封面提示词:Ruins of an ancient Western monastery, thick fog, a massive weathered ancient tree dominating the frame. Strong winds violently stretch the Klein blue and emerald green leaves in the same direction, forming abstract, flowing ribbons of color. Low-key and dark atmosphere, cold color palette. Leica coarse-grain film texture, master-level cold gray misty lighting, rich details in stone and bark textures, intense cinematic emotional storytelling.
上周藏师傅主要的工作内容如下:
- 迭代 CodePilot 重构的过程确实非常艰难。
- 维护 PPT Skill,很难想象它为什么会这么火,目前 GitHub Star 数马上就要突破一万了。
- 因为拿了真格基金的 Token Grant 奖项,最近接受了他们的一下专访。我把最近的一些想法和理解都写在这篇内容里了,感兴趣的朋友可以看看。
上周精选✦
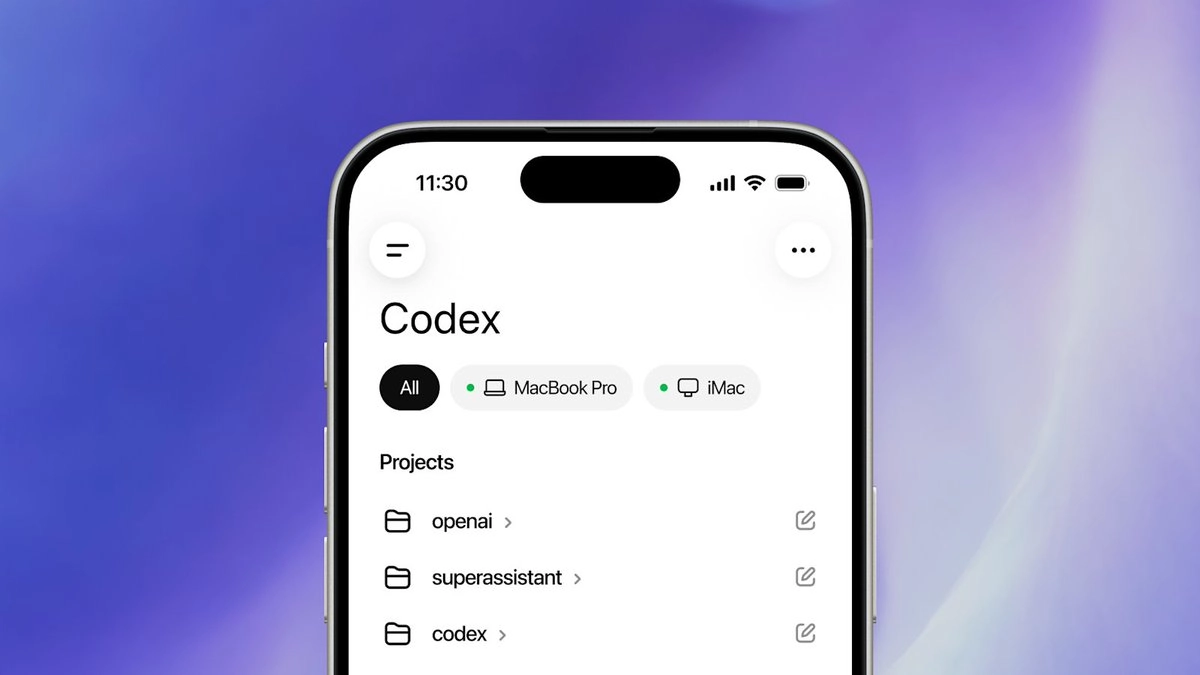
Codex 支持远程控制:Agent 进入云端-本地-移动端混合时代
CodeX 最近渗透率越来越高了,而且更新的能力一个比一个强。上周它终于支持手机上的 ChatGPT 远程控制,并且表现比 Cloud Code 的远程控制要更强。
除了支持正常的控制以外,还支持多个设备之间相互连接以及相互控制,支持远程的 SSH 连接,这可以玩出非常多的花样来。
可以自动同步你绑定的 Codex 设备上的所有对话,而且可以直接发送指令、审批权限、监控进度。
我写一下设置的教程:
- 点击桌面端 Codex 客户端左侧的“设置 Codex 移动版”,点击后系统会引导你开始设置。
