你有没有想过,为什么你刷抖音总是停不下来?为什么淘宝比你自己还了解你想买什么?
答案就在数据里。
AI的进步历程,本质上就是人类学会更好地收集、处理和利用数据的过程。从早期需要大量数据"喂饱"模型的时代,到现在追求高质量、精准数据的阶段,再到未来可能实现的"AI生成数据训练AI"的时代,每一步都是因为我们对数据的理解更深入了。
让我通过几个真实的故事来告诉你,数据的威力到底有多大。
故事一:抖音是怎么让你"上瘾"的?
你有没有发现,抖音的推荐简直像读心术一样准确?有时候连你自己都没意识到喜欢什么,它就推给你了。
这背后的秘密就是数据的精细化运用。
字节跳动的推荐算法被公认为全球最厉害的,不是没有原因的。他们每天要处理超过1000亿次推荐,而且每一次推荐都在学习。你在某个视频上多停留了几秒钟,你快速划过了哪些内容,你什么时候会点赞评论,甚至你手指滑动的速度,这些看起来微不足道的细节,都在为算法提供信息。
结果呢?抖音用户平均每天要刷95分钟。
故事二:Netflix如何"预测"你想看什么?
为什么Netflix的推荐总是那么准?据统计,Netflix用户观看的内容中,有80%都来自推荐系统的建议。也就是说,大部分时候不是你在选择看什么,而是Netflix在帮你选择。
这个"预测未来"的能力来自哪里?答案是对用户行为数据的深度挖掘。你什么时间看剧,看到哪里暂停了,快进了哪些片段,搜索了什么关键词,给了什么评分...每一个细微的动作都被记录下来,转化为算法理解你的依据。
更有意思的是,Netflix这几年做了一个重要的战略调整:从"算法优先"转向"数据优先"。他们发现,与其花大力气优化复杂的算法,不如专注于提升数据质量,效果反而更好。
故事三:一笔143亿美元的数据豪赌
就发生在这个月, Meta 将向 Scale AI 投资 143 亿美元,并将持有该公司 49% 的股份。你可能会想,这家公司是不是做了什么革命性的AI算法?
并没有。Scale AI专门做一件事:为其他科技公司提供高质量的训练数据。
这家公司不开发算法,不制造芯片,就是帮AI公司清洗数据、标注数据、管理数据。他们的客户包括特斯拉(自动驾驶数据)、OpenAI(语言模型数据)、甚至美国国防部。
Meta愿意花143亿美元买这家公司49%的股份,逻辑很简单:在AI竞争中,谁有更好的数据,谁就能胜出。并且从底层原始数据的设计方法上, 也能猜测这些公司在算法研究的探索方向。Scale AI的估值也从2021年的73亿美元飙升到现在的近300亿美元,4年时间涨了4倍。
在AI时代,专门做数据的公司可能比很多传统科技公司都值钱。
重新认识数据与AI的关系
数据是AI火箭的燃料:一个没有数据的AI模型,就像一枚没有燃料的火箭——只是一堆毫无生机的金属。无论这枚火箭的设计多么精良,材料多么先进,没有燃料,它永远不可能升空。只有注入了高质量、高相关性的数据,这枚"火箭"才能点火升空,发挥其巨大潜能。
AI是一面哈哈镜:这是一个更深刻也更具批判性的比喻。AI模型会忠实地反映其训练数据,但这种反映并非完美复刻,更像是一面哈哈镜的扭曲成像。它会放大并固化数据中存在的模式,包括那些隐藏的偏见和社会问题。如果训练数据中存在性别歧视,AI就会学会歧视;如果数据中充满了错误信息,AI就会传播错误。
AI是一座冰山,数据是海洋:我们日常与之交互的界面,如聊天机器人、推荐系统,仅仅是冰山的尖角。而在水面之下,是支撑其运行的庞大、复杂的基础设施、算法,以及最重要的——海量数据集。用户看到的智能表现,实际上是数据海洋中无数信息点的集合体现。
数据如何推动AI进步的?
