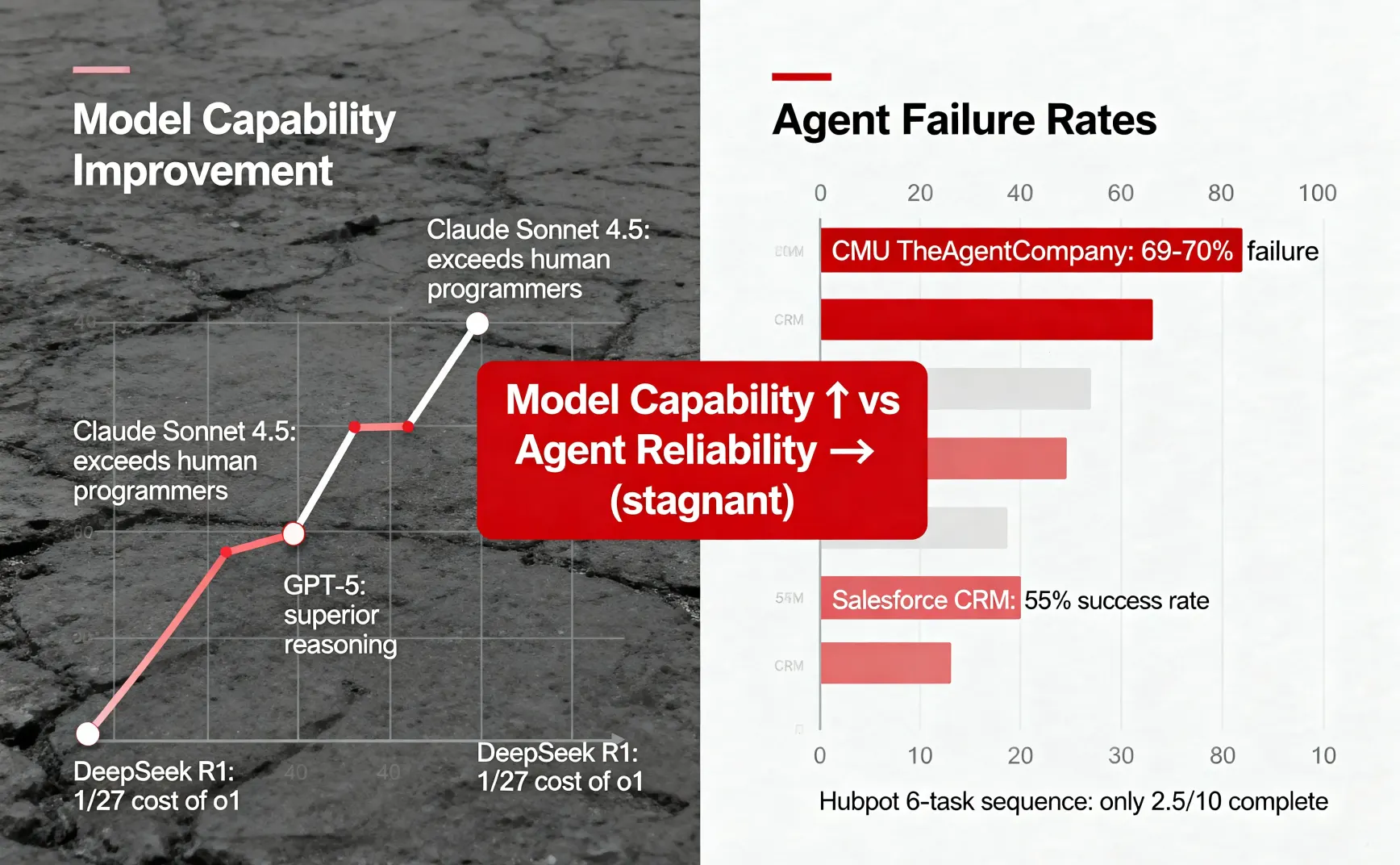
卡内基梅隆大学(CMU)和 Salesforce 的联合研究显示,在真实办公场景测试中,Gemini 2.5 Pro、Claude 3.7 Sonnet、GPT-4o 等顶级模型的 Agent 失败率达 69%-70%。
在 CRM 系统专业任务上,成功率仅 55%。连续完成 6 个任务,10 次尝试中只有 2.5 次能全部成功。
MiniMax 对此做了严格对照实验。数据显示,保留推理状态的 M2 模型,在 Tau²(工具使用)任务上比丢弃状态的版本提升 35.9%,在 BrowseComp(网页浏览)任务上提升 40.1%。
MiniMax 工程负责人 Skyler Miao 表示:"Anthropic 在 5 个月前就推出了 Interleaved Thinking,但社区支持仍然有限。OpenAI Chat Completion API 不支持传回推理内容,这是根本原因。"
但问题正在解决。MiniMax-M2 是第一个完整支持 Interleaved Thinking 的开源模型,成本仅 Claude 的 8%。
发布一周后,M2 在 OpenRouter 平台使用量跻身前 3。
文丨朴哲一
编辑丨TrueInk
Agent 失败率数据
