封面提示词:a bird's-eye view, a blue background with A white horse leads a group of black horses in motion, with motion blur, in a minimalist, massive negative space, simple poster design, in the style of yoji shinkawa, creating an atmosphere of mystery and power --ar 16:9 --raw --profile djfzowq
上周我自己主要是在迭代 CodePilot。核心内容分为两部分:
- 第一部分是思考如何让大家在 AI Agent 中更方便地使用 CLI 工具。为此,我还搞了一个 Agent 友好的 CLI 评判标准,并写了一篇文章进行详细介绍。
- 第二部分是关于最近 Claude Code 泄露的“宠物模式”。我也在想如何降低门槛,让大家更好地学习和使用这套 Agent 解析逻辑。于是我在 Google Play 中也实现了一个宠物模式,并顺便写了篇文章来讨论这件事情。
上周精选✦
Claude Code 源码意外泄露
上周最大的事就是 Claude Code 的源码泄露了,应该是他们手动发布,然后某个人失误把 NPM 注册表的 MAP 打包进了发布的文件里。
之后他们的员工也出来澄清了,意思是因为某个人的失误以及流程的不规范,导致被错误地打包了进去。很多人开玩笑说有没有人被开除,对此 Anthropic 表示他们奉行“零责任制”:一个人的问题就是所有人的问题。他们会把发布流程改为自动化。
发布打包失误是“人祸 + Bun 生成 sourcemap 的坑”,而且 13 个月前就犯过一次同样的错。
同时里面还有个 Undercover 模式:在非内部私仓自动注入系统 prompt,禁止暴露内部代号、版本号、甚至“Claude Code”字样,而且“只能强制打开,不能强制关闭”。
Rajan 根据泄露代码指出:Claude Code 的子Agent利用 KV cache 做 fork-join,让子Agent继承完整上下文,不用重复推理之前的内容,相当于在缓存层做分叉并行。
Ellen 结合源码,把 Claude Code 的会话内记忆管线拆成 8 个阶段:
1)session 初始化挂 hook、预热 memory cache、异步目录扫描
2)按优先级发现多层记忆源:企业策略 → 用户全局 → 项目 VCS → 本地目录 → 自动生成 → 团队共享
