封面提示词:flower reaching toward a soft blue and blush dusk sky, iridescent crystal light scatter, hazy atmospheric glow, analog 35mm film grain, soft focus, pastel sky, feels like a memory, floating weightlessly --v 8.1 --profile hs78bkj
上周精选✦
Open AI 的一些动向
上周 Anthropic 举行了开发者日,并没有什么特别大的发布,仅有的一些消息我写在下面了。目前主要的产品都没有更新,反倒是 OpenAI 一直有些动向。
尤其是 Codex,现在支持从 ChatGPT 里面导入你的设置,也可以把其他 Agent 的设置导入。
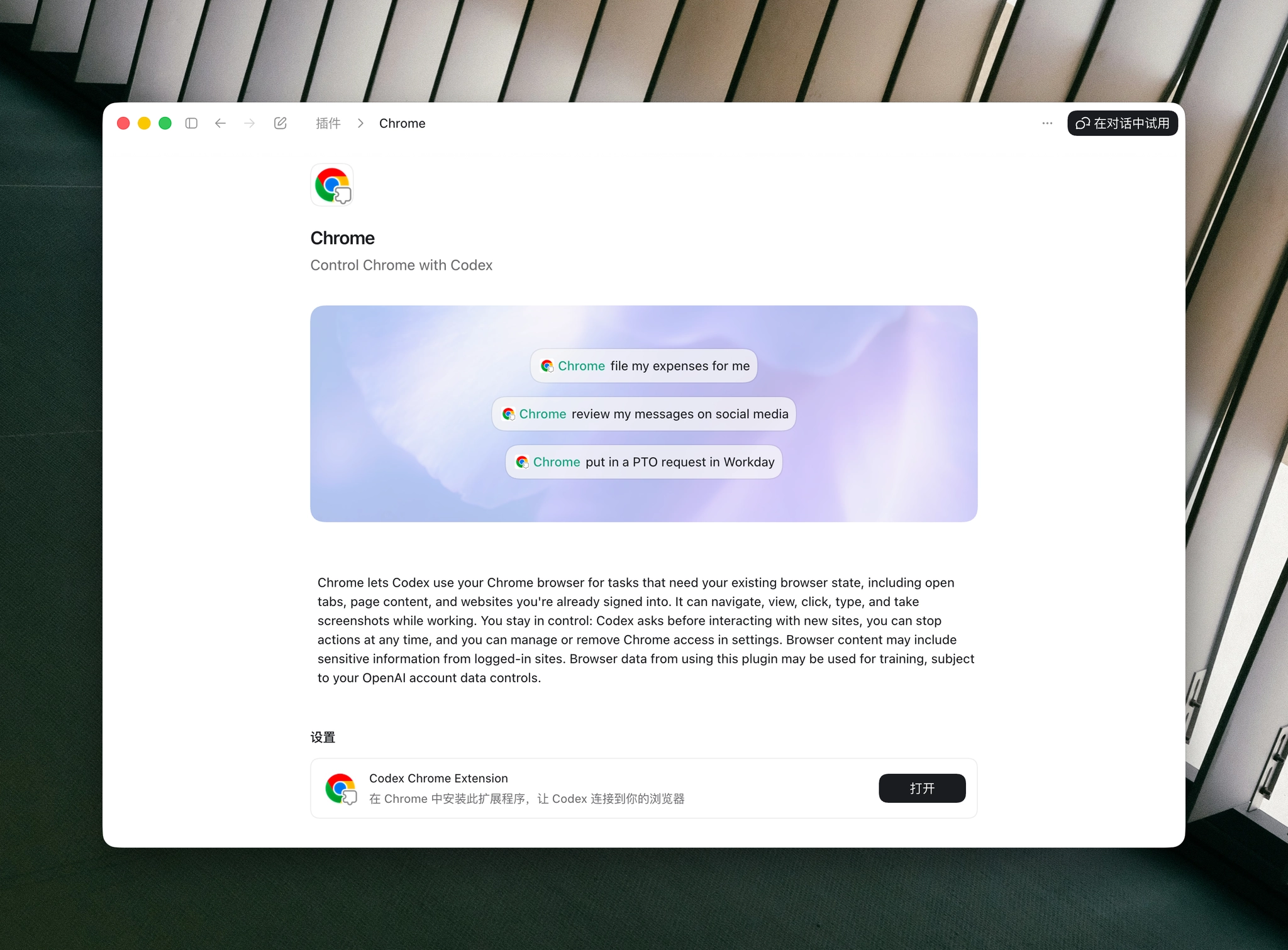
此外,Codex 还新增了内置的插件,支持使用和操作 Chrome 浏览器。
