封面提示词:Minimalist illustration, combination of reality and abstraction, blurred grainy texture, solid pure white background, blurred + grainy + textured + hazy feel, fresh and elegant, healing color palette, strong contrast between warm and cold tones, emphasizing a dreamy and warm atmosphere, shimmer, faint shapes of many colorful planets, surrounded by small stars, non-traditional composition, motion blur, self-order, artistic, cute, seamless pattern. --ar 16:9 --v 8.1
聊一下上周做了什么:
- GPT-Image-2 发布以后,我发了不少相关玩法。其中关于“生成游戏内容”和 Seedance 2.0 结合去做交互式游戏的玩法爆了,在推特上有两条百万曝光的推文。
- 去参加继刚的分享会时做了一个 PPT,大家都觉得做得不错,于是我就顺势做了一个 PPT Skills。目前相关的推特文章也快百万阅读了,看到很多朋友在用,后面也会继续迭代这个 PPT 相关的产品。
- 我的 CodePilot 开始重构了。主要想看看这次能不能让整体性更强一点,让所有的 Harness 都在一个体系下工作,而不是像之前那样东一榔头西一棒子地去搞。
上周精选✦
Open AI 发布 GPT-5.5 和 GPT-Image-2.0
上周 OpenAI 非常猛,不仅发布了 GPT-Image 2.0,还发布了 GPT 5.5 模型。同时,它的 Codex 客户端也更新了非常多有意思的功能。
这三者加起来,让我觉得现在 Codex 已经完全可以替换掉 Claude Code 和 Claude 那套体系了。尤其是在 Vibe Coding 的过程中,素材生成和交互界面的测试走查方面非常强。
