其他动态 ✦
- 可灵推出官方 Comfyui 插件,需要可灵API才能使用,支持文生图、图生图、虚拟试穿、图片生成,另外可灵网页版也上了虚拟试穿。
- Recraft V3 模型有了 API 以后也发了官方的插件,支持生成、升级、优化和删除背景,在 ComfyUI Manager 中搜索“RecraftAI”。
- Windsurf 支持了图片上传,现在可以让AI根据你的图片规划界面布局和样式了。
- IC-Lignt V2 更新了,更强照明变化和修改。不过依然没有开源只能在 Huggingface 试用。
- Comfyui 官方桌面版本正式向所有人发布!而且是开源的,可以基于这个开发你的客户端。支持有 CUDA 的 Windows 电脑和 M 芯片的 Mac。
- Claude 现在可以自定义输出内容的风格,默认的是简介、解释或者正式。你可以自定义关于输出风格的提示,说出要求 Claude 会帮你优化生成提示词。
- Sora API 上周泄露了,泄露者说自己是参与测试的艺术家,不满Open AI对他们的态度而泄露,不过艺术家可以搭建Huggingface空间提供服务这事挺匪夷所思的。
- 用于 SD3.5 M 的 controlnet 模型发布了,三个模型分别是 Blur、Canny 和 Depth。
- 看来谷歌是要好好搞 NotebookLM 了。有了自己的官网和官方推特,UI 也改版了。而且还可以直接转录 youtube 视频了,左边原始内容,右边聊天界面。
- Runway 居然发布了新的图像模型 Framer。主要优势是稳定的风格还原和简单的风格探索。
- 亚马逊正在开发一种名为“ Olympus ”的多模态模型,专为图像和视频分析而设计,旨在减少对 Anthropic 的 Claude 聊天机器人的依赖。
- xAI 计划最早于 2024 年 12 月推出独立的消费者人工智能应用程序。
- Hugging Face 推出了 SmolVLM,这是一系列小型视觉语言模型,提供三种变体:SmolVLM-Base、SmolVLM-Synthetic 和 SmolVLM-Instruct,仅需要 5.02 GB GPU RAM 即可进行推理,16K上下文。
- 继投资 66 亿美元后,软银将通过 15 亿美元的股票回购计划增加其在 OpenAI 的股份,使 OpenAI 的估值达到 1570 亿美元。
- Cursor 推出了 Composer Agent 0.43 更新,在其代码编辑器中引入了Agents。Agent可以执行终端命令、完成任务、选择上下文并以更高的清晰度和后续性规划项目结构。
图像及视频作品推荐✦
