其他动态 ✦
- Midjourney David 官宣了新的图像编辑器将在下周上线。支持上传外部图像基于图像的深度信息来生成新的图片。
- Heygen 新功能支持让虚拟人加入 zoom 会议。这样虚拟人用来整理会议纪要进行总结当主持人都很不错,你甚至可以自己跟自己开会。
- Twitter 最近更新的用户条款显示,他们会利用用户数据训练模型,内容可以与第三方共享,用于人工智能开发,新协议会从11月15号生效。
- Suno 移动应用可以通过图片和视频当做提示词生成音乐,同时在移动应用也出现了基于上下滑视频和音频结合的内容信息流,看起来他们野心真的很大。
- Pika 继续出 AI 视频特效,现在支持揉碎、溶解、放气和让内容消失。
- 为 B 端企业提供 AI Agents 服务的 decagon ai 公司获得 6500 万美元的 B 轮融资。这家公司现在的总融资金额已经达到 1 亿美元。他们的网站也很好看,可以参考一下。
- OpenAI正在与Crusoe Energy Systems合作在德州部署一个 10 万张 B200 的超级计算机集群。这个集群初期将使用 206 兆瓦的可再生能源,相当于约 10 万个普通家庭的用电需求,将在 2025 年上半年投入使用。
- Kimi 居然更新了语音通话模式,最好的一个设计是可以在语音界面展示字幕,还有独特的情景模式,目前应该还在灰度。
- Sam 的另一个项目 Worldcoin,更名为World,并且发布新的虹膜认证工具以及应用内的聊天工具等小程序。
有趣的AI内容 ✦
- 坤导(闲人一坤)在《山海奇镜》之后的新作好像是跟星爷公司合作的《无名特工队》即将上线,这次是AI动画风格,感兴趣可以看看。
- 让半夜的自己出现在中土世界变成一个精灵,用到的工具有,iPhone 拍摄、Sky glass app、Viggle AI、Runway、Udio。
- 新的爆款 FLUX Lora 预定,可以生成动漫和现实混合的图片,我用生成的图片做了个视频也被各种海外博主来回转。
- 这个Ethos 餐厅说自己是奥斯汀市排名第一的餐厅。在 ins 上有 7.2 万的粉丝,但是他们所有展示的食物和场地照片都是AI生成的。
- 这个海螺做的视频好玩。把经典影视内容所有的武器都变成冰淇淋。
- Flux Ghibsky Illustration 又一个非常好的 FLUX Lora。有一点吉卜力的风格,但是会有丰富的细节,饱和度很高,生成的图片很梦幻。
产品及模型推荐 ✦
陌生人闹钟
思路清奇的赵纯想最新作品,每天早晨,一个陌生人叫你起床。多管线的AI裁判,不知疲倦地负责监督声音,避免性别欺诈、声纹不一致性(变声器)和一切不友好、无意义内容。
把AI用在审核上真是好用法,直接解决陌生人社交最基本的信任问题。

BiLin搜索:沉浸式翻译团队新作