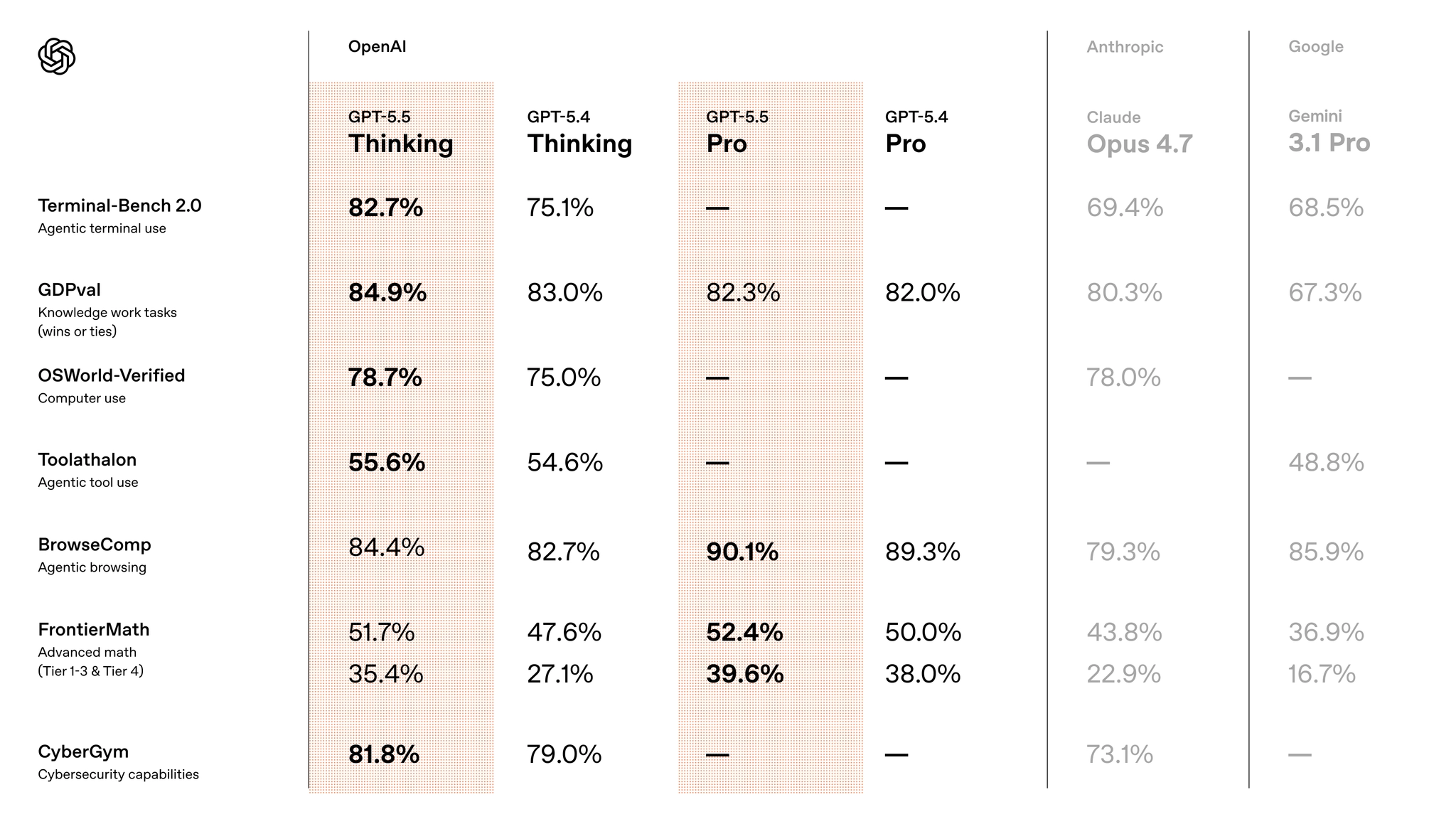
先来看看 GPT-5.5:
这次 OpenAI GPT 5.5 的发布,除了更聪明以外,在解题方式上也更加高效,能用更少的 Token 完成更高质量的输出。
OpenAI 表示 GPT 5.5 是他们最具有 Agent 能力的编程模型。它可以在一些编程测试上,用更少 Token 的同时得到优于 GPT 5.4 的结果,能够在 Codex 中承担从重构到调试、测试、验证等所有流程的工作。
从我自己的感知来看:
- GPT 5.5 几乎已经能够平替 Opus 4.7 了,而且在文本写作和对话语气方面比 Opus 4.7 要好很多。
- 它的 Token 生成速度提高了 20% 以上。
- 比较明显的缺点是在超长程任务的稳定性上稍差,且在对话过程中比较啰嗦。
此外,由于它的编码能力和漏洞发现能力变强了,在涉及到网络安全相关的任务时,系统会要求进行认证,否则不会开启这类任务。定价方面,GPT 5.5 比 GPT 5.4 稍微高一点。
然后是 GPT-Image 2.0 模型:
这个模型在图像模型的整体能力上,相较于 Nano Banana 2 又往前进了一步。主要表现在一些需要智能的、非常常见的设计任务上,能力有着非常大的提升。
而且它不需要你有复杂的提示词,就能够自己进行设计,给出一个非常好的、中等偏上的结果。从 OpenAI 自己的发布内容来看,它能够承担复杂的视觉任务,并生成即时可用的、精确的视觉效果,在中文文本渲染上非常强。
此外,Image 2.0 还有以下特点:
- 首款具备思考能力的图像模型:可以联网实时检索并获取信息。
- 多样化生成:能够根据一条提示词创建多种特色的图像。
- 自我检查机制:它会对输出结果进行检查,因此在准确性、实践性、时效性、连贯性以及视觉一致性上的效果都非常好。
用 OpenAI 的话来说,它实现了图像生成从单纯渲染到战略设计、从单一工具到视觉系统的跨越。
就我目前观察来看,它在任何常见设计任务上的表现都不错。但是在涉及到绘画、漫画、CG 渲染等非真实场景的绘画与艺术任务上,它的涂抹感非常严重,效果非常像即梦的 SeeDream 模型。这个我感觉后面他们估计得优化一下。

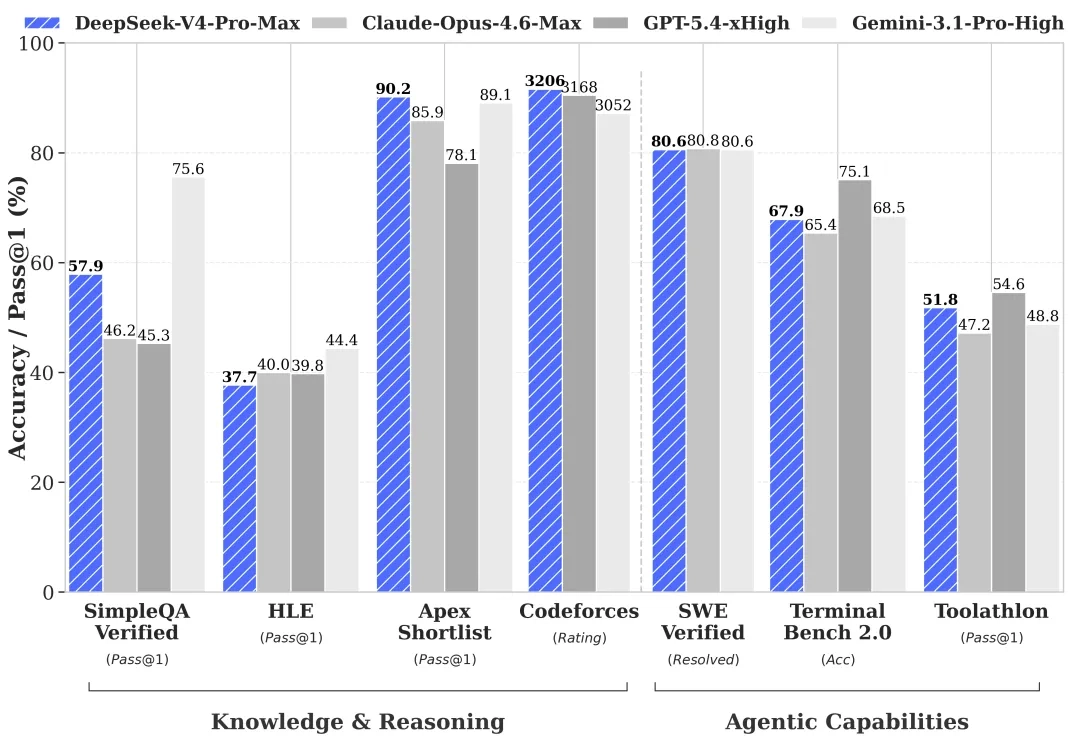
Deepseek 发布 Deepseek V4 模型
