

# 梁瑞宇:数字助听器关键算法研究现状与展望#

-
听力障碍与康复辅具
-
听力损失与助听器
-
助听器关键算法
-
OTC助听器简介及相关研究

听力障碍与康复辅具
听力障碍被WHO定义为“无声的流行病”。WHO2021听力报告指出,目前全球的听障人口有15亿。 我国65岁以上的听障人口有5000万,只有5%的患者使用了助听器,这一数字远低于西方发达国家的助听器使用率。 目前全球助听器的市场份额几乎由五大助听器集团垄断,总占比为95%。
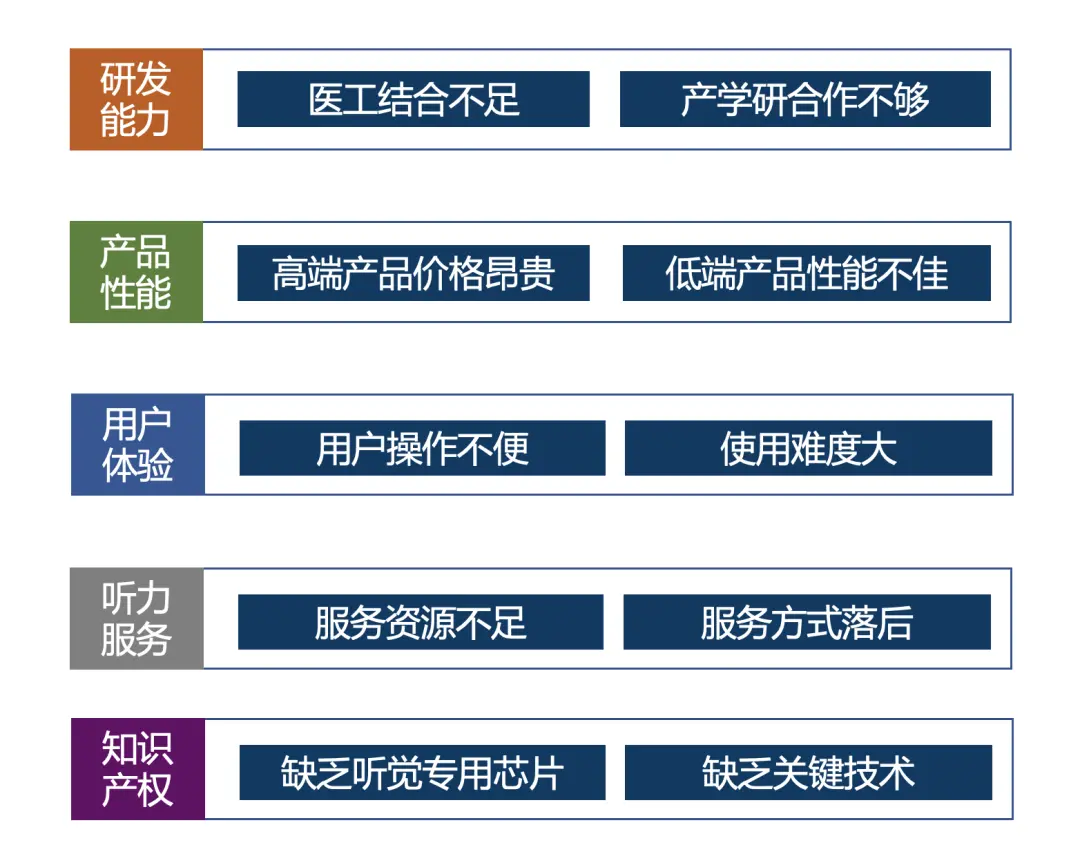
造成这一现象的主要原因包含以下几点:
听力损失与助听器
2008年,由WHO、哈佛大学、霍普金斯大学、华盛顿大学和昆士兰大学共同牵头,成立新一轮全球疾病负担(Global burden of diseases,GBD)评估工作委员会,该组织发布了听力障碍的分级标准。按听力阈值(听力较好耳在500Hz、1kHz、2kHz、4kHz的平均听阈)分为正常听力、轻度听损、中度听损、中重度听损、重度听损、极重度听损和全聋7类。WHO2021听力报告采用这个标准。
要想从算法角度来提升助听器性能,我们需要从信息的角度来理解听力损失,主要包含几个方面:
-
频率分量缺失: 在言语识别过程中,听力障碍者可能听不到某些频率的声音,因此在理解言语上存在困难。如果不能针对患者缺失的频率分量进行放大,听障患者往往觉得很吵闹,但是依然听不清语音。
-
动态范围减小: 听力动态范围是指人耳能够听到的最小声和不能忍受的最大声之间的差,即不适阈与接受阈的差值。尤其对感音神经性听损患者来说,其接受阈的变化远比不适阈的变化明显,从而导致此类患者的动态范围小于正常人。
-
频率解析度降低: 正常人耳蜗的不同位置解析不同频率的声音,使得听觉中枢可以精确区分声音的频率。由于听损患者的外耳毛细胞丧失了部分功能,导致耳蜗对声音的频率解析度降低,听障患者往往不能区分频率较为接近的语音分量与噪声,从而使大脑无法获得足够的信息区分语音与噪声。
