
因為最近在製作Anki筆記,需要由PDF擷取出文字,彙總使用的方法。
以下使用 國家教育研究院-全國中小學題庫網的國中七年級國文考卷為操作範例。
1. Google文件、LibreOffice
將PDF檔存入Google需端硬碟,再使用Google文件開啟。
內容較複雜或內容太多時,經常會轉換成圖片。
LibreOffice Writer也能開啟簡單的PDF,但會轉換成LibreOffice Draw。
2. Windows剪取工具
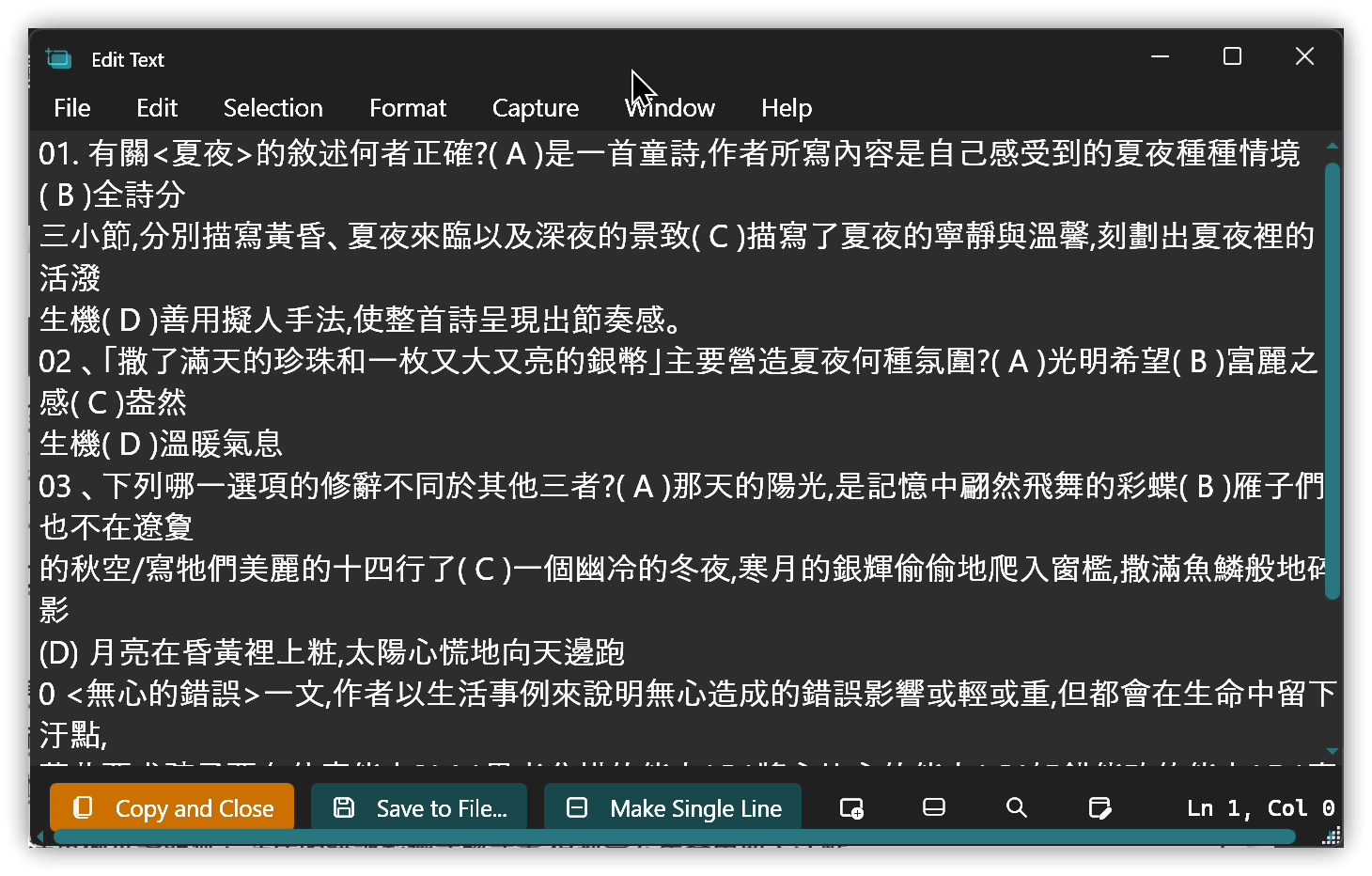
如果使用的Windows 11版本是23H2,那麼內建的剪取工具(SnippingTool.exe)會有「文字動作」按鈕,能執行文字辨識的功能,辨識率還不錯。