起因は OpenClaw が話題になったことです。最近、私は新しい Agent を開発しました。名前は Mister Morph です。
なぜ「また」と言うのかというと、以前にも一つ開発したことがあるからです。そのコードネームは GZK9000。当時はドメインまで購入していました:
挖新坑啦 pic.twitter.com/hQxNQJ28HR
— Lyric🌀 (@lyricwai) January 28, 2025
しかし、それは未完成のまま終わってしまいました。
この GZK9000 は、現在の基準で見ると確かに Agent です。以下はそのアーキテクチャ図です。
+-------------------------------------------------------------------------------------------+
| gzk9000 Process |
| main -> cmd/root (load config + init DB) -> cmd/server (HTTP + workers) |
+-------------------------------------------------------------------------------------------+
| |
| Online Dialogue Loop (looper + telegram) | Reflective Loop (goalfinder/overthinker)
v v
[Collect Input] Telegram message --> LoopService --> AI reply --> Telegram response
|
v
[Structure Facts] assistant.RecognizeFacts + DetectSentiment
|
v
FactService.CreateFact
| |
v v
PostgreSQL (facts) Qdrant (vectors)
|
v
[Memory Layer] memslices (for later recall)
|
+-------------------------------> [Recall Context] last 24h memslices + facts
|
v
[Find New Goals] extract + dedupe + compare goals
|
v
PostgreSQL (studygoals)
|
v
Guide next questions/thoughts for next input round
|
+----------------------> back to [Collect Input]
その中心的なループ設計は次のとおりです:
- 情報収集:
looperが Telegram からメッセージを読み込み、返信を生成。 - Fact 整理:
looperがRecognizeFacts/DetectSentimentを呼び出して入力を構造化。 - 事実登録:
fact.CreateFactがデータベースと Qdrant ベクトルインデックスへ書き込み。 - 新しい命題の探索:
goalfinderが直近の記憶片と事実から候補ゴールを抽出し、既存のゴールと重複除去したうえでstudygoalsに登録。 - 反復:新しい命題がその後の対話や情報収集に影響し、「情報収集 → Fact 整理 → 新命題探索 → 再収集」という閉ループを形成。
完成しなかった理由は、今振り返ると実装上の方向性を誤ったからです。それについては後で詳しく話します。
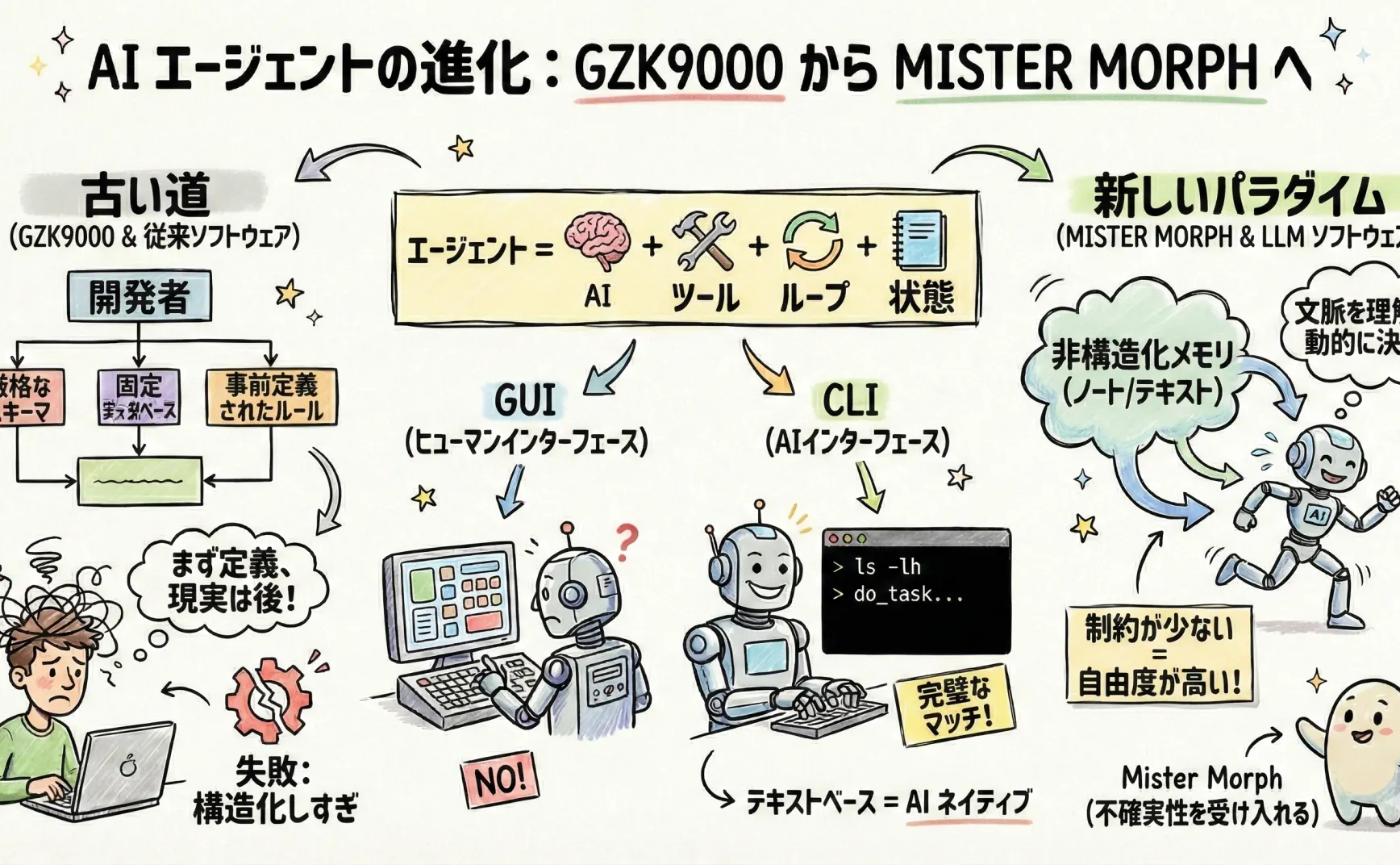
Agent とは何か
ある顧客から、「モデルの能力をテストするときに、なぜ chatgpt.com や grok.com の Web版ではなく API を使う必要があるのか」と聞かれました。
