
封面提示词 :A minimalist art photograph of a suspended smoked-glass infinity knot with smooth, flowing curves. The sculpture emits its own light, with royal-blue edges that transition into a sunlit amber glow towards the center. The entire piece is isolated against a very dark, onyx-black background. The entire image has a heavy, visible analog film grain. --ar 16:9 --raw --profile acx1ick --stylize 50
上周精选✦
Open AI 疯狂输出: Sora2 、GPT 打开应用、Agent 构建、Codex 正式版
这个国庆假期基本上是 OpenAI 一直在输出先是搞出了 Sora2,然后还有 Dev Day 的一堆面向开发者的更新,我们一个一个来看。
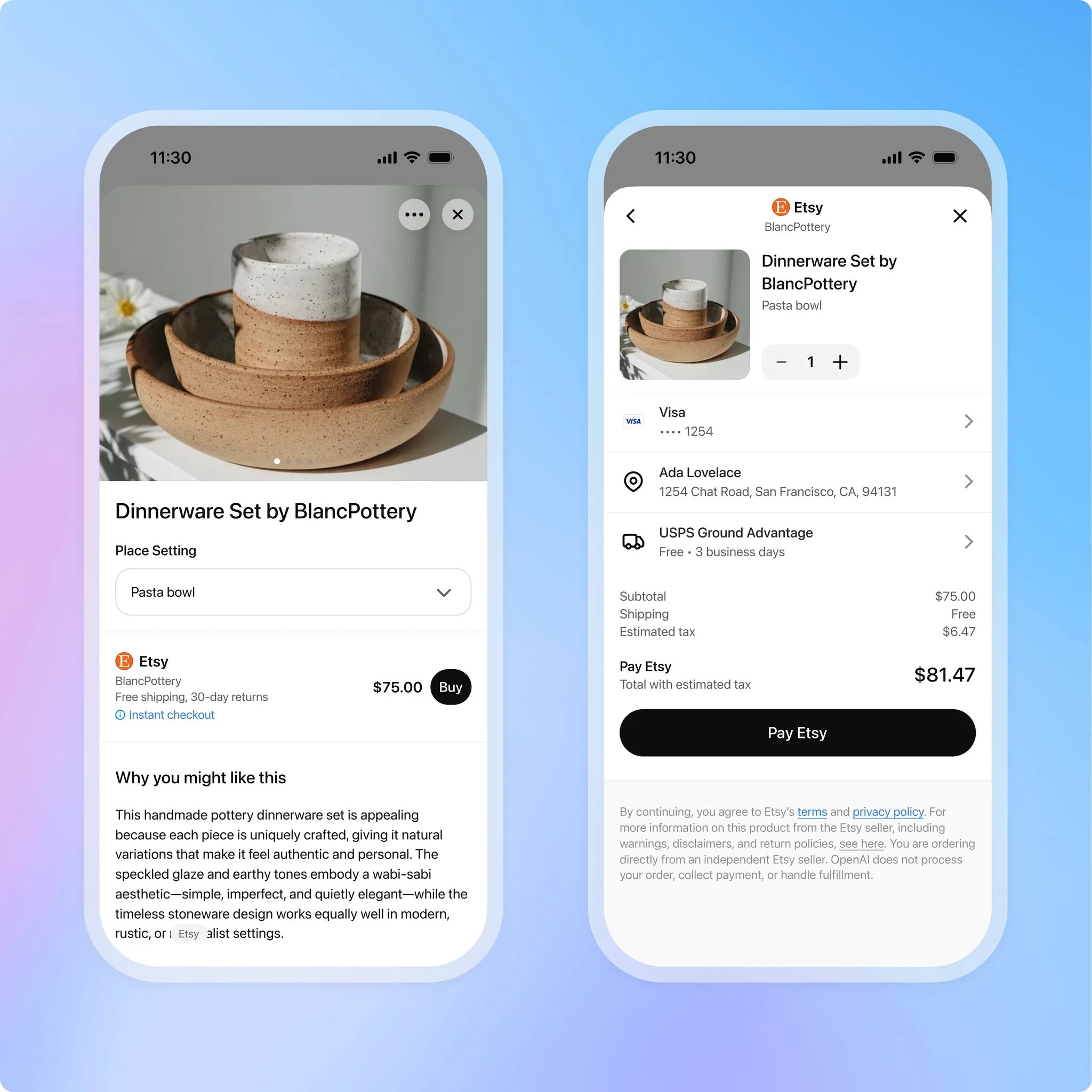
9 月 30 号 ChatGPT 支持了直接购物付款全流程,你可以跟 GPT 询问你想要买的产品的要求,GPT 会搜索所有符合要求的。
找到合适的时候商品的时候就可以直接看到 GPT 整理出来的商品详情页。
