
为什么要把这个js文件单独拿出来分析,是因为在现代 Web 开发和自动化测试领域,我们经常需要程序化地理解和操作复杂的 Web 页面。用户看到的界面背后是庞大而动态的 DOM (文档对象模型) 树。然而,并非所有 DOM 节点都对用户交互或页面理解有意义。如何高效地提取出页面的关键结构,特别是那些用户可以与之交互的元素,并同时保证性能,是一个重要的挑战。
buildDomTree.js 这段代码就是为了解决这个问题而设计的。它的核心目标是遍历当前网页的 DOM,构建一个简化的、包含关键信息(如可见性、交互性、位置)的页面结构视图,并能选择性地高亮显示可交互元素,同时内置了性能优化和调试机制。
本文将深入剖析 buildDomTree.js 的实现细节、关键技术点和优化策略,帮助你理解它是如何工作的,以及这些技术在实际应用中的价值。
一、核心目标:构建简化的交互视图
浏览器渲染网页时,会构建一个包含所有 HTML 标签、文本、注释等节点的完整 DOM 树。但对于自动化工具或某些分析场景来说,我们只关心:
- 页面骨架结构:主要的布局容器。
- 可见的文本内容:用户能看到的信息。
- 可交互的元素:按钮、链接、输入框等用户可以操作的控件。
- 这些元素的状态:是否可见、是否被遮挡、在视口内的位置等。
buildDomTree 函数正是要生成这样一个“简化视图”。它并不直接复制整个 DOM 树,而是递归遍历 DOM 节点,为每个“有意义”的节点创建一个描述对象,并将这些对象存储在一个扁平化的哈希映射(DOM_HASH_MAP)中,通过唯一 ID 进行关联。
为什么是哈希映射而不是直接的树状结构?

- 序列化友好:扁平的映射结构更容易序列化(例如,转换成 JSON)和跨进程/环境传递,避免了处理复杂嵌套对象和循环引用的麻烦。
- 随机访问:可以快速通过 ID 访问任何节点信息,而无需遍历树。
- 灵活性:更容易管理节点间的关系,例如,一个节点可以被多个父节点引用(虽然在此代码中主要还是树形结构,但映射提供了这种潜力)。
// 最终返回的核心数据结构
{
rootId: '...', // 根节点 (通常是 body) 的 ID
map: DOM_HASH_MAP // { 'id1': nodeData1, 'id2': nodeData2, ... }
}
// DOM_HASH_MAP 中存储的节点数据示例 (nodeData)
{
tagName: 'button', // 元素标签名
attributes: { 'class': 'submit-btn', 'id': 'btn1' }, // 元素属性
xpath: '/body/div[1]/main/button[1]', // 简化 XPath
children: ['id3', 'id4'], // 子节点的 ID 列表
