封面提示词(Nano Banana Pro):Minimalist botanical art poster with a faded photocopy texture. The main subject of the image is a large, translucent silhouette of a palm leaf, treated with high-contrast black and white halftone dots, overlaid on color blocks of warm sand and dusty rose. The mottled texture caused by "screen clogging" is clearly visible. The words "TROPICS" and "SILENCE" use an ultra-thin typewriter font and are irregularly scattered in the negative space of the leaf. The overall atmosphere is dry and quiet, like an old poster sun-bleached for a long time.
上周精选✦
谷歌发布 Gemini TTS 模型更新以及原生音频模型更新
Gemini 2.5 Flash 和 Gemini 2.5 Pro 的 TTS 模型更新
Gemini 2.5 Flash 和 Pro 的 TTS 模型更新了,这次比较强的是支持通过提示词直接定义语音的性别、年龄等特征了,情绪控制也支持,比现在主流的直接选模型要强非常多。核心改进包括:
更丰富的表达力,能更严格遵循风格提示,从“轻快乐观”到“庄重严肃”都能真实呈现;
上下文感知的节奏控制,可根据内容自然加减速,并更准确执行明确的语速指令;
更顺畅的多说话人对话,角色声音在来回切换中保持一致,且在多语言场景中持续稳定,目前支持 24 种语言。
开发者可立即在 Google AI Studio 与 Playground 体验,我自己也在 AI Studio 里面用这个做了个好玩的。
Gemini 2.5 Flash Native Audio 模型更新
除了 TTS 外谷歌的实时语音模型 Gemini 2.5 Flash Native Audio 也获得了更新,面向实时语音交互与智能客服等场景。新版本更擅长复杂工作流、遵循指令与多轮自然对话。
模型已经在 Google AI Studio、Vertex AI、Gemini Live 与 Search Live 等产品上线或开始推送。
比较强的是可以实现实时的同声传译,支持耳机端的流式语音到语音翻译,保留语者的语调、节奏与音高,覆盖 70+ 语言与 2000 语言对;支持连续聆听与双向对话、自动语言检测、风格迁移、多语输入与噪声鲁棒性。
这个功能已经可以在 Google Translate App 中面向美国、墨西哥、印度的 Android 设备上线,我试了一下现在没有声音的实时翻译也已经很强了。
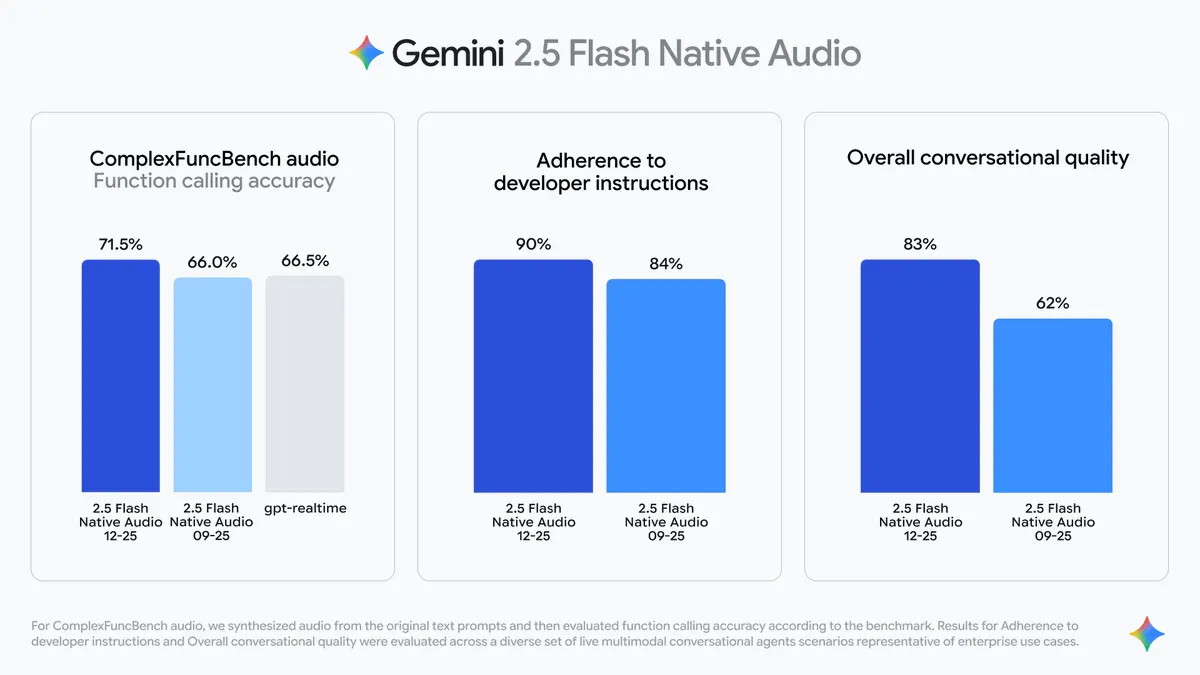
Open AI 发布 GPT-5.2
Open AI 也是在上周发布了预告了挺长时间的 GPT-5.2 。显著提升电子表格与演示生成、代码编写与调试、图像与界面理解、长上下文推理、工具调用,以及多步骤端到端任务执行。