你可以直接在 GPT 里面付款,不需要跳转到电商平台。可使用信用卡、Apple Pay、Google Pay 或 Stripe 的 Link 付款。
可以在 GPT 里面看到和追踪自己的订单。
为了完成这个服务他们自己也构建了一个为 Agent 提供支付支持的协议 Agentic Commerce Protocol (ACP)。
如果你是 Stripe 用户的话只需要一行代码就可以接入这个协议。
这下电商也得搞 GEO 了,如果你是出海商家,可以直接填表让 GPT 可以搜到你的商品,又一个新渠道。
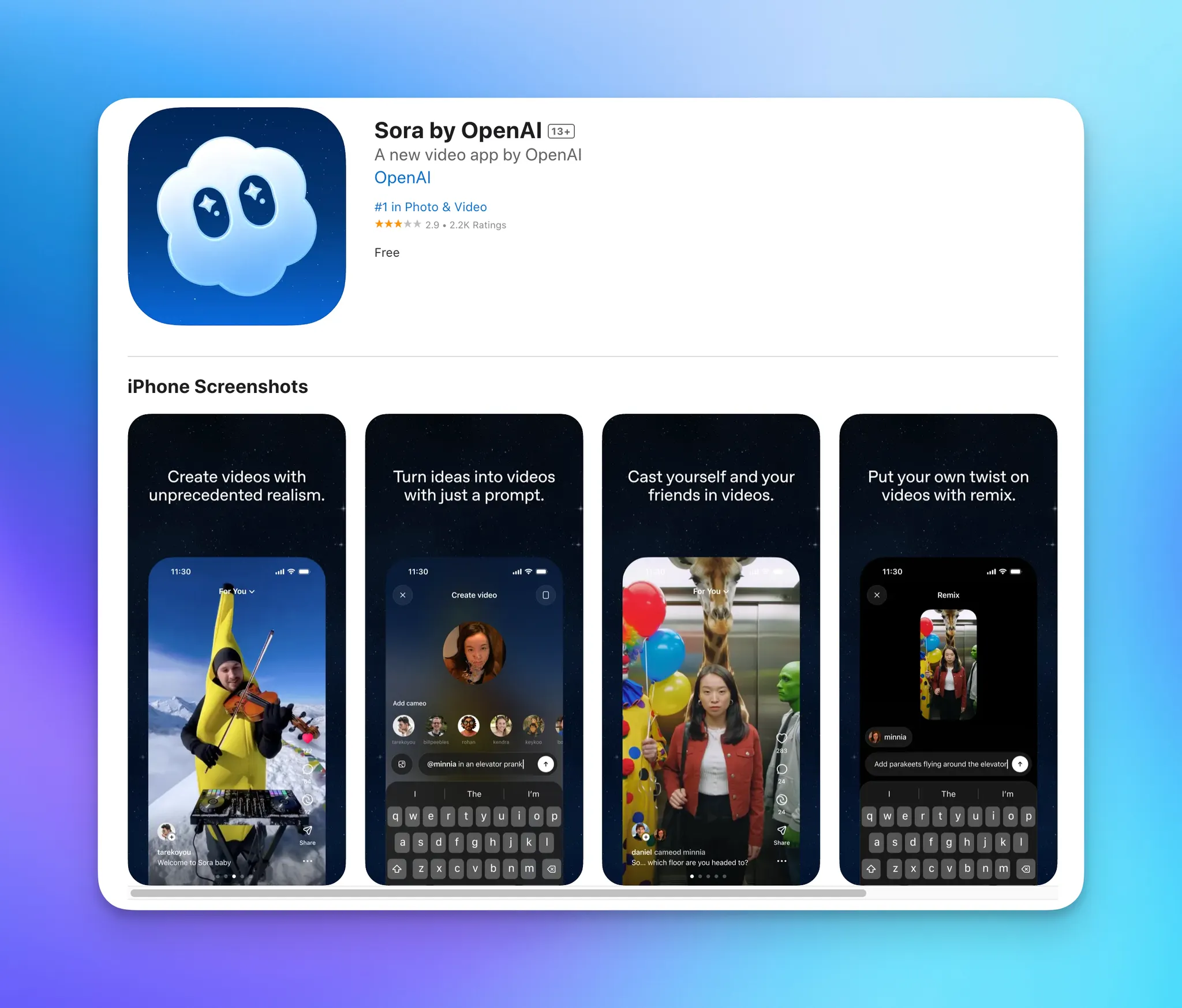
首先就是国庆第一天突击发布了 Sora 2,同时会有一个搭配的 APP(Sora 2 By Open AI),APP 需要邀请码注册,获得邀请码的人会获得访问权限。
注册的时候会让你录制三段大概两秒的视频,来固定你的人像 ID,进去以后你的朋友或者你自己只需要在提示词中@ 你的用户名就可以让你参演生成的视频,不过这个相似度很玄学,我的脸保持的非常好,很多朋友的不太行。
你可以选择什么人可以用你的脸生成视频,比如关注你的人,你关注的人或者任何 Sora 2 的用户。
写了一下这个我关于这个模型的一些想法:
- 这次 Sora 2 相较于其他视频模型最强的是他的编排和创意能力,你只需要很短的提示词就可以帮你生成完整的作品,而不是单纯的视频片段。
