go 版本:1.25.3
一、channel 底层数据结构
channel 底层是一个 大小不可变的循环数组
type hchan struct {
qcount uint // channel中元素的数量
dataqsiz uint // channel底层循环数组的大小
buf unsafe.Pointer // 指向底层循环数组的指针,只针对有缓冲的channel
elemsize uint16 // channel中每个元素的大小
closed uint32 // channel是否被关闭
// 与定时器关联的channel
// time.Afet(), time.NewTimer(), time.Tick() 等函数创建的channel,在特定时间到达后自动向channel发送数据
// 定时器channel会指向关联的timer对象
// 普通的channel这个字段为nil
timer *timer // timer feeding this chan
// channel的元素的元数据,用于类型检查和内存分配
elemtype *_type // element type
sendx uint // 下一个要写入的缓冲区位置(循环队列的写指针)
recvx uint // 下一个要读取的缓冲区位置(循环队列的读指针)
// 接收者等待队列,存放了所有 等待从channel中读取数据的goroutine
// 当channel为nil,或者缓冲区没有数据时, 从channel中读取数据的goroutine会被放到这个队列中阻塞
recvq waitq
// 发送者等待队列,存放了所有 等待向channel中发送数据的goroutine
// 当channel已经满了, 往channel写数据的goroutine会被放到这个队列中阻塞
sendq waitq
// 用于测试并发代码
bubble *synctestBubble
// lock protects all fields in hchan, as well as several
// fields in sudogs blocked on this channel.
// Do not change another G's status while holding this lock
// (in particular, do not ready a G), as this can deadlock
// with stack shrinking.
// 保护所有hchan的字段 以及 被阻塞在这个channel上的sudog的部分字段
lock mutex
}
// waitq本质是一个双向链表
// sudog是对goroutine的封装
type waitq struct {
first *sudog
last *sudog
}
为什么需要将 goroutine 包装成 sudog?
goroutine 和 channel 存在多对多关系
场景 1: 一个 goroutine 等待多个 channel:
select {
case <-ch1: // g 在 ch1 的 recvq 中需要一个 sudog
case <-ch2: // g 在 ch2 的 recvq 中需要一个 sudog
case <-ch3: // g 在 ch3 的 recvq 中需要一个 sudog
}
场景 2: 多个 goroutine 同时等待一个 channel:
// 多个 goroutine 可能等待同一个 channel
go func() { <-ch }() // goroutine 1 的 sudog
go func() { <-ch }() // goroutine 2 的 sudog
go func() { <-ch }() // goroutine 3 的 sudog
sudog 的存在是为了解决这种多对多的关系,它允许我们跟踪哪些 goroutine 正在等待哪些同步对象(channel 就算是一种同步对象)。
从另一个角度来看是为了解耦, sudog 作为 goroutine 和 同步对象 之间的一个桥梁,可以存储与等待相关的状态信息,而无需修改 g 结构体本身。如果没有 sudog ,channel 的实现可能会更复杂。
二、创建 channel:makechan ()
当我们使用 make(chan int) 创建一个 channel 时,编译器会将其转换为汇编指令,最终调用 src/runtime/chan.go 中的 makechan() 函数。这是理解 channel 底层实现的第一步。
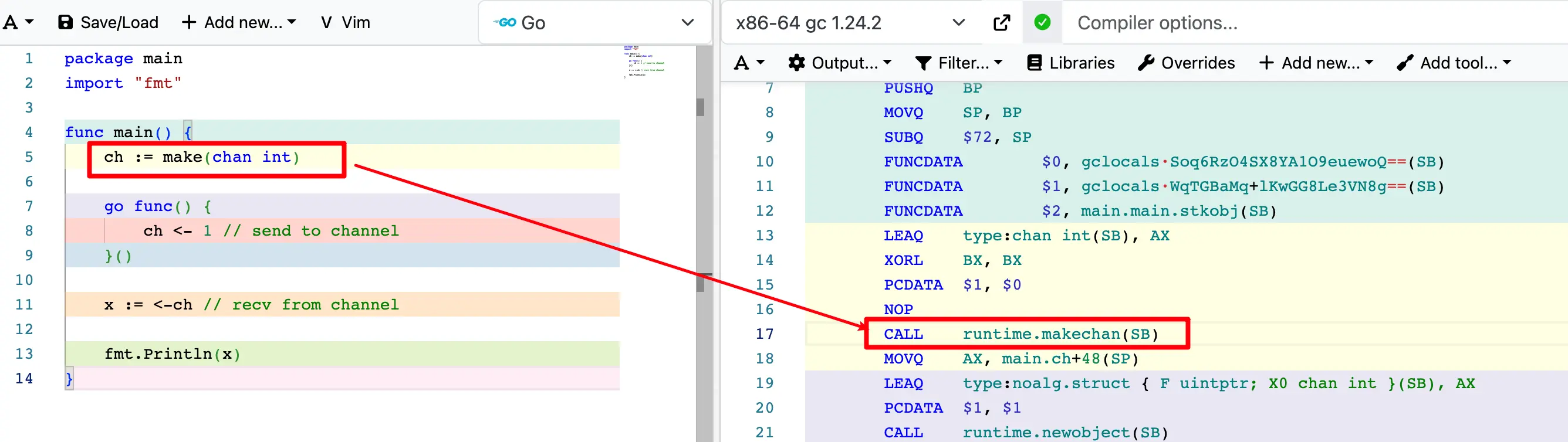
以 ch := make(chan int) 为例,对应的汇编指令如下:
LEAQ type:chan int(SB), AX ; 加载 chan int 的类型信息地址到 AX
XORL BX, BX ; 将 BX 清零(缓冲区大小为 0)
PCDATA $1, $0
NOP
CALL runtime.makechan(SB) ; 调用m makechan 函数,通过StaticBase传递参数给makechan
MOVQ AX, main.ch+48(SP) ; 将返回的 channel 指针存储到栈上
makechan 函数负责 channel 的创建和初始化,其核心逻辑包括安全检查和内存分配:
func makechan(t *chantype, size int) *hchan {
elem := t.Elem
// 元素大小检查:单个元素不能超过 64KB
if elem.Size_ >= 1<<16 {
throw("makechan: invalid channel element type")
}
// 内存对齐检查
if hchanSize%maxAlign != 0 || elem.Align_ > maxAlign {
throw("makechan: bad alignment")
}
// 计算缓冲区所需内存,并检查是否溢出
mem, overflow := math.MulUintptr(elem.Size_, uintptr(size))
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
// Hchan does not contain pointers interesting for GC when elements stored in buf do not contain pointers.
