🆕产品新版本/新功能介绍
Kubernetes 1.29 kube-proxy 的 NFTables 模式
Kubernetes 1.29 引入了一种新的 Alpha 特性:kube-proxy 的 nftables 模式。 目前该模式处于 Beta 阶段,并预计将在 1.33 版本中达到一般可用(GA)状态。 新模式解决了 iptables 模式长期存在的性能问题,建议所有运行在较新内核版本系统上的用户尝试使用。 出于兼容性原因,即使 nftables 成为 GA 功能,iptables 仍将是默认模式。
优点
- 改进数据平面延迟
- 改进控制平面延迟
缺点
-
较新,还不够稳定
-
内核要求高,无法在较旧的 Linux 发行版上工作;目前它需要 5.13 或更高版本的内核
-
与其他网络组件的兼容性问题,例如 Pod 网络或 NetworkPolicy 实现,这些组件可能尚不支持以 nftables 模式运行的 kube-proxy
-
与 iptables 模式运行的 kube-proxy 不完全兼容
未来计划
-
nftables 现在是的 kube-proxy 的最佳模式,但它还不是默认模式
-
继续长期支持 iptables 模式
-
IPVS 可能难逃被淘汰的命运
延伸讨论下 Cillium
Breaking the Chains of Kube-Proxy With Cilium
Rethinking System Architecture: The Rise of Distributed Intelligence with eBPF
了解 kube-proxy 如何影响性能及运维复杂度,以及 CNCF 旗下唯一毕业的容器网络接口(CNI)Cilium 如何帮助缓解这些挑战。
背景
Kubernetes 采用模块化架构,这种即插即用设计构建了一个灵活的生态系统,使团队可以选择适合自身需求的容器网络接口(CNI)、Ingress 控制器和日志方案。然而,这种灵活性也带来了更高的复杂度。
随着 Kubernetes 生态的不断扩展,默认配置在极端场景下可能表现不佳。尽管 Kubernetes 能自动化大量容器相关任务,但其默认组件在性能和安全性方面可能难以满足高要求的使用场景。
Kube-Proxy 的挑战
-
开销
kube-proxy 通过管理大量转发规则引入了额外的转换层。虽然初始影响较小,但随着集群规模扩大,这种开销会迅速增加,可能导致更高的延迟,并增加连接中断的风险。
-
复杂性
在生产环境中维护 iptables 或 IPVS 规则极具挑战性。新增或删除服务都会导致规则数量增加,必须不断维护和更新。在高频率代码发布的团队中,这种变动可能会影响开发效率,使团队需频繁处理规则更新和连接问题。
-
负载平衡的限制
kube-proxy 依赖各节点上的规则进行负载均衡,相较于直接在内核或基于 eBPF 的方法,其效率较低。随着 Pod 的不断增减,每个节点都需要重建大量规则集,从而影响集群的可扩展性。
Cillium 如何应对挑战
-
提升效率
基于 eBPF 的数据路径通过处理内核中的数据包来减少延迟并提高吞吐量。
-
安全性和可观察性
Cilium 与 eBPF 的深度集成可实现高级安全策略、实时流量洞察以及细粒度分析网络流的能力。
-
性能提升和简化
通过移除 kube-proxy,减少了系统中的可变组件。这种简化提升了集群节点的吞吐量、降低了延迟,并减少了 CPU 使用率。由于基于 eBPF 的负载均衡无需持续管理成千上万条规则,网络栈的响应速度更快,特别是在新服务频繁创建和销毁的集群中表现尤为明显。
SUSE Rancher Prime 增强
SUSE Unveils Cloud Native Innovations at SUSECON 2025
产品目标
SUSE 企业容器管理总经理 Peter Smails 在新闻发布会上所说,“我们的目标仍然非常简单易懂,我们希望 SUSE 成为每个组织的云原生平台。难道不是每个云原生公司都是如此吗?” “这一切都是为了完善该平台,增强其功能,并扩大生态系统。所有道路都指向让 SUSE Rancher Prime 成为组织构建云原生战略的‘唯一’平台。”
