
核心数据:Gartner 预测,超过 40% 的 agentic AI 项目将在 2027 年底被取消。失败原因:成本上升、业务价值不明确、风险控制不足。
据 Gartner 2025 年 6 月发布的预测,超过 40% 的 agentic AI 项目将在 2027 年底被取消。
这不是个例,是系统性失败。
原因是成本上升、业务价值不明确、风险控制不足。
Gartner 在 2025 年 1 月调研了 3,412 名参与者,19% 已进行重大投资,42% 进行保守投资,但大部分企业对 AI agent 的实施挑战估计不足。
Teradata 和 NewtonX 的调研显示,74% 的企业高管对 agentic AI 改善客户体验持中度到高度信心,50% 预计至少带来 100 万美元的收入或成本节省。
但同一调研也指出,93% 的企业在创建 AI 治理框架方面遇到挑战,34% 担心数据准确性。
热情与失败预警之间的巨大反差。

失败的三大根源
成本失控
Token 消耗是 AI agent 成本失控的主要原因。
据 Epoch AI 研究,推理模型的平均输出长度以每年 5 倍的速度增长(非推理模型为 2.2 倍),推理模型的响应长度是非推理模型的 8 倍。
一个简单查询可能内部消耗 5,000 个推理 token,但只返回 100 个 token 的响应。
一位 AI 产品经理告诉我们:"我们测试 AI agent 时发现,token 消耗比预期高 3-4 倍。
原因是 agent 需要多轮推理和工具调用,每次都产生大量中间 token。
成本模型完全失控。
基础设施成本也在上升。
虽然 Sam Altman 在博客中指出,"给定 AI 能力的使用成本每 12 个月下降约 10 倍",但新一代推理模型的单位成本更高,总成本反而上升。
价值不明确
ROI(投资回报率)难以证明。
Teradata 调研显示,50% 的企业预计 AI agent 将带来至少 100 万美元的收入或成本节省。
但如何归因这些价值?一个销售 AI agent 帮助关闭了一笔订单,这是 agent 的功劳还是销售人员的功劳?很难拆分。
不同客户对"结果"的定义也不同。
对客服 agent,客户 A 关心解决率,客户 B 关心满意度,客户 C 关心响应时间。
这导致定价和价值衡量变得复杂。