CMU 和 Salesforce 在 2025 年上半年发布了两项研究。
CMU 的 TheAgentCompany 基准测试搭建了一个仿真办公环境,包含 Slack、文档管理、HR 系统、内部应用。测试对象是 Gemini 2.5 Pro、Claude 3.7 Sonnet、Claude 3.5 Sonnet、GPT-4o。任务包括处理 Slack 消息、操作文档系统、使用 HR 机器人、写代码和生成报告。
结果是,最好的 Agent 在多步骤任务上失败率 69%-70%。这意味着 10 次任务中,7 次失败。
Salesforce 的研究聚焦 CRM 系统。专业任务成功率仅 55%。在 Hubspot 平台连续完成 6 个任务,10 次尝试中只有 2.5 次能全部成功。即使换成 Composio 连接器或让 Cursor 生成代码,10 次尝试中也只有 4 次能完成。
行业调研显示,39% 的 AI 项目在 2024-2025 年未达预期。但 51% 的企业计划在 2025 年加大 Agent 投资,三年内这个数字会涨到 82%。
数据之间的矛盾在于:模型越来越强,但 Agent 可靠性未同步提升。
Claude Sonnet 4.5 在编程任务上已超越人类程序员,GPT-5 推理能力远超 GPT-4,DeepSeek R1 用强化学习做推理,性能接近 OpenAI o1,成本却是 1/27。