- Perplexity 的黑五宣传片应该是用 AI 做的。在用 AI 制作营销视觉内容上,他们应该是实践最多的公司了。
- Midjourney 和海螺生成的视频,太可爱了。
- 这个 v2v 视频表现力好强。演的也好,转的也好。
- Runway 视频扩展的用处真的很大。3D 渲染一个非常小的视频,然后扩展到很大,非常节约资源。
产品推荐 ✦
ElevenReader:将阅读内容生成对谈播客
音频模型最好的 Eleven Labs 终于做了这个功能。你现在可以在 Elevenreader app 里面将收藏的文档、链接、电子书转换为智能播客。声音相当自然,支持 32 种语言。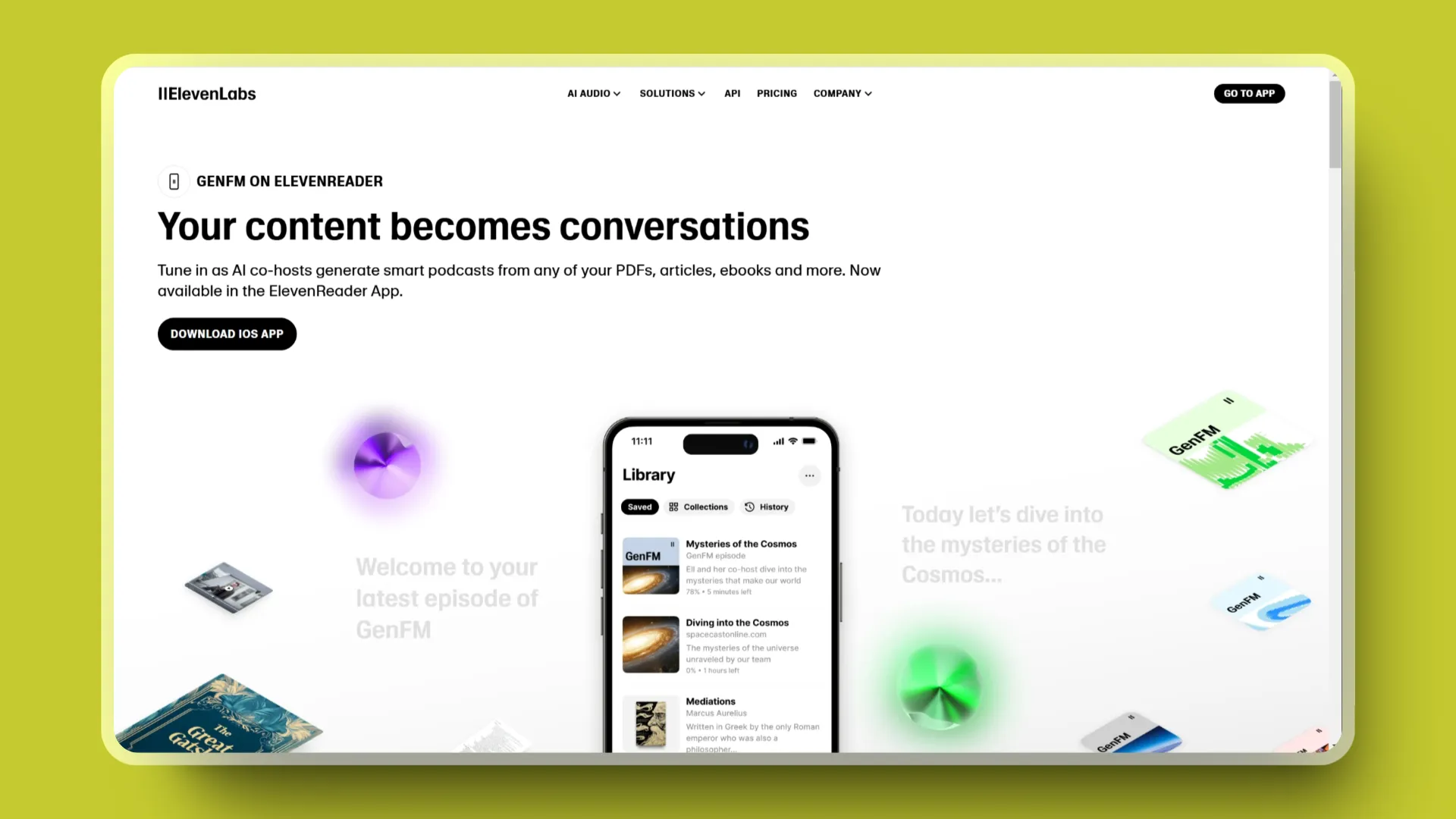
Gen chess:AI国际象棋
谷歌又有新玩意,很有创意的玩法。用提示词生成各种非常好玩的国际象棋棋子,然后跟谷歌的国际象棋 AI 下棋。我不会下瞎玩的,还可以选难度。

Pickle:克隆一个你帮你开会
Pickle 是一个创新的服务,它允许用户通过他们的 AI 克隆在视频通话或会议中保持参与。无论是因为不准备好出镜、在移动中还是需要暂时离开,Pickle 都能让用户的 AI 克隆代表他们出现在视频中。这项技术重新定义了人们连接和交流的方式。

Spiral:帮你生成你自己风格的文本
Spiral 是一个自动化工具,它允许用户将重复性的写作和思考任务自动化,并且能够以用户训练时的风格生成输出。用户可以通过提供示例来训练 Spiral,使其能够匹配所需的语气、风格和结构。Spiral 能够从文本中提取模式,并且可以被用来迭代输出,直到用户满意为止。用户还可以与团队共享他们构建的 Spiral,以提高质量和风格的标准。

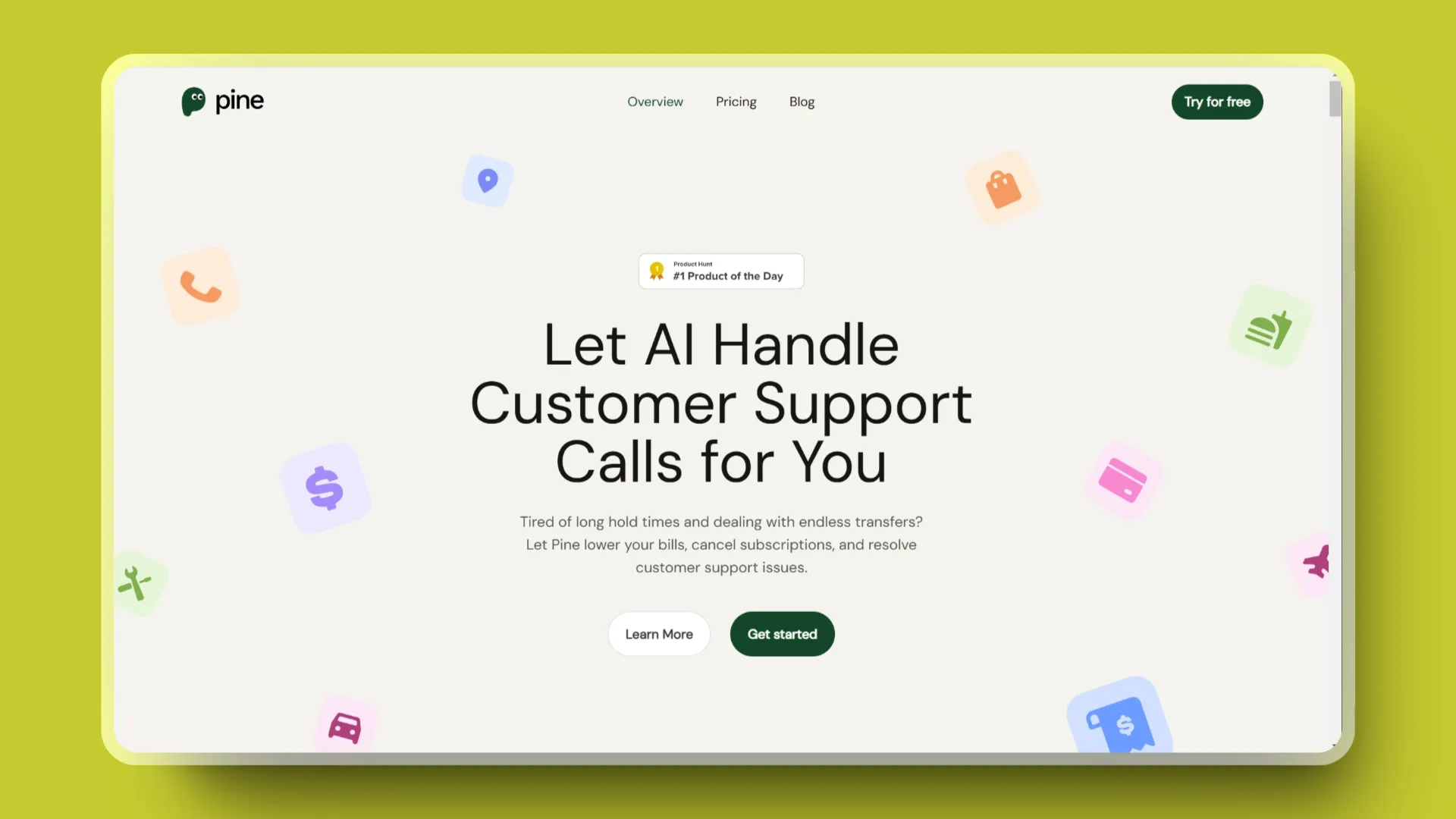
Pine :帮助用户处理订阅内容的助手
Pine 是一个人工智能助手,专门处理账单、订阅服务和客户支持问题,旨在通过 AI 技术节省用户时间,减少烦恼。
- 降低账单:通过 AI 谈判策略,如比较竞争对手的价格和提及忠实顾客身份,来降低电信、有线电视或其他服务的账单。
- 取消订阅:快速结束不再需要的服务。
- 免除费用:帮助用户免除信用卡滞纳金、电信公司费用、酒店度假村费用、银行管理费用等不必要的费用。
- 索赔退款:为任何不满意的购买或体验赢得补偿。
- 分析账单:检查账单中的隐藏费用和不必要的收费。
精选内容 ✦
模型上下文协议 (MCP) 快速入门
