其他动态 ✦
- Claude 3.5 Haiku 在鸽了 5 天之后发布了。能力提升巨大,但是比 Claude 3 haiku 贵了四倍,输出价格是 Gemini Flash 的 33 倍。属实离谱了,不知道后面会不会推出一个更便宜的型号来补足需求。
- Suno V4 要来了,一定要听这个 Demo,太强了。另外他们安卓版本即将上线。
- Liblib上线PC客户端,可以一键在本地运行Web UI和Comfyui,而且还可以浏览线上的模型,直接从Liblib下载。
- 即梦的 S 2.0模型全量上线了,进去就能用。
- 智谱开源了 CogVideoX1.5 视频生成模型。CogVideoX1.5-5B系列支持更高分辨率的10秒视频。CogVideoX1.5-5B-I2V支持任何分辨率的视频生成。
- FLUX1.1 [pro] Ultra 版本更新,支持 10 秒直出 4K 分辨率的图片,Raw Mode 模式,开启后会产生更加真实和自然的图片,我的测试。
- Open AI 购买了 chat.com 域名。这个域名上次交易价格已经炒过了 1000万美元,不知道这次 Sam 花了多少钱。
- Meshcapade 现在支持用文字生成你要求的3D动作动画,可以结合V2V生成视频实现精细动作控制。