举措
-
SUSE Rancher for SAP Applications:
这一全新平台专为 SAP 工作负载的无缝混合云集成量身打造。它基于 SAP 认证的 SUSE Rancher Prime,结合 Kubernetes、Linux、虚拟化、数据库、安全性及可观察性能力,以支持关键 SAP 应用程序。该解决方案可帮助企业更高效地部署 SAP 负载、降低成本,并确保合规性。SUSE 与 SAP 的长期合作为此奠定了坚实基础。
-
Temenos Core 认证
SUSE Rancher Prime 现已获得领先的核心银行平台 Temenos Core 认证。Temenos Core(又称 Temenos Transact,T24)是一款全面的云原生银行软件,支持零售、商业、企业、财富管理及支付等各类银行服务。该集成方案使金融机构能够利用 Kubernetes 现代化其基础设施,从而提升安全性、可扩展性和性能。
-
增强开发人员体验:
SUSE 推出了 SUSE Private Registry,一款由 Harbor 提供支持的企业级容器镜像仓库,适用于隔离环境中的安全镜像管理。Harbor 作为开源容器镜像仓库,提供策略控制及基于角色的访问控制(RBAC),确保镜像经过漏洞扫描,并支持签名验证以增强可信度。
-
虚拟机 (VM) 现代化
SUSE 虚拟化的最新版本新增对 Dell、NetApp、Oracle 及 Portworx 等主流存储方案的认证支持,大幅提升存储兼容性,助力企业无缝整合现有基础设施。
-
扩展的 SaaS 产品
SUSE 推出了 SUSE Rancher Hosted,即 SUSE Rancher Prime 的 SaaS(软件即服务)版本。该服务通过预构建的应用程序及可观察性解决方案,进一步增强了 SUSE 在 AWS 生态中的能力。
Red Hat Ansible 自动化平台 2.5 引入 feature flags
Red Hat Ansible Automation Platform 2.5
背景
“我们战略的核心支柱是更快地提供新功能,帮助我们的客户轻松管理基础设施、网络、安全策略和应用程序部署。根据该战略,我们引入了 feature flags,这将允许更好地控制在 Ansible 自动化平台环境中激活这些新功能的时间。”
feature flags 是什么
feature flags 允许开发人员和系统管理员(例如您)在安装期间打开或关闭平台的特定功能。这使您能够控制在产品发布生命周期中何时引入新功能:
- 评估组织团队对新功能的需求,并根据需要逐步推出新功能
- 在隔离环境中测试新功能,然后仅在您对其有信心后才为组织的其他部分激活它们
- 根据产品入职和认证的内部政策和流程测试新功能,这使您可以在将新功能投入生产或让更多用户采用之前熟悉它们
feature flags 的意义
- 有机会执行增强测试。我们都喜欢测试新事物,看看它们是否支持业务需求。打开或关闭功能的能力可以实现快速实验。
- 有助于推动创新。您的团队可以进行 A/B 测试、试用新功能并收集实时反馈,以便 Red Hat 可以迭代和改进对您来说重要的功能并与您的业务目标保持一致。这可以加速开发生命周期并确保新功能在完全集成到您的环境中之前经过您的审核。
- 新功能可以在特定环境中或由特定用户组进行测试,然后再在生产环境中全面部署。虽然实验性功能就是这样,但使用功能标记,您可以轻松避免任何可能影响生产系统的潜在兼容性问题。
Karmada v1.13 新增应用优先级调度能力
Karmada v1.13 版本发布!新增应用优先级调度能力
Karmada 是开放的多云多集群容器编排引擎,旨在帮助用户在多云环境下部署和运维业务应用。凭借兼容 Kubernetes 原生 API 的能力,Karmada 可以平滑迁移单集群工作负载,并且仍可保持与 Kubernetes 周边生态工具链协同。