按<span class='keybs'>Win+Shift+S</span >開始擷取。
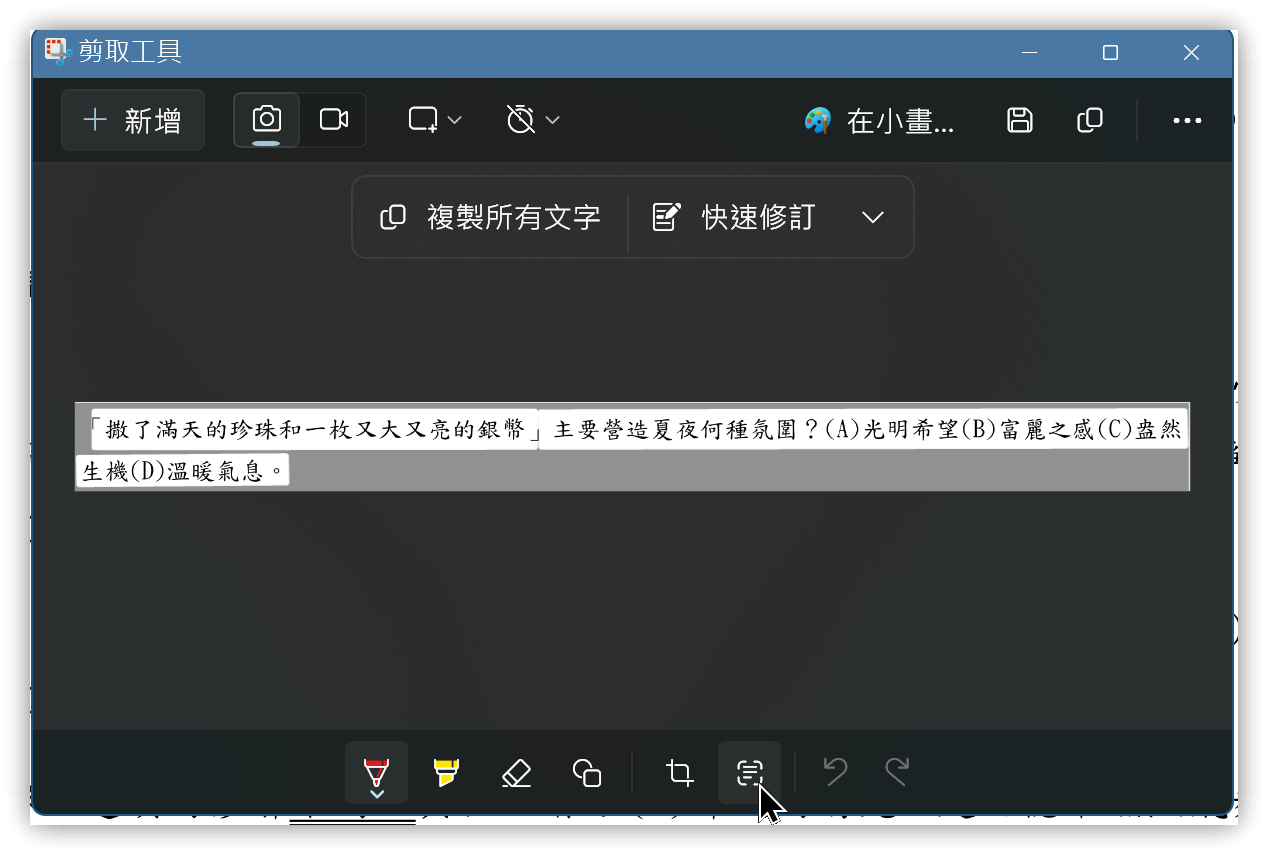
▼ 複製的文字,順序有誤,但皆有辨識出正確的文字
撒了滿天的珍珠和一枚又大又亮的銀幣」
生機(D)溫暖氣息。
主要營造夏夜何種氛圍?(A)光明希望(B)富麗之感(C)盎然
3. CapCap
測試到一款來自日本的擷取工具,剛好符合簡單、易用的目標。
- 使用前必須確認Windows有安裝好對應的語言,例如日文、英文
- 不同的語法必須設定不同的環境,例如來源語言是英文,目的語言是中文
▼ 來源與目的語言皆是繁體中文。