问题不在模型智商,在执行机制。
执行机制的缺陷
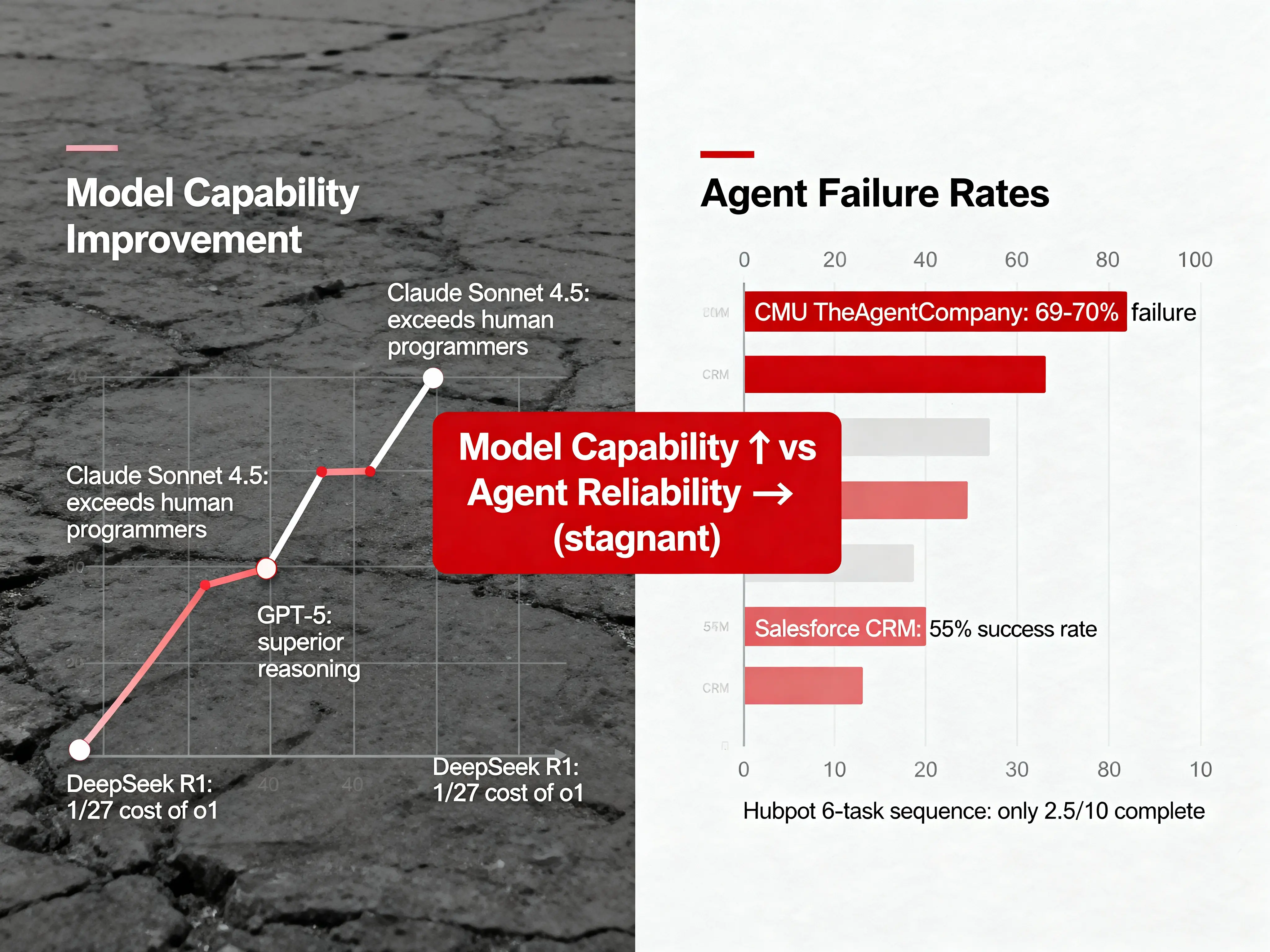
Agent 任务和普通问答不同。普通问答是一问一答,Agent 任务是多步骤的工具调用链。
以"调研 MiniMax-M2 并写技术报告"为例,Agent 需要搜索官方文档、社区讨论、媒体报道、代码示例,整理信息,生成大纲,撰写初稿,检查数据,完成报告。每个步骤都要调用工具,每个工具的返回结果都不确定。
问题出在工具调用失败后的处理。
理想流程是:搜索官方文档成功,搜索社区讨论成功,搜索媒体报道成功,完成报告。
现实流程是:搜索官方文档成功,搜索社区讨论失败(关键词太宽泛,结果无关),接下来有两种可能。
可能 1:继续按原计划执行。搜索媒体报道,搜索代码示例,撰写初稿。最终报告缺少社区反馈部分,质量不达标。
可能 2:调整策略。换关键词"MiniMax M2 interleaved thinking",重新搜索,找到高质量讨论,继续后续步骤,报告完整。
传统 Agent 是可能 1。工具调用出现意外,无法自我纠正,任务失败。
人类解决复杂问题的方式是 plan → act → reflect 循环。
制定计划,执行第一步,看结果评估,根据结果调整计划,继续执行,再看结果再评估。