本版本包含下列新增特性:
- 新增应用优先级调度功能,可用于保证关键作业时效性
- 新增应用调度暂停与恢复功能,可用于构建多集群队列系统
- Karmada Operator 功能持续演进
- Karmada 控制器性能优化提升
- Karmada Dashboard,可提供多云编排可视化能力
Karmada Dashboard 首个版本发布
Karmada Dashboard 首个版本发布!开启多云编排可视化新篇章
Karmada Dashboard 是一款专为 Karmada 用户设计的图形化界面工具,旨在简化多集群管理的操作流程,提升用户体验。通过 Dashboard,用户可以直观地查看集群状态、资源分布以及任务执行情况,同时还能轻松完成配置调整和策略部署。
主要功能包括:
- 集群管理:提供集群接入和状态概览,包括健康状态、节点数量等关键指标。
- 资源管理:业务资源配置管理,包括命名空间、工作负载、服务等。
- 策略管理:Karmada策略管理,包括分发策略、差异化策略等。
OpenShift 通过用户定义网络增强 Kubernetes Pod 网络
Enhancing the Kubernetes pod network with user-defined networks
用户定义网络(UDN) 支持 OpenShift 的 OVN-Kubernetes 集群网络与外部网络的无缝集成,并提供跨网络边界的定制化解决方案。UDN 通过支持 自定义二层(L2)、三层(L3)及 localnet 网络段,提升默认三层 Kubernetes Pod 网络的灵活性和分段能力。这些网络段可作为容器 Pod 和虚拟机的主网络或辅助网络。
UDN 旨在为所有网络段提供一致的体验。
具体见原文。
Koordinator v1.6 支持 AI/ML 场景的异构资源调度能力
原文:Koordinator v1.6: 支持 AI/ML 场景的异构资源调度能力
Koordinator 是什么
Koordinator 是一个现代化的调度系统,可在 Kubernetes 上共置微服务、AI 和大数据工作负载。它通过将弹性资源配额、高效 Pod 打包、过量承诺和资源共享与容器资源隔离相结合来实现高利用率。
Koordinator 的特点
- 精心设计的优先级和 QoS 机制,用于在集群中共置不同类型的工作负载,并在单个节点上运行不同类型的 pod。
- 通过应用程序分析机制,允许资源过度承诺以实现高资源利用率,但仍然满足 QoS 保证。
- 细粒度的资源编排和隔离机制,以提高延迟敏感的工作负载和批处理作业的效率。
- 灵活的作业调度机制,支持大数据、人工智能、音频和视频等特定领域的工作负载。
- 一套用于监控、故障排除和操作的工具。
v1.6 的版本目标
帮助客户解决 GPU、NPU、RDMA 等设备异构资源调度难题。
v1.6 做了什么
- GPU 拓扑感知调度:加速 AI 应用内的 GPU 互联。基于 NUMA、PCIE 等硬件拓扑结构和 GPU、CPU、内存等资源配置进行最优分配。
- 端到端 GDR 支持:提升跨机任务的互联性能。GPUDirect RDMA,其目的是解决多机 GPU 设备之间交换数据的效率问题。通过 GDR 技术多机之间 GPU 交换数据可以不经过 CPU 和内存,大幅节省 CPU/Memory 开销同时降低延时。
- GPU 共享强隔离:提高 AI 推理任务的资源利用率。允许多个 Pod 共享同一张 GPU 卡。
- 差异化 GPU 调度策略:有效降低 GPU 碎片率。多种类型资源(如 CPU、内存、GPU 等)通常在一个统一的平台上进行管理。然而,不同类型资源的使用模式和需求往往存在显著差异,这导致了对资源堆叠(Packing)和打散(Spreading)的不同策略需求。Koordinator 引入了 NodeResourceFitPlus 插件以支持为不同资源配置差异化的打分策略
- 精细化资源预留:满足 AI 任务的高效运行需求。