- 另一个是结合人像 ID 以及 @ 这个操作的交互创意,直接绑定了用户的社交关系,要知道一旦可以恶搞朋友做坏事,我们的创意和激情很多时候是无限的,而且不知道为啥我的人像稳定程度堪比 Sam,我也索性开放了所有人都能生成的权限,所以你最近应该在很多 Sora2 的视频里面看过我的脸。
- 顺着第一个说,由于 Sora 2 过高的智能程度,如果你对自己的创意和编排能力没信心的话建议提示词写短点,甚至可以传张图片,然后说“交给你了”。
- 同时 Sora 2 是可以调用 ChatGPT 的记忆能力的,如果你用的多他知道你的职业,你喜欢的运动,你关心的内容,也会让你感觉他非常智能而且很懂你。
- 最后一个相对重要的是在语音生成上,它可以生成很多主流语言的语音,而且相当生动,还能保持用户的音色,这个对于很多其他视频模型哪怕是 Veo 也是个挑战,另外他只有两秒的语音素材,但是生成的音色是非常像的,这个能力也超过了不少专门的语音模型。
最后 Sora 2 普通模型和 Pro 模型的 API 也上线了,普通模型每秒是 0.1 美元,API 输出是没有水印的,但是关于IP 和真人图片的限制一样严格。
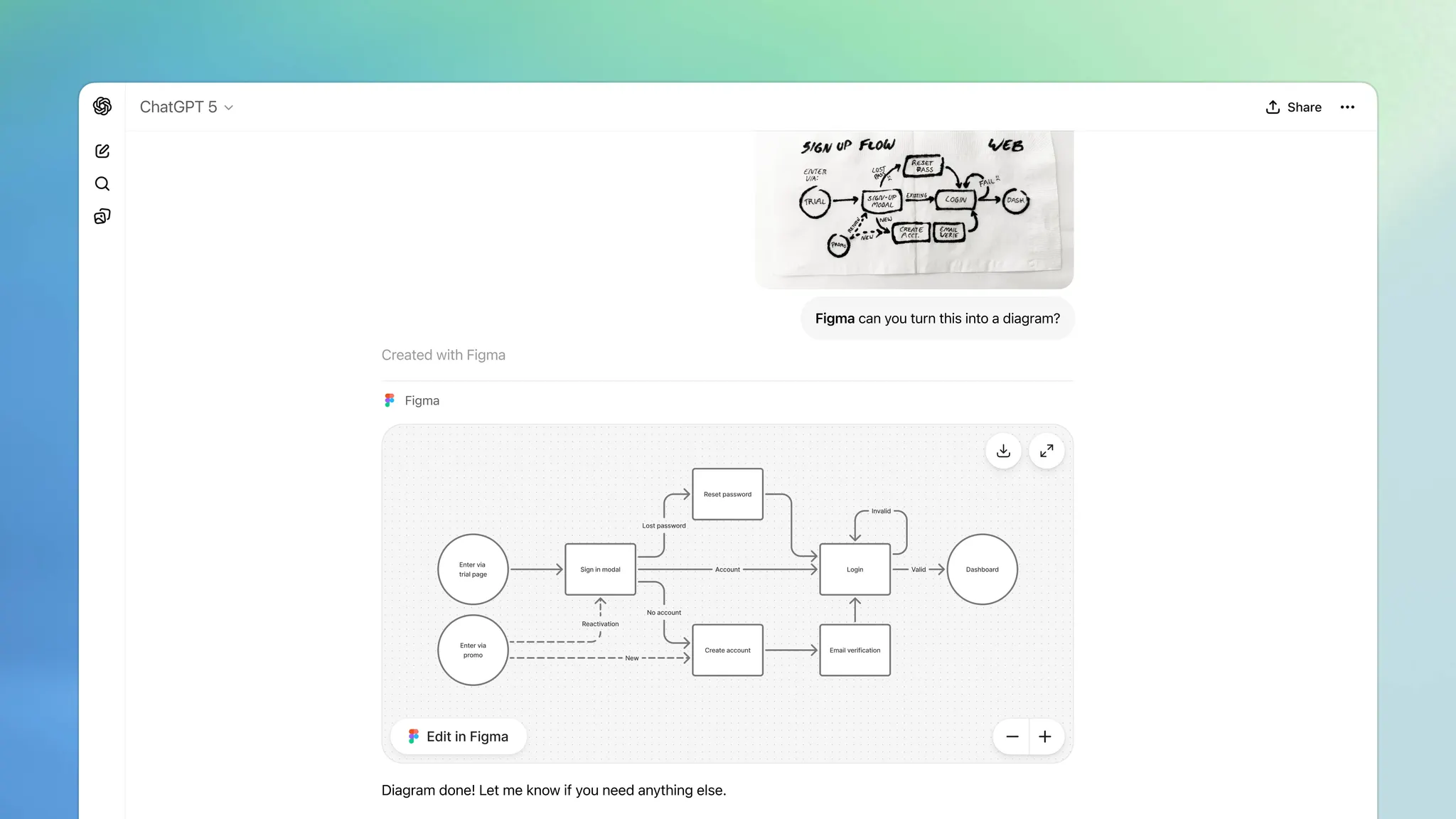
Dev Day 的一个发布内容,现在 ChatGPT 可以连接其他应用完成任务了。
比如你以前让他推荐 Spotify 的音乐或者播客的时候他只能文字回复,现在可以直接在 GPT 上展示播放列表了,你可以直接播放或者执行上一首下一首等操作,相当于在 GPT 塞了一个简易的 Spotify 的界面。