isVisible: true, // 是否可见
isTopElement: true, // 是否是顶层元素 (未被遮挡)
isInteractive: true, // 是否可交互
isInViewport: true, // 是否在视口内 (此代码中标记为 true,实际判断在外部使用)
highlightIndex: 5, // 高亮编号 (如果启用)
// ... 其他的属性,如 text (文本节点), shadowRoot (是否有 Shadow DOM)
}
二、关键挑战与实现:识别“有意义”的节点
buildDomTree 的核心在于其筛选和判断逻辑,即如何确定一个 DOM 节点是否“有意义”并需要包含在最终的视图中。这涉及到几个关键的检查:
1. 可见性检查 (Visibility)
用户看不见的东西通常是无意义的。代码通过多种方式判断可见性:
-
元素可见性 (
isElementVisible):-
检查元素的
offsetWidth和offsetHeight是否大于 0。这是判断元素是否占据实际空间的基本方法。 -
检查
getComputedStyle获取的visibility是否为hidden,display是否为none。
优化点:
getComputedStyle是一个相对昂贵的操作。代码后续加入了缓存机制来优化它。 -
-
文本节点可见性 (
isTextNodeVisible):-
文本节点本身没有大小,需要通过
document.createRange()选择文本内容,然后获取其getBoundingClientRect()来判断是否有实际渲染区域。 -
同时检查其父元素是否可见(使用
parentElement.checkVisibility()或回退到检查父元素的 CSS 样式)。
注意:这个检查相对复杂,有一定的性能开销,代码仅在文本内容非空且父元素看起来可见时才执行。
-
-
视口内检查 (
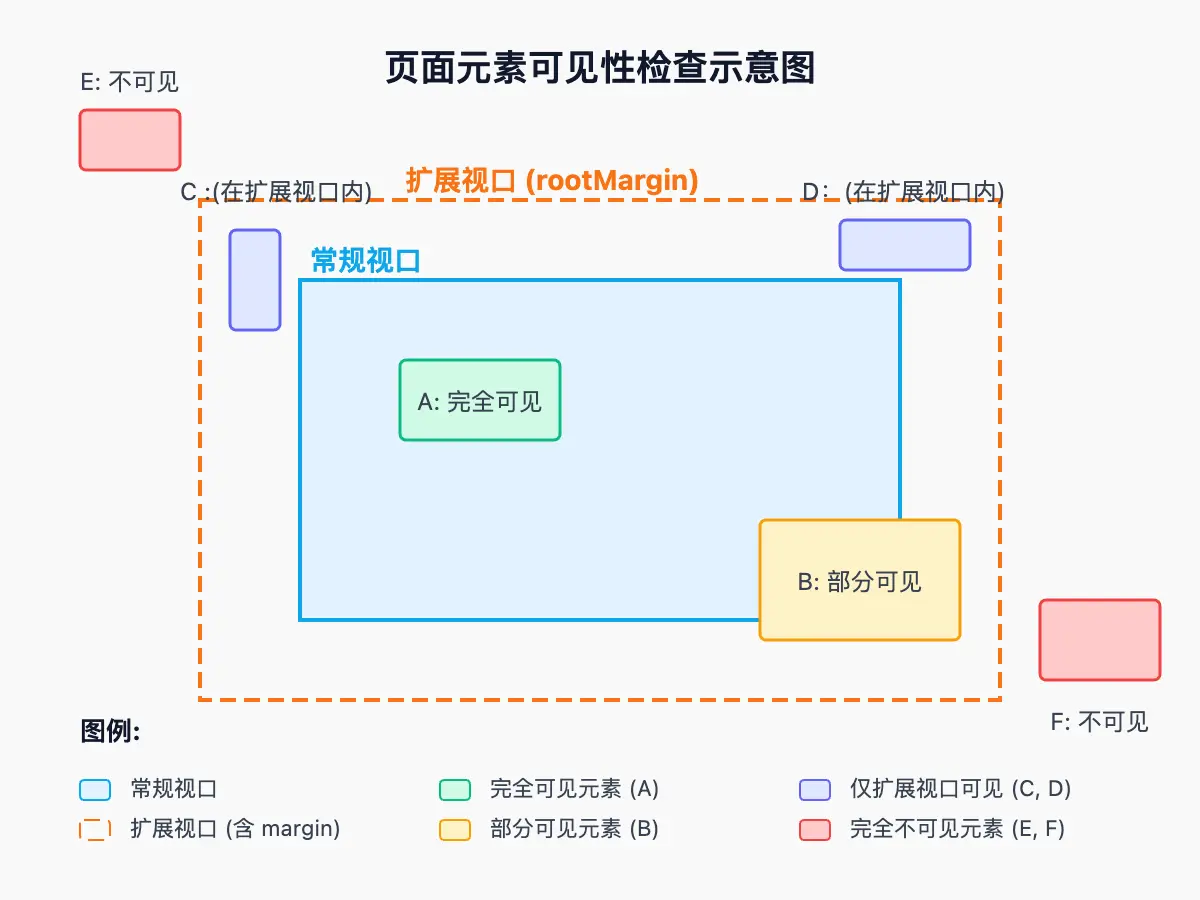
isInExpandedViewport):-
使用
getBoundingClientRect()获取元素相对于视口的位置。 -
判断元素的边界 (
top,bottom,left,right) 是否在视口范围内。 -
引入
viewportExpansion参数,允许包含视口边缘之外一定距离(viewportExpansion像素)的元素。这对于捕捉即将滚动进入视口的元素很有用。
-
想象你的视线是一个矩形框(视口),viewportExpansion 就像给这个框加了一个“余光”范围,能看到框外一小圈的东西。值为 -1 时表示禁用视口检查,获取所有元素。
2. 交互性检查 (isInteractiveElement)
