It all started when OpenClaw went viral. Recently, I developed another Agent called Mister Morph.
Why “another”? Because I had made one before, code-named GZK9000. I even bought the domain name for it:
挖新坑啦 pic.twitter.com/hQxNQJ28HR
— Lyric🌀 (@lyricwai) January 28, 2025
But it ended up unfinished.
This GZK9000, by today’s standards, was indeed an Agent. Here’s its architecture diagram:
+-------------------------------------------------------------------------------------------+
| gzk9000 Process |
| main -> cmd/root (load config + init DB) -> cmd/server (HTTP + workers) |
+-------------------------------------------------------------------------------------------+
| |
| Online Dialogue Loop (looper + telegram) | Reflective Loop (goalfinder/overthinker)
v v
[Collect Input] Telegram message --> LoopService --> AI reply --> Telegram response
|
v
[Structure Facts] assistant.RecognizeFacts + DetectSentiment
|
v
FactService.CreateFact
| |
v v
PostgreSQL (facts) Qdrant (vectors)
|
v
[Memory Layer] memslices (for later recall)
|
+-------------------------------> [Recall Context] last 24h memslices + facts
|
v
[Find New Goals] extract + dedupe + compare goals
|
v
PostgreSQL (studygoals)
|
v
Guide next questions/thoughts for next input round
|
+----------------------> back to [Collect Input]
Its core loop was designed as follows:
- Collect information:
looperreads messages from Telegram and produces replies. - Structure facts:
loopercallsRecognizeFacts/DetectSentimentto structure the input. - Store facts:
fact.CreateFactwrites to both the database and the Qdrant vector index. - Find new goals:
goalfinderextracts candidate goals from recent memory slices and facts, deduplicates them against existing goals, and writes them intostudygoals. - Iterate repeatedly: New goals influence upcoming conversations and information collection, forming a closed loop of “collect info → structure facts → find new goals → collect again.”
Looking back, the reason this project failed was that I took a wrong technical approach. I’ll go into that later.
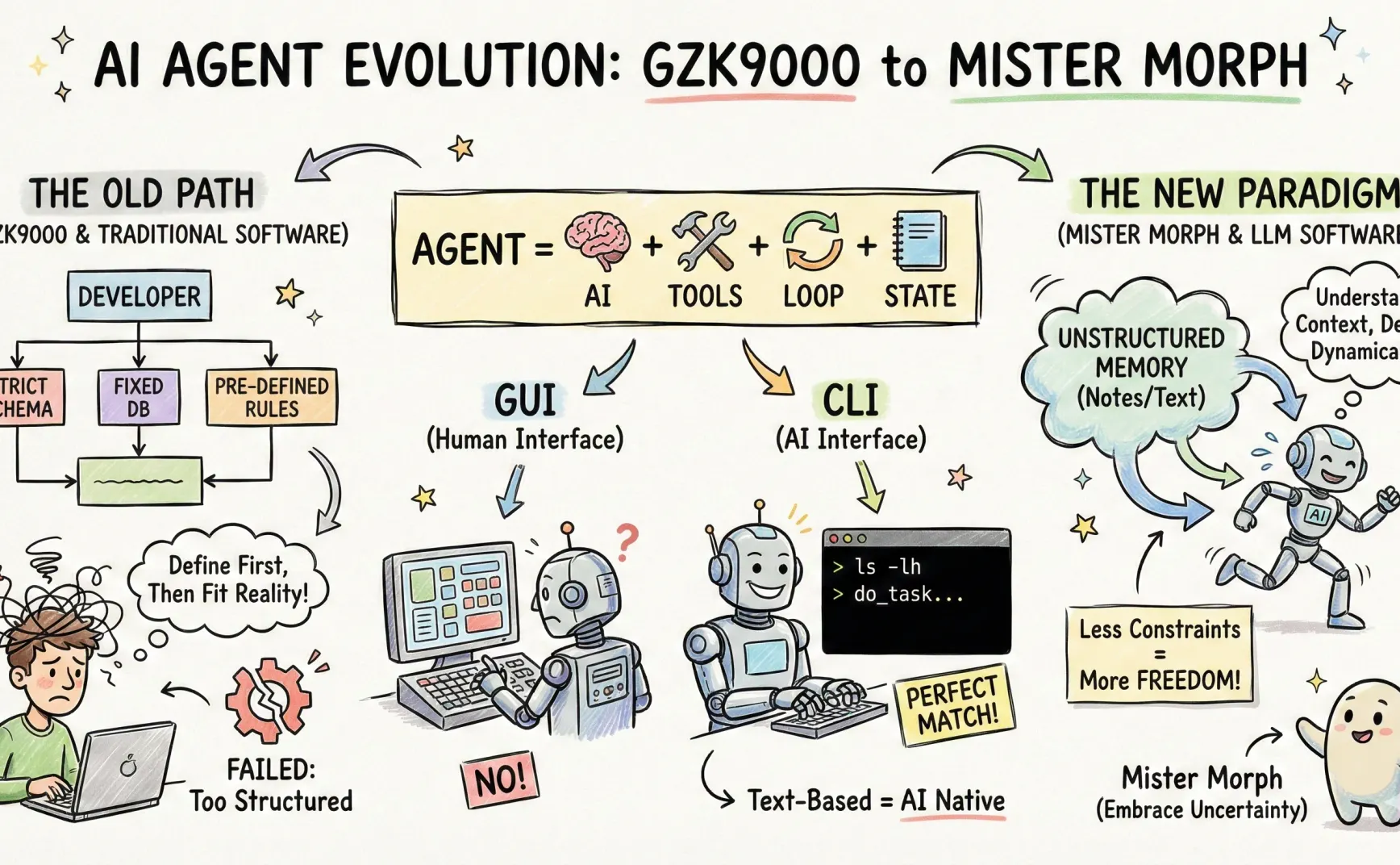
What is an Agent
A client once asked me why we can’t test model capabilities using web versions (like chatgpt.com or grok.com), but must use the API instead.
