
7 月 18 日,OpenAI 发布了 GPT-4o mini,一款便宜轻量级的多模态大型语言模型。 它支持文本和图像,比 Gemini Flash、Claude Haiku 和 GPT-3.5 Turbo 更准确、更快、更便宜。
DeepL宣布实施一个大型语言模型,专门用于语言翻译和语法检查。 语言学家对DeepL的翻译输出的评价是Google Translate的1.3倍,是ChatGPT-4的1.7倍,是Microsoft Translate的2.3倍。
我们将介绍并解释过去一周感兴趣的生成式 AI 技术,我们将介绍 Mem0 和 Qwen2-Audio,前者是一种记忆函数,可以长时间记录 AI 与用户之间的交互内容,并将 LLM 对用户的反应个性化,后者是一种擅长理解语音的大型语言模型。
Qwen2-Audio

阿里巴巴集团开发出擅长语音理解的大型语言模型“Qwen2-Audio”
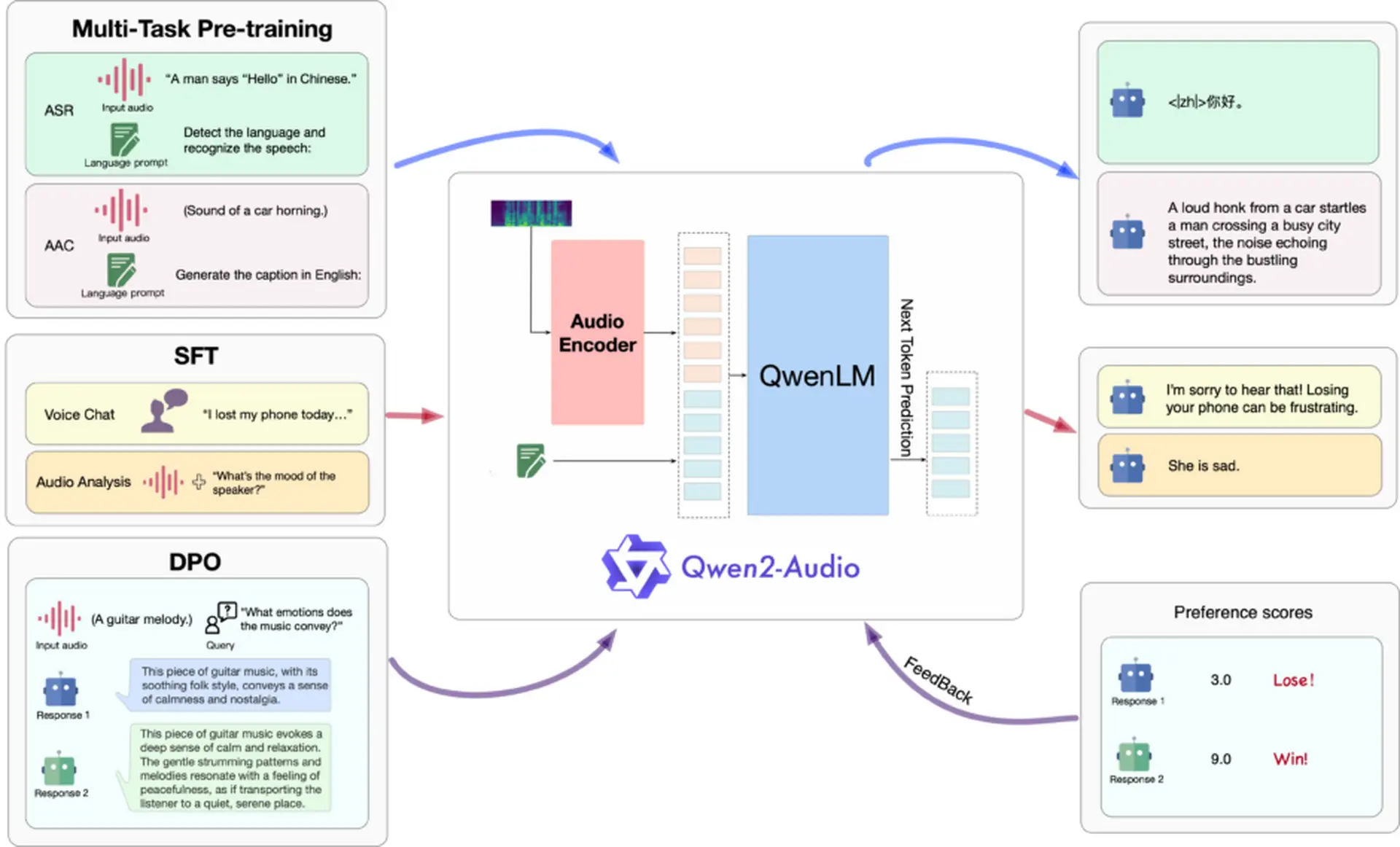
阿里巴巴集团的Qwen团队推出了一款大规模的口语模型Qwen2-Audio。 该模型是语音处理和自然语言处理的混合体,可以接受各种形式的语音输入,并生成高级语音分析和对语音指令的适当文本响应。
在Qwen2-Audio的开发中,研究团队摒弃了使用复杂层次标签的传统方法,转而采用利用自然语言提示的简化过程。 这种新方法大大增加了模型的多功能性,并获得了更灵活的遵循指令的能力。 我们还显著增加了用于预训练的数据量,以扩展模型的知识。
