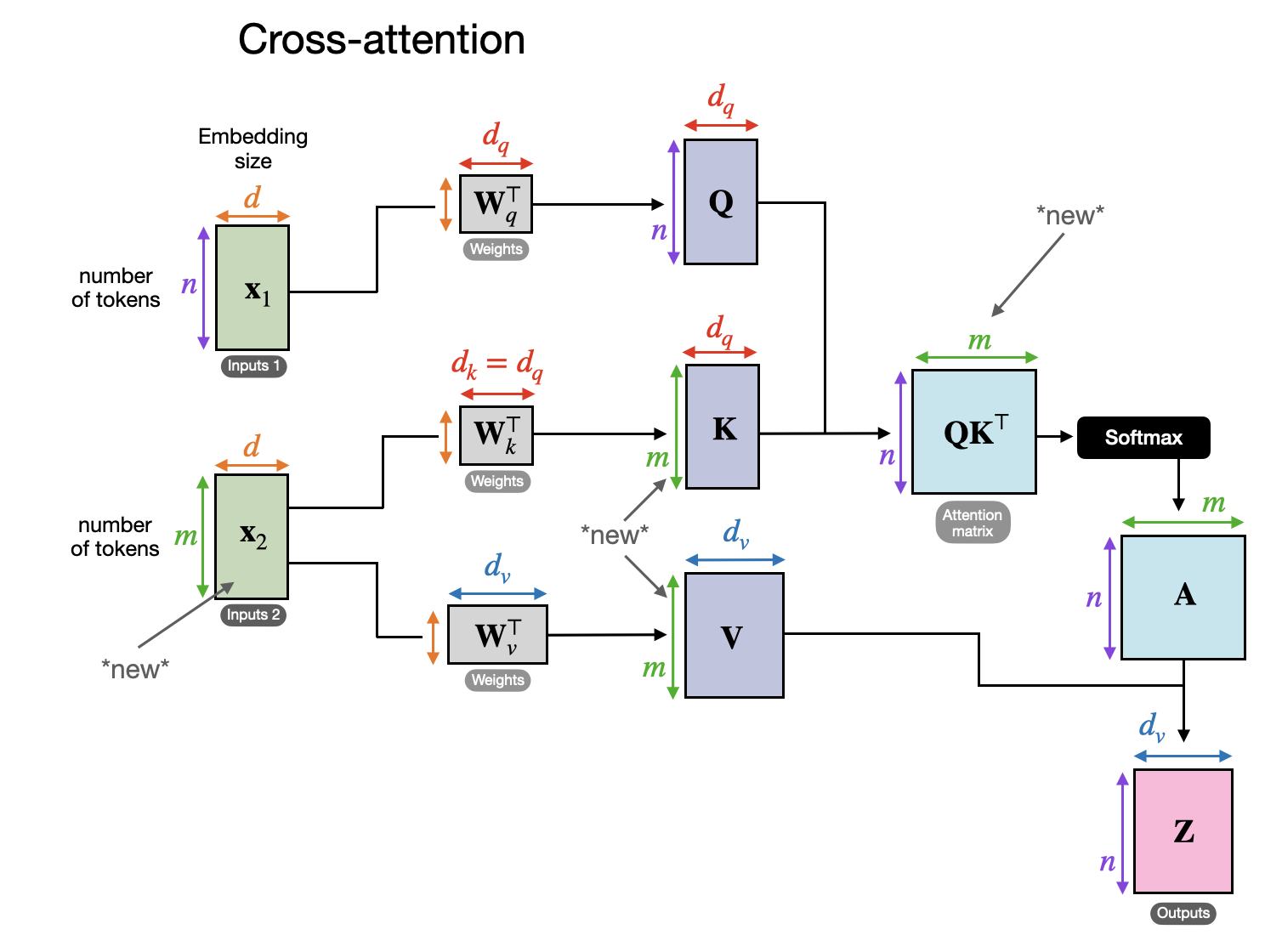
交叉注意力的图示,其中可以有两个不同的输入 x1 和 x2。
正如前两张图所示,自注意力处理的是相同的输入序列,而交叉注意力则将两个不同的输入序列混合或组合。
在 “Attention Is All You Need” 论文中原始 Transformer 架构的例子中,两个输入 x1 和 x2 分别对应于:x2 是左侧编码器模块返回的序列,而 x1 是右侧解码器部分正在处理的输入序列。在多模态 LLM 的背景下,x2 是图像编码器的输出。(请注意,查询通常来自解码器,而键和值通常来自编码器。)
请注意,在交叉注意力中,两个输入序列 x1 和 x2 可以具有不同数量的元素,但它们的嵌入维度必须匹配。当 x1 = x2 时,交叉注意力就等同于自注意力。
3. 统一解码器与跨注意力模型训练
在初步探讨了两种主要的多模态设计选择之后,现在让我们简要讨论模型训练过程中如何处理三个主要组成部分,如下图所示。
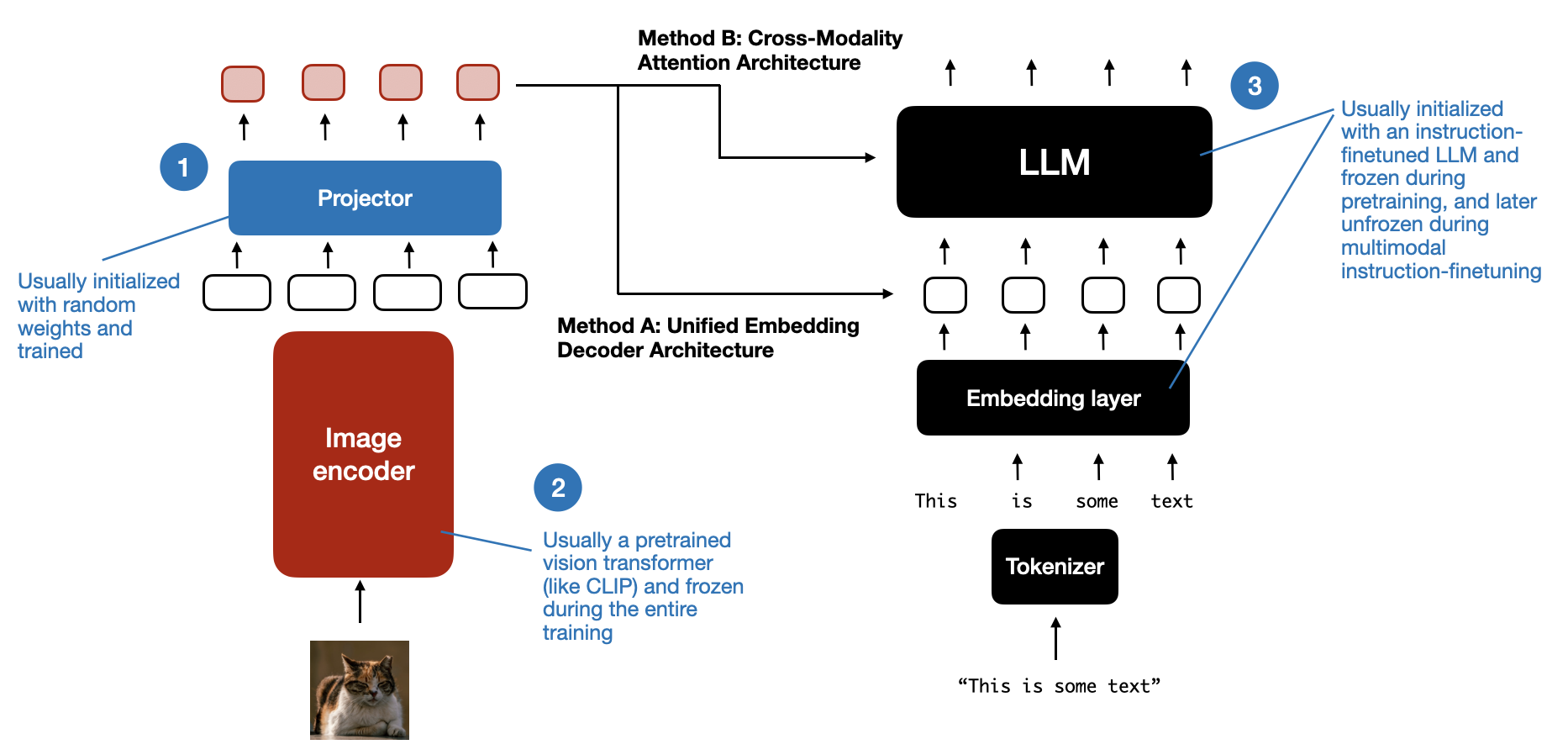
多模态 LLM 中不同组件的概览。编号为 1-3 的组件在多模态训练过程中可以被冻结或解冻。
与传统纯文本 LLM 的发展类似,多模态 LLM 的训练也包含预训练和指令微调两个阶段。然而,与从零开始训练不同,多模态 LLM 的训练通常以预训练好的、并经过指令微调的纯文本 LLM 作为基础模型。
对于图像编码器,CLIP (Contrastive Language–Image Pre-training,对比语言-图像预训练) 模型是常用的选择,并且在整个训练过程中通常保持冻结状态。虽然也存在例外情况,我们将在后面探讨。在预训练阶段,LLM 部分通常也保持冻结状态,仅专注于训练投影器 (projector)——一个线性层或小型多层感知机。考虑到投影器有限的学习能力(通常只包含一到两层),LLM 通常会在多模态指令微调阶段(第二阶段)解冻,以便进行更全面的全面更新。但是请注意,在基于跨注意力机制的模型(方法 B)中,跨注意力层在整个训练过程中始终处于解冻状态。
在介绍了两种主要方法(方法 A:统一嵌入解码器架构和方法 B:跨模态注意力架构)之后,您可能想知道哪种方法更有效。答案取决于具体的权衡考量。
统一嵌入解码器架构(方法 A)通常更容易实现,因为它无需对 LLM 架构本身进行任何修改。
跨模态注意力架构(方法 B)通常被认为计算效率更高,原因在于它不会用额外的图像 tokens 使得超出上下文,而是在交叉注意力层稍后引入图像信息。 此外,如果 LLM 参数在训练期间保持冻结,这种方法还能维持原始文本 LLM 的文本性能。