传统 Agent 是 plan → act → act → act,缺少 reflect。
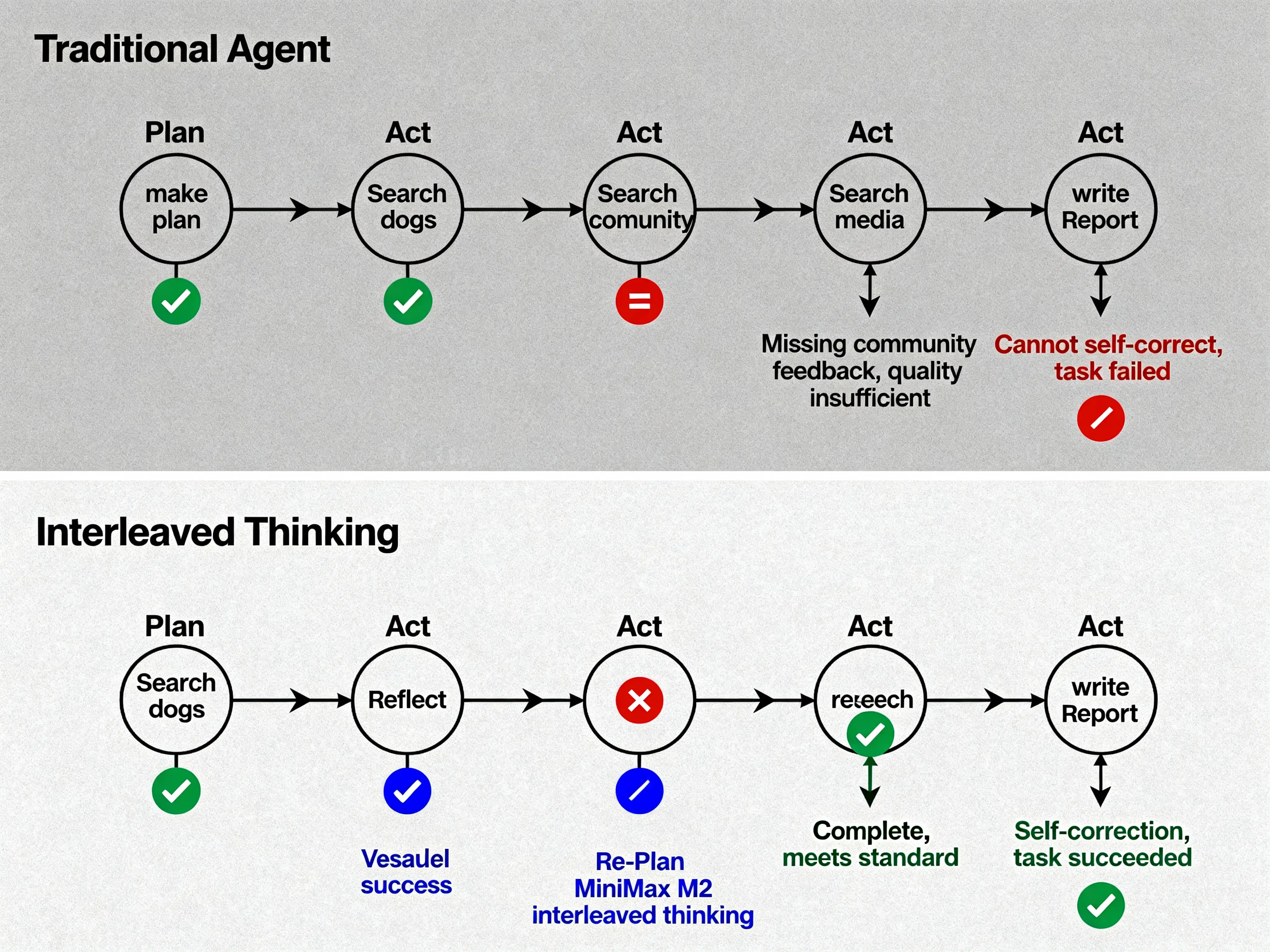
这种机制在学术界叫 Chain of Thought(CoT),2022 年 Google 提出。
CoT prompting 让模型"先想再答",效果提升。
但只能前置思考,不能边做边想。
2024 年,OpenAI o1、DeepSeek R1 推出 Extended Thinking(长时间思考)。
在开始任务前分配大量 tokens 做深度推理,复杂推理任务提升巨大。但依然是前置思考,想完再做。
2025 年 5 月 14 日,Anthropic 发布了 Claude Sonnet 4。
这个版本有个重要特性:在 API 层面支持 Interleaved Thinking。
在多轮对话中,模型会输出两种 content blocks:
thinkingblock:推理过程textblock:最终回答
关键是,thinking block 可以传回给模型。
{
"content": [
{
"type": "thinking",
"thinking": "用户要我搜索社区讨论,但结果不理想。我需要调整策略,换一个关键词..."