// buf points into the same allocation, elemtype is persistent.
// SudoG's are referenced from their owning thread so they can't be collected.
// TODO(dvyukov,rlh): Rethink when collector can move allocated objects.
// 根据不同情况分配内存
var c *hchan
switch {
case mem == 0:
// 无缓冲 channel 或零大小元素
c = (*hchan)(mallocgc(hchanSize, nil, true))
// Race detector uses this location for synchronization.
c.buf = c.raceaddr()
case !elem.Pointers():
// 元素不含指针:hchan 和 buf 一次性分配连续内存
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
// 元素包含指针:分开分配,便于 GC 管理
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
c.elemsize = uint16(elem.Size_)
c.elemtype = elem
c.dataqsiz = uint(size)
if b := getg().bubble; b != nil {
c.bubble = b
}
lockInit(&c.lock, lockRankHchan)
if debugChan {
print("makechan: chan=", c, "; elemsize=", elem.Size_, "; dataqsiz=", size, "\n")
}
return c
}
1. 编译期生成类型信息符号
编译器在编译期间会为 channel 生成类型信息,并在运行时通过寄存器传递。以下汇编指令将类型信息地址加载到 AX 寄存器:
LEAQ type:chan int(SB), AX
这里的 type:chan int(SB) 就是编译器生成的类型信息符号,它包含了 channel 元素的完整类型描述。
类型信息结构(ChanType)的定义如下:
// ChanType 表示 channel 类型的元信息
type ChanType struct {
Type // 嵌入的 Type 包含类型编号、大小、对齐方式等基础信息
Elem *Type // channel 中存储的元素类型
Dir ChanDir // channel 的方向:只读、只写或双向
}
// ChanDir 定义 channel 的方向
type ChanDir int
const (
RecvDir ChanDir = 1 << iota // <-chan(只读)
SendDir // chan<-(只写)
BothDir = RecvDir | SendDir // chan(双向)
InvalidDir ChanDir = 0 // 无效方向
)
// Type 是 Go 类型在运行时的表现形式
// 包含了类型的大小、对齐、GC信息等元数据
// Be careful about accessing this type at build time, as the version
// of this type in the compiler/linker may not have the same layout
// as the version in the target binary, due to pointer width
// differences and any experiments. Use cmd/compile/internal/rttype
// or the functions in compiletype.go to access this type instead.
// (TODO: this admonition applies to every type in this package.
// Put it in some shared location?)
type Type struct {
Size_ uintptr // 类型占用的字节数
PtrBytes uintptr // 类型前缀中包含指针的字节数,一个结构体里面,假定ptrBytes=16,代表前16个字节范围内是有指针的,gc扫描时必须扫描到第16个字节。之后的部分可以安全跳过(确定后面不含指针)
Hash uint32 // 类型的哈希值,用于快速比较
TFlag TFlag // extra type information flags
Align_ uint8 // 变量的对齐方式
FieldAlign_ uint8 // 结构题字段的对齐方式
Kind_ Kind // 类型的种类,string/int/slice等
// (ptr to object A, ptr to object B) -> ==?
// 用于比较两个对象是否相等的函数
Equal func(unsafe.Pointer, unsafe.Pointer) bool
// GCData stores the GC type data for the garbage collector.
// Normally, GCData points to a bitmask that describes the
// ptr/nonptr fields of the type. The bitmask will have at
// least PtrBytes/ptrSize bits.
// If the TFlagGCMaskOnDemand bit is set, GCData is instead a
// **byte and the pointer to the bitmask is one dereference away.
// The runtime will build the bitmask if needed.
// (See runtime/type.go:getGCMask.)
// Note: multiple types may have the same value of GCData,
// including when TFlagGCMaskOnDemand is set. The types will, of course,
// have the same pointer layout (but not necessarily the same size).
GCData *byte
Str NameOff // 类型的字符串表示
PtrToThis TypeOff // type for pointer to this type, may be zero
}
2. 安全检查
在分配内存之前, makechan 会进行三项关键的安全检查:
- 元素大小检查
- 内存对齐检查
- 缓冲区溢出检查
元素大小检查
// 单个元素不能超过 64KB
if elem.Size_ >= 1<<16 {
throw("makechan: invalid channel element type")
}
这个限制是为了防止单个元素占用过大内存,避免内存分配失败。
内存对齐检查
// 对齐检查, maxAlign为8
if hchanSize % maxAlign != 0 || elem.Align_ > maxAlign {
throw("makechan: bad alignment")
}
maxAlign 在 64 位系统上通常为 8 字节
hchanSize 是 hchan 结构体对齐到 maxAlign 边界后的大小,确保 channel 的内存布局符合 CPU 对齐要求,提高访问效率。
缓冲区溢出检查
// mem = 元素大小(elem.Size_) * 缓冲区容量(size)
mem, overflow := math.MulUintptr(elem.Size_, uintptr(size))
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
这个检查防止以下异常场景:
// 场景1:缓冲区过大导致溢出
func example1() {
c := make(chan byte, 1<<48) // panic: makechan: size out of range
println(c)
}
// 场景2:负数缓冲区大小
func example2() {
n := -1
c := make(chan byte, n) // panic: makechan: size out of range
println(c)
}
3.运行时根据不同策略分配内存
根据 channel 的缓冲区大小和元素类型,Go 运行时采用三种不同的内存分配策略,以优化性能和内存使用。
策略 1:无缓冲/零大小元素
case mem == 0:
c = (*hchan)(mallocgc(hchanSize, nil, true))
// Race detector uses this location for synchronization.