我试了一下,它不仅能操作 Chrome 浏览器,所有基于 Chrome 内核的浏览器都可以操作。比如我现在用的 Dia,它就可以操作。
具体的使用方式如下:
- 在插件页面找到 Chrome 浏览器的插件并安装。
- 安装后,它会引导你去安装一个 Chrome 浏览器扩展。
注意:这个插件在一些 IP 环境下无法安装,所以请留意你的网络环境。
这套方案应该还是基于 CDP MCP,只是做了一些深度的定制和优化。而且它在使用浏览器时是可以共享已有 Cookie 的,能够直接读取现在的登录状态,这一点还是挺好的。
OpenAI 还更新了 GPT-5.5 Instant 模型,现在变成了 ChatGPT 默认模型。
模型提升了实时准确性和日常任务的表现,主要改进:
性能优化:在法律、金融、医学等领域的幻觉率明显下降。同时,在图片理解和文档解析方面表现更好。
表达风格:回答更加紧凑且聚焦要点,减少了无用的铺垫和过渡排版。简单来说就是废话变少了,之前的 5.5 版本(GPT-5.5)确实废话有点多。此外,个性化能力也得到了提升。已经全量发布。ChatGPT 已经将其设为默认模型,Codex 没有更新。
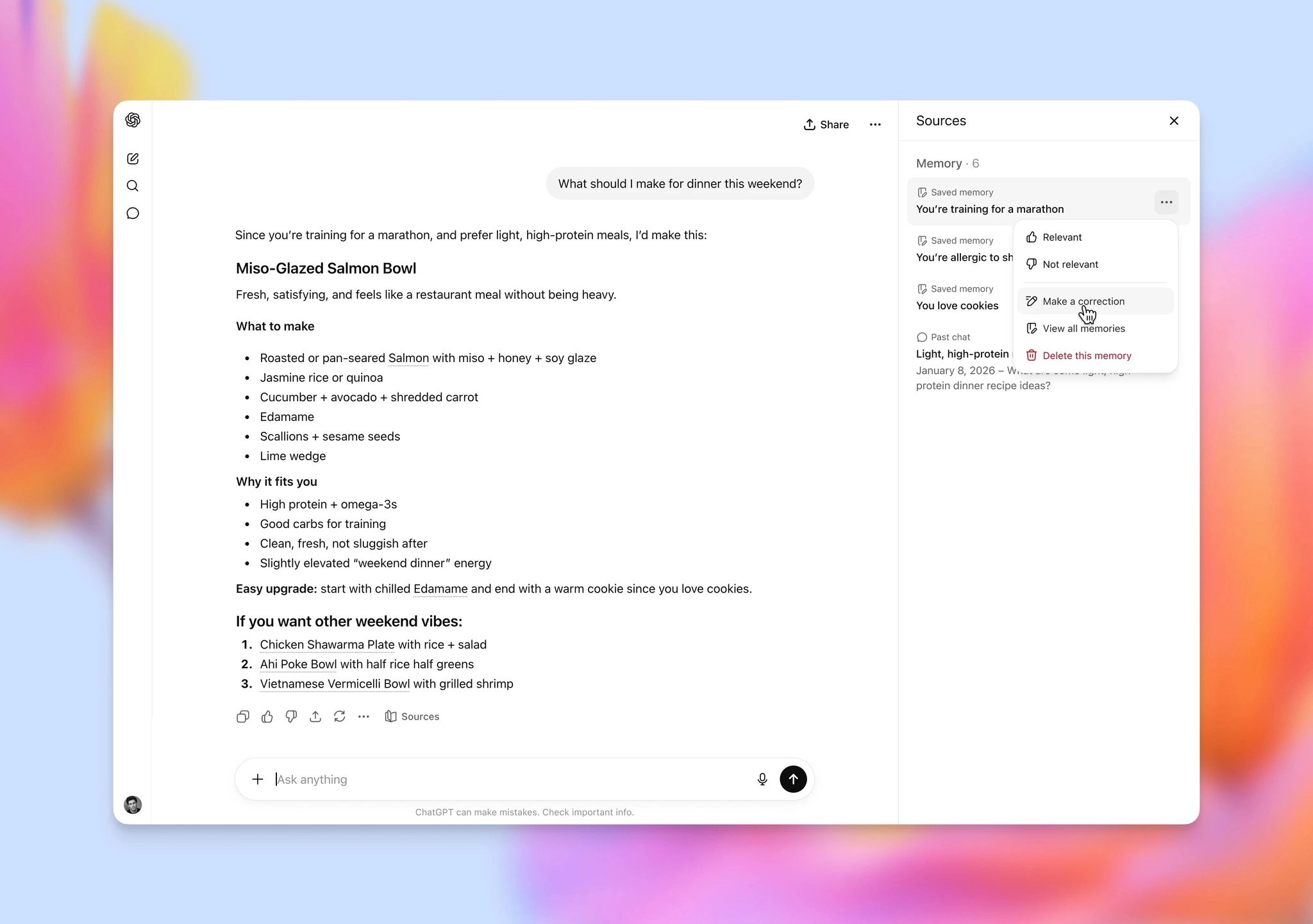
新功能引入:在 GPT 中引入了记忆来源功能。你可以通过控件可视化地查看 memory 来自什么地方,如果发现有问题,也可以直接编辑它。
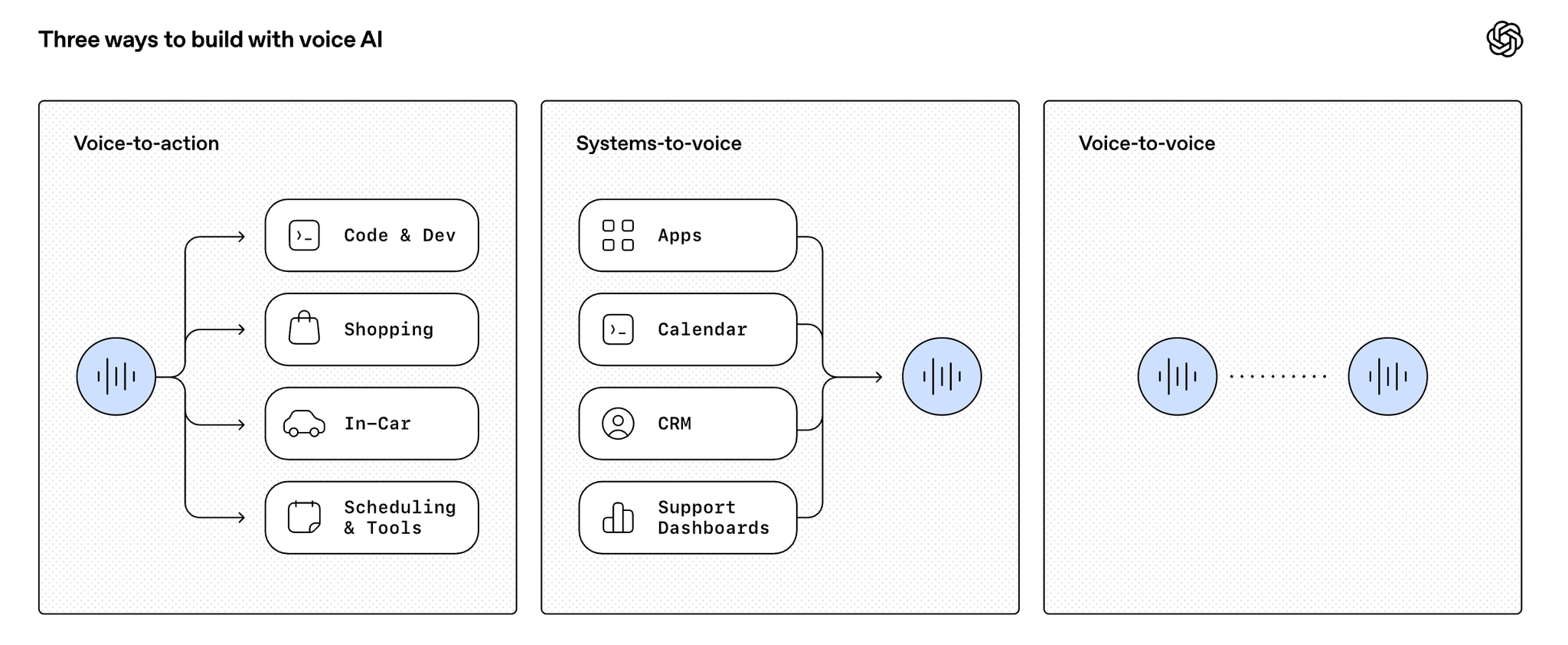
另外还推出了三个实时的语音模型。而且这次一反常态,没有将这些模型用在产品里面。
这可能是跟之前传言的 ChatGPT 与 Codex 合并的进度有关,估计会放到 Codex 里面。
GPT‑Realtime‑2、GPT‑Realtime‑Translate 和 GPT‑Realtime‑Whisper,目标是让语音成为人与软件交互的核心方式。相比传统“问一句、答一句”的语音助手,这些模型强调在对话中一边听一边想、一边调用工具、一边给出自然反馈,能处理更复杂的请求、保持上下文,并根据场景调整语气。