Qwen2-Audio提供两种不同的语音交互模式。 语音聊天模式允许用户完全通过语音自由地与模型进行交互,而无需输入文本。 另一方面,在语音分析模式下,用户可以提供语音数据和文本指令的组合,进行深入的语音分析。
在性能评估中,Qwen2-Audio在许多方面都表现出色。 在 AIR-Bench 测试中,它在理解和响应语音、环境声音、音乐和复合语音方面优于 Gemini-1.5-pro 等先前型号。 自动语音识别在LibriSpeech数据集中实现了1.6%的低WER(单词错误率),在CoVoST2数据集的多个语言对中,语音翻译的表现优于之前的模型。 此外,它还在情感识别和语音分类任务中实现了高精度。
Qwen2-Audio Technical Report
论文地址:https://arxiv.org/abs/2407.10759v1
GitHub 地址:https://github.com/QwenLM/Qwen2-Audio
IMAGDressing-v1

用于产品展示的装扮虚拟换装技术“IMAGDressing-v1”
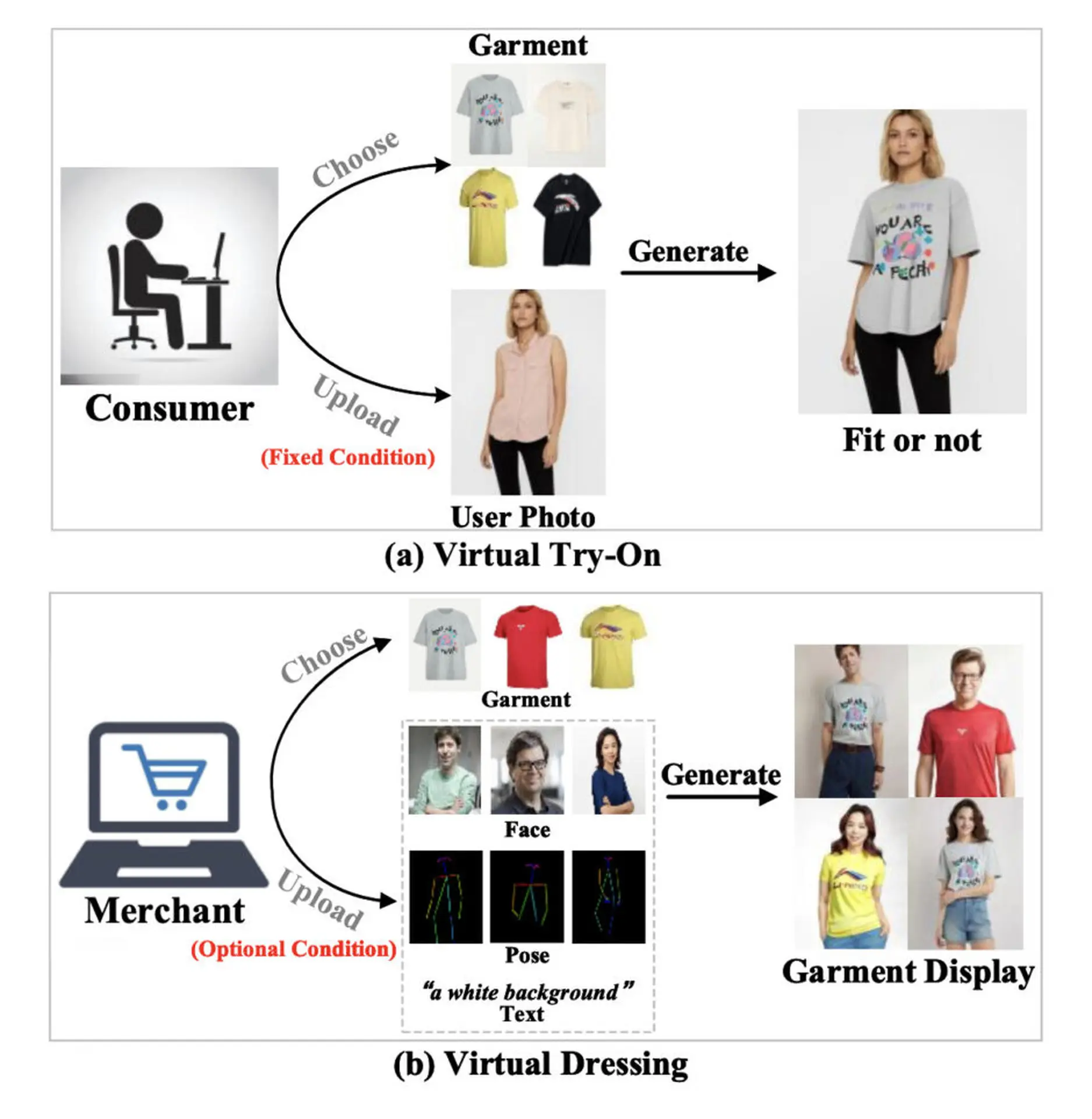
在线购物领域,虚拟 trion (VTON) 技术正在迅速发展。 然而,到目前为止,VTON技术主要是为消费者设计的,它一直无法充分满足卖家从多个角度展示他们的服装的需求。
为了应对这一挑战,一个研究团队开发了一种新的“虚拟敷料”(VD)技术。 VD技术旨在生成一个人的肖像图像,其面部,姿势,背景等可以随意改变,以对抗固定的衣服。
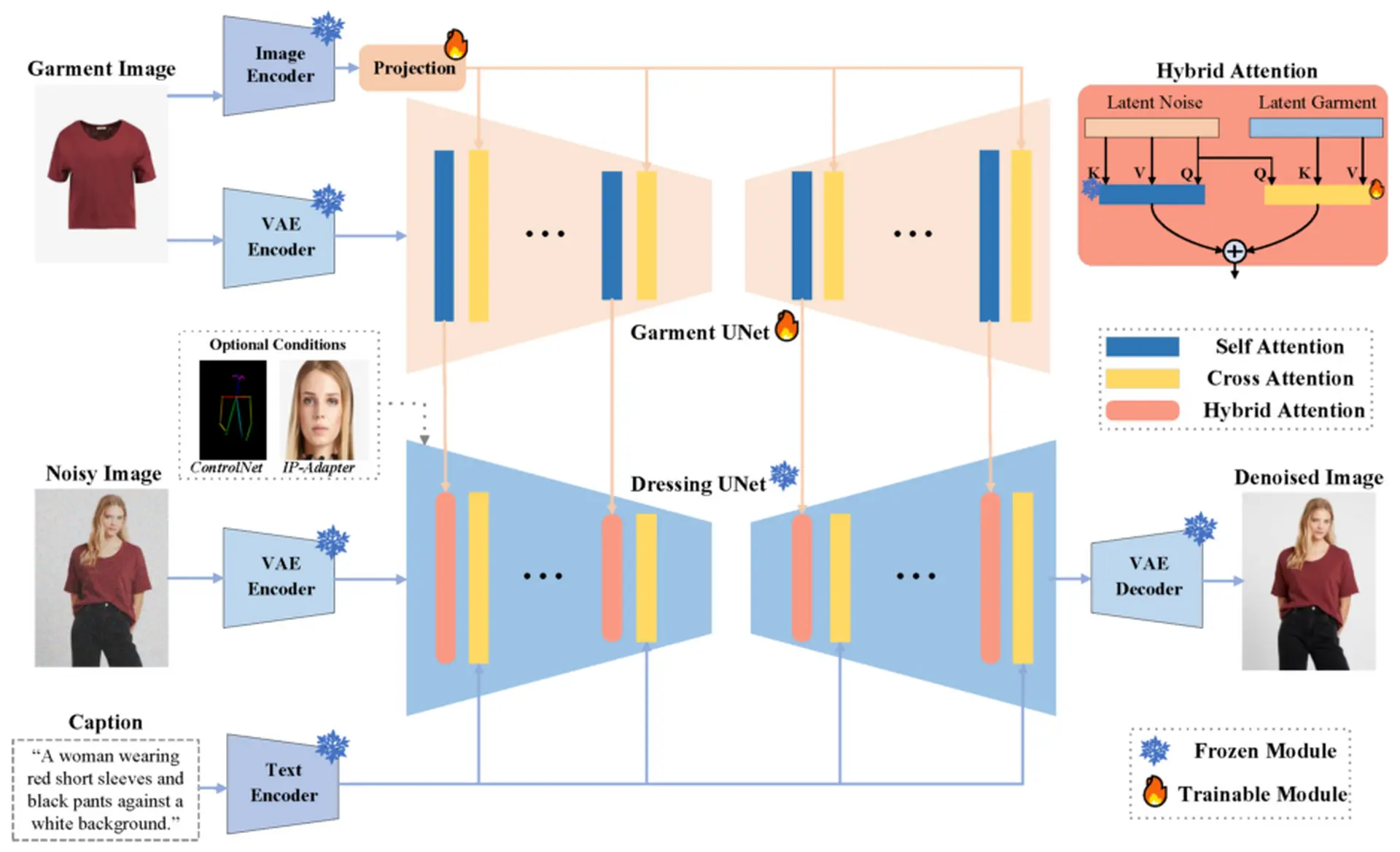