- XAI API 开放测试了,每个月 25 美元免费额度.
- Open AI 发布了预测输出功能,可以显著降低 gpt-4o 和 gpt-4o-mini 的输出延迟。
- 可灵上线了单独的iOS客户端,基本支持所有的功能。
- 微软正在考虑将其人工智能生态系统重命名为“Windows Intelligence”,旨在在其人工智能驱动的工具套件中实现统一的身份。
- 亚马逊正在就对 Anthropic 进行第二笔数十亿美元的投资进行谈判,条件是它使用亚马逊芯片为其人工智能训练服务器提供动力。
- Mistral AI 推出了由 Ministral 8B 模型支持的内容审核 API,可以检测 11 种语言的潜在有害内容。
- 苹果公司正在通过一项名为“ Project Atlas ”的新内部研究计划,来研究完全基于AI的智能眼镜。
- Open AI 安全和协调团队负责人 Lilian Weng 宣布离职,她的博客内容非常牛批,可以多翻翻。
- Google 准备推出 Gemini-2.0-Pro-Exp-0111。
图像及视频作品推荐✦
- 犯罪小说人工智能短片,我最近看到的最好的AI视频,而且图片全是用FLUX生成的。
- Julie W 用AI给她的孩子做的睡前故事绘本,非常精致。
- AI演绎Donald Trump经典现场,是什么在塑造媒体时代的现场? 汗青对于Runway镜头控制的创造性应用。
- Huggingface 上现在已经有超过 7000 个 FLUX Lora。前面的 Lora 质量都非常高。
- 假如复仇者联盟是八九十年代的电影。用八九十年代的影星演出复仇者联盟经典角色,比如尼古拉斯凯奇演洛基
产品推荐 ✦
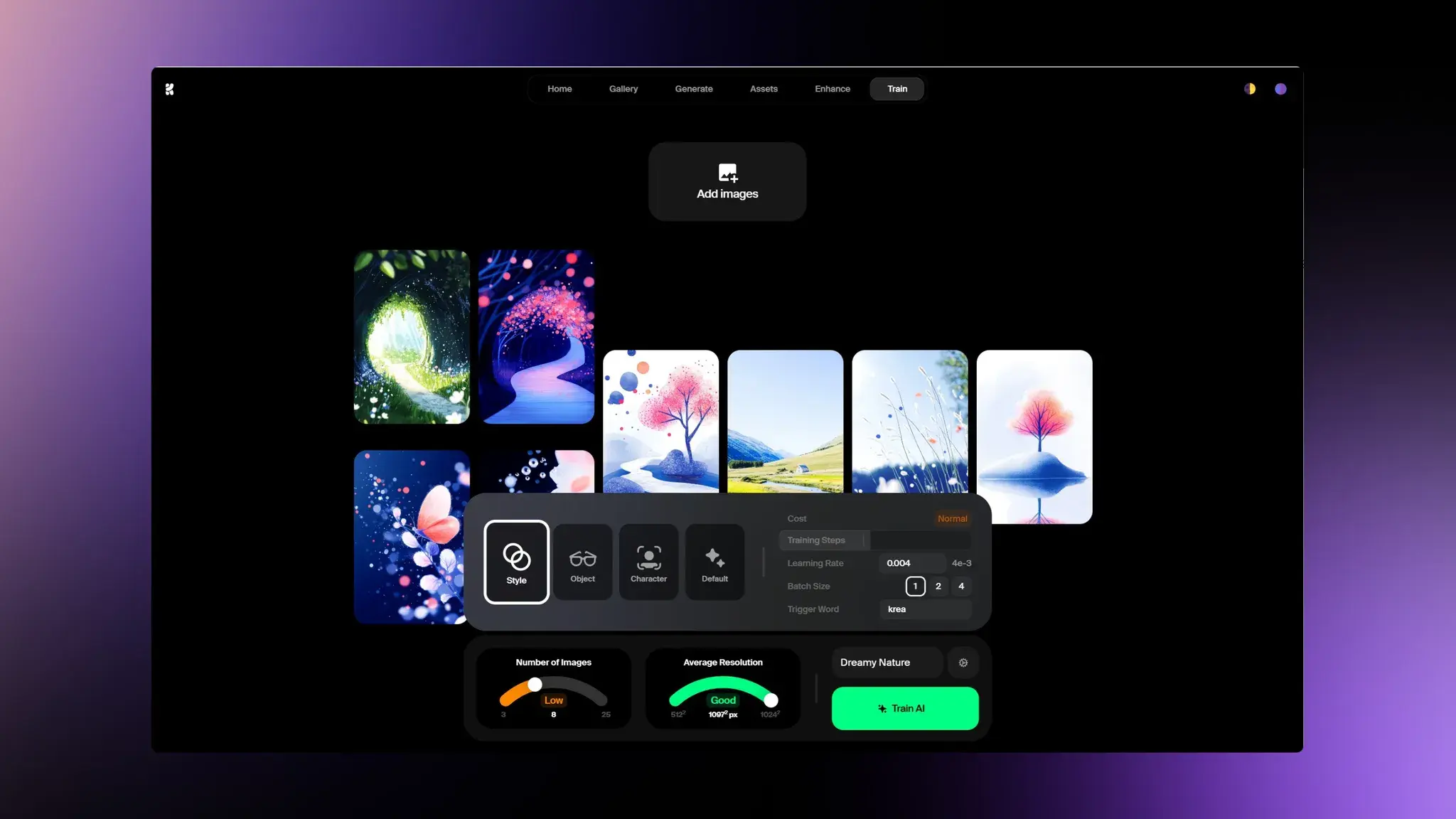
Krea 训练:低门槛训练FLUX Lora
Krea AI上线了 FLUX Lora的训练功能,这应该是现在门槛最低的FLUX Lora训练工具了,整个UI和交互设计的非常好,清晰、直观、简洁。所以说有些其他类似产品一点也不像互联网产品,照搬开源交互,十几个指标都扔给用户选择,也没有提效设计。
Unblocked AI:Figma AI图片生成插件
Unblocked AI 这个插件基本上把所有 AI 图像能力都搬进 Figma 了。现在更是支持一键将图标即可变成 3D 形式(也适用于 Logo)主要体验很好,比如这个图标 3D 化的功能还预置了很多提示词。

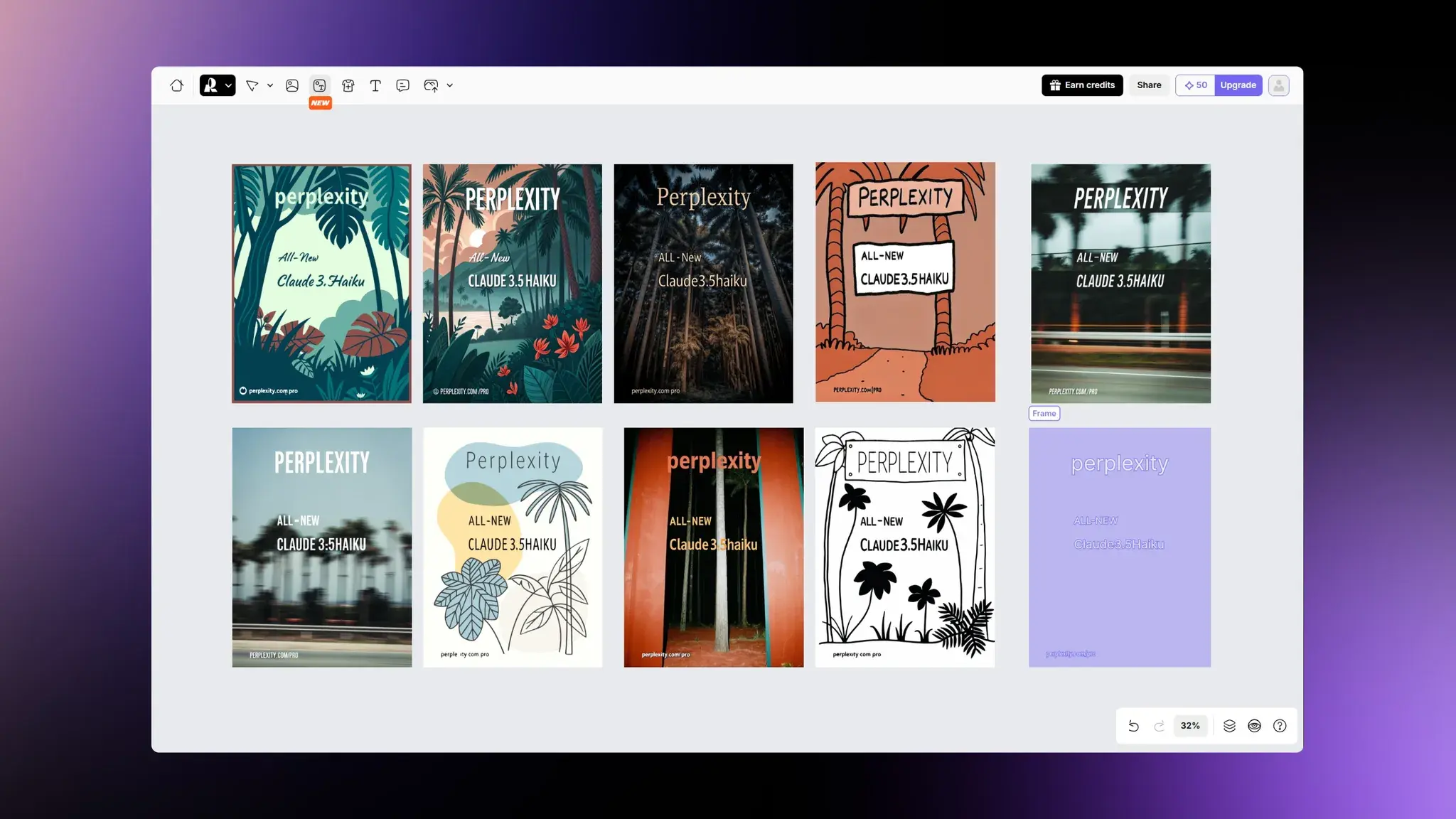
