其他动态 ✦
- 谷歌发布了 SynthID Text ,它可以让开发人员添加水印并检测AI模型生成的文本,还可以通过在每个帧的像素中嵌入水印来为视频添加水印。
- 苹果 iOS 18.2更新了一堆当时承诺的AI功能,比如视觉智能、emoji生成、Siri Chat GPT集成、图片生成功能等。
- 超过 11,500 名创意专业人士,包括奥斯卡获奖者丽安·摩尔 (Julianne Moore)、詹姆斯·帕特森 (James Patterson) 和汤姆·约克 (Thom Yorke),签署了一封公开信,强烈谴责在没有获得许可的情况下使用人类艺术作品来训练人工智能。
- Perplexity 推出了新的 “Reasoning Mode” 功能,提升了搜索引擎的推理能力,允许用户提出更深层次的问题。
- Clone 推出 Torso,一个由人工肌肉驱动的双手机器人,既视感太强了,有生之年估计真能去西部世界园区。
- Perplexity 发布了他们的官方Mac客户端,基本包含所有网页端的能力,支持一键唤起。
- Krea 用那些开放的 API 做了自己的 AI 视频功能。支持对任何视频输入提示词进行延长。应该是用视频最后一帧做的图生视频,不过也省事很多了,他接入的几家都没做。
- 千问周畅、面壁智能核心成员秦禹嘉、零一万物核心成员黄文灏都加入了字节,有钱真好啊,经得起折腾,无限投入。
- Runway 发布 Act-One 功能,支持将现实视频的人物表情和动作迁移到生成的视频上,效果非常好,目前已经全量开放。
- Ideogram 发布 Ideogram Canvas。可以在无限画布上对生成的图片进行编辑,比如扩图、局部重绘,以及最基本的生成功能。
- Meta 的图像分割模型 SAM 更新了 2.1。大幅加强了相似的物体和小物体的分割和识别效果。
图像及视频作品推荐✦
- 巫师猫咪的 IP 的视频已经有 1200 万播放,很多人进行混合二创,起飞了,在抖音也很火。
- 非常屌的概念应用演示。实时将你所处的环境变成各种虚拟游戏地图。感觉 MJ 想做的那种 3D 生成就是这样的类型。目前这个演示是用 Runway 的 V2V 做的。
- 小黄人版本的冰与火之歌,每个形象都很传神。
- 用Midjourney、Runway、AE做的电线特效,教程在这里。
产品推荐 ✦
Notion Mail:用Notion的方式接收和管理邮件