},
{
"type": "text",
"text": "我重新搜索了相关讨论,找到了更多信息..."
}
]
}
下一轮对话,把整个 content 传回去,模型就能"记住"上次的思考过程,继续推理。
在工具调用之间插入思考过程,plan → act → think → act → think。
区别在于,CoT 和 Extended Thinking 是"想完再做",Interleaved Thinking 是"边做边想"。
MiniMax-M2 的对照实验
2025 年 10 月 27 日,MiniMax 发布 M2 模型。230B 参数(总量),10B 激活(MoE 架构),开源权重(Hugging Face 可下载),性能达 Claude Sonnet 4 的 90%,成本仅 Claude 的 8%。
M2 是第一个完整支持 Interleaved Thinking 的开源模型。在此之前,只有 Claude Sonnet 4 支持,且闭源。
MiniMax 做了严格对照实验。实验组保留 prior-round thinking state(每轮思考都传回模型),对照组丢弃 thinking state(传统做法,只传 text),测试集是 5 个 Agent 能力 benchmark。
结果:
| Benchmark | 保留状态 | 丢弃状态 | 绝对提升 | 相对提升 | 任务类型 |
|---|---|---|---|---|---|
| SWE-Bench Verified | 69.4 | 67.2 | +2.2 | +3.3% | 软件工程 |
| Tau² | 87 | 64 | +23 | +35.9% | 工具使用 |
| BrowseComp | 44.0 | 31.4 | +12.6 | +40.1% | 网页浏览 |
| GAIA | 75.7 | 67.9 | +7.8 | +11.5% | 通用 Agent |
| xBench | 72.0 | 66.0 | +6.0 | +9.1% | 综合能力 |
Tau²(工具使用)提升 35.9%,BrowseComp(多步骤任务)提升 40.1%。

这不是参数变大、训练数据变多带来的提升,是机制性改进。
任务越复杂,提升越明显。SWE-Bench(相对单一的编程任务)提升 3.3%,BrowseComp(需要浏览多个网页、提取信息、综合判断)提升 40.1%。
越需要调整策略的任务,收益越大。
对照组也是 MiniMax-M2,只是不保留 thinking state。
同一个模型,只是改了调用方式,性能差 40%。
这证明,Agent 可靠性问题不是模型不够聪明,是执行机制有缺陷。
Interleaved Thinking 通过保持推理状态,让 Agent 记住之前的思考过程,根据工具返回结果重新评估,动态调整后续策略,从错误中自我纠正。
这是 plan → act → reflect 循环的威力。