从年前就各种消息满天飞,说 DeepSeek V4 要发布了,结果硬是熬到了 5 月劳动节前夕,上周才发布。
DeepSeek-V4 总共包括两个模型:Pro 和 Flash。Pro 模型:总参数:1.6T、激活参数:49B。Flash 模型:总参数:284B、激活参数:13B。二者的预训练数据都是 32T。
从他们的测试成绩来看,DeepSeek-V4 在各项能力上都跟现在的顶尖模型 GPT-5.4 和 Opus 4.6 相差不多。据官方所说,其 Agent 能力大幅提高,已经成为他们公司内部员工使用的 Agentic Coding 模型。此外,由于 V4 Pro 的参数高达 1.6T,在世界知识上也大幅领先其他开源模型。
关于 V4 Pro 和 Flash 的对比及技术亮点,主要有以下几点:
-
模型性能对比:
(a) 在世界知识储备上,V4 Flash 稍微逊色于 Pro 版本。
(b) 在 Agent 能力测评上,Flash 与 Pro 的表现基本相当。
-
超高上下文效率:
他们开发了一种全新的注意力机制,在 Token 维度进行压缩并结合 DSA 吸收注意力,实现了极长的上下文处理能力。现在 100 万上下文已成为官方 API 服务的标配,DeepSeek-V4 Pro 和 Flash 默认都会启用 100 万上下文长度。
-
产品适配:
官方针对 Claude Code、Claude Ops、OpenCloud、OpenCode 等主流 AI 插件产品进行了适配和优化。不过根据我自己在发布当天的测试,Pro 模型在 Claude Code 下的使用还存在一些问题,不知道是不是设置原因,这几天我还没来得及重新测试。
-
价格与优惠活动:
目前的定价策略非常有竞争力。Pro 模型的标准价格为:输入 12 元/百万 Token(缓存命中时为 1 元),输出 24 元/百万 Token。
重点在于他们在 5 月 6 号前开启了 2.5 折优惠活动:
(a) Flash 和 Pro 全线产品仅需原价的 1/4。
(b) Pro 模型的输出价格降至 6 元/百万 Token。
(c) 在缓存命中的情况下还会打 1 折,Pro 模型的输入成本仅需一毛钱。
这种价格水平非常恐怖。如果是原价,竞争力可能还没那么突出,但以目前的折扣价来说,这东西可太猛了。