其他动态 ✦
- Runway 发布自定义镜头控制,支持非常详细的镜头方向控制,而且 UI 和交互设计也有意思,如果你也在做类似产品可以试试。
- Huggingface 发布了 SmolLM2 系列模型,提供三种大小:135M、360M 和 1.7B 。预训练模型得分比 Llama 高很多,训练过程和数据集也会开源。
- Heygen 现在支持直接输入提示词生成指定长相的虚拟人,不需要自己拍视频上传训练了。
- Claude 3.5 Sonnet 可以查看PDF里面的图片了,能够理解文档里面的复杂图表或者示意图。
- 现在 Google AI Studio 和 Gemini API 支持直接返回 AI 搜索结果。除了更准确的响应之外,该模型还返回内联支持链接和搜索建议。
- Claude上线了桌面客户端,Mac和Windows都支持。
- 字节搞了个图像模型站点叫 炉米Lumi,炉米Lumi 会为用户提供模型上传分享、Workflow 搭建、LoRA 训练等多种服务。
- Wonder Dynamics 发布视频转3D功能,将真实视频转换为 3D 场景。并在一个 3D 空间内包含所有摄像机设置、角色身体和面部动画以及所有元素均可编辑。场景和人物都是选择已有的,但是依然很厉害,我的测试。
- 现在 Mac 和 Windows ChatGPT 客户端都支持高级语音了。
- SD 3.5 Medium (2.6B) 模型发布了。相较于8B的模型这个更适合消费级设备,模型本体只有5G,FP8的话感觉12G显存的设备也可以跑。
- PixVerse V3 视频模型发布,V3 的的视频清晰度提示词理解都非常强。还有类似 Pika 的视频特效和画面风格选择,马上万圣节了,流量爆品朋友们。另外他们也有现在最强的唇形同步功能。
- 在 Meta 的第三季度财报会议上扎克伯格宣布,Meta将与美国各政府机构合作,探索将Llama整合到公共部门应用程序中,以支持政府举措并应对社会挑战。
- OpenAI 正在与博通和台积电合作开发首款用于处理大型人工智能工作负载的内部芯片,生产可能于 2026 年开始。
- 截至 2024 年 8 月,OpenAI 的年化收入约为 3.6B 美元,高于 2023 年的 1.6B 美元。Anthropic 的收入预计到年底将达到 10 亿美元,较 1 亿美元增长 900%。