类比 AlphaGo。
传统围棋 AI 计算最优的 10 步棋,然后按计划下完,类似"想完再做"。
AlphaGo 的 MCTS(蒙特卡洛树搜索)每走一步重新搜索,根据当前局面重新评估后续策略,类似"边做边想"。
区别在 test-time compute 的分配方式。
传统方法把算力都花在开始前的规划,MCTS 把算力分配到每一步的决策。
Interleaved Thinking 是 Agent 版的 MCTS。
OpenAI API 的设计缺陷
Claude Sonnet 4 在 2025 年 5 月就支持 Interleaved Thinking。
到 11 月,已经半年。但 MiniMax 官方 11 月 2 日发文称:"我们很惊讶社区对 Interleaved Thinking 的支持这么差。
Sonnet 4 在 5 个月前就推出了,但采用率仍然有限。"
问题出在 API 设计。
AI 应用开发主要用两种 API:OpenAI Chat Completion API和 Anthropic Messages API。
OpenAI Chat Completion API 的 assistant 消息只有一个 content 字段。推理过程无处存放。
OpenAI Chat Completion API:
{
"model": "gpt-4o",
"messages": [
{"role": "user", "content": "帮我搜索 MiniMax-M2"},
{"role": "assistant", "content": "我找到了相关信息..."},
{"role": "user", "content": "继续分析"}
]
}
注意:assistant 的消息只有一个 content 字段。
即使模型内部有推理过程,API 也不返回,下一轮也传不回去。
Anthropic Messages API 的 content 是数组,可以包含多个 blocks:thinking block(推理过程)和 text block(最终回答)。
下一轮对话,把整个 content 传回去,模型就能继续推理。
Anthropic Messages API:
{
"model": "claude-sonnet-4-20250514",
"messages": [
{
"role": "user",
"content": "帮我搜索 MiniMax-M2"
},
{
"role": "assistant",
"content": [
{
"type": "thinking",
"thinking": "用户要我搜索 MiniMax-M2。我先搜索官方文档,然后搜索社区讨论..."
},
{
"type": "text",
"text": "我找到了相关信息..."
}
]
}
]
}
注意:content 是一个数组,可以包含多个 blocks。