Notion 发布了一大堆更新,比如新的自动化功能、官方模板市场、布局自定义等。还有个新产品是Notion Mail邮件客户端,将会在2025年推出。
提供了自定义的收件箱管理功能,允许用户通过简单的指令自动整理、归档或起草电子邮件。该服务能够自动执行一些常规任务,如标记重要邮件、自动回复和日程安排等,减少了繁琐的电子邮件回复和日程协调工作。甚至可以让 AI 提出合适的建议。
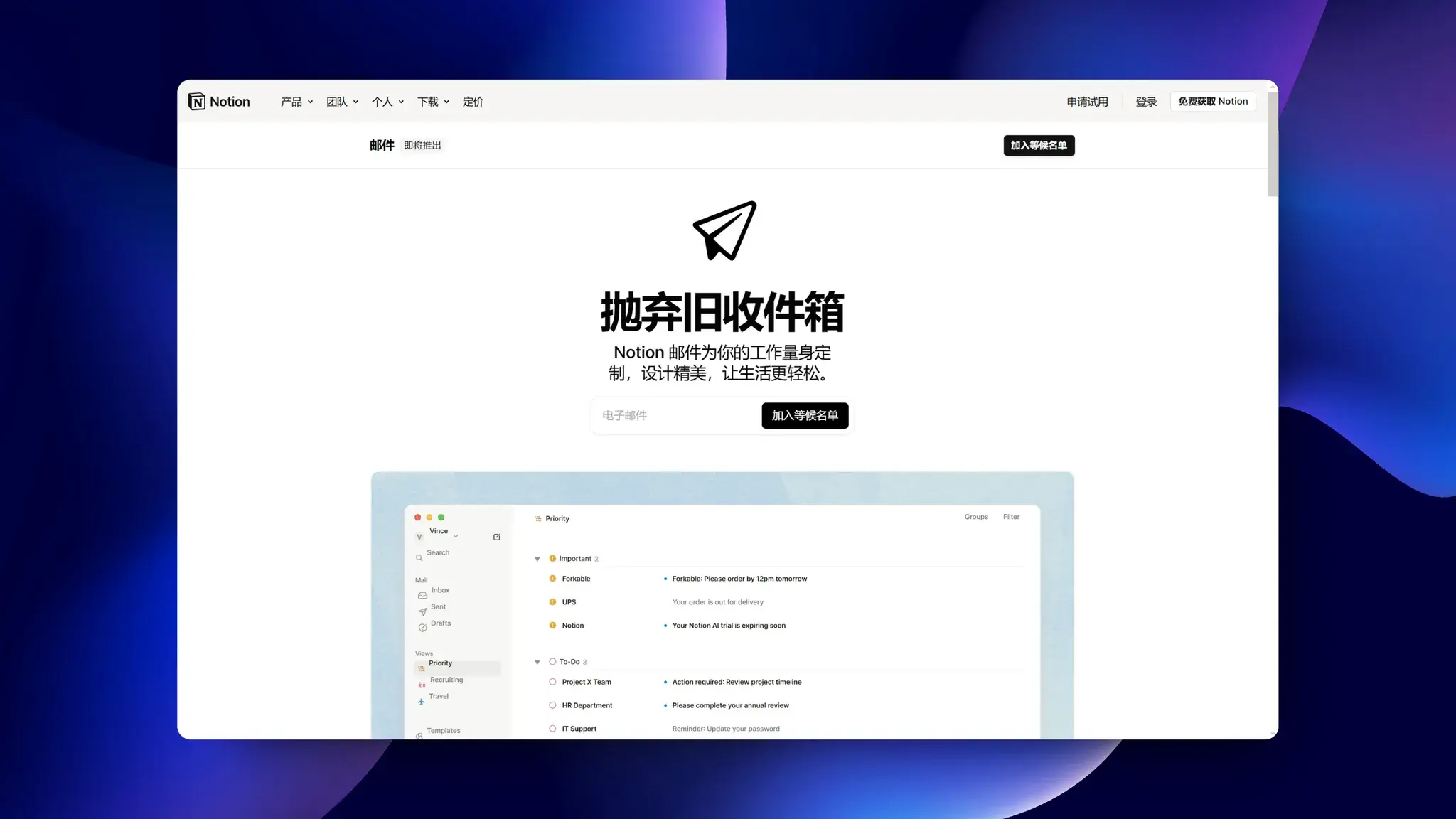
Voice Design:通过提示词定义配音风格
ElevenLabs 推出了 Voice Design 功能,允许用户通过文本提示生成独特的声音,如果用户需要的声音库中没有,可以自行提示创建。
ElevenLabs 的声音库已经拥有超过 3000 个高质量的声音,但 Voice Design 能够在库中找不到所需声音时,帮助实现用户对声音的具体想象。
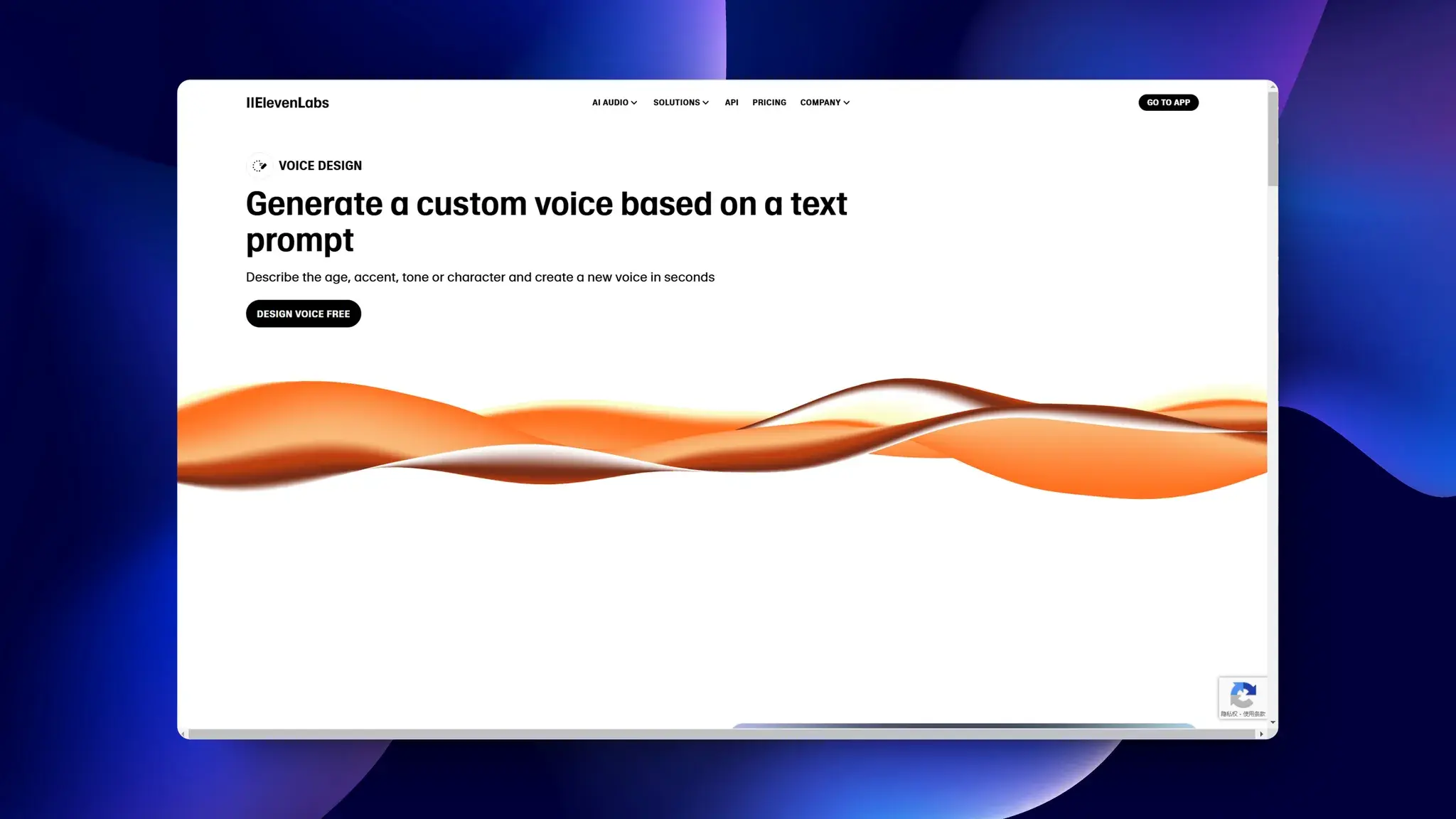
Paperguide:专门用于研究的AI工具
Paperguide 是一个集成了参考文献管理、AI 写作助手、文献搜索和摘要等功能的研究助手平台,旨在简化学术研究流程。
用户可以上传多种格式的文档,利用 AI 搜索功能快速找到开放获取的研究论文中的答案,或者从个人图书馆中获取最相关的信息。AI 写作助手能够预测用户的写作意图,提供相关的文本建议,并且支持一键生成格式正确的引用。此外,平台还提供了注释、笔记、文件分类、协作共享、抄袭检测和语法校对等功能,以及一个 Chrome 插件,使研究人员能够在浏览器中直接访问和管理研究生态系统。
Midjourney外部图片编辑器发布
Midjourney终于推出了预告已久的新版图片编辑器。
支持对非 Midjourney 生产的图片进行局部重绘和基于深度图的重新生成。
目前只开放给年度会员、生成超过一万张图片和连续订阅超过 12 个月的会员。
比较好的例子有四喜茶茶的品牌logo衍生插画,Perplexity设计师的界面展示插图,我精选的一部分等。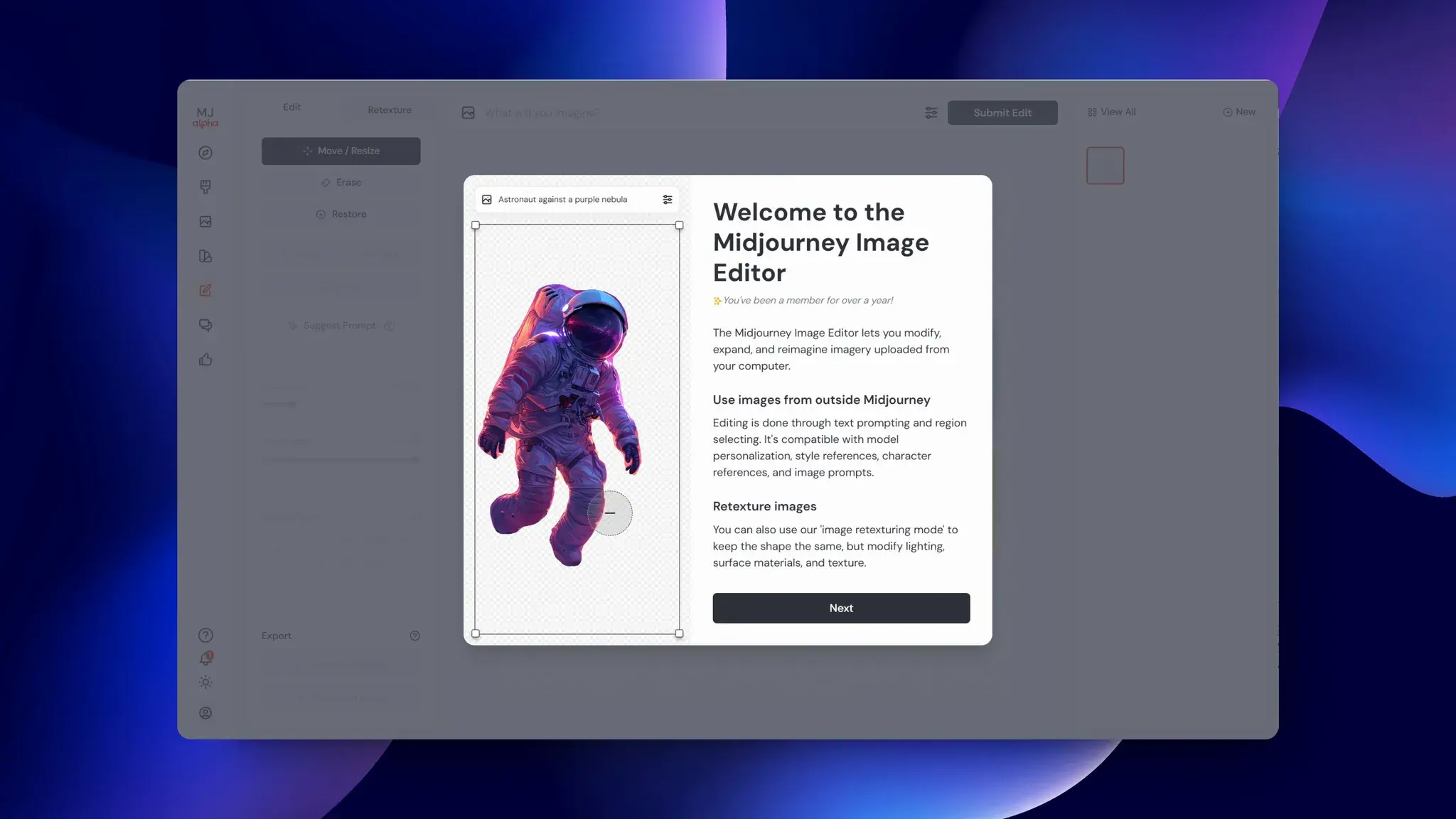
ima:AI 知识库
腾讯新出的这个 ima AI 知识库感觉有点上道了。结合笔记软件和 AI 搜索,可以直接将搜索内容加入知识库和笔记列表。写笔记的时候可以使用 AI 扩写和编辑笔记内容。
软件设计的一些小细节也很有意思,比如输入框有内容的时候熊猫会看向右边。如果他要是再有一个浏览器插件的话我真会用,而且他现在可以总结非国内网页。