▼ Copy original後的內容,會多出空白
「 撒 了 滿 天 的 珍 珠 和 一 枚 又 大 又 亮 的 銀 幣 」 主 要 營 造 夏 夜 何 種 氛 圍 ? ( A ) 光 明 希 望 ( B ) 富 麗 之 感 ( C ) 盎 然 生 機 ( D ) 溫 暖 乿 息
- 每次擷取皆會產生一份「貼紙」,可拖拉到螢幕任意位置,按右鍵可複製、翻譯或隱藏,最後以【Close】結束
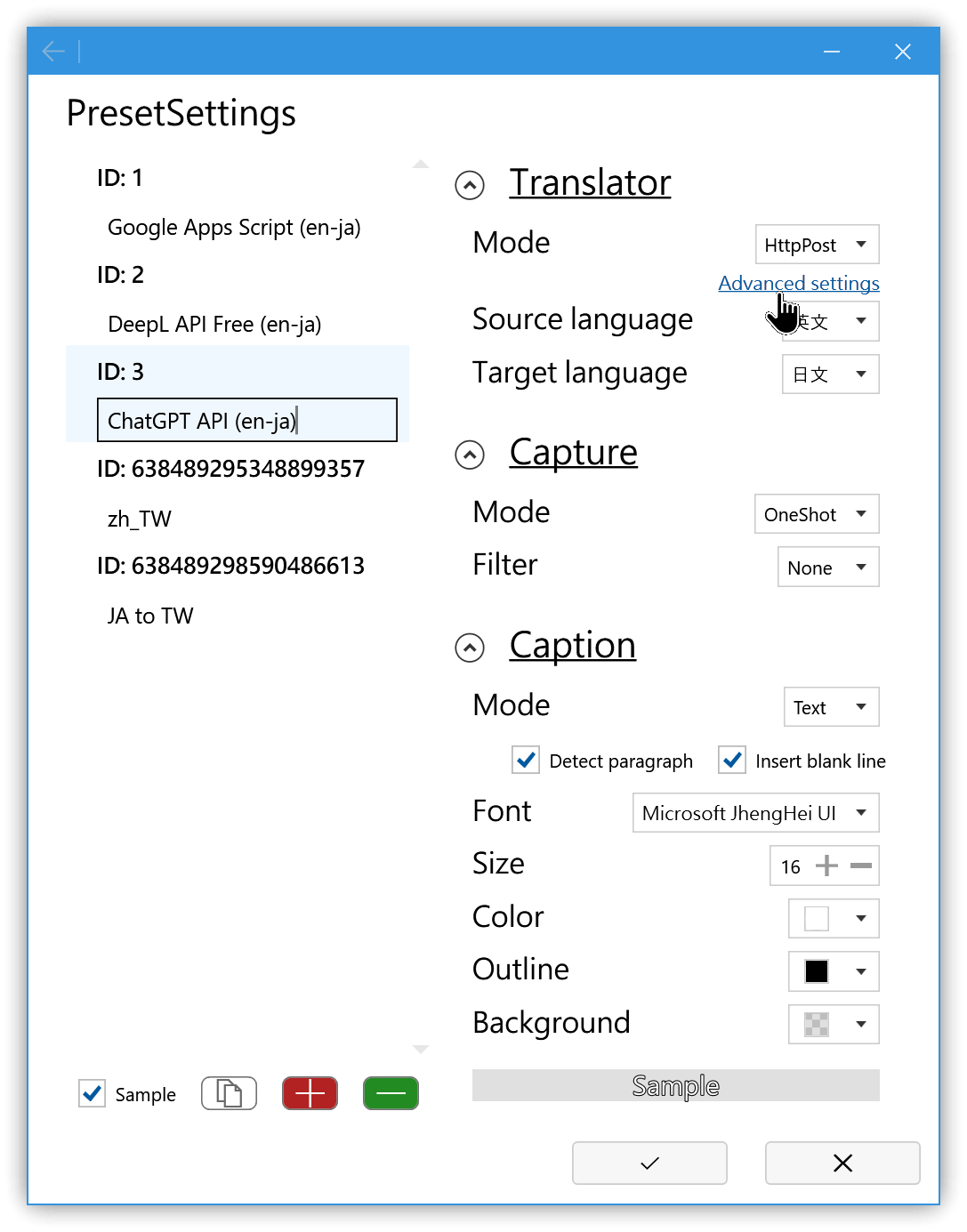
3.1. 預設設定
勾選右下角的Sample時,會出現ID 1、2、3的三個預設設定,分別是Google Apps Script、DeepL API Free與ChatGPT API,點擊右方的Advanced settings後可輸入連線的網址等資料,屆時提供即時翻譯的功能。