我们将在后续章节中重新讨论建模性能和响应质量,届时我们将探讨 NVIDIA 的 NVLM 论文。
至此,我们对多模态 LLM 的略显冗长的介绍就告一段落了。在撰写本文时,我意识到讨论的篇幅已经超出最初的计划,这或许表明现在是结束本文的合适时机。
然而,为了提供更具实践意义的视角,考察一些实现这些方法的最新研究论文将是很有益处的。因此,我们将在本文的剩余部分探讨这些论文。
4. 近期多模态模型与方法
在接下来的部分,我将回顾近期关于多模态LLM的文献,特别关注最近几周发表的论文,以聚焦近期进展。
因此,这并非是对多模态LLM的历史性概述或全面综述,而只是对最新进展的简要审视。我也会尽量保持这些摘要的简短,避免过多冗余,因为总共有10个模型需要介绍。
本文末尾的结论部分提供了一个概述,比较了这些论文中采用的方法。
4.1 Llama 3 模型群
Meta AI 于今年早些时候发表了论文 The Llama 3 Herd of Models (2024年7月31日),在LLM领域,这感觉就像是很久以前的事了。然而,考虑到他们在论文中仅描述了多模态模型的架构,而实际模型的发布则延迟至数月之后,因此将 Llama 3 纳入此列表也情有可原。(Llama 3.2 模型于 9 月 25 日正式发布并提供。)
多模态 Llama 3.2 模型,包括 110 亿(11B)和 900 亿(90B)参数两种版本(注:1B 即 10 亿),是图像-文本模型,它们采用了之前描述的基于交叉注意力的方法,如下图所示。
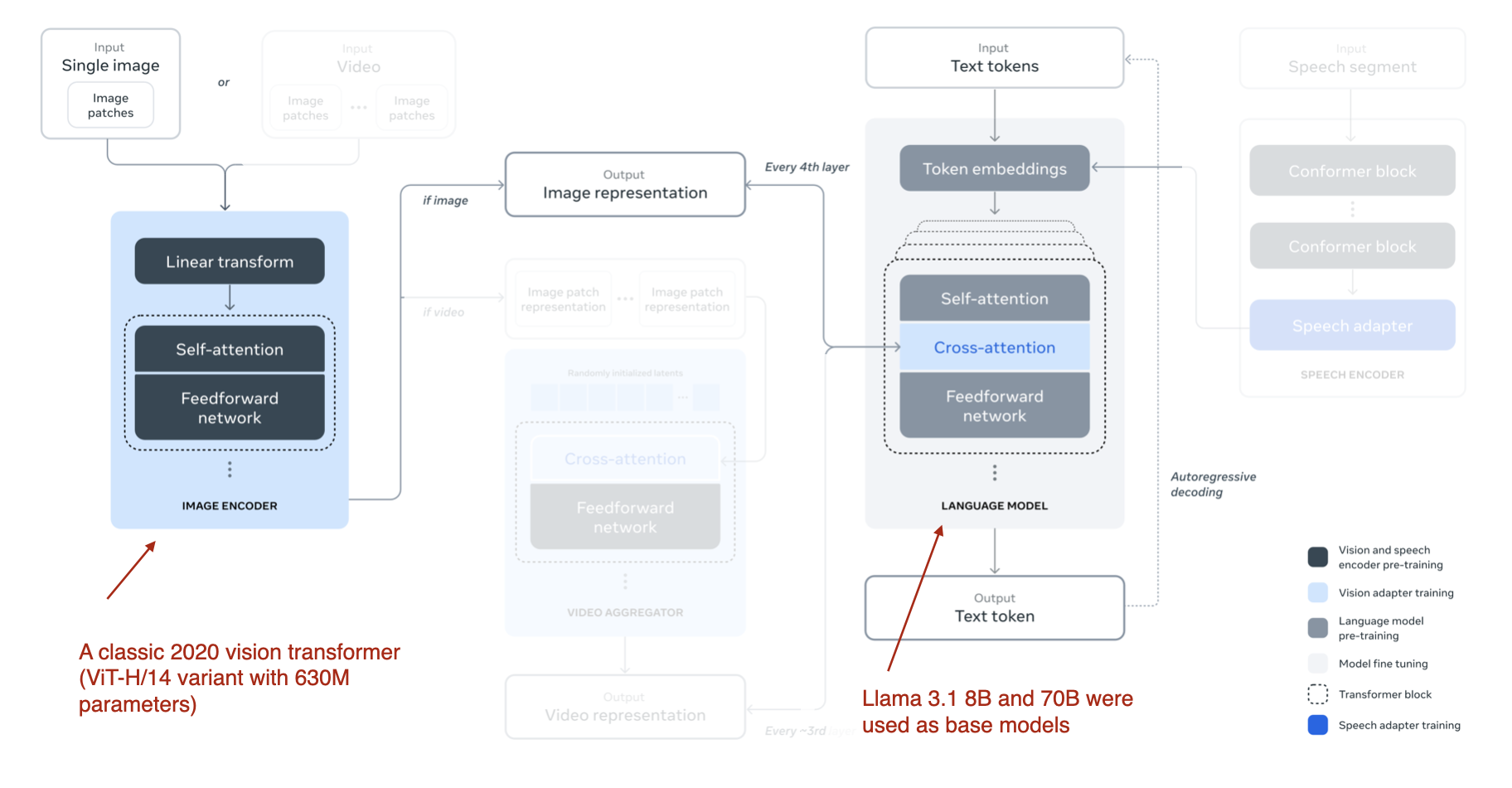
Llama 3.2 使用的多模态 LLM 方法示意图。(来源:Llama 3 论文 https://arxiv.org/abs/2407.21783。视频和语音部分在视觉上被遮挡,以突出图像部分。)
请注意,虽然图中也描绘了视频和语音作为可能的模态,但截至本文撰写之时,发布的模型仅关注图像和文本。
Llama 3.2 使用了基于交叉注意力的方法。然而,它与我之前写到的一些内容略有不同,即在多模态 LLM 开发中,我们通常会冻结图像编码器,仅在预训练期间更新 LLM 参数。
而在这里,研究人员几乎采取了相反的方法:他们更新了图像编码器,但不更新语言模型的参数。研究团队指出,这种设计是有意为之,旨在保留模型的纯文本处理能力,以便 11B 和 90B 多模态模型可以作为 Llama 3.1 8B 和 70B 纯文本模型在文本任务上的直接替代品。