3)每次 API 调用都合成三路上下文:system prompt + memory section + user context,并用子调用选最多 5 个 memory 文件
4)模型通过专门的读写工具直接操作 memory 文件,后台 extractor 与模型写作互斥
5)每次回复后都会触发三个后台 agent:extractMemories、sessionMemory 和 autoDream
6)上下文接近上限时,按策略压缩旧消息,至少保留 10k tokens / 5 个文本块
7)记忆分布在 ~/.claude/、项目根、sessions/、agent-memory/,自动记忆 gitignore,团队记忆进 VCS
8)通过“写入 → 提取 → 会话记忆 → 周期性 dream 合并”的闭环,在多次会话之间自我整理。
Himanshu:memory = index,不是存储,本质是“自愈记忆”
Himanshu 这条长推,基本把源码里的记忆设计总纲抽出来:
- MEMORY.md 只是索引,不是内容:每行约 150 字符,真正知识在外部 topic 文件里,按需加载。
- 三层结构:index(总是加载)→ topic files(按需)→ transcripts(只 grep,不整段回读)。
- 严格写入纪律:先写文件,再更新索引,禁止把大段内容直接 dump 进 index,避免熵增和污染。
- 背景“自动重写”(autoDream):合并、去重、删除矛盾、把模糊改成明确、持续瘦身。
- “陳旧性”是一等公民:memory 和现实不一致时,以现实为准,代码推导出来的事实不会存入记忆。
- 隔离:consolidation 在 forked subagent 中跑,工具受限,避免污染主上下文。
- 检索是“怀疑式”的:记忆只是提示,使用前必须再核实。
- 最重要的是“不存什么”:不存日志、不存代码结构、不存 PR 历史,可推导的就不持久化。
在 Claude Code 的代码泄露以后,Anthropic 也发了很多新的补丁,用来解决他们家额度不够的问题。
比如说大家一直说的缓存出错问题,调研了半天,发现他们的意思是没有问题。
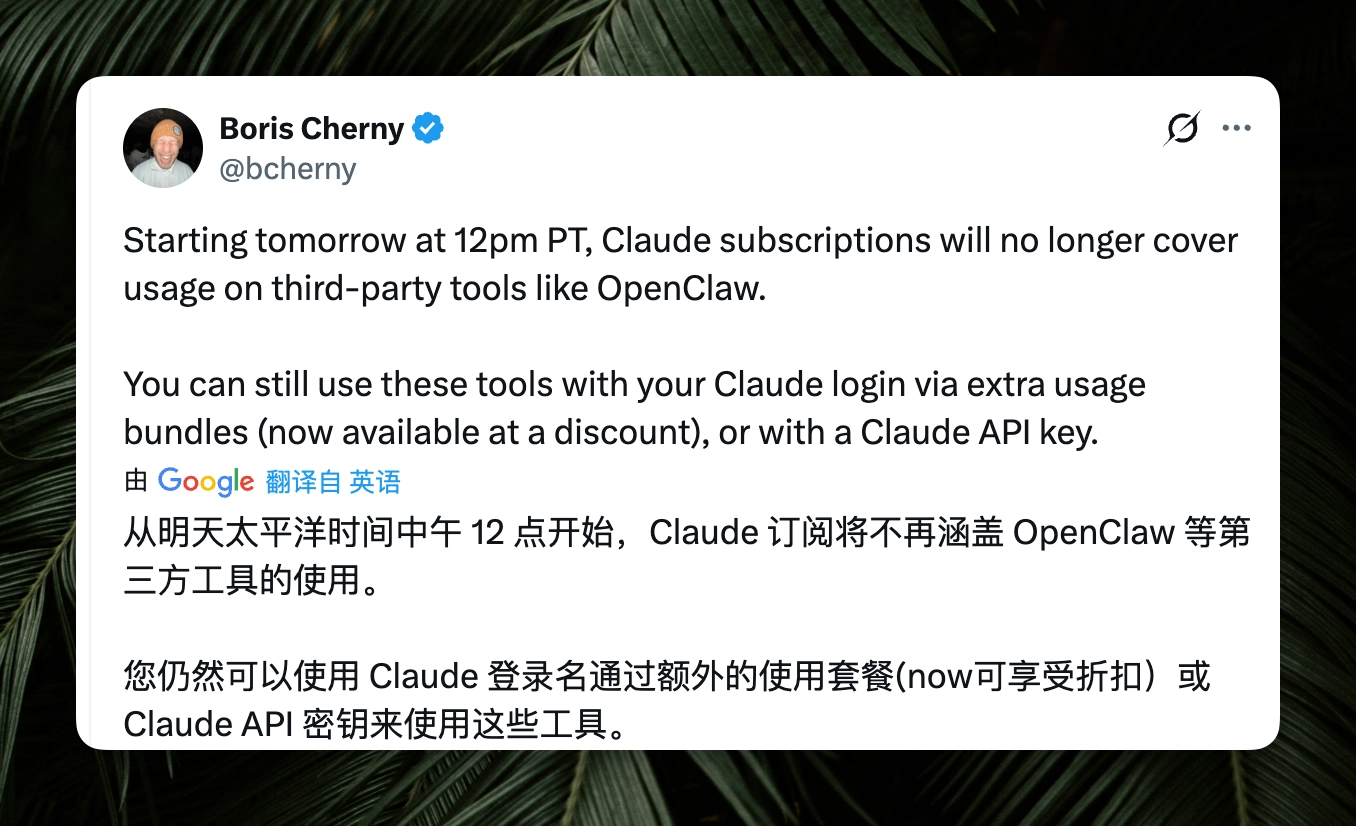
另外还宣布说,Claude 的 Max Pro 账号额度不允许给第三方产品用了。
也就是说,如果你没有使用 Agent SDK 和 Claude Code 为底座的产品,就不能用这个账号里的额度,需要单独购买。特别提到了针对这个 OpenClaw。
