其他动态 ✦
- 华尔街日报给Open AI上眼药,在O3发布后发了一篇爆料说GPT-5连续多次训练失败。
- Krea 这个局部重绘功能的演示真的吸引人,用他们的 Lora 训练功能加局部重绘就能让产品穿在模特身上,能把 FLUX 的 Fill 模型和 Lora 训练结合成这样的产品真的很强。
- 可灵 1.6 发布了,一跃成为现在可以用到的最好的图生视频模型,这里是我的测试。
- Runway 更新了,现在除了首尾帧之外还支持插入中间帧控制视频生成。
- Perplexity 收购了 Carbon,一个将外部数据源连接到大型语言模型的检索引擎,他们将利用这个公司的技术为 Perplexity 增加将 Notion 和Google Doc 这种外部数据链接到 Perplexity 的能力。
- ElevenLabs 发布 Flash 模型,可以在75毫秒内生成语言,甚至算上了应用处理和网络延迟的时间。Flash v2 仅支持英文,Flash v2.5 支持 32 种语言。
- 微软也是急了,GitHub Copilot 可以免费使用,不过仅限于免费模式。
- 有人给混元视频模型搞了一个加速模型,现在只需要 6 步推理就能生成视频,与原始的 50 步相比可以节省 8 倍生成时间。
- Pixverse 推出了 V2V 视频延长功能,可以用提示控制延长的视频,另外3.5版本的模型也开始测试质量很高。
- 谷歌会在 Gemini 里面增加一个图片编辑功能,支持局部重绘、扩图等常见图片编辑操作,估计会跟 1 月份 Gemini 2 的原生图片生成一起上线。
- 英伟达发布针对个人的小型 AI 开发套件 Jetson Orin Nano Super,性能提升 70% 至 67 INT8 TOPS,内存带宽提升 50% 至 102GB/s,而且价格只需要 249 美元,跟 4060 差不多的价格。
- Midjourney推出Moodboards功能,支持批量上传图片提取风格代码。
- Comfyui 现在有官方的中文翻译功能,解决了以前插件翻译的很多问题,可以更新到最新版开启,卸掉以前的翻译了。
- Meta 将于明年在 Instagram 上引入人工智能视频编辑功能,由其 Movie Gen 模型提供支持。用户可以使用简单的文本命令调整服装、背景等。
- Perplexity AI 在一轮融资中筹集了 5 亿美元,短短六个月内其估值增加两倍,达到 90 亿美元。
- Meta 为其 Ray-Ban 智能眼镜引入了新功能,现在提供实时人工智能交互、实时语音翻译(英语、西班牙语、法语、意大利语)和 Shazam 支持的音乐识别。
AI艺术
- Metaverse | Eric 用Veo 2做了一个非常好的科幻短片,除了清晰度之外很多镜头都是可用的
- 海辛做的宝可梦加世界著名地标搞怪视频很强,已经是新的流量密码了。
- 谷歌 Veo 2 做的这个水墨动画效果也很好。
