Canonical 将 Kubernetes 发行版支持时间延长至十倍
原文:Canonical Extends Kubernetes Distro Support to a Dozen Years
Canonical 是什么
科能软件有限公司(Canonical Ltd.) 是一家私人公司,由南非的企业家马克·沙特尔沃思创建,主要为了促进开源软件项目。其知名的产品与项目为 Ubuntu, Launchpad, Bazaar, TheOpenCD, Ubuntu One 等。
做了什么
2025 年 2 月 11 日,Canonical 宣布从 Kubernetes 1.32 开始,会提供 12 年的安全维护和支持承诺。像 Ubuntu 一样,从 Kubernetes 1.32 LTS 开始,Canonical 将每两年发布一个 Kubernetes LTS 版本。
为什么要这么做
上游的 Kubernetes 发行节奏是很快的,每 4 个月发行一个新版本,并提供为时 14 个月的安全维护。频繁的 Kubernetes 版本升级会破坏业务的连续性、耗费时间且需要运维。开发者和新部署 Kubernetes 集群的用户往往喜欢最好和最新的发行版。但是对于已经部署集群的企业级用户来说,他们优先考虑的是稳定,同时对于新版本中的新功能并没有很强的需求,所以并没有多少会喜欢最新的发行版,也不愿意经常升级。
其他厂商的做法
OpenShift
Red Hat 宣布 OpenShift 4.14 及后续的偶数版本的 EUS (Extended Update Support) 时间将延长至 12 个月,也说明这些 OpenShift 版本的完整生命周期达到 3 年。
Announcing additional Extended Update Support for OpenShift 4.14 and beyond!
Microsoft Azure Kubernetes Service (AKS)
Microsoft Azure Kubernetes Service (AKS) 对 (GA) Kubernetes 版本提供 12 个月的支持,对 LTS 版本提供 2 年的支持。目前 AKS 提供的 LTS Kubernetes 版本包括 1.27、1.30。
Supported Kubernetes versions in Azure Kubernetes Service (AKS)
相关文章
Canonical announces 12 year Kubernetes LTS
Canonical Extends Kubernetes Distro Support to a Dozen Years
KubeSphere 产品生命周期管理政策公告正式发布
原文:KubeSphere 产品生命周期管理政策公告正式发布
什么是产品生命周期
根据维基百科的定义,产品生命周期(英语:Product lifecycle,缩写:PLC)是产品的市场寿命,即一种新产品从开始进入市场到被市场淘汰的整个过程。具体包含以下阶段。
引入期
引入期是指产品从设计产出直到投入市场进入测试阶段。新产品投入市场,便进入介绍期。此时产品品种少,顾客对产品还不了解,除少数追求新奇的顾客外,几乎无人实际购买该产品。生产者为了扩大销路,不得不投入大量的促销费用,对产品进行宣传推广。
成长期
当产品进入引入期,销售取得成功之后,便进入成长期。成长期是指产品通过试销效果良好,购买者逐渐接受该产品,产品在市场上站住脚并且打开销路。这是需求增长阶段,需求量和销售额迅速上升。生产成本大幅度下降,利润迅速增长。与此同时,竞争者看到有利可图,将纷纷进入市场参与竞争,使同类产品供给量增加,价格随之下属,企业利润增长速度逐步减慢,最后达到生命周期利润的最高点。