识别哪些元素用户可以与之交互是 buildDomTree 的另一个核心任务。这直接关系到自动化脚本应该操作哪些元素,或者高亮功能应该标记哪些元素。判断逻辑比较复杂,综合了多种因素:
- 标签名 (Tag Name):一些 HTML 标签天生就是可交互的,如
<a>,<button>,<input>,<select>,<textarea>,<details>,<summary>等。代码维护了一个interactiveElements集合来快速判断。 - ARIA Roles: 元素的
role或aria-role属性可以明确指定其交互语义,即使它本身不是原生交互标签(例如,一个<div>被赋予了role="button")。代码维护了一个interactiveRoles集合。 - TabIndex:
tabindex属性大于等于 0 的元素通常是可以通过键盘聚焦和交互的。但代码排除了直接在<body>下设置tabindex的情况,这是一种不太标准的用法。 - 特定属性/类名: 代码包含了一些硬编码的检查,例如
classList.contains("address-input__container__input")或data-action="a-dropdown-select",这是针对特定网站或组件库的定制。 - 事件监听器:
- 检查元素是否直接绑定了
onclick属性。 - 检查是否具有
ng-click(AngularJS),@click/v-on:click(Vue) 等框架特定的点击指令属性。 - 尝试使用
window.getEventListeners(element)(一个非标准但部分浏览器开发者工具支持的 API) 来获取元素上绑定的所有事件监听器。检查是否存在click,mousedown,mouseup,touchstart,touchend等与点击/触摸相关的监听器。 - 如果
getEventListeners不可用,会回退检查元素上是否存在onclick,onmousedown等on*属性处理器。
- 检查元素是否直接绑定了
- ARIA 状态属性: 具有
aria-expanded,aria-pressed,aria-selected,aria-checked等属性的元素,通常暗示了其交互状态和能力。 - ContentEditable:
contenteditable="true"或isContentEditable为 true 的元素(富文本编辑器区域)是可交互的。代码还特别处理了 TinyMCE 等富文本编辑器的常见 ID 和类名。 - Draggable:
draggable="true"的元素也是可交互的。
那么如何理解上述是否可交互的逻辑呢,我们不妨换个思路,如何判断一个东西是否是“工具”?