产品推荐 ✦
tldraw computer:无限画布AI计算机
tldraw computer,一台AI计算机,没有代码,只有自然语言和流程组件。支持流程分支、切换和循环,而且项目还能变成模版跟其他人共享。Andrej Karpathy 也给了很高评价。
可以想像成一个更简单更本质的Coze或者Dify,全是基础组件没有那么多复杂的交互,看你的想象力了。
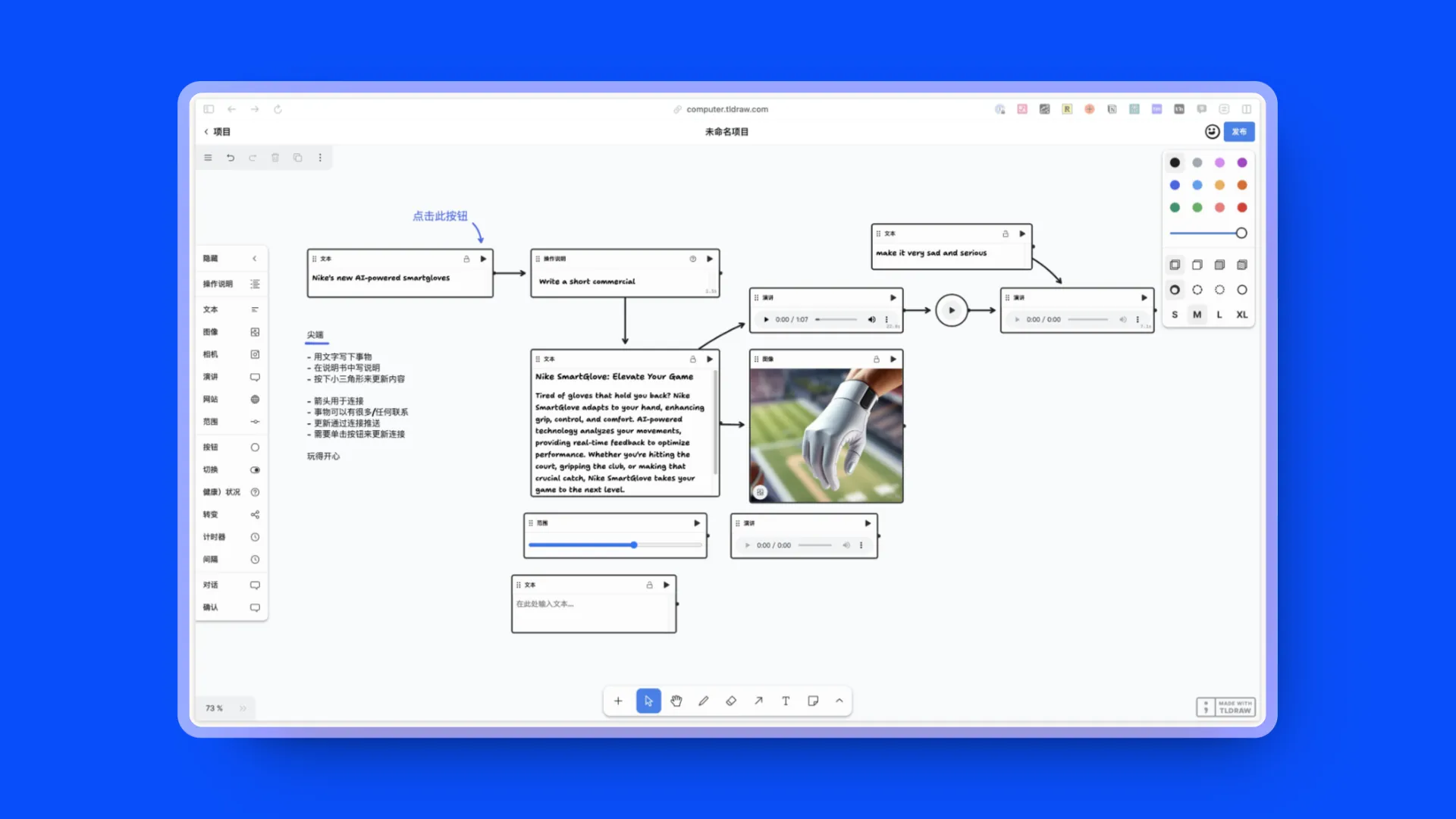
Tempo : React 可视化编辑器
其核心目标是加速 React 应用的开发过程,通过提供一个单一的真实源头让设计师和开发者协作变得更加高效。Tempo 允许用户将想法转化为功能性的 React 应用,通过拖放编辑器进行设计,感觉就像使用设计工具一样。用户可以通过视觉编辑代码、构建和维护设计系统,以及从 Storybook 导入自定义组件库来精细化设计细节。Tempo 能够与任何 React 代码库一起工作,支持本地编辑代码、使用 VSCode 和推送到 GitHub。
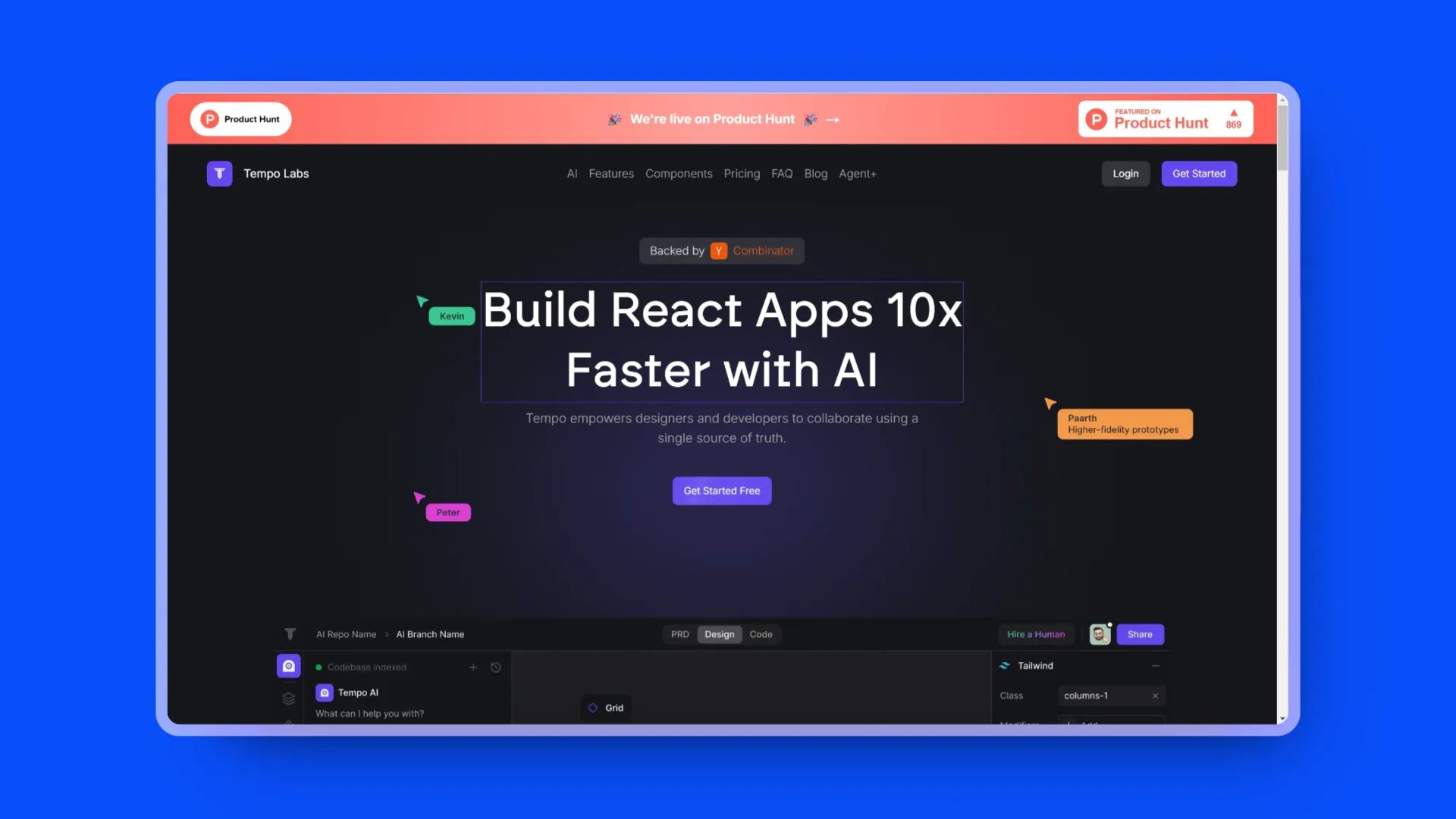
Animate AI:用于连贯视频动画生成的AI工具
AnimateAI 是视频生成器,专为儿童故事动画视频系列设计。它采用最先进的 AI 技术,提供吸引人的视频系列,并保持角色的一致性。AnimateAI 提供了一个全面的 AI 视频生成工作流程,包括角色生成、故事板生成和视频生成。用户可以选择或生成角色,AI 角色生成器能够根据故事创意生成定制的角色,并保证系列故事中的角色一致性。故事板生成器能够将剧本快速转换为详细的故事板,简化了制作过程。视频生成器则能够将文本提示转换为 30 秒的高质量视频。
MagicMail:AI 驱动的邮件排版工具
MagicMail 是一个利用人工智能技术帮助用户创作引人入胜的电子邮件、诚挚的问候语和邀请函的在线工具,很有意思,是不是能搞一个AI驱动的微信公众号排版工具,我愿意付费。
精选内容 ✦
Anthropic 核心创始人聊公司的现在过去和未来
Anthropic 几个核心创始人罕见的一起录了一个播客,详细介绍了他们如何认识然后产生共识最后迫不得已创建公司的事情。
Anthropic 公司创始人及高管的讨论记录,他们围绕 AI 技术的发展、安全问题、以及公司的使命和目标进行了深入的探讨。讨论开始时,参与者们分享了自己为何选择从事 AI 安全研究以及加入 Anthropic 的原因。他们强调了 AI 技术在未来可能带来的巨大影响,以及为了确保这些技术的安全性和可靠性所需的努力。
构建有效的代理
Anthropic 说 2025 年将是 Agentic 系统年,所以发了一个 Agents 综述的文章,介绍了他们构建 Agentic 系统的一些发现。非常适合入门看。