Recraft:图形设计生成器
Recraft 发布图形设计生成器,彻底解决海报生成问题。干死 Canva 和 PS。空白画布打字-选择风格-点击生成只需要三步。10 张 Perplexity 宣传图只需要 30 秒,点就完事了。
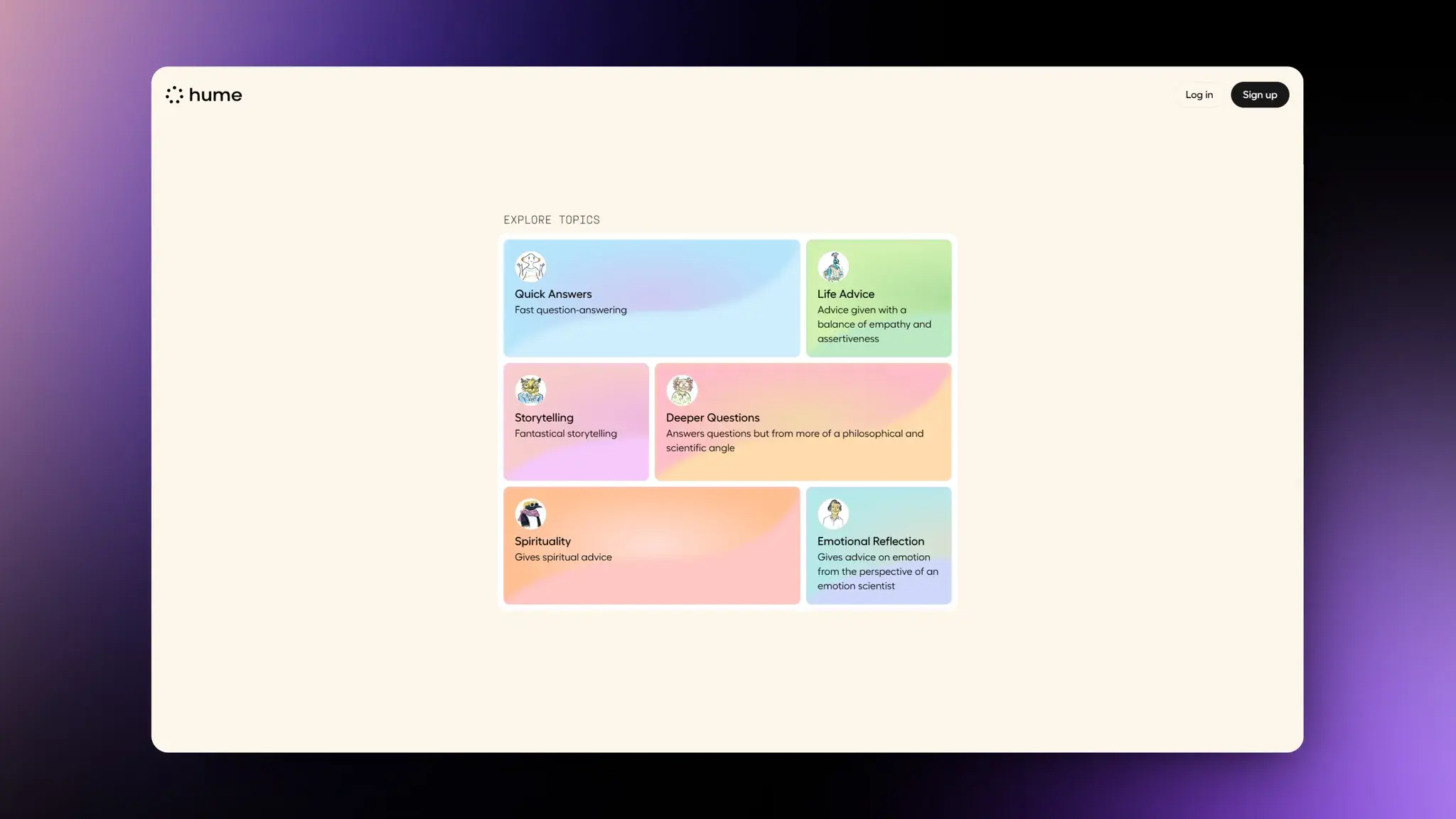
Hume:情感丰富的AI助手
Hume 也是发挥他们语音模型的优势基于 Claude 3.5 Haiku 和 EVI 2 语音语言模型重构了他们的应用。在故事讲述方面,EVI 2 展现了其在情感和戏剧性交付上的优势,而与此同时,fal 提供的图像生成能力让这些故事更加生动。对于更深层次的对话和生活建议,EVI 2 与 Claude 3.5 Sonnet 结合,并配合网络搜索功能,以提供更为精准和及时的信息。
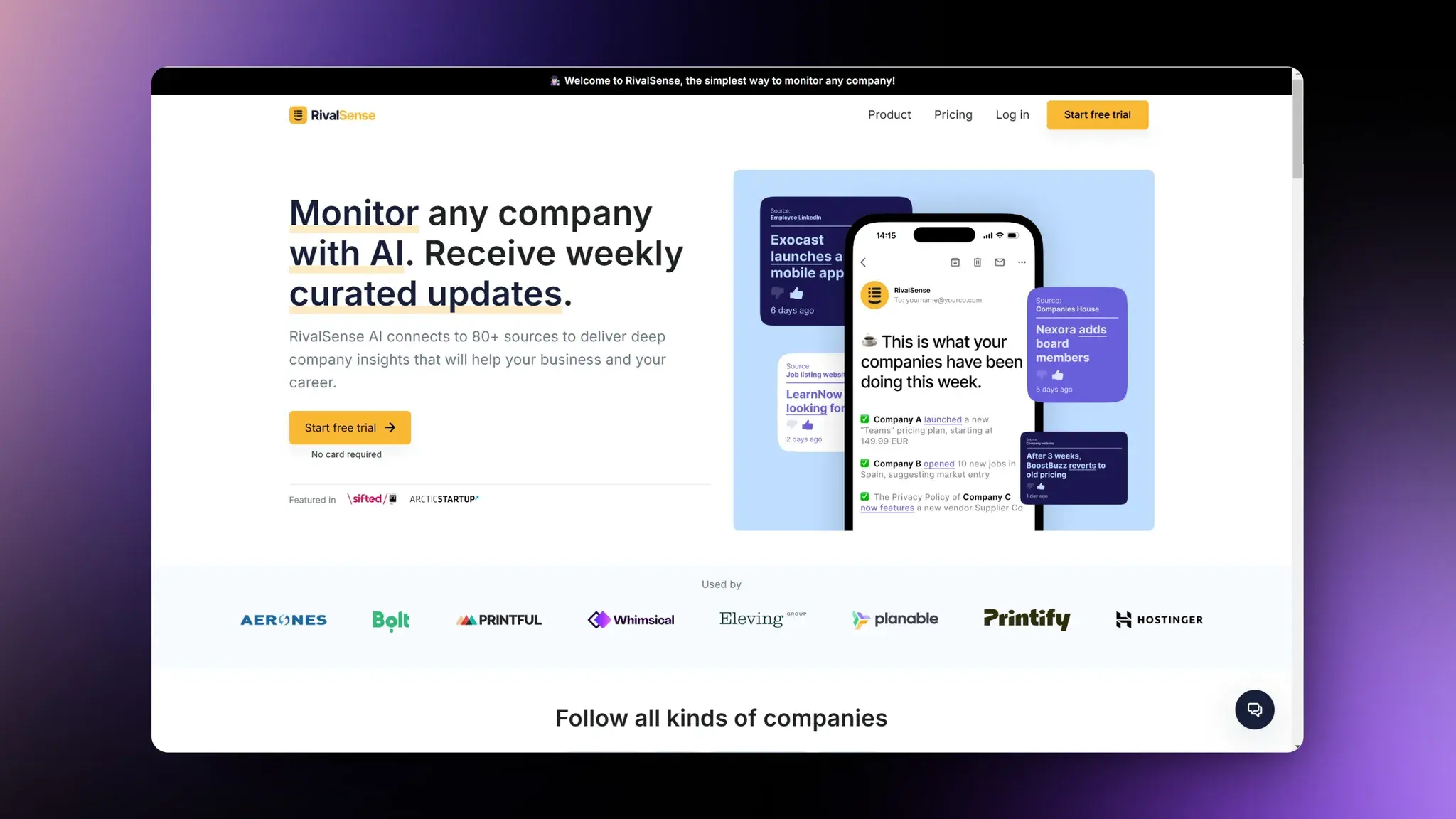
RivalSense:利用AI收集竞争对手信息
RivalSense 是一个利用 AI 技术的企业监控工具,它可以连接超过 80 个数据源,为用户提供深入的企业洞察,帮助他们了解业务伙伴、客户、潜在客户、竞争对手等的最新动态。