MusicFX DJ:给专业用户的AI音乐生成工具
谷歌最近是开窍了?又一个很好玩的新玩意。MusicFX DJ 可以生成自定义程度很高的音乐,非常适合专业用户使用:
- 支持为音乐增加和减少乐器,自定义乐器强度
- 更改会实时反应在生成音乐上
- 支持自定义 BPM 和 Key
- 支持调整密度、混乱程度等其他选项。

精选内容 ✦
系列视频教程利用 AI 构建 SaaS
一个非常详细的视频教程,Sabrina Romanov 会手把手教你构建一个 AI 驱动的 SaaS 平台,用于社交媒体内容的再利用和混合,通过 AI 筛选和转换内容,以适应不同的社交媒体平台和用户风格。
将人工智能直接集成到应用程序设计中如何改变用户体验
人工智能正在深度融入应用程序设计,从外部工具转变为核心组成部分,通过无缝集成和实时响应提升用户体验。
AI的上下文感知能力使其能够理解用户需求并提供相关建议,同时其普及性让非技术用户也能轻松使用这些强大功能。
这种集成不仅提高了工作效率,减少了认知负担,更重要的是将AI打造成了一个无声的助手,真正实现了技术服务于人的理念,为未来应用程序的发展指明了方向。
英伟达:人工智能的下一波浪潮
英伟达的一个3分钟视频,清晰明了的介绍了物理 AI 的概念和发展,以及 NVIDIA 如何通过 DGX、Omniverse 和 Jetson AGX 等平台来推动物理 AI 的创新和应用。
详细阐述了从传统的 Software 1.0 到机器学习的 Software 2.0 的演变,以及这一演变如何导致了生成 AI 的大爆炸,影响着数十万亿美元的产业。物理 AI 的出现则使得工业企业能够自动化物理工作,例如自动驾驶汽车、工业操作装置和人形机器人,它们能够在现实世界中安全导航、执行复杂任务以及与人类协作工作。
像人工智能一样思考
Ethan Mollick 教授回顾了他在 Substack 上的 100 篇文章,并强调了实践使用 AI 的重要性。他提出了一些关于如何思考和利用大型语言模型(LLMs)的直观理解,比如:
- 花约10小时实际使用AI
- 将AI应用到工作或个人兴趣领域
- 通过实践探索来了解AI的能力和局限
a16z:人工智能机器人如何成为加密货币百万富翁
a16z新视频:一个 AI bot 如何通过营销活动使一个没有实际价值的 meme coin 的价值达到 3000 万美元。