Model Context Protocol (MCP) 是 Glama 开发的一种新技术,旨在优化团队中的人工智能协作。MCP 允许多个用户与单一的 AI 模型进行交互,同时保持对话上下文的连贯性。这项技术通过引入用户身份验证和上下文管理,确保了信息的安全性和准确性。MCP 的快速启动指南提供了安装、配置以及最佳实践,帮助团队迅速集成和使用这一协议。通过 MCP,团队成员可以更有效地共享知识,提高工作效率。
使用 Bolt 编码的详细教程
推上一个老哥写了一份使用 Bolt 编码的详细教程。很多技巧很有用,比如在Claude里梳理提示节省Token、关于数据库和API等
无需任何设计或编码经验,为 iOS 构建并设计一款 AI 图像生成器应用程序
Ammaar Reshi 在其个人社交媒体平台上发布了一项实验成果,展示了如何通过与 GPT-4 的互动以及使用编程平台 Replit,在没有任何 JavaScript 编程经验的前提下,仅用不到 20 分钟的时间,成功开发了一个在浏览器中可以运行的贪吃蛇游戏。
Bolt、v0 和 Cursor 这几个 AI 编程工具之间的区别
这个老哥总结了一下 Bolt、v0 和 Cursor 这几个 AI 编程工具之间的区别。
最后的比喻很好:
“虽然 Bolt 和 v0 看起来对初学者很友好,但我还是建议要学习编程!
这些工具就像赌场里的老虎机,一开始会让你尝到甜头,感到兴奋不已。但很快你就会遇到障碍,之后的每一步都会变得异常困难。”
中国大模型生存战:巨头围剿,创业难熬
上周晚点这个文章详细分析了中国大模型行业的竞争格局和发展现状,非常值得看一下。
中国大模型行业正经历巨头与创业公司的激烈竞争。字节跳动在不到12个月内实现了惊人的崛起,豆包App日活达945万,成为中国最大的AI产品,同时成功组建了Flow部门并招募多位行业顶尖人才。
与此同时,创业公司面临严峻挑战。至少5家大模型创业公司出现人员调整,融资环境转冷,在投放和用户留存等方面难以与巨头竞争。阿里和字节采取了不同的战略路线,阿里选择资本战略,大手笔投资月之暗面和MiniMax,而字节则专注于业务战略,快速扩张产品矩阵。
这场竞争本质上是"半熟的技术遇上半新的市场"。技术尚未完全成熟,仍存在创新空间,但市场仍依赖现有移动互联网基础设施。创业公司的出路可能在于专注小众细分市场,或等待巨头战略调整带来的机会。
2024 年的科技赢家和输家: 真正的创新之年和产品全面失败之年
ZDNET 网站的文章详细回顾了 2024 年科技界的亮点与失误。
在失败者名单中,X(原名 Twitter)因 Elon Musk 的管理失误成为自我破坏的典范,亚马逊公司的返回办公室政策导致了人才流失,特斯拉的 Cybertruck 因为多次召回和性能问题成为笑柄,苹果的 Vision Pro 价格昂贵且缺乏杀手级应用,Intel 公司因缺乏创新而逐渐走向边缘,CrowdStrike 的软件更新失误导致全球性的 IT 中断,AI 穿戴设备因为实用性问题未能取得成功,Sonos 的应用更新问题导致了市场表现的下滑。