用户可以通过输入关注的公司和选择相关的监控主题来开始使用。RivalSense AI 会每天监控公司网站、LinkedIn、Twitter、职位发布、新闻网站等,捕捉任何重要变化,并每周提供一个精选、易读的更新邮件。用户可以根据自己的兴趣调整监控的重点,AI 会根据用户的反馈优化信息展示。
精选内容 ✦
YC Sam Altman 访谈如何创造未来
Sam Altman 对未来技术趋势的展望,特别是人工智能领域的突破和潜力。他强调 AI 技术的快速进步,以及这一进步如何为创业公司提供独特的机遇。
Altman 回顾了 OpenAI 的创立,包括他们如何聚集人才、选择研究方向,以及他们在 AI 领域的一系列成就,如 GPT 系列模型的开发。他还谈到了 OpenAI 与其他大型科技公司的区别和竞争,以及他们如何专注于长期目标,如实现通用人工智能(AGI)。
Altman 对于 AI 技术在未来几年可能达到的里程碑表示乐观,包括解决气候变化、建立太空殖民地、发现宇宙的所有物理定律,以及实现几乎无限的智能和能源。
金融时报系列报道:人工智能的未来
为什么现在夸大人工智能在生产力方面的前景还为时过早;医生如何利用人工智能来改善医疗保健;雇主们正在率先采用人工智能工具来填补技能差距。科技正在改变该行业的各个领域,催生出新的岗位,而更传统的低技能工作则可能面临风险。
