封面提示词:A close-up motion of a vibrant butterfly. The wings are dynamic and flowing. The center of the butterfly glows creating a striking contrast. The background is a light color, 4k --ar 16:9 --profile 8rbojvx
现在的播客版本用 Listenhub 的 FlowSpeech 能力生成,信息丢失和废话问题少了很多:
https://listenhub.ai/episode/u/6899642c303dea6e06647165
上周精选✦
Open AI 发布 GPT-oss 开源模型和 GPT-5
首先是周五凌晨发布了大家期待很久的 GPT-5,虽然整个由于之前的泄露、发布初期的问题以及大家的高预期导致很多人认为 Open AI 拉了,但是能在一天完成向数十亿用户提供新的模型服务这个能力还是相当可怕的。
他们这次面向 ChatGPT 用户和面向开发者的模型是分开的。
面向 ChatGPT 的话用户只能看到三个模型 GPT-5、GPT-5 Thinking 以及 GPT-Pro,其中 Pro 模型 Pro 用户才能用。
跟之前宣传的一样主打“统一系统”架构,集成了智能高效模型、深度推理模型(GPT-5 Thinking)和实时路由器。它能根据对话类型、复杂度、工具需求和用户意图自动选择最合适的模型,显著提升了响应的准确性和效率,第一天大家觉得 GPT-5 也是这个路由的原因,Sam 说这玩意坏了,很多时候没有切换 Thinking 模型。
面向开发者的话提供了gpt-5、gpt-5-mini、gpt-5-nano 三个版本,便于在性能、成本、延迟间权衡。最大支持 272K 个输入和 128K 个输出,总上下文 400K,支持流式处理、结构化输出、并行工具调用、提示缓存等能力。
这次的 GPT-5 代码能力终于达到了可用的级别,这里是我的测试,如果不是受限于 ChatGPT 里面可怜的上下文长度,可能表现还要再好一些。
首次发布遇到了一堆问题,比如刚才说的路由问题,还有额度问题,还有很多人不满意 Open AI 强制下线就模型的问题,Sam 都做了解释和制定了修复措施,比如现在所有人都能在设置开启旧版模型的访问了。
还为了摆脱 Closed AI 的名头发布了两个开源模型,分别是 gpt-oss-120b 和 gpt-oss-20b。
Gpt-oss-120b 测试基准与 OpenAI o4-mini 几乎持平,能在单个 80GB GPU 上高效运行。Gpt-oss-20b 测试基准与 OpenAI o3‑mini 差不多,可在 16GB 内存的设备上运行。
预训练阶段,gpt-oss-120b 和 gpt-oss-20b 使用高质量、以英文为主的纯文本数据集,重点覆盖 STEM、编程和通用知识领域。数据 Token 化采用了 OpenAI o4-mini 和 GPT-4o 所用 Token 化器的超集(o200k_harmony),以提升模型对多样化内容的理解能力。模型架构方面,每个模型都是 Transformer,并采用专家混合(MoE)技术,减少每次处理输入时所需的活跃参数数量,从而提升推理和内存效率。位置编码使用旋转位置嵌入(RoPE),原生支持长达 128k 的上下文长度。