- Suno 更新 Personas 功能,可让保存歌曲的精髓 - 人声、风格、氛围 ,图片里面的IPA或者单图Lora。
图像及视频作品推荐✦
- 将视频拆分为各个层级,有点帅的这个 Demo。
- Midjourney 的图片编辑加上 C4D 渲染的 Framer LOGO。
- 两个同事计划午餐约会的短片。太精致了,这个 Act-One 用的非常完美,适当添加的噪点也提高了视频真实度。
- Nicolas 这段 AI 视频素材混剪太牛了。没有剧情,没有主题,没有配音,但是就是看的停不下来。
产品推荐 ✦
Screenshot to Figma:截图转换为可编辑的 Figma 设计稿
Codia AI推出了一款名为“Screenshot to Figma”的插件,旨在简化设计过程。该插件允许用户通过一键上传截图,将其快速转换为可编辑的Figma UI设计。看了一个演示效果非常好,付费的话截图里的图标还会给你转成矢量的 SVG。
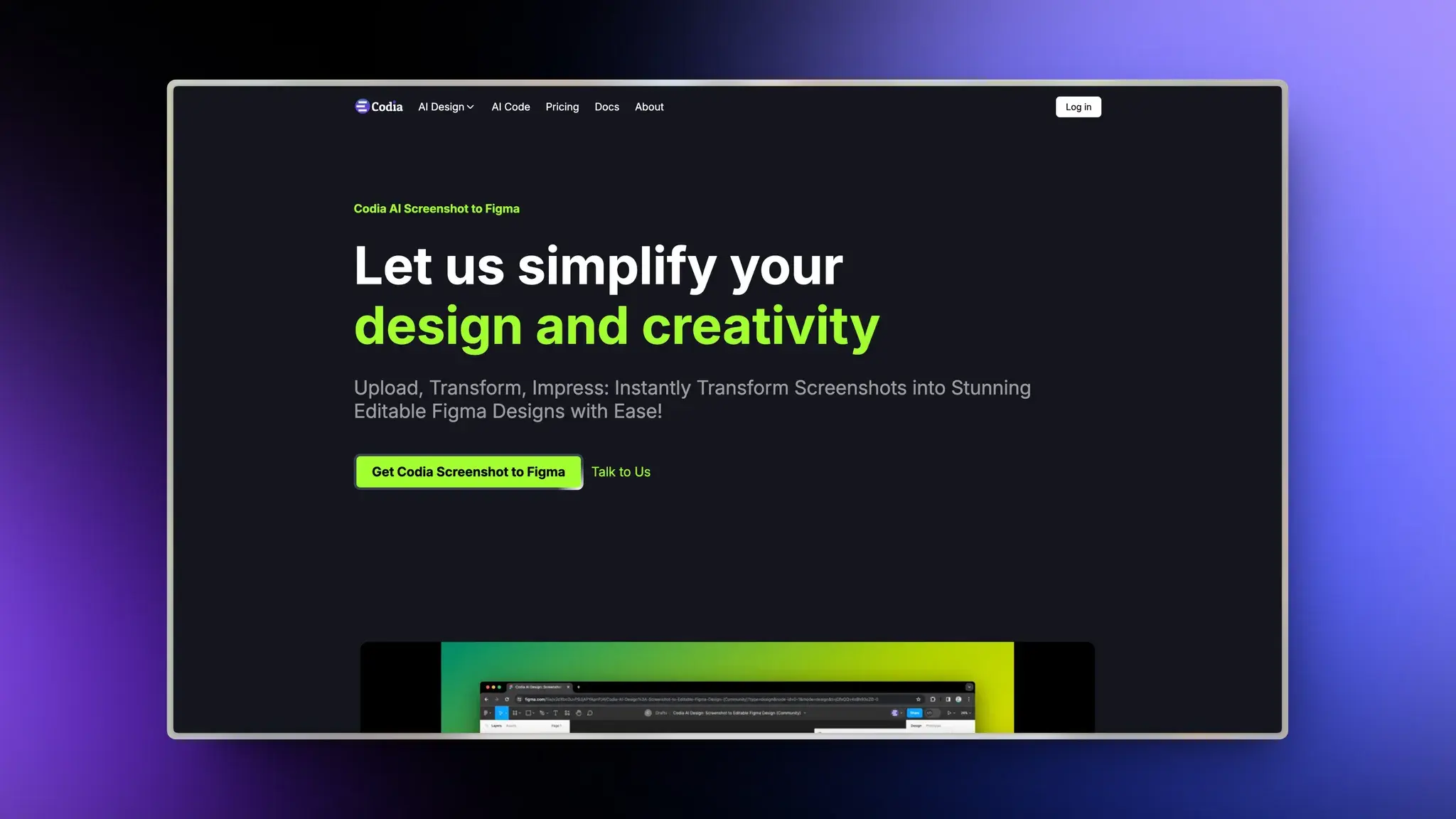
Learn About:谷歌的AI 学习工具
谷歌除了 NotebookLM 之外又发布了一个新的学习工具。
Learn About 可以根据你提出的问题给出详细的解释,而且还会推荐合适的视频教程以及文字教程。
他还会询问你教程的难易程度,如果觉得太难就会给你制定更简单的学习计划。
这个工具更像一个真的老师在做的事情,讲解问题,介绍读物、询问难易度进行调整,出测试题测试水平。
Recraft:强力图片生成模型加持的设计工具
前几天在 Artificial Analysis 排第一的 Red_Panda 模型终于发布了。原来是一家英国公司 Recraft 训练的 Recraft V3。
这个模型的文本处理能力真的很强,非常适合用来直接生成营销内容。是世界上唯一可以生成带有超长文本(而不是只有一个或几个单词)的图像的模型。
重要的是这个平台的其他图片编辑功能也很强,配合模型如虎添翼。你可以将生成的图片导出为矢量图,还支持抠图调整颜色等操作。
屏幕截图到代码
可使用 AI 将屏幕截图、模型和 Figma 设计转换为干净、实用的代码。现在支持 Claude Sonnet 3.5 和 GPT-4O,还原度相当离谱。
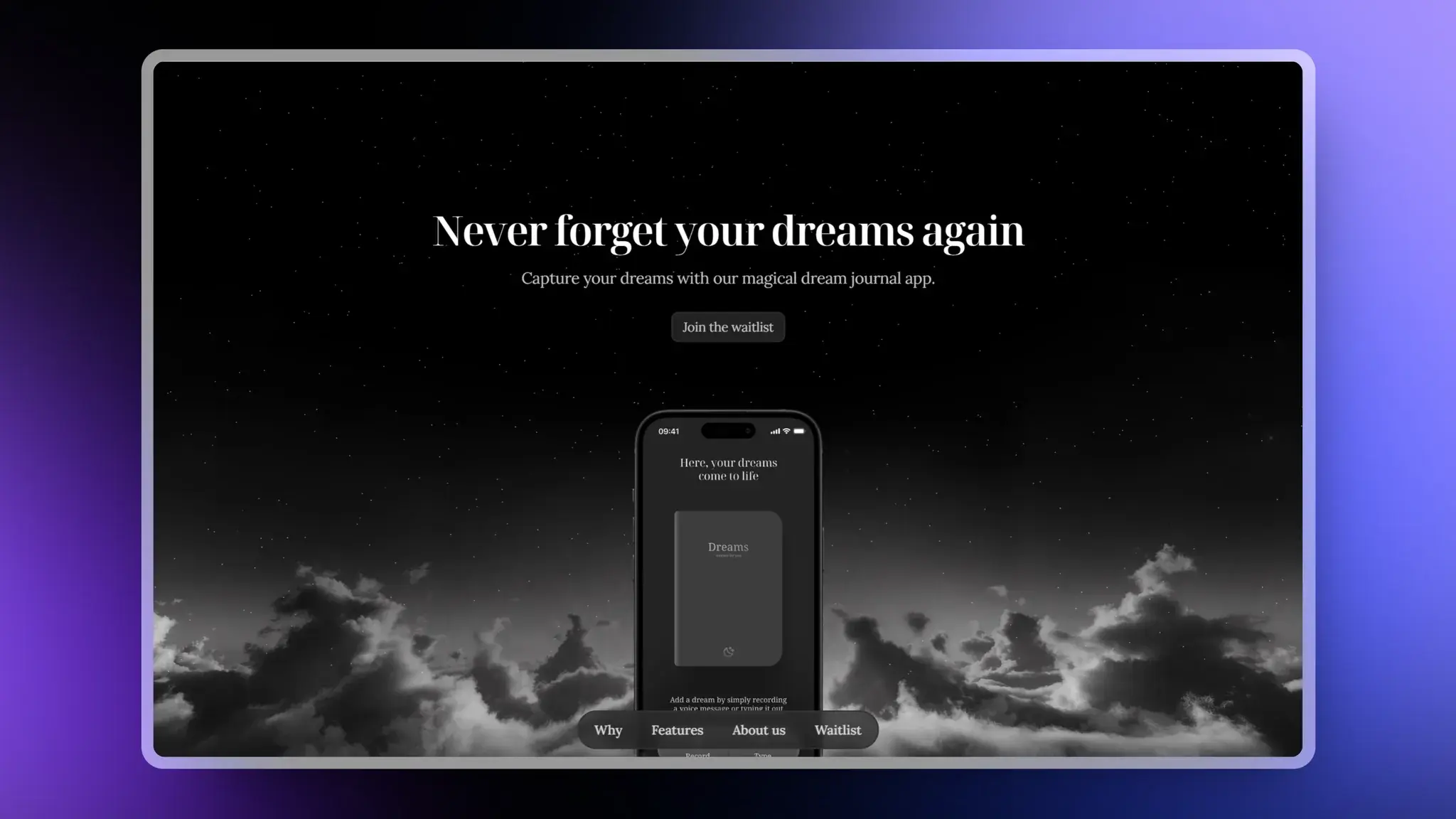
Yume:设计非常精美的AI笔记工具