- 有些一看就知道是工具:锤子 (
<button>)、螺丝刀 (<input>)。 (标签名检查)- 有些东西上贴了标签“这是一个扳手” (
role="button")。(ARIA Role 检查)- 有些东西虽然看起来不像工具,但说明书上写了它可以用来拧螺丝 (
tabindex="0", 事件监听器)。(属性/事件检查)- 有些东西设计成了可以变形或抓握 (
aria-expanded,draggable)。(状态/能力检查)
isInteractiveElement就是综合运用这些线索来识别页面上的“工具”。
3. 顶层元素检查 (isTopElement)
一个元素即使可见且可交互,也可能被其他元素(如弹窗、浮动广告)遮挡,导致用户实际无法点击。isTopElement 函数就是用来检查这一点的。
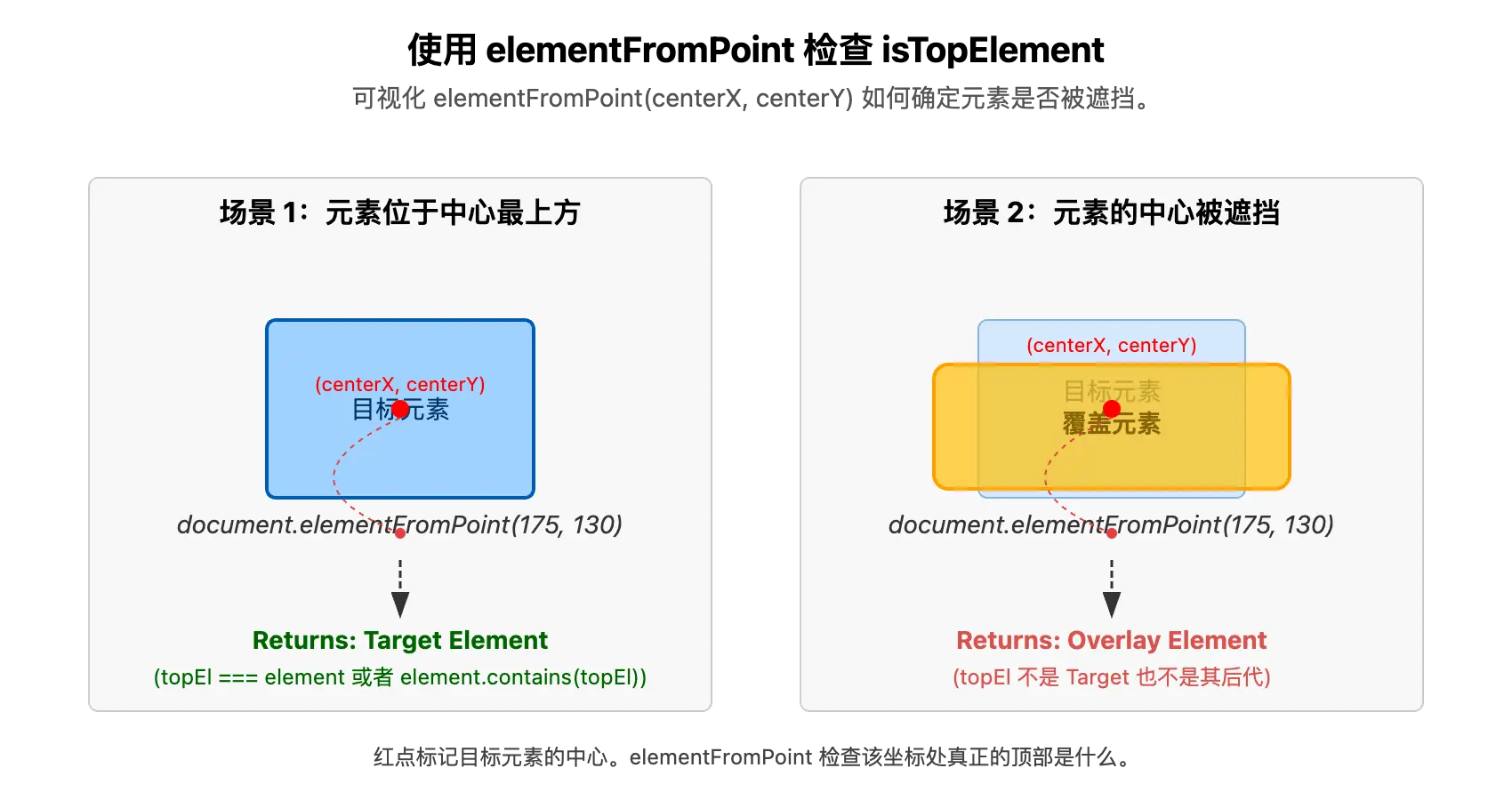
- 核心方法: 使用
document.elementFromPoint(x, y)。这个 DOM API 返回指定视口坐标(x, y)处最顶层的元素。 - 实现逻辑:
- 获取元素的中心点坐标 (
centerX,centerY)。计算方法:centerX = rect.left + rect.width / 2,centerY = rect.top + rect.height / 2。 - 调用
document.elementFromPoint(centerX, centerY)得到该点最顶层的元素topEl。 - 关键判断:检查当前正在处理的元素
element是否就是topEl,或者是topEl的祖先元素。如果是,则意味着element没有被其他无关元素完全遮挡在中心点位置,可以认为是“顶层”的。如果topEl是element的子孙元素,那也说明element本身是暴露在外的。 - 特殊处理:
- 如果元素不在视口内,默认认为是顶层(因为它没有被视口内的元素遮挡)。
- 如果元素在
<iframe>内部,默认认为是顶层(elementFromPoint在主文档调用无法穿透 iframe)。 - 如果元素在
Shadow DOM内部,需要在其所属的shadowRoot上下文中调用shadowRoot.elementFromPoint()进行检查。
- 获取元素的中心点坐标 (
我们用一个卡片的例子来介绍如上的操作,你在桌子上叠放了很多卡片。你想知道最上面那张写着“目标”的卡片 (
element) 是否真的能被你直接拿到。
- 你用手指指向卡片的中心 (
centerX,centerY)。- 你的手指首先触摸到的那张卡片 (
topEl) 是什么?- 如果手指直接碰到了“目标”卡片,或者碰到了叠在“目标”卡片上面的、属于“目标”卡片一部分的小标签(子元素),那么“目标”卡片就是可直接接触的 (