而且不止可以执行查询任务,也可以执行创建任务,链接 Figma 之后它可以直接在 Figjam 上帮你画各种流程图,完事你还可以跳转 Figma 进行编辑,也可以用 Canvas 帮你生成海报等操作,这个服务免费用户也可以使用。
为了让各种 APP 更方便的接入 ChatGPT,他们也发布了一个 APP SDK,这个协议基于 MCP 进行构建如果原来有 MCP 的话可以很方便的适配。
感觉现在创业公司可以准备起来了,等到开放接入申请的时候可以直接上架 GPT,这个流量入口还是非常可观的,后面也会根据使用量跟各种接入的 APP 现金分成。
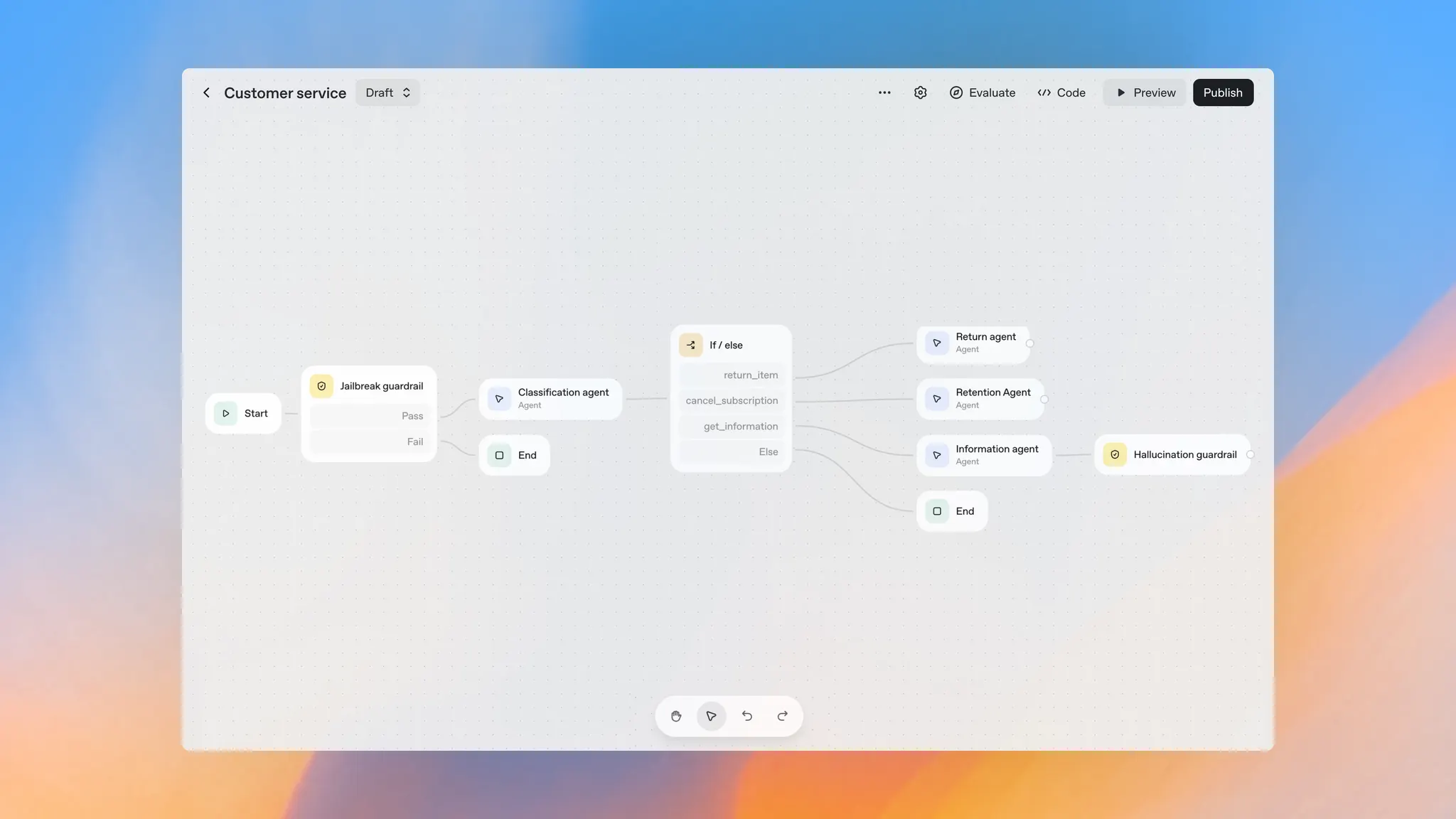
然后是 Dev Day 的第二个东西 AgentKit,一整套供开发者和企业用来构建、部署和优化代理的工具。
类似 N8N 的可视化 Agent 构建工具,主要有三个部分组成:
- Agent Builder: 可视化画布,拖拽节点编排多代理工作流,支持预览运行、内联评估配置与完整版本控制;可启用开源模块化安全层 Guardrails(PII 屏蔽、越狱检测、幻觉防护),并可独立或以 Python / JavaScript 库集成。
- Connector Registry: 企业级集中式连接器管理,在 ChatGPT 与 API 间统一整合 Dropbox、Google Drive、SharePoint、Microsoft Teams 及第三方 MCP 数据源;需 Global Admin Console 作为前置条件。