研究团队开发的“IMAGDressing-v1”模型在捕捉服装的最小特征方面表现出色。 此外,文本输入可用于控制背景和其他场景,同时适当反映服装的特性。 此外,IMAGDressing-v1 可以与 ControlNet 和 IP-Adapter 等扩展插件结合使用,以进一步提高生成图像的多功能性和可控性。
作为这项研究的一部分,我们还发布了IGPair,这是一个包含超过300,000双服装和穿着图像的大型数据集。 此数据集包含高分辨率影像和详细说明。
实验结果表明,IMAGDressing-v1的性能优于现有的先进技术。 特别是,它因其能够在各种场景中生成自然的人像图像而备受推崇,同时保留了服装的精细特征。
IMAGDressing-v1:可定制的虚拟着装
论文地址:https://arxiv.org/abs/2407.12705v1
GitHub 地址:https://github.com/muzishen/IMAGDressing
Mem0

Mem0,一种用于个性化 AI 的记忆功能,可记录与 AI 的交互,并从为用户优化的响应内容中学习
Mem0 是为大型语言模型 (LLM) 开发的个性化 AI 内存功能。 该系统通过与用户的对话收集信息并不断学习,从而不断发展。 Mem0 的核心功能是通过 AI 自动管理内存。 除了组织和关联信息外,它还学习用户的使用模式以提高内存质量。
这样就可以提供针对每个用户优化的信息,并根据个人的兴趣和习惯做出响应。 你使用它的次数越多,它就会变得越聪明,你就能提供的相关信息就越多。 此外,Mem0 在不同的应用程序中保持一致的内存,提供无缝的体验。