-
时间解析度降低: 正常人耳可以利用在噪声低时听到的语音片段理解语言。而听损患者对声音的时间解析能力下降,导致噪声对语音的掩蔽效应持续时间更长,患者无法得到噪声间隙中的语音信号,从而降低患者的语言理解度。对这种情况,助听器应能快速跟踪语音信号,当语音分量弱时及时进行放大,从而减小噪声掩蔽语音的情况。
虽然助听器始于20世纪40年代,但是一直是一个比较小众的研究领域。近年来,耳机、智能终端企业正逐步杀入这片技术的蓝海。2017年,FDA正式批准OTC助听器在柜台进行销售,可借助APP实现自主测听与调试。此外,人工智能技术大大提升语音降噪效果,从而打破噪声环境下的听障患者言语识别率低的瓶颈。
助听器关键算法
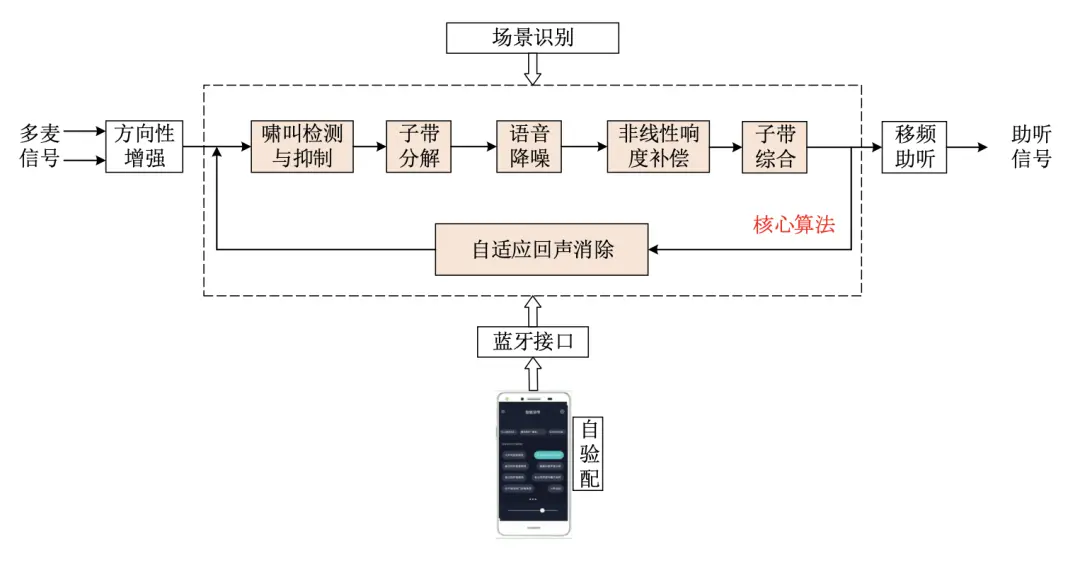
一个完整的数字助听器涉及的核心算法通常包括啸叫检测与抑制、非线性响度补偿、语音降噪和自适应回声消除。
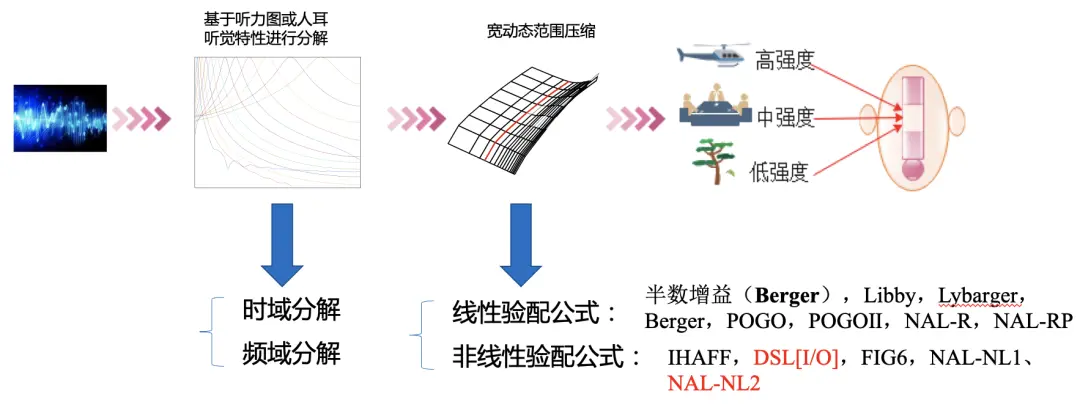
- 非线性响度补偿算法:由于听损患者对声音的敏感程度随频率变化而不同(用听力图表征),故数字助听器应针对不同频率的听力损失和输入信号的强度计算不同的信号增益。涉及的核心技术包括滤波器分解和助听器处方公式等。
-
语音降噪算法:降噪在语音研究领域是一个永恒的话题,提升患者在噪声环境下的言语理解度是影响患者助听器满意度的关键指标。时域降噪方法包括增益衰减和噪声估计;频域方法常见的有维纳滤波法和谱减法;新兴的基于人工智能的降噪技术如RNN,LSTM取得了不错的降噪效果。
-