- 混部:Mid tier 支持空闲资源再分配,增强 Pod 级别 QoS 配置。
- 调度、重调度:持续提升的运行效率
未来计划
- 精细化设备调度支持昇腾 NPU
- 提供重调度插件解决资源不均衡问题
- Reservation 支持绑定已分配 Pod
📰新闻与讨论
flexera 2025 年云现状报告
⚠️ 仅摘取部分内容。
背景
本报告分析了 云计算趋势、IT 专业人士所面临的挑战,以及他们在当今动态且不断变化的环境中保持竞争力所采取的战略举措。
调查对象:全球 759 名云计算决策者和用户,所有参与者均来自经过严格筛选和审查的独立受访者小组,并具备完整的个人资料信息。
公有云相关
- 从使用的服务来看,AI 势头强劲,容器也超过半数。
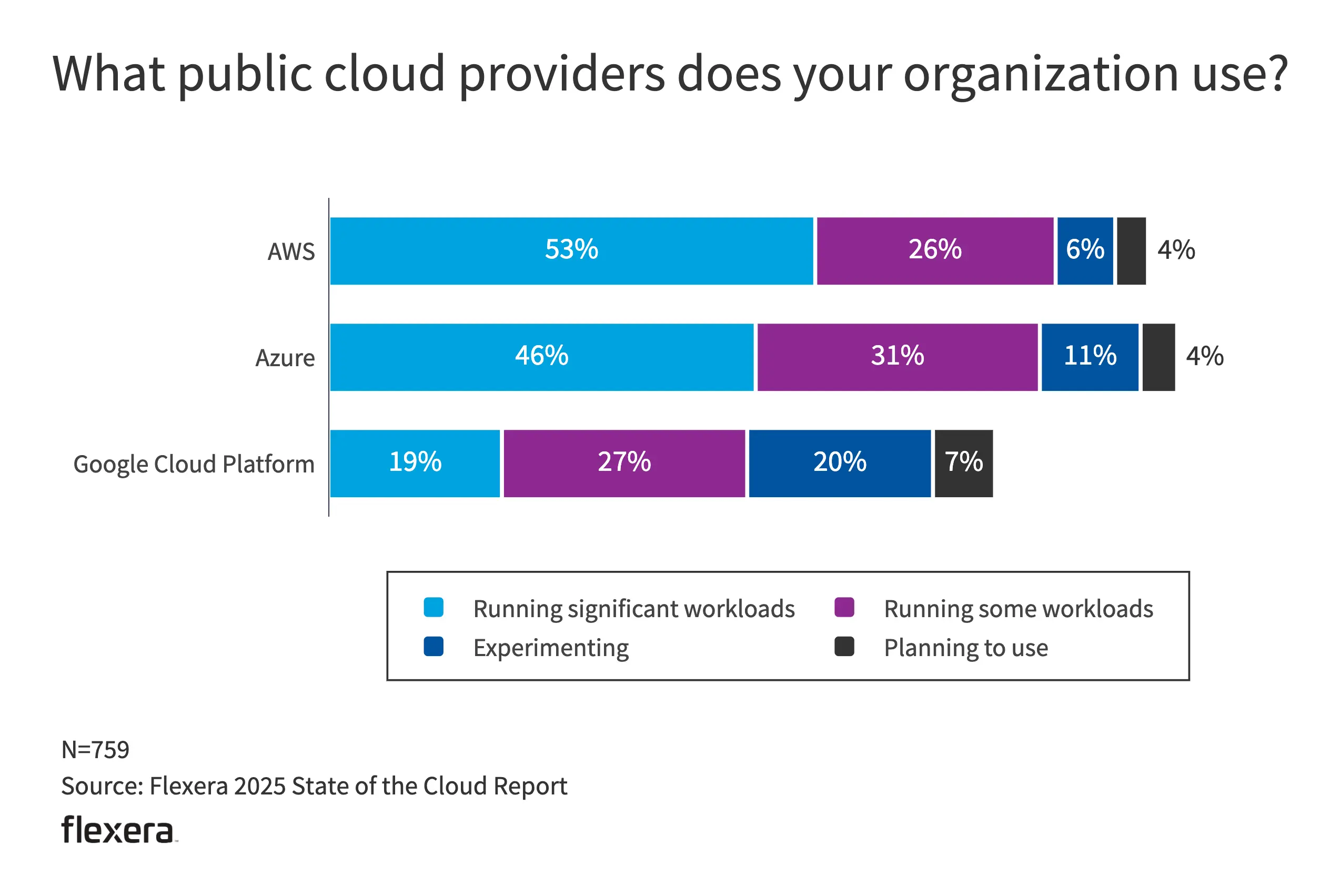
- 从供应商来看,53% 的 AWS 用户在其平台上运行关键业务,Azure 用户的整体使用率达到 88%。

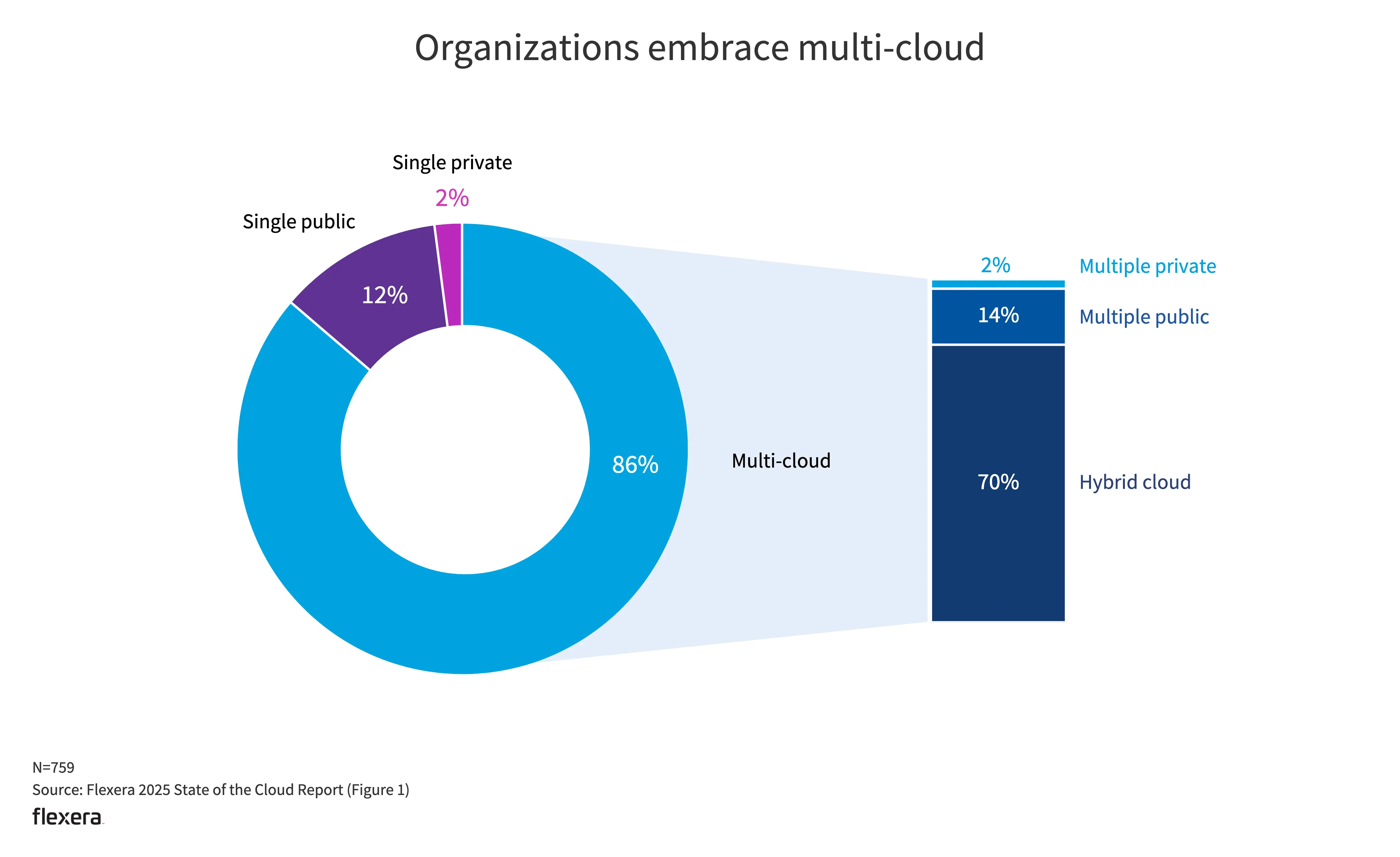
多云与混合云
- 仅 2% 使用单个私有云;2% 使用多个私有云。
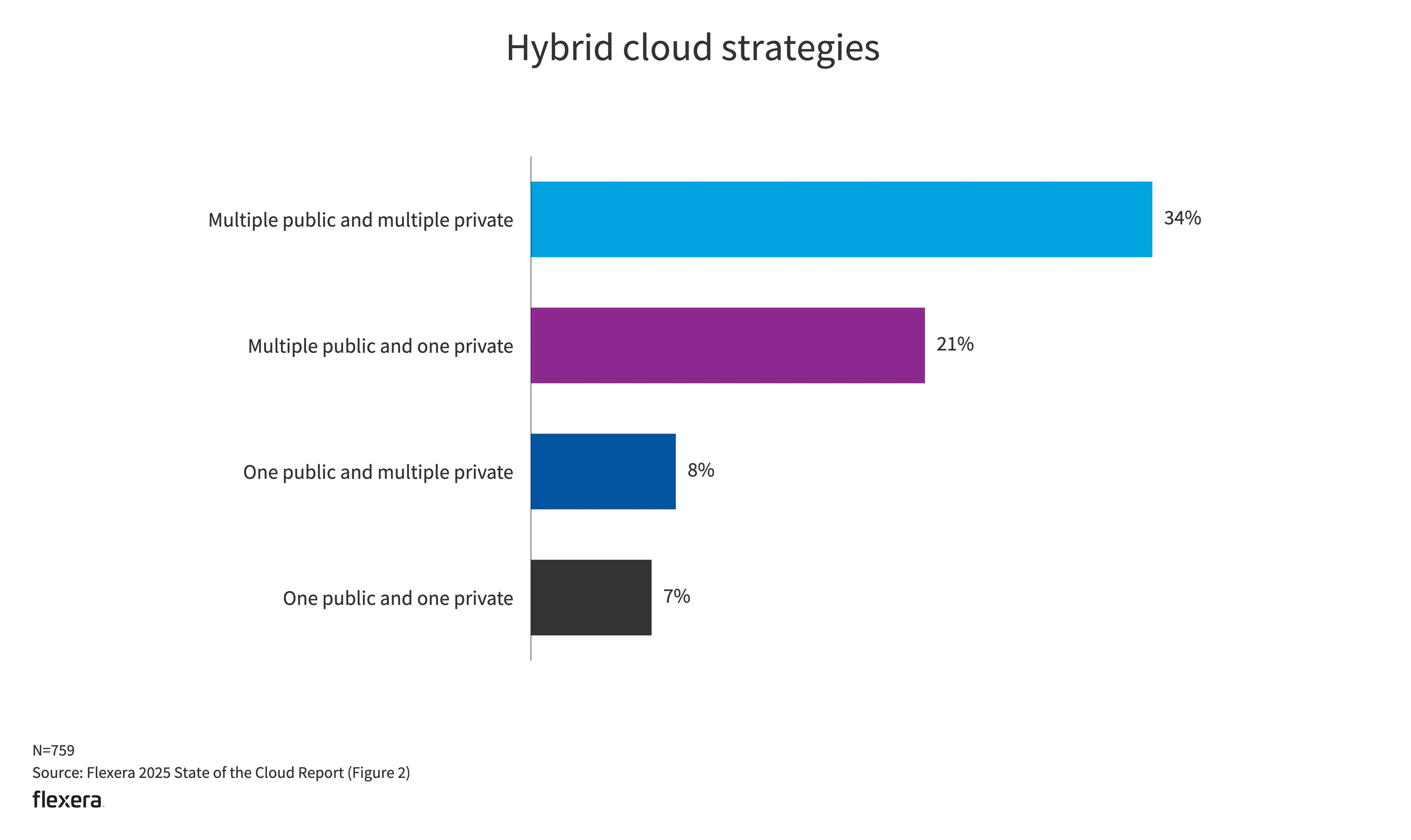
- 在混合云的使用上,多个公有云结合多个私有云的组合是占比最高的。
- 从多云架构的使用方式来看,排名第一的是孤立在不同云上的应用程序,然后是云之间的灾难恢复/故障转移、云之间的工作负载移动性、云之间的数据集成、单个应用程序跨越公有云和私有云等等。(对于第一名不确定是符合预期还是现状如此。)

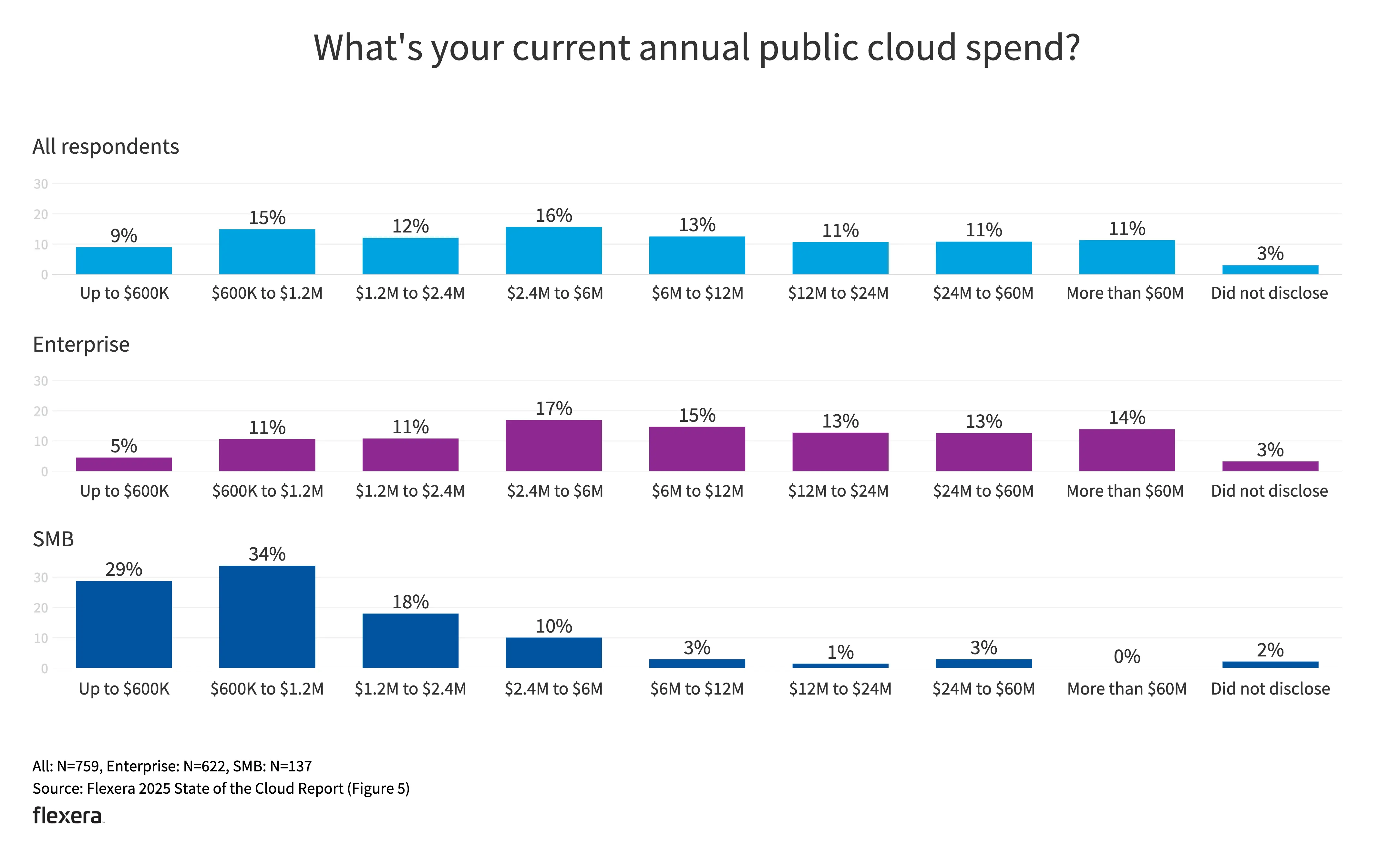
云支出
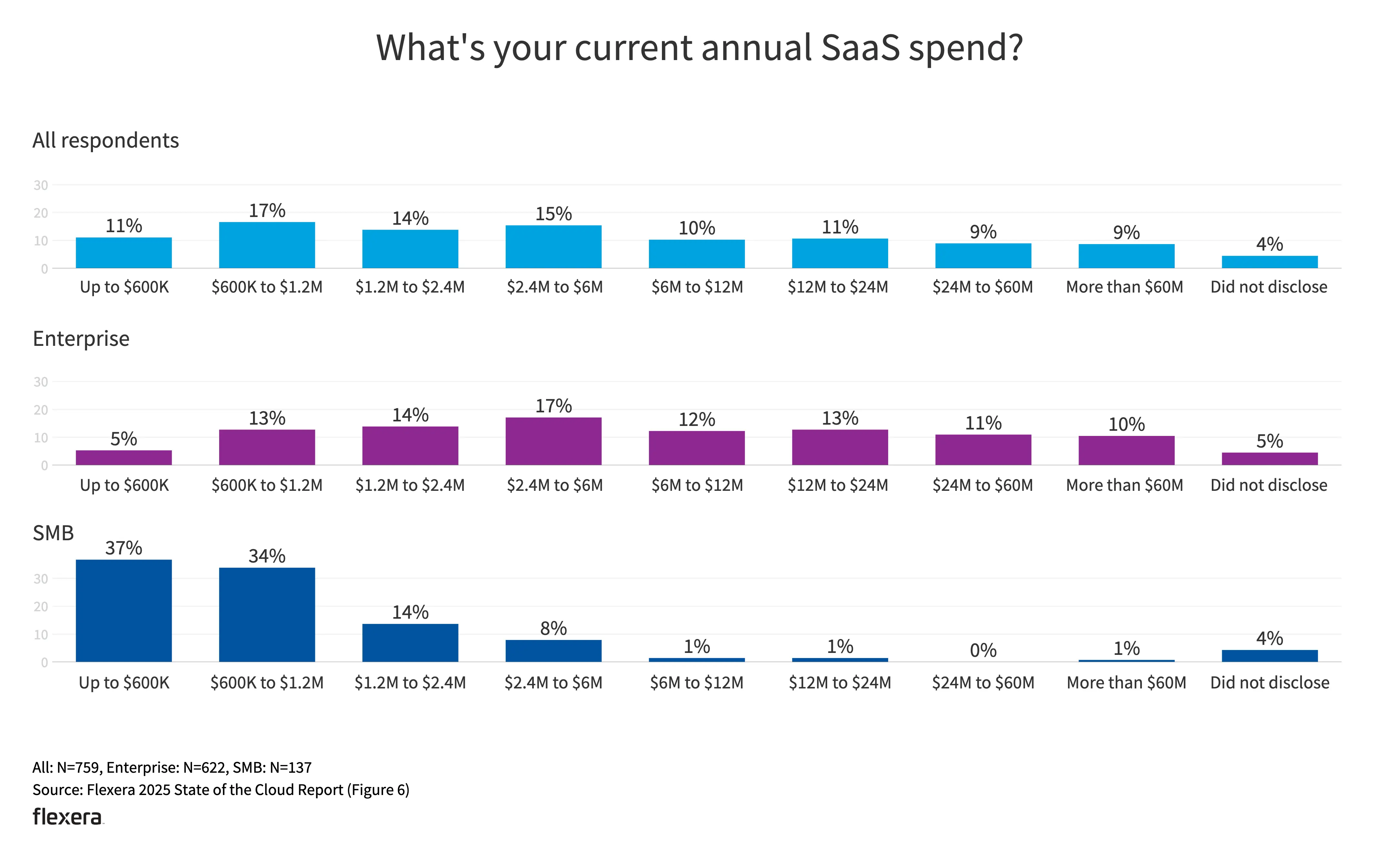
- 企业级客户和中小客户的支出规模也较符合预期。
- 33% 的组织每年在公共云上的支出超过 1200 万美元
- 34% 的企业每月在 SaaS 上的支出超过 100 万美元
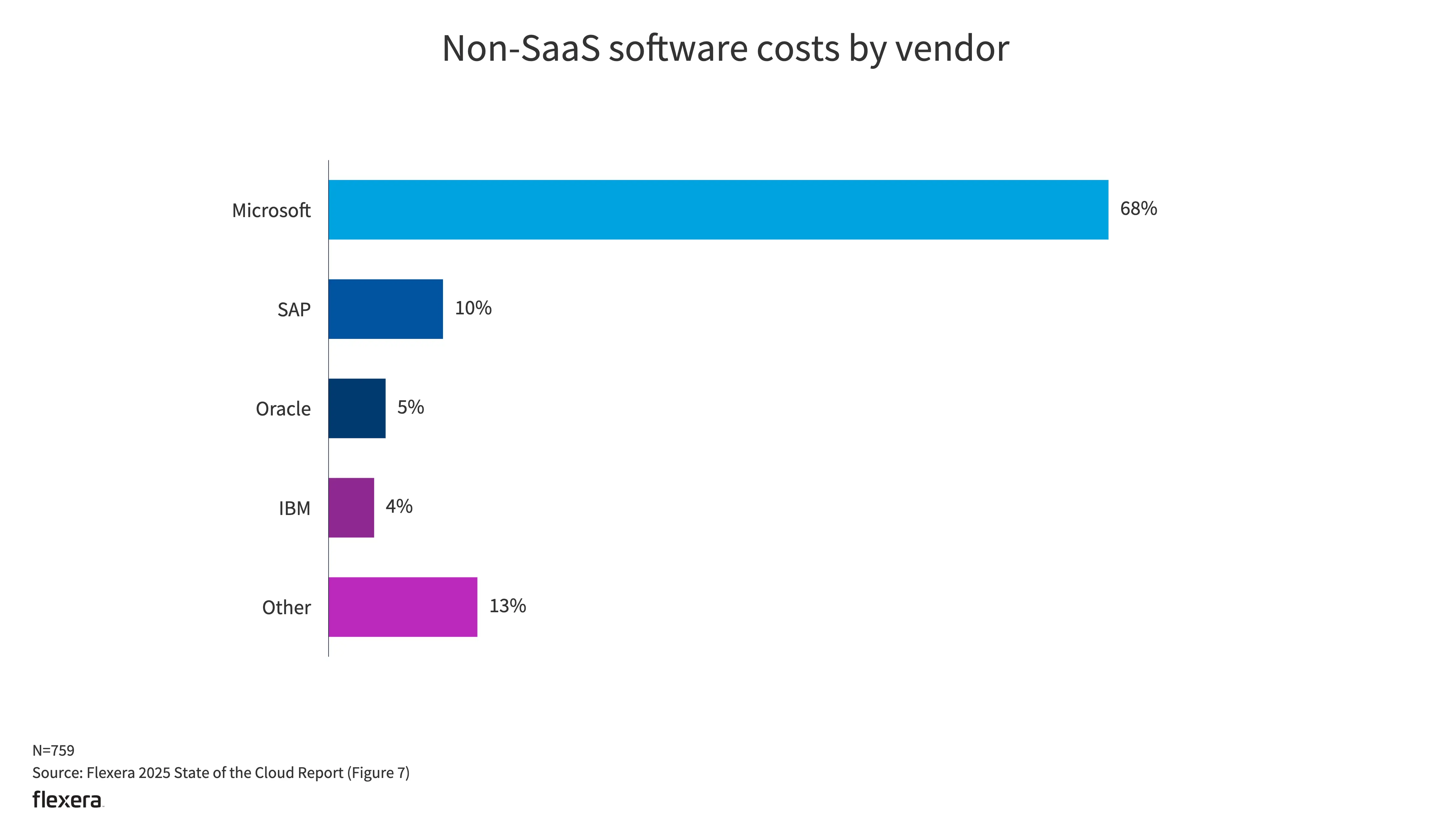
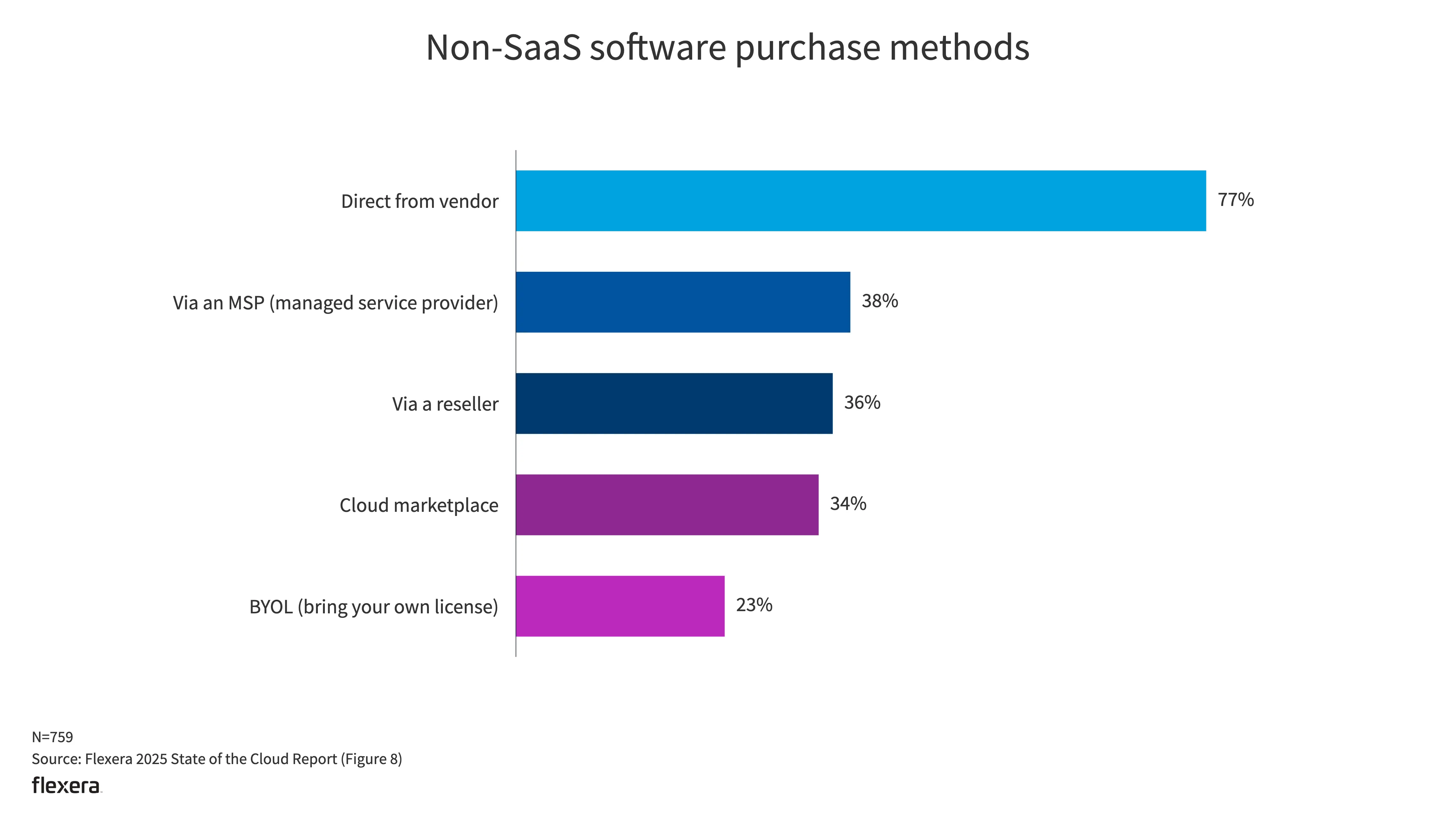
- 微软是最常见的非 SaaS 供应商。最常见的还是从供应商直接购买。
公有云和私有云互迁
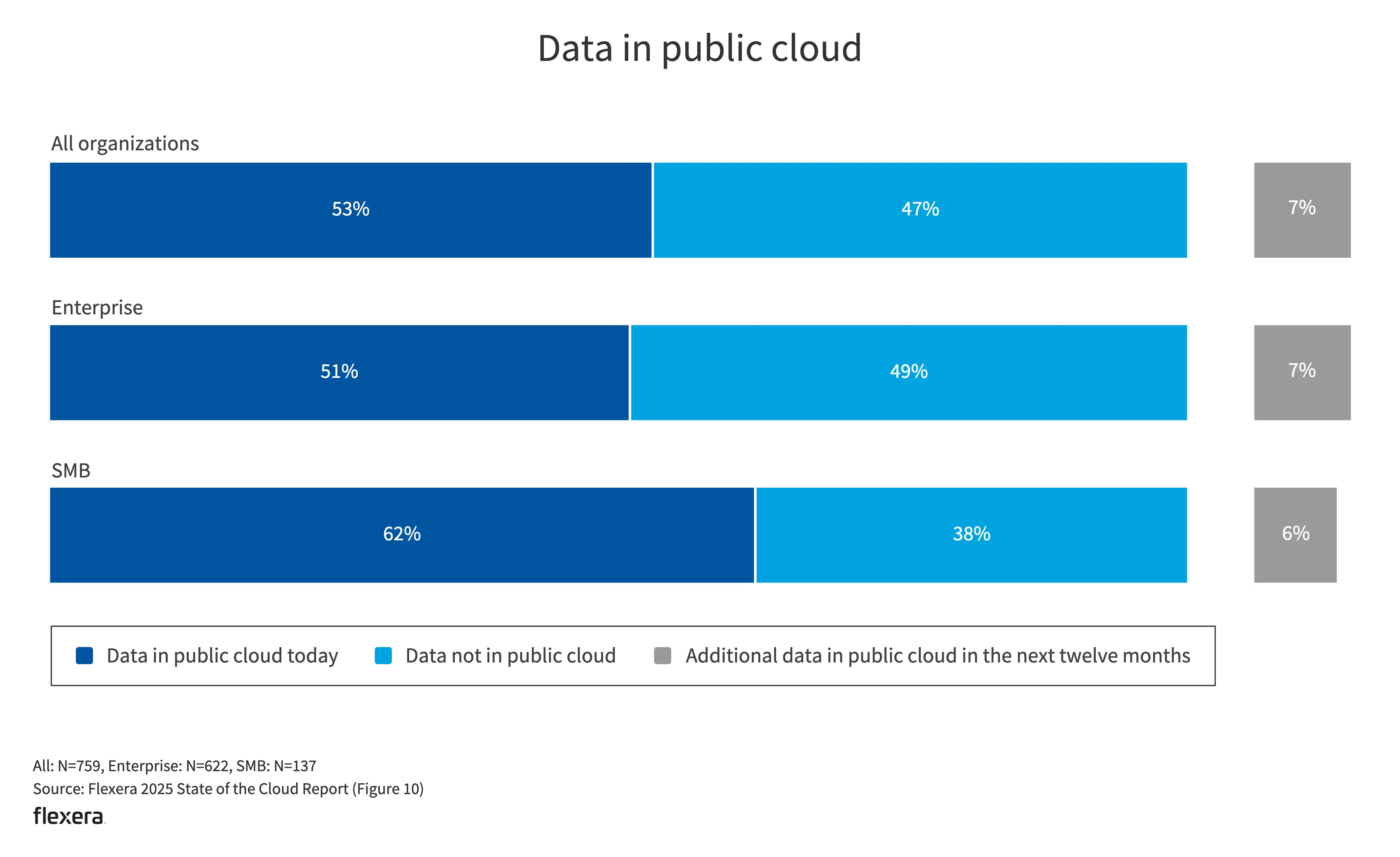
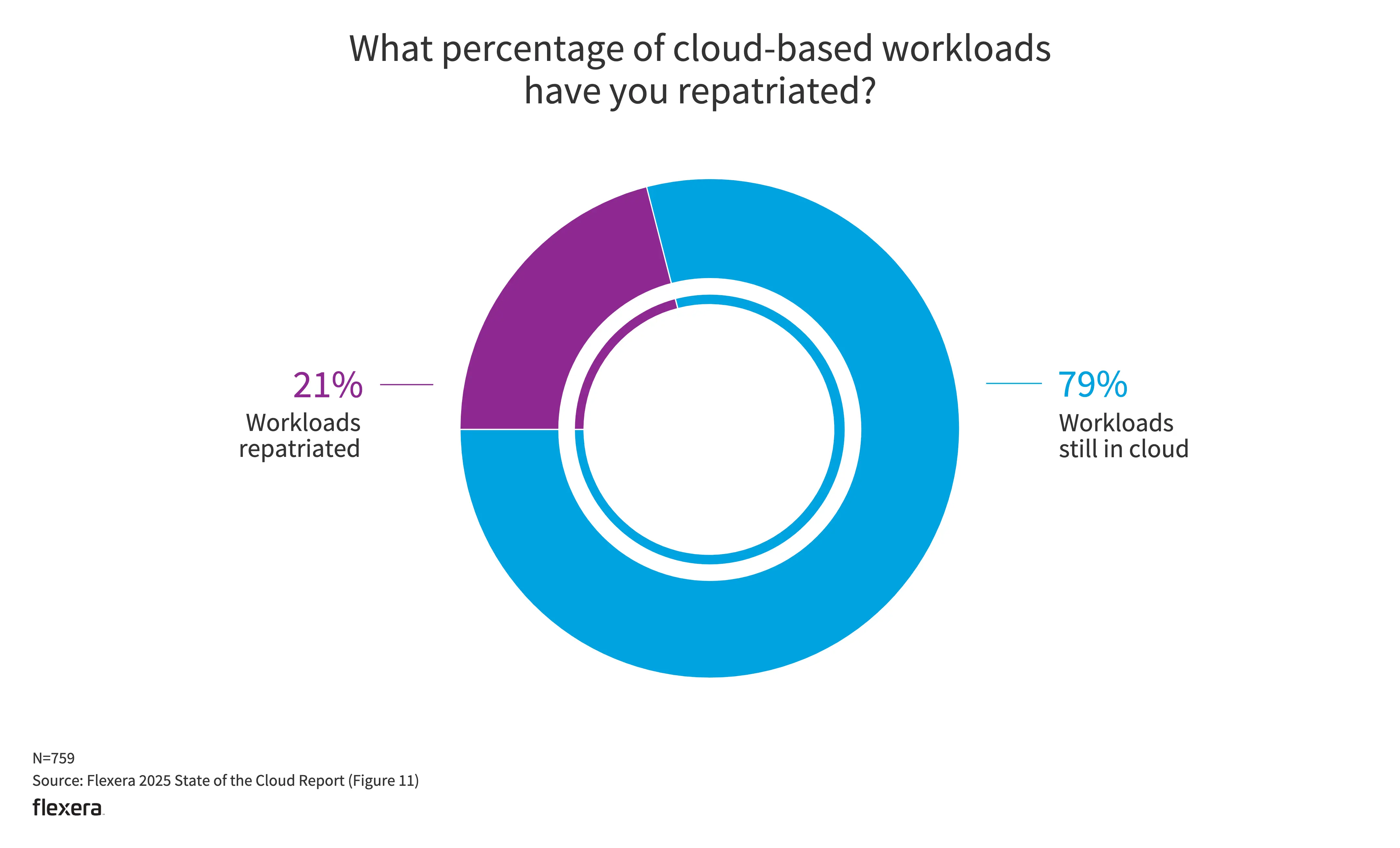
- 13% 的中小企业预计将增加公共云工作负载;但同时有 21% 的工作负载和数据都已遣返回私有云。
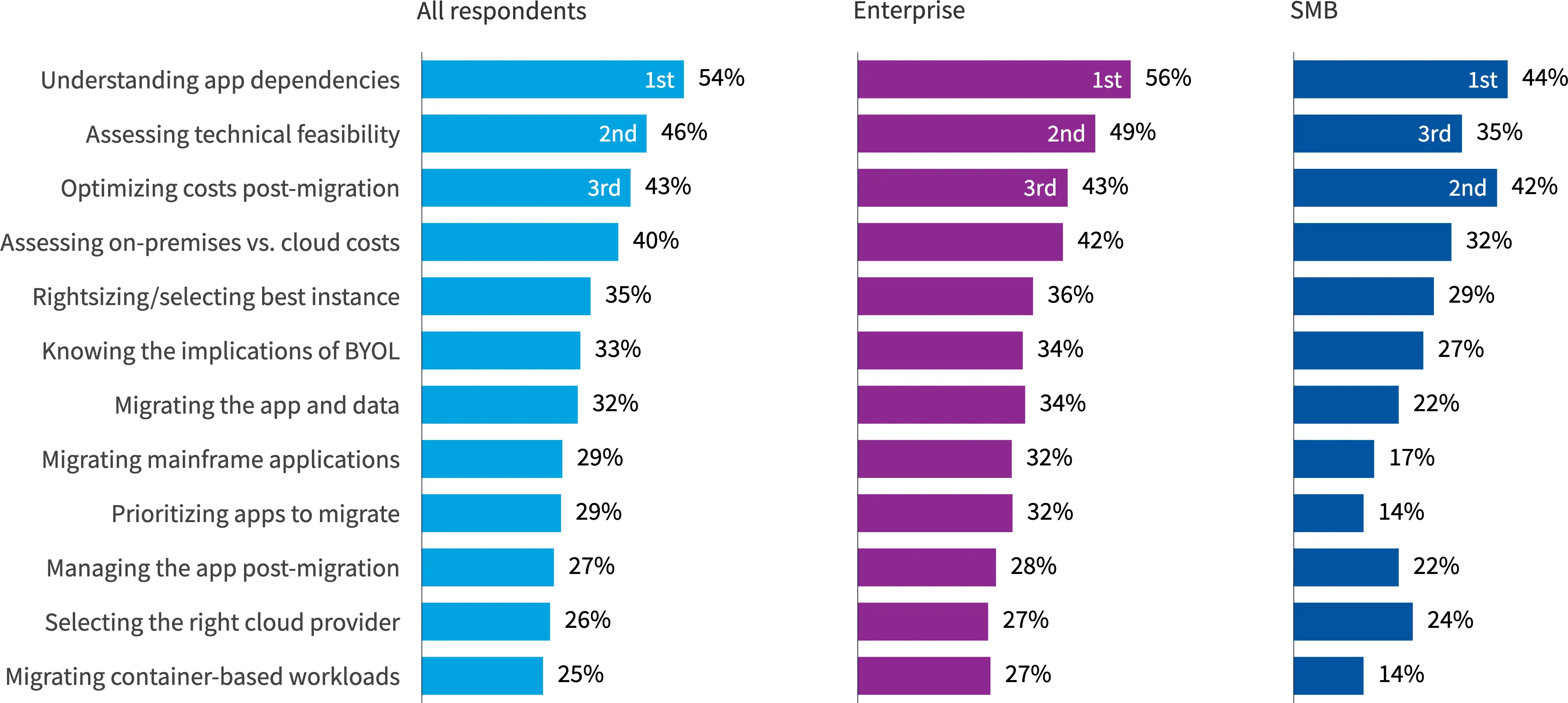
- 将应用迁移到公有云最困难的前三项分别是:
- 明确应用之间的依赖关系。
- 评估技术可行性。
- 优化迁移后的成本。
未来的计划
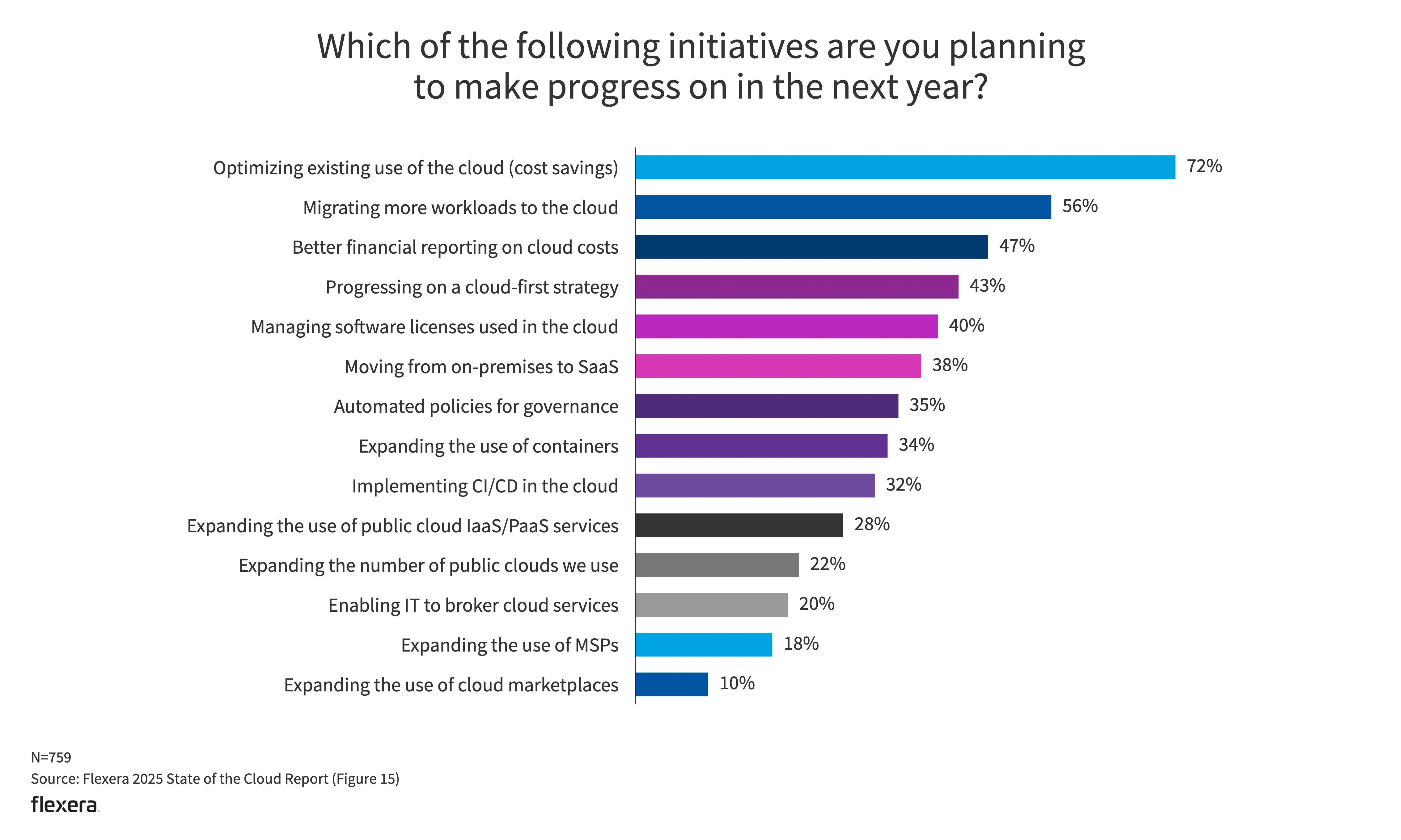
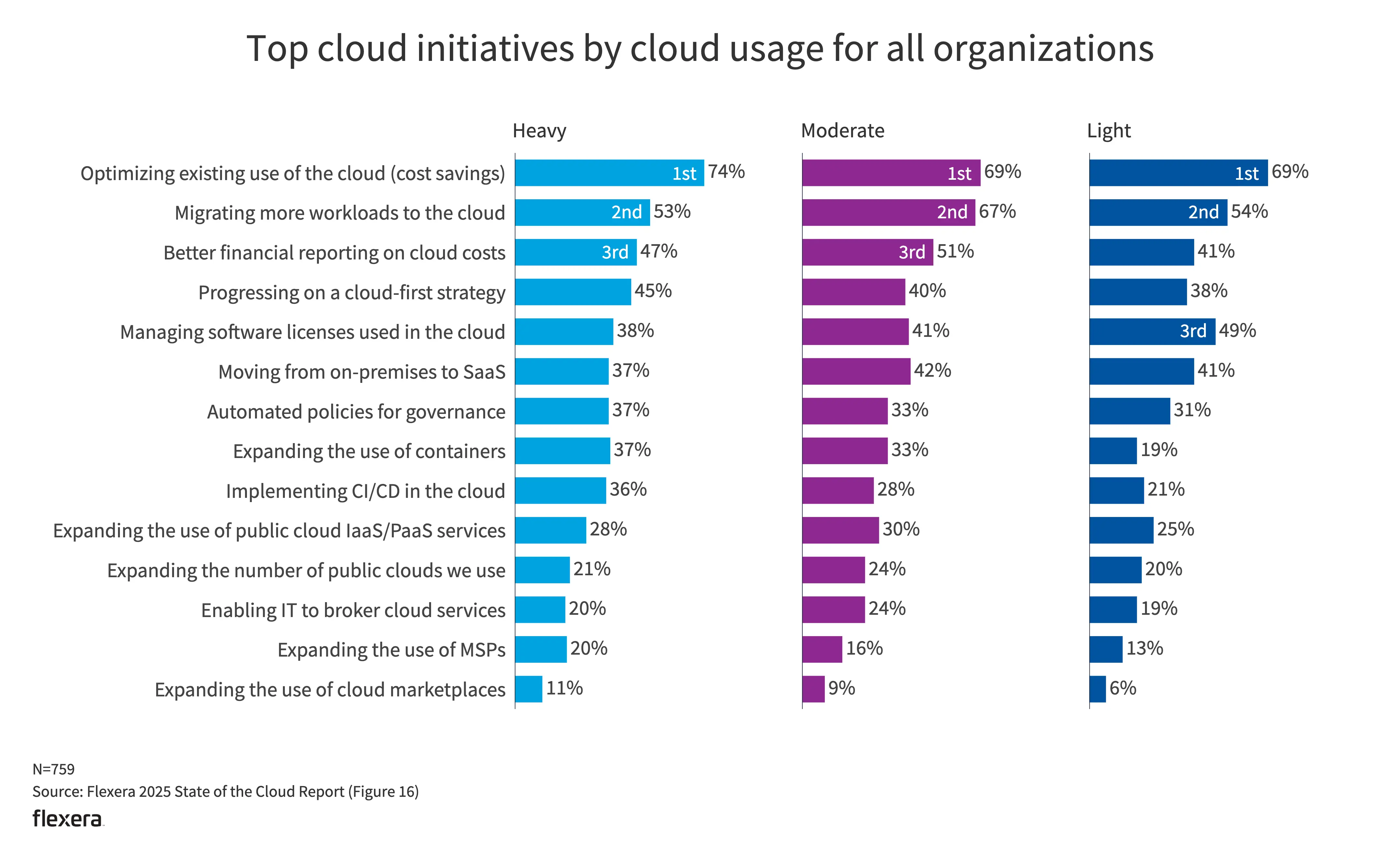
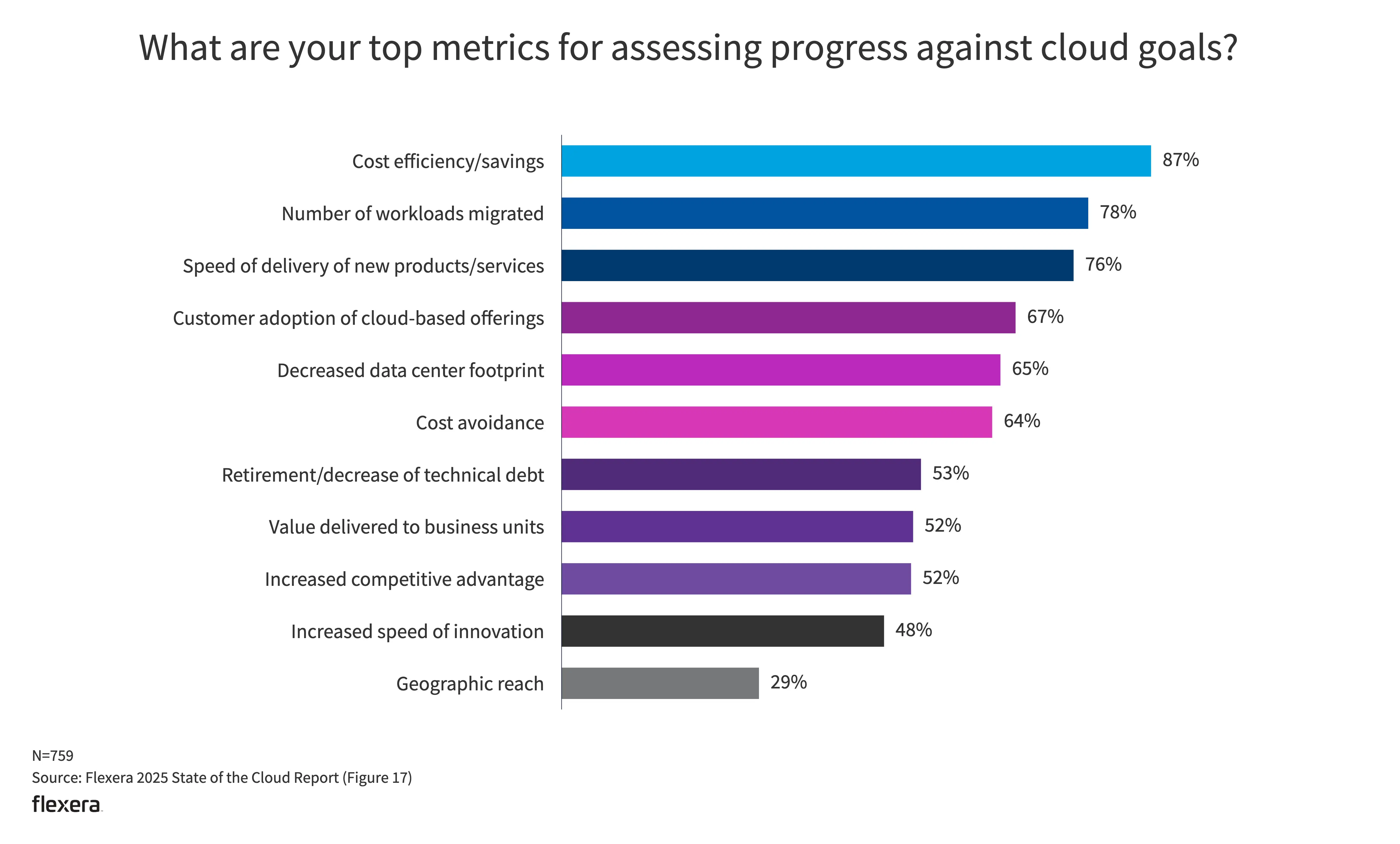
- 优化现有的云使用方式(节省成本)仍然是一项主要举措。也侧面体现了许多组织在云使用方面已达到稳定状态。
支出与浪费
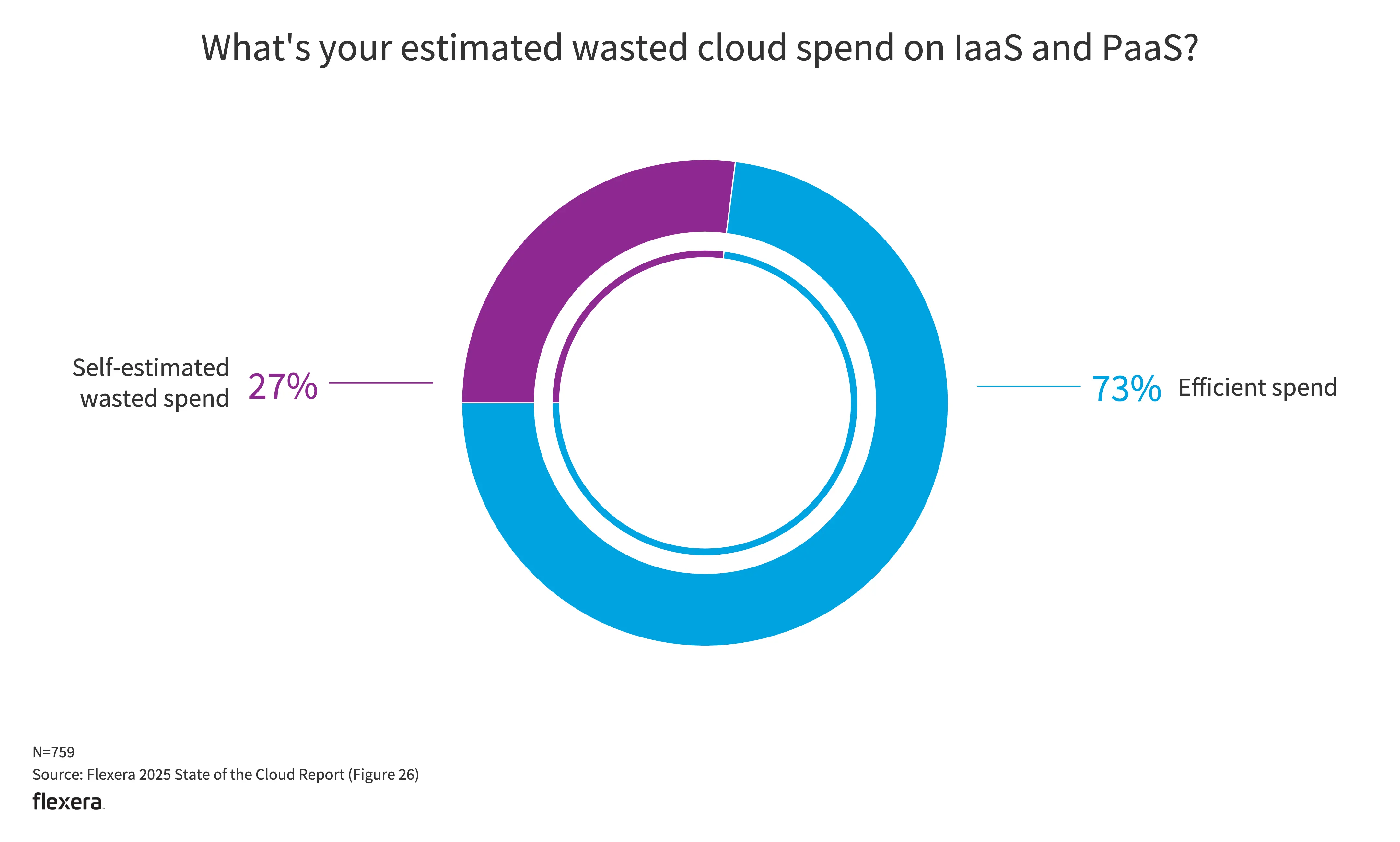
- 在 IaaS 和 PaaS 上的云支出浪费估计为 27%。
- 关于 FinOps 可以看 FinOps and AI: A Winning Strategy for Cost-Efficient Growth
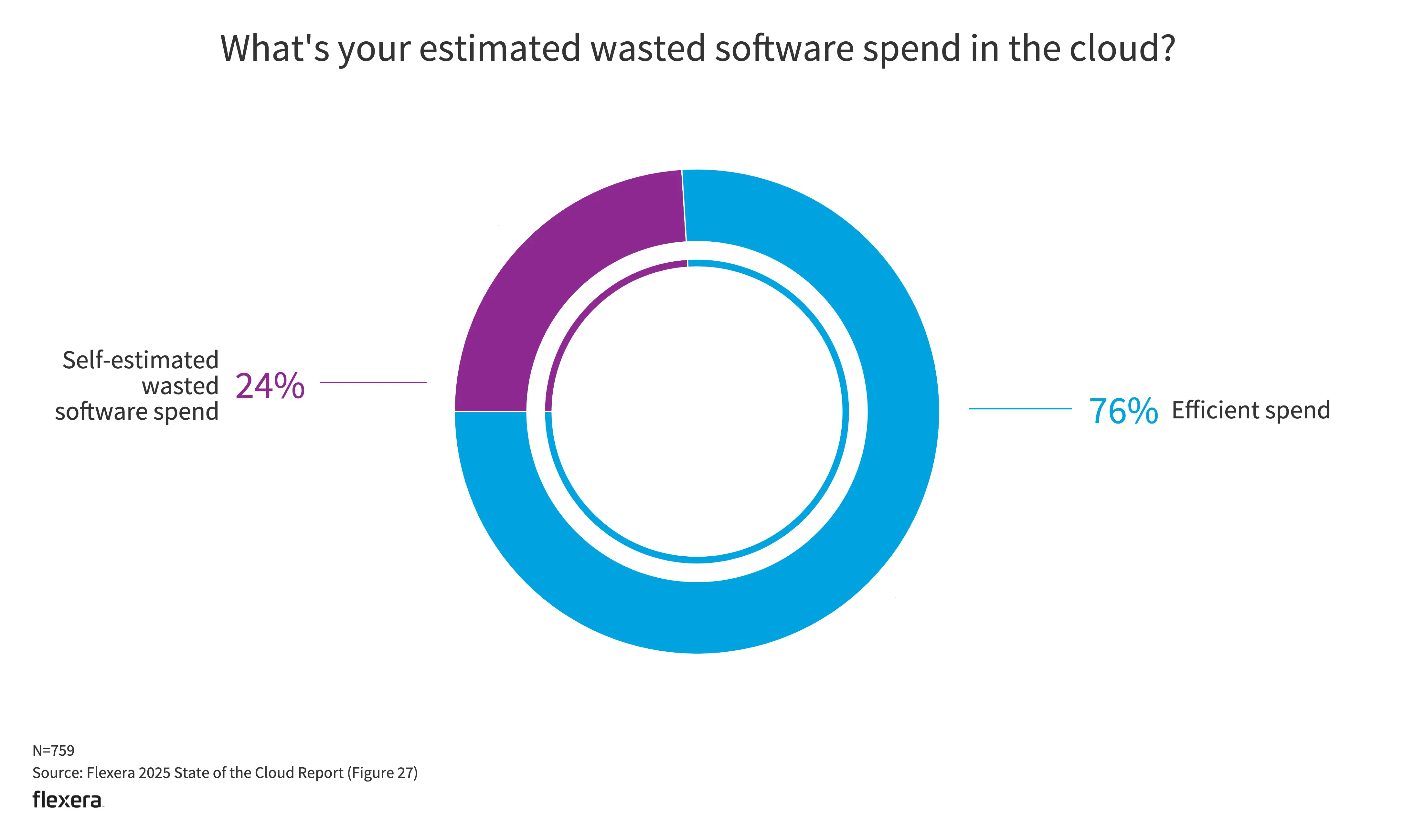
其他
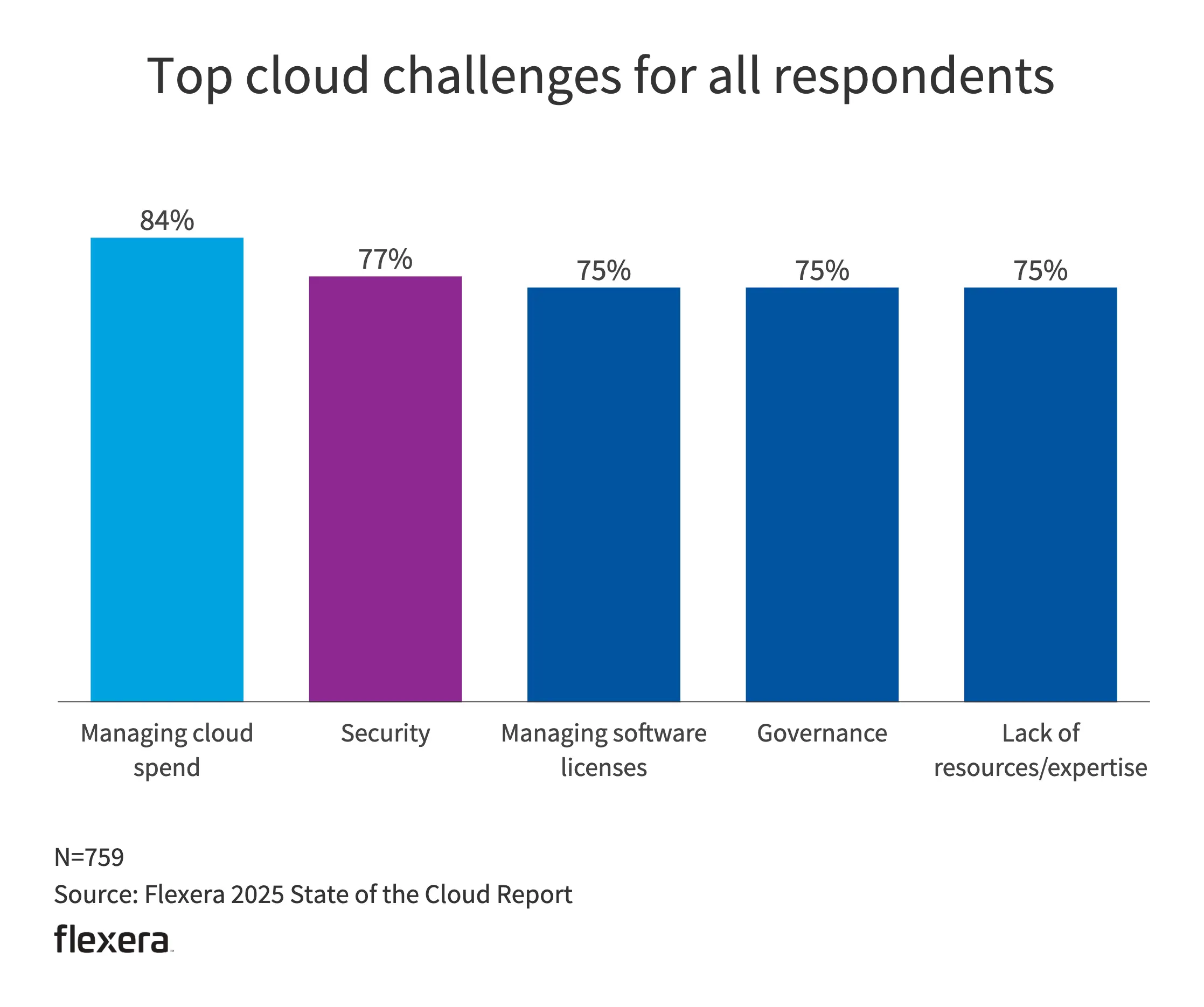
- 在经济下行的现在,最大的挑战显然是支出。
- 安全、管理软件许可、治理、缺少资源与经验则是其余的挑战,彼此不相上下。
cast ai 2025 Kubernetes 成本基准报告