- ChatKit: 面向产品内嵌的可定制聊天代理工具包,处理流式响应与线程管理,展示“模型思考”,适用于知识助手、入职引导、客服与研究代理等场景。
ChatKit 这个有点意思,又多做了一步把前端样式也搞定了,他们也提供了一些常见的 UI 组件样式可供使用,可以在这里尝试。
普通 C 端用户用这个成本有点高,这个类似 GPT-5 的模型 API 也需要进行企业身份认证。
这部分的更新内容就比较少了,就三个比较小的更新感觉是凑数的:
- 全新 Slack 集成:像对同事一样,直接在团队频道或线程中将任务委派给 Codex 或向其提问。
- Codex SDK:将驱动 Codex CLI 的同一代理嵌入到您自己的工作流、工具和应用中,在无需额外微调的情况下实现基于 GPT‑5-Codex 的最先进性能。
- 新的管理工具:通过环境控制、监控和分析仪表板,ChatGPT 工作区管理员现在可以更清晰地可视化并控制大规模管理 Codex。
还有一些其他的 Open AI 相关信息:
- GPT-5 Pro 的 API 也发布了,每一百万 Token 的输出要 120 美元。
- 还发布了一款更加便宜的实时语音通话模型 gpt-realtime-mini**,**能够通过 WebRTC、WebSocket 或 SIP 连接实时响应音频和文本输入。
- 还有一个更便宜的 4o 图片模型 gpt-image-1-mini,中等质量下一张图片只需要 0.015 美元。
谷歌也搞了一堆东西
谷歌虽然没有发布什么重磅内容,但也一直在发东西,感觉是在为 Gemini 3 预热了。