私は言いました。Web版の ChatGPT や Grok は「生のモデル」ではなく、すでに agentic な、軽量の Agent なのです。つまり、ベースモデルにはない追加能力を持っています。Web版で list your tools と入力すると、それぞれが使用可能なツール(検索・計算機・コード実行など)を一覧にしてくれます。また、「どのツールをいつ使うか」「失敗時にどう再試行するか」「結果をどう文脈へ書き戻すか」といった一連の戦略も備えています。
一方で API はより「生のモデル」に近い存在です。推論エンジンのみを提供し、ツール接続やループ処理、状態管理などはすべて自分で実装する必要があります。したがって、モデルの推論能力や言語能力そのものを比較したい場合は、Web版よりも API の方がノイズが少なく、より制御しやすく、実際の開発環境に近いテストができます。
この観点から見ると、あるシステムが agentic(=自律的にタスクを進められる)に振る舞うためには、次のような追加能力が必要になります。
- ツール:思考を行動に変える力。ツールがなければ、モデルはテキストを出力するだけで、新しい情報の取得や外界への作用ができません。
- ループ:不完全な情報下でも「計画 → 実行 → 観察 → 修正」を繰り返す力。一度きりの対話では完璧な回答を出すのは難しく、ループによって解が磨かれます。
- 状態:ループの結果を記録・継承できる仕組み。記憶・メモ・進捗・外部環境変化の記録などであり、状態がなければ発展はなく、ループはただの空回りになります。
したがって、Agent の最小定義をするならこうです:
Agent = モデル + ツール + ループ + 状態
モデルは理解と判断を担当し、ツールは行動を可能にし、ループは反復で最適化し、状態は経験を蓄積します。これにより、ノイズや不確実性の中でも、タスクを継続的に前進させることができ、単発の美しい回答だけでは終わらないのです。
なぜ Agent が必要なのか
理由は二つあります。
第一の理由:One shot では不十分だから
文脈は常に不完全であり、一度の問答で完璧な結果を得ることは難しい。その点、Agent の形式は文脈を拡張するのに適しています。
ツールの利用で効果的な情報を得られます。例えば web_search なら、インターネット上から関連知識を補完できます。記憶を使えば、対話内容や以前のタスクまで覚えておけます。ループ機構によって、Agent は何度も考え、質問を投げかけることができます。
人間も同様なやり方で仕事をしています。脳や感覚システムのバッファは限られており、一度にすべて理解することはできません。そのため、分割して作業する必要があります。具体的には、a) 何度も質問して情報を補う、b) メモを取る、c) 休憩中に過去情報を思い返して反芻する、などです。
第二の理由:ツールは AI の手足になるから
思考した後は、実行が必要です。ツール呼び出しこそが、AI が実行を行う手段です。
人間も同じです。たとえば「コンピュータ」を発明し、まず頭で考え、次にそのツールを使って文章を書き、プログラムを組み、財務分析をし、在庫管理を行う。コンピュータは人間のツールです。
だからこそ、「コンピュータ」そのものを AI にも渡すという発想が自然に生まれます。OpenAI は ChatGPT に Apps を組み込み、他サイトやツールをつなげました。Manus は AI に直接 PC 上でブラウザやアプリを操作させています。
なぜ OpenClaw なのか(別名:なぜ Manus や ChatGPT Apps ではうまくいかないのか)
既存の App サイトや UI 体系は人間向けに設計されており、人間の注意特性や習慣に最適化されています。しかし、それは AI にとっては非常に不向きです。
AI に合ったインタラクション体系を新しく作るのは難しく、エコシステムも存在しません。
ChatGPT Apps は新しいエコシステムを再構築しようとし、Manus は人間の操作をシミュレートしようとしましたが、いずれも困難に直面しています。
ではどうすれば?