接近 400 万曝光的 V0+Cursor AI 编程项目开发技巧
这个老哥在全职工作的同时用 AI 还做了 5 个客户项目。相对体系化,每个人都可以使用。
未来可能重塑全球经济的18个新兴行业领域
麦肯锡的一个报告,详细探讨了未来可能重塑全球经济的18个新兴行业领域。第一还是电商,第二是 AI。
报告预测,未来的竞争大场将包括人工智能软件和服务、云服务、电动汽车、数字广告、半导体、共享自动驾驶汽车、太空、网络安全、电池、模块化建筑、流媒体视频、视频游戏、机器人、工业和消费者生物技术、未来空中交通、抗肥药物和核聚变电力等行业。这些行业的成功与地缘政治发展、人工智能技术的进步以及绿色转型的步伐有关。
写和不写
YC 的创始人认为由于 AI 的加入未来的世界可能会分成会思考的人和不思考的人的世界。
因为计算机科学家 Leslie Lamport 说过:不写作而思考,那只是自以为在思考罢了。
人们现在可以依靠 AI 来完成写作工作,这使得之前必须思考才能写作的压力得以释放。
这将导致一个分层的世界,其中只有少数人会保持写作能力,而大多数人则可能完全失去这一能力。
世界上仍然会有头脑清晰的思考者,但只限于那些主动选择思考的人.