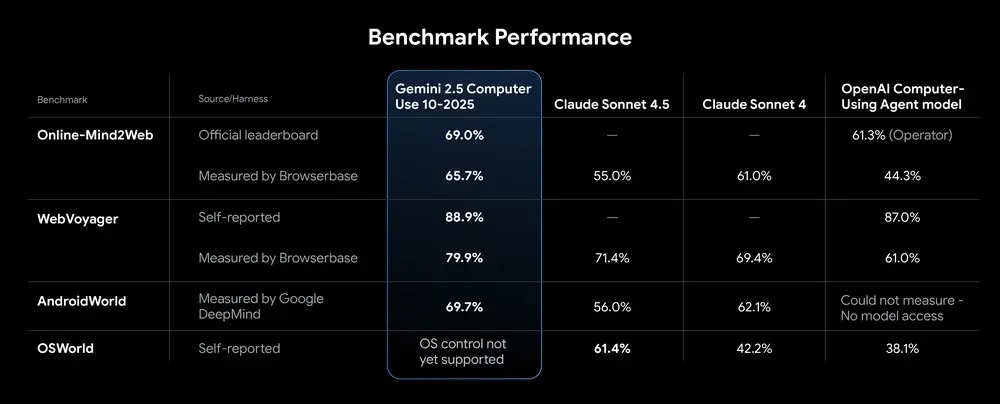
发布了专门用于UI 操作的 Gemini 2.5 Computer Use
基于 Gemini 2.5 Pro 的视觉理解与推理能力,专门用于驱动能“看屏幕、点按、输入、拖拽、滚动”的智能代理,实现网页与应用的 UI 交互,并在多项基准上以更低延迟取得领先准确率。
在 Browserbase harness 的在线网页控制中,达到 70%+ 准确率、约 225 秒时延 的优异“质量‑时延”平衡,优于竞品。
已在 Google AI Studio 与 Vertex AI 公测预览开放。可在 Browserbase 的演示环境试用。
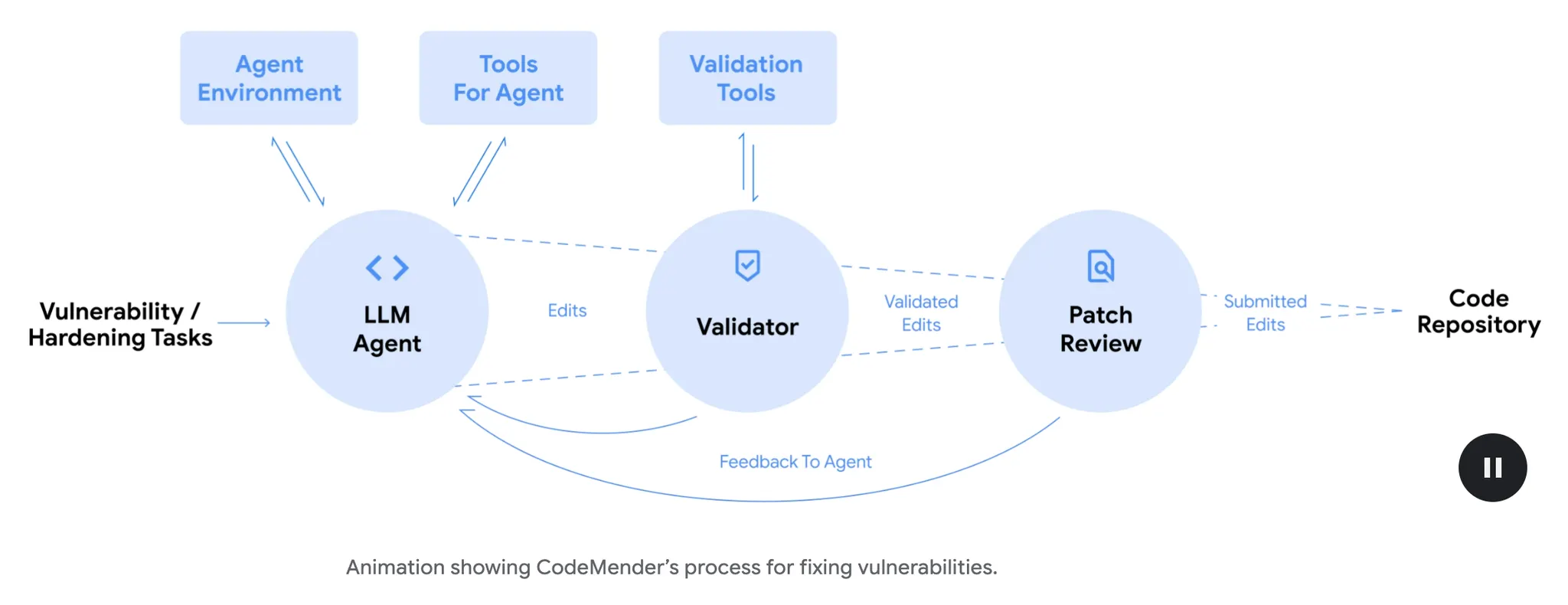
一个以 Gemini Deep Think 推理能力为核心的自主代理,用于提升开源软件的代码安全。它兼具“被动响应”与“主动预防”两种能力:一方面能在发现新漏洞后自动生成并验证高质量补丁,另一方面还能系统性地重写与加固既有代码,从根源上消除整类漏洞。
代理配备了调试器、源码浏览与验证工具,先“推理-修改”,再“自动验证”,只把通过多维校验的补丁提交给人类审核。验证维度包括:是否修复根因、功能正确性、无回归、风格合规等。为增强推理与验证效果,研究团队引入了两类技术体系:其一是基于高级程序分析的工具链,结合静态/动态分析、差分测试、fuzzing 与 SMT 求解器,从控制流与数据流层面定位架构弱点与漏洞根因;其二是多智能体系统,例如用 LLM 驱动的“差异批判”工具比对修改前后代码,辅助回归检查与自我纠错。