成熟期
指产品走入大批量生产并稳定地进入市场销售,经过成长期之后,随着购买产品的人数增多,市场需求趋于饱和。此时,产品普及并日趋标准化,成本低而产量大。销售增长速度缓慢直至转而下降,由于竞争的加剧,导致同类产品生产企之间不得不加大在产品品质、花色、规格、包装服务等方面加大投入,在一定程度上增加成本。
衰退期
指产品进入淘汰阶段。随着科技的发展以及消费习惯的改变等原因,产品的销售量和利润持续下降,产品在市场上已经老化,不能适应市场需求,市场上已经有其它性能更好、价格更低的新产品,足以满足消费者的需求。此时成本较高的企业就会由于无利可图而陆续停止生产,该类产品的生命周期也就陆续结束,以至最后完全撤出市场。
为什么需要产品生命周期管理
根据 atlassian 的介绍,产品生命周期管理 (PLM) 可帮助企业规划和执行产品生命周期的各个方面,从设计和开发到分销、营销和销售。它能加快产品上市速度,降低成本,并有助于有效管理资源。PLM 使用标准化的产品交付方法,将跨职能团队联系起来。它可以改善沟通,促进协作解决问题,并将所有人聚集在一起实现共同的目标。
PLM 是一种系统,用于将来自不同领域(开发、营销、服务和合作伙伴)的不同信息、流程和人员整合到统一的端到端产品开发战略中,并对其进行管理。它将所有必要的信息和活动进行数字化和系统化。
KubeSphere 的产品生命周期管理政策是什么
KubeSphere 这篇文章从产品版本定义、服务与支持等级定义、产品生命周期说明等方面向外界介绍他们的规则与定义。
产品版本定义
KubeSphere 产品软件版本号格式包括主版本号 (Major Version)、次版本号 (Minor Version)、补丁版本号 (Patch Version) 和热修复版本号 (HotFix)。
- 主版本号:主版本号的设置通常表示软件有重大更新或变化,这可能包括全新的产品架构、功能模块、操作体验或与旧版本不再兼容的变更。
- 次版本号:次版本号的设置表示软件有一般的更新或改进,这可能包括新增功能模块、性能改善、安全性强化或兼容性增强等。
- 补丁版本号:补丁版本号的设置表示软件有较小的修复或优化,这通常用于修复错误、改进稳定性、或优化产品体验等。补丁版本不会开启新的产品生命周期。例如,KSE v4.1.3 将共享 KSE v4.1 的生命周期。
- 热修复版本号:热修复是指对软件进行的紧急修复,其通常用于解决如无法继续的阻塞或严重的安全隐患导致客户业务停滞或没有临时方案的问题。热修复仅就对应发现的严重问题进行修复和针对性测试,不会像上述三类正式产品版本一样进行全量的测试验证,是解决紧急问题的临时性处置措施。最佳方案依然是升级至后续正式产品版本。热修复通常不改变产品版本号的主要部分,仅在现有版本上立即应用。
服务与支持等级定义
KubeSphere 的产品与服务涉及多种类型的服务与支持。根据等级的划定,可分为:FS(Full Support,全面服务与支持)与 ES(Extended Support,延长服务与支持)。
KubeSphere 服务与支持等级表如下:
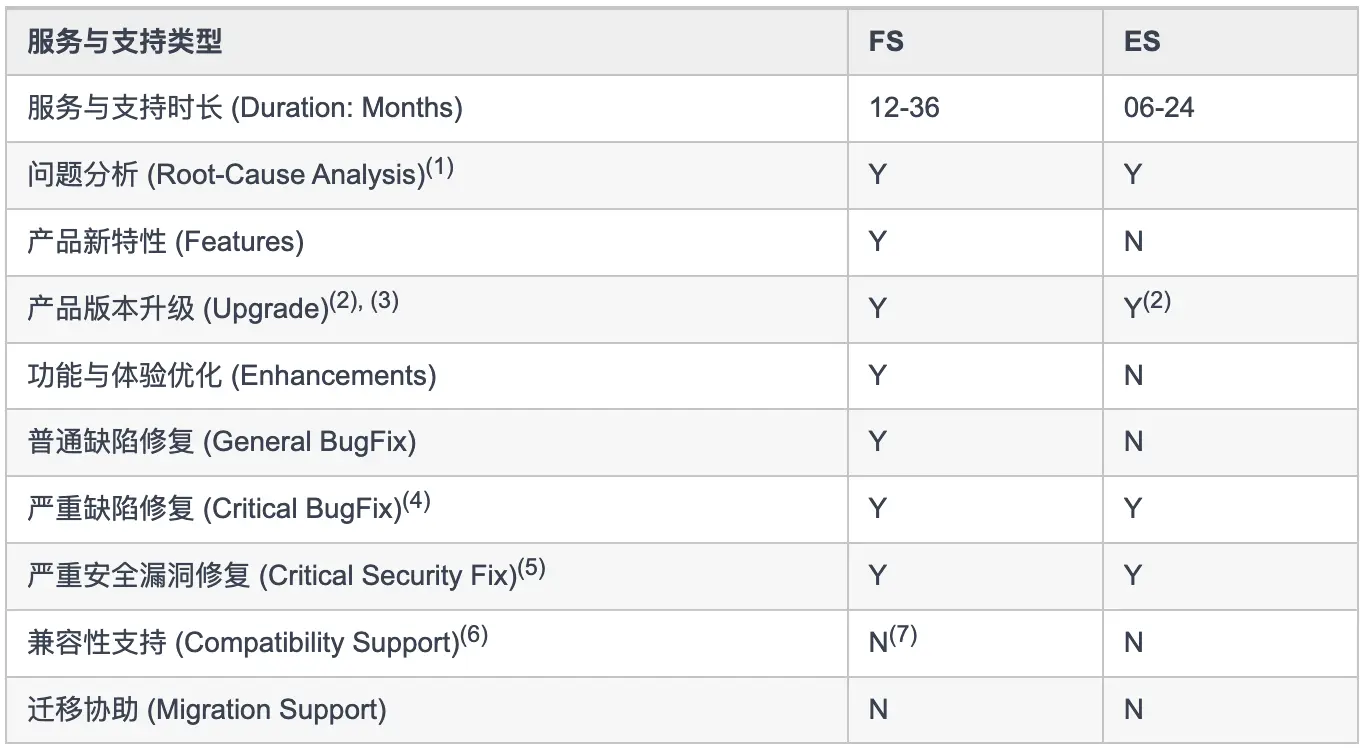
下面对每一项进行具体的说明:
- 服务与支持时长:不同等级的服务与支持时长。例如 KubeSphere 这里有“全面服务与支持”和“延长服务与支持”两种,用于说明这两种等级的服务与支持时长。
- 问题分析:指对非产品自身、从外部引入的第三方软硬件带来的问题进行分析与支持。如客户自己开发的业务系统、自采购硬件设备、自行部署的第三方软件等,青云科技仅承诺协助性分析与支持,不承诺能定位或解决此类非青云科技提供的产品的问题。