赢家包括 AI 工具和平台,如 Google 的 Gemma 2 和 OpenAI 的 GPT 系列,它们在各个领域展现了强大的能力,Adobe 的 Firefly 让非设计师也能进行创意工作。NVIDIA 因其 AI 芯片的强劲销量和市场表现成为了年度的佼佼者。开源软件如 LLaMA 3、Falcon 和 Gemma 2 为开发者提供了无障碍的开发环境,ARM 处理器的进步使得苹果的 M4 芯片和高通的 Snapdragon X Elite 芯片在性能和效率上创下了新标准。Bluesky 社交平台因其去中心化模式和用户优先政策而受到欢迎,Matter Protocol 的推出使得智能家居设备的兼容性大大提升,Meta 公司的 Ray-Ban 智能眼镜以其轻便和实用性赢得了市场的认可,苹果的 iPhone 16 因其卓越的硬件性能而成为市场焦点。
人工智能入门:什么是足够好的提示
大多数人在尝试使用AI时存在误区,他们往往将AI当作搜索引擎来使用,仅询问事实性问题[1]。这种使用方式导致他们无法真正发挥AI的潜力,也没有投入必要的10小时左右的时间来真正理解AI的功能。
良好提示的两种方式
- 任务型提示:应该将AI视为一个极具耐心但每次对话都会遗忘前文的新同事。在使用时需要明确任务要求,提供具体背景,并善用AI的无限耐心特性来获取多样化的答案[1]。
- 思维型提示:AI可以作为思维伙伴,通过自然对话的方式与其互动。这种方式特别适合通过语音交互来实现,目前GPT-4和Copilot应用提供了较好的语音模型支持。
最重要的是要实际使用AI至少10个小时,这样才能真正理解AI如何融入工作和生活。不要追求完美,而是从某个起点开始,在使用过程中不断学习和改进[1]。不需要一开始就掌握复杂的提示工程技巧,重点是培养对AI能力的直觉理解。
Sam Altman 的天才笔记方法
YouTube创作者分享了他对 Sam Altman 笔记方法的理解和实践。Sam Altman提倡使用螺旋绑定的小本子进行笔记,因为这样可以轻松撕掉页面,便于整理和回顾想法。他建议使用能够平铺在桌面上的纸张,以及适合书写的好纸张。
介绍了他自己的三本笔记本系统。他使用 Lochby 品牌的口袋笔记本,并将其中的页面索引到 Notion 中。他对笔和笔记本的选择进行了详细的讨论,包括哪些笔适合放入口袋笔记本的螺旋绑。