c.buf = c.raceaddr()
由于无需缓冲区或元素本身不占空间,只需分配 hchan 结构体的内存即可。
make(chan int) // 无缓冲 channel,用于同步通信
make(chan struct{}, 100) // 0大小元素, 用作信号通道/控制并发
策略 2: 元素不含指针
// retrun: 是否包含指针
case !elem.Pointers():
// 一次性分配连续内存:hchan + buf
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
这种情况下会一次性分配连续的内存空间,大小为 hchanSize + mem 。
这可以提高缓存局部性(cache locality),访问 hchan 和 buf 时更有可能命中 CPU 缓存。
mallocgc 传递 nil,表示整块内存没有指针,不存在内存逃逸,GC 扫描的时候可以跳过这块内存(noscan)
适用的场景:
make(chan int, 10) // int 不含指针
make(chan float64, 5) // float64 不含指针
make(chan [100]byte, 3) // 字节数组不含指针
策略 3: 元素包含指针
default:
// Elements contain pointers.
c = new(hchan)
// elem告诉gc这块内存的布局,GC可以正确识别和追踪其中的指针
c.buf = mallocgc(mem, elem, true)
适用场景:
make(chan *User, 10) // 指针类型
make(chan []int, 5) // slice 含指针
make(chan string, 3) // string 含指针
make(chan interface{}, 10) // interface 含指针
为什么要分开分配 ?
分开分配,让 GC 只扫描c.buf。
hchan 本身不需要特殊的 GC 追踪,而 buf 缓冲区,通过传递 elem 类型信息,GC 可以:
- 按照
elemsize步长遍历缓冲区 - 准确识别每个元素中的指针字段
- 正确追踪指针引用
举个例子:
type User struct {
Id int64
Name *string // 指针在offset 8
}
make(chan *User, 10)
// 代码等价于下面这行
// elem.Size_ = 8字节, 64位系统的指针大小
// size = 10
// mem = 8 * 10 = 80
// 96是 hchan的大小
c = malloc(96 + 80, userType, true)
如果不分开分配内存,而是直接用 mallocgc,gc 会认为整块内存都是 User 对象,会导致内存被破坏。实际上 96+80 代表的是 hchan
80 是 hchan.buf ,我们应该让 GC 去管理 hchan.buf 的内存而不是 hchan 。
三、发送数据到 channel:chansend
当我们使用 ch <- value 向 channel 发送数据时,编译器会将其转换为 runtime.chansend1() 的调用,该函数内部会调用 src/runtime/chan.go 中的 chansend() 函数来完成实际的发送操作。
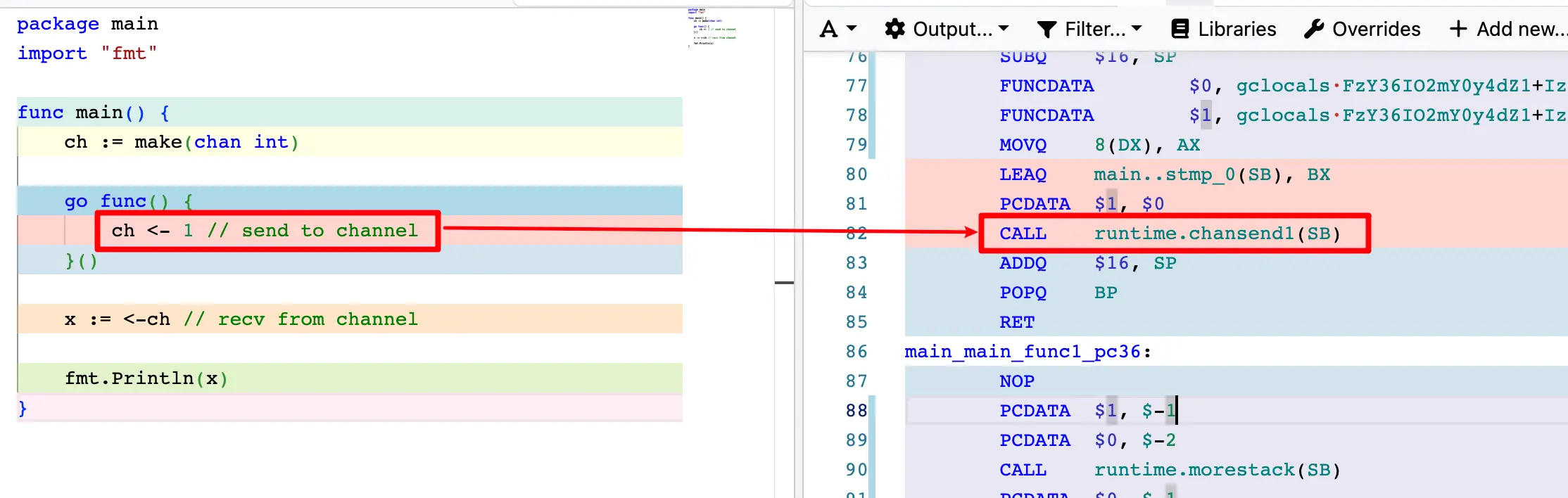
/*
* chansend - channel 发送操作的核心实现
*
* 参数说明:
* c: 目标 channel
* ep: 指向要发送数据的指针
* block: 是否阻塞模式
* - true: 阻塞模式(普通发送 ch <- x)
* - false: 非阻塞模式(select 中的发送)
* callerpc: 调用者的程序计数器(用于性能分析和调试追踪)
*
* 返回值:
* true: 发送成功
* false: 非阻塞模式下发送失败(select 会尝试其他 case)
*
* 唤醒机制:
* 被阻塞的 goroutine 可能因为 channel 关闭而被唤醒(g.param == nil)
* 此时最简单的做法是重新执行操作,会发现 channel 已关闭并 panic
*/
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
// ==================== 阶段 1: nil channel 处理 ====================
if c == nil {
if !block {
// 非阻塞模式(select):直接返回 false,select 会尝试其他 case
return false
}
// 阻塞模式:永久挂起当前 goroutine
// 这是一个常见的陷阱:向 nil channel 发送会永久阻塞
// 示例:
// var ch chan int
// ch <- 1 // 永久阻塞,因为 ch 是 nil
gopark(nil, nil, waitReasonChanSendNilChan, traceBlockForever, 2)
throw("unreachable")
}
if debugChan {
print("chansend: chan=", c, "\n")
}
// race detector 支持:记录并发访问以检测竞态条件
if raceenabled {
racereadpc(c.raceaddr(), callerpc, abi.FuncPCABIInternal(chansend))
}
if c.bubble != nil && getg().bubble != c.bubble {
fatal("send on synctest channel from outside bubble")
}
// ==================== 阶段 2: 快速路径(无锁优化)====================
// 这是 select 非阻塞发送的性能优化
//
// 原理:
// 1. 只在非阻塞模式(!block)下执行
// 2. 无锁检查两个条件:c.closed == 0 && full(c)
// 3. 利用单字读取的原子性和 channel 状态的单调性保证正确性
//
// 为什么安全?