啸叫检测与抑制算法:数字助听器在使用时,其受话器输出的语音可能通过耳道、助听器外壳和外界环境返回被麦克风接收,从而形成闭环回路。当整个系统的闭环增益上升并形成正反馈时,回声产生。回声是助听器使用中的一个普遍问题,轻则影响语音质量,严重时产生啸叫,损害患者的残余听力和硬件设备。常见的啸叫检测方法多基于信号特征进行判断,比如基于峰值-均值功率比,峰值-谐波功率比,峰值-邻值功率比等,而采用抑制方法包括增益衰减与陷波器等。
-
自适应回声消除算法:啸叫检测和抑制更多的是一种补救策略,而更有效的方法应该是在啸叫出现前进行抑制,而自适应回声消除基于此策略而设计的。回声消除算法能自适应地估计出回声路径,进而估计出回声信号,达到消除回声、提高助听器最大增益的目的。经典算法包括LMS,NLMS等,但是对于助听器来说,由于期望信号和输入信号的相关性,使得传统自适应算法无法产生较好效果。通常的处理策略是进行信号去相关,包括延时,移频,引入全通滤波器等。
除了上述助听器基本算法外,现代化的数字助听器还会包含一些辅助算法。一些代表性的算法如下:
-
场景识别算法:场景识别算法通过对音频环境进行检测并识别,从而使助听器能根据不同场景进行参数切换。早期分类包含安静、语音、噪声、语音+噪声、音乐四类,而一些助听器厂家在此基础上会进行延伸。主要有基于特征(振幅调制、频谱包络、音高、振幅起点等…)和基于机器学习的两类方法。
-
方向性增强算法:数字助听器的方向性语音增强主要利用麦克风阵的空间信息和声源位置减小特定方向的噪声和干扰声,从而提高助听器使用者的言语理解度。但是受助听器体积限制,通常一阶定向麦克风或自适应麦克风的3-5dB的信干比并不能满足要求,这推动了二阶定向麦克风和麦克风阵列的发展。
-
移频助听算法:大部分的听损患者高频听力损失都比较严重,这就意味患者可以很好的感知低频声音,而对高频听的很少甚至根本听不到。而高频增益会受声反馈,功率和耳蜗死区限制,不能过大,因此移频技术被设计来解决该问题。常用的移频方法主要包含慢放、声码器、频移和频率压缩四类,目前常用的移频方法主要是后两类。
-