沉浸式翻译团队的新产品 AI 搜索 Bilin 很有意思。完全不做总结,只是提供多语言的搜索结果,拓展信息面。专注于解决某个语言的互联网内容不够的问题,其实已经很够用了。国内很多 AI 搜索质量差的问题是国内能搜到的数据就不行。
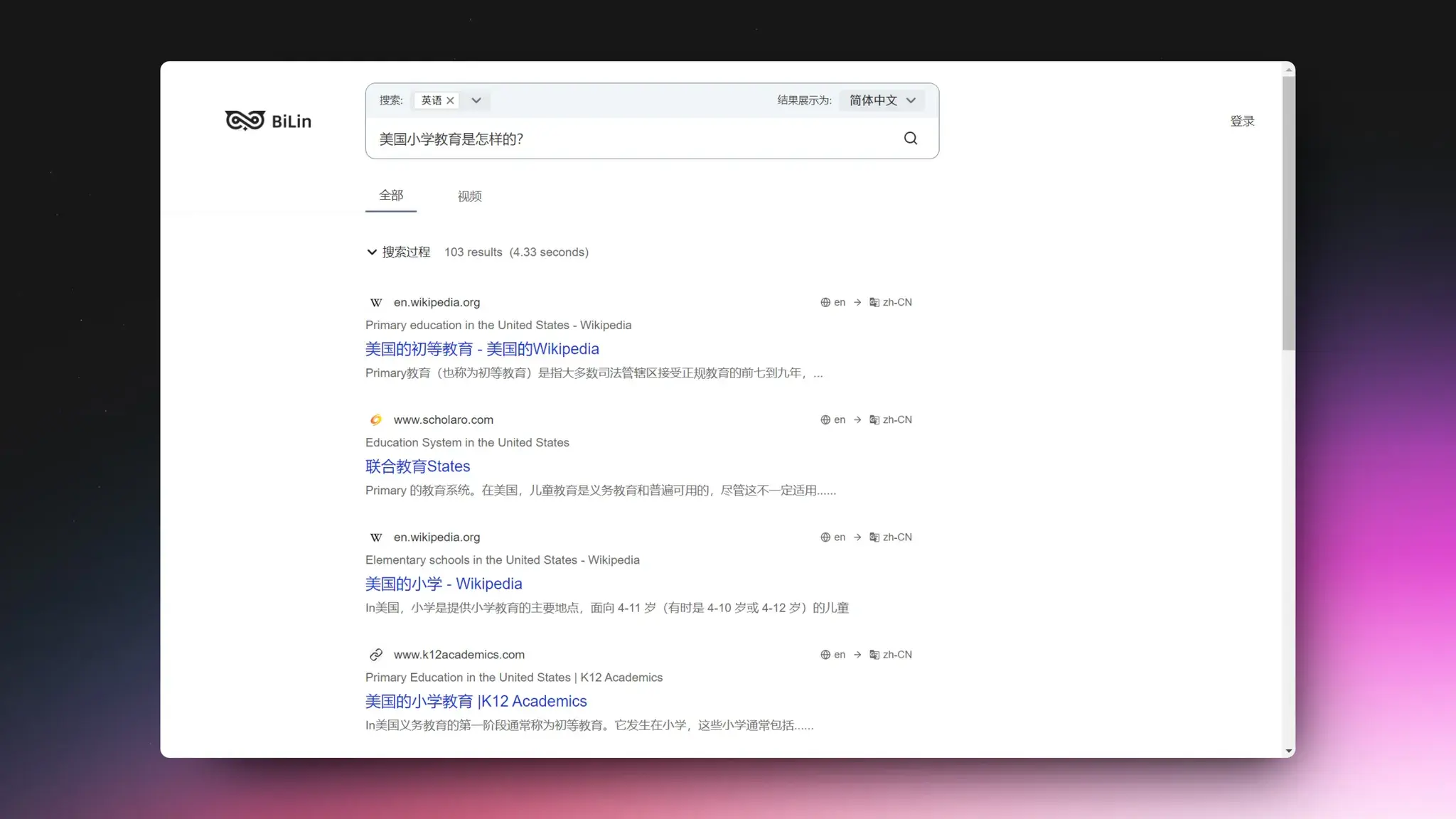
Reiden:快捷键副驾驶
这个很有意思,软件会在后台实时运行,然后识别你使用软件的低效时间段,并建议键盘快捷键以提高效率。通过智能键盘快捷键最大限度地减少压力,减少对鼠标的依赖并降低重复性压力损伤的风险。
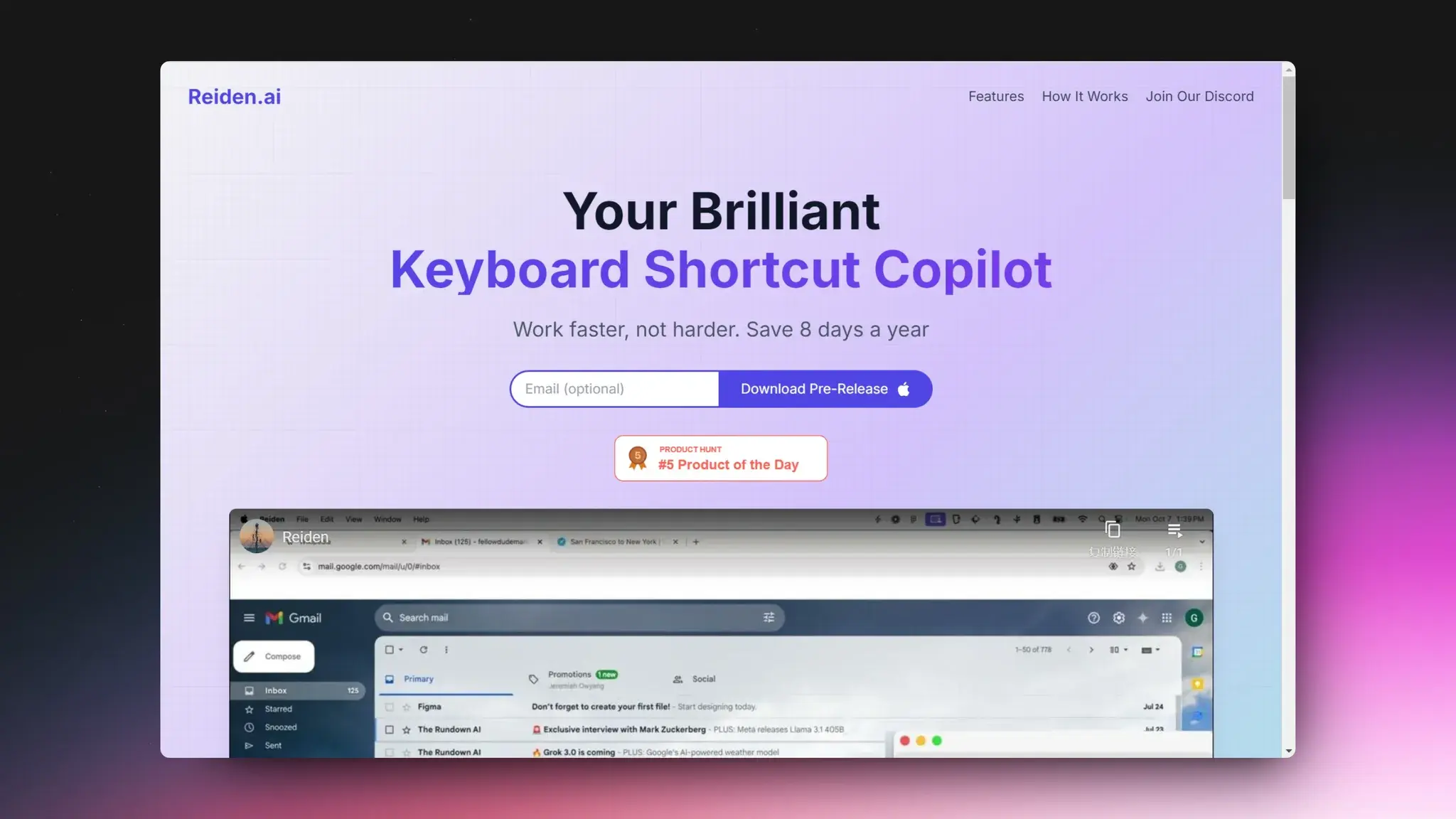
Reworkd:AI自动针对网页生成爬虫代码
Reworkd 是一个提供无需编码、无需维护的大规模网页数据提取解决方案的平台,它通过 AI 技术自动化整个数据提取流程,并提供深入的分析和维护服务,帮助企业有效地获取和使用网页数据。
该服务支持自动化数据提取、自我修复的爬虫、不产生幻觉的 AI 代码生成、处理任何数据类型(文本、图像、文档)的能力、深入的分析仪表板,以及实时监控和管理数据提取工作的状态。
精选内容 ✦
红杉:生成式人工智能(AI)进入了 “思维推理” 时代
红杉文章,随着生成式 AI 技术的发展,研究正在从快速预训练响应转向在推理时进行更深层次的推理。
AI 的推理能力的提升,促使了从预训练模型到深层次推理的转变,这种转变类似于 AlphaGo 在棋盘游戏中的思维过程。AI 正在从简单模仿人类模式的行为,向能够在复杂新颖情境中进行深思熟虑的推理思维迈进。这种推理能力的提升,对于 AI 的未来发展具有深远的影响,可能会导致 AI 技术在服务市场中的应用迅速扩展。
在 AI 技术栈中,基础模型层的凝固和推理层的竞争,为 AI 投资和应用提供了新的机遇。尽管存在一些挑战,如构建价值函数和编码领域特定的认知架构,但是 AI 原生应用正在出现,这些应用通过自动化和智能化的方式,为各行各业提供服务,从而创造和扩展市场。
对于现有的软件即服务(SaaS)公司,AI 的推理能力可能会带来破坏性的变革,因为 AI 原生应用不仅能够提供软件,还能够提供服务,这可能会导致 SaaS 公司的商业模式和市场定位发生变化。
使用思维机器的五种新思维方式
Dan Shipper 在其文章中探讨了人工智能时代对我们思维方式的影响,提出了五种新的思维方式,以适应与思维机器合作的新现实。
- 本质与序列:在人工智能之前,我们需要将问题简化为其本质,而在人工智能时代,我们更关注导致特定事件发生的底层序列。
- 规则与模式:从寻找规则转变为寻找模式,后者不能简化为简单的规则。
- 过程与直觉:从依赖过程和规则转变为依赖直觉和序列,以建立无法简化为规则的应用程序。