MMC Ventures 对 30+ 欧洲 AI agent 创业公司的调研显示,"基于结果定价"被称为"圣杯"(Holy Grail),但实际采用率只有 3%。
原因是归因难、衡量难、预测难。
一位 AI 创业者说:"我们最初想做基于结果的定价,但发现根本做不了。客户的业务流程太复杂,AI agent 只是其中一环,无法准确归因。最后改成了混合定价——基础费加按任务收费。"
风险失控
治理框架不成熟是最大的风险。
Teradata 调研显示,93% 的企业在创建 AI 治理框架方面遇到挑战。
这不是技术问题,是组织问题。
谁负责 AI agent 的决策?
出错了谁承担责任?
如何审计 AI agent 的行为?
这些问题大部分企业没有答案。
数据准确性是另一个风险。
34% 的企业担心数据准确性。
即使 MMC 调研显示,90% 的 AI agent 达到 70% 以上的准确率,但在高风险场景(如金融合规、医疗诊断),70% 的准确率远远不够。
MIT 的研究指出,人机协作在决策任务上往往表现不如单独的人类或 AI。
原因是沟通障碍、信任问题、伦理顾虑、缺乏有效协调。
一位企业 AI 负责人告诉我们:"我们发现,员工要么过度依赖 AI(AI 给出错误答案也照做),要么完全不信任 AI(检查所有输出,降低效率)。两种极端都很糟糕。"

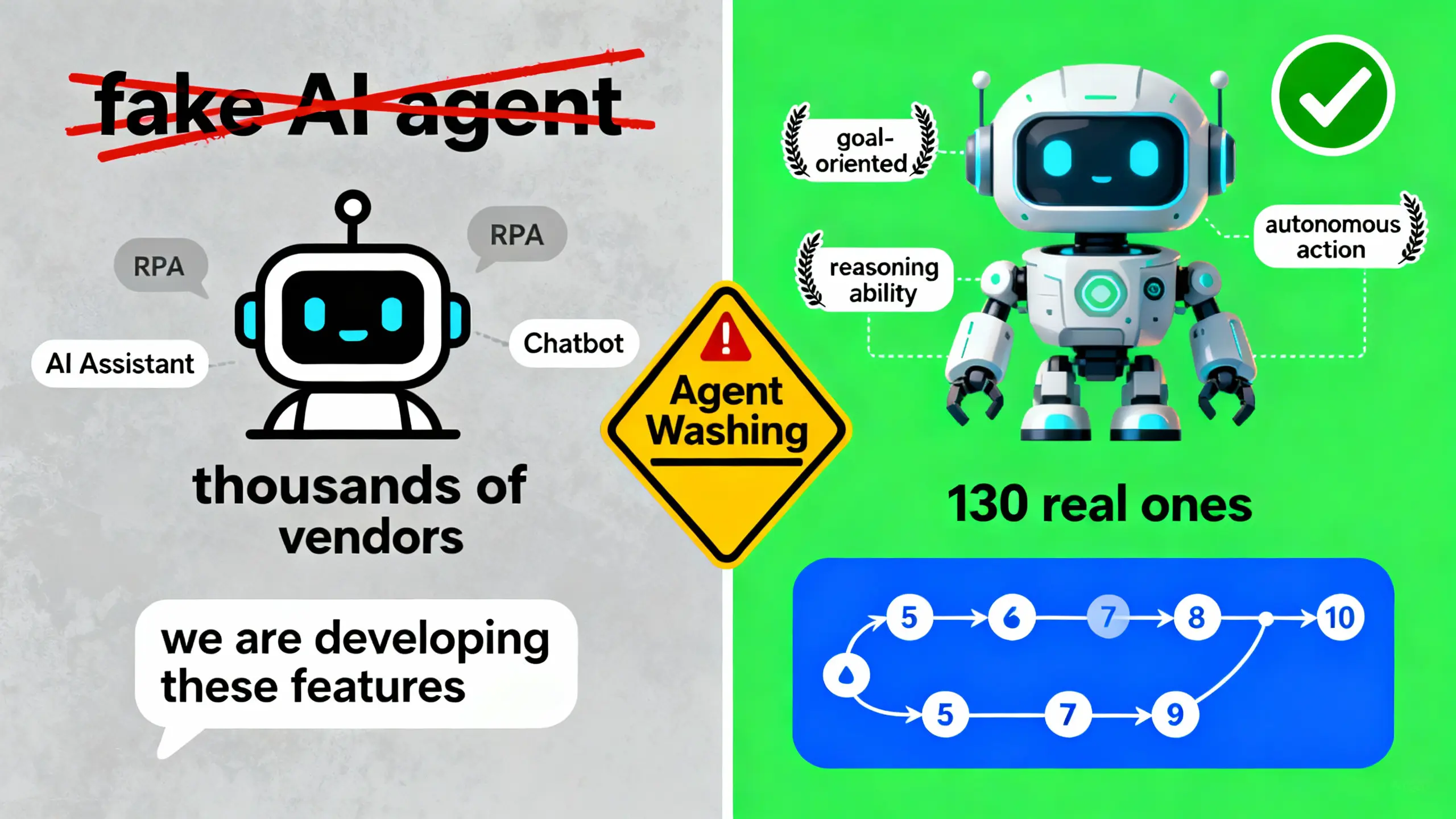
骗局警示:"Agent Washing"
Gartner 估计,数千家 agentic AI 供应商中,只有约 130 家是真正的。
"Agent Washing"现象泛滥。
大量供应商将现有产品(AI assistants、RPA、chatbots)重新包装成"agentic AI",但没有实质性的 agentic 能力。
真正的 agentic AI 需要具备三个核心能力:
- 目标导向:能理解和追求明确的目标
- 推理能力:能将复杂问题拆解成子任务,规划执行路径
- 自主行动:能通过工具调用(tool calling)执行任务,而不是只回答问题
一位技术架构师告诉我们:"我们评估了 20 多家 agentic AI 供应商,发现大部分只是聊天机器人加了几个 API 调用。真正能做多步推理、能根据环境动态调整计划的,不到 5 家。"
如何识别"Agent Washing"?