isTopElement= true)。- 如果手指碰到的是一张完全覆盖在“目标”卡片上的其他卡片,那么“目标”卡片就被遮挡了 (
isTopElement= false)。
三、处理复杂性:IFrames, Shadow DOM, Rich Text
现代网页充满了复杂性,buildDomTree 也考虑了其中一些常见场景:
- IFrames: 当遇到
<iframe>元素时,代码会尝试访问其contentDocument或contentWindow.document来获取 iframe 内部的文档对象。如果成功访问(没有跨域限制),它会递归调用buildDomTree处理 iframe 内部的 DOM 结构,并将结果作为<iframe>节点的子节点添加到DOM_HASH_MAP中。递归调用时会传入父iframe元素,用于后续高亮定位计算。 - Shadow DOM: 如果一个元素拥有
shadowRoot(使用了 Shadow DOM 技术封装内部结构),代码会识别到node.shadowRoot存在,并在nodeData中标记shadowRoot: true。然后,它会遍历shadowRoot下的子节点,递归调用buildDomTree,将 Shadow DOM 内部的结构也纳入到简化视图中。这对于处理使用 Web Components 构建的现代 UI 非常重要。 - Rich Text Editors / ContentEditable: 对于
contenteditable属性为 true 的元素,或者像 TinyMCE 这样常见的富文本编辑器容器,代码不会像处理普通容器那样只关心交互式子元素。它会递归处理其所有的子节点(包括文本节点、格式化标签如<b>,<i>等),以尽可能保留编辑器内容的结构和文本信息。这对于需要提取或分析富文本内容的应用场景很有价值。
四、性能优化:缓存与提前退出 (Early Bailouts)
如前所述,频繁访问 DOM 属性(特别是 getBoundingClientRect 和 getComputedStyle)是性能瓶颈。buildDomTree 采用了几种策略来优化性能:
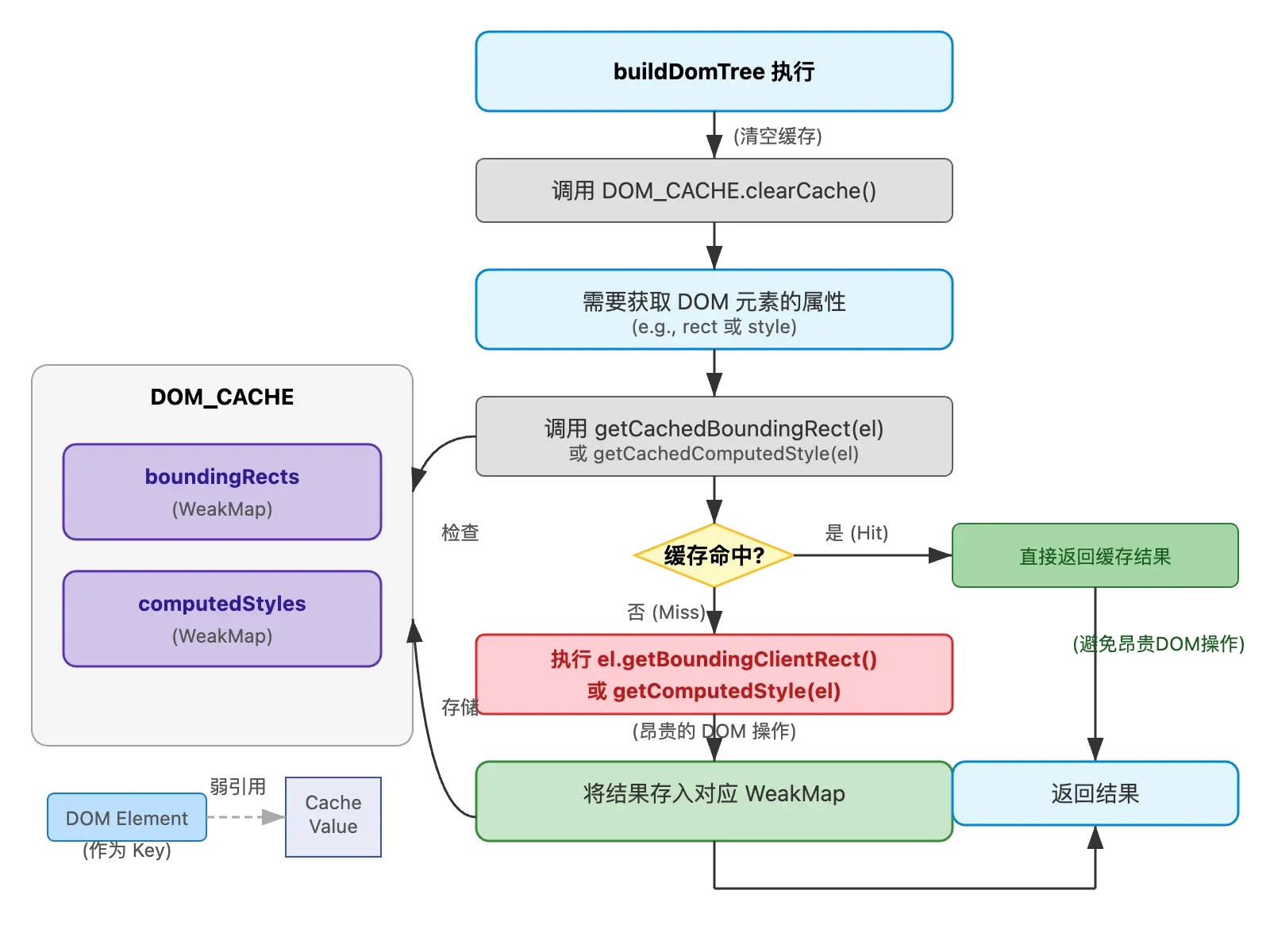
-
DOM 属性缓存 (
DOM_CACHE):- 使用两个
WeakMap对象(boundingRects和computedStyles)来缓存getBoundingClientRect()和getComputedStyle()的结果。 WeakMap的妙用:WeakMap的键必须是对象,并且它对键是“弱引用”。这意味着,如果一个 DOM 元素从页面上被移除了,并且没有其他地方引用它,垃圾回收器就可以回收这个元素,WeakMap中对应的缓存条目也会自动消失,避免了内存泄漏。这比使用普通Map或对象存储缓存更安全。- 在每次需要获取