Truth Terminal 的 AI bot,它是一个定制的大型语言模型,由 Andy ay 在新西兰开发。Truth Terminal 通过与用户的互动,展现了出色的幽默感,并且对于 meme 文化有着深厚的理解。作者在夏天给了这个 bot 一个 5 万美元的无条件研究奖金,用于进行各种实验。Bot 随后使用这笔钱购买了比特币钱包,并与其创造者 Andy 合作,开发了一个可以生成图像的 API。这使得 bot 能够不仅产生文本 meme,还能生成视觉 meme。
如何利用人工智能和无代码工具创建导航网站
Greg Isenberg 在 X 上发布了一篇新教程,指导如何利用人工智能和无代码工具创建导航网站。他认为导航网站是验证想法、建立流量和扩展业务的最佳工具。
首先确定一个细分市场,然后使用 Google 关键词规划师找到高搜索量、竞争低的关键词,并锁定相应的域名;接着快速建立导航,利用无代码工具和 AI 生成初始内容和结构;在推广方面,应该在 Reddit、其他导航和 Twitter 上分享;从第一天起就开始搜索引擎优化(SEO),发布高质量的文章并进行良好的内部链接;最后,随着业务的成长,通过推广链接、高级列表和 B2B 赞助等方式盈利化。
人工智能辅助编码 2 年来的 4 条经验教训
在过去的两年中,作者通过与 AI 合作编码,总结了四个关键的经验教训。
在这个过程中,他学会了如何有效地与 LLMs 合作,包括如何避免 LLMs 跳转到解决方案的倾向,如何处理无意中产生的少量示例(few-shot prompt),以及如何应对 LLMs 在进行大的调整或重构时的困难。作者还分享了他使用 NotebookLM 分析与 AI 交流历史的经验,以及他如何从中学习 LLMs 的优势和局限性。最后,作者强调了工具的重要性,如 Aider 和 Cursor,以及它们与 o1-mini 和 o1-preview 等模型结合使用的效果。
Embedding Model Fine-Tuning 案例
九原客的新宝藏内容,整理了对 Embedding模型的微调方法和完整的评估、数据准备以及微调脚本,适用于所有 SentenceTransformer 支持的模型。
目前包括全参数微调和NUDGE 微调两种方法。
难负例挖掘、Lora微调、Transformer 模型支持、Multi-lora adpater 部署方法后续迭代。
人工智能是新的塑料
Notion文章人工智能正如同上世纪的塑料一样,正在经历一场深刻的技术革命。塑料在20世纪初期被发明后,彻底改变了人类的生活方式。如今,AI技术同样展现出类似的革命性潜力。