- 雕塑与园艺:创造性工作变得更像园艺,即创造条件让想法自然生长,而不是雕塑,即逐步塑造想法。
- 解释与预测:从追求解释转变为追求预测,特别是在复杂领域,预测比解释更能推动进步。
Cursor dethrones Copilot:8 条实用的 Cursor 实用技巧
Beta Acid 介绍了如何使用 Cursor 工具提高开发效率,并分享了一些实用技巧和最佳实践。
比如:
- 为任务选择合适的 LLM 模型至关重要,对于日常开发,推荐使用 Anthropic 的 Claude 3.5 Sonnet;对于更深入的架构规划,可以使用 Open AI 的 o1 模型。
- 通过自定义文档和规则,可以让 Cursor 更好地适应项目需求。 添加自定义文档可以提供更好的上下文,而
.cursorrules文件可以帮助标准化团队的代码风格和偏好。
人工智能驱动的社交媒体操纵应用程序有望“重塑现实”
Impact 应用程序被描述为 “数字世界的志愿消防队”,它通过发送推送通知和提供 AI 生成的文本,组织支持者在社交媒体上进行协调性的真实行为,以对抗不真实的信息和操纵行为。
Impact 的工作原理是通过向支持者发送推送通知,指导他们回应特定的社交媒体帖子,并提供 AI 生成的文本以便复制粘贴,从而淹没回复区域以推广特定的政治信息。
国内饭圈粉圈数据女工的利器啊,但是感觉这么做有点危险,肯定会被打击。
如何构建 AI 搜索(第 1 部分)
详细介绍了构建一个类似 Perplexity 的 AI 搜索引擎的步骤,特别是如何通过 LLM(如 Claude)生成相关查询、获取搜索结果、提取内容以及生成带有引文的回答。
作者 Charlie Guo 提出了一个多部分系列的方法,首先将其作为一个无头 Python 脚本来实现,没有 UI。他强调了主要的挑战,包括生成相关的搜索结果和创建准确的引文。
文章中还包含了一系列的 Python 函数示例,用于实现各个组件,如请求搜索结果、生成相关查询、提取 URL 内容以及流式处理 LLM 的响应。
如何合成高质量数据
详细讨论了合成数据的重要性和应用价值,特别是在大型语言模型(LLMs)的训练中。
作者 Nathan Cooper 首先解释了为什么合成数据在 AI 训练中变得重要,即它能够提供无限量、高质量且多样化的训练数据。
文章接着详细介绍了合成数据的关键要素:质量和多样性,并探讨了如何平衡这两个方面,以及如何通过 LLMs 生成具有高质量和多样性的数据集。
还演示了如何使用claudette库来实验这些概念,并通过实例展示了如何生成和评估英语和西班牙语的翻译对。
NotebookLM 是 Google 的 ChatGPT 时刻吗?
海外独角兽翻译的红杉美国的 Pat Grady 和 Sonya Huang ****对 NotebookLM 的核心开发团队成员的访谈,翻译质量很高,比听效率高点,原始视频在这里。