讨论了代理系统的构建,包括基本概念、何时以及如何使用代理系统,以及如何使用框架。文章分为两大部分:工作流程和代理。工作流程包括:简单的提示链(Prompt Chaining)、路由(Routing)、并行化(Parallelization)、编排者 - 工作者(Orchestrator-workers)以及评估者 - 优化者(Evaluator-optimizer)。
OpenAI's o3: 2024 年人工智能的压轴大戏
Nathan Lambert 撰写了一篇文章,介绍了 OpenAI 最新的 o3 模型,这个模型预计将在 2025 年 1 月底向公众开放。o3 模型继 o1 之后,展示了人工智能在推理和解决复杂问题方面的飞速进步。与 o1 相比,o3 在算术、编程和物理等领域的表现更是令人震惊。例如,o3 成为了首个在公开的 ARC AGI 挑战赛中超过 85% 准确率的模型,并在 Frontier Math 基准测试中的表现从 2% 提升到 25%。此外,o3 在编程领域的 SWE-Bench Verified 评分达到了 71.7%,几乎达到了人类国际大师级别的水平。
2025 年人工智能对各行业的影响 | 谷歌云博客
概述了生成式人工智能(gen AI)如何从未来的概念转变为当前业界的关键战略,并对其在零售、金融服务、卫生保健和媒体娱乐等行业中的实际应用和长期变革前景进行了深入分析。
- 生成式人工智能(gen AI)已经成为提升业务效率和顾客参与度的关键工具。
- 企业需要将 gen AI 策略与商业战略相结合,以确保 AI 投资的最大化回报。
- 不同行业正在探索和实施 gen AI 的具体使用案例,以推动行业内的增长和效率。
- 随着 gen AI 技术的发展,组织必须面对新的挑战,特别是在深度伪造防御方面。
- Google Cloud 致力于帮助组织导航其最艰难的挑战,并提供指导和框架来发展强大的 AI 战略。
a16z:一些AI大佬选择的2024年最佳AI应用
我们测试了数百款AI应用程序,涵盖从写歌、创建播客到自动化日常琐事等领域。回顾这一技术盛宴,哪些应用真正让人印象深刻?a16z消费者团队邀请了一些AI早期采用者分享他们最喜欢的产品。点击装饰品和礼物查看最终赢家!
Latent Space Windsurf创始人访谈
Varun Mohan 和 Anshul Ramachandran 分享了 Codeium 的最新进展,包括他们推出的企业级 AI IDE—Windsurf。他们回顾了 Codeium 从一个有 10,000 用户的小公司发展成为拥有 100 万用户的公司的过程,以及他们如何保持自动完成功能的免费特性。他们讨论了 Windsurf 的功展,以及它如何帮助开发者更高效地编写代码,特别是在多步骤编辑和多文件编辑方面。他们还强调了企业级集成的重要性,包括对不同版本控制系统的支持,以及他们如何通过自己的 IDE 实现代理编程工作流程。此外,他们探讨了企业销售策略,包括技术深度、部署工程和持续学习的重要性,以及他们如何通过自己的产品和基础设施的持续改进来适应市场的需求。
