
当前AI领域最前沿的探索之一,是让AI真正“理解”我们所处的世界。这便引出了“世界模型”(World Models)的概念——一种被认为是构建更高级、更接近人类认知能力的AI的关键路径。Yann LeCun(杨立昆)正是这一方向的积极倡导者。
当全世界都在为AI模型的能力而惊叹时,这位深度学习的奠基人却发出了不同的声音:当前的大型语言模型远远不够,AI需要真正"理解"世界,而不仅仅是模仿人类的文本。
"We need AI that builds models of how the world works—not just mimics human text."
——Yann LeCun,图灵奖得主、Meta首席AI科学家
Yann LeCun作为图灵奖获得者、Meta首席AI科学家、纽约大学教授,他认为AI社区必须从统计模式匹配转向能够推理、理解世界和规划行动的模型——这一愿景可能重塑未来十年AI发展的轨迹。
本篇文章带您一同探索AI在3D内容生成方面的最新进展,并深入了解Yann LeCun提出的让AI更好地理解世界的世界模型。这不仅仅是关于AI如何“画”出3D模型,更是关于AI如何学习“思考”这个世界。
AI生成3D模型:从“无”到“有”,万物皆可“造”
年初, 电影“哪吒2”爆火,从幕后纪录片看到了制作这部3D动画电影中的一个10秒镜头就可能需要一年的时间来完成, 类似的包含上百个角色的3D电影、游戏——这需要从业者花费数月甚至数年的时间来完成。传统模式的3D建模就像手工活,需要:
- 高昂的时间成本:一个复杂的3D角色可能需要几周时间
- 专业技能门槛:掌握Maya、Blender等软件需要years的学习
- 规模化困难:面对海量需求,人工创作力不从心
3D模型主流技术路径:AI的“神笔马良”们
AI并非单一的魔法,它通过不同的技术路径来实现3D模型的生成。这些路径各有千秋,如同神话中神笔马良的不同画技,都能“点石成金”,创造出三维世界。
1. 生成对抗网络(GANs)- 相互博弈的“艺术家”与“评论家”
假设AI世界里有两位“大师”:一位是“生成器”(Generator),它努力学习创造逼真的3D模型;另一位是“判别器”(Discriminator),它则像一位火眼金睛的“评论家”,试图分辨出哪些模型是AI生成的“赝品”,哪些是真实的3D模型。它俩在训练过程中不断“斗法”:生成器力求以假乱真,骗过判别器;判别器则努力提升鉴赏水平,找出破绽。经过成千上万轮的较量,生成器最终会掌握以假乱真的高超技艺。
NVIDIA的GET3D就是这样的代表,它能从2D图片学习,生成带有精细纹理的3D模型。
其核心在于使用两个“潜码”(latent codes)——可以理解为模型的“基因编码”——分别定义3D模型的形状(通过SDF,即符号距离场,一种描述物体表面的数学方法)和表面纹理
2. 神经辐射场(NeRF)- 用光线和密度“绘制”三维空间
当你从不同角度拍摄了某个物体或场景的一系列照片。NeRF就像一个超级智能的AI,它不去直接构建一个由点、线、面组成的传统3D骨架模型,而是学习理解这个场景中光线的传播方式和每个点的“密度”。它学习到一个神奇的函数,只要你告诉它空间中的任意一个点坐标和观察方向,它就能告诉你这个点的颜色和“浓稠度”(密度)。
工作原理揭秘:
- NeRF以多张2D图像及其对应的相机拍摄位置和角度作为输入数据。
- 其核心是一个神经网络(通常是多层感知器MLP),这个网络学习将一个五维坐标(空间位置x,y,z 和 观察方向角度θ,φ)映射到该点的体积密度(volumetric density)和RGB颜色值。
- 当需要从一个新的视角生成图像时,NeRF会从这个虚拟相机发出无数条光线,沿着每条光线采集多个样本点,获取这些点的颜色和密度信息,然后通过一种称为“体渲染”(volume rendering)的技术,将这些信息合成为最终的2D图像。
Luma AI等工具让普通用户也能用手机拍个视频,就生成令人惊艳的3D场景。
3. 扩散模型(Diffusion Models) in 3D - 从"混沌"中创造秩序