团队成员除了讨论 NotebookLM 的诞生背景、关键技术原理外,也分享了他们观察到的 NotebookLM 的 一系列 use case。关于如何打造一款 AI- native 产品,NotebookLM 团队也有着有趣的理解:
- 上下文是 LLM 交互的一个重要特点,只有基于上下文才能创造粘性极高的用户体验;
- 今天 AI 应用的开发处于“拟物化”的阶段,和 iOS 早期一样,这是因为还有大量用户才刚开始接触到 AI,开发者需要通过用户熟悉交互或者场景来让他们习惯和 AI 互动;
- Claude Artifacts 的动态 UI 也许是 AI 交互的未来形态之一。
能源与人类的富足
这份文档太好了,看完就能对目前的能源领域的所有知识有个大概的了解,行文精炼简洁逻辑清晰,即使学习写作技巧也很好。
随着 AI 算力需求的增加,核心的制约从硬件能力已经过渡到了能源层面。谷歌和微软最近都在购买或者新建专门用于算力中心的小型或者中型核电站。
adammaj 整理了一份分享详细的文档,涵盖了能源领域你需要了解的所有东西。深入探讨和了解能源行业将如何定义我们的未来。
人工智能开发者的两难选择:专有人工智能与开源生态系统
AI 开发者在选择集成 AI 到业务时面临的主要挑战是选择大型专有模型还是开源生态系统,文章探讨了这两种方法的优缺点以及它们对企业部署 AI 解决方案的影响。
还探讨了数据检索和生成的方式,包括模型内存中的生成和基于检索的生成,以及它们对企业级 GenAI 部署的重要性。
在执行环境的选择上,企业需要权衡 GaaS 的便捷性与内部管理的安全性和隐私保护,这取决于企业的具体需求和资源。
开始使用 NotebookLM 的 8 个专家提示
Notebook LM 团队成员和作家 Steven Johnson 分享了他使用这个工具的 8 个专家提示。
有的方法还挺好的,比如按项目把所有需要的内容都给他整理,或者跟它沟通完后让他生成总结整理到另一个笔记本,甚至把最近的十个不相关内容上传给他然后提出问题询问他们的关联。
Runway CEO 关于组织的分类
Runway CEO 把组织分成了两部分,知识寻求型(KSO)和优化寻求型组织(OSO)。
在特定行业(OSO)这种组织形式是必须的,比如一些低利润行业,有明确的流程和分工,相对固化。
但是在发展迅速、行业早期(KSO)组织会取得相对好的结果,这也是为什么 AI 领域大厂手握那么多资源,但取得的结果却跟自己的资源不匹配的原因。
我在两个星期内研究了LLMs:一个全面的路线图
作者通过自己的学习经历,提供了一个详细的大型语言模型(LLMs)学习路线图,从基础到高级层面涵盖了两周的学习内容。