后训练阶段,流程与 O4-mini 类似,包含监督式微调和高计算量强化学习。目标是让模型符合《OpenAI 模型规范》,并具备思维链(CoT)推理和工具使用能力。
这次 Open AI 可以说是把戏做足了,提供了专门用来预览两个模型的网页,如果你不想本地部署可以试试。两个模型的所有相关资源、模型微调指南、

谷歌发布 Genie 3 世界模型
相较于 GPT-5 可能更令我兴奋的是谷歌新的世界模型 Genie 3,这次生成时长和分辨率都很给力,而且还支持通过文本动态改变世界事件,这搭配一个 LLM 不就妥妥的 AI 游戏吗,能以 24 帧每秒的速度生成,分辨率高达 720P,支持超过几分钟保持环境一致性。
- 模型能模拟自然现象,并展现真实世界的物理特性。
- 支持跨越地理和时间界限,生成如阿尔卑斯山、威尼斯、古希腊等多样场景,通过自回归方式逐帧生成,
- 能在几分钟内保持环境物体和细节的一致性,视觉记忆最长可达一分钟。
- 不仅支持导航,还能通过文本 prompt 动态改变世界事件。
- 可为 AI 智能体(如 SIMA agent)生成丰富环境,支持复杂目标的达成和长期任务训练。
如果一个场景的记忆能达到十几分钟的话完全可以做游戏了,一个线性单机流程十几分钟一个场景也是可以的,而且这个自定义程度更高。可以看看他们这个演示,注意脚踩到水的时候。
另外谷歌给 Gemini 也增加了两个功能:
引导式学习:类似上周 ChatGPT 那个学习模式,通过探索性和开放性问题鼓励参与,而且引导式学习还会提供丰富、多模态的回复——包括图片、图表、视频和互动测验。
故事书模式:可以根据你的提示词创建图文并茂的故事书,每个都是 10 页内容,还能朗读,不过朗读只支持英语。

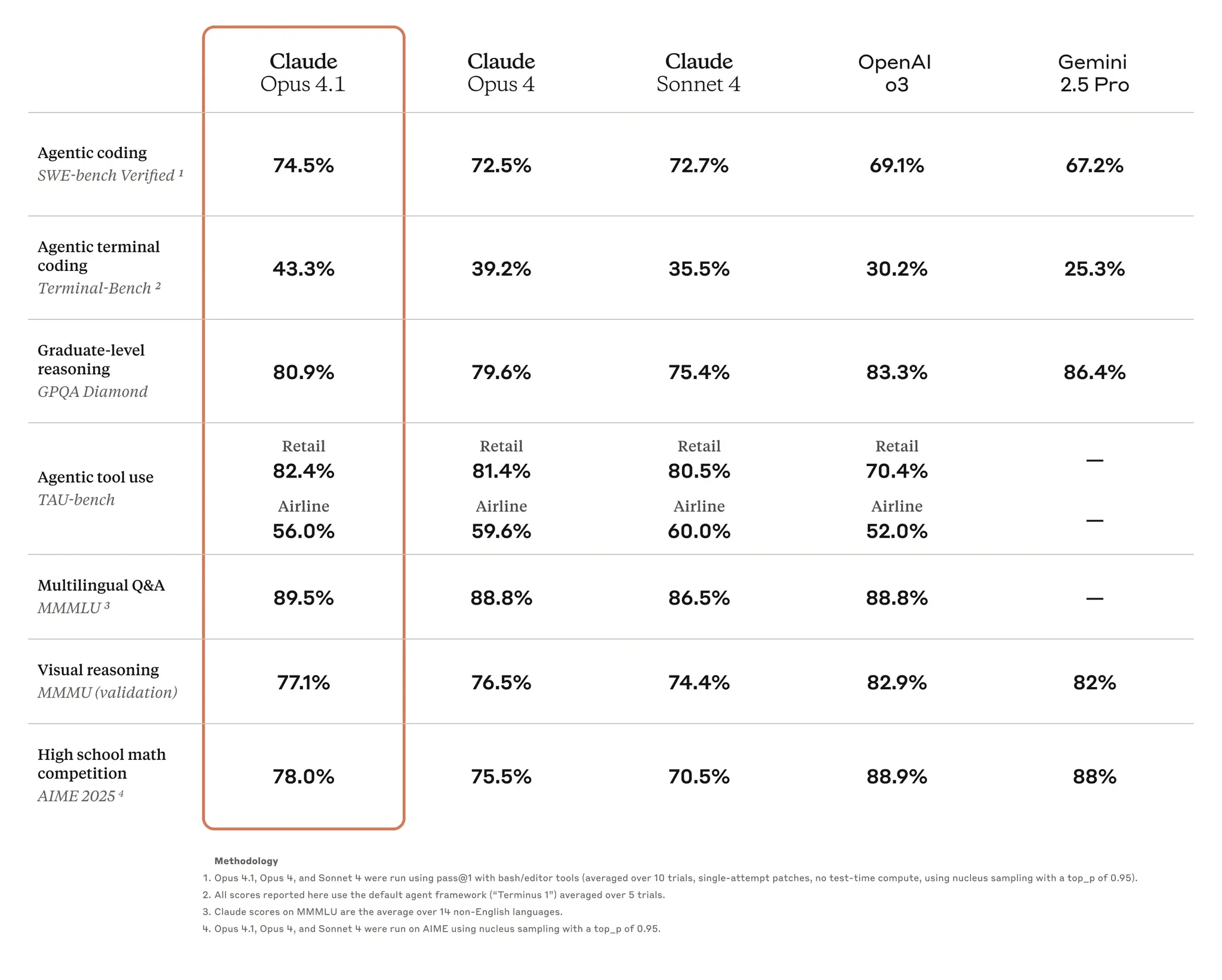
Claude 发布 Claude opus 4.1
Anthropic 整了个 Claude 4.1 出来,官方的说明是这是 Claude Opus 4 在 Agent 任务、实际编码和推理方面的升级。价格和 opus 4 一致。很多人反馈说升级 4.1 以后速度变快了,感觉是为了应对暴增的需求对模型进行了一些操作降低推理成本。
Claude Code 也进行了一些更新:
首先是“可自定义状态栏”功能,允许用户在终端中自由设置和显示各种实时信息。只需输入 /statusline 加上你想要的状态描述,就能在终端界面展示如当前 git 分支、本地目录、天气信息,甚至是一个陪伴你编程的数字伙伴等内容。
然后 Claude Code 的最新更新允许你在开发过程中,将如启动开发服务器、运行测试或构建项目等耗时任务放到后台执行。这样,你可以继续在前台与 Claude 交互,无需等待这些任务完成,也不会影响你的其他操作。
最后是两项自动化安全审查新功能:一是 /security-review 斜杠命令,允许你在终端直接发起安全分析,自动检测如 SQL 注入、XSS 漏洞和不安全的数据处理等常见安全风险;二是 GitHub Actions 集成,可以在每次 Pull Request 时自动进行安全检查,并以评论形式给出详细解释和修复建议。