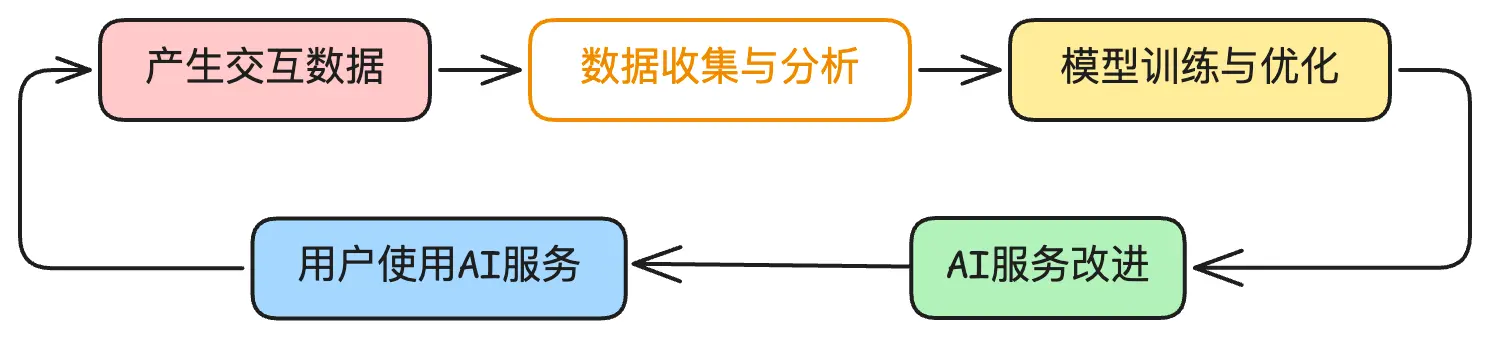
规模效应真的存在
从2012年的AlexNet(6000万参数)到现在的GPT-4(估计超过1万亿参数),AI模型的规模增长了上万倍。但更关键的是数据规模的增长:从早期的几万张图片,到现在的数万亿个文本token,数据的增长甚至超过了模型规模的增长。
质量比数量更重要
不过,业界逐渐意识到一个问题:盲目增加数据量并不总是有效的。OpenAI在训练GPT-4时,花了大量时间清洗和筛选数据,这是GPT-4比前代模型质量提升明显的重要原因。
多样性带来突破
现在的AI系统不再满足于单一类型的数据。多模态模型可以同时处理文字、图片、音频,这种数据的多样性让AI的能力大幅扩展。
实时学习形成闭环
最厉害的AI系统都有一个特点:能够从用户的反馈中持续学习。每一次互动都会产生新数据,这些数据又用来改进模型。特斯拉的自动驾驶就是这样,每辆车都是一个数据收集器。
AI如何"消化"数据
训练阶段:从原始数据到智能
训练AI很像人类婴儿学习的过程。当你要学会认识猫,需要看很多猫的照片,还需要有人告诉你"这是猫"。神经网络底层学习过程类似,但更加系统化。