训练本身分多个迭代进行,从 Llama 3.1 文本模型开始。在添加图像编码器和适配器(adapter,即投影器)层后,他们在图像-文本数据上对模型进行预训练。然后,类似于 Llama 3 模型纯文本训练(我在 之前的文章 中写过),他们继续进行指令和偏好微调。
研究人员没有采用像 CLIP 这样的预训练模型作为图像编码器,而是使用了一个从头开始预训练的视觉 Transformer。具体来说,他们采用了经典视觉 Transformer 架构的 ViT-H/14 变体(6.3 亿参数)(Dosovitskiy et al., 2020)。然后,他们在包含 25 亿图像-文本对的数据集上对 ViT 进行了五个 epoch 的预训练;这在将图像编码器连接到 LLM 之前完成。(图像编码器接受 224×224 分辨率的图像,并将其划分为 14×14 的网格块,每个网格块的大小为 16×16 像素。)
由于交叉注意力层增加了大量的参数,因此它们仅添加到每四个 Transformer 块中。(对于 8B 模型,这增加了 30 亿参数(3B),对于 70B 模型,这增加了 200 亿参数(20B)。)
4.2 Molmo 和 PixMo:用于先进多模态模型的开源权重和开放数据
论文 The Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models (2024年9月25日)引人注目,因为它承诺开源模型权重,以及数据集和源代码,类似于仅语言的 OLMo LLM。(这对 LLM 研究非常有利,因为它使我们能够查看确切的训练过程和代码,并允许我们在相同的数据集上运行消融研究和复现结果。)
论文标题中包含两个名称的原因如下:Molmo 指的是模型(Multimodal Open Language Model,多模态开放语言模型),而 PixMo (Pixels for Molmo) 是数据集的名称。
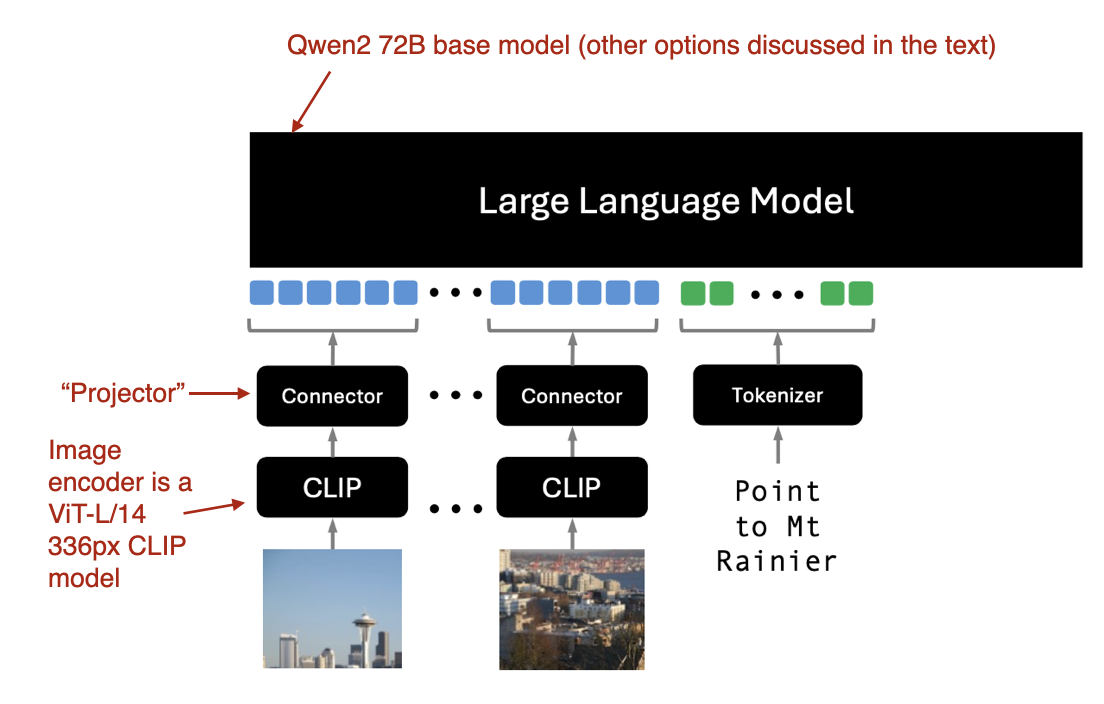
Molmo 解码器专用方法(方法 A)的示意图。(来源:论文 Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models:https://www.arxiv.org/abs/2409.17146。)
如上图所示,图像编码器采用了现成的视觉 Transformer,具体来说是 CLIP。“连接器”一词在这里指的是将图像特征与语言模型对齐的“投影器”。
Molmo 通过避免多个预训练阶段来简化训练过程,而是选择了一个简单的流水线,以统一的方式更新所有参数——包括基础 LLM、连接器和图像编码器的参数。