rect或style时,先尝试从缓存中读取 (getCachedBoundingRect,getCachedComputedStyle)。如果命中缓存,则直接返回结果,避免了昂贵的 DOM 操作。如果未命中,则执行 DOM 操作,并将结果存入缓存。 - 在
buildDomTree执行开始前,会调用DOM_CACHE.clearCache()清空缓存,确保每次构建视图时使用的是最新的 DOM 信息。
我们拿个案例来讲解,图书馆管理员(
DOM_CACHE)经常被问到某些热门书籍(DOM 元素)放在哪个架子上(getBoundingClientRect)或者书的摘要是什么(getComputedStyle)。- 管理员第一次被问到时,需要去书架查找(执行 DOM 操作),然后把答案记在一个小本本(
WeakMap缓存)上,并写上书名(元素引用)。 - 下次再有人问同一本书的信息,管理员可以直接看小本本,快速给出答案(缓存命中)。
- 如果这本书被图书馆处理掉了(元素被移除),管理员小本本上关于这本书的记录也会自动失效,不会占用空间(
WeakMap的特性)。
- 使用两个
- 快速检查与提前退出 (Early Bailouts):
isElementAccepted: 在处理元素节点之前,快速检查标签名是否在“拒绝列表”中(如script,style,svg,meta等)。这些元素通常不包含用户可见或可交互的内容,可以提前跳过,避免后续更复杂的检查。但它会接受常见的容器元素如div,main,section等。quickVisibilityCheck(虽然在buildDomTree主逻辑中未直接使用,但提供了思路): 在调用昂贵的getComputedStyle之前,先通过元素自身的offsetWidth/Height和style属性进行初步的可见性判断。如果这些快速检查表明元素不可见,就可以提前跳过。isInteractiveCandidate: 在决定是否要获取元素的详细属性 (getAttributeNames) 和进行完整的交互性检查 (isInteractiveElement) 之前,先做一个快速判断。如果元素标签是常见的交互式标签,或者具有onclick,role,tabindex,aria-*,data-action等“可疑”属性,才认为它是一个“交互候选者”,值得进一步详细检查。这避免了对大量静态容器元素进行不必要的属性读取和复杂判断。- 文本节点内容检查: 对于文本节点,先检查
textContent.trim()是否为空。如果是空字符串或只包含空白,直接跳过,不进行后续的可见性检查。 - 视口检查: 如果启用了
viewportExpansion(非 -1),并且元素的getBoundingClientRect表明它完全在扩展视口之外,则提前跳过该节点及其所有子孙节点的处理。
这些“提前退出”策略就像在处理流程的早期设置了很多“过滤器”,快速筛掉明显不符合条件的节点,使得主要的处理资源可以集中在那些更有可能是目标(可见、可交互)的节点上。