- 产品新特性:指是否还会支持新特性。
- 产品版本升级:指是否支持产品版本升级。
- 功能与体验优化:指是否还会提供使用优化的改进。
- 普通缺陷修复:指是否会修复普通缺陷。
- 严重缺陷修复:指是否会修复严重缺陷。严重缺陷指客户、产品经理、测试经理、产品技术负责人、技术支持工程师及项目经理等多方共同认定下,明确影响到客户业务连续性、稳定性、可靠性等的问题。
- 严重安全漏洞修复:指是否会修复严重安全漏洞修复。严重安全漏洞修复指 CVSS 大于等于 7 的安全漏洞问题。
- 兼容性支持:兼容性支持取决于软件主版本、次版本发布时的适配兼容情况,在后续的产品生命周期中不再改变。FS 不再新增兼容适配。兼容性主要包括兼容 Kubernetes 新版本、新的 CPU 架构、新的 OS 类型或架构、OS 的新版本等。
- 迁移协助:指的是帮助用户将现有的应用程序、服务或数据从一个环境迁移到 KubeSphere 的过程。
产品生命周期说明
KubeSphere Standard 类型产品版本说明表如下:
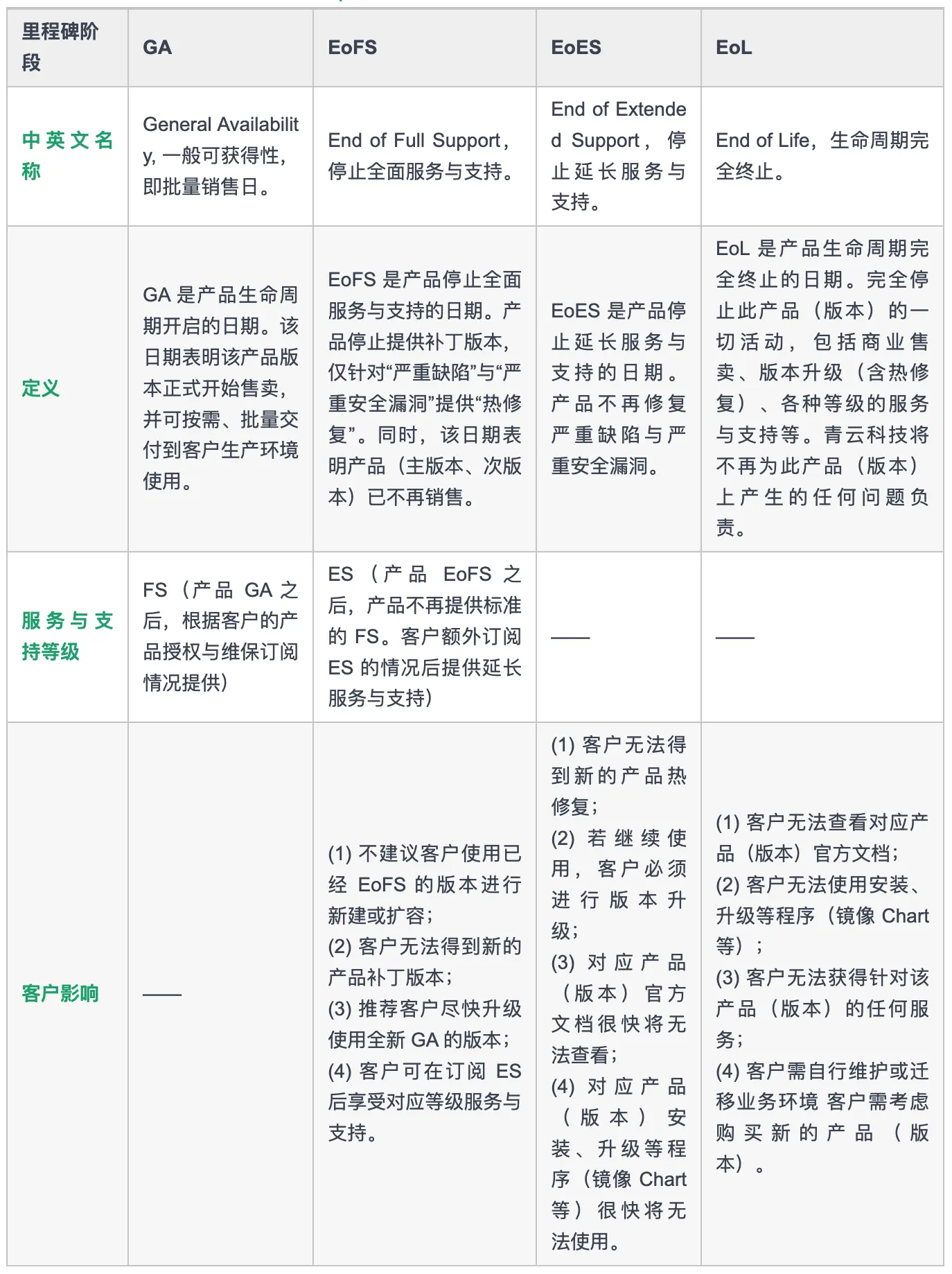
相当于 GA 日期是一个产品版本的生日,EOL 日期代表产品死亡时间。EoFS 代表进入减少对其投入的阶段,仅保证基于现有功能可以使用,会修复一定程度的漏洞,所以如果用户不希望升级还是可以留在这个阶段,但需要明白这个产品版本的生命已经进入倒计时,需要规划升级了。EoES 代表不再对其进行任何投入,不对其可用性提供任何保障,用户需要进行升级以获得相关服务与支持。
KubeSphere 企业版、开源版产品生命周期时间表
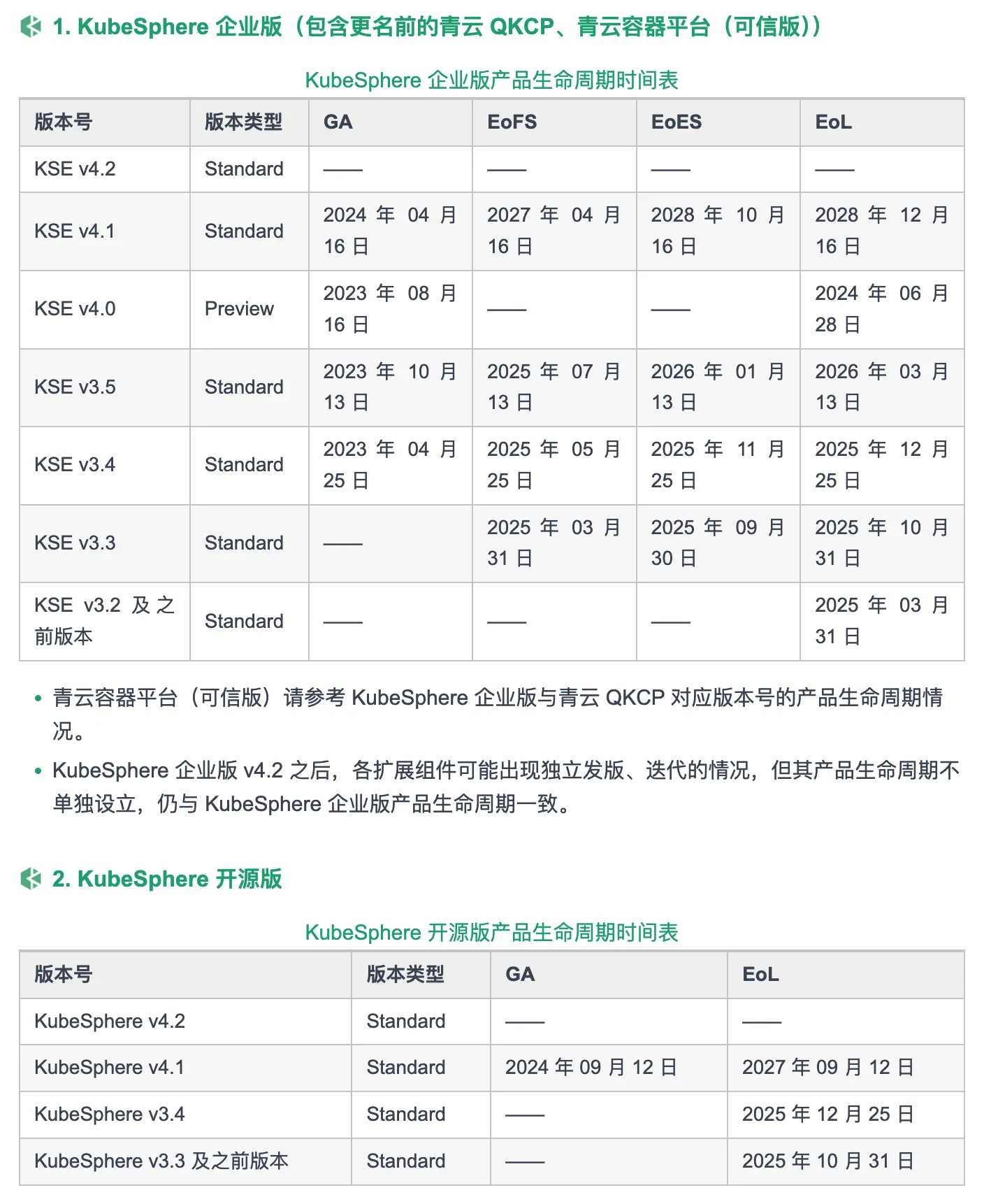
可以看出,对于 Standard 版来说,一个版本的生命周期是有越来越长的趋势的。例如相较于 KSE v3.5 为期 2 年 5 个月的生命周期,KSE v4.1 的生命周期达到了 4 年 8 个月。
OpenShift 4.18 新功能
原文:
Red Hat unveils OpenShift 4.18: Enhanced security and virtualization experience
Guide to observability with Red Hat OpenShift 4.18
根据发布说明,可以看到主要在以下几方面进行了更新:
- 通过用户定义网络 User Defined Networks (UDNs) 和边界网关协议增强网络灵活性,用于 Pods 和虚拟机(VM)
- 支持在多个 vSphere vCenter 群集中部署 OpenShift
- 利用 oc-mirror v2 的性能提升,加速镜像仓库同步(Registry Mirroring)
- Operator Lifecycle Management 提供了增强的安全性和 GITOPS 集成
- 展了对客户管理的 OpenShift 在主要云提供商中的裸金属支持
- 日志、分布式追踪等可观测性功能的增强
...
直观感受是重点对网络架构、IaaS 适配、可观测性进行了相关的迭代。可能需要持续多关注几个版本,再摸到产品规划层面的脉络。
OpenShift 的 cluster observability operator 正式 GA
原文:Announcing the general availability of cluster observability operator
cluster observability operator 是什么
cluster observability 是一个单一入口点的可选 operator,主要用于:
- 创建与默认的集群内监控系统独立的独立监控堆栈