I said the web versions of ChatGPT and Grok aren’t raw models — they’re already agentic, lightweight agents with abilities base models don’t have. If you input list your tools in the web versions, both ChatGPT and Grok will list their tools (e.g., search, calculator, code execution, etc.). They also have strategies for when to use what tool, how to retry on failure, and how to write results back to context.
The API, on the other hand, is closer to a “bare model”: it gives you a reasoning engine, but you have to implement tool connections, loops, and state management yourself. So if the goal is to compare reasoning and language ability, the web interface mixes in too many variables. The API version is more controllable and closer to the real-world engineering challenges you’ll face.
From this perspective, for a system to appear agentic (i.e., capable of self-directed task progression), it usually needs several extra abilities:
- Tools: To turn “thoughts” into “actions.” Without tools, the model can only output text — it can’t truly gather new information or affect the external world.
- Loops: To repeatedly “plan → act → observe → adjust” under incomplete information. Single-turn Q&A rarely reaches perfection; loops let it continuously approach usable solutions.
- State: To store results of past loops for reuse. State can include memory, notes, task progress, or records of environment changes. Without it, loops can’t accumulate progress — they just spin in place.
So, if I had to give a minimal definition, it would be:
Agent = Model + Tools + Loops + State
The model handles understanding and decision-making, the tools take action, the loop iteratively refines solutions, and the state preserves what’s learned for the next round. Only then can it keep pushing forward amid noise and uncertainty, rather than giving one-off polished answers.
Why We Need Agents
I think there are two main reasons:
1. One-shot interactions can’t get the job done
Because context is incomplete, single-turn Q&A rarely yields perfect results. The Agent’s way of working naturally extends context.
Tools can fetch more relevant information — for example, web_search can pull additional background knowledge. Memory allows the Agent to remember prior conversations or task details. The loop mechanism lets the Agent repeatedly think and ask questions.