问供应商这 3 个问题:
- 你的 agent 能处理多少步的任务链? 真正的 agent 应该能处理 5-10 步以上的复杂任务。
- agent 如何处理失败和异常? 真正的 agent 应该有重试机制、错误恢复、备选方案。
- agent 的决策是否可追溯? 真正的 agent 应该能记录每一步的推理过程和工具调用。
如果供应商回答不出来,或者说"我们正在开发这些功能",基本可以判断是"Agent Washing"。
成功者的 3 个避坑策略
MMC Ventures 调研了 30+ 欧洲 AI agent 创业公司和 40+ 企业实践者,提炼出成功者的共同特征。
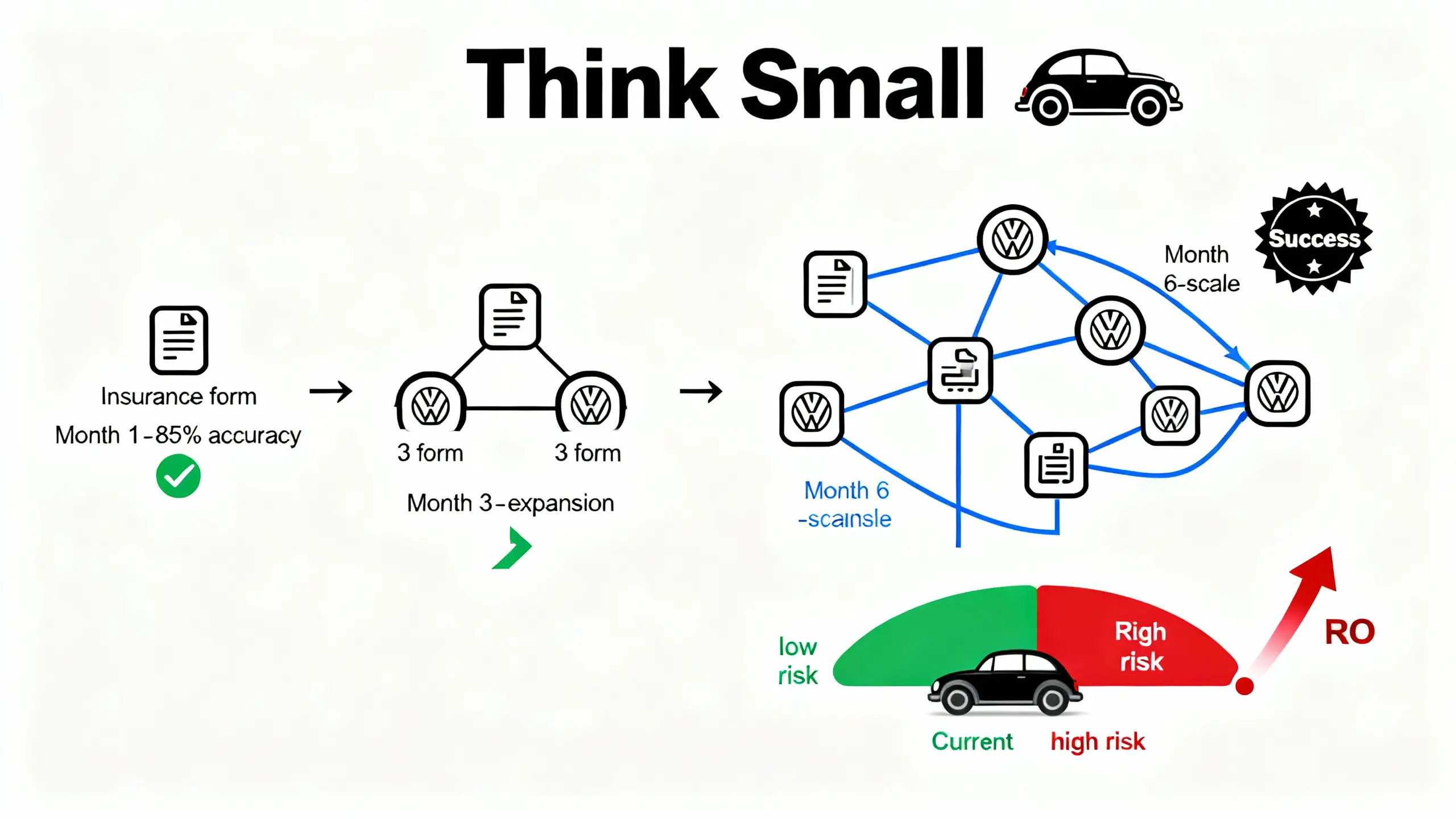
策略 1:Think Small
从低风险、易验证的任务开始。
MMC 调研显示,最成功的部署策略是:
- 简单且明确的用例,有清晰的价值驱动
- 对现有工作流的破坏性小
- 最好是自动化用户讨厌的任务(或已外包的任务)
- 输出易于人工验证
- 快速展示 ROI
Health Force 是一个典型案例。
这家公司的 AI agent 自动化医院的日常行政任务(如填写表格、预约安排)。这些任务医院原本就外包给第三方,风险低、流程清晰、输出易验证。
Health Force 免费提供"AI Readiness Assessment",帮医院识别哪些工作流最适合 AI agent。
一位医院 IT 主管告诉我们:"我们从最简单的任务开始——自动填写保险表格。这个任务流程固定、风险低、省时间。跑了 3 个月,准确率达到 85%,节省了 2 个全职员工的时间。然后我们才敢扩展到更复杂的任务。"
Volkswagen 的经典广告词适用于 AI agent:"Think Small"。
不要一开始就想自动化整个业务流程,从一个小任务开始。
策略 2:Co-pilot 定位
即使技术能做到 80% 自主性,也只说 50%。
MMC 调研发现一个"定位悖论":90% 的 AI agent 达到 70% 以上的准确率,但只有 66% 达到 70% 以上的自主性。
技术上能做到更高自主性,但企业不敢用。
原因是信任问题。
MMC 调研显示,高自主性的 agent 引发更强的员工抵触。
医疗、合规等高风险领域,即使 AI 准确率达到 90%,企业也只给 40% 的自主性。
成功的创业公司采用 Co-pilot 定位,而非 Full Autonomy。