Yume 提供了多种功能来帮助用户捕捉和保存他们的笔记。用户可以通过语音记录或打字的方式添加笔记,并且可以随时回读或听自己以前的记录。应用程序设计简洁,以黑白为主,易于使用,并且可以根据个人偏好进行定制。
精选内容 ✦
AI经济学
探讨了 AI 技术如何被设计来替代人类工作者,尤其是白领工作者。尽管有大量的 AI 自动化产品和服务的推出,如 Microsoft 的自主代理、Apple 的跨设备应用控制系统以及 Anthropic 的 Claude,但全球生产力下降和美国与欧洲的就业率上升,表明 AI 自动化的实际影响可能还需要几年时间才会显现。AI 系统需要更便宜、更可靠,才能真正取代人类工作者。
马斯克和迪亚曼迪斯博士对话AI的未来
Elon Musk 与 Peter Diamandis 进行了一次关于 AI 未来的对话。Musk 认为 AI 正在以惊人的速度发展,可能在未来几年内达到人类智能的水平。他提到了 AI 的风险,认为 AI 可能是人类最近的存在威胁之一,同时也指出了全球人口衰减的问题。Musk 强调,为了确保 AI 的安全,需要创建一个追求真理的 AI,而不是一个受政治正确影响的 AI。他还提到了能源问题,预测了未来几十年内太阳能成为主要能源来源。
聊天机器人竞技场类别
LLM 竞技场新博客。介绍了聊天机器人竞技场的不同类别评估,包括定义、方法和见解,以及如何通过这些类别更深入地了解各种语言模型的优势和劣势。
- 用户在问什么?随时间变化的趋势
- 竞技场类别是如何制定的
- 对模型优势和劣势的关键见解
- 社区如何贡献新的评估分类
如何创建一个LLM作为测试集来驱动商业结果
分享了作者在帮助超过 30 家公司设置评估系统时的经验教训。文章首先指出 AI 团队在数据中淹没是常见问题,包括过多的指标、随意的评分系统、忽视域名专家以及未验证的指标。
作者提出了一个解决方案,即通过与主要域名专家合作,创建一个多样化的数据集,并利用 LLM 生成的用户输入来评估 AI 的表现。通
过域名专家的简单通过或失败判断以及详细的批评,可以明确 AI 的表现是否达到了预期目标。文章还详细介绍了如何修正错误、构建 LLM 评判者、进行错误分析以及创建更专业的 LLM 评判者。
Claude 3.5 Sonnet 的 SWE-bench 测试实践