預設設定共供參考,要使用的話必須點擊Sample右方的複製圖示,在產生出的個人設定裡修改。
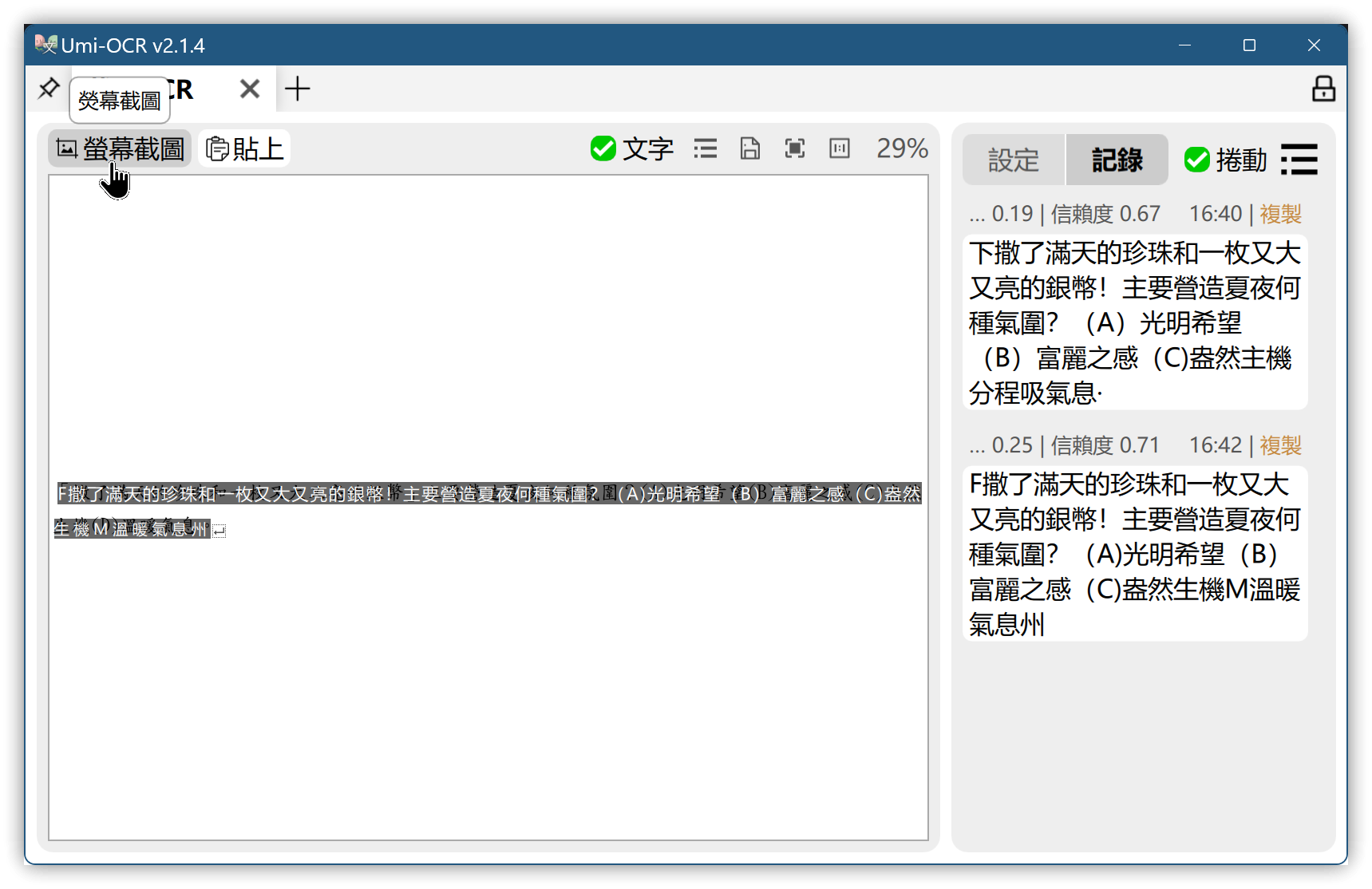
4. Umi-OCR
- Windows、Linux適用
- 有中文介面
5. Text-Grab
- 作者是PowerToys的Power Text Extractor工具作者
- Windows適用
- 預設<span class='keybs'> Win+Shift+F</span>全螢幕選取範圍後擷取,<span class='keybs'> Win+Shift+G</span>出現可拖動、變更大小的範圍視窗,按Grab擷取範圍內的文字
