
封面提示词:Create a high-resolution vertical wallpaper featuring a bouquet of softly blurred pastel flowers (colours: lavender, blush pink, cream) placed in the background.Overlay a vertical ribbed/faceted glass texture, similar to the clean refraction effect seen on Nothing Phone aesthetics — smooth, linear distortions running top to bottom, without any cracks or irregular breaks.The glass should refract and slightly distort the background flowers along the vertical lines, creating a minimalistic and futuristic visual effect.Style: modern, sleek, refined, and slightly ethereal.Colour palette: muted soft tones with subtle light bloom.Lighting: diffused and slightly luminous, avoiding harsh shadows.Composition: centre-focused but allowing natural vertical flow through the glass ribs, maintaining an airy and elegant mood.
上周精选✦
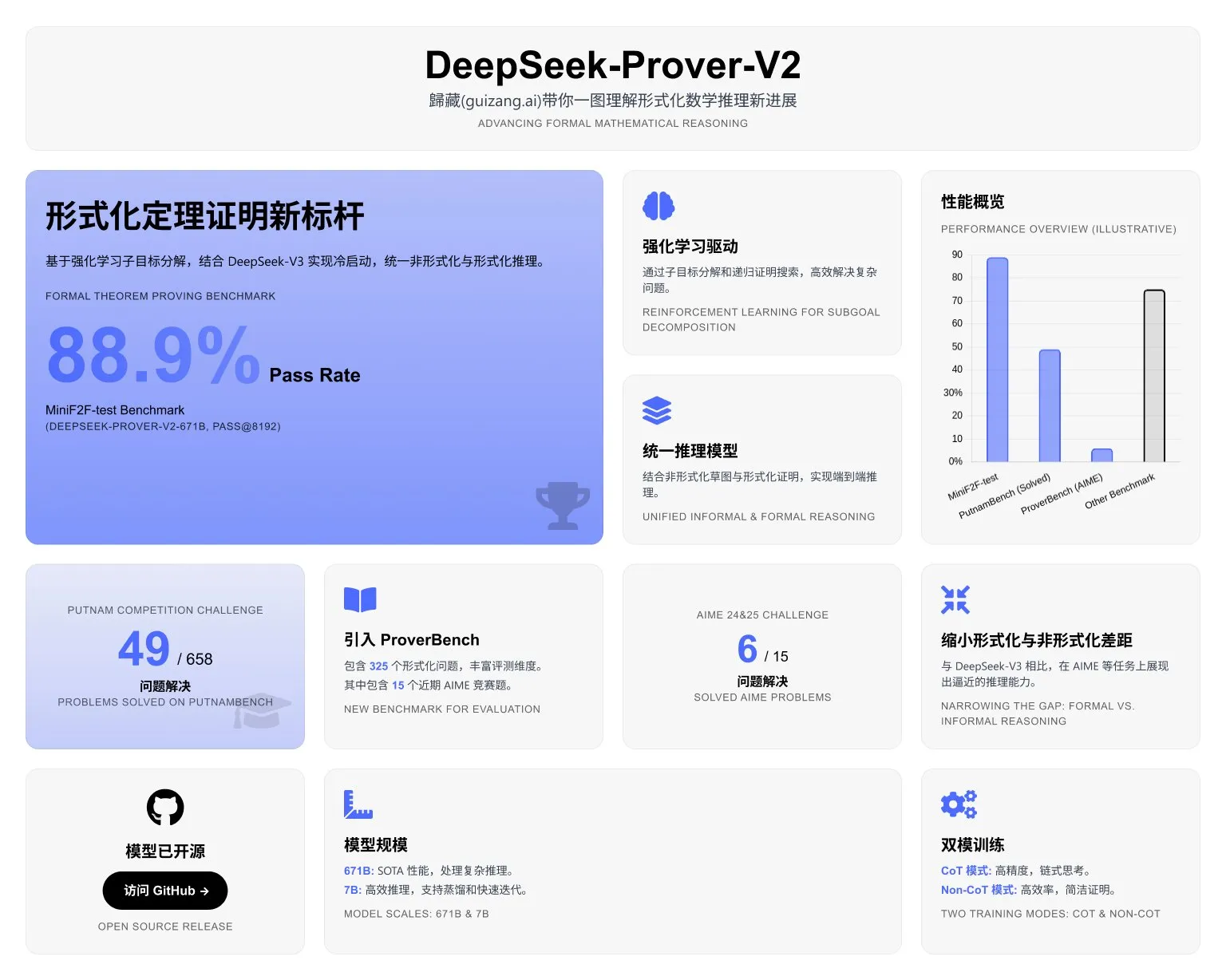
DeepSeek 发布 Prover V2
五一这一周前就一直有人说Deepseek要发R2,但内容是某个炒股的瞎编的,没想到真发东西了。
DeepSeek-Prover-V2 一个专为 Lean 4 形式化定理证明设计的开源大型语言模型。其核心目标是利用强化学习进行子目标分解,从而提升形式化数学推理能力。
核心方法与创新:
- 递归定理证明流水线 (Recursive Theorem Proving Pipeline):
利用通用的 DeepSeek-V3 模型将复杂问题分解为一系列子目标 (subgoals)。
DeepSeek-V3 同时生成自然语言的证明草图 (proof sketch) 和对应的 Lean 4 形式化语句框架(使用 sorry 占位符表示待证明细节)。 - 子目标解决与合成 (Subgoal Solving & Synthesis):
使用一个较小的 7B 参数的 Prover 模型递归地解决由 DeepSeek-V3 分解出的子目标。
将已解决的子目标证明组合起来,构建原始复杂问题的完整形式化证明。 - 冷启动数据生成 (Cold-Start Data Generation):
将 DeepSeek-V3 生成的链式思考 (Chain-of-Thought, CoT) 过程(包含问题理解、证明草图和 Lean 4 证明结构)与最终合成的完整形式化证明配对。