在“主动加固”方面,文章提到 CodeMender 已为广泛使用的图像压缩库 libwebp 的部分代码应用 -fbounds-safety 注解,让编译器自动增加边界检查,从而杜绝溢出类利用。文中点到 CVE-2023-4863 曾被用于零点击 iOS 利用,如果当时相关代码已应用这些注解,绝大多数缓冲区溢出将被“永久不可利用”。
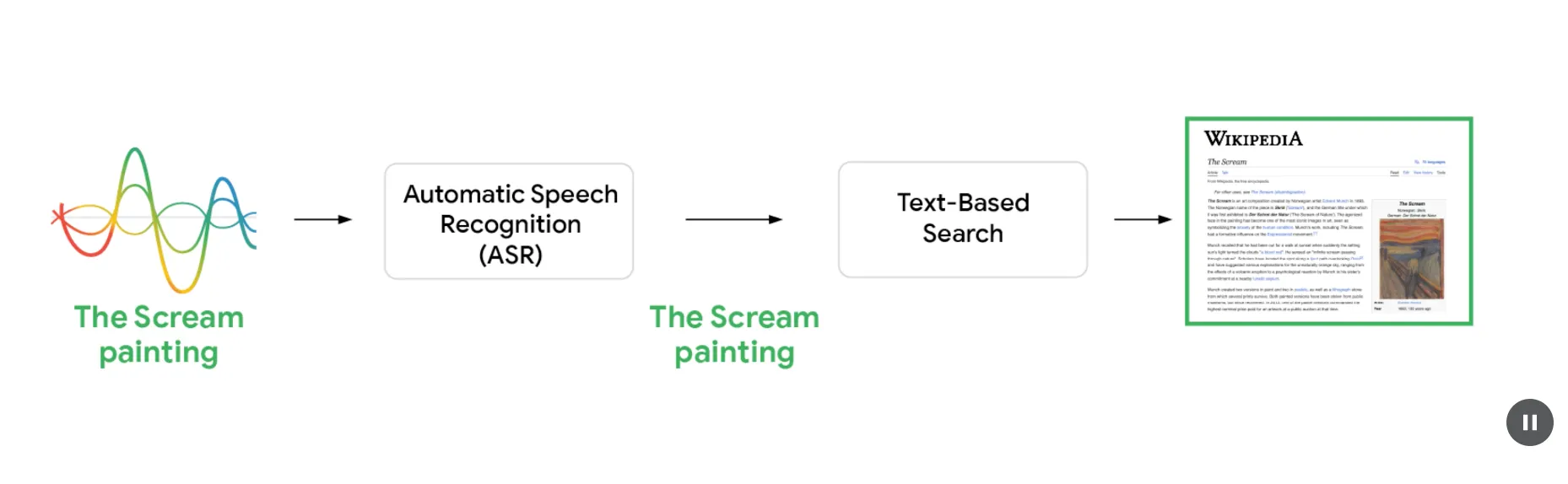
发布了 Speech-to-Retrieval(S2R)语音搜索架构
不再先做文本转写(ASR),而是直接从语音嵌入检索用户想要的信息,避免“转写出错→检索跑偏”的级联问题。文章通过对比“真实级联ASR”和“理想级联(人工转写)”两套系统,发现即使 WER 较低也不必然带来更高 MRR,且两者在所有测试语言上存在显著性能差距,揭示了从语音直接到意图的巨大提升空间。
核心技术是双编码器架构:音频编码器把语音问题转为语义向量,文档编码器为候选页面生成向量;通过成对训练,使正确答案在向量空间里与语音查询更接近。在线检索时,语音嵌入先高效召回相似文档,再由搜索排序系统结合数百信号在毫秒级重排,给出更可信的最终结果。以“‘呐喊’这幅画”为例,S2R能从语义出发命中维基和博物馆等高相关来源,避免把“scream”误听成“screen”的灾难性偏差。
谷歌专门针对低收入国家整的会员等级 Plus 会员现在已经扩展到 36 个国家,包括一堆除了新加坡的东南亚国家。