- 部署用于 Red Hat OpenShift 和 Red Hat 高级集群管理(Red Hat Advanced Cluster Management for Kubernetes)的可观测性可视化和分析组件
cluster observability operator 的价值
- 可扩展性:添加更多指标
- 多租户支持:每个命名空间部署多个堆栈或为多个命名空间部署单个堆栈
- 可扩展性:根据需要创建 cluster observability operator 管理的监控堆栈
- 灵活性:cluster observability 与 Red Hat OpenShift 发布周期分离
- 高度可定制:cluster observability operator 可以将自定义资源中某些可配置字段的所有权委托给其他组件
安全项目 Kubescape 达到孵化状态
原文:Kubescape Achieves CNCF Incubation Status
Kubescape 是什么
Kubescape 是一个开源 Kubernetes 安全平台,提供全面的安全保障,涵盖整个开发和部署生命周期。它提供强化、态势管理和运行时安全功能,以确保为 Kubernetes 环境提供强大的保护。利用基于 eBPF 的 Kubernetes 节点事件监控来实时检测安全威胁。
可观测性中的 Data lake
原文:Observability: Do You Need a Data Lake?
Data lake 是什么
Gartner 给出了如下定义:
A data lake is a semantically flexible data storage repository combined with one or more processing capabilities. Most data assets are copied from diverse enterprise sources and are stored in their raw and diverse formats so they can be refined and repurposed repeatedly for multiple use cases. Ideally, a data lake will store and process data of any structure, latency or container, such as files, documents, result sets, tables, formats, binary large objects (BLOBs) and messages.
数据湖是一个语义灵活的数据存储库,结合了一种或多种处理能力。大多数数据资产来自不同的企业来源,并以原始和多样的格式存储,以便可以多次精炼和重新利用,适用于多个用例。理想情况下,数据湖能够存储和处理任何结构、延迟或容器的数据,如文件、文档、结果集、表格、格式、二进制大对象(BLOBs)和消息。
为什么需要 Data lake
随着技术架构越来越复杂,团队中的用户希望能够对实时和历史数据进行日志分析、指标查看、数据追踪等。并希望通过整合来自不同系统的数据,获得更全面的洞察,从而提升系统的可观测性和故障响应能力。
而 Data lake 支持数据收集和高级分析,是对传统数据仓库的补充。例如,Data lake 中庞大的源数据存储库支持广泛、灵活且无偏见的数据探索,这是数据挖掘、统计、机器学习 (ML) 和其他分析技术的先决条件。Data lake 还可以提供可扩展和高性能的数据采集、准备和处理,既可以提炼并加载到数据仓库中,也可以在 Data lake 内进行处理。所以非常适合用在可观测性的场景中。