Anthropic 更新了新 Claude 3.5 Sonnet 通过 SWE-bench 测试的一些细节。详细介绍了 SWE-bench 这个测试集特点以及他们为了测试构建的 Agents 工具。
Anthropic 的最新模型 Claude 3.5 Sonnet 在 SWE-bench Verified 上达到了 49% 的成绩,超越了之前的最佳成绩 45%,这表明了模型在软件工程任务上的提升,以及通过构建 “代理” 系统和工具使用策略来提高性能的重要性。
生成式人工智能、美国工人和工作的未来
一份人工智能对美国劳动力的潜在影响以及雇主、工人和政策制定者主动应对的必要性的调研报告找了几个条有意思的数据。
- 超过30%的工人将看到其工作任务的50%以上受到生成式AI的影响。
- 85%的工人将有至少10%的工作任务受到影响。
- 在办公室和行政支持职业中,71%的任务可能被自动化,且这些职位中71%由女性担任。
- 金融业仅有1%的工人有工会代表,而这恰恰是AI影响最大的行业之一。
- 保险承保人和保险理赔处理员的工作任务中有100%可能被自动化,而建筑工人仅有1.8%的任务面临自动化风险。
- 教育行业是少数既有较高AI影响(教师约33%的任务可能受影响)又有较高工会组织率(32.7%)的领域。
开始使用真实世界的机器人
huggingface 的机器人入门项目,介绍了机器人组装和控制的方方面面。详细介绍了如何订购和组装机器人,以及如何连接、配置和校准机器人的电机。如何使用 DynamixelMotorsBus 通信协议来控制电机,包括如何读写电机数据。
2024 年的网页内容爬虫
tuna 分享了在 2024 年进行 Web 爬虫的实践技巧,包括正确设置 HTTP 头部、建立 URL 跟踪系统以及实际的爬虫代码示例,并强调了在使用爬虫时需要遵守的尊重原则。
移动设备革命与人工智能革命
探讨了移动革命与人工智能(AI)革命的对比,并预测了 AI 革命的发展趋势及其对社会和经济的潜在影响。
阐述了技术革命的周期性,包括兴起、疯狂、同步和成熟阶段,并将 AI 革命与过去的技术革命进行了比较,认为 AI 革命可能更接近于互联网革命的规模,甚至可能是一个新的离散式革命,这将是计算机从模仿计算器转向模仿人脑的新时代。
还讨论了 AI 革命可能带来的创业机会,分为扩展、使能和相关行业三个层面,并强调了在新技术革命的早期阶段选择正确的投资对象的重要性。
为什么说人工智能与传统软件制作完全不同?