背景
本报告基于对 2024 年 1 月 1 日至 12 月 31 日 期间 AWS、GCP 和 Azure 上 2,100 多家企业的数据分析。该分析排除了 CPU 少于 50 个 的集群,并专注于这些组织在采用 Cast AI 自动化之前的数据。
⚠️ 是一篇有产品推广倾向的文章,信息作简单参考即可。尽管该数据来源于公有云,但仍然反映出资源配置的浪费问题。
相关结论
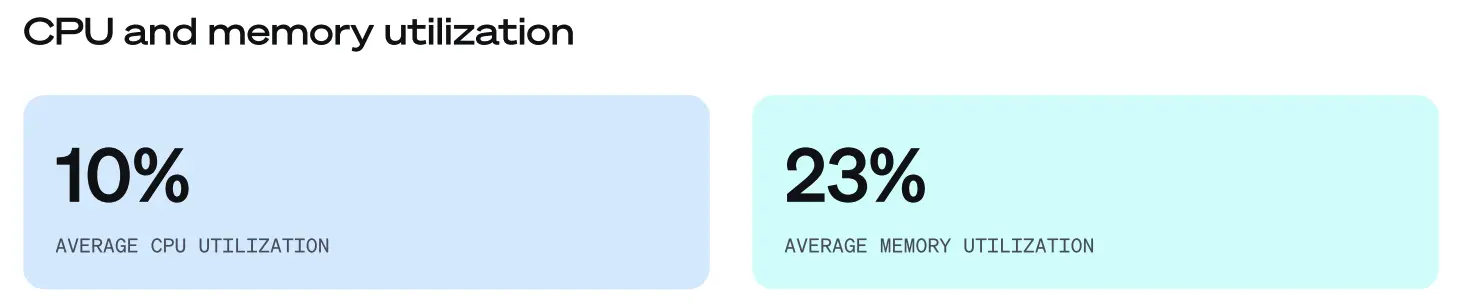
- 集群平均 CPU 利用率仅 10%(同比下降 3%),而 平均内存利用率为 23%(同比上升 3%)。这表明,相较于去年的报告,云资源的使用效率并未显著改善。
-
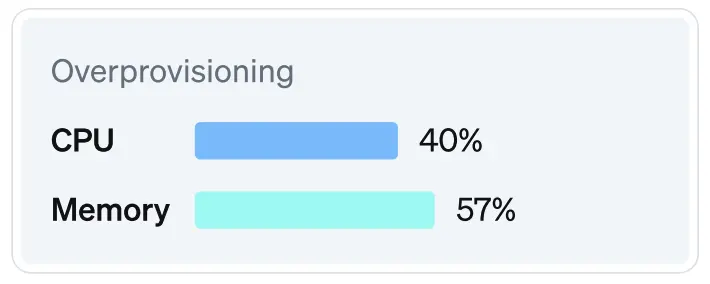
已配置资源与实际请求资源之间的差距仍然较大,平均相差 40%(CPU)和 57%(内存)。尽管 CPU 预期使用率与配置使用率之间的差距有所缩小,但 实际利用率仍然远低于配置容量。
-
99.94% 的集群 CPU 资源过度配置,仅 0.06% 存在资源不足的情况。
售后 case 分析与处理可以参考的思路与方法
Learning from Failure, Why You Should Write Post-Mortems for Your Homelab
事后分析是什么
忽视事件及其根本原因,往往会导致同类问题反复出现,甚至引发更严重的系统故障。如果问题未被记录和共享,它们可能会以不同的形式再次发生。因此,我们应采取相反的策略:
- 创建事件的书面记录
- 分析其影响
- 记录修复所采取的措施
- 确定根本原因
- 概述防止再次发生的后续步骤
事后分析不仅仅是一个流程性任务,更是一种文化实践。它的目的不是追究责任,而是从失败中学习,迭代优化系统。高可靠性的基础设施不仅依赖于优秀的工程实践,更依赖于持续改进的能力。
如何撰写可靠的事后分析报告
撰写事后分析报告没有统一的标准,因为每个组织都有自己的格式。但是,根据 Google SRE 工作手册,一份好的事后分析报告应该遵循结构化的格式,以确保事件的所有关键方面都得到记录。以下是典型的结构:
- 基本信息:事件标题、日期、所有者、受影响的团队以及报告状态(草稿/最终版)。
- 执行摘要:事件的高层概述:发生了什么、其影响、根本原因和解决方案。
- 问题描述:事件的持续时间、受影响的系统、用户影响以及潜在的财务后果。
- 检测过程:如何发现问题(监控、警报、用户报告)以及识别问题需要多长时间。
- 解决方案:缓解和完全解决问题所采取的步骤,包括恢复时间。
- 根本原因分析:深入研究问题出在哪里,包括任何触发事件和潜在的系统故障。
- 时间线/恢复过程:按时间顺序细分事件响应期间的关键事件、采取的行动和做出的决定。
- 经验教训:总结有效的措施、改进点,以及可能影响事件发展的运气因素。
- 行动项目:跟进任务,防止再次发生,改善监测,并增强系统恢复能力。
- 附加文档(可选):日志、图表、相关事件报告和技术术语表。
指责游戏:避免“猎巫”心态
高质量的事后分析不应成为“追责大会”。当人为错误导致系统故障时,沮丧情绪在所难免,但真正值得关注的问题是:
- 我们的系统怎么会导致这种故障发生?
- 我们如何才能在未来让它更有弹性?
事后分析的重点不应是追究个人责任,而是找出系统架构、流程或保障机制中的缺陷。每次事故都应被视为一次学习机会,推动基础设施、监控能力和自动化水平的持续提升。
这正是持续改进的核心理念。通过培养“无责备”文化,可以鼓励团队保持透明、主动问责并增强协作。最可靠的系统不是从不失败的系统,而是能够安全地应对失败并快速恢复的系统。
CNCF Kubernetes 策略工作组《下移安全论文》
Shift-Down Security:How Cloud Native Platform Teams Can Help Break the Logjam
可以直接阅读原文。