还有一个是说,如果你的系统提示里改了(就是你 Claude Code 的系统提示改了),也会报错。
如果不是原来的系统提示,比如你加上了 OpenCode 这种词,即使是用 Claude Code,也没有办法响应了。
最后一个,今天写的时候发现,就是如果大家用这个 Claude Code 去分析 Claude Code 泄露的源码就会报错。我目前没有报错,但是已经有很多人都开始报错了。
总的来看,Anthropic 对于他们的产品(如 Claude)的开放度以及额度,存在越来越严格的趋势,并通过这种方式不断涨价。
所以我开始将我的 Codepilot 迁移,与 Claude Code 脱钩,确保大家没有 Claude Code 也可以正常使用。
谷歌发布开源端侧系列模型 Gamma 4
谷歌在沉寂了很长时间以后,终于发了一个不错的模型,而且还是开源的 Gamma 4 系列。专门用来在本地设备(比如手机、电脑)上跑,而且支持了 agent 和工具使用。
四个参数大小:
- E2B:主打手机 / IoT / 边缘设备。
- E4B:为移动端 + Jetson / 树莓派设计。
- 26B MoE:单次激活 3.8B,有效参数很小,主打高 TPS、低延迟。
- 31B Dense:全密集 31B,主打桌面工作站 / 单卡 H100 等。
这次他们把 Agency Workflows 的支持作为第一优先级:原生支持 Function Call、JSON 和结构化输出、System Instruction
更强的是这玩意还是原生多模态模型,支持:图像和视频理解,语音转文本,可以做本地语音助手。
而且它们这次是真正的 Apache 2.0 开源,允许商用、再分发和内嵌产品,以及私有部署,没有额外条款。
他们之前用来测试端侧模型的应用 Google AI Edge Gallery 也首先支持了这几个模型,你可以在手机上体验,ios 和安卓都有,我拿我自己的安卓试了一下推理速度相当快。
而且这个 App 现在还内置了一个 Skills 的体验区域,你可以自己去让它调用工具编写和试用 Skills。
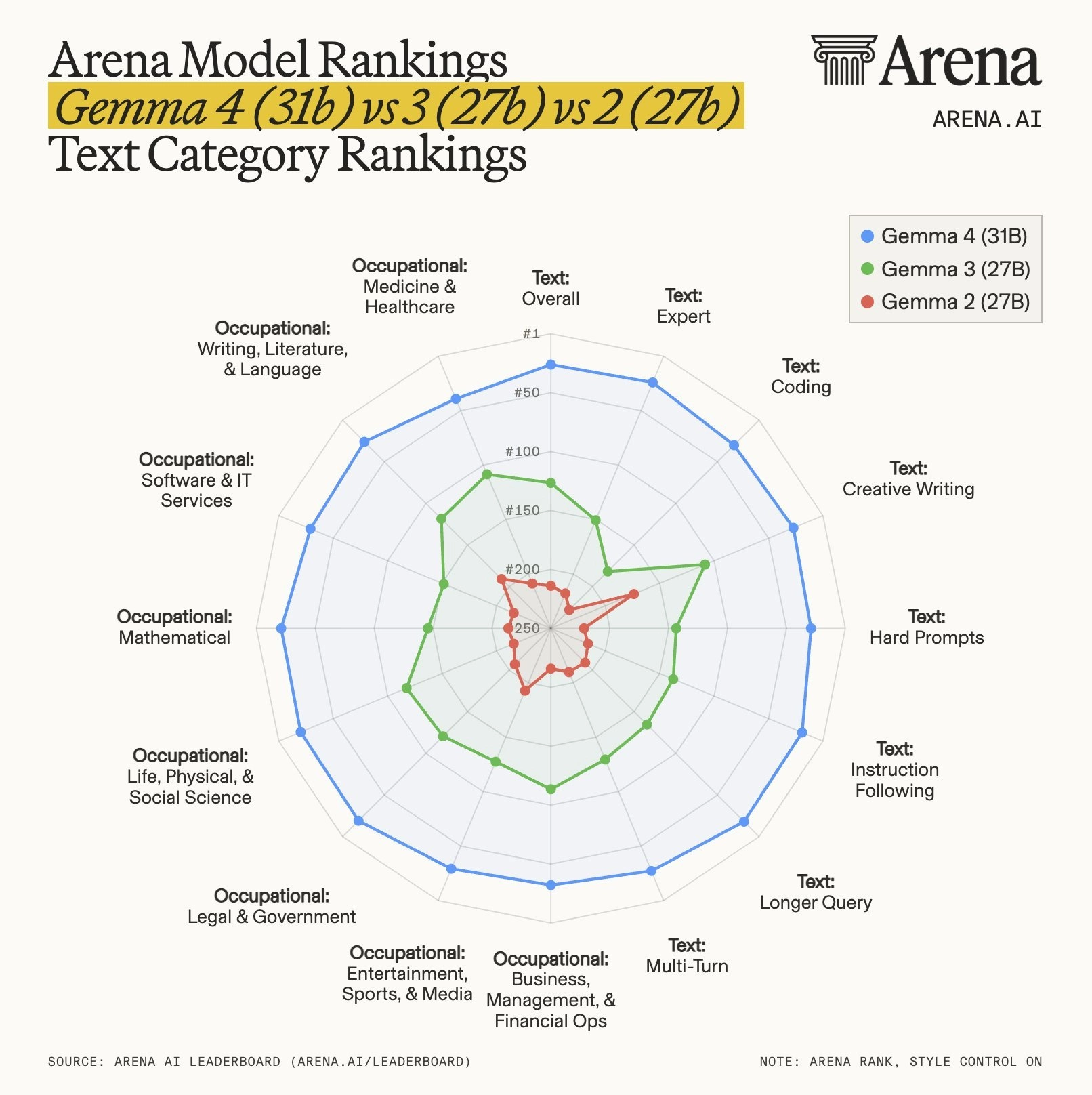
Arena 这个图能特别好地体现出谷歌 Gemma 4 模型的进步。可以看到 Gemma 4 和 3、2 的一个区别:
以前它的得分是有非常明显的长板和短板的,而 Gemma 4 几乎全能,在参数没有大提升的情况下,排名高了非常非常多。这两个性能提升的时间点分别是 9 个月和 13 个月。