Data lake 的缺点
- 延迟高
- 成本高,包括存储成本、集成成本、维护成本等
AI 相关的一些技术
大规模 LLM 负载均衡:带有有界负载的一致性哈希
原文:LLM Load Balancing at Scale: Consistent Hashing with Bounded Loads
操作大型语言模型(LLMs ) 在实际场景中大规模运行需要多个后端副本。副本间负载平衡算法通过影响现代推理引擎固有的缓存动态,极大地影响了整个系统的性能。
这种需求是否会影响 LB 的功能和优化迭代方向。
HAMi:异构 AI 计算虚拟化中间件
HAMi(前身为 'k8s-vGPU-scheduler')是一个面向 Kubernetes 的异构设备管理中间件。它可以管理不同类型的异构设备(如 GPU、NPU、MLU、DCU 等),实现异构设备在 Pod 之间的共享,并基于设备拓扑和调度策略做出更优的调度决策。
当对一项和 AI 相关的技术不够清楚时,有时候会看一下博云的 AI 产品功能图。博云在 AI 这个领域真的是深耕。
如何通过自助服务方法构建多租户平台
原文:How to Build a Multi-Tenancy Internal Developer Platform with GitOps and vCluster
概念介绍
什么是平台工程
在介绍内部开发人员平台之前,先介绍下平台工程。
根据 Gartner 的定义,平台工程(Platform Engineering)是构建和运营自助式内部开发平台的一门学科。每个平台都是一个由专门的产品团队创建和维护并通过与工具和流程对接来支持用户需求的层。平台工程的目标是优化生产力和用户体验并加快业务价值的实现。拥有多个开发团队的企业,常常面临优先事项彼此竞争、多样化的工具和技术管理、建立最佳实践以及遵循安全和合规标准等方面的挑战。
值得注意的是,Gartner 将平台工程预测为 2024 年十大战略技术趋势之一,与其并列的还有 AI 相关的各种领域。
另外在原文中的定义是:
-
Is ABOUT abstracting or composing individual services, building an overlay, and making them self-service consumableby the end user. 是关于抽象或组成单个服务,构建覆盖层并使它们可供最终用户自助使用。
-
Is NOT ABOUT abstracting or composing individual services, building an overlay, and using them internally to provide infrastructure. If that’s your approach, you’re not a Platform Team — you’re a Managed Infrastructure Team. 不是关于抽象或组成单个服务,建立覆盖层并在内部使用它们来提供基础架构。如果那是您的方法,那么您不是平台团队,而是一支由托管的基础架构团队。
这个定义介绍了基础设施管理和平台工程的区别:传统的基础设施管理团队主要负责配置和维护基础设施资源,而平台工程则关注如何使这些资源更易于使用,创建自助服务的机制,使最终用户能够根据自己的需要直接获取服务,而无需与平台团队直接交互。
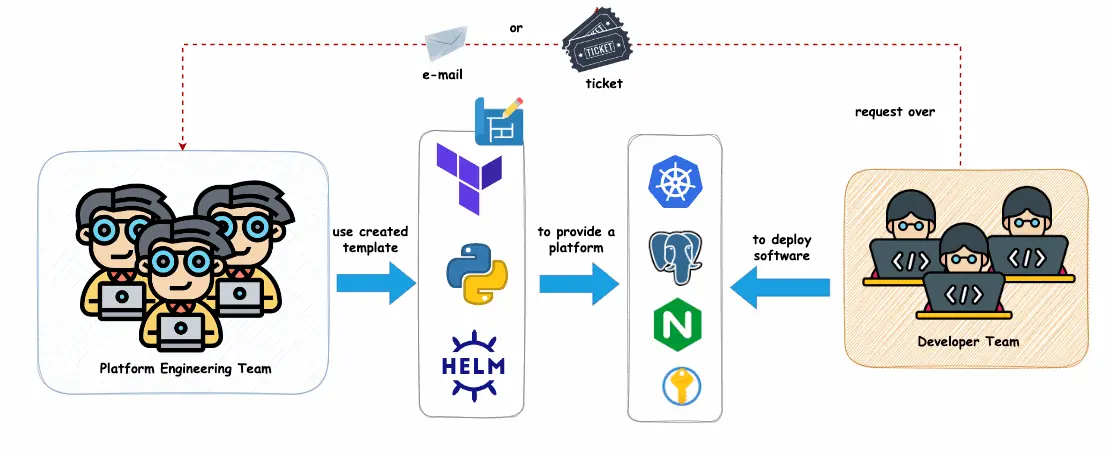
基础设施团队如何工作
