封面提示词:iridescent bat wings, glowing night sky, magical shadows, mystical atmosphere use. --no text, logo, watermark --chaos 40 --ar 16:9 --raw --profile meb953z --stylize 250 --weird 300
上周精选✦
Kimi K2 模型发布应该是目前开源模型 SOTA 了
本来这周的头条应该是 Grok 4 的,没想到 kimi 整了个大的,发布了世界首个开源万亿参数模型。
周五晚上我第一时间测试了一下发现非常强,然后经过两天的发酵在推特彻底爆了,一些三方测试出来之后感觉比我想的还要强,不只是前端厉害在创意写作和 EQ 上都是第一。
月之暗面这次开源的模型包括预训练模型和后面的指令微调模型,激活参数 32B,总参数 1T。
这里是我的一些前端测试,还有在 Claude Code 里面使用 K2 的方式。
值得关注的还有他们基于 Muon 搞得这个MuonClip 优化器。
之前很多人怀疑 Muon 优化器没办法训练 K2 这种超大规模的模型,月之暗面证明了是可以的。
kimi 用基于 Muon 的 MuonClip 优化器将可以训练的模型规模推到了万亿这个级别。
在 15.5 万亿的 Token 规模上进行训练,训练过程非常稳定。
模型的损失(loss)或梯度没有出现异常的剧烈上升,保持的非常漂亮且平稳的曲线。
而且还通过智能体数据合成和通用强化学习增强了 K2 的 agentic 能力。
团队开发了一个大规模的数据生成流程,模拟真实世界中工具使用的场景,智能体与模拟环境和用户代理互动,创造出真实的多轮工具使用场景。
Kimi K2 不仅能处理有明确奖励的任务(如数学、编程),还可以通过自我评判机制处理无明确奖励的任务(如写报告)。模型在无明确奖励的任务中充当自己的“评论家”,基于评分标准给出反馈,实现可扩展的自我学习。对于有明确奖励的任务,采用 on-policy rollouts 持续更新“评论家”,提升对最新策略的评估准确性。
XAI 的 Grok 4 模型发布
再然后就是老马渲染了几周的 Grok 4,确实屠榜了各大测试集,分数高的吓人,但是在我的使用感受上面不是很出彩,没有跟其他前沿模型有明显差距,在代码上的效果超级差。
包括 Grok 4 和 Grok 4 Heavy 两个模型。
内置了工具链调用能力,支持检索、代码执行、计算器等工具。
256K 上下文窗口,支持文本、图像、结构化数据输入。
预训练阶段相较 Grok 3 提升约 10 倍。Grok 4 reasoning 在 RL 阶段再 提升 10 倍。
APP 现在三个会员等级:
基础会员现在只能免费用 Grok3 了
SuperGrok 300 美金一年,支持 128K 上下文的 Gork4,语音和视觉输入。
SuperGrok Heavy 3000 美金一年,可以抢先体验新功能,使用 Grok 4 Heavy 模型。
API同步推出: Grok 4模型,输入 3美元、输出 15 美元,输出价格接近 o3 的两倍,太贵了。
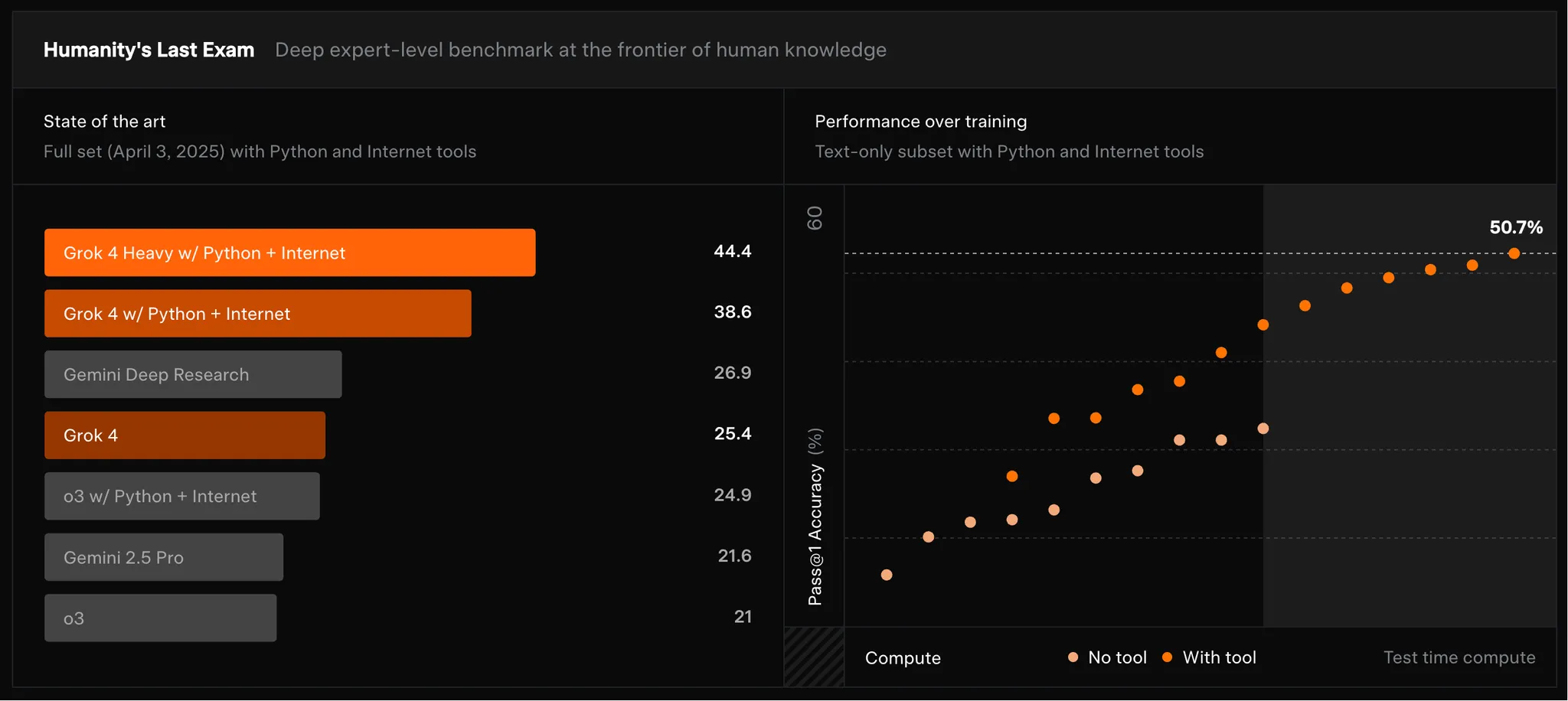
基准测试结果上:
Humanity’s Last Exam(2500 题,100+ 学科)Grok 4 Heavy + 工具刷到了44.4 %,o3 约为 21%。
AIME25(数学竞赛):Grok 4 Heavy = 100 %(满分)。
USAMO25(数学证明):Grok 4 Heavy = 61.9 %,领先次席 24 pp。
Chest Agent Bench(胸片 Agent 任务):Grok 4 = 72.8 %,行业最高。
Vending-Bench(商业运营模拟):Grok 4 人均净资产 $4694(第 2 名约 $2077)。
未来路线图:
7 月:Grok 4 Release(已完成)。
8 月:Coding Model(代码生成与代理)。
9 月:Multi-modal Agent(统一文本-图像-工具的任务执行)。
10 月:Video Generation Model(视频生成,对标 Sora / Veo)。