风险、回报与打造独角兽芯片公司,与英伟达一较高下
对 Groq 公司创始人 Jonathan Ross 进行的访谈,探讨了 Groq 如何在半导体行业中与 Nvidia 等巨头竞争。
Ross 分享了 Groq 在设计和生产自己的芯片过程中遇到的挑战,包括技术上的创新、市场定位以及资金筹集等方面。他还谈到了 Groq 如何通过提供定制化的芯片解决方案来满足不同客户的需求,并且强调了公司在可扩展性和性能方面的优势。
No Priors Ep. 89:黄仁勋访谈
与 NVIDIA 首席执行官黄仁勋坐下来,反思该公司过去一年的非凡增长。 Jensen 讨论了 AI 对数据中心的接管以及 NVIDIA 对 x.AI 超级集群的快速发展。对话还涵盖了 Nvidia 长达十年的基础设施押注、软件寿命以及 NVLink 等创新。 Jensen 分享了他对实体人工智能、数字员工的未来以及人工智能如何改变科学发现的看法。
与 OpenAI 首席产品官 Kevin Weil、Anthropic 首席产品官 Mike Krieger 和 SarahGuo 的对话
- 讨论了 AI 产品开发中的评估和迭代过程,以及如何根据模型的性能调整产品设计。强调了模型能力的不断提升,以及产品经理需要具备的新技能。
- 分享了如何通过模型进行产品原型设计和用户研究,以及如何通过用户反馈来改进产品。讨论了 AI 在企业中的应用,以及如何处理模型的不确定性和用户的适应问题。
- 讨论了如何教育产品团队和用户更好地使用 AI 产品,以及如何通过 AI 改善工作效率。分享了一些关于 AI 如何帮助解决实际问题的例子,如自动化 UI 测试和处理客户服务请求。
- 讨论了 AI 模型的未来发展趋势,包括模型的主动性和异步交互能力。预测了 AI 在未来可能带来的变革,如实时翻译和个性化的 AI 伴侣。
- 总结了 AI 产品开发中的一些关键点,包括模型的评估、用户教育、产品设计和未来趋势。嘉宾们对 AI 技术的未来表示乐观,并感谢对话的机会。
AI 技术正在改变 YouTube 视频缩略图产业
YouTube 视频缩略图设计成为了一个微观经济体,顶级创作者如 MrBeast 愿意为单个视频的缩略图支付高达 $10,000。然而,AI 工具的出现让一些设计师对未来感到不安。例如,AI 研究人员 Anand Ahuja 推出的 CTRHero 能够在几分钟内创建缩略图,引起了设计师的强烈反对,甚至有人威胁他。
对于 YouTuber 来说,缩略图是吸引观众的关键,顶级创作者会测试多达 20 个不同的缩略图变体。这一趋势孕育了全球的自由职业 YouTube 缩略图艺术家群体。设计师们对于如 Midjourney 和 AlphaCTR 这样的 AI 文本到图像生成工具既感到好奇又感到焦虑。
重点研究 ✦
腾讯开源最大规模的 MoE LLM Hunyuan-Large
总参数量达到 389B,激活参数量为 52B,预训练模型支持 256K 上下文长度。基准测试和数学推理能力基本超过了所有同规模的大语言模型。
Hunyuan-Large 会上线腾讯云TI平台,同步支持业务自主精调及部署测试。
另外还优化了推理架构,显著减少了 GPU 内存使用(KV-Cache 部分节省了 50%),通过 FP8 量化优化,实现与传统 FP16/BF16 量化相比内存使用减少 50%的同时保持精度。
Hunyuan3D-1.0:开源3D模型生成
Hunyuan3D-1.0 现在应该是最好的开源 3D 生成模型了,支持文本和图片生成 3D 模型。
主要的优势是是非常强的泛化能力,无论是建筑、角色、场景、生物都可以很好的生成。
采用两级级联模型架构,标准质量只需要 4 秒就能生成,高精度模型也只需要 7 秒。
你现在可以在元宝APP”3D 角色梦工厂“应用里面测试这个模型,上传自己的照片就可以生成跟你一样的多种类型 3D 模型。
DimensionX:从单个图片生成 3D和4D场景视频