AI继续
主要探讨了 AI 技术的最新发展,特别是 OpenAI 在 AGI 实现上的努力,以及国内 AI 产业的走向和潜在的投资机会,同时提到了字节和 NV 链在 AI 领域的合作和端侧 AI 的发展前景。
自 o3 开始,OpenAI 正在努力证明其接近 AGI(人工通用智能)的程度,尽管存在成本和算法效率的挑战,但 AI 技术的进步不断,新算法的出现可能会继续消耗现有算力,而不是减少对硬件的需求。此外,OpenAI 可能会采取各种方法来证明其 AGI 的实现,以脱离微软的控制并重新谈判投资协议。
接着,文章提到国内 AI 产业正值兴起,尽管中美在顶尖人才密度上存在差距,但中国 AI 的发展速度快,且在推理和架构创新方面有望追赶。字节跳动的产业趋势线表明,AI 的应用和商业模式正在成功,这对国内 AI 的行情有积极影响。
重点研究 ✦
Genesis:用于机器人技术及其他领域的通用生成物理引擎
Genesis 这个项目具有生成 4D 动态物理世界的能力,但是很多人对项目提出了质疑,目前开源的不u分并没有生成能力,而且很多关键函数都空着。
- 可生成复杂的角色动画
- 支持生成和模拟多种机器人系统表现
- 能够生成丰富的场景环境
- 集成VLM代理,可创建4D动态世界
- 支持面部动画和情感过渡的生成
OpenAI:推理使语言模型更安全
OpenAI 引入了深思熟虑的对齐(Deliberative alignment)策略,这是一种训练范式,它直接向推理大型语言模型(LLMs)传授人工编写和可解释的安全规范的文本,并训练它们在回答之前对这些规范进行明确的推理。这种方法被用于对齐 OpenAI 的 O 系列模型,使得这些模型能够利用思维链(Chain-of-Thought, CoT)推理来处理用户提示,识别相关的内部政策文本,并起草更安全的响应。
FACTS Grounding: 评估大型语言模型真实性的新基准
DeepMind推出了一个名为FACTS Grounding的新基准测试系统,用于评估大语言模型(LLMs)的事实准确性和信息依据能力[1]。该基准包含1,719个示例,分为公开集(860个)和私有集(859个),涵盖金融、技术、零售、医疗和法律等多个领域的文档。评估过程采用Gemini 1.5 Pro、GPT-4和Claude 3.5 Sonnet三个前沿LLM作为评判,通过两个阶段进行:首先评估响应是否充分解答用户请求,然后判断回答是否完全基于提供的文档且没有产生幻觉[1]。这一基准测试的推出旨在推动行业在事实性和信息依据方面的进步,DeepMind还在Kaggle上设立了FACTS排行榜来追踪进展。
大概念模型: 句子表示空间中的语言建模