一张完全被随机噪点覆盖的模糊图片。扩散模型训练的过程就是学习如何一步步地去除这些噪点,最终还原出一张清晰的图像。反过来,当需要生成新内容时,它就从一团纯粹的随机噪声开始,运用学到的“去噪”流程、参数,逐步将其“雕琢”成一个有结构、有细节的图像,或者构建一个3D模型。
3D领域的应用:
这个过程通常包含两个阶段:
- “前向扩散”(forward diffusion)阶段,AI不断地向一个清晰的3D模型添加噪声,直至其变成完全无序的随机数据。
- “反向扩散”(reverse diffusion)阶段,神经网络学习如何逆转这个加噪过程,从随机噪声出发,在文本提示(比如“一个红色的苹果”)或图像条件的引导下,逐步去除噪声,最终生成一个结构化的3D模型 。
扩散模型在2D图像生成领域(如DALL-E、Stable Diffusion等著名模型)已经取得了令人瞩目的成就,如今这股浪潮正席卷3D领域。它们有望生成质量极高、细节丰富且具有良好可控性的3D资产,为创作者带来更多可能性。
这三种主流的AI 3D生成技术——GANs、NeRF和扩散模型——实际上代表了AI在“创造”这件事上截然不同的几种“哲学思想”。
- GANs通过内部的“竞争机制”来提升生成质量;
- NeRF则更侧重于对场景的光学特性和空间几何进行细致入微的“理解与重建”;
- 而扩散模型则像一位从混沌中寻找秩序的雕塑家,通过“迭代式的精炼”从无到有地塑造出作品。
技术路径的多样性,恰恰说明了AI生成3D领域是一个充满活力和潜力的研究方向。不同的技术方法可以根据具体的3D任务需求(例如,NeRF更适合高保真地复现已有场景,而扩散模型和GANs则可能在生成全新的、富有想象力的物体方面更具优势)被灵活选用,甚至相互融合,催生出更强大的创作工具。
应用场景
- 🎮 游戏开发:快速生成角色、道具,大幅缩短开发周期
- 🥽 AR/VR:为虚拟世界填充丰富内容,提升沉浸感
- 🛍️ 电商购物:虚拟试穿、3D产品展示,让网购更直观
- 🎬 影视制作:降低特效成本,加速内容产出
- 🚗 自动驾驶:生成训练数据,让AI更好理解复杂场景
世界模型与JEPA架构:让AI拥有“常识”和“预见”
在AI领域,仅仅让机器学会“画画”, “编程” 或 “拍马屁”是远远不够的。一个共同的趋势是:让AI拥有对世界的基本理解能力,即所谓的“常识”,并能够基于这种理解进行推理和预测。“世界模型”概念及其核心架构JEPA,为我们描绘了通往更高级人工智能的一条可能路径。
当前AI的"认知盲区"
作为深度学习的奠基人,Yann LeCun对当前AI技术有着深刻的理解。他在深度学习发展初期就曾说过:
"The idea of deep learning was around, but it wasn't until we had the data, computing power, and improved architectures that it became practical."
——Yann LeCun
尽管大型语言模型在文本生成、对话理解等方面展现出惊人的能力, Yann LeCun"把一个鸡蛋从10楼扔下会怎样?",它可能给出听起来合理但可笑的回答。

LLMs更像是一个基于海量文本数据训练出来的“模式匹配高手”和“文本续写大师”,它们能够生成符合语法和统计规律的文本,但并不真正“理解”文本背后的含义,也“对潜在现实的了解有限,缺乏常识,缺少记忆,不能准确规划答案”。Yann LeCun甚至认为,单纯依赖自回归式的LLM(即逐字逐词生成内容)去实现通用人工智能(AGI)是“注定要失败”的,因为这类模型本质上“不可控、呈指数发散”,有着与生俱来的内在缺陷。
Yann LeCun指出了当前AI的核心问题:大型语言模型缺乏对物理世界的基本理解,它们"对潜在现实的了解有限,缺乏常识,没有记忆,而且无法规划"。
他用一个对比来说明这个问题:
"A dog has more common sense about the physical world than any AI system today."