在覆盖 44 职业的 GDPval 评测中,GPT‑5.2 Thinking 有 70.9% 任务达到或超过行业专家水准;在软件工程上,SWE‑bench Pro 55.6%、Verified 80.0%,更可靠完成生产级调试、重构与功能交付。
视觉方面,ScreenSpot‑Pro 显著降错,空间布局理解更强;工具调用在 τ2‑bench Telecom 达到 98.7%,多轮复杂任务的协调更稳健。
着重吹了一波视觉能力的提升,但是很快就被打脸了。推特上有人拿他们的测试题,去掉标记的框,然后同时让GPT-5.2和Gemini 3 Pro去标记,结果Gemini 3 Pro完爆。
ChatGPT 端分为三款:GPT‑5.2 Instant(高效主力,解释更清晰)、Thinking(复杂深入工作,编码/长文档/数学推理更强)、Pro(高难场景最高可靠)。GPT‑5.1 仍保留三个月后停止支持。API 命名与可用性:gpt‑5.2(Thinking)、gpt‑5.2‑chat‑latest(Instant)、gpt‑5.2‑pro(Pro),Thinking/Pro 新增 xhigh 第五档推理强度。定价提升但强调 Token 效率:gpt‑5.2 输入 $1.75/M、输出 $14/M,缓存输入九折优惠;gpt‑5.2‑pro 输入 $21/M、输出 $168/M。
Runway 急了,发布了一堆视频模型,但都是期货
Runway 急了,上周开了一个视频发布会。直接发布了 5 个新的视频和世界模型:
首先是它的Gen 4.5视频模型,现在支持原声音频的生成和原声音频的编辑。
ALF 视频编辑模型支持对任意长度和多个镜头的视频进行编辑,保证角色、光照和环境的一致性。
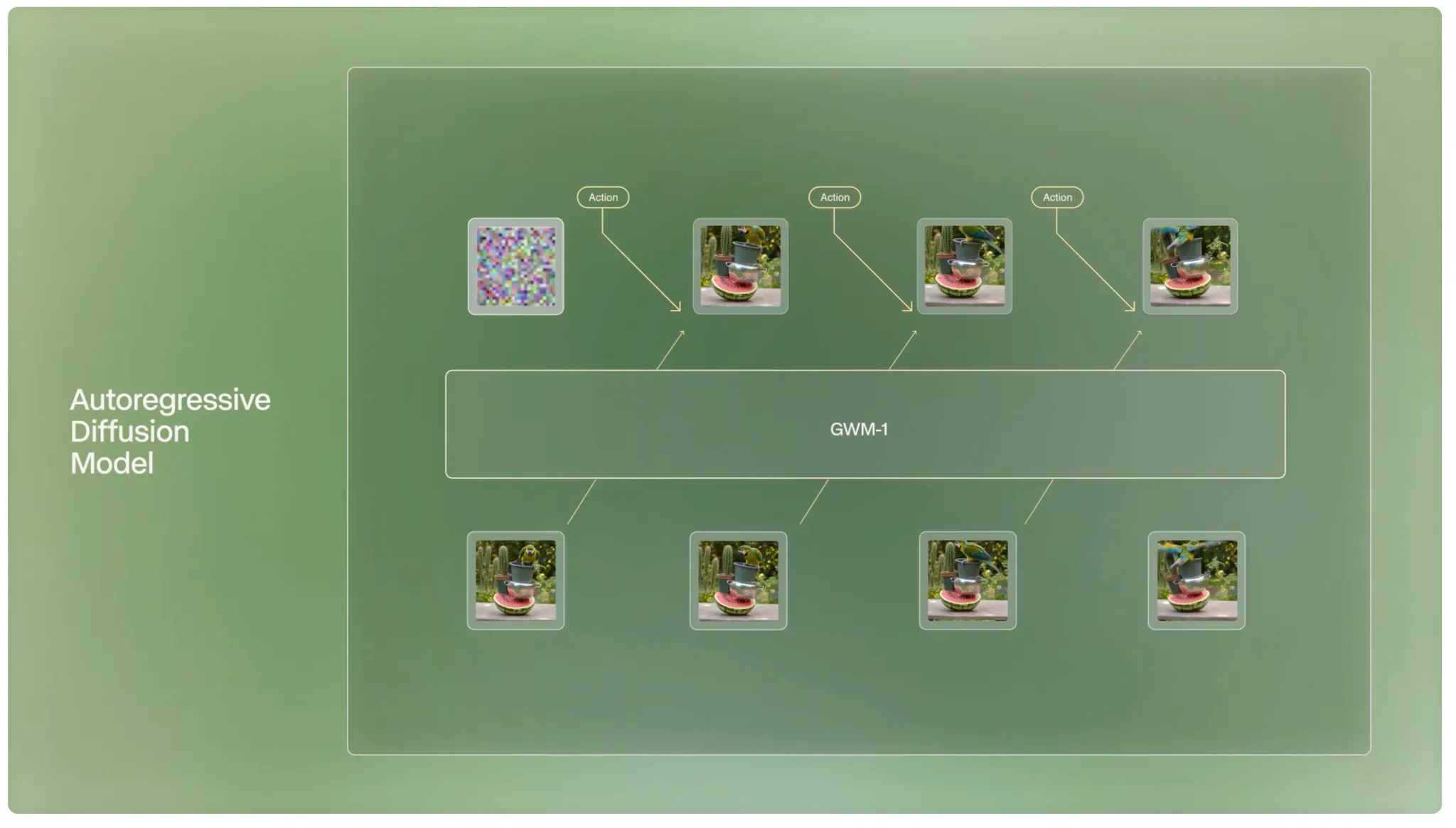
他们发布了自己的首个通用世界模型GWM1,基于Gen 4.5训练的自回归模型,可以根据前序内容进行后续的逐帧预测,用户可以在流式生成过程中随时进行干预及采取行动。