// - c.closed 从 0→1 是单向的(closed 状态不可逆)
// - 即使读到旧值,最坏情况是错过优化机会,不会导致错误
// - 有慢速路径(加锁)兜底,保证最终正确性
//
// 优化效果:
// - 避免大量 select case 的锁竞争
// - 在 channel 已满时快速失败,性能提升 5-10 倍
//
// 注意:这个检查允许读操作重排序,但通过 unlock() 的内存屏障
// 保证最终一致性
if !block && c.closed == 0 && full(c) {
return false
}
// 记录阻塞开始时间(用于性能分析)
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}
// ==================== 阶段 3: 加锁,进入慢速路径 ====================
lock(&c.lock)
// 检查 channel 是否已关闭
// 向已关闭的 channel 发送数据会 panic(这是 Go 的设计决策)
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
// ==================== 阶段 4: 直接传递给等待的接收者(最快路径)====================
// 尝试从接收队列中取出一个等待的接收者
// 这是性能最优的路径:直接传递,避免经过缓冲区
if sg := c.recvq.dequeue(); sg != nil {
// 找到了等待的接收者!
//
// 优化原理:
// 传统方式:发送者 → 缓冲区 → 接收者(两次拷贝)
// 直接传递:发送者 → 接收者(一次拷贝)✨
//
// sg: 接收者的 sudog(包含接收者 goroutine 和目标地址)
// ep: 要发送的数据指针
// func() { unlock(&c.lock) }: 解锁函数,数据拷贝后解锁
// 3: skip 参数,用于调用栈追踪(跳过 3 个栈帧到达用户代码)
//
// 执行流程:
// 1. sendDirect() 将数据从 ep 拷贝到 sg.elem(指向了接收者的栈空间地址),内部调用了memmove函数
// 2. 解锁 channel
// 3. 唤醒接收者 goroutine
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
// ==================== 阶段 5: 写入缓冲区(次优路径)====================
// 检查缓冲区是否有空间
if c.qcount < c.dataqsiz {
// 有空间!将数据写入缓冲区
//
// 循环队列实现:
// buf: [0][1][2][3][4] (dataqsiz = 5)
// ↑ ↑
// recvx sendx
//
// qp: 指向 buf[sendx] 的指针
qp := chanbuf(c, c.sendx)
if raceenabled {
racenotify(c, c.sendx, nil)
}
// 拷贝数据到缓冲区
// typedmemmove 会:
// 1. 检查类型是否包含指针
// 2. 如果包含指针,触发写屏障(通知 GC)
// 3. 执行实际的内存拷贝
typedmemmove(c.elemtype, qp, ep)
// 更新写索引(循环队列的关键)
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0 // 循环到开头
}
// 增加元素计数
c.qcount++
unlock(&c.lock)
return true
}
// ==================== 阶段 6: 非阻塞模式失败 ====================
// 缓冲区满了,且是非阻塞模式(select)
// 直接返回 false,让 select 尝试其他 case 或 default
if !block {
unlock(&c.lock)
return false
}
// ==================== 阶段 7: 阻塞等待(最后的选择)====================
// 缓冲区满了,且是阻塞模式
// 将当前 goroutine 挂起,等待接收者来取数据
//
// 关键概念:
// - 接收者会从 sendq 取出这个 sudog
// - 直接从 mysg.elem 拷贝数据
// - 然后唤醒我们
gp := getg() // 获取当前 goroutine
// 从对象池获取一个 sudog(goroutine 的代理对象)
// sudog 用于表示阻塞在同步对象上的 goroutine
// 使用对象池可以避免频繁分配,减少 GC 压力
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1 // 标记需要记录阻塞时间
}
// 设置 sudog 的关键字段
// 注意:在赋值 elem 和将 mysg 加入队列之间不能有栈分裂(stack split)
// 因为 copystack 需要找到 gp.waiting 来更新栈上的指针
mysg.elem = ep // 指向要发送的数据(在发送者的栈上)
mysg.waitlink = nil // 用于构建等待链表
mysg.g = gp // 关联当前 goroutine
mysg.isSelect = false // 不是 select 操作
mysg.c = c // 关联的 channel
gp.waiting = mysg // goroutine 记录正在等待的 sudog
gp.param = nil
// 将 sudog 加入发送队列
// 接收者会从这个队列取出 sudog,直接从 mysg.elem 拷贝数据
c.sendq.enqueue(mysg)
// 标记:即将在 channel 上 park(阻塞)
// 这个标记告诉栈收缩(stack shrinking)机制:
// - 在 G 状态改变到设置 activeStackChans 之间的窗口期
// - 栈收缩是不安全的
// - 因为 sudog 中可能有指向栈的指针
gp.parkingOnChan.Store(true)
// 确定阻塞原因(用于调试和追踪)
reason := waitReasonChanSend
if c.bubble != nil {
reason = waitReasonSynctestChanSend
}
// gopark: 阻塞当前 goroutine
// 参数:
// - chanparkcommit: 解锁函数(会调用 unlock(&c.lock))
// - &c.lock: 要解锁的锁
// - reason: 阻塞原因
// - traceBlockChanSend: 追踪事件类型
// - 2: skip 栈帧数
//
// 执行后:
// 1. 解锁 channel(通过 chanparkcommit)
// 2. 将 goroutine 状态改为 _Gwaiting
// 3. 调度其他 goroutine 运行
// 4. 当前 goroutine 在这里停住,直到被唤醒
gopark(chanparkcommit, unsafe.Pointer(&c.lock), reason, traceBlockChanSend, 2)
// ========== 被唤醒后从这里继续执行 ==========
// KeepAlive: 确保 ep 指向的数据在接收者拷贝之前不被 GC 回收
// 原因:
// - mysg.elem 指向 ep(发送者栈上的数据)
// - 但 sudog 不被 GC 视为栈追踪的根
// - 如果没有 KeepAlive,GC 可能认为 ep 已经不再使用
// - 可能在接收者拷贝之前就回收了栈空间
KeepAlive(ep)
// 被唤醒了!检查唤醒原因
// 完整性检查:确保等待列表没有被破坏
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
// 清理 goroutine 的等待状态
gp.waiting = nil
gp.activeStackChans = false // 栈上不再有活跃的 channel 操作
// 检查唤醒原因
// mysg.success 表示是否成功完成通信
// - true: 接收者成功拷贝了数据
// - false: channel 被关闭导致唤醒
closed := !mysg.success
gp.param = nil
// 记录阻塞事件(用于性能分析)
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
// 清理 sudog 并归还到对象池
// 必须清空 c 指针,避免野指针
mysg.c = nil
releaseSudog(mysg)
// 如果是因为 channel 关闭而被唤醒
if closed {
// 双重检查:确保 channel 确实关闭了
if c.closed == 0 {
throw("chansend: spurious wakeup") // 虚假唤醒,不应该发生
}
// 向已关闭的 channel 发送会 panic
panic(plainError("send on closed channel"))
}
// 成功发送!