thinkingblock:推理过程textblock:最终回答
下一轮对话,把整个 content 传回去,模型就能继续推理。
OpenAI 的 Chat Completion API 是 2023 年 3 月随 GPT-3.5 Turbo 发布的,那时还没有 Interleaved Thinking 概念。
API 设计很简单:user 说话,assistant 回答,内容是字符串。
后来有了 reasoning models(o1、o3),OpenAI 也没改 API 结构。
原因是兼容性。
全世界有几百万个应用基于这个 API 开发,改了就全炸了。
OpenAI API 是市场主流,生态最大。
结果是,大部分 AI 应用基于 OpenAI API 开发,即使接入 Claude,也用 OpenAI-compatible 模式。
推理内容传不回去,Interleaved Thinking 用不了。
MiniMax 官方观察:"OpenAI Chat Completion API 不支持传回推理内容。
Anthropic API 原生支持,但社区对 Claude 之外的模型支持较少,很多应用仍然没有正确传回 thinking。"
社区反馈显示,Reddit、Hacker News 上有大量帖子说 Agent 表现不稳定,根本原因是很多应用错误地实现了 Interleaved Thinking,要么不传回 thinking,要么只传部分。
API 设计的历史包袱阻碍了 Interleaved Thinking 的普及。
这不是技术问题,是生态问题。
即使模型支持,应用层也用不了。

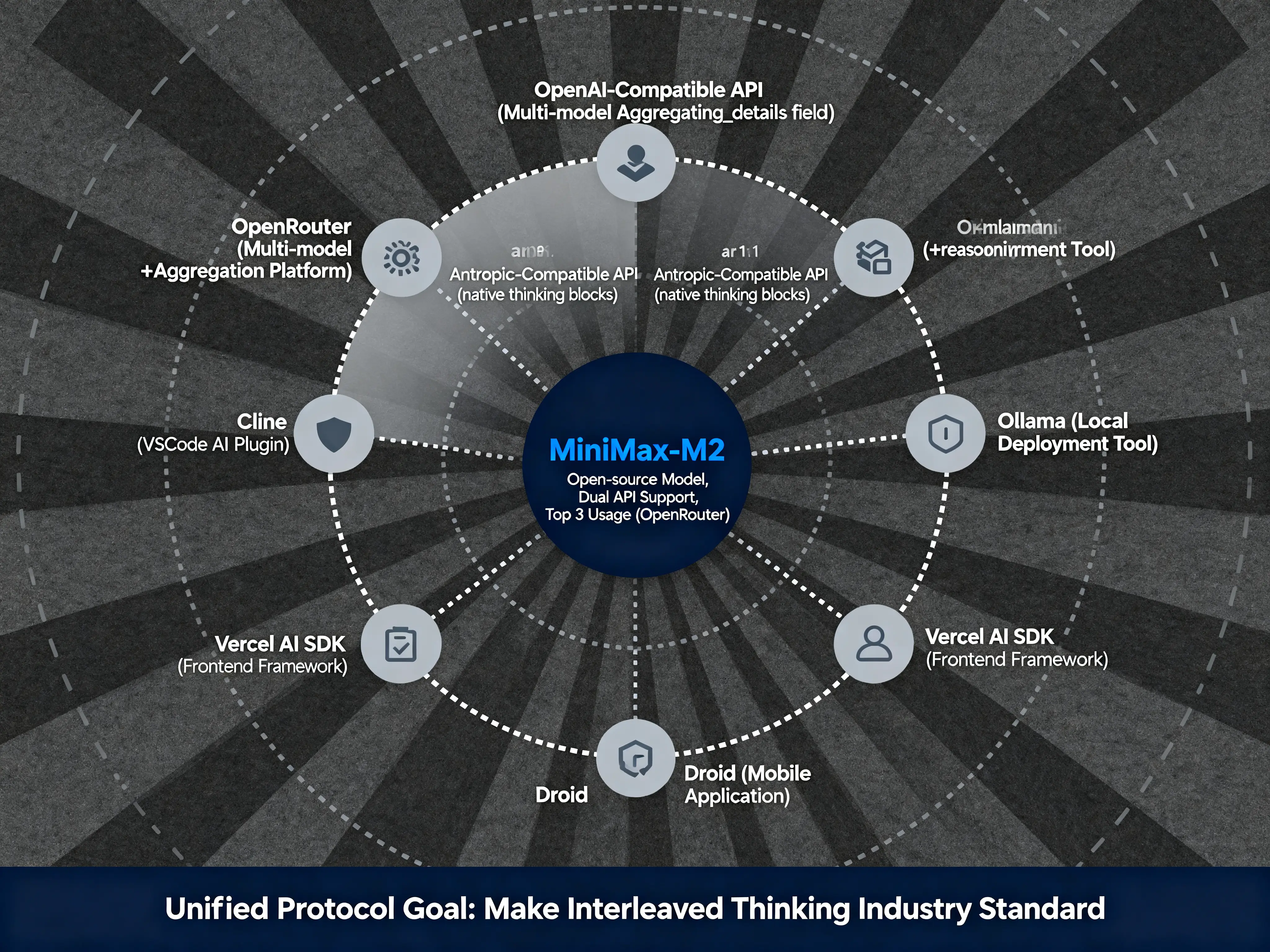
MiniMax-M2 的生态推动
MiniMax-M2 提供两套 API。
第一套是 OpenAI-Compatible API。
在 OpenAI API 的基础上新增 reasoning_details 字段。
返回结果包含 reasoning_details,下一轮对话传回去,模型就能继续推理。
好处是向后兼容,不破坏现有应用,OpenAI 生态的应用稍微改几行代码就能用。
第二套是 Anthropic-Compatible API。
直接兼容 Anthropic 的 API 格式,支持 thinking blocks。
已经用 Claude 的应用,直接换 endpoint 就行。
MiniMax 不只发布模型,还在推动生态标准化。
官方博客说:"我们在帮助 OpenRouter、Ollama、Droid、Vercel、Cline 等合作伙伴正确实现 Interleaved Thinking。我们的目标是建立统一的协议,让 Interleaved Thinking 成为标准。"
OpenRouter 是多模型聚合 API 平台,M2 发布一周后就成为平台上使用量前 3 的模型。
MiniMax-M2 为什么重要?
