約1ヶ月前にllama.cppがCLBlastのサポートを追加しました。
そのため、AMDのRadeonグラフィックカードを使って簡単に動かすことができるようになりました。以下にUbuntu 22.04 Jammy Jellyfishでllama.cpp + llama2を実行する方法を紹介します。
モデルのダウンロード
親切なTheBlokeが変換済みのLlama2モデルを提供してくれています:
・TheBloke/Llama-2-70B-GGML
・TheBloke/Llama-2-70B-Chat-GGML
・TheBloke/Llama-2-13B-GGML
・TheBloke/Llama-2-13B-chat-GGML
・TheBloke/Llama-2-7B-GGML
・TheBloke/Llama-2-7B-Chat-GGML
メモリに応じて適切なバージョンをダウンロードしてください。例えば、70bのバージョンは約31GB〜70GBのメモリを必要とします。私はllama-2-13b-chat.ggmlv3.q4_K_M.binをダウンロードしました。
q4は4bitバージョンを意味します。ダウンロードしたモデルは.binで終わるファイルで、~/Downloads/llama-2-13b-chat.ggmlv3.q4_K_M.binに保存します。
llama.cppのコンパイル
Ubuntuで関連ツールとライブラリをダウンロードします:
sudo apt install git make cmake vim
まず、Llama.cppのコードをクローンします:
git clone https://github.com/ggerganov/llama.cpp
公式サイトでは直接makeするように書かれていますが、私の環境では問題があったため、cmakeを使用しました:
mkdir build
cd build
cmake ..
cmake --build . --config Release
ビルドされたプログラムはllama.cpp/build/binに配置され、mainがコマンドプログラムのエントリーポイント、serverがWebサーバーのエントリーポイントです。
これをコピーして名前を変更します:
cp ./bin/main/main ../llama-cpu
cd ..
テスト
llama.cpp/examplesにはいくつかのテストスクリプトがあるので、1つコピーして自分用に変更します:
cp examples/chat-13B.sh examples/chat-llama2-13B.sh
vim examples/chat-llama2-13B.sh
examples/chat-llama2-13B.shのMODELのモデルパスを自分のパスに変更します。例えば、
MODEL="/home/lyric/Downloads/llama-2-13b-chat.ggmlv3.q4_K_M.bin"
そして、./mainを自分の名前./llama-cpuに変更します。
次に実行します:
./examples/chat-llama2-13B.sh
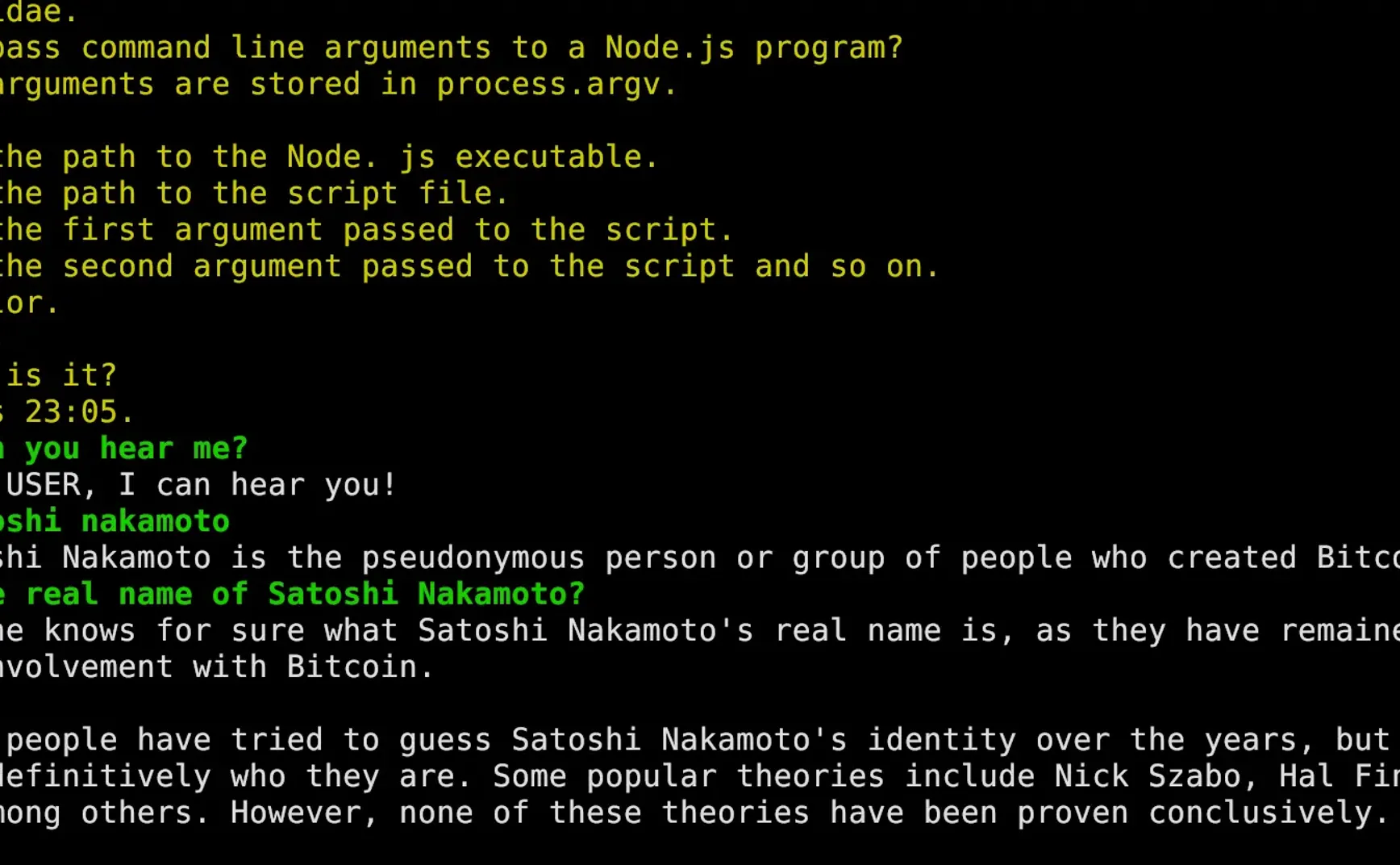
マシンの設定に応じて、少し待つとチャットが始まり、以下のような結果が得られます。緑の文字が自分の入力で、白の文字がLlama 2の応答です。