Molmo 团队为基础 LLM 提供了几个选项:
- OLMo-7B-1024(一个完全开放的模型骨干),
- OLMoE-1B-7B(一种混合专家架构;效率最高的模型),
- Qwen2 7B(一个开源权重模型,性能优于 OLMo-7B-1024),
- Qwen2 72B(一个开源权重模型,也是性能最佳的模型)
4.3 NVLM:开放前沿级多模态 LLM (锚点链接:4.3 NVLM:开放前沿级多模态 LLM)
NVIDIA 的论文 NVLM: Open Frontier-Class Multimodal LLMs (2024年9月17日)特别有趣,因为它没有专注于单一方法,而是探索了两种方法:
- 方法 A,统一嵌入解码器架构(“decoder-only architecture”,NVLM-D),以及
- 方法 B,跨模态注意力架构(“cross-attention-based architecture”,NVLM-X)。
此外,他们还开发了一种混合方法 (NVLM-H),并对所有三种方法进行了直接比较。
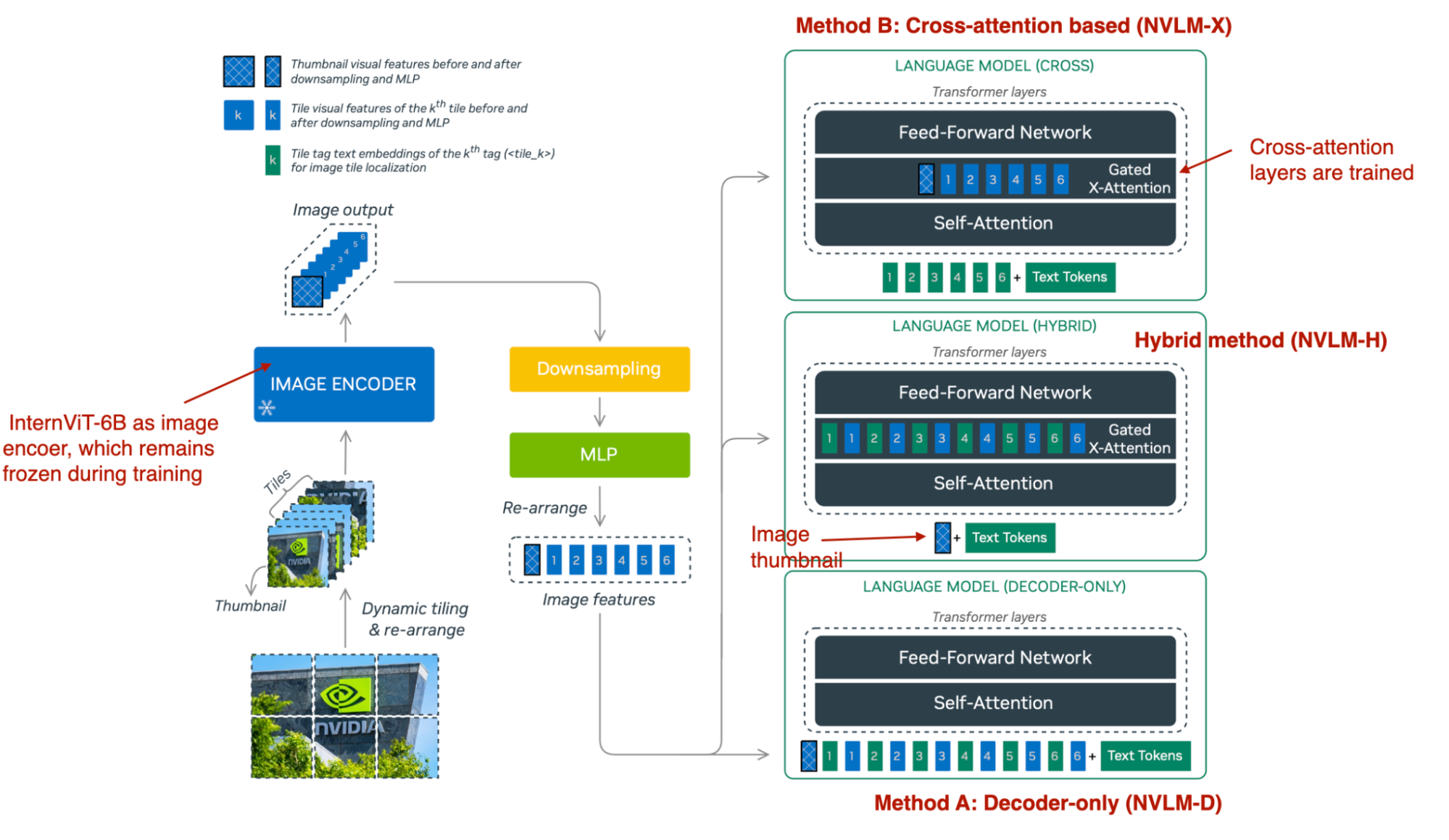
三种多模态方法的概述。(来源:论文 NVLM: Open Frontier-Class Multimodal LLMs:https://arxiv.org/abs/2409.11402)
如下图所示,NVLM-D 对应于方法 A,NVLM-X 对应于方法 B,正如前面讨论的那样。混合模型 (NVLM-H) 背后的概念是将两种方法的优点结合起来:提供图像缩略图作为输入,然后通过交叉注意力传递动态数量的图像块,以捕获更精细的高分辨率细节。
简而言之,研究团队发现:
- NVLM-X 在高分辨率图像方面表现出更高的计算效率。
- NVLM-D 在 OCR 相关任务中实现了更高的准确率。
- NVLM-H 结合了两种方法的优点。
与 Molmo 和其他方法类似,他们从纯文本 LLM 开始,而不是从头开始预训练多模态模型(因为通常这样做效果更好)。此外,他们使用指令调优的 LLM 而不是基础 LLM。具体来说,骨干 LLM 是 Qwen2-72B-Instruct(据我所知,Molmo 使用的是 Qwen2-72B 基础模型)。
在训练 NVLM-D 方法中的所有 LLM 参数时,他们发现在 NVLM-X 中,冻结原始 LLM 参数并在预训练和指令微调期间仅训练交叉注意力层效果良好。
对于图像编码器,他们没有采用常见的 CLIP 模型,而是选择了 InternViT-6B。在整个训练过程中,该编码器始终保持冻结状态。