Juna AI 的 agent 优化制造业的复杂生产流程。
技术上,agent 可以直接调整生产参数。
但 Juna 选择 Co-pilot 模式:agent 给出优化建议,客户决定是否执行。
一位 Juna 客户告诉我们:"一开始我们也怀疑。但 agent 连续 3 个月给出的建议都很准,我们才开始信任它。现在我们采纳率超过 80%。"
定位为 Co-pilot,而非 Replacement,还有一个好处:降低员工抵触。MMC 调研显示,50% 的 AI agent 创业公司遇到员工抵触问题。
将 agent 定位为"增强你的能力",而非"取代你",阻力会小很多。
策略 3:前置投资——工作坊和咨询式 GTM
成功的企业部署需要大量手把手指导。
原因是企业不清楚:
哪些用例适合 AI agent?
如何评估和采购 AI agent 产品?
如何重新设计工作流?
如何培训员工?
成功的 AI agent 创业公司采用"工作坊 + 咨询式 GTM"。
Runwhen 的 AI agent 用于开发者体验(DevEx)。在客户签约前,Runwhen 免费做"预装分析"——分析客户现有的告警和聊天记录,计算有多少可以被 agent 自动化。
这给客户明确的预期:大概能省多少时间、成本多少、回报多少。
一位 DevOps 负责人表示:"Runwhen 的预装分析打消了我们的顾虑。他们告诉我们,我们的 500 个告警中,大概 200 个可以被 agent 自动化,预计节省 30% 的 on-call 时间。这个数字很具体,我们很容易做决策。"
咨询式 GTM 的另一个好处是帮助客户预测消费。
混合定价模式(基础费 + 按任务/按用量)需要客户预测使用量。
工作坊可以基于历史数据给出预测,避免账单冲击(Bill Shock)。
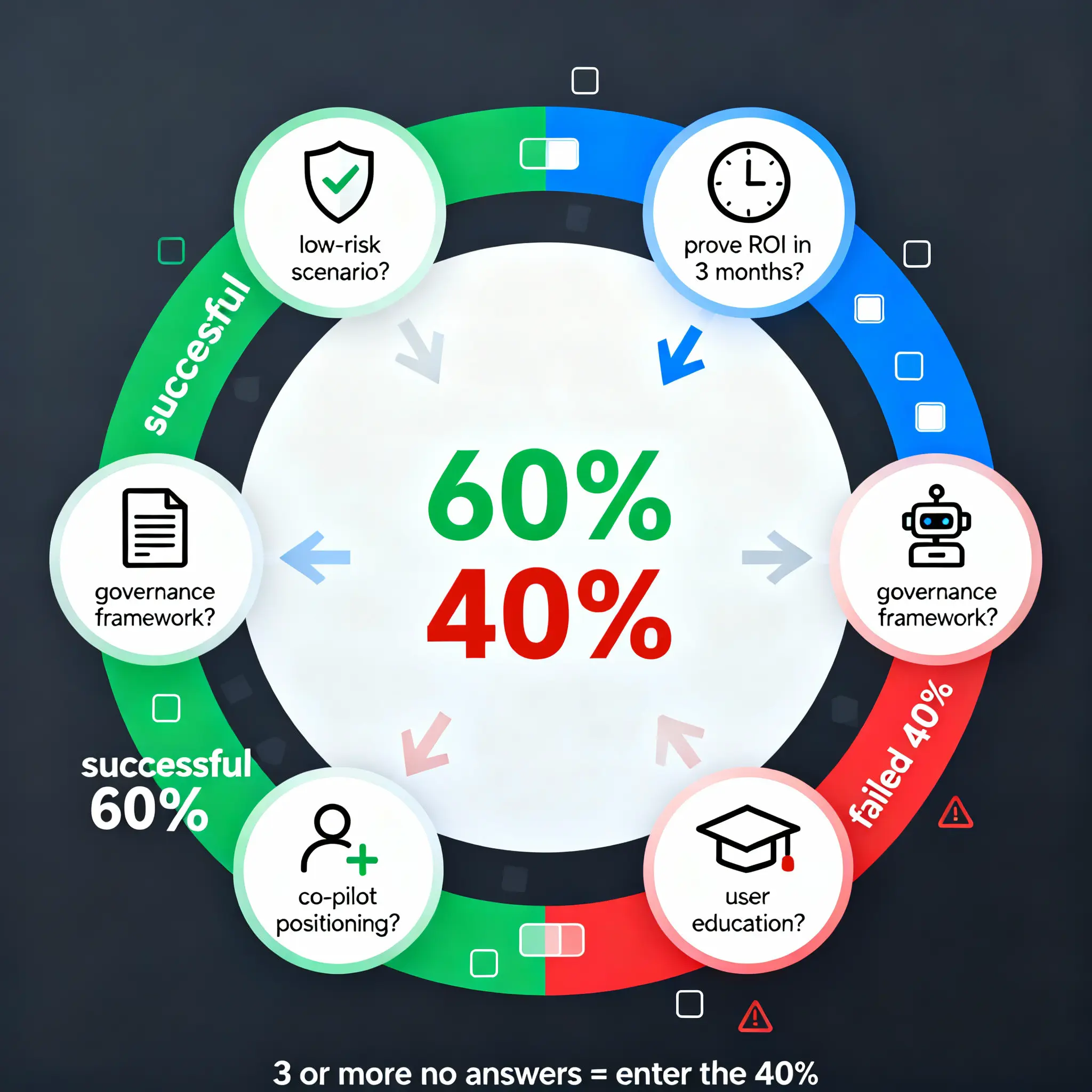
自检清单:你的项目会成功吗?
回答这 5 个问题:
1. 你是否选择了低风险、易验证的场景?
低风险 = 失败的成本低。易验证 = 人类能快速判断 agent 的输出是否正确。
如果你选择的场景是高风险(如自动审批贷款)或难验证(如生成战略报告),失败概率很高。
2. 你是否能在 3 个月内证明 ROI?
Gartner 的预警是 2027 年底,也就是说,失败的项目大多在 1-2 年内被取消。
如果你的项目需要 1 年以上才能看到价值,很可能撑不到那天。
3. 你是否有清晰的治理框架?
93% 的企业在治理框架上遇到挑战。