Humans work in much the same way. The brain and sensory system have limited buffers — we can’t ingest and process everything at once, so we work in slices over time. In practice:
a) we ask questions repeatedly to gather missing info;
b) we take notes;
c) our brains “ruminate” during downtime, etc.
2. Tools act as the AI’s hands and feet
After thinking comes action. Calling tools is how AI acts on its decisions.
Humans do the same. We invented “computers” not as brains but as tools — to write, code, analyze financial reports, manage inventory, and so on. The computer is a human tool.
Naturally, people thought about giving that “computer” tool to AI. OpenAI’s ChatGPT Apps tried integrating websites and tools directly into ChatGPT; Manus allows AI to operate browsers and apps on a computer.
Why OpenClaw (aka Why Manus/ChatGPT Apps Don’t Work)
Current app platforms and their interfaces are designed for humans — they fit human attention and habits but not AI’s.
Reinventing a full interaction system for AI is too hard, and there’s no existing ecosystem.
ChatGPT Apps tried to rebuild an ecosystem, Manus tried to simulate humans — both are difficult.
So what do we do? Let’s look at existing interaction systems that already suit AI and have rich ecosystems. The answer is the CLI. That’s why OpenClaw chose the CLI.
For readers without a computer science background, let me explain briefly:
Most users interact with computers or smartphones through graphical interfaces — clicking buttons, entering text, etc.
But in the early days of computing, before graphic interfaces existed, all operations were done through commands. For example:
ls lists files in the current folder;
date displays the current time.
Each command also has many parameters to adjust behavior — e.g., ls -lh shows detailed info, where -lh means “show in detailed format.”
Since there are no images, both input and output are pure text.
Okay, lecture over.
You see, CLI interaction is command-based. Each command has a clear semantic input and a clear output. The flow of information is two-dimensional and text-based — a perfect match for LLMs, which also operate through text.
In short, CLI predates graphical interfaces, has a complete ecosystem (you can do almost anything in an OS using commands), and its text-based nature suits LLMs extremely well. Once OpenClaw adopted it, it felt like breaking a seal — leaving ChatGPT Apps and Manus in the dust.
Why GZK9000 Failed
Two reasons:
First, positioning. I originally designed GZK9000 as a boxed-in thinking machine, not giving it hands or feet (you can tell from the name — a nod to HAL 3000 and that underlying fear of AI).
Second, how it was built. I developed GZK9000 like traditional software, not software designed for LLMs.
What do I mean by “software designed for LLMs”? It’s a concept I came up with. Here’s a quick comparison:
| Dimension | Traditional Software | LLM-Oriented Software |
|---|---|---|
| Core Assumption | Deterministic input/output | Input/output are uncertain |
| Execution | Orchestrated workflow | Dynamic decisions |
| Data vs. Code Boundary | Data and control signals are separate | Data and control are tightly coupled (memory shapes behavior) |
| Memory | Formal, structured (e.g., databases) | Semantic, textual, generalized, unstructured |
| Development Method | Logical modeling of real-world problems (like solving applied math) | Prompt-based semantic understanding + logic (like a human) |
In short:
Traditional software front-loads structure, compressing the world into computable form; LLM-oriented software is more like human note-taking — loosely structured, preserving raw reality, and structuring only where automation is needed.
In practice, agent logic heavily depends on code like llm.Chat: passing the model information for decisions and receiving decision outcomes from it.
But I developed GZK9000 using a traditional mindset.
For example, to distinguish Facts/Statements/Goals, I created multiple tables and deduplication logic. But since the model naturally varies how it expresses the same concept, I spent most of my time debating schema design and semantic parsing instead of simply storing the world’s information first. In the end, the memory system was rigid and hard to debug.
Classic move — define everything first, build tables, fix schemas, and then try to squeeze reality into them.
That approach was wrong. LLM-oriented software is a new paradigm — one that should give AI fewer constraints and more freedom.
That’s all for today. Next time, I’ll write about how to actually give it that freedom.