Edmar Ferreira 在 Every Studio 制作的 Source Code 专栏中探讨了构建 AI 产品与传统软件开发之间的本质区别,以及 AI 产品开发中独有的可行性风险和如何通过快速实验来应对这些风险。
Ferreira 强调了 AI 产品的非确定性和实验性,以及 AI 项目中非标准的迭代和测试过程,他还提到了深度 AI 创业公司与应用 AI 创业公司之间的风险差异。Ferreira 总结了 AI 创业公司面临的风险链(可行性 -> 价值 -> 可持续性),并强调了理解风险、正确分配资源和能量的重要性。
重点研究 ✦
In-Context LoRA:一次生成ID或者风格一致图片
In-Context LoRA 这个项目太强了啊。非常适合用来直接生成AI视频中需要的连续图生视频关键帧。
这个项目可以一次生成多张风格和ID一致但是内容相互关联的图片集。支持电影故事板生成、ID一致人像摄影、字体设计、PPT排版设计、家居装饰摄影。最关键的是基于FLUX。
谷歌:推动音频技术的发展
谷歌终于公布了他们有用来生成 NotebookLM 播客的音频技术细节。
主要包括两部分:
SoundStream 是一种神经音频编解码器,可以高效地压缩和解压音频输入,而不会影响其质量。
在训练过程中 SoundStream 可以学到韵律和音色等属性。AudioLM 框架不对生成的音频类型或组成做出任何假设,并且可以灵活处理各种声音,而无需进行架构调整。
在 TPU V5E 上 3 秒就可以生成2分钟的语音内容。他们还研发了一种专门的Transformer架构,可以高效处理信息的层次结构,与声学Token的结构相匹配。
为了教导模型如何生成多个发言者之间的真实对话,对其进行了数十万小时的语音数据预训练。
然后在一个更小的数据集上对其进行了微调,该数据集包含高音质和准确的发言者注释的对话,由多位配音演员进行非脚本和真实的不流畅语言对话组成。
MuVi:通过语义对齐和节奏同步实现视频到音乐的生成
阿里前几天发布了一个基于视频画面生成对应节奏音乐的研究 MuVi。
能够分析视频内容,并生成与视频情绪、主题、节奏和速度相协调的音乐。
基于流匹配,具有上下文学习能力,可以控制生成音乐的风格和流派。
开源 NotebookLM 播客方案 NotebookLlama
Meta 发布了他们的开源 NotebookLM 播客方案 NotebookLlama。他们提供了一个教程一步一步教你构建 PDF 到 Podcast 工作流程。
具体包括四部分内容:
步骤 1:处理原始 PDF:使用 Llama-3.2-1B-Instruct 模型将 PDF 转换并存储为 .txt 文本文件。
步骤 2:编写播客脚本:使用 Llama-3.1-70B-Instruct 模型将文本改写成播客脚本
步骤 3:提升表现力:使用 Llama-3.1-8B-Instruct 模型增强脚本的表现力和感染力
步骤 4:语音合成:使用 parler-tts/parler-tts-mini-v1 和 bark/suno 生成自然对话风格的播客音频
Meta 发布了 LongVU,一个可以处理长视频的多模态LLM
LongVU 项目由 Meta AI 团队及其他研究机构合作开展,旨在解决多模态大型语言模型(MLLMs)在处理长视频时的挑战。
该项目提出了一种基于跨模态查询和帧间依赖性的空间适应性压缩机制,通过去除高度相似的冗余帧,并利用文本引导的跨模态查询选择性减少帧特征,同时在帧之间基于时间依赖性进行空间令牌压缩。这种适应性压缩策略能够有效地处理大量帧,并在有限的上下文长度内最小化视觉信息损失。
GPT-4o 系统说明卡
Open AI发布了GPT-4的系统卡论文,GPT-4o 可以在短至 232 毫秒的时间内响应音频输入,平均为 320 毫秒,这与人类对话中的响应时间相似。它在英语文本和代码上的性能与 GPT-4 Turbo 的性能相匹配,在非英语语言文本上的性能显着提高,同时 API 的速度更快且便宜 50%。
在此系统卡中,详细介绍了 GPT-4o 的跨多个类别的功能、限制和安全评估,重点关注语音到语音,同时还评估文本和图像功能,以及确保模型实现而实施的措施是安全且一致的。
你可以在这里找到我:
| 即刻 | 推特 | Quail订阅 | 微信公众号:歸藏的AI工具箱 |邮箱:[email protected] | 微信号:op7418
也可以分享给更多的朋友,让大家都有机会了解这些内容,扫描下面右侧二维码加我好友,我拉你进会员交流群。