▼ 範圍視窗擷取
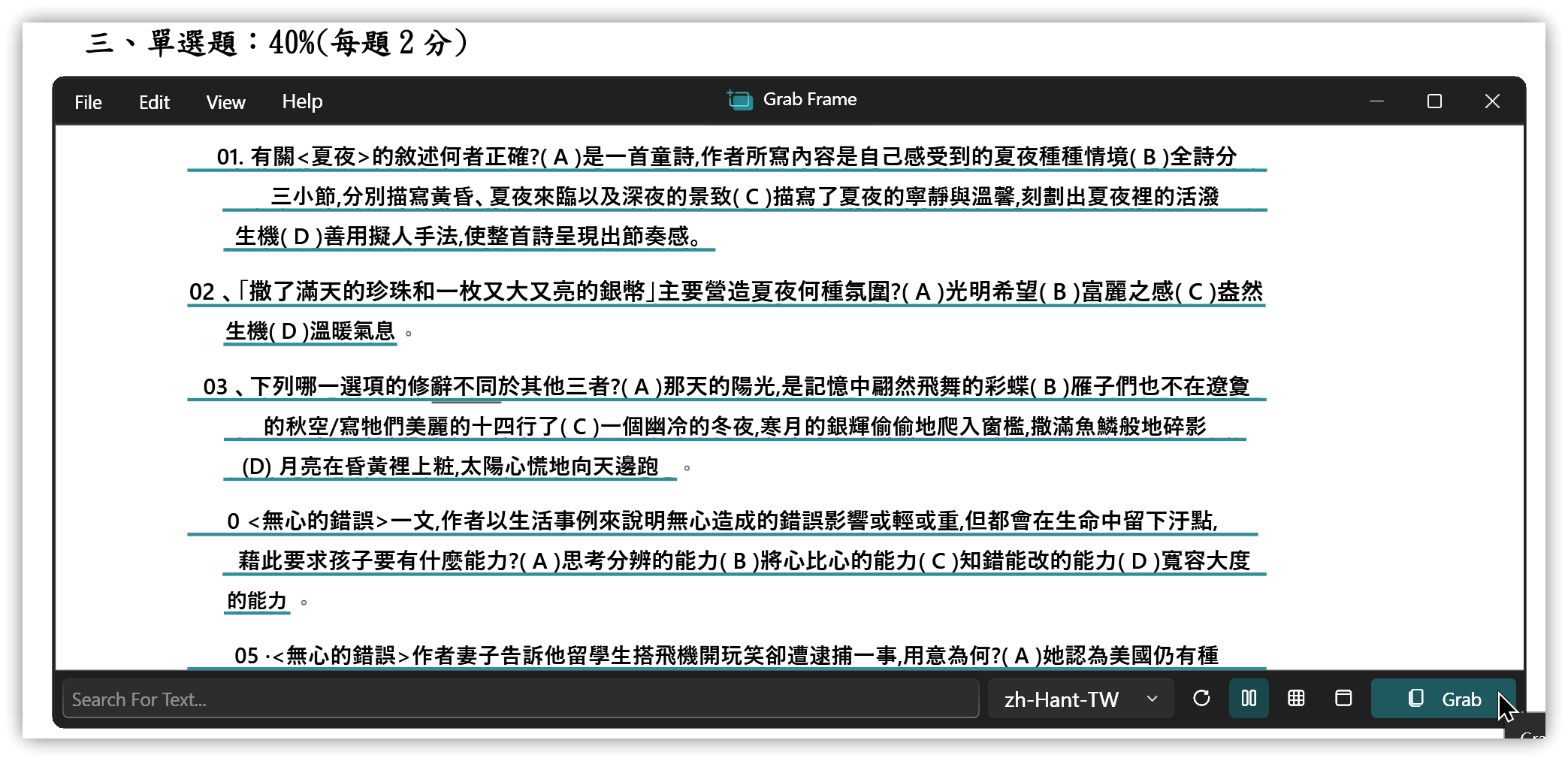
▼ 雙擊Grab的內容視窗可彈出編輯視窗
6. 💡 相關鏈接
💡 解說文章: https://jdev.tw/blog/8530/
✅CapCap (海外遊戲字幕顯示更方便): https://mecha-uma.blogspot.com/p/capcap.html
✅ Umi-OCR: https://github.com/hiroi-sora/Umi-OCR
✅ Text-Grab: https://github.com/TheJoeFin/Text-Grab
7. 教學影片
##