GPT‑Realtime‑2 主攻“语音 + 推理 + 工具调用”,支持并行调用工具、预响应短语、更长 128K 上下文和可调节的推理强度(从 minimal 到 xhigh),适合客服、搜索、运营等需要长对话和强决策的场景。GPT‑Realtime‑Translate 专注多语言实时翻译,支持 70+ 输入语言、13 种输出语言,面向客服、跨境销售、教育和内容出海等场景;GPT‑Realtime‑Whisper 则用于低延迟的流式转写,可做直播字幕、会议记录和实时语音理解。
Markdown 和 Html 的新共识
上周有两个我觉得比较有意思的讨论:Markdown 与 HTML 的分工。
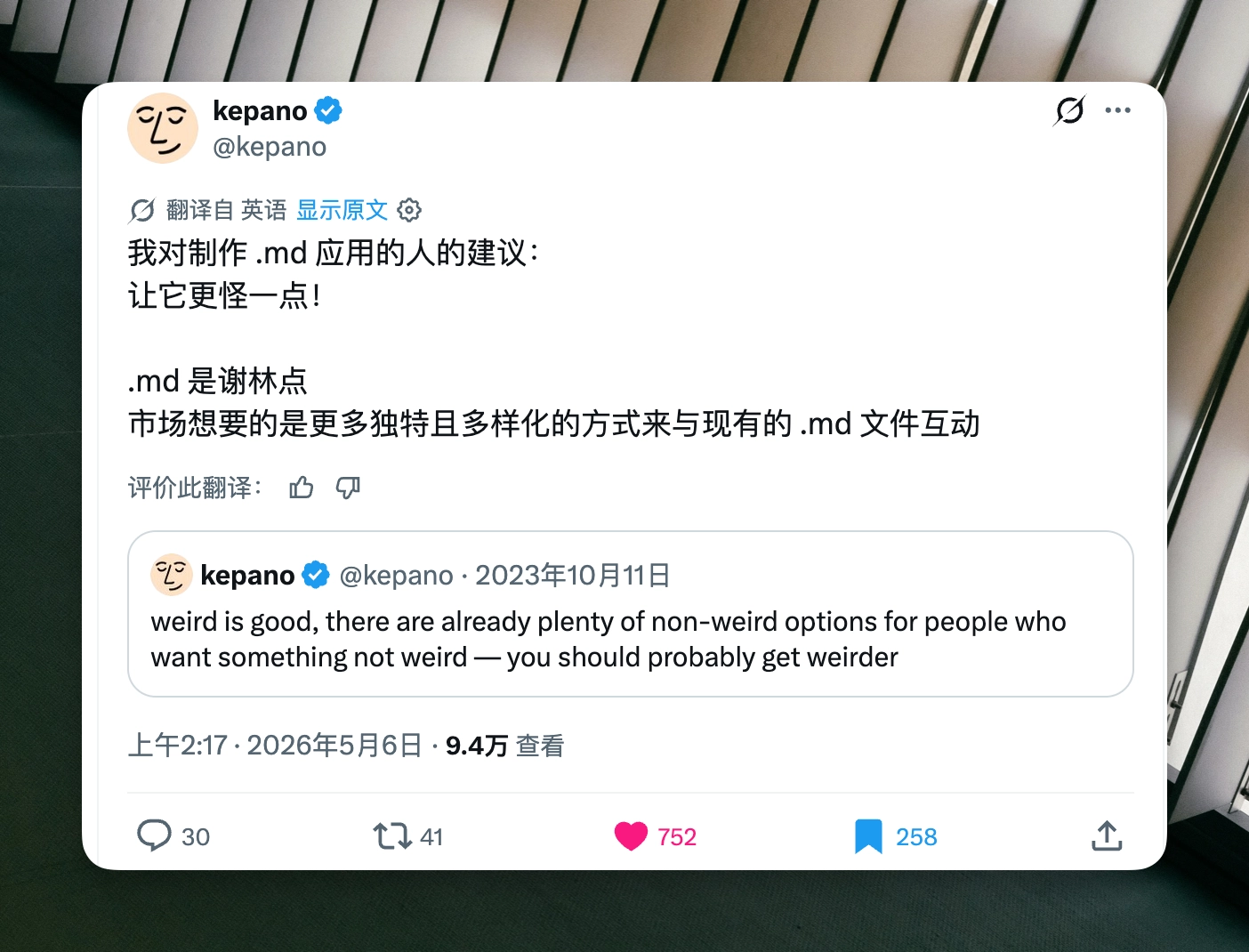
Obsidian 作者认为,Markdown 文件已经成为了 AI 文件交互的一个“谢林点”。
大家非常默契地将自己的文本系统变为 Markdown 后再进行其他工作,基本上 Markdown 已经赢得了 AI 时代文本格式的战争。
Claude Code 的作者提到,他对外分享的形式已经全面转向 HTML。
现在的趋势非常清晰:AI 的文件系统和格式就是 Markdown。
在展示时,将 Markdown 中的知识性内容(GC 内容)写成 HTML 展示给人类。给 AI 看的是 Markdown,它也能兼顾人类的理解;而 HTML 存在明显的痛点,比如版本控制非常困难,且因为混杂了大量的代码结构和样式等与事实无关的内容,并不适合直接给 AI 消费。
体系的演进:
数据层以 Markdown 为主,表现层以 HTML 为主。这表明 AI 产品终于从单纯的聊天,变成了一个可交互的 Artifact 体系。
之前的 Agent Memory 系统是以向量数据库为主,现在开始逐渐白盒化,转向 Markdown 体系,在各种数据库体系中的比重越来越重。
工作流的双向解耦:Markdown 和 HTML 的分工,解决了机器和人类在处理信息时的“抗阻不匹配”问题:
机器端:使用 Markdown。它不需要花哨的格式,只需要高密度的逻辑和内容。
人类端:人类是视觉动物,HTML 承担了将高维逻辑降维到可视化任务的职责,方便人类理解。
我感觉 AI 时代的新的协议,就会以这两个格式为核心去发展和演进。