GWM Worlds 实时环境模拟的世界模型,户可以通过描述场景或提供图像参考,生成一个具有正确几何结构、光照和物理属性的沉浸式环境,允许探索和交互。
GWM Avatars 高保真数字人模型,音频驱动的实时视频生成模型,能够模拟自然的人类动作和微表情,既可以模拟逼真的真人,也可以模拟动画角色。
GWM Robotics 机器人与物理 AI 模拟模型,该模型不仅学习成功的交互动态,还能模拟失败场景,这对于机器人学习至关重要,要用于策略评估和合成数据生成。
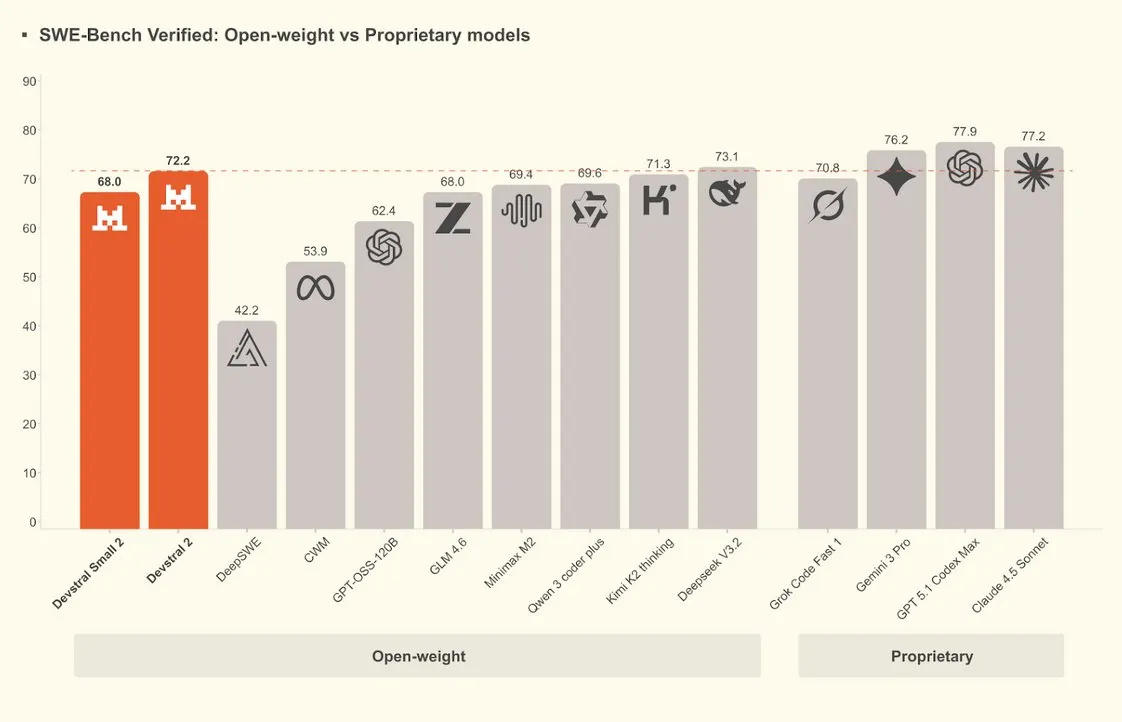
Mistral 开源专门用于编码的 AI 模型 Devstral 2,发布 CLI 工具
欧洲AI独角兽Mistral最近也是疯狂发力,开源了专门用于编码的 AI 模型 Devstral 2 。另外,他们还发布了一个叫 Mistral Vibe 的本地CLI编程工具,支持端到端自动化。
Devstral 2 包含两个模型:Devstral 2(123B)和 Devstral Small 2(24B)。目前以通过他们的 API 免费使用 Devstral 2,这个好。Devstral 2 在 SWE-bench Verified 上的分接近 Deepseek v 3.2 为 72.2 分。
Mistral Vibe CLI 是由 Devstral 提供支持的开源命令行编码助手。主要功能有:
- 自动扫描你的文件结构和 Git 状态以提供相关上下文。
- 通过 @ 自动补全引用文件,使用 ! 执行 shell 命令,并使用斜杠命令进行配置更改。
- 理解整个代码库——不仅限于你正在编辑的文件。
- 持久历史、自动补全和可自定义主题。