Mem0 的一些常见用例包括个性化学习助手、客户支持 AI 代理、医疗保健助理、虚拟伴侣和游戏 AI。 这些应用程序利用长期记忆来记住用户的偏好、过去的交互和进度,以提供更加个性化和有效的体验。
Mem0: The Memory Layer for Personalized AI
论文地址:
GitHub 地址:https://github.com/mem0ai/mem0
Shape of Motion

谷歌和其他公司开发了一种名为“运动形状”的技术,可以将图像转换为移动的3D环境
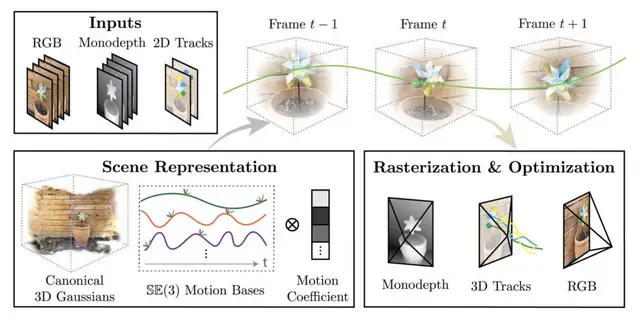
“运动形状”是一种从单个视频生成运动图像的 3D 模型的技术。 虽然在重建静态 3D 环境方面取得了进展,但从单个视频重建移动 3D 场景是一项非常困难的挑战。
运动形状的特点是 3D 空间表示为许多小 3D 点(3D 高斯溅射)的集合,这些点随时间移动和旋转以再现运动。 这种方法可以有效地表示和操纵具有复杂运动的 3D 环境。
它还有效地集成了来自不同来源的互补线索,例如单目深度图和远程 2D 跟踪(在较长时间内跟踪视频中对象或特定点的运动),以提供动态场景的全球一致表示。
研究团队评估了合成和真实世界的视频数据集。 因此,Shape of Motion在远距离2D/3D跟踪精度和动态场景的新视角合成质量方面都明显优于现有方法。
Shape of Motion: 4D Reconstruction from a Single Video
论文地址:https://arxiv.org/abs/2407.13764
GitHub 地址:https://github.com/vye16/shape-of-motion/