另外为了反击 Open AI 的 AgentKit,谷歌的类似产品可以通过自然语言和可视化无限画布构建 Agent 产品的 Opal,在美国之外的很多国家也开放了使用权限,可以去试试。
Nano banana 终于支持指定输出比例了,一共可以指定10种比例,常见的都支持。另外 API 支持了只输出图片,不输出文字。
谷歌正在加速 Google Home Gemini 化,发布了由 Gemini 驱动的 Nest 摄像头和门铃、Gemini for Home、全新设计的 Google Home 应用。
Anthropic 发布了 Claude Sonnet 4.5
Anthropic 发布了 Claude Sonnet 4.5,在价格比 Opus 4.1 便宜 5 倍的情况下几乎所有的测试基准都超过了 Opus 4.1.
Sonnet 4.5 可以连续工作 30 个小时直到完成任务,在计算机使用上的能力也有了提升,现在 Claude 的浏览器扩展也更强了。
同时 Claude Code 也配合进行了升级,增加了检查点,可以随时回滚代码。
开放了同款的 Claude Agent SDK 基建,其他人也可以用 Claude Code 的技术构建 Agent。
API 里面加上了上下文编辑能力和记忆能力。
另外还增加了一个 Imagine with Claude 的实验性项目,这个界面类似电脑桌面,他会基于你的要求实时生成前端 UI 和功能,目前只对 MAX 用户开放。