Shift-Down Security 的核心理念:将安全责任从开发者(Shift-Left)下沉至平台工程团队,通过在平台层内置安全能力,实现 “默认安全”(Secure by Default)。
如何规划集群规模
One giant Kubernetes cluster for everything
背景
Kubernetes集群规模规划是系统设计初期(Day 0)就必须明确的关键决策。
在架构选择的光谱中,一端采用单一大型集群,另一端部署多个小型集群,中间存在各种混合方案。这一决策将长期影响组织的基础设施架构。更值得注意的是,后期调整集群拓扑将导致巨大的时间和资源浪费。
单一大型集群的优点
- 提升资源利用率
- 减少运维管理成本
- 简化的网络通信和服务发现机制
- 统一的治理策略
- 更具成本效益(仅需维护单个控制平面)
单一大型集群的缺点
- 故障影响范围更大
- 复杂的多租户管理
- 可伸缩性限制
- 集群层级对象的唯一性,例如 CRD
作者的建议
两个集群:一个用于生产,另一个用于其他一切。并通过 vCluster 缓解单一巨型集群的问题。(注:此方案可能存在商业推广倾向)
IaC(基础设施即代码)中的抽象债务
The Abstraction Debt in Infrastructure as Code
早期
在基础设施即代码(IaC)的初期实践中,我们的目标十分明确:实现跨多环境的高效、规模化、精准且一致的管理。这一愿景虽为众多团队所共有,但随着系统规模的扩展,现有工具的局限性逐渐显现。
最初,抽象化被视为理想的解决方案。然而,一个始料未及的问题随之浮现:过度抽象化演变成了技术债务。抽象的本意在于封装复杂性,但若实施不当,反而会导致系统透明度的丧失——难以洞察底层实际运行状况。当系统不可避免地出现故障时,新成员不得不穿透层层抽象才能诊断基础性问题。原本旨在简化基础设施管理的尝试,最终却成为了系统理解和故障排查的障碍。核心挑战在于:如何在保持必要复杂性的同时避免过度抽象,实现流程简化的平衡?
抽象成为负担的地方
尽管抽象化被广泛认可为最佳实践,但其负担效应会快速显现。过深的模块嵌套使得资源交互逻辑难以理解。基于 Terraform 构建的自定义封装层和内部 CLI 工具,不仅带来了额外的学习成本,更增加了调试的复杂度。隐式标记方案或模块内嵌假设等隐性依赖关系,使得排查非显性问题变得尤为困难。当抽象化达到某个临界点后,其维护和调试所需的开销将超过代码复用带来的收益。
如何平衡简单与过度抽象
为避免抽象化成为负担,关键在于把握适度原则。必须保留"应急出口",允许工程师在必要时绕过抽象层直接操作。Terraform 模块设计应当支持关键参数的直接修改,而非强制使用预设默认值。可观测性应当作为首要设计原则:抽象层需提供清晰的日志记录、结构化的输出以及对底层配置的可视化访问。完善的版本控制和文档说明同样不可或缺,确保抽象设计的意图透明可理解。最后需要强调的是,抽象化应该在某个模式被至少原生实现一次后再行引入,过早的抽象往往会导致过度设计而非效率提升。
构建 LangGraph 代理来对 GitOps 漏洞进行优先级排序
How We Built a LangGraph Agent To Prioritize GitOps Vulns
背景
在当今复杂的 Kubernetes 环境中,漏洞管理和优先级排序工作往往令人应接不暇。当数十个甚至数百个容器跨多个服务运行时,如何科学决策漏洞修复的优先级?
传统方法仅依赖严重性评分(Critical/High/Medium/Low),却忽略了具体基础设施环境的上下文。例如:内部非关键服务中的 High 级别漏洞,其紧急程度可能远低于面向互联网组件中的 Medium 级别漏洞。
做法
我们开发了 HAIstings 系统,帮助基础设施团队基于多维因素评估漏洞优先级:
- 基础严重程度(Critical/High/Medium/Low)
- 基础设施环境特征(来自 GitOps 仓库的配置)
- 用户提供的组件关键性评估
- 通过对话式交互持续优化理解
更多内容见原文。
VMware 将于 2025 年终止支持哪些产品?