第一,打破垄断。之前只有 Claude 支持 Interleaved Thinking,闭源,成本高,依赖 Anthropic。M2 提供了开源选择。开发者可以自己部署,不依赖 Anthropic,可以查看模型权重,研究 Interleaved Thinking 的实现,成本更低,适合大规模应用。
第二,推动标准化。仅靠 Anthropic 一家,无法改变 OpenAI 主导的生态。需要更多厂商跟进,形成行业标准。MiniMax 的双 API 策略,就是在推动这个过程。
第三,降低成本。Claude Sonnet 4 是 $3/M input, $15/M output,MiniMax-M2 是 $0.30/M input, $1.20/M output,成本降到 1/10,让更多应用用得起。
第四,开源生态。权重可下载(230GB),可以在 256GB Mac Studio 上本地部署,MLX 社区已经移植好了。
Simon Willison(Datasette 作者)评价:"M2 是第一个支持 Interleaved Thinking 的模型,这是 agentic models 最重要的特性之一,充分利用了 test-time compute。"
MacStories 科技媒体表示:"我一直用 Claude 作为生产力 LLM,M2 的体验和 Anthropic 版本的 Sonnet 一样。"
开发者建议
如果你在开发 AI Agent,选模型要考虑:用 Claude,直接用 Anthropic API,启用 thinking mode,性能最好,但成本高。
用开源模型,MiniMax-M2 是目前最佳选择,支持双 API,兼容性好,成本低,可本地部署。
用 OpenAI,GPT-5 系列还不支持 Interleaved Thinking,可以等 Responses API 的进一步支持,或者考虑切换到支持的模型。
如果你要用 Interleaved Thinking,必须保留 thinking blocks 传回模型。
错误的做法是只传 text,丢失 thinking。正确的做法是把完整的 content(包含 thinking block 和 text block)传回去。
使用正确的 API endpoint。
Anthropic API 是 https://api.anthropic.com/v1/messages,MiniMax Anthropic-compatible 是 https://api.minimax.io/v1/messages。
不要用 OpenAI Chat Completion API,除非是 MiniMax 的 OpenAI-compatible endpoint。
参考官方示例。
Anthropic 官方文档和 MiniMax 官方指南都有详细说明,不要自己瞎改,容易出错。
未来 1-2 年,Interleaved Thinking 会成为 Agent 标配。更多模型会跟进(Gemini、Llama 等),性能优势太明显,不支持就落后。API 标准会逐步统一,OpenAI 可能会更新 API(或推广 Responses API),行业会形成共识,统一字段命名。
开源生态会快速跟进,MiniMax-M2 开了个好头,Hugging Face、Ollama 会提供更好的工具支持,本地部署会越来越容易。
机制比参数重要
AI Agent 的可靠性问题,不会靠"更大的模型"解决。
参数从 7B 到 70B 到 700B,会让模型更聪明。但更聪明不等于更可靠。
真正提升可靠性的,是更好的机制。
Interleaved Thinking 证明了这一点:同一个模型,只是改了调用方式,性能就提升 40%。
这告诉我们:有时候,改变一个设计,比堆参数更有效。
参考资料:
- CMU TheAgentCompany Benchmark: https://superface.ai/blog/agent-reality-gap
- Salesforce CRM AI Research: https://arxiv.org/abs/2411.02305
- MiniMax-M2 Official Blog: https://www.minimax.io/news/minimax-m2
- Anthropic Extended Thinking: https://docs.anthropic.com/en/docs/build-with-claude/extended-thinking
- Simon Willison Blog: https://simonwillison.net/2025/Oct/29/minimax-m2/