return true
}
chansend 的无锁优化
chansend 中有一段代码是实现了 select 非阻塞语义的快速路径无锁优化,避免了 select 大量 case 的锁竞争
非阻塞的情况下,判断 closed 和 full 是没有加锁的
// ========== 无锁优化 BEGIN =============
if !block && c.closed == 0 && full(c) {
return false
}
// ========== 无锁优化 END =============
// 其他代码...
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
返回 false 是 select 语义的要求:如果这个 case 不能立即完成,就不能选择这个 case
select {
case ch <- x: // 尝试发送
// 只有能立即完成才执行这里
default:
// select的快速路径 return false就会走到这里
}
为什么 closed 和 full 不需要额外上锁?不怕读到旧的值吗?
-
硬件层面保证安全
- 单字(word-sized)读取在现代 CPU 上是原子的
closed和full()都只涉及了单字的读取,uint32/uint/指针等类型的读取不会读到“一半的值”,读取这些类型的值不需要额外的同步指令。
-
快路径的保守判断,只处理明确失败的情况:
| 读取值 | 处理方式 | 结果 |
|---|---|---|
closed=0, full=true |
返回 false | ✅ 正确(确实无法发送) |
closed=1, full=* |
继续加锁 | ✅ 慢路径精确判断 |
closed=0, full=false |
继续加锁 | ✅ 可能成功,需加锁 |
- 由于并发导致读取到旧值的情况:
情况 A:读到旧的closed值
// 时间线
T0: c.closed = 0
T1: close(ch) -> c.closed = 1
T2: 读到旧值 0, 条件不满足快路径
T3: 继续加锁, 检测到 closed = 1, panic
结果: 安全, 只是错过了快速失败的机会
情况 B:读到旧的 full() 值
// 时间线
// full()调用, 内部读取的是qcount和dataqsiz
T0: qcount = 3, dataqsiz = 3 // 已满
T1: <-ch 后, qcount = 2 // 有空间了
T2: 读到旧值 3,误判为满
T3: 返回 false, select 执行 default
结果: 安全, 符合 select 语义(尽力尝试)
如果在for循环执行select,则可以等待下一轮发送, 这一轮只是走了快路径提前返回了
总结:读到旧值也安全,最坏的结果只是错过快路径优化
阻塞模式 / 非阻塞模式
在 select 中给 channel 发送数据就是非阻塞模式
select {
case c <- v:
... foo
default:
... bar
}
其中 c <- v 会被处理为 chansend(c, elem, false, sys.GetCallerPC())
false表示非阻塞模式
///////////////////////
ch := make(chan int)
ch <- 1 会被处理为 chansend(c, elem, true, sys.GetCallerPC())
true表示阻塞模式
需要注意的是,select 不写 default 也会被优化成阻塞模式:
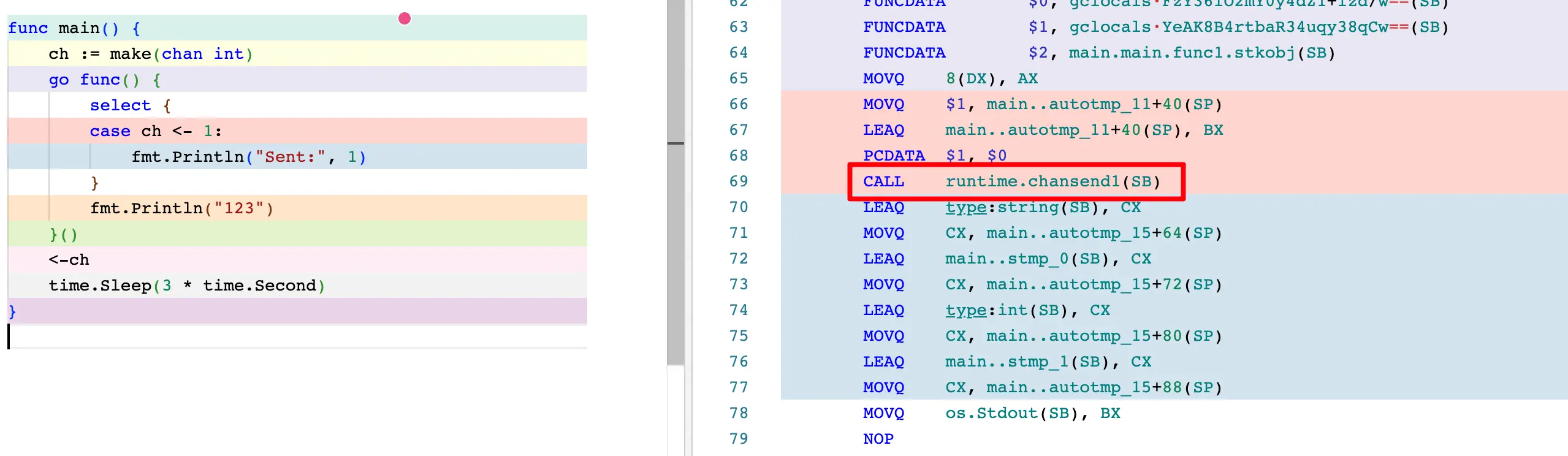
func chansend1(c *hchan, elem unsafe.Pointer) {
// true 代表阻塞模式
chansend(c, elem, true, sys.GetCallerPC())
}
性能分析辅助:skip 跳过栈帧
绕过缓冲区发送数据给 goroutine 的时候, 跳过了 3 个栈帧:
if sg := c.recvq.dequeue(); sg != nil {
// 直接传递数据, 绕过缓冲区直接发送给接收者
// sg: 等待接收的goroutine
// ep: 要发送到数据
// func() { unlock(&c.lock) }: 解锁函数, 在发送完成后解锁
// 3: 跳过3个栈帧
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
// send内部调用了 goready 的时候传入了 skip + 1 = 4
最终要跳过4个栈帧
举个例子:
// 用户代码
func main() {
ch := make(chan int)
go func() {
ch <- 42 // ← trace 应该记录到这里
}()
<-ch
}
// 调用栈(不想记录的部分):
main.func1() // 用户代码 ✅ 保留
runtime.chansend1() // ❌ 跳过
runtime.chansend() // ❌ 跳过
runtime.send() // ❌ 跳过
runtime.goready() // ❌ 跳过
简单来说,skip 是为了让性能分析工具能正确归因到用户代码,而不是 runtime 内部的实现细节
优化:数据直接传递给 goroutine 的栈空间
channel 的等待队列有 goroutine 的时候, c <- 1 会直接把 1 拷贝到 goroutine 所在的内存空间,数据不经过 channel 的缓冲区,少了 1 次拷贝