强调了理解 LLMs 的重要性,并介绍了他的学习材料和资源。学习材料包括从头构建 LLMs、LLMs 幻觉现象以及超越注意力机制的高级技术。
还在 GitHub 上创建了一个名为ml-retreat的仓库,收集了所有学习材料。
重点研究 ✦
Anthropic:前沿模型的破坏评估
Anthropic 的新研究,如果人工智能模型试图误导我们,或者秘密破坏任务,它们能在多大程度上做到这一点?
他们的研究结果是目前破坏性不大,只需要极小的措施就能解决。主要评估方向有:人类决策破坏、代码破坏、隐藏真实能力(Sandbagging)和渎职监管。
Janus 解耦视觉编码,实现统一的多模态理解和生成
DeepSeek 开始搞多模态了。开源了一个多模态理解和生成一体的模型 Janus,既可以理解图片内容又可以生成图片。
Janus的核心创新是将视觉编码分为两个独立的部分:一个用于多模态理解,一个用于图像生成。
这种解耦设计可以缓解理解和生成任务对视觉编码器的不同需求所带来的冲突,从而在两种任务上都实现更好的性能。它采用统一的自回归变换器架构来处理不同模态的输入。
ComfyGen: 文本到图像生成的提示自适应工作流程
感觉用 LLM 帮助生成 ComfyUI 工作流确实是一个很好的方式。
ComfyGen 这个项目就利用 LLM 来生成对应的 Comfyui 工作流调用各种工具改善图像生成质量。
他们用了两种方法一种是通过 RAG 让 LLM 生成工作流的时候调取这些知识。
另一种是通过微调的方式让 LLM 学会相关的内容。
不过可惜的是他们这个项目只能用来搞定提高图像质量的工作流,不能实现其他功能。
TANGO:通过音频内容生成对应的人物肢体运动视频
我们有开源的 Heygen 可以用了?目前开源的HeyGen类似项目基本都支持面部和唇形同步,不支持更大范围的肢体运动。
TANGO 这个项目只需要提供几十秒的肢体运动视频,就可以无限生成匹配对应音频的全身视频。再搭配上一些唇形同步开源项目比如快手的LivePortrait,完美复刻HeyGen不是梦想。
Hallo2:长时间、高分辨率音频驱动的人像视频
Hallo2 是一个先进的音频驱动的肖像动画生成系统,它能够接受高达 1024x1024 分辨率的图像输入,并通过音频信号生成连续的图像动画,可以输出4K,最长 1 小时的视频。
该系统采用了一种新型的网络结构设计,能够有效地处理长时间序列的数据,并且生成的动画具有高度的自然性和流畅性。此外,Hallo2 还在保持高分辨率的同时,提升了处理速度,使得实时应用成为可能。
你可以在这里找到我:
| 即刻 | 推特 | Quail订阅 | 微信公众号:歸藏的AI工具箱 |邮箱:[email protected] | 微信号:op7418
也可以分享给更多的朋友,让大家都有机会了解这些内容,扫描下面右侧二维码加我好友,我拉你进会员交流群。