内容创作者还展示了他如何使用 Sam Altman 的笔记方法,包括如何选择笔记本和笔,以及如何使用和整理笔记。
重点研究 ✦
CAT4D:利用多视角视频扩散模型创建 4D 中的任何内容
谷歌项目,给一个视频就生成多角度的 3D 运镜视频。最强的是他们的项目页面支持实时渲染演示。
CAT4D 项目旨在通过多视角视频扩散模型从单目视频生成多视角视频,并利用这些视频重建动态的 3D 场景。该技术能够在浏览器中实时渲染 4D 场景,允许用户通过 Brush 平台进行交互式体验。CAT4D 的核心是能够区分相机和场景运动控制的多视角视频扩散模型,它可以生成三种类型的输出序列:固定视角变化时间、变化视角固定时间、以及同时变化视角和时间。
Qwen2vl-Flux:用Qwen增强FLUX提示词理解
Qwen2vl-Flux 这个模型用 Qwen2VL 替换了 FLUX 中的 T5 模型。让 FLUX 的多模态图像理解,和提示词理解变得很强。
- 无文本图像直接基于图像生成图像
- 类似 IPA 将图片和文字结合生成对应风格的图片
- GridDot控制面板,细致的风格提取
- ControlNet 集成,支持 Depth 和 canny
OminiControl 新的 FLUX 通用控制模型
OminiControl 是一个公开的项目,旨在为 FLUX.1 扩散变换器提供一个简洁而通用的控制器。
可以一个模型实现图像主题控制和深度控制。这个图像控制看起来效果很好,一个提示词加一个服装图片就能让生成的人物穿上服装。或者实现将图片中的物品放到生成图片的指定位置。
NVIDIA 推出 Fugatto AI 音频生成模型
NVIDIA 的新生成 AI 模型 Fugatto(Foundational Generative Audio Transformer Opus 1)能够通过文本和音频作为输入,创建或转换任何类型的音乐、声音和声音效果。这个模型不仅能够根据文本提示创建音乐片段、从现有歌曲中添加或移除乐器、改变语音的口音或情感,甚至能够产生从未听过的新声音。Fugatto 的创造者希望这个模型能够像人类一样理解和生成声音,它展现了新的 AI 模型应用,如快速原型设计、音乐编辑、广告语言定制、语言学习工具个性化、视频游戏音效动态调整等。Fugatto 使用了 ComposableART 技术,允许用户在推理过程中组合不同的指令,并通过时间插值和属性控制来精细地控制声音的生成和变化。
英伟达发布 Edify 3D 生成模型
终于有可以直接生成 3D 场景的模型了。英伟达发布 Edify 3D 生成模型。可以利用 Agents 自动判断提示词场景中需要的模型,生成后将他们组合为一个场景。