if sg := c.recvq.dequeue(); sg != nil {
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
// send - 直接传递:将数据从发送者直接拷贝给等待的接收者
//
// 这是 channel 最重要的优化之一,避免了缓冲区的中转
//
// 参数说明:
//
// c: channel(必须已加锁)
// sg: 接收者的 sudog(已从 recvq 取出)
// ep: 发送者的数据指针(指向发送者栈或堆)
// unlockf: 解锁函数(通常是 unlock(&c.lock))
// skip: 调用栈跳过的帧数(用于性能分析追踪)
//
// 前置条件:
// - channel 必须已加锁
// - sg 必须已从 c.recvq 移除
// - ep 必须非 nil
//
// 执行流程:
// 1. 直接拷贝数据到接收者的栈(跨 goroutine 栈操作!)
// 2. 解锁 channel
// 3. 标记成功并唤醒接收者
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
// synctest 检查
if c.bubble != nil && getg().bubble != c.bubble {
unlockf()
fatal("send on synctest channel from outside bubble")
}
// race detector 支持
if raceenabled {
if c.dataqsiz == 0 {
// 无缓冲 channel:直接同步
racesync(c, sg)
} else {
// 有缓冲 channel:假装经过缓冲区(用于 race detector)
// 虽然实际是直接拷贝,但为了 race detector 正确工作
// 需要更新索引(仅在 raceenabled 时)
racenotify(c, c.recvx, nil)
racenotify(c, c.recvx, sg)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.sendx = c.recvx // 保持 sendx 和 recvx 同步
}
}
// ========== 核心:跨 goroutine 栈的直接拷贝 ==========
//
// sg.elem 的含义:
// - 指向接收者 goroutine 栈上的变量地址
// - 由接收者在阻塞时设置
//
// 示例:
// 接收者执行:x := <-ch
// 编译器生成:chanrecv(ch, &x, true)
// 内部设置:mysg.elem = &x
// 这里就涉及到了跨栈写入, mysg所在的协程A 要往 x所在的协程B写数据
//
// sendDirect 做什么:
// 从 ep(发送者的数据)拷贝到 sg.elem(接收者的变量)
// 使用特殊的写屏障(typeBitsBulkBarrier)处理跨栈写入
//
// 为什么设置为 nil:
// - sudog 会被回收到对象池并重用
// - 接收者的栈可能很快被回收
// - 必须断开指针,避免野指针和内存泄漏
if sg.elem != nil {
sendDirect(c.elemtype, sg, ep)
sg.elem = nil // 🔒 防止悬挂指针
}
// 获取接收者 goroutine
gp := sg.g
// 解锁 channel(数据已拷贝完成,可以释放锁)
unlockf()
// 设置唤醒参数
gp.param = unsafe.Pointer(sg) // 传递 sudog 给接收者
sg.success = true // 标记:成功接收(非 channel 关闭)
// 记录唤醒时间(用于性能分析)
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
// goready: 唤醒接收者 goroutine
// 将接收者从 _Gwaiting 状态改为 _Grunnable
// 放入运行队列,等待调度
goready(gp, skip+1)
}
// ==================== 跨 goroutine 栈写入的特殊处理 ====================
//
// Channel 的直接传递机制(无缓冲或有接收者等待时)会产生一个独特的场景:
// 一个正在运行的 goroutine 写入另一个 goroutine 的栈
//
// 这违反了 GC 的基本假设:
// - GC 假设:栈写入只发生在 goroutine 运行时,且只由该 goroutine 自己完成
// - Channel 打破了这个假设
//
// 为什么不能用 typedmemmove:
// - typedmemmove 调用 bulkBarrierPreWrite(堆写屏障)
// - 但目标地址是栈,不是堆,堆写屏障不适用
//
// 解决方案:
// - 使用 memmove 直接拷贝内存
// - 使用 typeBitsBulkBarrier(栈写屏障)通知 GC
// - 这样 GC 才能正确追踪跨栈的指针
// sendDirect - 将数据从当前栈拷贝到另一个 goroutine 的栈
//
// 跨栈写入的危险场景:
//
// 时刻 1: 读取 sg.elem(指向接收者栈的地址)
// 时刻 2: 接收者栈可能被 GC 收缩/移动
// 时刻 3: 写入数据到 sg.elem(此时地址可能已失效!)