——Yann LeCun(AI常识的缺失)
Yann LeCun坚信,AI若想达到人类甚至普通动物那样的智能水平,就必须构建关于世界如何运作的内部模型,即“世界模型”。这样的模型能让AI通过观察和互动来学习物理规律、理解因果关系、预测自身行为可能产生的后果,并据此进行规划。他用了一个比喻来解释这个概念:“婴儿在出生后的头几个月通过观察世界来学习基础知识。观察一个小球掉几百次,普通婴儿就算不了解物理,也会对重力的存在与运作有基础认知。” 这种通过观察和经验积累形成的对世界基本运作规律的直观理解,正是当前AI所欠缺的。
”世界模型“实际上是在呼吁AI研究领域的一次重要范式转变:从当前主流的、以大型语言模型为代表的“模式识别”和“统计关联”学习,转向构建能够对环境形成因果性、可预测性理解的系统。目前,LLMs因其缺乏常识、规划能力和对真实世界的深刻理解而受到诟病。而世界模型的核心目标恰恰是赋予AI“预测其行动的后果,并规划一系列行动”的能力。这代表了一种从生成统计上貌似合理的输出(如文本)到真正模拟和推理世界动态的质的飞跃。如果这一方向取得成功,未来的AI将不仅仅是复杂的模仿者,更有可能成为具备稳定性、适应性并能进行真正意义上推理的智能体。
需要明确的是,Yann LeCun对LLMs的批评并非全盘否定其价值。他承认LLMs在特定任务上“表现惊人”,例如在“协助写作、文本润色、编程等方面表现出色”。然而,他认为LLMs若作为通往AGI的主要或唯一路径,则“注定要失败”,因为它们充其量只是“大脑中的一小部分区域”。LLMs在未来的AI生态中仍会扮演重要角色(例如作为人机交互的接口),但要实现更高层次的智能,则需要一个更为全面和基础的架构,例如一个集成了世界模型的认知系统。
JEPA:通往智能的全新路径
为了实现构建世界模型的目标,Yann LeCun团队提出了一种名为JEPA架构(Joint Embedding Predictive Architecture,联合嵌入预测架构)的创新框架。
https://arxiv.org/pdf/2301.08243
Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
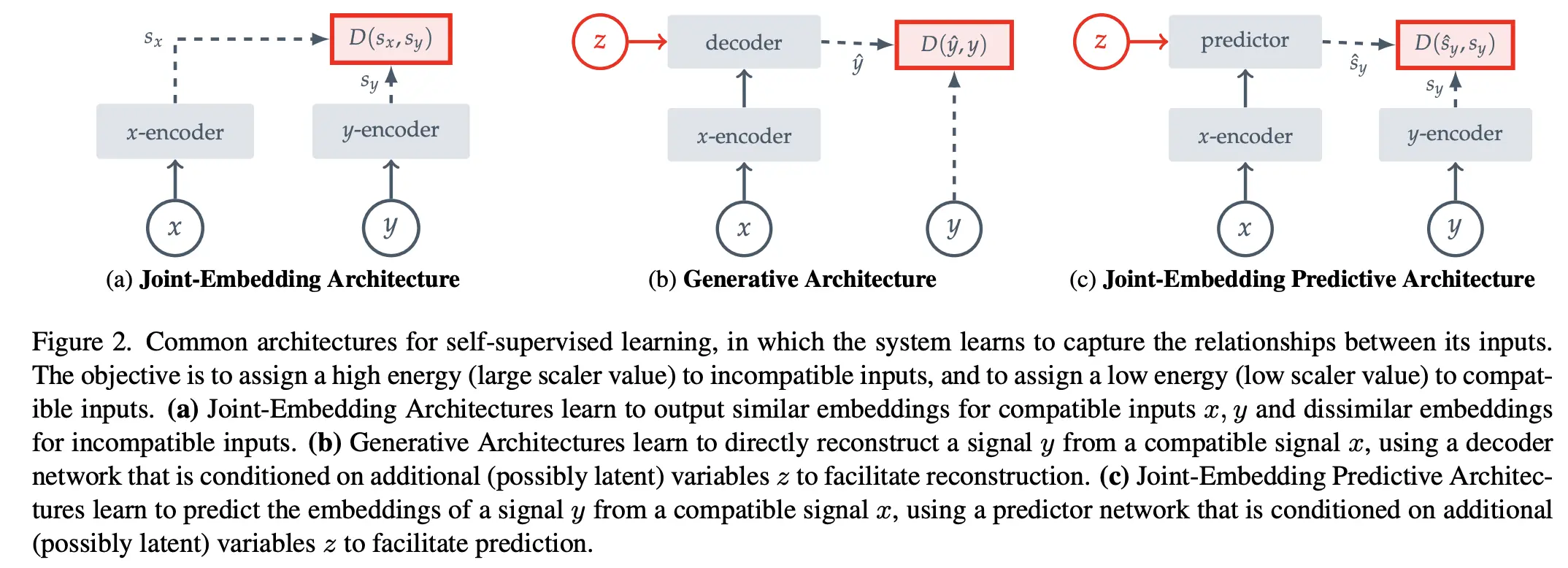
🎯 JEPA的核心思想:玩"填空游戏"学世界