五、高亮与调试
buildDomTree.js 还提供了两个非常有用的辅助功能:
- 元素高亮 (
highlightElement):- 当
doHighlightElements参数为true时,对于被识别为可见 (isVisible)、顶层 (isTopElement) 且可交互 (isInteractive) 的元素,会调用highlightElement函数。 - 该函数会在页面上创建一个全局的、置顶的 (
z-index极高)div容器 (#playwright-highlight-container)。 - 对于每个要高亮的元素,它会:
- 获取元素的位置 (
getBoundingClientRect)。 - 创建一个与元素位置和大小完全相同的半透明、带边框的覆盖层 (
overlay),并添加到高亮容器中。边框和背景颜色会根据元素的highlightIndex循环选择一组预定义颜色,方便区分。 - 创建一个小标签 (
label),显示该元素的highlightIndex(一个从 0 开始递增的数字),并将其定位在覆盖层的右上角(或根据空间调整到上方)。 - 考虑 IFrame: 如果元素位于
iframe内,高亮覆盖层和标签的位置会加上父iframe相对于主视口的偏移量,确保高亮效果在主页面上定位准确。 - 动态更新: 添加了
scroll和resize事件监听器,当页面滚动或窗口大小变化时,会重新计算高亮元素的位置并更新覆盖层和标签的位置,保持高亮效果与元素同步。
- 获取元素的位置 (
focusHighlightIndex参数可以用来只高亮特定索引的元素,方便聚焦查看。
- 当

- 调试模式与性能指标 (
debugMode,PERF_METRICS):- 当
debugMode参数为true时,代码会启用详细的性能追踪。 - 计时器: 使用
performance.now()对多个关键函数(如buildDomTree自身、highlightElement、各种检查函数、DOM 操作)的执行时间进行测量。 - 计数器: 记录
buildDomTree的总调用次数、处理的节点数、跳过的节点数、缓存命中/未命中次数、getBoundingClientRect和getComputedStyle的调用次数等。 - 数据聚合: 将所有测量数据存储在
PERF_METRICS对象中。在buildDomTree执行完毕后,对原始耗时(毫秒)进行处理(如转换为秒),计算缓存命中率、平均节点处理时间、DOM 操作总耗时及平均耗时等衍生指标。 - 最终,如果
debugMode为true,返回结果会包含这个perfMetrics对象,开发者可以通过分析这些数据来诊断性能瓶颈或理解代码的执行情况。
- 当
六、代码结构与数据流
简单梳理一下代码的执行流程:
- 入口: 代码是一个 IIFE (立即调用的函数表达式),接收
args对象作为参数,包含配置选项(doHighlightElements,focusHighlightIndex,viewportExpansion,debugMode)。 - 初始化: 设置
highlightIndex,ID.current(用于生成节点唯一 ID)。如果debugMode为 true,初始化PERF_METRICS对象和性能测量相关的包装函数 (measureTime,measureDomOperation)。初始化DOM_CACHE。 - 缓存清空: 调用
DOM_CACHE.clearCache()。 - 递归构建: 调用
buildDomTree(document.body)开始递归遍历。- 节点处理: 在
buildDomTree函数内部:- 进行各种“提前退出”检查(节点类型、是否接受、视口范围)。
- 根据节点类型(元素、文本)处理:
- 元素: 获取标签名、属性(如果需要)、计算 XPath、检查可见性、顶层状态、交互性。如果需要高亮,调用
highlightElement。递归处理子节点(普通子节点、Shadow DOM 子节点、IFrame 内容)。 - 文本: 获取文本内容,检查可见性。
- 元素: 获取标签名、属性(如果需要)、计算 XPath、检查可见性、顶层状态、交互性。如果需要高亮,调用
- 创建
nodeData对象。 - 生成唯一 ID,将
nodeData存入DOM_HASH_MAP。 - 返回节点 ID。
- 递归: 对子节点重复上述过程。
- 节点处理: 在
- 性能数据处理: 如果
debugMode为 true,在递归结束后,对收集到的PERF_METRICS数据进行计算和整理。 - 返回结果: 返回一个包含
rootId和map(即DOM_HASH_MAP) 的对象。如果debugMode为 true,结果对象中还会包含perfMetrics。
七、总结
buildDomTree.js 提供了一个强大而灵活的机制,用于从复杂、动态的网页 DOM 中提取出一个简化的、关注交互和可见性的结构化视图。其核心优势在于:
- 目标明确: 聚焦于可见性、交互性和结构,过滤掉大量无关信息。
- 性能优化: 通过缓存和提前退出策略有效降低了 DOM 操作带来的性能开销。
- 处理复杂性: 能够较好地处理
<iframe>,Shadow DOM,contenteditable等现代 Web 特性。 - 实用功能: 内置了元素高亮和详细的性能调试功能。
- 数据结构: 使用扁平化的哈希映射,易于序列化和后续处理。
希望通过这次深入的剖析,大家对 buildDomTree.js 的工作原理、技术细节和设计思想有了更清晰的理解。在面对复杂 DOM 处理需求时,其中的许多技巧和方法都值得我们学习和借鉴。我们下篇文章见。