基础架构团队以这样的方式运作:开发人员通常通过电子邮件或票证提交诸如 PostgreSQL 数据库、Vault 实例或托管 Kubernetes 之类的基础架构的请求。然后,团队代表开发人员提供这些服务并管理升级,扩展和维护。例如,当开发人员需要新的 Vault 或数据库升级时,是由托管基础架构团队进行处理而不是开发人员。
什么是内部开发人员平台
根据 RedHat 的定义,内部开发人员平台(IDP)由一系列标准化的自助服务工具和技术组成,供开发人员来创建和部署代码。IDP 的宗旨是通过整合和简化开发流程的组成要素,使开发团队的日常工作变得更易管理、更加高效且更方便协作。
应用开发人员是 IDP 的主要用户, 平台工程师负责初始配置和维护。对于平台工程师而言,IDP 可以被视为一款经过精挑细选的集成产品,旨在为开发人员提供在应用的整个生命周期中实施应用所需的工具。
简言之,平台团队会根据平台工程的思路,提供一个具体的 IDP 产品。
IDP 的建设要点
IDP 正如三层的汉堡一样,真正的美味来自中间层。中间层使每个 IDP 独一无二并可以彰显其价值。而可自定义的中间层,取决于公司的自动化级别、工具堆栈和整体策略。所以,并不能只购买现成的 IDP,而是需要去构建它以满足组织的具体需求。
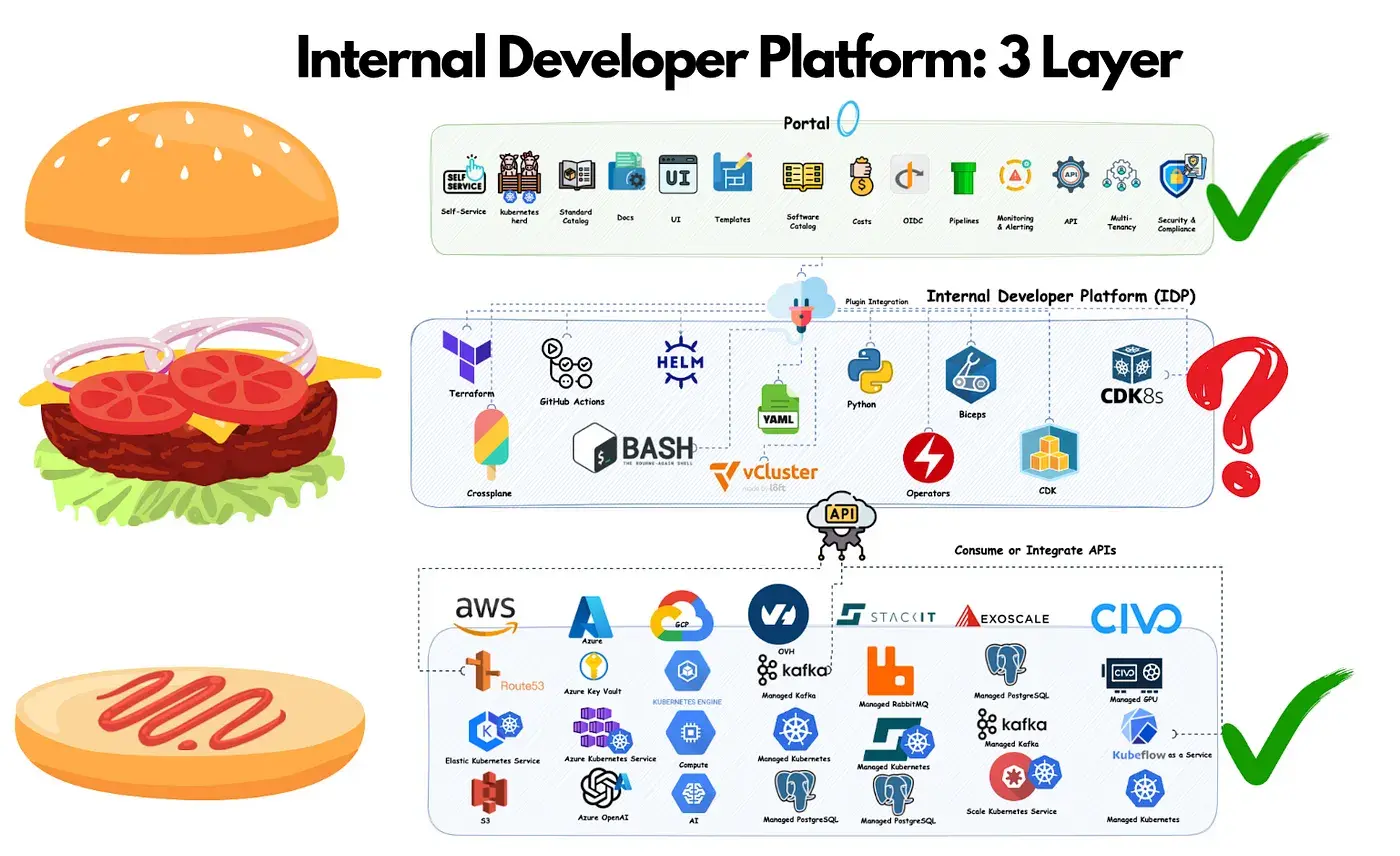
注:文章后半部分介绍了具体的实践操作,感兴趣的话可以具体查看。
相关文章
EKS 集群升级失败讨论
原文:Thought We Had Our EKS Upgrade Figured Out… We Did Not
EKS 是什么
根据 Amazon EKS 文档的定义,Amazon Elastic Kubernetes Service(Amazon EKS)是一项托管式的 Kubernetes 服务,让您无需在亚马逊云科技(AWS)云端和自己的数据中心中运行和维护 Kubernetes 集群的可用性和可扩展性。
发生了什么
使用 Terraform 来执行升级操作时,kube-proxy 升级失败,某些 Pod 进入了 CrashLoopBackOff 状态。
原因是什么
Kube-Proxy 1.31 需要一个带有加密扩展的 ARMV8.2 处理器,链接。
其他做法
评论中有人提到 ta 们从不升级群集,而是创建新的集群并迁移工作负载。ta 们可以在两个群集上同时运行工作负载(在同一应用程序的两个群集上部署),然后仅将传入的网络流量切换到新的负载平衡器。如果出现问题,切换并修复并重试。如果有效,会像这样并行运行一两天,然后删除旧的群集。
一些想法
由于 Kubernetes 版本更新比较频繁,所以集群升级自然成为一个需要重视的操作。Kubernetes 官方推荐的集群升级方式是滚动升级,也就是逐步替换集群中的所有节点。这样的好处是:可以确保集群始终可用,不会因为一次性更新而造成服务中断;由于节点是逐步更新的,所以如果在某个节点出现问题也可以及时回滚,减小对整个系统的影响;用户可以根据自己的需求控制升级的步长和策略,比如每次升级多少个节点,具有更强的可控性。
然而很多国内用户都更倾向于原地升级,原因可能有以下几方面:
- 在传统 IT 的管理模式中,原地升级是一种更常见的方式,许多用户习惯通过直接升级现有的操作系统或应用程序,而非重新部署。因此,用户可能对这种方式更为熟悉和信任。
- 部分用户的安全监管以及网络配置依赖节点 IP,所以希望节点的 IP 可以保持不变。
- 对于追求稳妥的用户来说,往往会对较大的运维操作预留停机时间。原地升级由于是一次性更新,所需要的时间较为集中。滚动升级是分阶段升级,一部分更新完成后再开始下一部分的更新,所以从升级角度看,相对来说需要更长的升级时间。
- 相较于原地升级,滚动升级可能会需要额外的资源,例如额外的节点、IP 等。
- ......