你需要回答:谁负责 AI agent 的决策?出错了谁承担责任?如何审计 agent 的行为?如果没有答案,项目很难规模化。
4. 你是否采用 Co-pilot 而非 Full Autonomy?
Full Autonomy 听起来很酷,但会引发更强的员工抵触和更高的风险。
Co-pilot 定位更容易获得信任和采纳。
5. 你是否有用户教育和期望管理计划?
MMC 调研显示,60% 的 AI agent 创业公司遇到工作流集成和人机界面问题。
你需要教育用户:agent 能做什么、不能做什么、如何最好地使用。如果用户不会用或期望过高,项目必然失败。
如果 5 个问题中有 3 个以上回答"否",你的项目很可能成为那 40%。
40% 不是宿命
Gartner 的预测不是危言耸听,是基于历史数据的推演。
但 40% 的失败不是宿命。
失败的项目都在重复犯错:选择过于复杂的场景、追求完全自主、忽视员工抵触、没有治理框架、无法证明 ROI。
成功的 60% 都在做正确的事:Think Small、Co-pilot 定位、前置投资。
一位技术架构师总结:"AI agent 的成功不取决于技术有多先进,而取决于你有多了解人性和组织。技术只是入场券,真正的壁垒是产品设计、组织变革管理、信任建立。"
你会是哪 60%?
参考资料
- Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027
- MMC Ventures - State of Agentic AI: Founder's Edition (2025-11-03)
- MIT Sloan - Humans and AI: Do they work better together or alone? (Nature Human Behaviour, 2024)
- Teradata & NewtonX - AI Agents for Customer Experience Survey (2025)
- Deloitte - Agentic AI Enterprise Adoption Guide (2024)
- Rubrik - It's Early Days For Agent AI (2025)
- IDC - 中国 AI Agent 市场剖析,3Q25
- Epoch AI - Average Output Length Analysis
- Sam Altman - Three Observations