其他动态 ✦
- 可灵发布可图 1.5 图像生成模型,可灵 1.5 支持尾帧视频生成功能,对口型支持音色情感选择。
- Grok 的单独网页版应用和 APP已经在澳大利亚上线,UI 设计相当不错,还可以搜索推特内容。
- Hume 发布新的全功能文本和语音引擎 OCTAVE,基本支持 Open AI、Eleven和谷歌音频的大部分功能:根据简短的提示生成声音和个性,从短至 5 秒录音提取并克隆说话者的声音和个性,生成或采集的声音和个性可以用于实时互动,OCTAVE 可以生成多个角色的对话。
- XAI 这融资速度太离谱了,宣布完成了 60 亿美元的 C 轮融资,而且宣布 xAI 迄今为止最强大的模型 Grok 3 目前正在训练。
- Perplexity 推出了年终盘点,整理了科技、金融等八个领域中用户最关注的事情,比如科技领域搜索量最高的三个居然是可灵、Willow量子芯片和 ChatGPT 不能说出的那个名字。
- ComfyUI 官方支持了 8G 显存运行混元视频生成模型。
- 耐克这个广告用大量AI图控制和脑暴画面的方式,可能是现在大成本商业内容可以参考的,极大降低了分镜图绘制成本,用毫秒级别的控制来确保内容制作时候的准确性。
- Open AI 更改了组织结构,将盈利的部分剥离为了特拉华州的一个PBC公司。PBC公司要求利润不是唯一目标,查了一下这玩意其实没啥约束力。现在的结构是非盈利母公司持有这个PBC公司的股票然后PBC复责研发和产品,非盈利部分负责慈善和公益。
产品推荐 ✦
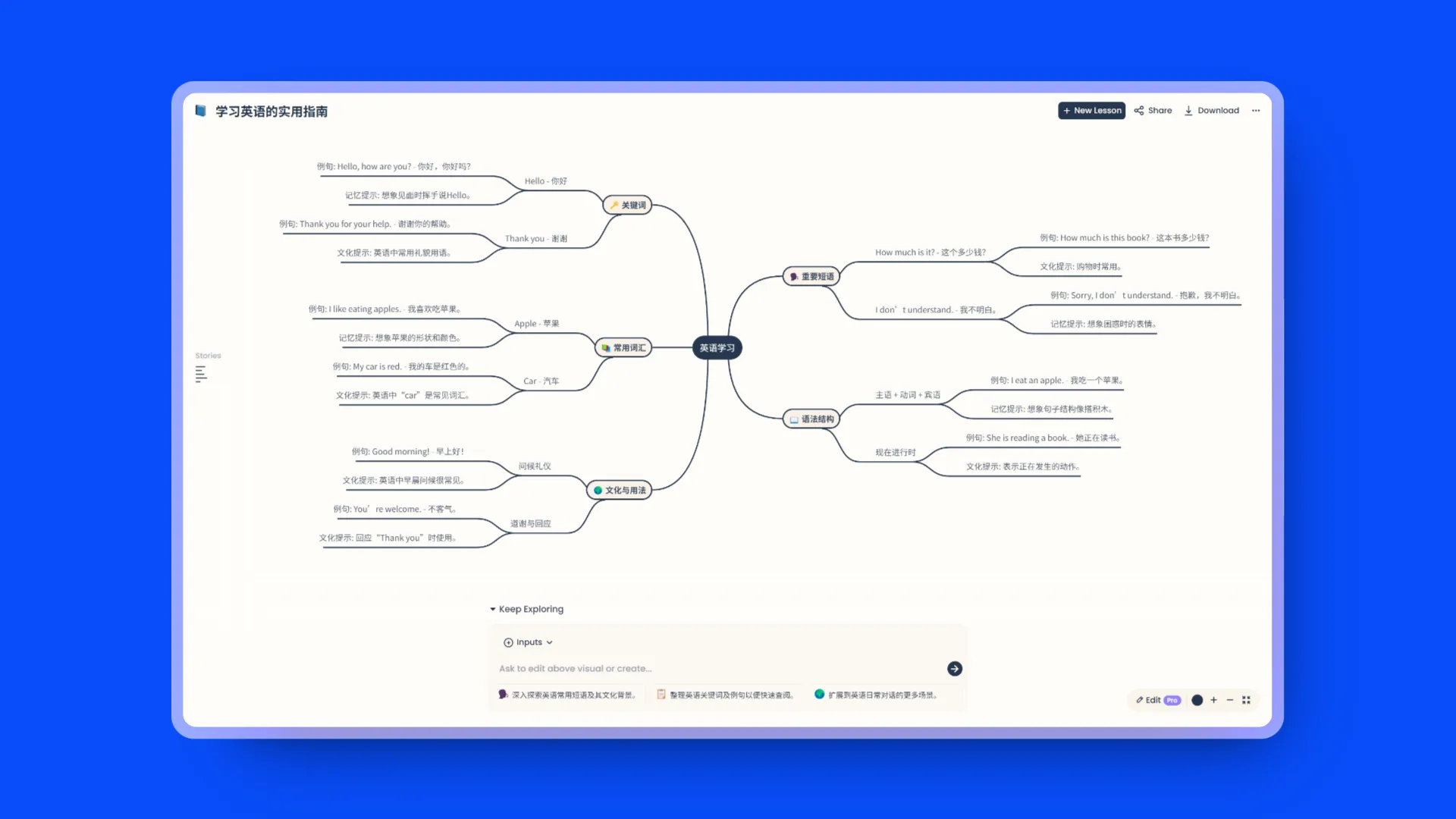
EasyLang AI:AI驱动结构化学外语
交互和结构非常好的一个产品,可以从你上传的文件或者你提出的问题中通过思维导图和表格列出所有相关单词,而且还会给出例句,你可以一个单词一个单词向下穿透获取的到所有相关单词和文化提示以及记忆提示。
精选内容 ✦
Exa CEO:AGI 前夜的思考
AI 搜索公司 Exa CEO 的年底长文,对 AGI 到来的前的一段时间社会变化做了一些预测。
首先受到严重影响的是数学家,然后是开发人员,每个开发人员都会变成技术主管,专门的前端开发可能会在三年内消失,之后是理论物理学。
2025 年人工智能工程阅读清单
Latent Space 关于 2025 年人工智能工程领域的阅读清单,列出了 50 篇关键的论文、模型、博客文章,涵盖了大型语言模型、基准测试、提示工程、检索增强生成、智能体、代码生成、视觉、语音、扩散模型和微调等十个领域的研究成果。
作者还提到了一些值得关注的荣誉提名,以及与基准测试紧密相关的数据集。此外,文章还建议了一些实用的学习资源,如 LlamaIndex、LangChain 等,以及对于代码生成和智能体领域的一些实践建议。
2025年会发生什么?来自Elad Gil、François Chollet、Maxime Labonne、swyx等人的预测
几个AI圈的创业者和研发对于2025年AI领域的预测:
- 更小、更紧凑的模型。训练的进步将重点放在用更少的冗余知识进行推理上。人们将开始感受到更小的模型如何有用,以及如何以更小、更有针对性的方式使用它们。具有成本效益,并且可能在设备上使用。
- 真正的多模式模型将会出现,让你可以在更长的时间范围内与视频进行交互和操作。
- 推理时间搜索将成为未来几年人工智能功能的主要驱动力。它将使人工智能变得更加有用,推动需求,同时使服务更加昂贵,增加成本(和价格)。
- 语言和多模态的进一步进步将导致沟通优于提示:据我们所知,提示正在消亡,取而代之的是对无缝沟通的新强调。正如人们曾经学会如何使用 Google 一样,到 2025 年,每个接触人工智能的人都会本能地知道如何通过文本、音频或图像与其进行交流。这种演变减少了对“提示工程师”的需求,并催生了人工智能经理和人工智能策展人等更广泛的角色。
人工智能代理谱系
文章《The AI Agent Spectrum》探讨了人工智能代理的概念及其在 2025 年可能的发展方向。
随着 AI 的发展趋势,2025 年代理将成为 AI 技术的试金石。AI 代理的最基本形式包括语言模型与搜索功能的结合,以及像苹果的 Siri Intelligence 这样的操作系统层。文章还提到,AI 代理的定义过于宽泛,大多数人通过强化学习的镜头来看待所有代理,但现在代理的概念已经超越了这一框架。AI 代理的复杂性从单一工具和语言模型到多工具集成,再到多语言模型组合,以及对模型调用的 while 或 for 循环等不断增加。未来的代理可能不再局限于单一计算机的概念。文章还提出了一个 AI 代理的分类系统,包括代理的运行时间、成功标准、信息处理方式以及与其他代理的交互等。
如何在 2025 年用Huggingface微调开源LLM
本文详细介绍了如何在 2025 年使用 Hugging Face 平台对开源大型语言模型(LLMs)进行微调。文章首先指出,随着 2024 年 LLMs 的发展,模型变得更小、更强大,且更加高效。尽管 LLMs 现在可以通过提示(prompting)处理多种任务,但对于需要高精度或领域专业知识的特定应用,微调仍然是提高结果质量、降低成本、保证特定用例可靠性和一致性的有力方法。
本指南与 2024 年的微调指南不同,更侧重于优化、分布式训练和可定制性,支持不同的参数高效微调(PEFT)方法,如全参数微调、QLoRA 和 Spectrum,以及使用 Flash Attention 或 Liger Kernels 进行更快、更高效的训练。此外,还介绍了如何使用 DeepSpeed 将训练扩展到多个 GPU。
重点研究 ✦
大概念模型: 句子表示空间中的语言建模
Meta 的重磅论文,提出了 LCM 大概念模型,现在 LLM 模型基本都基于 Token 操作,但是人类思考的时候都是基于句子或者概念的。tokenization 会导致 LLM 能回答博士级别的数学问题但无法回答 9.9 和 9.11 哪个大。