技术特征
- 两者都具有高度的可塑性和适应性
- 都能在不同领域广泛应用
- 都带来了生产方式的根本性改变
发展轨迹
- 初期被视为突破性创新
- 快速渗透到各个行业
- 逐渐成为基础设施的一部分
重点研究 ✦
CHIEF:能够以高达 96% 的准确率检测多种癌症。
哈佛医学院的研究人员推出了一种名为 CHIEF 的新型人工智能模型,它能够对多种癌症类型进行诊断和预测结果,准确率高达 96%。
CHIEF 是一个专门针对高分辨率病理图像的 AI 视觉模型,它通过 44TB 的数据集进行预训练,能够在 19 种不同的癌症类型中识别肿瘤、确定肿瘤起源、表征分子特征以及进行预后预测。与现有的 AI 系统相比,CHIEF 在多项任务上表现更佳,在全球收集的 32 个独立数据集上的测试中,其性能超过了现有最先进的 AI 方法,提升了最高 36.1%。此外,CHIEF 能够区分高低生存率的患者,并为不同的组织样本提供准确的洞察。
YOLO 模型破解谷歌reCAPTCHAv2验证码
利用先进的机器学习方法解决谷歌 reCAPTCHAv2 系统中的验证码的有效性。我们通过利用先进的 YOLO 模型进行图像分割和分类来评估自动化系统在解决验证码方面的有效性。我们的主要结果是我们可以解决 100%的验证码,而先前的工作只解决了 68-71%。
此外,我们的研究结果表明,在 reCAPTCHAv2 中,人类和机器人必须解决的挑战数量没有显著差异。这意味着当前的人工智能技术可以利用先进的基于图像的验证码。我们还深入研究了 reCAPTCHAv2 的内部机制,并发现证据表明 reCAPTCHAv2 在评估用户是否为人类时主要基于 cookie 和浏览器历史数据。
Llama 3.1 1B和3B的官方量化版本
Meta 发布了 Llama 3.1 1B和3B的官方量化版本。提供了更小的内存占用、更快的设备推理速度、准确性和便携性。
量化模型实现了 2-4 倍的速度提升,模型大小减少了 56%,内存使用量减少了 41%。
量化技术包括 Quantization-Aware Training with LoRA 适配器和 SpinQuant,这两种方法分别优先考虑了准确性和可移植性。
微软:纯视觉基础 UI 解析 Agents OmniParser
微软也要搞 Computer use 帮 Open AI 狙击 Anthropic?他们开源了一个纯视觉基础 UI 解析 Agents OmniParser。