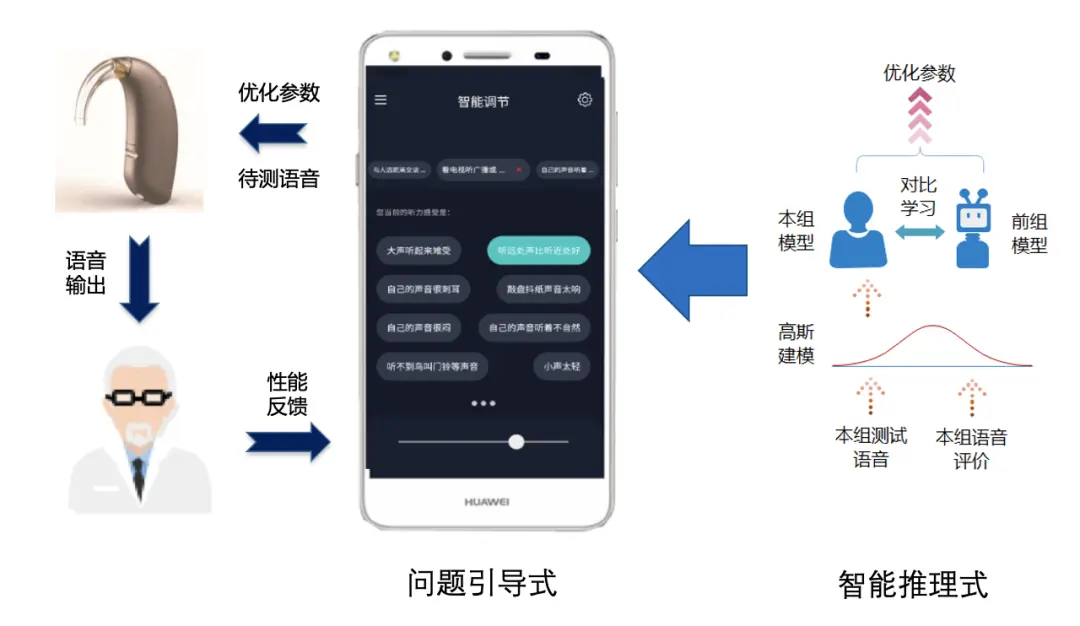
自验配算法:传统助听器依靠听力专家的验配经验和专业技能来调配算法参数以尽可能达到最佳的工作状态。这种完全依靠专家水平的验配方法低效且难以有效传承,具有一定局限性。改善这一情况的策略之一是研究一种可以辅助听力专家进行助听器调配的方法,比如助听器根据患者情况,自动评估或患者反馈语音质量,从而自动更新算法参数。目前自验配策略有问题引导式和智能推理式两种。
OTC助听器简介及相关研究
简介
重要事件:
-
2017年,美国通过非处方助听器法,标志着OTC助听器时代的开始;
-
2021年10月,美国FDA发布提案,将建立一个新的OTC助听器类别。
主要特点:
-
OTC助听器适用于18周岁以上,听力损失轻到中度的成年人,不能用于儿童或听力损失严重的成人。带动各种类型患者自我参与服务和听力项目的可能性,包括网络听力自我检测、互联网助听器自我验配和调试、互动助听器的推广、助听器效果的自我评估等;
-
相比于传统助听器,OTC助听器主要面向轻度-中度听损用户,增益较小,主要由用户自己验配,无需专家验配,可通过大众消费渠道购买,不属于国家药品监督管理局监管。
OTC助听器相关指标
2021年FDA关于OTC助听器的提案中提到的指标包括:
-
最大输出声压限制。OSPL90下的输出声压小于115dB(SPL)
-
输出失真控制限制。在最大音量时,总谐波失真加噪声不得超过输出值的 5%。
-
自身产生的噪声级限制。自身噪声不得超过32 dB SPL。
-
延迟。小于15毫秒。
-
频率响应带宽。250 Hz或以下到5 kHz或更高。
-
频率响应平滑度。1/3倍频程的频率响应的任何一个峰值不得超过设定值。
理论研究
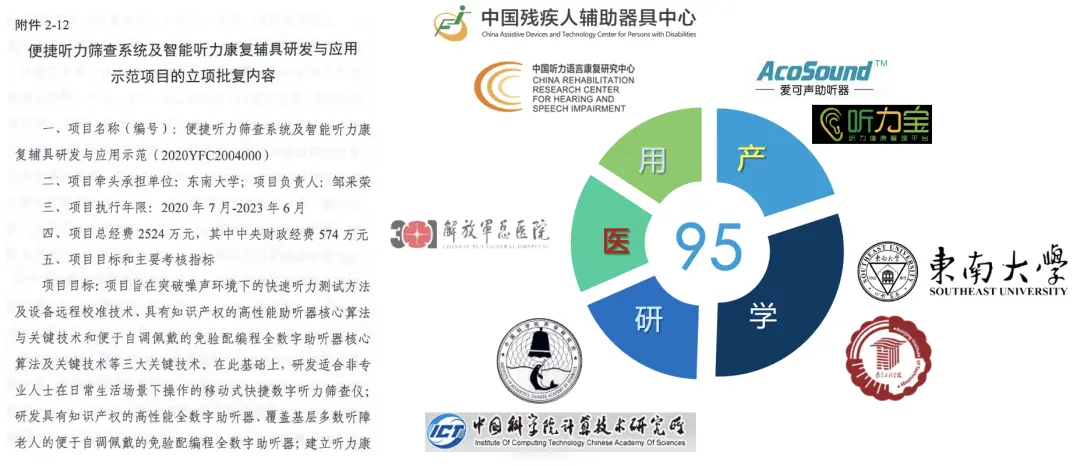