- 如果你的 ChatGPT 没有设置多重因素验证(MFA),系统会弹出网页要求你设置。这里推荐使用 Google Authenticator(谷歌身份验证器)App,不要用手机短信。
- 系统会要求你使用手机 ChatGPT 客户端扫码。如果你直接打开手机端 App,它通常会弹出授权请求,直接点击允许即可,不扫码也是可以的。
- 绑定完成后即可开始使用。你会在手机 ChatGPT 上看到一个 Codex 侧边栏,进去后能看到当前绑定的桌面端设备的所有 Codex 对话。你可以点击进入任意对话并发送命令让它执行。
注意:目前仅支持 Mac 版 Codex,Windows 版本还在开发中。OpenAI 在封号上没有 Anthropic 那么激进和傻逼,所以你可以放心用。
而且 ChatGPT 可以控制你的多个设备的 Codex ,然后你可以在里面切换去发送信息。
Codex 除了用 ChatGPT 连接和远程控制以外,还可以在 Codex 再控制你的另一台电脑。这样你就可以在 ChatGPT 上直接控制多台电脑,而不用在 ChatGPT 切换设备,只需要切换项目就好。
比如我这个 Mac Book 的 Codex 可以读取他本地的文件,也可以直接读取我另一台 Mac Mini 的上下文和文件。说一下怎么做:
- 首先你去“设置”里的“连接”,选择“控制其他设备”。
- 在“控制其他设备”里点击加号,选择你其他已经安装 Codex 的设备。
- 选择完了以后,你需要在新聊天下的“选择工作区”里连接远程项目。
- 找到你另一个远程设备下需要让它访问的文件夹。
这样你就可以在 Codex 下看到另一个设备跑的项目,ChatGPT 选择这个设备时也能看到另一个设备的项目。它们的上下文就共享了。这个太有用了!
谷歌发布 Gemini Intelligence
谷歌安卓 I/O 大会最大的跟 AI 相关的发布,是发布了 Gemini Intelligence。会先在三星 Galaxy 和 Pixel 手机上推出,后面会拓展到其他所有类型的安卓设备。
具体功能上,首先它可以帮你自动完成在多个 App 上操作的繁琐任务,而且可以跨多个软件去操作。比如你备忘录里有一堆购物清单,然后你可以让它直接把这些清单加到购物车里。