LCM 将"下一个词元预测"改变为"下一个概念预测"。一个"概念"被视为一个句子,代表一个抽象的想法或行为。他们用来测试的 7B LCM 模型在多语言零样本泛化性能方面表现出色,超过了同等规模的现有LLMs。
LuminaBrush :光线笔刷
敏神新作,LuminaBrush 光线笔刷,在 IC-Light V2 的基础上现在可以用不同颜色的画笔定义画面光线位置和颜色。
LuminaBrush 是一个用于在图像上绘制光照效果的交互式工具项目。该框架采用两阶段方法:
- 第一阶段将图像转换为"均匀照明"的外观
- 第二阶段根据用户的涂鸦生成光照效果
Byte Latent Transformer: Patches Scale Better Than Tokens
Meta的研究,这是一个新的字节级大语言模型架构。它首次在规模化应用中达到了基于分词的大语言模型的性能水平,同时在推理效率和鲁棒性方面取得了显著改进。BLT将字节编码成动态大小的数据块(patches),这些数据块作为计算的基本单位。数据块的分割基于下一个字节的熵值,在数据复杂度较高的地方分配更多的计算资源和模型容量。
我们首次展示了一项受控于FLOP的字节级模型扩展研究,模型规模达到80亿参数,训练数据量达到4万亿字节。我们的研究结果表明,在没有固定词表的情况下,直接用原始字节训练可扩展模型是可行的。由于能够在数据可预测性高的情况下动态选择较长的数据块,模型在训练和推理效率上都得到了提升,同时在推理能力和长尾泛化方面也有质的提升。
VidTok:微软开源的视频分割器
microsoft/VidTok 是一个开源项目,提供了一系列的视频分割器,这些分割器在连续和离散的视频编码方面都有显著的性能优势。
VidTok 采用了高效的架构设计,通过分离空间和时间采样来降低计算复杂度,同时保持高质量的视频编码。它引入了有限标量量化(FSQ)来解决离散视频编码中的训练不稳定和编码书籍崩溃的问题。此外,VidTok 采用了两阶段的训练策略,即先在低分辨率视频上进行预训练,再在高分辨率视频上进行微调,以提高训练效率。
这种策略还包括降低帧率以改善运动动态的表示。VidTok 在大规模视频数据集上的训练使其在所有指标上超过了之前的模型,包括 PSNR、SSIM、LPIPS 和 FVD。
CogAgent:智谱开源的 GUI Agents 模型
CogAgent-9B-20241220 模型基于 GLM-4V-9B 双语开源VLM基座模型。通过数据的采集与优化、多阶段训练与策略改进等方法,CogAgent-9B-20241220 在GUI感知、推理预测准确性、动作空间完善性、任务的普适和泛化性上得到了大幅提升,能够接受中英文双语的屏幕截图和语言交互。此版CogAgent模型已被应用于智谱AI的 GLM-PC产品 。
你可以在这里找到我:
| 即刻 | 推特 | Quail订阅 | 微信公众号:歸藏的AI工具箱 |邮箱:[email protected] | 微信号:op7418
也可以分享给更多的朋友,让大家都有机会了解这些内容,扫描下面右侧二维码加我好友,我拉你进会员交流群。