课题组参与东南大学牵头的国家重点计划,与国内知名机构合作面向助听器相关技术进行理论和算法研究。主要研究内容包括:构建测听和验配大数据、研究高性能助听器算法、探索OTC助听器算法方案和积累临床病例。目前研究团队已获批团体标准两项:《T/CARD 022—2021成人纯音听力筛查方法》和《T/CARD 017—2021个人听力信息数据格式》,发表高水平论文10篇,授权发明专利4项。
在 OTC 助听器算法研究方面,团队主要关注三个方向:
-
面向OTC助听器的听障患者分类,力争为大部分听障患者快速找到验配方案;
-
研究一种面向助听器的语音质量评估方法,取代传统助听器验配过程的频繁交互;
-
设计基于大数据的增益补偿方法,研发适合汉语的处方公式。
芯片研发
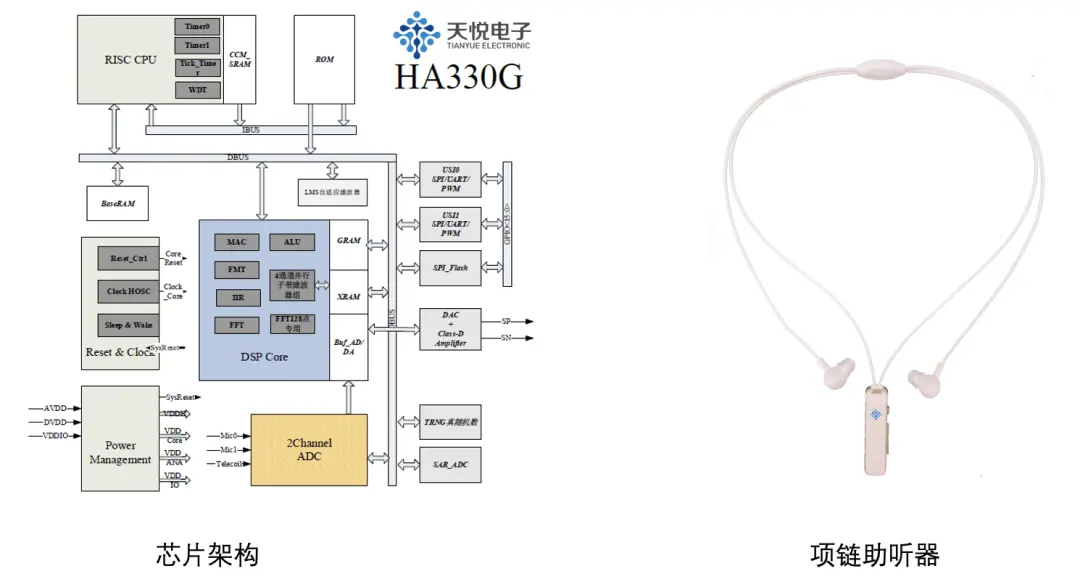
课题组与南京天悦电子科技有限公司、东南大学一起合作研发多款国产低功耗助听器芯片。南京天悦电子科技有限公司于2018年11月成立,是一家致力于高性能、低功耗微处理器研发、音频采集与专用集成电路研发的高科技公司。团队拥有强大的软硬件实力,为国内医疗级助听器、OTC非验配助听/辅听器、TWS/蓝牙耳机及方案商提供核心芯片及完整的解决方案。
2019 年,设计的数字助听器芯片通过江苏省电子学会科技成果鉴定,技术和产品达到国内领先水平。
2021年,由南京天悦团队自主研发的一款高性能低功耗数字助听器芯片HA601SC正式投入量产。HA601SC在MCU+DSP的架构下,采用全面的低功耗设计技术。芯片载有一颗32位的RISC-CPU,具有指令丰富易用、执行效率高的特点。双MAC结构的DSP核内置多通道DMA控制器和多运算加速器,实现快速、高效的运算响应。芯片还集成了2路16bitADC,1路内置的Class-D功率放大DAC及多重外设接口,具有较灵活的可扩展性。配合丰富完善的固件库和可编程特性,厂商可设计出符合需求、效能兼顾、应用广泛的数字助听/辅听产品。