VMware Products Going EOL in 2025: The Full-Year Rundown
VMware 产品线众多,通过一篇文章整理 2025 年 EOL 的情况,蛮清晰。
云原生和边缘原生
⚠️ 本文虽然包含 nats 的产品推广内容,但其前半部分的技术分析仍具参考价值。云环境与边缘环境的应用场景存在本质差异,这直接导致了"云原生"与"边缘原生"两种截然不同的设计范式。
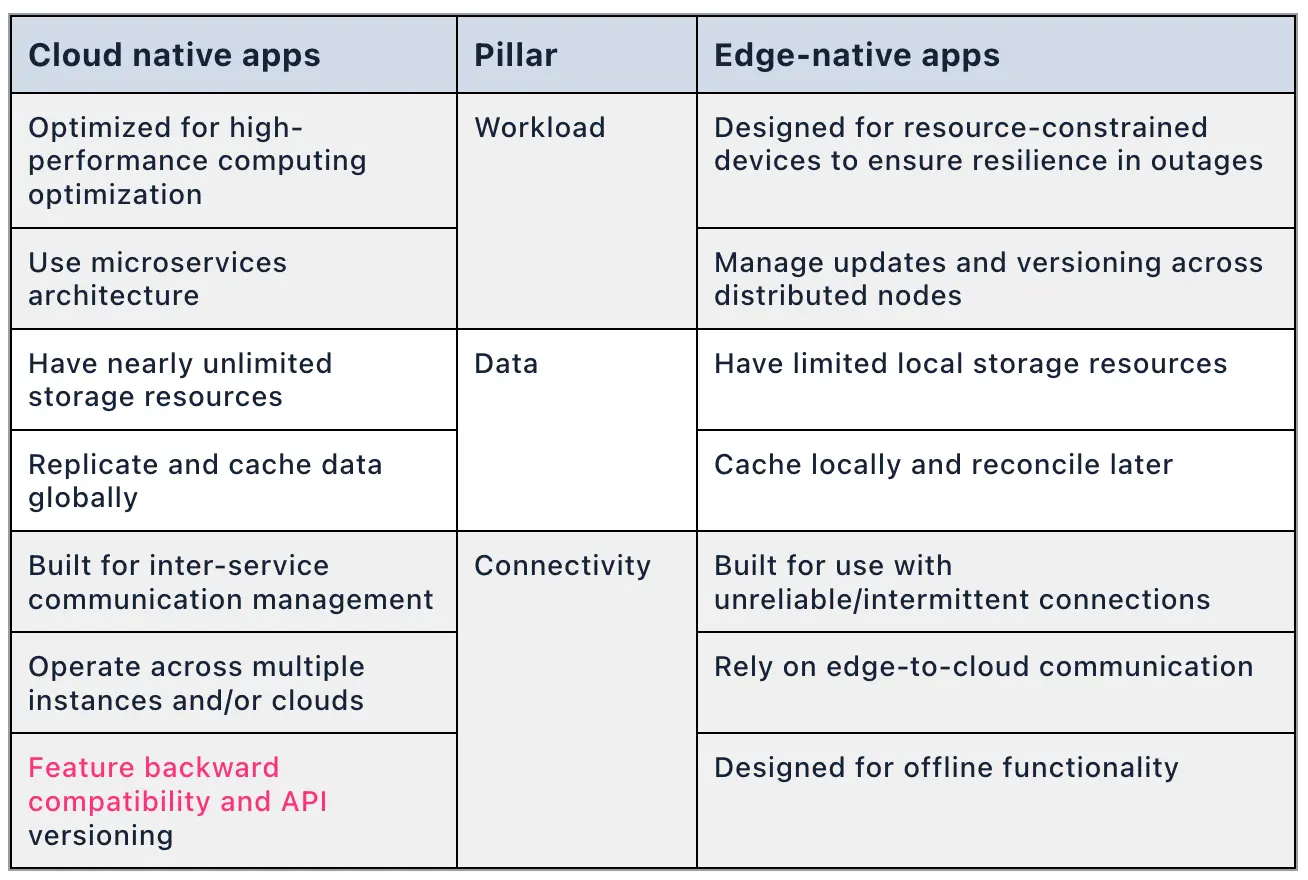
如何避免 Kubernetes 中的核心服务混乱
How to Avoid Core Services Chaos in Kubernetes
背景
尽管 Kubernetes 提供强大的容器编排能力,但其核心服务组件(包括网络、服务发现、Ingress、DNS、证书管理、日志及监控等)需要独立配置。初期实践中,团队往往采用临时方案组合开源工具与自定义脚本来搭建这些服务。随着时间推移,这种分散式管理会导致以下问题:
- 跨集群的组件差异(如不同 Ingress 控制器版本)
- 日志采集配置不一致
- 监控体系碎片化
- 维护成本呈指数级增长
痛点分析
-
环境一致性难题
在保证必要灵活性的同时,维持跨环境配置一致性是首要挑战。 -
可观测性困境
各集群产生的海量日志和指标若缺乏统一管理,将导致:i. Prometheus 和 Fluentd 等工具部署不一致
ii. 监控数据噪声大于有效洞察 -
证书管理风险
大规模环境中手动管理证书将引发:
i. 证书过期导致服务中断
ii. 密钥轮换操作风险 -
安全策略缺口
分散式架构隐藏的安全隐患包括:
i. 配置错误的 Ingress 规则
ii. 未及时更新的服务版本
iii. 难以全局检测的漏洞
最佳实践
-
定义标准化核心服务蓝图
组织应创建一套基本的核心服务(网络、安全、可观察性和自动化),每个集群都必须包含这些服务。该蓝图应定义首选工具和配置,确保每个集群都使用相同的基础组件构建。
-
使用自动化实现一致性和效率
i. Helm charts:服务模板化部署
ii. ArgoCD:GitOps 实践
iii. Crossplane:多云资源编排
iv. Terraform:混合云环境管理 -
集群舰队管理模式
平台团队不应单独管理每个集群,而应实施包含所有必要核心服务的模板化集群配置。通过将基础设施定义为代码,组织可以部署预装核心服务的新集群,从而减少设置时间和操作偏差。
-
监控并执行跨集群的策略合规性
使用集中监控和安全策略实施工具有助于保持跨环境的一致性。Fluentd 和 Prometheus 提供了对集群运行状况的可见性,而安全策略应通过 Kyverno 或 OPA Gatekeeper 等自动化策略引擎来实施。
-
版本兼容性和升级规划
随着核心服务的发展,保持多个集群之间的版本一致性至关重要。组织应采用结构化的升级策略,在生产环境中推出更改之前先在暂存环境中测试更改,并利用自动化来最大限度地减少停机时间。
为什么不应强制终止正在删除的命名空间,以及如何查找遗留资源
Why you should not forcefully finalize a terminating namespace, and finding orphaned resources
一篇技术分享,具体见原帖。
Kubernetes RBAC 管理的相关讨论
Is Kubernetes RBAC Too Painful? How Are You Managing It?
一篇经验讨论,具体见原帖。
Kubernetes 和 Openshift 的对比讨论
Difference between K8s and Openshift
讨论里面的一些观点摘要:
- Kubernetes 面临的最大挑战之一是维护,尤其是对于小型团队而言。跟上更新、管理兼容性和处理发布是一项持续不断的挑战。Kubernetes 提供了灵活性,但需要您自己组装和维护一切。
- OpenShift 强制实施更多标准化,而 Kubernetes 则提供完全控制。如果您拥有专业知识并希望获得灵活性,那么 Kubernetes 是一个不错的选择,但 OpenShift 可以成为具有企业支持的良好“即插即用”选项。
- OpenShift 很贵。但是,管理层决定使用它,作为一名平台工程师,我很高兴使用它。只要我能拿到工资,少些烦恼。
- 作为一名被迫使用 OpenShift 的 Kubernetes 工程师,它给我带来的麻烦比上游的还要多。
- 如果您的组织现在需要 Kubernetes,但又不想设计自己的平台,那么 OpenShift 实际上是一个很好的起点。企业支持 == 风险缓解。
- 对我来说,openshift 相对于 kubernetes 的最大优势是它运行的 RHCOS 操作系统。它是一个开箱即用的极简、非常安全的操作系统,所有配置都通过 kubernetes 资源(machineconfig/machineconfigpool)处理。您几乎永远不需要通过 ssh 连接到节点来“维护”它。如果主机遇到问题,我们只需在本地重建它,5-15 分钟后将其重新加入集群。在 aws 中甚至更容易,删除节点然后机器集将替换它。当然,在我看来,用户管理更简单。使用合规操作员,我们很容易满足大多数 CMMC 安全准则。我的用户喜欢 WebUI。我觉得开箱即用的 pod 安全性和 scc(安全上下文约束)更容易为合规性和安全性审计提供安全的环境,但这也是导致大多数用户需要手动操作的原因,因为用户一开始并不理解它。更新和升级非常简单,而且相当可控。operatorhub 让您只需点击几下即可安装操作员。一般来说,我认为并推荐 openshift 给那些想要一个交钥匙解决方案的人,该解决方案具有所有基本功能,并为企业提供多项生活质量改进。如果您处于 Redhat 生态系统中,那就更有意义了。
kubectl 使用技巧讨论
You probably aren't using kubectl explain enough.
讨论中介绍了很多技巧,学海无涯。
人工智能时代的 6 项基本人类技能
Future-proof your tech career: 6 essential human skills for the AI era
AI 的存在对人类提出了配合的要求,人类需要学习适应 AI 了。
开始使用自托管(分享)
虽然并不是该文章的真正受众,但是读到这样结构清晰的内容总是有种新奇的愉悦的。特别是里面提到 “I just wanted to have some ownership over my data” 和 “but I did have cheap computers and free time”。
✍️产品/方案学习
多集群应用管理相关
帖子中给了一些分类,相对比较系统。下面梳理下。
集群生命周期管理
-
Cluster API 是 Kubernetes 的一个子项目,专注于提供声明性 API 和工具,以简化配置、升级和操作多个 Kubernetes 集群。
-
Kubean 是一个基于kubespray和其他集群 LCM 引擎的生产就绪集群生命周期管理工具链。
-
启动和运行生产级 Kubernetes 集群的最简单方法。将其视为集群的 kubectl。kops 不仅可以帮助您创建、销毁、升级和维护生产级、高可用性 Kubernetes 集群,还可以提供必要的云基础设施。
-
Kamaji 是 Kubernetes 控制平面管理器。它以极小的运营负担大规模运营 Kubernetes。
控制器 & 编排
-
Karmada(Kubernetes Armada)是一个 Kubernetes 管理系统,使您能够在多个 Kubernetes 集群和云中运行云原生应用程序,而无需更改应用程序。通过使用 Kubernetes 原生 API 并提供先进的调度功能,Karmada 实现了真正的开放式、多云 Kubernetes。
-
Open Cluster Management 是一个社区驱动的项目,专注于 Kubernetes 应用的多集群和多云场景。该项目正在开发用于集群注册、工作分配、策略和工作负载的动态放置等的开放 API。
-
帮助用户像“访问互联网”一样轻松地管理多个 Kubernetes 集群(因此得名“Clusternet”)。它是一个通用系统,用于控制不同环境中的 Kubernetes 集群,就像它们在本地运行一样。
-
kubefed v2(archived)
Kubernetes Cluster Federation 又名 KubeFed 或 Federation v2,是 Kubernetes SIG Multi-Cluster 团队新提出的集群联邦架构(Architecture Doc 与 Brainstorming Doc),新架构在 Federation v1 基础之上,简化扩展 Federated API 过程,并加强跨集群服务发现与编排的功能。
-
Azure 云平台汇集的产品和云服务超过 200 种,旨在帮助你将新解决方案付诸实践,以便解决当今的难题,并创造未来。利用所选的工具和框架,在多个云中、在本地以及在边缘生成、运行和管理应用程序。
-
KubeAdmiral 扩展了 Kubernetes Federation v2 API,提供了与 Kubernetes 原生 API 的兼容性以及更强大的资源管理能力。
应用程序管理
-
KubeVela 是一个现代化的软件交付平台,它可以让你的应用交付在当今流行的混合、多云环境中变得更加简单、高效、可靠。
KubeVela 是基础设施无关的、可编程的,但最重要的是: 它是完全以应用为中心的。它可以帮助你构建多样化的云原生应用,并交付到任意的云和基础设施!
-
无需编写代码即可构建控制平面。Crossplane 具有高度可扩展的后端,可让您编排应用程序和基础架构,无论它们在何处运行;它还具有高度可配置的前端,可让您定义它提供的声明性 API。
-
Backstage 是一款围绕服务所有者而非集群管理员的需求而设计的工具。现在,无论服务以何种方式部署或部署在何处,开发人员都可以轻松检查其服务的运行状况 - 无论是在本地主机上进行测试,还是在全球数十个集群上进行生产。
资源搜索
-
clusterpedia(支持 SQL)
Clusterpedia 这个名称借鉴自Wikipedia,是多集群的百科全书,其核心理念是收集、检索和简单控制多集群资源。 通过聚合收集多集群资源,在兼容Kubernetes OpenAPI 的基础上额外提供更加强大的检索功能,让用户更方便快捷地在多集群中获取想要的任何资源。
-
karmada search(mvp)
karmada-search 启动一个聚合服务器,提供多云环境下的全局搜索、资源代理等功能。
网络
-
Cilium 是一种网络、可观察性和安全性解决方案,具有基于 eBPF 的数据平面。它提供了一个简单的平面第 3 层网络,能够以本机路由或覆盖模式跨越多个集群。它具有 L7 协议感知能力,可以使用与网络寻址分离的基于身份的安全模型在 L3-L7 上实施网络策略。
-
Submariner 支持不同 Kubernetes 集群(本地或云端)中的 Pod 和服务之间的直接联网
服务网格
-
Istio 扩展了 Kubernetes,以建立可编程、应用程序感知的网络。Istio 可与 Kubernetes 和传统工作负载配合使用,为复杂的部署带来标准、通用的流量管理、可观测和安全性。
选择所需的功能,Istio 会根据需要部署代理基础设施。使用零信任隧道实现四层性能和安全性,或添加强大的 Envoy 服务代理实现七层功能。
-
唯一为人类设计的服务网格。
无需企业复杂性即可实现企业级功能。Linkerd 可为任何 Kubernetes 集群增加安全性、可观察性和可靠性。100% 开源,CNCF 毕业,使用 Rust 编写。
调度
-
Kueue 是一个云原生作业排队系统,用于 Kubernetes 集群中的批处理、HPC、AI/ML 和类似的应用程序。
-
Armada 是一个多 kubernetes 集群批处理作业元调度程序。它帮助组织在多个集群的多个节点上每天分配数百万个批处理作业。Armada 是 CNCF Sandbox 的一部分。
CICD
其他
-
Liqo 是一个开源项目,支持动态、无缝的 Kubernetes 多集群拓扑,支持异构的内部部署、云和边缘基础设施。
如何在升级 Kubernetes 版本之前确定哪些 API 被弃用了?