JEPA的核心思想非常巧妙。它不再像传统的生成模型那样,试图去预测输入信号中的每一个细节(比如图像中的每一个像素点,或者视频中的每一帧画面),而是学习在一个“抽象的表示空间”(abstract representation space)中进行预测。
打个比方:当你看到一只猫的尾巴从小沙发后面一晃而过,你并不需要在脑海中精确地重建出被沙发遮挡住的那部分猫的每根毛发,就能判断出那里仍然是一只猫,并且大致知道它的形态。你的大脑拥有一个关于猫的抽象概念模型。
-
JEPA试图做的与此类似:它接收一个输入信号(比如图像的一部分,我们称之为
x),将其编码(转换)成一个抽象的、向量化的表示(embedding),然后尝试去预测另一个相关的输入信号(比如图像中被遮挡或未来将出现的另一部分,我们称之为y)的抽象表示。 -
关键在于,JEPA“仅捕获
x和y之间的依赖关系,而不显式生成对y的预测”。也就是说,它不直接画出y,而是预测y的“灵魂”或“代表(Representation)”。
通过在抽象空间进行预测,模型被激励去学习更高层次的、更具语义的特征(即事物的“意义”或“概念”),而不是纠缠于底层。相比于完美重建每一个像素,预测抽象表示在计算上通常更为高效的、琐碎的像素细节。这有助于避免模型“过于关注不相干的细节”
🔍 为什么这种方式更聪明?
传统AI模型就像"完美主义者",要把每个像素都画得一模一样。JEPA这种方式学习到的特征表示,可能对于输入信号中一些无关紧要的变化(如光照的微小改变、背景的细微扰动)更加不敏感,即更具稳定性。
JEPA对抽象预测的强调,可以看作是对许多生成模型中存在的“像素执念”的一种直接反思和修正。Yann LeCun认为,过度追求像素级别的完美生成或重建,反而会阻碍模型学习到真正的语义和常识。例如,他曾提到生成模型在生成“正确的人手”这类具有复杂结构和多变姿态的物体时常常遇到困难,这可能就是因为模型过于关注局部像素的逼真度,而忽略了对“手”这个概念的整体结构和功能的抽象理解。JEPA通过将预测任务从像素空间转移到抽象表示空间,其设计目标正是迫使模型去学习那些更具泛化能力、更能反映数据本质的语义特征。这种策略如果成功,有望催生出更像人类那样通过抽象化来理解概念的AI,从而在常识推理和对新情境的适应能力上取得突破。
I-JEPA与V-JEPA:从静态图像到动态视频的“世界理解”
基于JEPA的核心思想,Meta AI的研究人员已经开发出针对不同类型数据的具体模型实现,其中最具代表性的是I-JEPA(图像)和V-JEPA(视频)。
