In the previous article, I mentioned that “software systems oriented toward LLMs represent a new paradigm that requires giving AI fewer constraints and more freedom,” and left a hint: “Next time, I’ll discuss how to actually give that freedom.”
Before getting to that, let’s ask a question: why are we instinctively inclined to impose constraints on an Agent?
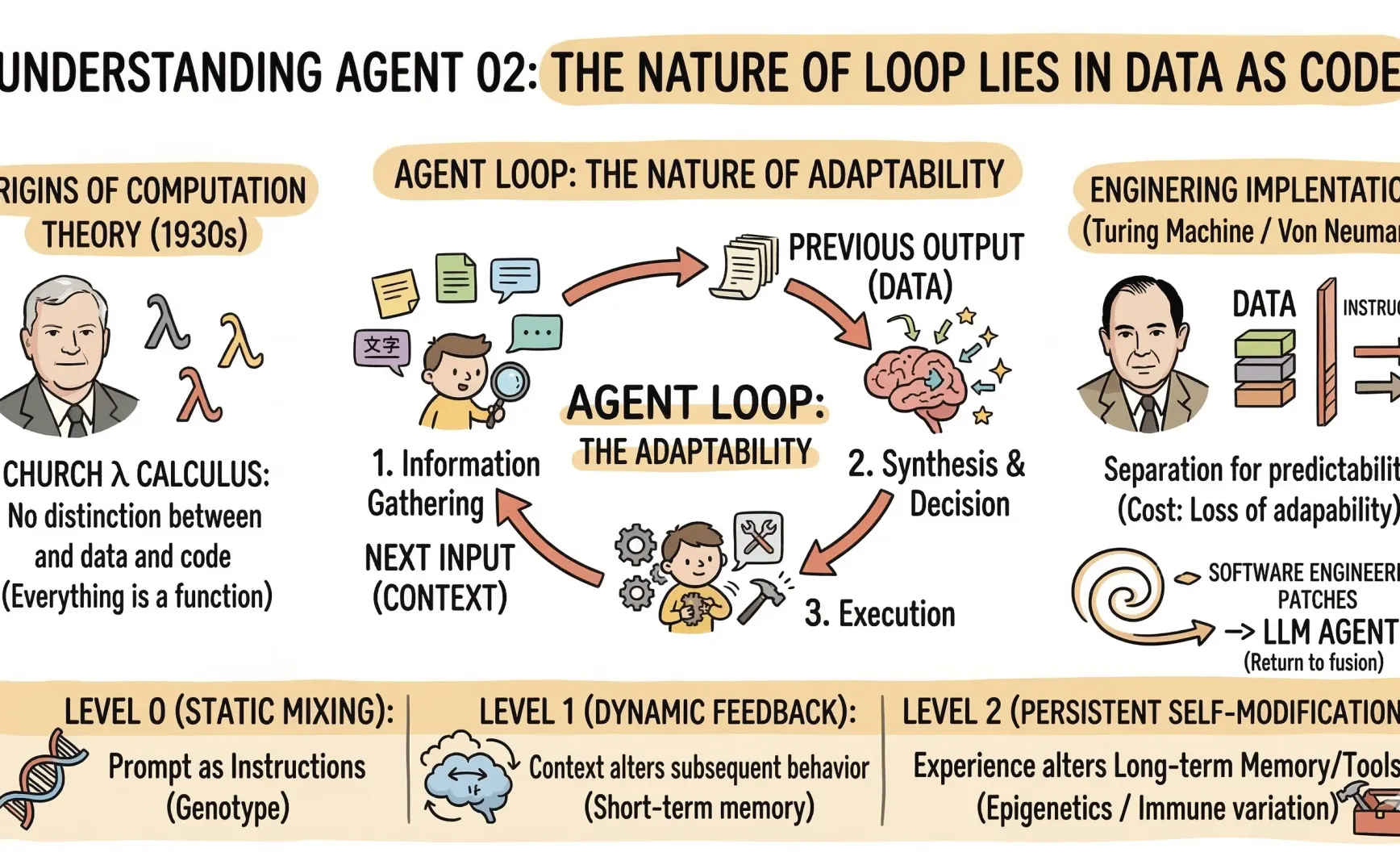
To answer that, we first need to understand one thing: in the world of Agents, the boundary between data and code is dissolving.
Starting with a loop
In the previous piece, I mentioned that the core loop of an Agent roughly works like this: gather information → organize → decide → execute → gather again.
In code, this translates to a single llm.Chat call: you pass in a prompt and get a response. Then, in the next round, you append the previous response to the new prompt and feed it back again.
Sounds simple, right? But there’s something quite unusual here:
The output from the last round (data) directly becomes an input condition for the next round (part of the control flow).
In traditional software development, that’s a big no-no.
Where does that tradition come from?
Back to the origins of computing?
If we return to the roots of computation theory, two paths appeared almost simultaneously in the 1930s:
Church’s λ-calculus and Turing’s machine
In Church’s λ-calculus, there is no distinction between “data” and “code” (see my earlier article Church numerals and Lambda calculus). A function is a value, and a value is a function.
A Church numeral is itself a function; Booleans are functions; conditionals are functions. Everything is a λ-expression—everything can be applied (as code) and passed along (as data). The fusion of data and code isn’t a new paradigm—it’s the origin of computation theory.
Separation came later. The Turing machine separated “symbols on tape” from “state transition rules.” The Von Neumann architecture made that separation concrete in hardware design. Although instructions and data share memory, they are treated differently in logic.
We later adopted the Von Neumann architecture not because it was more correct, but because it was more predictable. When writing a program, we need to understand what it does. The separation of data and code exists so humans can comprehend and control systems—it stems from a primal fear of the inexplicable.