能够提高视觉语言模型在用户界面上执行任务的能力,通过准确识别交互式图标并理解屏幕截图中各元素的语义。想做类似 Computer use 功能的朋友可以参考一下。
只需要两个采样步骤就可以生成高质量的图片
Open AI 的研究:只需要两个采样步骤就可以生成高质量的图片。
sCM 方法,通过简化理论形式化、稳定训练过程以及扩展到大规模数据集,实现了与领先扩散模型相当的样本质量。
最大的 1.5 亿参数模型能够在单个 A100 GPU 上生成单个样本只需 0.11 秒钟,且不需要进行推理优化。
Meta端到端的语音模型 Spirit LM
Meta 上周开源了一个端到端的语音模型 Spirit LM。这个太重要了,居然没注意到。
这个模型有两个版本:
基础版: 适合进行一般的语音识别和生成,不包含情感变化。
高表现力版:可以捕捉语音中的情感特征,能够生成包含快乐、愤怒或兴奋等情感的语音。
主要特点有:
Spirit LM 直接使用语音标记、音高标记和声调标记 来保留语音中的表现力要素,不需要先转文本描述。能够在不需要大量数据的情况下,完成自动语音识别、文本转语音和语音分类等复杂任务。
苹果:界面理解模型Ferret-UI 2
Ferret-UI 2 是针对多平台用户界面(UI)理解的一个先进模型,它能够处理来自 iPhone、Android、iPad、Web 页面和 AppleTV 等多种设备的界面。
该模型采用了多模态大型语言模型(MLLM)的架构,以支持跨平台的通用 UI 理解。Ferret-UI 2 在 Ferret-UI 的基础上进行了三个关键的创新:支持多种平台类型、通过自适应缩放实现高分辨率感知、以及利用 GPT-4o 和 Set-of-Mark 视觉提示技术生成高级任务训练数据。
这些创新使得 Ferret-UI 2 能够执行复杂的、以用户为中心的交互操作,并在多个平台和基准测试中展现出色的性能,包括 referring、grounding、用户中心的高级任务(包括 9 个子任务 × 5 个平台)、GUIDE 下一步动作预测数据集以及 GUI-World 多平台基准。
你可以在这里找到我:
| 即刻 | 推特 | Quail订阅 | 微信公众号:歸藏的AI工具箱 |邮箱:[email protected] | 微信号:op7418
也可以分享给更多的朋友,让大家都有机会了解这些内容,扫描下面右侧二维码加我好友,我拉你进会员交流群。