既存の体系の中で、AI にも適合し、かつエコシステムが豊富なものは何か?
答えは CLI です。そうして OpenClaw は CLI を選択しました。
非コンピュータ分野の読者のために、CLI を簡単に説明します。
ほとんどの一般ユーザーは、コンピュータやスマートフォンと、ボタンを押したりテキストを入力したりする「グラフィカルな」操作で関わります。
しかし、コンピュータの初期にはグラフィカルな UI はまだなく、すべての操作が「コマンド入力」によって行われていました。例えば、現在のフォルダ内のファイルを表示するには ls、現在時刻を表示するには date と入力します。
各コマンドには動作を調整する多くのパラメータがあります。たとえば ls -lh は詳細情報を一覧に表示するという意味です。
つまり、入力も出力もすべてテキストです。
これで基礎説明は終わりです。
CLI はコマンドに基づいたインターフェースで、各コマンドには明確な意味的入力と出力があります。情報の流れは二次元のテキスト空間で起こります。これはテキストベースの LLM にとって、最適と言っていいほどの組み合わせです。
要するに、CLI は GUI よりも古いインタラクション体系であり、非常に充実したエコシステムを持ち(コマンドだけで OS 上でほぼ何でもできる)、そしてその形態は LLM に驚くほど適しています。OpenClaw はこれを採用したことで、まるで封印が解けたかのように、ChatGPT Apps や Manus を圧倒しました。
なぜ GZK9000 は失敗したのか
理由は二つです。
第一に、コンセプトの問題です。私は当初、GZK9000 を閉じ込められた思考機械として設計し、手足を与えるつもりはありませんでした(名前の GZK9000 は HAL3000 へのオマージュでもあり、AI に対する一種の恐れを含んでいました)。
第二に、実装上の問題です。私は GZK9000 を「伝統的なソフトウェアシステム」として開発していました。「LLM 向けソフトウェアシステム」としてではありません。
「LLM 向けソフトウェアシステム」とは何か?私が自分で考えた概念です。比較表を作ってみます。
| 次元 | 伝統的ソフトウェアシステム | LLM 向けソフトウェアシステム |
|---|---|---|
| 中核仮定 | 入出力は確定的 | 入出力は不確定的 |
| 実行方式 | フローを構成 | 動的に意思決定 |
| データとコードの境界 | データと制御信号は分離(データは実行されない) | データと制御信号が密接に結合(記憶が行動を形成) |
| 記憶機構 | 構造化・形式的(DBなど) | テキスト意味に基づく非形式・非構造(文書など) |
| 開発方法 | 論理で現実をマッピング(応用問題を解くように) | プロンプトの意味理解 + 論理(人間的手法) |
要するに:
伝統的ソフトウェアは「構造」を前提に世界を計算可能な形へ圧縮する。対して LLM 向けソフトウェアは人間の筆記のように、弱い構造で可能な限り世界の形をそのまま取り込み、必要箇所だけを局所的に構造化する。
開発面では、Agent の主要部分は llm.Chat のようなコードに大きく依存します。つまり、決定に必要な情報を LLM に渡し、その結果を受け取って次を判断する仕組みです。
しかし私の GZK9000 は、依然として伝統的なソフトウェア方式を使っていました。
Fact / Statement / Goal を区別するために、何枚ものテーブルと重複除去ロジックを書きました。しかしモデルは同じことを多様に表現するため、スキーマ設計と意味解析に多くの時間を費やすことになり、結果として記憶システムは柔軟性を失い、デバッグも困難になりました。
典型的な「定義を固めてからスキーマを作り、現実をその枠に押し込む」やり方です。
これは違います。LLM 向けソフトウェアシステムは新しいパラダイムであり、AI に対してはより少ない制約と、より多くの自由を与えるべきなのです。
今日はここまで。次回は「自由をどう与えるか」について書きます。