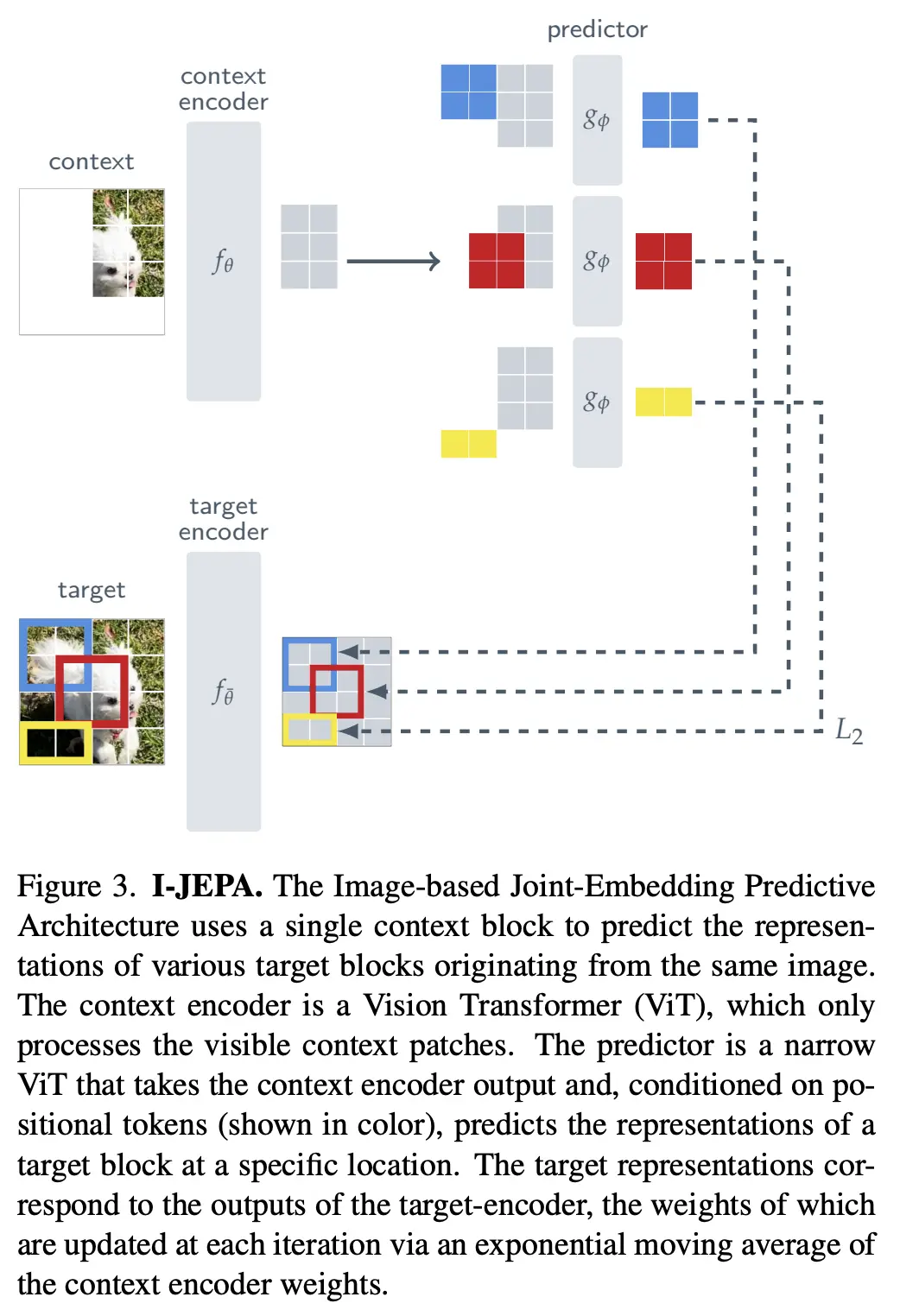
📸 I-JEPA (Image-based JEPA):理解图像中的"空间关系"
https://ai.meta.com/blog/yann-lecun-ai-model-i-jepa/
I-JEPA: The first AI model based on Yann LeCun’s vision for more human-like AI
I-JEPA从单张静态图像中学习。它首先将输入图像分割成若干图块(patches)。其中一个或多个图块作为“上下文块”(context block),其信息被编码器提取出来。然后,模型的目标是去预测图像中其他被遮蔽或未观察到的“目标块”(target blocks)的抽象表示。整个预测过程发生在学习到的嵌入空间(representation space)内,而非像素空间。一个关键的设计是其“多块掩码”(multi-block masking)策略,即选择足够大的目标块进行预测,以确保这些目标块包含丰富的语义信息,从而引导模型学习更有意义的特征。
I-JEPA旨在学习图像内部的统计规律和语义关联,而无需像传统的对比学习方法那样依赖大量人工设计的图像增强操作(如旋转、裁剪等),也无需进行像素级别的重建。
🎬 V-JEPA (Video-based JEPA):捕捉运动与变化的规律
2025年6月,Meta团队发布了V-JEPA 2,这是一个真正能够理解、预测和规划的AI系统:
https://arxiv.org/html/2506.09985v1
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
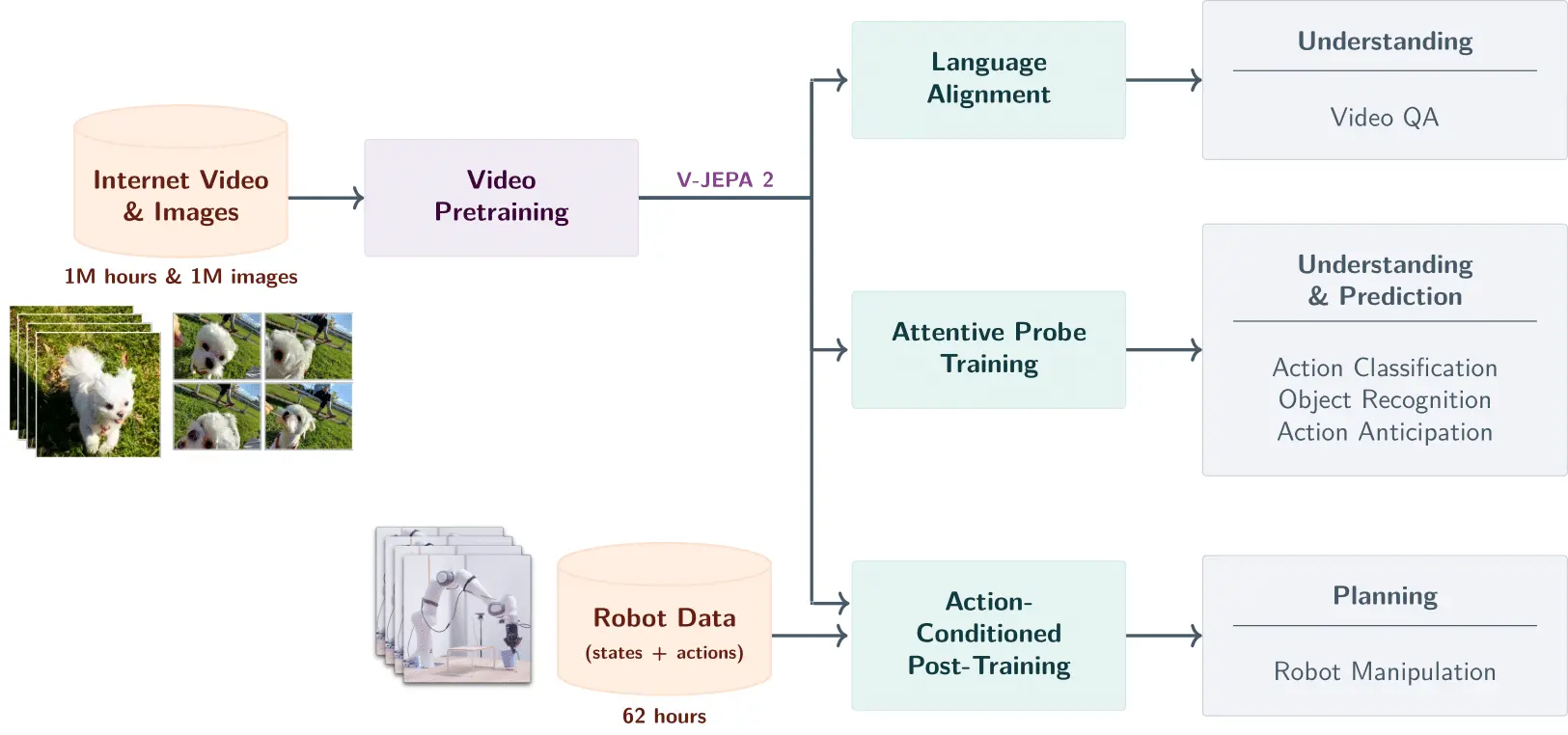
V-JEPA将JEPA的理念成功地从静态图像拓展到了动态的视频数据。它通过观察海量视频,学习预测视频中被遮蔽的、缺失的或未来可能出现的片段的抽象表示,同样避免了像素级别的重建。这种方式使得V-JEPA能够学习到关于物体运动、相互作用以及物理世界基本运作方式的知识。
V-JEPA在理解一些基本的“直觉物理”(intuitive physics)概念方面展现出巨大潜力。例如,通过观看视频,V-JEPA能够学习到“物体恒存性”(被遮挡的物体依然存在)、“物体连续性”(物体沿连续轨迹运动)和“物体固实性”(物体不能相互穿透)等常识性物理规律。在一些专门用于测试直觉物理理解能力的基准测试中,V-JEPA的表现显著优于传统的像素预测模型,甚至在某些方面超过了一些大型多模态语言模型。Meta官方也表示,V-JEPA的发布是“朝着让机器智能对世界有更扎实理解迈出的关键一步”。