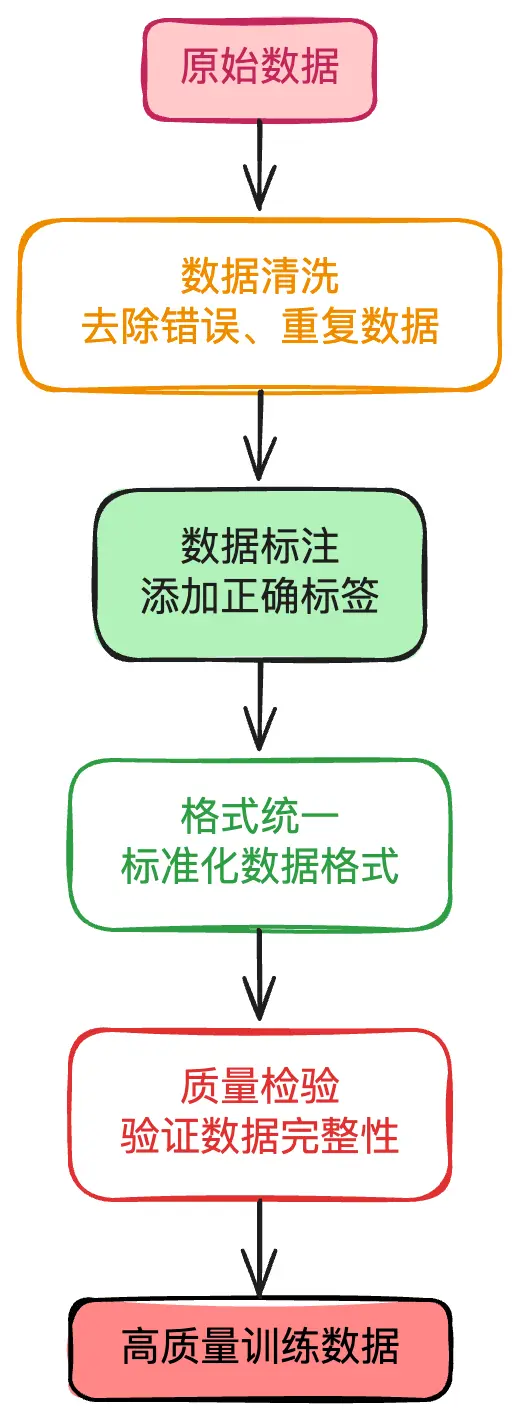
数据预处理:淘金的过程
原始数据就像含金的矿石,需要经过处理才能提取出价值。这个过程包括:
- 清洗:清理掉错误和重复的数据
- 标注:给数据加上正确的标签
- 格式化:把各种格式的数据统一起来
- 归一化:确保数据的质量和一致性
这一步通常占据整个AI项目80%的时间,但它是成功的基础。数据预处理的流程如下:
特征提取:让机器"理解"数据的艺术
机器不能直接理解图片中的猫或文本中的情感,需要将这些复杂信息转换为数字特征。现代深度学习模型能够自动学习这种转换,但理解这个过程仍然至关重要:
- 图像数据被转换为像素值矩阵
- 文本被转换为词向量或token序列
- 音频被转换为频谱图或波形特征
模型训练:学习的过程
训练就是让AI从大量例子中找规律。比如看了100万张猫的照片后,AI就能总结出猫的特征:有胡须、有尖耳朵、有四条腿等等。更多的是人类无法理解的升维抽象特征。这个过程中,数据的质量直接决定了AI学到的"知识"是否准确。
验证测试:考试的过程
训练完成后,需要使用独立的测试数据来验证模型的真实能力。这个环节同样依赖高质量的数据,因为测试数据的质量直接影响我们对模型能力的判断。