Thus, the entire modern software security model is built on the consensus that “data should not become part of the control flow.”
DEP, NX bit, sandbox—all exist to enforce that consensus.
The cost? A loss of adaptability.
Programs cannot modify their own logic based on runtime results. Self-modifying code? In modern systems, that’s a security vulnerability, not a feature.
So over the decades, software engineering invented various patches to compensate for this “defect”: strongly typed languages, version control, iterative models, A/B testing—all of them simulate, under the constraint that “data cannot become code,” the effect of data influencing behavior, but in a clumsy and controlled way.
The real narrative, then, is a spiral:
Starting point of computation: λ-calculus → data and code are not separate
↓
Engineering realization: Turing machine / Von Neumann → separation introduced for predictability
↓
Software engineering → adding patches to simulate fusion
↓
LLM Agent → returning to fusion
Loop: the system rewriting its own input using its output
In every iteration, the Agent rewrites its input conditions using its own output. This is essentially self-modifying code—except it modifies semantic context rather than binary code.
This self-reference is intrinsic in λ-calculus—Y combinator is precisely the mechanism that lets a function “call itself,” purely through λ-expressions, without any external machinery.
The self-bootstrap of an LLM Agent is, in a sense, a semantic reincarnation of the Y combinator. Through looping, the system continually feeds its output back into itself to generate new behaviors.
Viewed in layers, it roughly breaks down into three levels:
Level 0: Static fusion. The system prompt itself is “code in data form.” The text you write is both literal data and an instruction telling the model what to do. This is the shallowest level—almost all LLM applications operate here.
Level 1: Dynamic feedback. The Agent’s output is appended back into the context window, changing subsequent behavior. Memory, tool results, chain-of-thought all belong here. Key feature: short-term reversibility—the context window has size limits, and older parts are truncated.
Level 2: Persistent self-modification. The Agent writes experiences into long-term memory, modifies its prompt templates, even changes its tool code. This is genuine self-evolution. Key feature: irreversible or difficult to roll back; the effects may emerge many rounds later.

From a biological perspective, the fusion of data and code is the norm.
DNA is a blueprint, yet transcription factors—proteins encoded by genes—regulate how that blueprint is read. That’s Level 1.
Epigenetics is even more interesting: without changing the DNA sequence, chemical markers alter gene expression patterns—like changing memory without touching the system prompt. That’s Level 2.
The immune system goes further, cutting and recombining gene fragments to produce new antibodies—an extreme form of Level 2. To adapt to unknown pathogens, the system actively modifies its own code.
So perhaps the essence of the Agent loop isn’t software imitating biology, but this: once a system becomes complex enough to need adaptation, the fusion of data and control flow becomes inevitable.
Historically, the Von Neumann story of separating code and data may have been an engineering simplification, not a natural law. Both λ-calculus and biology understood this from the beginning…
A new narrative and shifting perspectives
In biology, a genome has two types of regions:
- Highly conserved regions: core metabolic pathways that haven’t changed for billions of years—mutations here are lethal and leave no descendants.
- Highly mutable regions: such as variable regions in immunoglobulins—these are encouraged to mutate and recombine, potentially improving adaptability.
The Agent’s architecture should resemble that:
- Conserved zone: core invariants, principles, safety boundaries—hard to modify.
- Variable zone: free-evolving areas—behavior strategies, knowledge memory, tool preferences—encouraged to modify.
This answers the first half of “how to give freedom.” It’s not a question of whether to give it, but where to give it.
For software development, this means
The conserved zone is gradually shrinking, while the variable zone is expanding.
- At first, everything was conserved. Waterfall models, strong typing, complete upfront design. Code shouldn’t change after writing—effective, but only for fully predictable demands.
- Over the past twenty years, the variable zone appeared—but was tightly isolated. We had databases, dependency injection, A/B testing. Code and data could interact, but only through explicit interfaces. You could change configurations without recompiling; configs could alter behavior but not code.
- Now, boundaries are dissolving. An Agent’s prompt is both data and code. Tool-calling results directly determine what to execute next. An Agent can write code, execute it, and adjust strategy based on the outcome.
Freedom isn’t the opposite of constraint; it exists only within proper boundaries
Initially, we pursued an immutable ideal form: a perfect structure where real-world demands were mere projections. Traditional software development followed that mindset—we’d define schemas, interfaces, type systems first, and let runtime data fit those fixed structures.
Existentialism flipped that relationship: existence precedes essence. Often, action defines identity, not the other way around. Biological organisms—and humans—are existential by nature, and pure Agent loops are too. They have very few truly predefined modes; most of their definition emerges through interaction with the environment.
But pure existentialism is disastrous in engineering—such systems are impossible to debug or trust.
Thus, just as we need some priors—structures and principles resistant to experience overwriting—Agents need a set of core constraints that are hard to change, so free evolution doesn’t become random drift.
You could say LLMs or Agents are kinds of “language games.” Meaning doesn’t reside in words themselves but in the rules and contexts of use. That’s also how LLMs inherently work—tokens have no intrinsic semantics; their meaning is defined by relationships within context.
So relationships can be explored, meaning can be created—there isn’t hard-coded control flow, only collapsing and recombining semantic states. As described in What Is It Like to Create a World, I think that’s precisely the part that fascinates me most about Agents and LLMs.
That’s all for now
But this framework is still static—how does an Agent handle such fusion at runtime?
After all, defining the boundaries of the variable zone is one thing; ensuring the system respects them in operation is another.
By the way, the link to join the group chat shown above is:
https://t.me/+tP06DqgNMnlmMTc1