//
// 防护措施:
//
// 在读取 sg.elem 和使用它之间不能有抢占点(preemption point)
// 这样可以保证栈地址不会在中途改变
func sendDirect(t *_type, sg *sudog, src unsafe.Pointer) {
// src: 当前 goroutine 栈上的数据
// dst: 接收者 goroutine 栈上的目标地址
// 读取目标地址(从这一刻起到拷贝完成,不能有抢占!)
dst := sg.elem
// 通知 GC:我们要跨栈写入了
// typeBitsBulkBarrier 会:
// 1. 扫描类型中的指针字段
// 2. 标记这些指针指向的对象(防止被 GC 误回收)
// 3. 更新 GC 的栈追踪信息
typeBitsBulkBarrier(t, uintptr(dst), uintptr(src), t.Size_)
// 直接内存拷贝(不需要 cgo 写屏障,因为目标总是 Go 内存)
memmove(dst, src, t.Size_)
}
四、从channel 读取数据
channel 的不同写法会转变成对 chanrecv1 / chanrecv2 / selectnbrecv 的调用:
package main
import "fmt"
func main() {
ch := make(chan int, 100)
// 调用 chanrecv1
v1 := <-ch
// 调用 chanrecv2
v2, ok := <-ch
// 非阻塞接收
select {
// 调用 runtime.selectnbrecv
case v3, ok := <-ch:
fmt.Println("received:", v3, ok)
default:
fmt.Println("no data available")
}
// 调用 runtime.chanrecv2
for v := range ch {
fmt.Println(v)
}
fmt.Println(v1, v2, ok)
}
本质上是调用 runtime.chanrecv() , 函数签名为:
// block: 阻塞/非阻塞接收
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool)
// ==============================
// x := <-ch
func chanrecv1(c *hchan, elem unsafe.Pointer) {
chanrecv(c, elem, true)
}
// x,ok := <-ch
func chanrecv2(c *hchan, elem unsafe.Pointer) (received bool) {
_, received = chanrecv(c, elem, true)
return
}
// select case x:= <- ch
// select case x,ok := <-ch
func selectnbrecv(elem unsafe.Pointer, c *hchan) (selected, received bool) {
return chanrecv(c, elem, false)
}
| 语法 | 编译后实际调用 | chanrecv 的block 参数 |
|---|---|---|
x := <-ch |
chanrecv1(ch, &x) |
true |
x, ok := <-ch |
chanrecv2(ch, &x) |
true |
select case x := <-ch |
chanrecv(ch, &x, false) |
false |
<-ch(丢弃值) |
chanrecv1(ch, nil) |
true |
// 当 received 返回true时表示还可以继续 读数据
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
// raceenabled: don't need to check ep, as it is always on the stack
// or is new memory allocated by reflect.
if debugChan {
print("chanrecv: chan=", c, "\n")
}
// 从空的channel读数据
// 如果是select非阻塞模式返回false
// 如果是阻塞模式,就永久阻塞
// var ch chan int
// x := <- ch // 永久阻塞
if c == nil {
if !block {
return
}
gopark(nil, nil, waitReasonChanReceiveNilChan, traceBlockForever, 2)
throw("unreachable")
}
if c.bubble != nil && getg().bubble != c.bubble {
fatal("receive on synctest channel from outside bubble")
}
if c.timer != nil {
c.timer.maybeRunChan(c)
}
// 快路径优化: 非阻塞模式下,不加锁,判断channel是否为空
// Fast path: check for failed non-blocking operation without acquiring the lock.
if !block && empty(c) {
// After observing that the channel is not ready for receiving, we observe whether the
// channel is closed.
//
// Reordering of these checks could lead to incorrect behavior when racing with a close.
// For example, if the channel was open and not empty, was closed, and then drained,
// reordered reads could incorrectly indicate "open and empty". To prevent reordering,
// we use atomic loads for both checks, and rely on emptying and closing to happen in
// separate critical sections under the same lock. This assumption fails when closing
// an unbuffered channel with a blocked send, but that is an error condition anyway.
// Q:为什么 不直接读 closed 而是要用 atomic来读?
// A: 这里存在指令重排的问题, 假定 closed和 empty都不加锁,
// 先判断 empty, 再判断closed, 重排之后错误地判断为: 打开且为空的channel
// 所以需要使用 atomic来保证顺序一致性, 通过原子操作得到顺序保证
if atomic.Load(&c.closed) == 0 {
// closed的状态只能是从0到1, 不能重新打开
// 如果上锁观察到 closed是0,说明第一次观察到empty的时候 channel也没关闭
return
}
// channel已经关闭,需要检查channel是否为空,因为有可能在判断empty和closed之间,有数据发送到了channel
// The channel is irreversibly closed. Re-check whether the channel has any pending data
// to receive, which could have arrived between the empty and closed checks above.
// Sequential consistency is also required here, when racing with such a send.
if empty(c) {
// The channel is irreversibly closed and empty.
if raceenabled {
raceacquire(c.raceaddr())
}
if ep != nil {
// 清零目标内存
typedmemclr(c.elemtype, ep)
}
return true, false
}
}
// 记录阻塞时间, 用于性能分析
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}
lock(&c.lock)
// channel已关闭
if c.closed != 0 {
// channel已关闭,且没有数据
if c.qcount == 0 {
if raceenabled {
raceacquire(c.raceaddr())
}
unlock(&c.lock)
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
// The channel has been closed, but the channel's buffer have data.
} else {
// Just found waiting sender with not closed.
// channel没关闭,如果有等待发送的sender,直接从sender那里获取数据,绕过缓冲区
// ch <- 1 所在的gorotine就是 sg
if sg := c.sendq.dequeue(); sg != nil {
// 找到了等待的发送者!
//
// 两种情况:
// 1. 无缓冲 channel (dataqsiz == 0):
// 直接从发送者拷贝数据到接收者(一次拷贝)
//
// 2. 有缓冲 channel 且缓冲区满了:
// - 从缓冲区头部取出数据给接收者
// - 将发送者的数据放入缓冲区尾部
// - 由于缓冲区满,头尾指向同一个槽位(循环队列特性)
//
// 为什么有发送者等待?