安卓的 Chrome 浏览器可以自动帮你操作浏览器去检索内容和总结内容,也可以帮你填写表单之类的。
他们在新推出了一个语音输入功能,叫 Rambler,它可以自动将你的口语转换成文本语言,去掉一些语气词并重新排版,而且支持多语言混用。
最显眼的是它支持你通过自然语言去生成你想要的任何桌面小组件。比如说你可以让它生成一个每周推荐食谱的小组件,它就会自定义 AI 帮你生成,然后固定到你的桌面上。或者说你只关心某些天气的属性,比如说风速和降雨,然后它就会自动生成一个只有这些数据的桌面组件。
这个功能我在去年六七月的时候跟一个 AI 创业者提过,结果到现在谷歌自己出了。
而且他们这次还发布了 Material 3 Expressive 的设计语言,跟苹果的液态玻璃区别挺大的。它会在没有交互的时候是实体的边界,非常明显的分隔线,就是组件边界。在 AI 开始交互的时候,组件的边界会发生虚化和高斯模糊,非常的漂亮。

Thinking Machines 发布交互模型
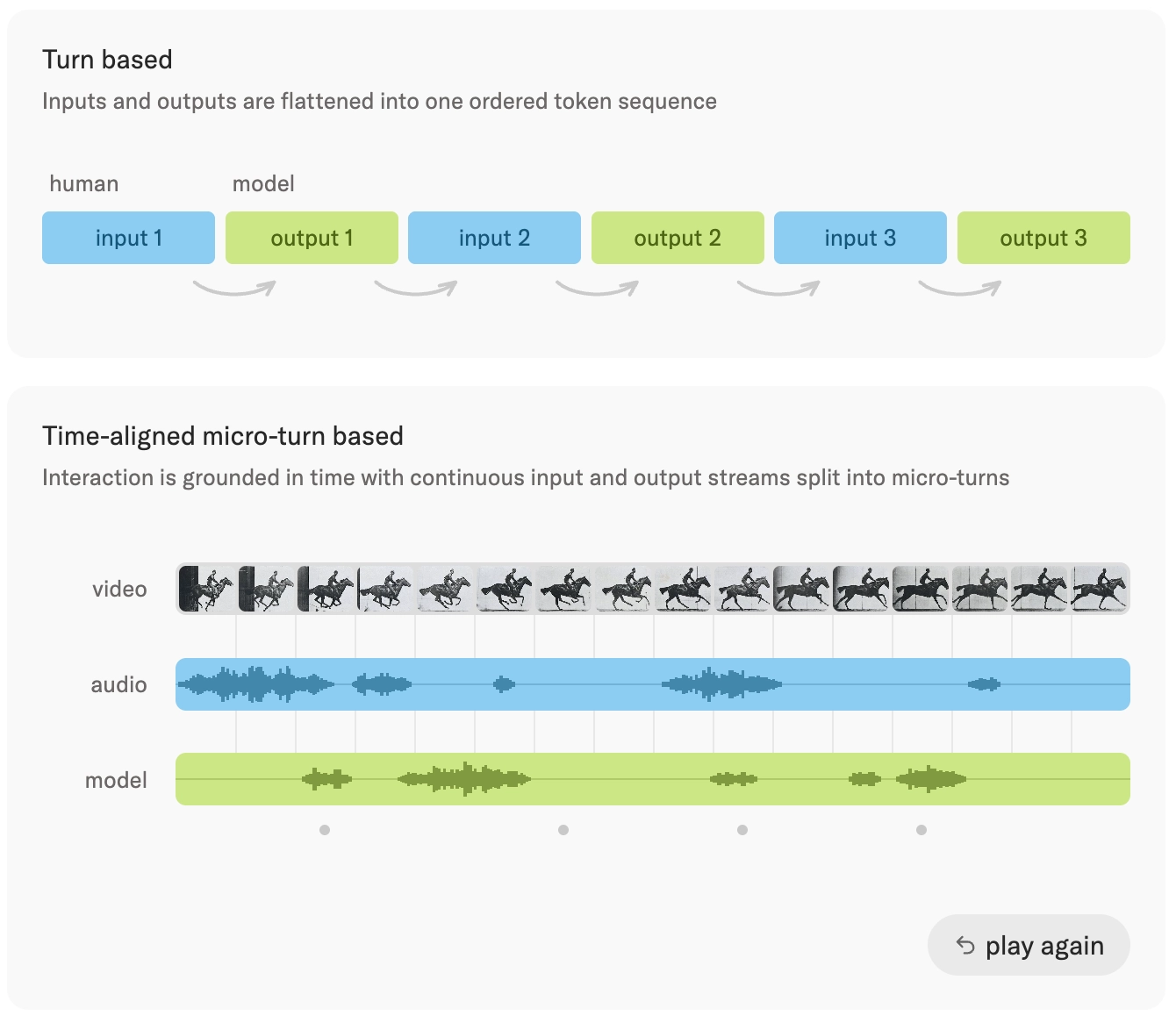
前 OpenAI CTO Mira 的公司 Thinking Machines 发了一个非常创新的模型,他们叫交互模型。这个模型能够持续接收音频、视频、文本等原生的多模态内容,并且实时进行思考、响应和行动。
它不像之前那种 Agent 脚手架,把多个模型、多个模态的模型通过 Agent 串起来,而是所有模态都在一整个模型里。这样就可以让用户和 AI 在任意模态下实时进行交互:
你可以随时打断它,随时进行补充,AI 会实时关注你的状态,输出结果,不会像之前一样,必须等一句话结束了才能跟模型交互。
核心思路就是把交互部分训练到了模型里。他们从零训练的这个交互模型主要包括两部分:
前台交互模型:
(a) 一直在线,一直在听、看和读用户提供的内容
(b) 每 200 毫秒作为一个节点,同时处理输入并产出一小段输出
(c) 负责照顾用户的在场感,支持用户打断、插话,并能对屏幕和视频内容做出反应
后台推理模型:
(a) 用来处理需要持续推理、工具调用以及长上下文、长规划的任务
(b) 交互模型会在合适的时候,将推理模型的结果放回到对话里,不会插入突兀的内容
用户最终看到的结果,就是一个既能实时交互,又能够处理重度任务的界面。