从I-JEPA到V-JEPA的演进,清晰地展示了JEPA理念在处理日益复杂和动态数据方面的战略性扩展。I-JEPA首先在静态图像中验证了抽象预测学习的可行性及其在提取语义特征方面的优势。随后,V-JEPA将这一核心思想应用于包含时间维度和动态交互的视频数据。
V-JEPA 2的技术细节
性能表现
- 77.3%运动理解准确率:在Something-Something v2基准测试中创造新记录
- 39.7% Epic-Kitchens回忆率:比之前最佳模型提升44%,展现出色的动作预测能力
- 84.0% PerceptionTest准确率:结合大语言模型后的视频问答能力
- 超过100万小时视频训练:Meta团队使用前所未有的数据规模
最令人震撼的突破是:V-JEPA 2仅用62小时的未标注机器人视频,就实现了零样本机器人控制!
实验设置:
- 使用Droid数据集的62小时未标注视频
- 部署在两个不同实验室的Franka机械臂上
- 无需任何特定任务训练或奖励信号
任务表现对比:
| 任务类型 | V-JEPA 2-AC | 传统方法 | 提升倍数 |
|---|---|---|---|
| 到达目标 | 100% | 100% | - |
| 抓取杯子 | 65% | 15% | 4.3倍 |
| 抓取盒子 | 25% | 0% | ∞ |
| 搬运任务 | 80% | 15% | 5.3倍 |
💡 核心技术突破
Block-causal attention机制:革命性的注意力架构,让AI能够理解时空因果关系
表示空间自回归预测:避免像素级预测的复杂性,专注于语义理解
能量最小化规划:16秒内完成复杂动作规划,比竞争对手快15倍
技术架构对比:
视频输入 → V-JEPA 2编码器 → 抽象表示 → 动作条件预测器 → 机器人控制
↓ ↓ ↓ ↓ ↓
原始像素 语义特征 状态表示 动作序列 物理执行
关键创新:
- 冻结视频编码器:保持预训练知识,避免灾难性遗忘
- 轻量级预测器:仅3亿参数实现高效规划
- 交叉熵方法优化:快速动作规划,实时响应
JEPA与传统AI的本质区别
| 特征 | 传统生成模型 | V-JEPA 2 | GPT-4 |