投影器是一个多层感知机,而不是单个线性层。
4.4 Qwen2-VL:增强视觉语言模型在任意分辨率下对世界的感知能力
前文提及的 Molmo 和 NVLM 模型均构建于 Qwen2-72B LLM 之上。而在这篇论文中,Qwen 研究团队正式发布了他们自己的多模态 LLM——《Qwen2-VL:增强视觉语言模型在任意分辨率下对世界的感知能力》(Qwen2-VL:Enhancing Vision Language Models’ Perception of the World at Any Resolution,2024年10月3日)。
这项工作的核心在于他们提出的“基础动态分辨率”(Naive Dynamic Resolution)机制(此处的“naive”是特意为之,而非笔误,虽然 “native” 一词也颇为贴切)。这种机制使模型能够处理各种分辨率的图像输入,无需预先进行简单的下采样,因此直接接受原始分辨率的图像。
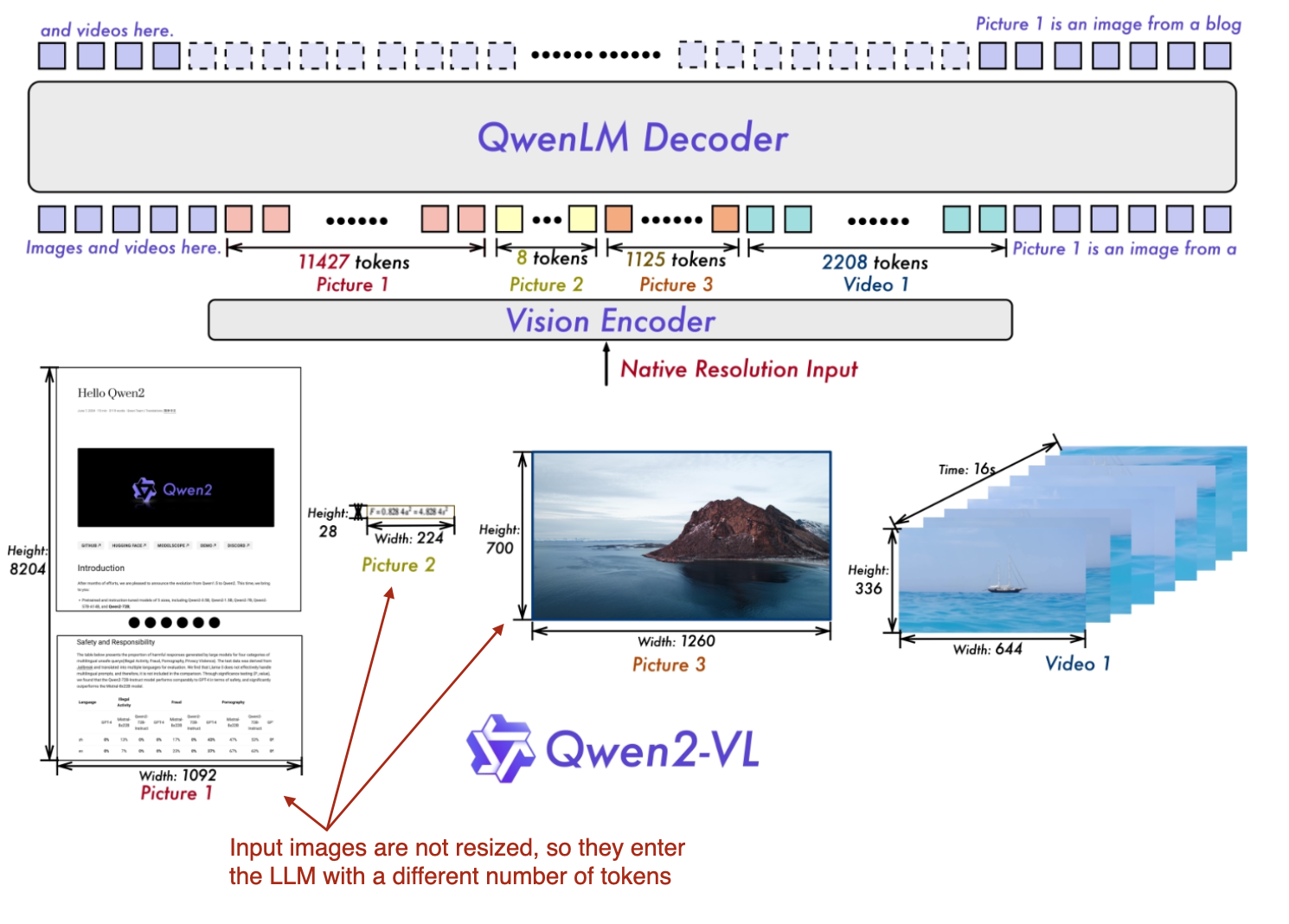
多模态 Qwen 模型概览:该模型能够原生处理多种不同分辨率的输入图像。(图片来源:《Qwen2-VL》论文,点击查看详情,已添加注释)
原生分辨率输入功能的实现,得益于对 ViT(Vision Transformer,视觉 Transformer 模型)的改进。改进之处在于移除了原始的绝对位置嵌入,并引入了 2D-RoPE(二维旋转位置编码)。
研究团队采用了经典的视觉编码器(包含 6.75 亿参数)以及不同规模的 LLM 主干网络,具体配置如下表所示。

不同 Qwen2-VL 模型的组成部分。(图片来源:《Qwen2-VL》论文,点击查看详情,已添加注释)
Qwen2-VL 的训练过程分为三个阶段:
- 第一阶段:图像编码器预训练 - 仅对图像编码器进行预训练。
- 第二阶段:全参数解冻 - 解冻包括 LLM 在内的所有模型参数。
- 第三阶段:指令微调 - 冻结图像编码器,仅对 LLM 进行指令微调。
4.5 Pixtral 12B
接下来要介绍的是 Mistral AI 推出的首个多模态模型——Pixtral 12B(发布于 2024 年 9 月 17 日)。Pixtral 12B 基于方法 A:统一嵌入式解码架构。 遗憾的是,目前尚无官方技术论文或报告,但 Mistral 团队在其博客文章中分享了一些值得注意的细节。
值得注意的是,Mistral 团队并未使用预训练的图像编码器,而是选择从零开始训练了一个拥有 4 亿参数的编码器。 LLM 主干网络方面,他们采用了 12B(即 120 亿)参数的 Mistral NeMo 模型。