除了查看官方文档外,还可以使用工具。
AI 相关
kagent:运行 AI 代理的开源框架
一个供 DevOps 和平台工程师在 Kubernetes 中运行 AI 代理的开源框架,可自动执行复杂的操作和故障排除任务。
2024 年上半年 CNCF Sandbox 中的 14 个云原生项目
Exploring Cloud Native projects in CNCF Sandbox. Part 3: 14 arrivals of 2024 H1
应用程序定义 & 映像构建
-
在官方文档中罗列了与其他多种产品的对比,通过对比更好地介绍自己是谁,是一个蛮好的方式。读了一些产品文档之后,更容易意识到,作为一个当代缺乏耐心的读者,在茫茫产品中很难愿意去停下来细细研究产品。一种思维惯性是希望立刻获取这个产品是做什么的、和其他产品核心的差异是什么。
Radius 是一个开源的云原生应用程序平台,使开发人员和支持他们的运营商能够在公共云和私有基础设施上定义、部署和协作云原生应用程序
-
Stacker
Stacker 是一款用于构建 OCI 镜像的工具,它以静态构建的二进制文件形式提供,并以 YAML 进行配置。
-
Score
Score 是一种以开发人员为中心、与平台无关的工作负载规范。它确保本地和远程环境之间的配置一致。
自动化 & 配置
-
Bank-Vaults 提供的工具使使用和操作 Hashicorp Vault 更加容易。它是官方 Vault 客户端的包装器,具有自动令牌更新和内置 Kubernetes 支持,为基于 Golang 数据库/sql 的客户端提供动态数据库凭据提供程序。它有一个 CLI 工具来自动初始化、解封和配置 Vault。它还提供了一个用于配置的 Kubernetes 操作员和一个用于注入机密的变异 webhook。
-
Trestle 是一套工具,可用于创建、验证和管理文档工件以满足合规性需求。它利用 NIST 的OSCAL作为工具和人员之间交换的标准数据格式,并提供了一种采用 OSCAL 的自定方法。
-
bpfman 是一个 eBPF 管理器。它简化了在 Linux 主机和 Kubernetes 集群上加载/卸载、修改和监控 eBPF 程序的过程。
安全与合规
-
前文介绍过。
-
KubeSlice 是一个与供应商无关的框架,可在部署在不同基础架构中的 Kubernetes 集群之间实现覆盖网络:裸机、云、多云、混合云或边缘。简而言之,它跨集群和云提供多种功能,例如应用程序连接、网络策略、RBAC、DNS 条目、自动服务发现、流量优先级和微服务隔离。
自动化和配置
-
Atlantis 是一款自动执行 Terraform 拉取请求的应用程序。它通过 webhook 监听新事件,远程执行特定的 Terraform 命令( plan 、 import 、 apply ),并通过评论相关的拉取请求来添加其输出。
-
Kubean 建立在 kubespray 之上,旨在简化和自动化您在生产中运行的 Kubernetes 集群的 Day 2 操作。当您拥有现有集群时,它会介入,主要作为 Kubernetes 操作员实现,该操作员由多个用于监控各种对象的控制器组成:集群节点、清单等。
远程过程调用
-
Connect 是 Protobuf RPC 的跨语言框架,其座右铭是“简单、可靠、可互操作”。Connect 的创建是为了回应当今 gRPC 库的“极端主义设计精神导致了极大的复杂性”,它简化了构建与浏览器和 gRPC 兼容的 HTTP API。
WebAssembly & 边缘计算
-
Kairos 是适用于在边缘上运行的 Kubernetes 集群的不可变 Linux 发行版。基本上,它允许您使用您选择的 Linux 发行版和 Kubernetes 为边缘设备创建可启动映像。
API 网关
-
Kuadrant 提供了一套用于在 Kubernetes 中实施网关策略的工具。它允许运营商和开发人员“连接、保护和观察服务端点”。
数据库
-
openGemini 是一个分布式 TSDB(时间序列数据库)。它专注于提供高性能读写以及数据分析功能。
无分类
KWOK:可用少量资源构建大量虚假节点
KWOK 是什么
KWOK 发音为/kwɔk/,是 Kubernetes WithOut Kubelet 的缩写,目前提供两种工具:
- kwok 是该项目的基石,负责模拟虚假节点、pod 和其他 Kubernetes API 资源的生命周期。
- kwokctl 是一个 CLI 工具,旨在简化集群的创建和管理,其中节点由 kwok 模拟。
KWOK 是一款工具包,可在几秒钟内设置数千个节点的集群。在场景中,所有节点都模拟为与真实节点一样运行,因此整体方法占用的资源非常少,您可以在笔记本电脑上轻松试用。
KWOK 的使用场景
适用于需要测试 Kubernetes 但又不想消耗太多资源的场景,比如性能测试、规模测试等等。
与其他产品的对比
KWOK vs. kubemark —— 资源消耗
kubemark 是一个不真正运行容器的 kubelet,其行为与 kubelet 完全相同,也就是说模拟大量节点和 pod 需要大量内存。
kwok 只是模拟节点的行为。因此,它可以使用很少的内存来模拟大量节点和 pod。
KWOK vs. kind —— 是否真实
kind 在 Docker 中运行 Kubernetes,创建一个真正的集群。如果你将一个 nginx pod 部署到 kind 集群,您可以 curl 到其 IP 地址并获取包含其 HTML 页面的 HTTP 响应。但在 KWOK 集群中,您什么也得不到,因为 pod 不是真实的。
在某些不需要实际运行任何 pod 的情况下,可以使用 kwokctl 来替代 kind。
KWOK 的优势
- 轻量级:可以在笔记本电脑上模拟数千个节点,且不会消耗大量 CPU 或内存资源。目前,KWOK 可以轻松可靠地维护 1k 个节点和 100k 个 pod。
- 快速:可以几乎立即创建和删除集群和节点,无需等待启动或配置。目前,KWOK 每秒可以创建 20 个节点或 Pod。
- 兼容性:KWOK 可与任何符合 Kubernetes API 的工具或客户端配合使用,例如 kubectl、helm、kui 等。
- 可移植性:KWOK 没有特定的硬件或软件要求。可以安装 Docker/Podman/Nerdctl 后,使用预构建的镜像运行它。或者,二进制文件也适用于所有平台,并且可以轻松安装。
- 灵活性:可以配置不同的节点类型、标签、污点、容量、条件等,并且可以配置不同的 pod 行为、状态等来测试不同的场景和边缘情况。
KWOK 的缺点
- 不能运行真实的 Pod 和应用
- 不能测试 Kubelet 相关的功能
- 不能测试实际的网络情况
Kube-Sec:安全配置错误和漏洞的扫描工具
Kube-Sec 是什么
Kubernetes Security Hardening CLI 是一款用于扫描 Kubernetes 集群是否存在安全配置错误和漏洞的工具。它有助于识别以下问题:
- 特权容器
- RBAC 配置错误
- 可公开访问的服务
- 以 root 身份运行的 Pod
- 主机 PID/网络暴露
Kube-Sec 有哪些功能
- 集群连接:支持 kubeconfig 和服务帐户身份验证。
- 安全扫描:检测潜在的错误配置和漏洞。
- 计划扫描:每天或每周运行后台扫描。//未完成
- 日志记录和报告:记录安全扫描结果并以 JSON/CSV 格式导出报告。
- 可定制的检查:允许用户禁用特定的安全检查。
Devtron:工具集成平台
Devtron 是什么
Devtron 是 Kubernetes 的工具集成平台。Devtron 通过直观的 Web 界面与微服务生命周期内的产品(即 CI/CD、安全性、成本、调试和可观察性)深度集成。Devtron 可帮助您在所有集群中部署、观察、管理和调试现有的 Helm 应用程序。
Devtron 的特点
- Kubernetes 的无代码软件交付工作流程
- 多云部署
- 轻松集成 DevSecOps
- 应用程序调试仪表板
- 企业级安全性和合规性
- 实现 GitOps
- 运营洞察
LoxiLB:超大规模软件负载均衡器
简介
LoxiLB 是一款适用于云原生工作负载的开源超大规模软件负载均衡器。它使用 eBPF 作为核心引擎,并基于 Golang。
LoxiLB 将 Kubernetes 网络负载均衡转变为高速、灵活且可编程的 LB 服务。它可自动执行外部负载均衡器管理任务:部署、引导、配置、配置、扩展、升级、迁移、路由、监控和资源管理。它主要用于支持本地、边缘和公有云 Kubernetes 应用,但它也可以作为独立负载均衡器运行。
优势
- 高性能
- 专门构建的基于 eBPF 的数据平面
- 专为高性能和可扩展性而设计
- 云原生
- 云原生设计
- 全面支持k8s
- 裸机和公有云 K8s 支持
- 互操作性
- 使用 goBGP 轻松导出您的云原生 k8s 微服务
- 面向未来
- 与 MEC/OpenRAN 本地集成
- 支持 SRv6、SCTP、GTP (ext) 等
xlskubectl:通过电子表格管理 Kubernetes 集群
“用电子表格取代 YAML 一直是我们公司的使命,我们将继续这样做。”
评论刻薄又不失礼貌:
- Sounds amazing. Now can someone make a way to control Kubernetes from PowerPoint? Or Outlook Calendar?
- Wow you invented pain as a service
wanaware:智能可观察性平台
简介
WanAware 智能观测平台为您所有连接的资产提供实时洞察与可执行方案。
特点
-
网络安全
使用我们的知识发现引擎进行业界领先的威胁检测和响应,每天主动扫描 > 100 亿个公共 IP 和所有私有 IP 的攻击面和应用程序。
-
性能
通过实时监控和分析每个公共和任何私有 IP 地址的流量模式和流程,获得全面的性能洞察、问题识别和解决方案。
-
可用性
我们的全球监控平台通过跟踪每个 IP 地址、准确识别问题并触发自动补救措施以快速解决问题,提供实时资产可用性。
-
成本低
Shipwright:构建容器镜像的可扩展框架
简介
Shipwright 是一个用于在 Kubernetes 上构建容器镜像的可扩展框架。声明并重用构建策略来构建您的容器镜像。
特点
-
易集成
由于使用了 Kubernetes API,Shipwright 可以无缝融入现有的 Kubernetes 堆栈。
-
可观测性
通过 Kubernetes 事件和日志,你可以追踪构建状态,方便调试和优化。
-
灵活扩展
不需要修改核心代码,只需编写插件即可增加新的功能。
Descheduler:节点调度器
简介
Descheduler 组件是一个可选的 Kubernetes 插件,用于自动化 Kubernetes 集群中节点的调度和优化。它的主要目的是解决 Kubernetes 集群中节点资源利用率不高的问题,通过在集群中调度和剔除空闲或低负载节点来优化集群的资源利用率。
Kubernetes 中的调度是将待处理的 Pod 绑定到节点的过程,由 Kubernetes 的组件 kube-scheduler 执行。调度程序的决定(即是否可以或不能在何处调度 Pod)由其可配置策略指导,该策略由一组规则(称为谓词和优先级)组成。当出现新的 Pod 进行调度时,调度程序的决定会受到其对 Kubernetes 集群的看法的影响。由于 Kubernetes 集群非常动态,并且其状态会随时间而变化,因此出于各种原因,可能需要将已经运行的 Pod 移动到其他节点:
- 一些节点利用率过低或者过高。
- 原来的调度决策不再成立,因为污点或标签被添加到节点或从节点中删除,pod/节点亲和性要求不再得到满足。
- 一些节点出现故障,其 pod 移动到其他节点。
- 新节点被添加到集群。
因此,集群中可能会有多个 Pod 被调度到不太理想的节点上。Descheduler 根据其策略找到可以移动的 Pod 并将其驱逐。请注意,在当前实现中,descheduler 不会安排替换被驱逐的 Pod,而是依靠默认调度程序来完成。
使用场景
例如确保 Pod 在故障转移后返回原始节点。
Wait4X:等待各种端口和服务达到预期状态
简介
Wait4X 是一款功能强大的零依赖工具,它会等待服务准备就绪后再继续。它支持多种协议和服务,是以下应用不可或缺的组件:
- CI/CD 管道- 确保在测试运行之前依赖项可用
- 容器编排——应用启动前的健康检查服务
- 部署流程- 部署前验证系统准备情况
- 应用程序初始化- 验证外部服务可用性
- 本地开发- 简化本地主机服务就绪性检查
特点
- 多协议支持:TCP, HTTP, DNS
- 服务集成:Redis, MySQL, PostgreSQL, MongoDB, RabbitMQ, InfluxDB, Temporal
- 反向检查:反转检查以查找可用端口或未就绪的服务
- 并行检查:同时检查多个服务
- 指数退避:增加延迟以重试以提高可靠性
- CI/CD 集成:专为自动化工作流程而设计
- 跨平台:适用于 Linux、macOS 和 Windows 的单一二进制文件
- Go 包:导入到您的 Go 应用程序中
- 命令执行:检查成功后运行命令