在本文中,我们提出了一种在显式的高层语义表示(我们称之为概念)上运作的架构尝试。概念是与语言和模态无关的,代表了流程中的高层次想法或行为。因此,我们构建了一个"大规模概念模型"。在这项研究中,作为可行性证明,我们假设一个概念对应一个句子,并使用现有的SONAR句子嵌入空间,该空间支持多达200种语言的文本和语音模态。
大规模概念模型被训练来在嵌入空间中执行自回归式的句子预测。我们探索了多种方法,即MSE回归、基于扩散的生成的变体,以及在量化SONAR空间中运行的模型。这些探索使用了16亿参数的模型和约1.3万亿词元的训练数据。随后,我们将其中一个架构扩展到70亿参数规模,使用了约2.7万亿词元的训练数据。
Ruyi-Mini-7B:开源视频模型
Ruyi-Mini-7B 是一个开源的图像到视频生成模型,它能够从一个输入图像生成后续的视频帧,分辨率范围从 360p 到 720p,支持多种长宽比,最长可以生成 5 秒的视频。该模型通过集成运动和摄像机控制功能,提供了更大的灵活性和创造性。Ruyi-Mini-7B 基于 EasyAnimate V4 模型架构,拥有约 71 亿个参数,包括因果 VAE 模块、扩散变换器模块和 CLIP 模型。
Sketch2Sound:声音控制模型
我们提出了Sketch2Sound,这是一个能够根据一组可解释的时变控制信号(响度、音色亮度和音高)以及文本提示来创建高质量声音的生成式音频模型。Sketch2Sound可以从声音模仿(即声音模仿或参考声音形状)合成任意声音。
Sketch2Sound可以在任何文本到音频的潜在扩散变换器(DiT)之上实现,仅需要4万步微调和每个控制对应一个线性层,这使其比现有的方法(如ControlNet)更加轻量化。为了从类似草图的声音模仿中进行合成,我们建议在训练期间对控制信号应用随机中值滤波,这使得Sketch2Sound能够使用具有灵活时间精确度级别的控制信号来进行提示。
我们展示了Sketch2Sound能够合成出符合声音模仿输入控制要点的声音,同时保持对输入文本提示的遵从性,并与仅文本基准相比保持相当的音频质量。Sketch2Sound使声音艺术家能够创作具有文本提示的语义灵活性,以及声音手势或声音模仿的表现力和精确性的声音。
Enhance-A-Video:视频生成增强
研究团队提出了一种新的视频增强方法,旨在通过维护帧间一致性和提高视觉质量来改善生成视频的质量。他们发现,通过可视化时间注意力模式,帧间的注意力权重明显低于对角线沿线的注意力权重,这可能导致帧间的不一致。为了解决这个问题,研究团队首次提出了调整时间注意力温度参数的方法,以增强跨帧相关性。他们设计了一个增强块作为并行分支,计算非对角元素的平均值作为跨帧强度(CFI),并通过增强的温度参数乘以 CFI 来增强时间注意力输出。
你可以在这里找到我:
| 即刻 | 推特 | Quail订阅 | 微信公众号:歸藏的AI工具箱 |邮箱:[email protected] | 微信号:op7418
也可以分享给更多的朋友,让大家都有机会了解这些内容,扫描下面右侧二维码加我好友,我拉你进会员交流群。