与 Qwen2-VL 相似,Pixtral 也原生支持处理可变尺寸的图像,如下图所示。
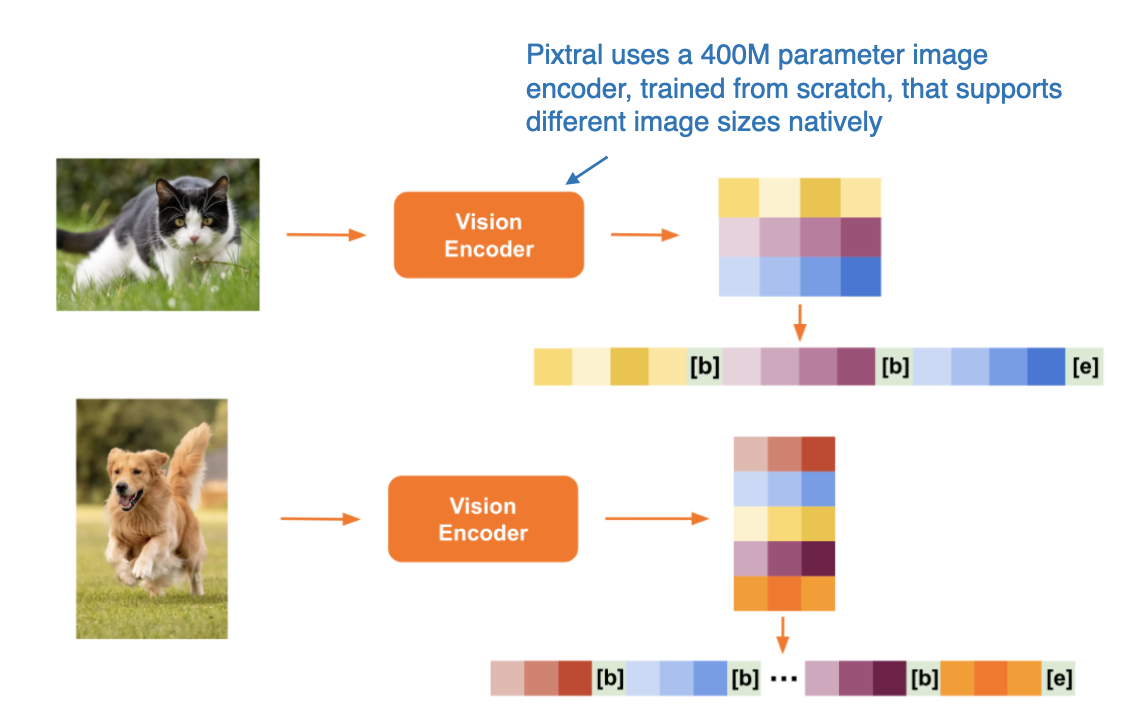
Pixtral 模型处理不同尺寸图像的方式示意。(图片来源:Pixtral 博客文章,点击查看详情,已添加注释)
4.6 MM1.5:多模态 LLM 微调方法、分析与洞见
《MM1.5:多模态 LLM 微调方法、分析与洞见》论文(MM1.5: Methods, Analysis & Insights from Multimodal LLM Fine-Tuning,2024年9月30日发布)不仅提供了一系列多模态 LLM 微调的实用技巧,还介绍了一种混合多专家模型,以及一个类似于 Molmo 的密集模型。 这些模型的参数规模覆盖广泛,从 1B 到 30B(即 10 亿到 300 亿)不等。
该论文中描述的 MM1.5 模型,其核心在于方法 A——统一嵌入式 Transformer 架构。这种架构能够有效地组织多模态输入,从而优化多模态学习效果。
此外,论文还包含了一系列有趣的消融实验,深入研究了数据混合策略以及坐标 tokens 的作用。
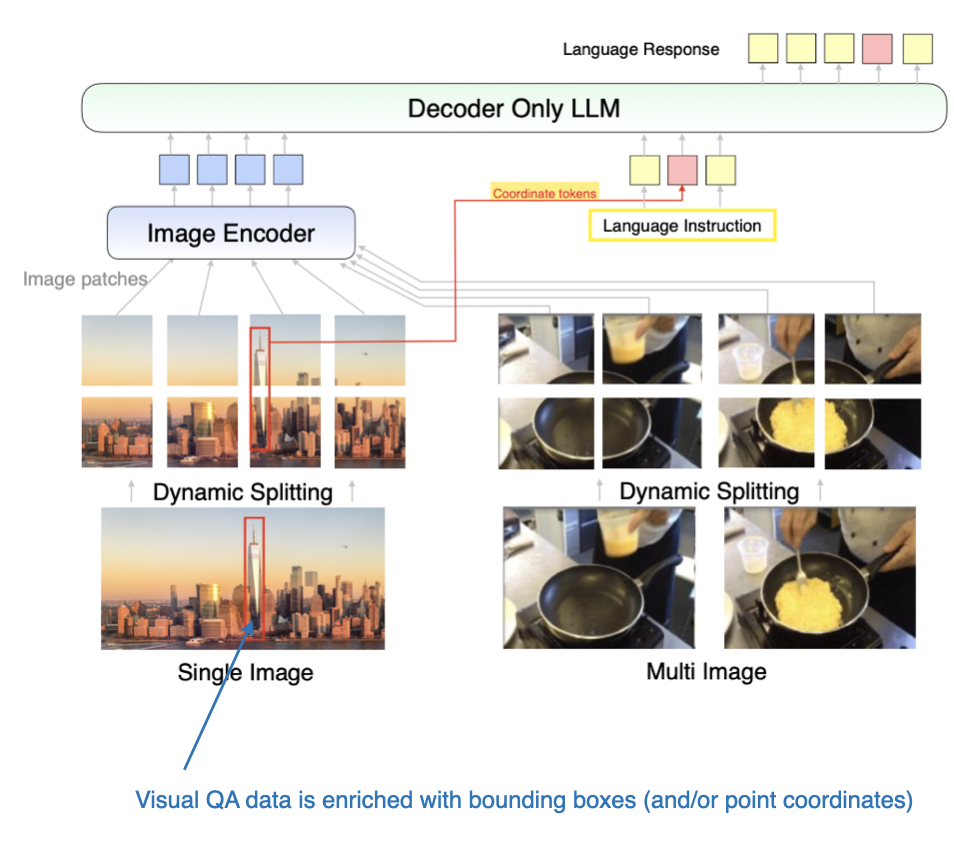
MM1.5 方法示意:该方法引入了额外的坐标 tokens 以表示边界框。(图片来源:《MM1.5》论文,点击查看详情,已添加注释)
4.7 Aria:开放式原生混合专家多模态模型
《Aria:开放式原生混合专家多模态模型》论文(Aria: An Open Multimodal Native Mixture-of-Experts Model,2024年10月8日发布)介绍了另一种混合专家模型,与 Molmo 和 MM1.5 中的变体模型相似。
Aria 模型总参数量为 24.9B(即 249 亿),其中每个文本 token 的参数约为 3.5B(即 35 亿)。图像编码器 (SigLIP) 的参数量为 4.38 亿。
Aria 模型基于交叉注意力机制,其整体训练流程包括以下两个阶段:
- 从零开始训练 LLM 主干网络。
- 预训练 LLM 主干网络和视觉编码器。
4.8 Baichuan-Omni
《Baichuan-Omni 技术报告》(Baichuan-Omni Technical Report,2024年10月11日发布)介绍了 Baichuan-Omni,这是一款基于方法 A(统一嵌入解码器架构)的 7B(即 70 亿)参数多模态 LLM,模型结构如下图所示。
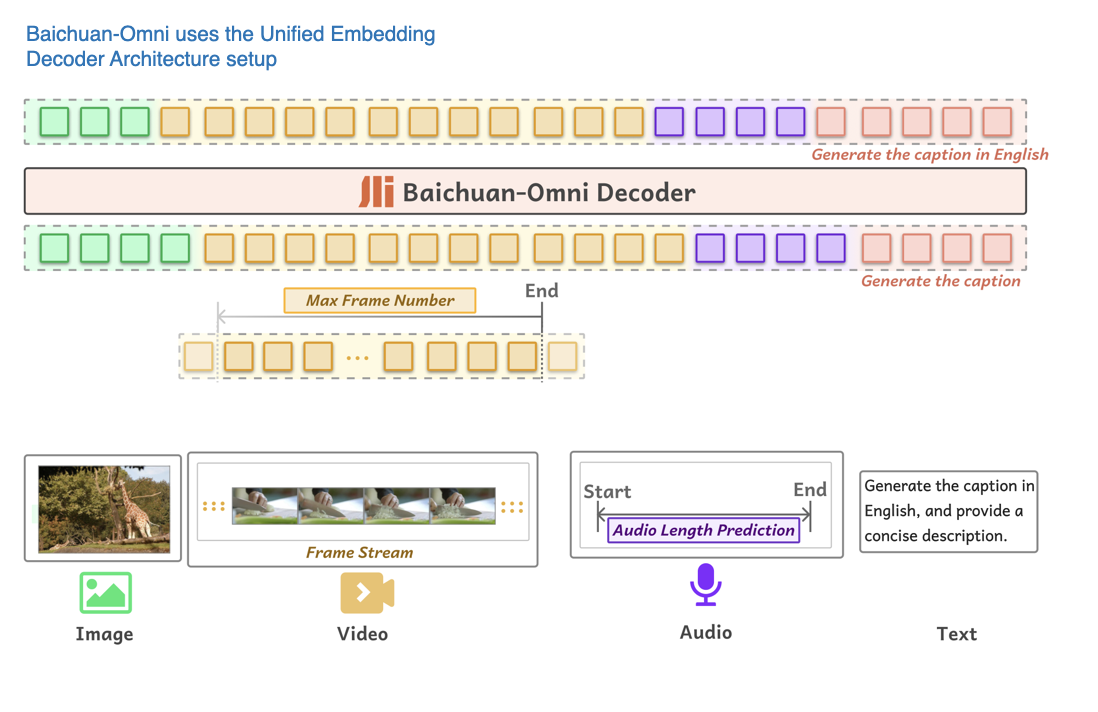