|---|---|---|---|
| 目标 | 生成逼真的像素 | 理解事物间的关系 | 文本模式匹配 |
| 关注点 | 表面细节的完美 | 深层规律的把握 | 语言统计规律 |
| 学习方式 | 模仿和复制 | 理解和推理 | 模式记忆 |
| 智能程度 | 高级"复印机" | 初步的"理解者" | 语言专家 |
| 物理世界理解 | 无 | 85% | 30% |
| 动作预测 | 无 | 77.3% | 10% |
| 机器人控制 | 无 | 80%成功率 | 0% |
| 训练数据需求 | 大量标注数据 | 62小时无标注 | 数千小时文本 |
AI的真正突破:从模仿到理解
掌握基本的物理常识是构成通用智能和与物理世界安全有效互动的基础。这不仅仅是将同一模型应用于不同类型的数据,更是朝着理解世界更复杂层面(如时间演化、因果关系)迈出的重要一步。这类架构的持续发展,对于未来研发能够在真实物理环境中进行智能交互的机器人和具身智能体(embodied AI)至关重要。
JEPA架构的蓝图:通往更高级AI的模块
Yann LeCun所构想的JEPA,并不仅仅是一个孤立的模型,而是他宏伟蓝图中一个更庞大、更完整的“认知架构”(Cognitive Architecture)的核心组成部分——即世界模型模块。这个认知架构旨在模拟生物(尤其是人类)智能的某些关键方面,它由六个主要的可微分模块构成,协同工作以实现更高级的AI功能。
概念模块解析:
- 1. 配置器 (Configurator Module):扮演着类似大脑中“执行控制中心”或“规划师”的角色。它负责设定整体任务目标,协调其他各个模块的工作流程和参数,决定AI系统在特定任务中需要关注的重点,类似于人类在行动前进行规划和设定意图。
- 2. 感知模块 (Perception Module):相当于AI的“感官系统”(视觉、听觉等)。它从外部世界接收原始的感官输入数据(如图像、声音信号),进行初步处理和特征提取,并将与当前任务相关的信息传递给其他模块。它会过滤掉不相关的细节,专注于关键信息,就像人类在嘈杂环境中专注于与朋友对话一样。
- 3. 世界模型模块 (World Model Module):这正是JEPA大显身手的地方。该模块的核心功能是构建和维护一个关于环境如何运作的内部模型。它能够基于当前状态和感知输入,模拟世界的动态演化,预测不同行为可能导致的未来状态,并理解行为与结果之间的因果关系。