结合帖子中的讨论,可能需要进一步了解国内用户的需求、顾虑、取舍的边界,探索更符合国内用户习惯、使用场景的升级方式。
OpenTelemetry: A Guide to Observability with Go
原文:OpenTelemetry: A Guide to Observability with Go
OpenTelemetry 是什么
如 OpenTelemetry 官网定义:OpenTelemetry 是一个可观测性框架和工具包, 旨在创建和管理遥测数据,如链路、 指标和日志。 重要的是,OpenTelemetry 是供应商和工具无关的,这意味着它可以与各种可观测性后端一起使用, 包括 Jaeger 和 Prometheus 这类开源工具以及商业化产品。
OpenTelemetry 不是像 Jaeger、Prometheus 或其他商业供应商那样的可观测性后端。 OpenTelemetry 专注于遥测数据的生成、采集、管理和导出。 OpenTelemetry 的一个主要目标是, 无论应用程序或系统采用何种编程语言、基础设施或运行时环境,你都可以轻松地将其仪表化。 重要的是,遥测数据的存储和可视化是有意留给其他工具处理的。
日志、指标和链路
- 日志(Logs)是离散事件的记录。可以把它们看作是应用程序的日记条目。当出现问题时,日志是首先查看的地方。
- 指标(Metrics)跟踪随时间变化的数值数据,如请求持续时间、CPU 使用率或活跃连接数。它们帮助监控趋势并发现性能问题。
- 链路(Traces)跟踪请求在多个服务之间的流动。一个追踪由多个跨度(spans)组成,每个跨度表示一个独立的操作。
总的来说,日志告诉我们发生了什么,指标展示了它发生的频率,链路揭示了系统不同部分如何互动。
OpenTelemetry 的工作机制
在 OpenTelemetry 中,providers, resources, exporters 和 collectors 是共同收集,处理和将遥测数据发送到外部系统的组件。providers 负责生成遥测数据,它们依赖于 resources,resources 定义了应用程序的元数据,如服务名称、版本和主机。一旦遥测数据被收集,它需要被发送到某个地方,这就是 exporters 的作用。exporters 将数据转发到像 Grafana 这样的可观察性后端。为了更高效地管理这个过程,OpenTelemetry 使用 collectors,collectors 充当中介,聚合、处理并路由遥测数据,然后将其发送到一个或多个后端。收集器有助于减少应用程序的开销,并提供遥测存储和分析的灵活性。
两款专注边缘场景的产品
原文:
StarlingX 10: Support for Dual-Stack Networking at the Edge
LoxiLB + K3s:打造多主高可用 Kubernetes 集群
Loxilb 和 StarlingX 分别是什么
根据官网定义,Loxilb 是一个基于 GoLang/eBPF 的开源云原生负载均衡器,旨在实现跨各种本地、公有云或混合 K8s 环境的交叉兼容性。loxilb 的开发是为了支持电信、移动和边缘计算领域采用云原生技术。
根据官网定义,StarlingX 是一套完整的云基础架构软件堆栈,适用于工业物联网、电信、视频交付和其他超低延迟用例中最苛刻的应用程序所使用的边缘。凭借边缘应用程序所需的确定性低延迟以及使分布式边缘易于管理的工具,StarlingX 为可扩展解决方案中的边缘实现提供了基于容器的基础架构,现已准备好投入生产。
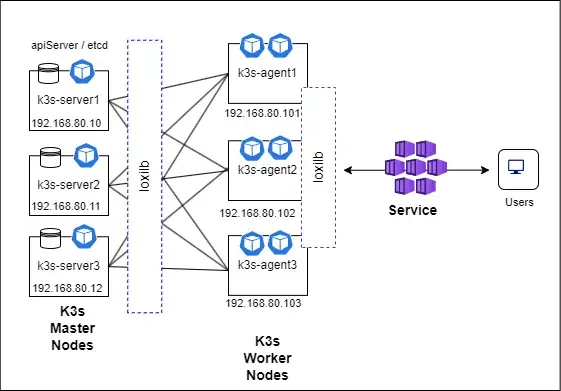
LoxiLB + K3s:打造多主高可用 Kubernetes 集群
原文:LoxiLB + K3s:打造多主高可用 Kubernetes 集群
需要使用奇数个 server 节点来维持仲裁(quorum)。架构图如下:
StarlingX 10.0 新特性
开源分布式云平台 StarlingX 正式发布了备受期待的 10. 0版本,标志着其发展历程中的一个重要里程碑。此次更新于周三发布,带来了许多新功能和增强功能,以提高各种应用程序的性能和用户体验,特别是在物联网 (IoT) 、5G 和边缘计算环境中。需要关注的新特性如下:
- StarlingX 10.0 的突出特点之一是支持 IPv4/IPv6 双栈网络。这一增强功能允许用户同时操作两种协议,确保行业从 IPv4 过渡到 IPv6 时的兼容性,而 IPv4 过渡在许多行业中都在进行中。
- 该框架使用 OSTree 安装新软件,而主机继续在现有文件系统上运行。因此,只需简单重启即可过渡到新软件,与以前的方法相比,停机时间大大减少。它还可以同时部署补丁和更新。
- Linux 内核版本 5.10 升级到 6.6 。此更改增强了性能并扩展了对更广泛硬件平台和设备驱动程序的支持。此更新基于最新的长期支持 (LTS) Yocto Linux 发行版。Yocto 是一款备受好评的可定制嵌入式 Linux。
- 现在每个系统控制器可以管理多达 5,000 个远程站点,而以前的版本只能管理 1,000 个。这一增强功能对于大规模部署至关重要。
- 附带 Kubernetes 的 Harbor 作为其容器镜像仓库。
- 集成 Kubernetes 1.29 版本。
Cluster API + Talos + Proxmox = ❤️
原文:Cluster API + Talos + Proxmox = ❤️
Cluster API 是什么
Cluster API 是一个开源项目,旨在自动化 Kubernetes 群集的部署,配置和管理。
TALOS 是什么
Talos 是为 Kubernetes 设计的 Linux 发行版 - 安全,不可变和最小的。
Talos 具有以下特性:
- 支持云平台,裸机和虚拟化平台
- 所有系统管理都是通过 API 完成的,没有 SSH,Shell 或控制台
- 准备就绪:支持世界上一些规模较大的 Kubernetes 集群
- Sidero Labs 团队的开源项目
Proxmox 是什么
Proxmox Virtual Environment(简称:Proxmox VE、PVE),是一个开源的服务器虚拟化环境 Linux 发行版。Proxmox VE 基于 Debian,使用基于 Ubuntu 的定制内核,包含安装程序、网页控制台和命令行工具,并且向第三方工具提供了 REST API,在 Affero 通用公共许可证第三版下发行。Proxmox VE 支持两类虚拟化技术:基于容器的 LXC(自 4.0 版开始,3.4 版及以前使用 OpenVZ 技术)和硬件抽象层全虚拟化的 KVM。
注:原文介绍了具体的操作步骤,感兴趣的话可以具体查看。
相关文章
Making Kubernetes Simple with Talos
对象存储应用:云本地人的最新体系结构