Baichuan-Omni 模型概览:该模型能够处理多种输入模态。(图片来源:《Baichuan-Omni》论文,点击查看详情,已添加注释)
Baichuan-Omni 的训练过程分为以下三个阶段:
- 第一阶段:Projector 训练 - 初始阶段仅训练 Projector(映射层),视觉编码器和语言模型(LLM)保持冻结状态。
- 第二阶段:视觉编码器训练 - 解冻视觉编码器并进行训练,LLM 仍保持冻结状态。
- 第三阶段:完整模型训练 - 最后,解冻 LLM,允许对整个模型进行端到端训练。
Baichuan-Omni 模型采用了 SigLIP 视觉编码器,并整合了 AnyRes 模块,通过下采样技术来处理高分辨率图像。
虽然该技术报告并未明确指出 Baichuan-Omni 的 LLM 主干网络具体是哪个模型,但考虑到其 7B 的参数规模和命名惯例,推测其很可能基于 Baichuan 7B LLM。
4.9 Emu3:基于下一个 Token 预测的图像生成新范式
《Emu3:只需预测下一个 Token》论文(Emu3: Next Token Prediction is All You Need,2024年9月27日发布)为图像生成任务提供了一种引人注目的新思路,它完全基于 Transformer 解码器架构,从而为扩散模型提供了一个替代方案。 尽管 Emu3 并非传统意义上的多模态 LLM(即专注于图像理解的模型),但其创新性在于证明了 Transformer 解码器同样可以胜任图像生成任务,而这一领域长期以来由扩散模型占据主导地位。(需要注意的是,此前已有类似研究,例如《Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation》)。
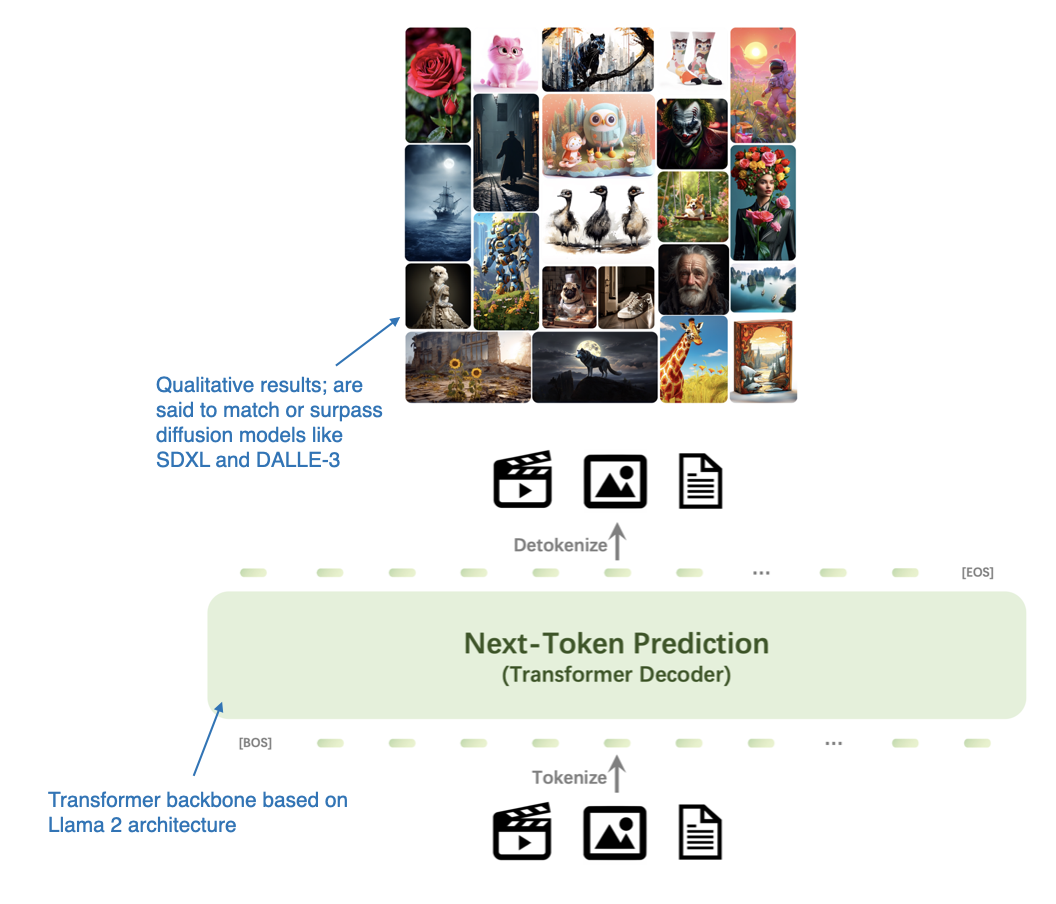
Emu3 主要作为图像生成 LLM,旨在成为扩散模型的有效替代方案。(图片来源:《Emu3》论文,点击查看详情,已添加注释)
Emu3 由研究人员从零开始训练,并采用偏好优化 (DPO) 算法,使模型输出与人类偏好对齐。
Emu3 的架构包含一个视觉 tokenizer,其设计灵感来源于 SBER-MoVQGAN。核心 LLM 架构则基于 Llama 2,但同样是从头开始训练的。
4.10 Janus:解耦视觉编码,实现多模态理解与生成的统一