南京天悦诚挚欢迎国内外相关企业和研究单位共同帮助更多听障患者乐享健康生活,为助听器市场构建健康发展生态。

现场互动Q&A
Q:
助听器硬件怎么评估好坏呢?有什么重要指标吗?
针对助听器的电声特性,有专门的国家标准GB/T 25102.100-2010《电声学助听器 第0部分:电声特性的测量》,里面有比较详细的说明和测量方法。
Q:
目前市面上有完全国产芯片的助听器产品吗?
有的。比如南京天悦电子科技有限公司除了研发芯片,也做整机助听器。
Q:
梁老师刚才提到的公式,各大厂家都在研发适合中国人的处方公式,梁教授比较推荐哪些处方公式呢?
目前最常用的处方公式就是NAL-NL和DSL。但是不同厂家都会根据产品进行调整。
Q:
助听器是不是通道数越多越好?一般业内是多少通道?
个人觉得不是越多越好。现在业内普遍都支持16通道。
Q:
OTC助听器算法,免验配全数字助听器的进展如何?难点在哪里?
我们团队的针对免验配助听器的研究主要分为建立助听器验配数据库,基于听损分类,言语质量评估等方面。目前研发的难点,验配数据的分析和有效性评估。


扫码查看回放
健康听力技术论坛
往期回顾

随着TWS耳机的飞速发展、辅听产品技术的日新月异,以及美国FDA发布OTC助听器草案的政策驱动下,未来五年,助听产品和辅听产品的跨界与整合将成为主流趋势。
在行业变革时代背景下,北京听力协会主办了「健康听力技术论坛」,长期为大家提供发声的平台。论坛持续以每期两位嘉宾、不固定更新上线的形式长期举办。
期待声学领域、TWS领域、辅听及助听领域的专家、学者,以及产业供应链上中下游多方代表积极参与论坛并发表演讲。我们希望通过论坛的举办,搭建行业平台,促进产品变革,推动技术发展,为轻中度听损人士及健听人士提供更合适的听力保护及听力辅助方案,实现「全民健康听力」这一终极目标。

作者:梁瑞宇
编辑:Elan
排版:Elan