原文:Object Store Apps: Cloud Native’s Freshest Architecture
对象存储是什么
对象存储也称为基于对象的存储,是一种计算机数据存储架构,旨在处理大量非结构化数据。与其他架构不同,它将数据指定为不同的单元,并捆绑元数据和唯一标识符,用于查找和访问每个数据单元。
这些单元(或对象)可以存储在本地,但通常存储在云端,以便于从任何地方轻松访问数据。由于对象存储具有横向扩容能力,它的可伸缩性几乎没有限制,并且存储大量数据的成本也低于块存储等其他存储方法。
如今的许多数据都是非结构化的,无法很好地存储在传统数据库中,包括电子邮件、媒体和音频文件、网页、传感器数据和其他类型的数字内容。因此,寻找高效且经济实惠的方法来存储和管理这类数据成为了一个难点。越来越多的企业将对象存储作为存储静态内容、数据架构和备份的首选方法。
对象存储的优势
- 对象存储意味着“无限廉价存储”。这非常适合云原生发展。“任何有限的东西对开发人员来说都是烦人的。”
- 高吞吐量(高延迟)
总的来说,对象存储为开发者提供了一个更便宜、更易维护且更具扩展性的解决方案,推动了云原生应用的快速发展。
注:更多内容请阅读原文。
相关文章
一种新的资源调度器 —— Kro
原文:
Kubernetes Gets a New Resource Orchestrator in the Form of Kro
Kubernetes Gets a New Resource Orchestrator in the Form of Kro
背景
出现 Kro 的核心原因是:与 Kubernetes 打交道很复杂。尽管 Kubernetes 已经进入第 11 个年头,但开发者、运维人员和 SRE(网站可靠性工程师)仍然认为它复杂。安装、管理、扩展和处理 Kubernetes 需要高级技能以及对其底层结构的深入理解。为了解决这个问题,已经进行过多次尝试。例如,Helm 被引入作为包管理器,Cloud Native Application Bundles(CNAB)则作为分布式应用的标准化打包格式被创建。
Kro 是什么
参考官网的定义,Kro 是一个 Kubernetes 原生框架,旨在简化复杂的 Kubernetes 资源配置的创建。与在定义和运行时管理单个资源不同,Kro 允许运维人员将这些资源分组为可重用的单位,从而提高部署的效率和可管理性。
Kro 是历史上首次由 Amazon Web Services,Google 和 Microsoft 合作的开源项目。
Kro 的工作原理
Kro 引入了 ResourceGraphDefinition(RGD)的概念。RGD 是一个 Kubernetes 自定义资源定义(CRD),用于声明一组底层 Kubernetes 资源及其之间的关系。它是创建和管理这些资源作为一个单一单位的蓝图。够作为一个原子单位管理整个定义。
Kro 使用 Common Expression Language(CEL)来进行逻辑操作,CEL 也是 Kubernetes webhooks 使用的语言。通过 CEL 表达式,Kubernetes 用户可以无缝地在对象之间传递值,并将条件逻辑集成到自定义 API 定义中。基于这些表达式,Kro 自动确定对象创建的正确顺序。
Kro 的优势与特点
-
简化复杂资源配置: Kro 使得创建和管理复杂的 Kubernetes 资源配置变得更加简单。它通过将多个资源组合成一个可重用的单元来简化运维任务,而不是在定义和运行时分别管理每个单独的资源。
-
提升应用管理效率: Kro 通过 RGD 可以帮助用户将多个 Kubernetes 资源作为一个单元进行创建和管理,从而提高了部署过程的效率和资源的可管理性。
-
自动理解资源依赖关系:RGD 被设计成有向无环图,它能智能地理解资源的依赖关系,并自动确定资源创建的顺序,确保资源按正确的依赖顺序部署。
-
灵活: Kro 利用 CEL 来进行逻辑操作,使得 Kubernetes 用户可以轻松地在对象之间传递数据,并在自定义 API 定义中使用条件语句。CEL 的使用使得逻辑操作更加灵活和强大。
与其他类似产品的对比
Kro vs. Helm
- 结构化的 YAML 与 CEL:Kro 使用结构化的 YAML 配合 CEL,相较于 Helm 的图灵完备模板语言,Kro 提供了一个 更安全、更可预测的运行时环境。由于 CEL 的使用,Kro 能确保计算成本可预测,因为 API 服务器处理了所有的执行过程。
- 自动依赖管理与 DAG:Kro 基于 DAG 的自动依赖管理确保了资源的正确部署顺序,而 Helm 的 Chart 是打包和分发的,不能像 Kro 那样自动处理依赖关系。
- CRD 升级管理:相比 Helm,Kro 在处理 CRD(自定义资源定义) 升级时表现得更好,能够更轻松地管理升级过程,避免潜在的版本兼容性问题。
Kro vs. Kustomize
- 功能扩展:Kro 提供更先进的功能,如自动依赖管理、创建自定义资源和控制器的能力,而 Kustomize 主要专注于对 现有清单的定制。Kustomize 的重点是对已存在的 Kubernetes 资源进行修改和定制化,而 Kro 则提供了一个更全面的资源编排解决方案。
- 资源编排与管理:Kro 提供了一个完整的资源管理框架,包括依赖管理和多种自定义资源的定义,适用于复杂的资源配置。相比之下,Kustomize 更加专注于资源清单的组合和修改,而不是从头开始进行资源编排。
- 潜力与未来:一些用户认为,Kro 有潜力成为管理 Kubernetes 部署的首选工具,甚至可能在未来取代 Helm,尤其是在大规模、复杂的资源管理和自动化配置方面具有更大优势。
数据基础架构,而不是 AI 模型,将推动其在 2025 年的支出
原文:Data Infrastructure, Not AI Models, Will Drive IT Spend in 2025
背景
当组织争相实施人工智能(AI)计划时,他们遇到了意外的瓶颈:支持 AI 应用程序所需的数据基础架构的巨大成本。
尽管 Gartner 预计 2025 年的 IT 支出增长了 9.8% ,但真实的故事并不是关于模型或计算资源的,而是关于数据基础架构成本的指数增长,威胁到使 AI 计划在经济上不可持续。
成本挑战的因素
- 传统体系结构通常需要跨不同系统的相同数据的多个副本 - 一种用于流媒体,另一个用于批处理处理,另一个用于 AI 训练。
- 将这些数据在云环境中的不同区域之间移动会产生巨大的网络成本。
- 为实时处理和批处理维护独立的基础设施会增加运营开销并导致低效。
组织需要重点关注什么
- 实现最小化数据重复和移动的架构;
- 利用对象存储和无头设计来降低基础设施成本;
- 统一流处理和批处理,以简化操作;
- 优化云资源使用,控制网络开销。
对未来的影响
下一波 AI 创新不仅仅来自更好的模型,还将来自更高效的方式来存储、传输和处理支撑 AI 的海量数据。解决这一基础设施挑战的组织,将最有可能成功扩展其 AI 计划。