前文主要关注的是用于图像理解的多模态 LLM,Emu3 是一个图像生成的特例。而《Janus:解耦视觉编码,实现多模态理解与生成的统一》论文(Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation,2024年10月17日发布)则提出了一个新颖的框架,旨在通过单一的 LLM 主干网络,统一处理多模态理解和生成任务。
Janus 的关键创新在于解耦了视觉编码通路,以适应理解和生成任务的不同需求。研究人员指出,图像理解任务需要高维度的语义表征,而生成任务则需要图像具备精细的局部信息和全局一致性。 Janus 通过分离视觉编码通路,有效地兼顾了这两种任务的不同需求。
Janus 模型采用了与 Baichuan-Omni 相似的 SigLIP 视觉编码器来处理视觉输入。 在图像生成方面,则利用“向量量化 (VQ)” tokenizer 来驱动生成过程。 Janus 的基础 LLM 是 1.3B 参数的 DeepSeek-LLM。
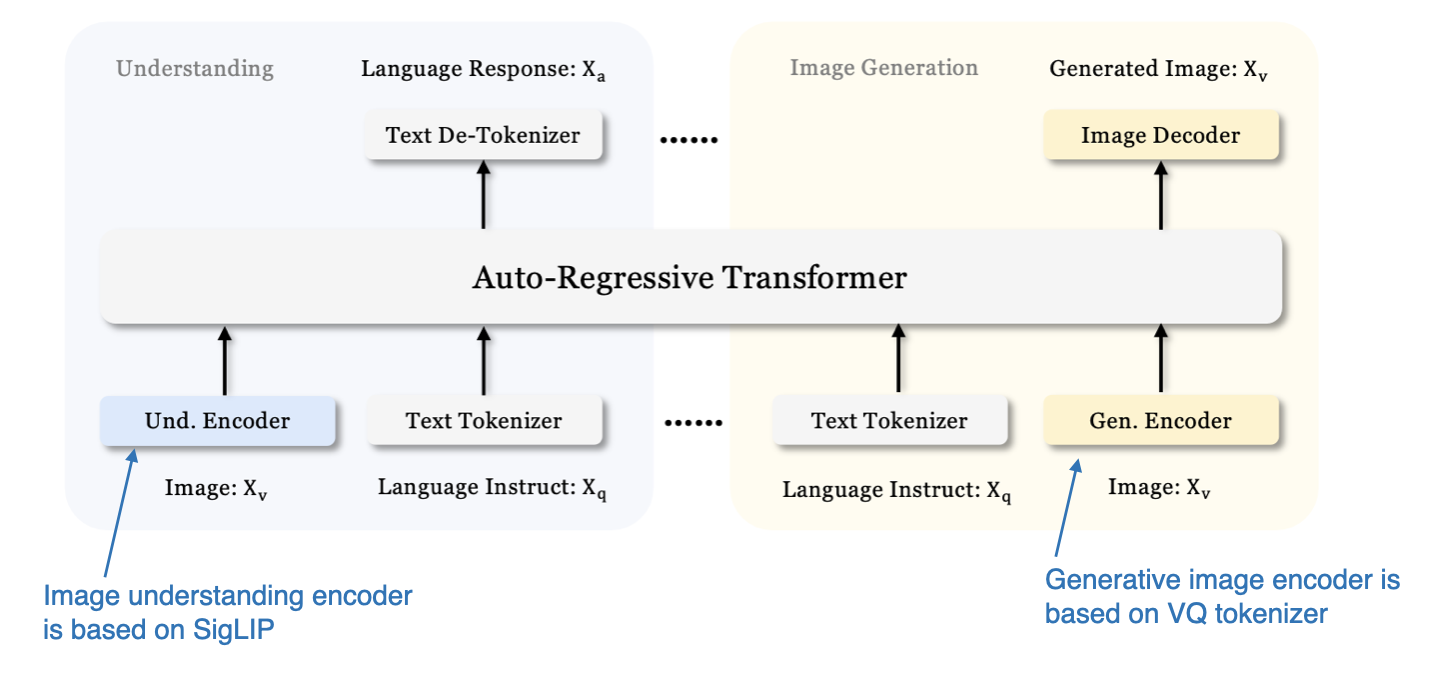
Janus 模型采用的统一解码器框架概览。(图片来源:《Janus》论文,点击查看详情,已添加注释)
下图展示了 Janus 模型的三阶段训练过程。
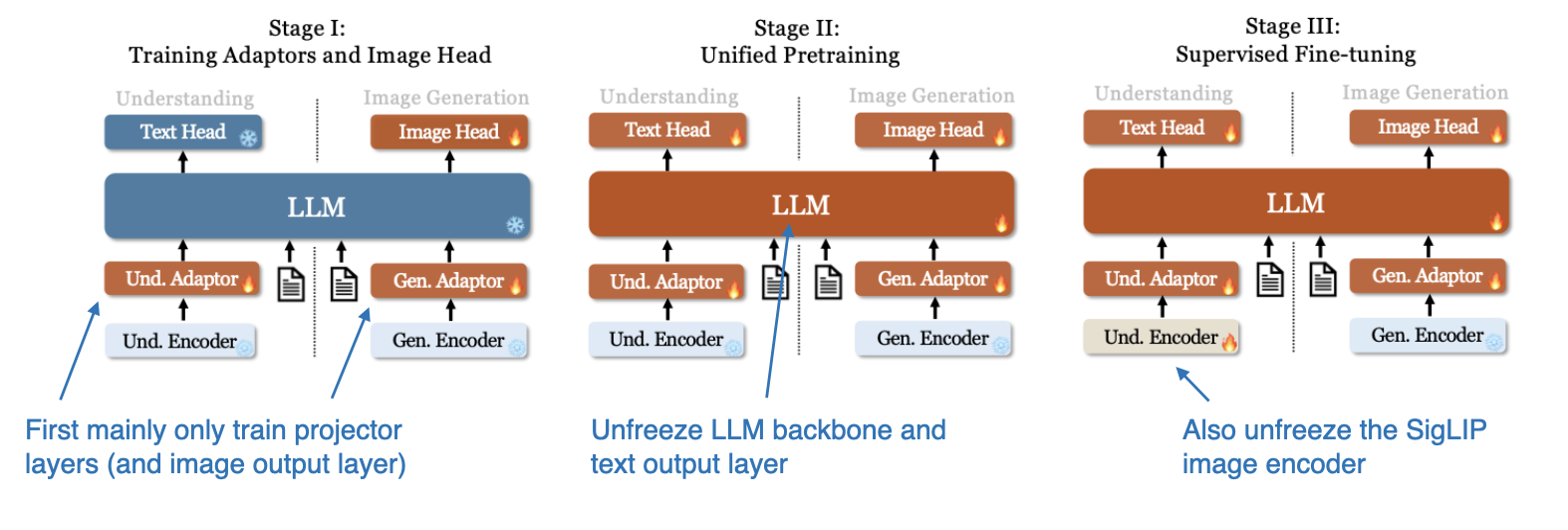
Janus 模型的三阶段训练过程示意。(图片来源:《Janus》论文,点击查看详情,已添加注释)
Janus 的训练过程分为三个阶段。第一阶段,仅训练 Projector 层和图像输出层,LLM、理解编码器和生成编码器保持冻结。第二阶段,解冻 LLM 主干网络和文本输出层,进行跨理解和生成任务的统一预训练。第三阶段,解冻包括 SigLIP 图像编码器在内的整个模型,进行监督微调,以充分整合和优化模型的多模态能力。
结论
细心的读者可能已经发现,本文几乎没有涉及模型和计算性能的对比分析。 这主要是因为,在公开基准测试中直接比较 LLM 和多模态 LLM 的性能是极具挑战的,数据污染问题普遍存在,即测试数据可能已泄露并被模型在训练过程中学习。
此外,不同模型的架构组件差异显著,也使得 “苹果对苹果” 的直接对比难以实现。 因此,NVIDIA 团队开发不同版本的 NVLM 确实是一项值得称赞的工作,它至少为我们提供了一个在解码器专用模型和交叉注意力模型之间进行相对比较的可能。
总而言之,本文的核心 takeaways 是:多模态 LLM 可以通过多种途径成功构建。 下图总结了本文所介绍的各个模型的关键组件。
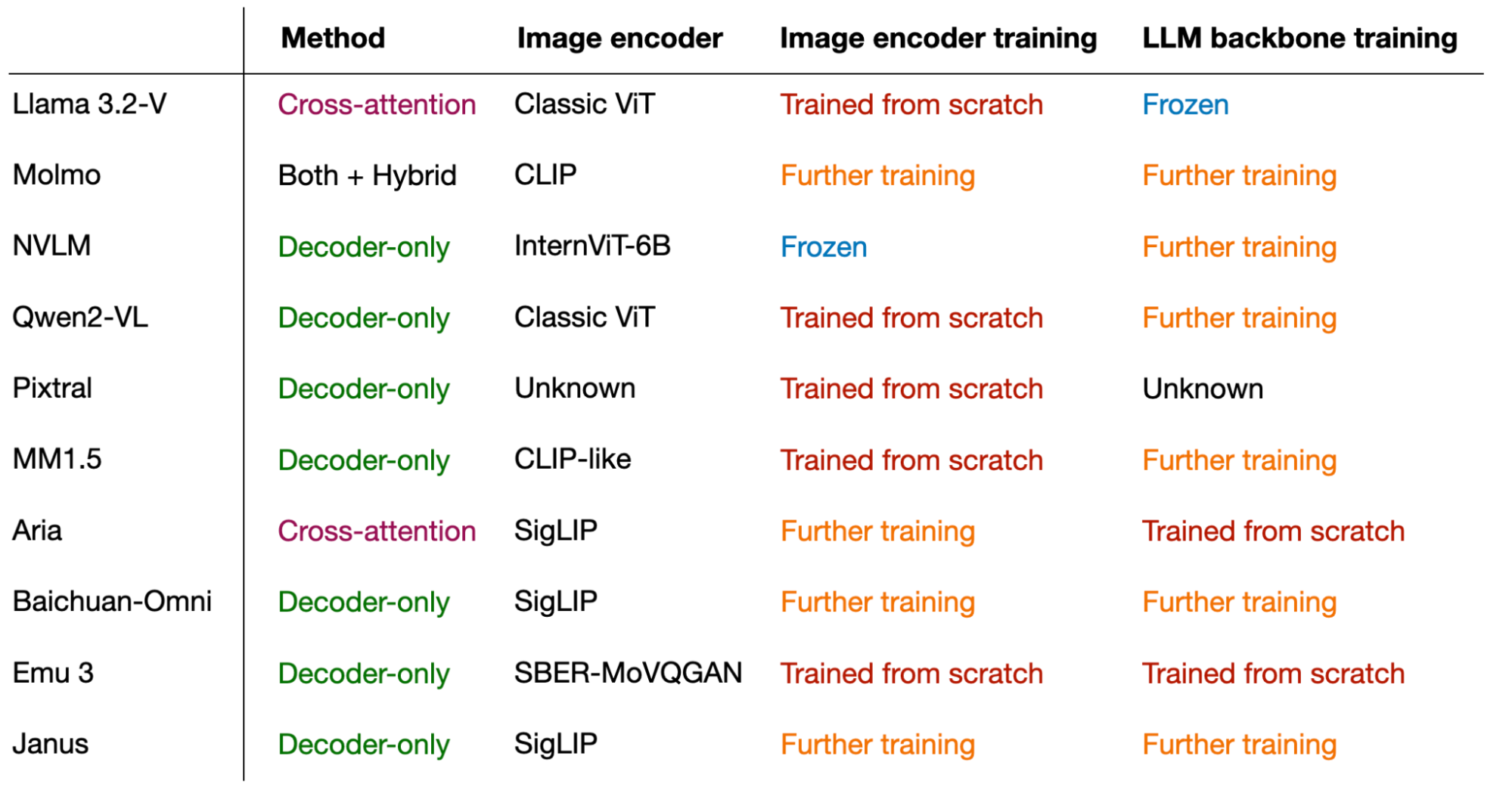
本文介绍的不同模型及其子组件和训练方法概览。
希望本文能为您带来启发,并帮助您对多模态 LLM 的工作原理建立更深入的理解。