这种方法生成了高质量的、结合了非形式化推理和形式化证明的初始训练数据(冷启动数据)。 - 强化学习 (Reinforcement Learning, RL):
在冷启动数据微调的基础上,使用 GRPO (Group Relative Policy Optimization) 算法进行强化学习。
奖励机制:主要使用二元奖励(证明正确为 1,错误为 0)。在早期训练中加入一致性奖励 (consistency reward),鼓励模型生成的证明结构与 CoT 中的子目标分解保持一致。 - 课程学习 (Curriculum Learning):
利用分解出的子目标生成不同难度的定理(例如,将前面的子目标作为后续子目标的假设),逐步增加训练任务的难度,引导模型学习。
模型与训练:
主要模型: DeepSeek-Prover-V2-671B (6710亿参数)
小型模型: DeepSeek-Prover-V2-7B (70亿参数,通过蒸馏 671B 模型的 RL 数据得到)
基础模型: DeepSeek-V3 (用于初始分解和 CoT)
训练流程:
第一阶段 (非 CoT 模式): 使用专家迭代 (Expert Iteration) 和课程学习训练非 CoT 模型,侧重于快速生成简洁的 Lean 代码,同时通过子目标分解解决难题并收集数据。
第二阶段 (CoT 模式): 使用合成的冷启动 CoT 数据进行监督微调 (SFT),然后进行强化学习,重点提升模型的推理过程和最终证明能力。
关键贡献与发现:
- 提出了一种有效的结合非形式化推理(子目标分解、CoT)和形式化证明的方法。
- 证明了通过合成高质量冷启动数据和强化学习可以显著提升大型语言模型在形式化定理证明上的能力。
- 引入了 ProverBench,一个包含近期竞赛题目的新形式化证明基准。
- DeepSeek-Prover-V2 在多个基准上达到了 SOTA 水平。
- 观察到大型语言模型在形式化推理和非形式化数学推理能力上的差距正在缩小。
- CoT 推理模式对于解决复杂形式化证明至关重要。
Claude 支持远程MCP添加以及深度研究
Claude 五一期间宣布推出 Integrations 功能,主要是通过新的MCP协议实现的(看这次更新的MCP细节的话可以翻下面精选内容的那篇),另外还有Advanced Research高级研究功能也就是类似Open AI的 Deep Research。
Integrations 功能主要的能力是使 Claude 能够无缝对接网络及桌面应用中的远程 MCP 服务器。
开发者可以构建并托管增强 Claude 能力的服务器,而用户则可自由发现并连接任意数量的此类服务至 Claude。
默认内置了十多个重要软件的远程MCP服务可以很方便的添加,包括 Atlassian 的 Jira 和 Confluence、Zapier、Cloudflare、Intercom、Asana、Square、Sentry、PayPal、Linear 和 Plaid——后续还将增加 Stripe 和 GitLab 等公司的更多服务。
Advanced Research 现在能够深入调查数百个内部和外部来源,在 5 到 45 分钟内提供更全面的报告。
Integrations和Advanced Research已在 Max、Team 和 Enterprise 计划中提供测试版,很快也将在 Pro 计划中推出。