- 4. 成本模块 (Cost Module):这是一个“价值评估”模块。它计算一个“成本函数”,用以衡量不同状态或行为序列的“好坏”程度。这个成本可以包含内在的“驱动力”(如好奇心、探索欲,即内在奖励)和外在的、与特定任务相关的“目标函数”(如任务是否成功完成)。成本模块的输出指导着AI的学习和决策,让AI明白哪些行为是值得鼓励的,哪些是需要避免的。
- 5. 行动器模块 (Actor Module):基于世界模型的预测和成本模块的评估,行动器模块负责规划并输出一系列具体的行动指令,以期在满足约束条件的前提下,最大化预期回报(或最小化预期成本),从而达成配置器设定的目标。
- 6. 短期记忆模块 (Short-Term Memory Module):负责存储和更新关于世界当前状态、系统自身状态以及近期历史信息的动态记录,为其他模块的运作提供必要的上下文信息。
模块化设计的意义:这种模块化的设计思路,在一定程度上借鉴了复杂生物系统(包括大脑)的组织方式。它有望使得AI系统的设计、训练、调试和理解变得更加 tractable(易于处理)。例如,可以针对不同模块进行专门的训练和优化,或者在系统出现问题时,更容易定位到故障发生的模块。
Yann LeCun提出的这个包含六大模块的认知架构,其核心是作为世界模型的JEPA,构建一种不仅仅擅长执行狭隘任务,而是具备更全面、更接近人类认知结构的AI系统。这个系统旨在整合感知、推理、规划和行动等多种高级认知功能。这种架构与当前流行的、试图用一个巨大的、端到端的单一网络模型来解决所有问题(所谓的“大力出奇迹”)的思路有所不同。它的目标是实现“自主智能”(autonomous intelligence),这意味着AI需要具备比现有系统更广泛的能力集合。如果这一宏伟的架构愿景得以实现,未来的AI系统可能会更加灵活、适应性更强,其内部运作机制也可能更容易被人类理解和分析(例如,通过检查不同模块的表征和输出来探究其决策过程)。这将是朝着通用人工智能(AGI)迈出的重要一步,有望催生出能够处理更复杂、需要长远规划和综合智能的现实世界任务的AI。
虽然通往真正“懂世界”的AI之路依然漫长,但无论是生成式3D模型的日新月异,还是JEPA这类旨在构建更深层认知能力的架构创新,都清晰地指明了方向。我们有理由对AI的未来抱持乐观:一个不仅能力更强大,而且在认知和推理方式上更接近人类智慧的AI时代,或许正在加速到来。而这种进步,最终将可能导向更普惠、更负责任、也更能造福人类社会的人工智能。