// - 无缓冲:发送者在等接收者
// - 有缓冲:缓冲区满了,发送者被阻塞
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
}
// channel没关闭,且有数据
if c.qcount > 0 {
// 从缓冲区中获取数据
qp := chanbuf(c, c.recvx)
if raceenabled {
racenotify(c, c.recvx, nil)
}
if ep != nil {
// 将数据从缓冲区拷贝到ep
// x := <-ch, ep就是x的地址
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp)
// 更新循环队列的读指针
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
unlock(&c.lock)
// 返回true, true, 表示成功接收数据
return true, true
}
// channel没关, 没有等待的发送者, 缓冲区为空
// 非阻塞模式,直接返回false, false
if !block {
unlock(&c.lock)
return false, false
}
// 缓冲区为空,阻塞等待
// 将当前goroutine挂起
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
// No stack splits between assigning elem and enqueuing mysg
// on gp.waiting where copystack can find it.
mysg.elem = ep
mysg.waitlink = nil
gp.waiting = mysg
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.param = nil
c.recvq.enqueue(mysg)
if c.timer != nil {
blockTimerChan(c)
}
// Signal to anyone trying to shrink our stack that we're about
// to park on a channel. The window between when this G's status
// changes and when we set gp.activeStackChans is not safe for
// stack shrinking.
gp.parkingOnChan.Store(true)
reason := waitReasonChanReceive
if c.bubble != nil {
reason = waitReasonSynctestChanReceive
}
gopark(chanparkcommit, unsafe.Pointer(&c.lock), reason, traceBlockChanRecv, 2)
// someone woke us up
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
if c.timer != nil {
unblockTimerChan(c)
}
gp.waiting = nil
gp.activeStackChans = false
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
success := mysg.success
gp.param = nil
mysg.c = nil
releaseSudog(mysg)
return true, success
}
recv 函数
有 2 种情况会调用recv 函数:
- 无缓冲channel 发送数据
- 有缓冲channel 且缓冲区已满
// recv - 从等待的发送者接收数据
//
// 两个关键步骤:
// 1. 将发送者的数据放入 channel(或缓冲区)
// 2. 将数据写入接收者的目标地址
//
// 两种场景:
//
// 同步 channel (dataqsiz == 0): 两个值相同,直接传递
// 异步 channel (dataqsiz > 0): 接收者从缓冲区取,发送者放入缓冲区
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if c.bubble != nil && getg().bubble != c.bubble {
unlockf()
fatal("receive on synctest channel from outside bubble")
}
if c.dataqsiz == 0 {
// 无缓冲channel, 直接传递
if raceenabled {
racesync(c, sg)
}
if ep != nil {
// copy data from sender
// 将sg.elem的数据拷贝到ep
// 跨goroutine栈拷贝数据
recvDirect(c.elemtype, sg, ep)
}
} else {
// 有缓冲channel, 从缓冲区中获取数据
// 队列满了, 从队列头部获取数据
// 将发送者的数据放入缓冲区尾部
// 由于缓冲区满,头尾指向同一个槽位(循环队列特性)
// 场景:dataqsiz = 3, qcount = 3
// buf: [A][B][C]
// ↑
// recvx = sendx (都是 0)
//
// 操作:
// 1. 接收者取走 A (recvx 位置)
// 2. 发送者放入 D 到原来 A 的位置 (sendx 位置)
// 3. recvx++, sendx++ (同步移动)
//
// 结果:buf: [D][B][C], recvx = sendx = 1
// qp 指向队头(即将被接收者取走)
qp := chanbuf(c, c.recvx)
if raceenabled {
racenotify(c, c.recvx, nil)
racenotify(c, c.recvx, sg)
}
//
if ep != nil {
// 从缓冲区qp 拷贝给接收者 ep
typedmemmove(c.elemtype, ep, qp)
}
// copy data from sender to queue
// 将发送者的数据 sg.elem 放入缓冲区尾部 qp
typedmemmove(c.elemtype, qp, sg.elem)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
}
// sg需要复用, 将指针设为null防止悬挂指针
sg.elem = nil
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
sg.success = true
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1)
}
五、关闭 channel
func closechan(c *hchan) {
// 关闭空channel导致Panic
if c == nil {
panic(plainError("close of nil channel"))
}
if c.bubble != nil && getg().bubble != c.bubble {
fatal("close of synctest channel from outside bubble")
}
lock(&c.lock)
// 重复关闭channel导致Panic
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("close of closed channel"))
}
if raceenabled {
callerpc := sys.GetCallerPC()
racewritepc(c.raceaddr(), callerpc, abi.FuncPCABIInternal(closechan))
racerelease(c.raceaddr())
}
c.closed = 1
var glist gList
// 处理阻塞的接收者
for {
sg := c.recvq.dequeue()
if sg == nil {
break
}
// 清零接收者的值
// 接收者的代码: x,ok := <-ch
// 接收者阻塞的时候: sg.elem = &x;
// channel 关闭时: 将 x 设置为0值, sg.elem = nil(不指向任何地址)
if sg.elem != nil {
typedmemclr(c.elemtype, sg.elem)
sg.elem = nil
}
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = unsafe.Pointer(sg)
sg.success = false
if raceenabled {
raceacquireg(gp, c.raceaddr())
}
glist.push(gp)
}
// 处理阻塞的发送者
// 在 chansend函数中, 发送者会因为 c.closed != 0 导致 Panic
// if c.closed != 0 {
// unlock(&c.lock)
// panic(plainError("send on closed channel"))
// }
//
for {
sg := c.sendq.dequeue()
if sg == nil {
break
}
sg.elem = nil
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = unsafe.Pointer(sg)
sg.success = false
if raceenabled {
raceacquireg(gp, c.raceaddr())
}
glist.push(gp)
}
unlock(&c.lock)
// 批量唤醒goroutine
for !glist.empty() {
gp := glist.pop()
gp.schedlink = 0
goready(gp, 3)
}
}
六、总结
| nil channel | 已关闭的 channel | 空 channel | 满 channel | |
|---|---|---|---|---|
| 写 | 永久阻塞(阻塞模式);返回 false(select) | Panic | 正常写 | 阻塞等待 |
| 读 | 永久阻塞(阻塞模式);返回 false(select) | 返回零值 + false | 阻塞等待 | 正常读 |
| close | Panic | Panic | 正常关闭 | 正常关闭 |
关键规则:
- ❌ 永远不要向 已关闭的 channel 发送数据(会 panic)
- ❌ 永远不要关闭 已关闭的 channel(会 panic)
- ❌ 永远不要关闭 nil channel(会 panic)
- ✅ 从已关闭的 channel 接收数据是安全的(返回零值和 false)
- ✅ nil channel 在 select 中会被忽略(用于动态控制 case)