GPUアクセラレーションの有効化
AMDからドライバをダウンロードします:https://repo.radeon.com/amdgpu-install/
注意:5.*バージョンが新しいバージョンであり、2*.*.*は旧バージョンです。旧バージョンは使用できません。
私がインストールしたのは5.5バージョンです:https://repo.radeon.com/amdgpu-install/5.5/ubuntu/jammy/
インストール後、次を実行します:
amdgpu-install --usecase=opencl,rocm
Ubuntuで関連ライブラリをダウンロードします:
sudo apt install ocl-icd-dev ocl-icd-opencl-dev \
opencl-headers libclblast-dev
-DLLAMA_CLBLAST=ONパラメータを追加して再コンパイルします:
cd build
cmake .. -DLLAMA_CLBLAST=ON -DCLBlast_dir=/usr/local
cmake --build . --config Release
これをコピーして名前を変更します:
cp ./bin/main/main ../llama-cl
cd ..
次に起動スクリプトを変更します:
vim examples/chat-llama2-13B.sh
./llama-cpuを自分の名前./llama-clに変更し、最後から2行目に--n-gpu-layers 40を追加します。例えば:
./llama-cl $GEN_OPTIONS \
--model "$MODEL" \
--threads "$N_THREAD" \
--n_predict "$N_PREDICTS" \
--color --interactive \
--file ${PROMPT_FILE} \
--reverse-prompt "${USER_NAME}:" \
--in-prefix ' ' \
--n-gpu-layers 40
"$@"
--n-gpu-layersはトークン生成を加速するためにVRAMを使用します。私のグラフィックカードでは40に設定しましたが、任意の大きな数字を設定できます。例えば100000など。llama.cppは使用可能な最大レイヤー数を自動的に選択します。
次に実行します:
./examples/chat-llama2-13B.sh
理論上、GPUアクセラレーションを使用すると待ち時間が大幅に短縮され、以下のようなメッセージが表示されるはずです:
ggml_opencl: selecting platform: 'AMD Accelerated Parallel Processing'
...
ama_model_load_internal: using OpenCL for GPU acceleration
llama_model_load_internal: mem required = 710.19 MB (+ 1600.00 MB per state)
llama_model_load_internal: offloading 40 repeating layers to GPU
llama_model_load_internal: offloaded 40/41 layers to GPU
llama_model_load_internal: total VRAM used: 7285 MB
...
これでGPUアクセラレーションが有効になり、私の環境では生成速度が600+トークン毎秒に達し、非常に高速です。
サーバーの実行
llama.cppはサーバーも提供しており、公式ドキュメントを参考にしてください。
私の場合、以下のコマンドで直接実行します:
./server -m ~/Download/llama-2-13b-chat.ggmlv3.q4_K_M.bin \
-c 2048 -ngl 40 --port 10081
次に、http://localhost:10081を開くとWeb UIが使用できるようになります。
このWebサーバーはAPIリクエストをサポートしており、例えば:
curl --request POST \
--url http://localhost:10081/completion \
--header "Content-Type: application/json" \
--data \
'{"prompt": "Build a website can be done in 10 steps:","n_predict": 128}'
これにより、自分のモデルを簡単に利用できます。
トラブルシューティング
OpenCLの権限問題
root権限でのみopencl関連の関数にアクセスできる場合があります。例えば、clinfo実行時にopenclが見つからない
と表示され、sudo clinfoでは正常に表示される場合です。
その場合は、以下を実行します(LOGIN_NAMEを自分のユーザー名に変更してください):
sudo usermod -a -G video LOGIN_NAME
sudo usermod -a -G render LOGIN_NAME
これで現在のユーザーに権限を付与します。
Llama2の問題
OpenAIのChatGPTは多くのプロンプトエンジニアリングと最適化を経ていますが、自分で実行するLlama2はこれらを行っていません。そのため、Llama2が期待に応えない場合は、プロンプトを増やす必要があります。例えば、Llama2にJSONを出力させたい場合は、以下のようにプロンプトにいくつかのJSON生成例を提供する必要があります:
次のテキストを読んで、ユーザーの意図を認識します。
可能な意図は次の通りです:
1. "食事"
2. "睡眠"
3. "豆を打つ"
9999. "不明な意図"
最も自信のある意図を返してください。
結果をJSON形式で返してください。
テンプレートは次の通りです:
{ "id": id, "intent": "USER'S INTENT", "confidence": 0.9 }
**指示: お腹が空いた**
{ "id": 1, "intent": "食事", "confidence": 0.9 }
**指示: 眠い、寝たい**
{ "id": 2, "intent": "睡眠", "confidence": 0.9 }
**指示: 豆はどこ?打ちたい**
{ "id": 3, "intent": "豆を打つ", "confidence": 0.7 }
**指示: 今何時?**
{ "id": 9999, "intent": "不明な意図", "confidence": 0.9 }
Web UIに設定する場合、以下のようになります:

実行結果は以下のようになります:

なかなか良い感じです。