DimensionX 项目可以从单个图片生成 3D和4D场景视频。通俗点说就是Runway 镜头控制的加强版。支持单图生成视频后,随意调整视频镜头角度和运镜。
1/用于可控视频生成的 ST-Director:我们引入 ST-Director,通过在我们收集的维度变化数据集上学习维度感知 LoRA,来分解视频扩散模型中的空间和时间参数。
2/使用 S-Director 生成 3D 场景:给定一个视图,可以从 S-Director 生成的视频帧中恢复高质量的 3D 场景。
3/使用 ST-Director 生成 4D 场景:给定单个图像,T-Director 生成时间变化视频,从中选择关键帧来生成空间变化参考视频。
通用多代理系统 Magentic-One
微软发布类似贾维斯的通用多代理系统 Magentic-One 。
Magentic-One 采用了一个名为 Orchestrator 的首席代理来指导其他四个代理完成任务。
这些代理分别是 WebSurfer(操作 Chromium 浏览器)、FileSurfer(读取本地文件)、Coder(编写和执行 Python 代码)和 ComputerTerminal(执行程序和安装新的编程库)。
能够在不修改其核心功能或架构的情况下,在多个挑战性的代理基准上实现竞争性能。
基于 AutoGen 开源框架构建,这使得系统具有模块化和灵活性,并且支持代理的即插即用设计。
ReCapture:将已有视频转换为另一种运镜方式
谷歌新研究 ReCapture。支持将已有视频转换为另一种运镜方式。
使用多视图扩散模型或基于深度的点云渲染生成具有新相机轨迹的嘈杂锚定视频。
然后使用蒙版视频精细将锚定视频重新生成为干净且时间一致的重新排列视频- 调整技术。
包括微调蒙版锚视频上的时间 LoRA 以了解场景动态,以及微调源视频中的增强帧上的空间 LoRA 以了解场景的外观。
GIMM-VFI 一个针对视频帧插值的通用解决方案
能够在任意时间步长上进行连续运动建模和插值。
看演示涉及一定的生成,即使非常不流畅的视频,也可以补全剩下的帧。
Kijai 也开发了 Comfyui 插件,有视频插帧需求的可以试试。
X-Portrait 2:极具表现力的肖像动画
字节发布 X- Portrait2 单图生成面部视频技术。面部和唇部肌肉非常自然而且生动,真实的有点离谱了。这下 AI 脱口秀视频和对谈视频,还有表演技术彻底成熟了。
X-Portrait 2技术上的突破是:
他们构建了一个最先进的表情编码器模型,通过新的端到端自监督训练框架,能够从人像视频中自学习ID无关的运动隐式表征。
另外通过为模型设计过滤层,编码器能有效过滤运动表征中的ID相关信号,使得即使ID图片与驱动视频中的形象和风格差异较大,模型还可以实现跨ID、跨风格的动作迁移。
GameGen-X:可交互游戏生成模型
可交互游戏生成模型 GameGen-X 发布!!能够生成非常高质量的可以操作的游戏画面。
DiT 视频模型就是新的游戏引擎!模型创建角色、提供动态环境、复杂动作和多样化事件。Epic CEO 看到 Oasis 实时生成游戏的时候就急了,直接开骂。红杉合伙人说再过五年看看,现在来看可能不需要 5 年。
InstantX:DiT的免培训区域提示
InstantX 这个区域提示项目很强啊,感觉会有很多玩法。
可以精确控制 FLUX 生成图片时每个区域的内容,而且支持和 Controlnet 和 Lora 一起使用。
比如可以让生成图片的一部分是写实的一部分是 2D 动漫,也可以控制图片中物体出现的具体局域.
你可以在这里找到我:
| 即刻 | 推特 | Quail订阅 | 微信公众号:歸藏的AI工具箱 |邮箱:[email protected] | 微信号:op7418
也可以分享给更多的朋友,让大家都有机会了解这些内容,扫描下面右侧二维码加我好友,我拉你进会员交流群。