Edify 3D 可以在两分钟内生成详细的、可用于生产的 3D 资源、生成有组织的 UV 贴图、4K 纹理和 PBR 材质。
Agent-as-a-Judge:评估智能体性能
这篇论文介绍了一个名为"Agent-as-a-Judge"的新框架,用于评估智能体系统的性能[1]。传统的评估方法要么只关注最终结果而忽略了智能体系统的逐步性质,要么需要大量人工劳动。该框架通过让智能体系统来评估智能体系统,为整个任务解决过程提供中间反馈。
作者将该框架应用于代码生成任务,并提出了一个名为DevAI的新基准测试集,包含55个真实的AI开发任务,配有365个层次化需求。他们使用该基准测试对三个主流的开源代码生成智能体框架进行了评估,发现Agent-as-a-Judge的表现显著优于LLM-as-a-Judge,并且与人工评估基准相当。
实验结果表明,Agent-as-a-Judge与人类评估者的一致性达到90%以上,而LLM-as-a-Judge仅为70%。此外,考虑到评估成本,Agent-as-a-Judge相比于三位人类专家可以节省97.72%的时间和97.64%的成本。这项研究为现代智能体系统的评估提供了一个具体的进步方向,为动态和可扩展的自我改进提供了必要的反馈信号。
Moirai-MoE 时间序列基础模型
这篇论文提出了一个名为Moirai-MoE的时间序列基础模型。研究指出,现有的时间序列基础模型虽然在零样本预测方面表现出色,但在统一训练方面仍面临挑战。传统方法如Moirai和TimesFM都采用基于频率的模型专门化方法,这种方法存在明显的局限性。
论文指出了现有基于频率专门化方法的两个主要缺陷:首先,频率并不能可靠地指示时间序列的潜在模式,因为不同频率的时间序列可能显示相似的模式,而相同频率的时间序列可能表现出不同的模式;其次,由于时间序列的非平稳性,即使在单个时间序列的短期上下文窗口内也会出现不同的分布,而频率层面的专门化过于粗糙,无法捕捉这种多样性。
为解决这些问题,Moirai-MoE采用了单一的输入/输出投影层,并将不同时间序列模式的建模任务委托给Transformer中的稀疏专家混合(MoE)。这种设计减少了对人为定义启发式的依赖,实现了自动的token级别专门化。在39个数据集上的大量实验表明,Moirai-MoE在分布内和零样本场景下都优于现有的基础模型。
你可以在这里找到我:
| 即刻 | 推特 | Quail订阅 | 微信公众号:歸藏的AI工具箱 |邮箱:[email protected] | 微信号:op7418
也可以分享给更多的朋友,让大家都有机会了解这些内容,扫描下面右侧二维码加我好友,我拉你进会员交流群。