推理阶段:数据驱动的智能决策
个性化推荐:千人千面
每个用户都有独特的数据画像,AI系统通过分析这些个人数据,为每个用户提供定制化的服务。这不仅仅是简单的数据匹配,而是对用户偏好、行为模式、潜在需求的深度理解。
异常检测:发现不正常
通过学习大量正常数据的模式,AI能够识别出异常情况。这在反欺诈、网络安全、设备维护等领域非常有用。
几个典型应用的深度解析
推荐系统的数据魔法
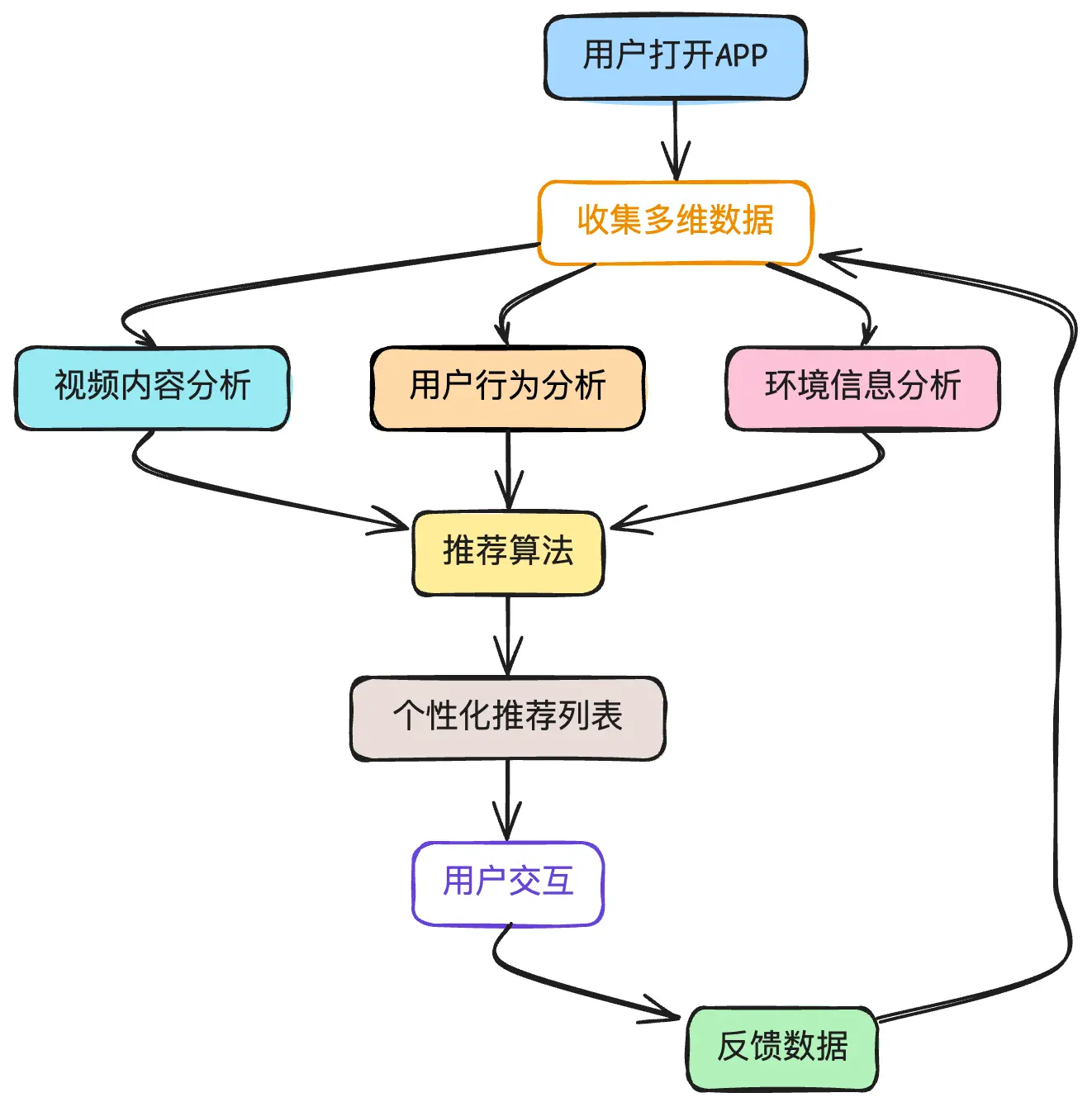
以抖音为例,他们的推荐系统处理的数据类型包括:
- 视频内容:通过AI识别视频中的物体、文字、音乐
- 用户行为:停留时间、完播率、点赞评论
- 环境信息:使用时间、设备类型、网络状况
- 社交互动:关注关系、分享频率
所有这些数据实时融合,为每个用户生成个性化的推荐。
自动驾驶的数据挑战
自动驾驶可能是对数据要求最高的AI应用:
- 特斯拉收集了超过30亿英里的真实驾驶数据
- 每辆车上8个摄像头提供360度视觉
- 雷达和传感器提供距离和速度信息
- GPS和地图提供位置和路况信息
所有这些数据需要实时处理,做出毫秒级的驾驶决策。
数据的双刃剑效应
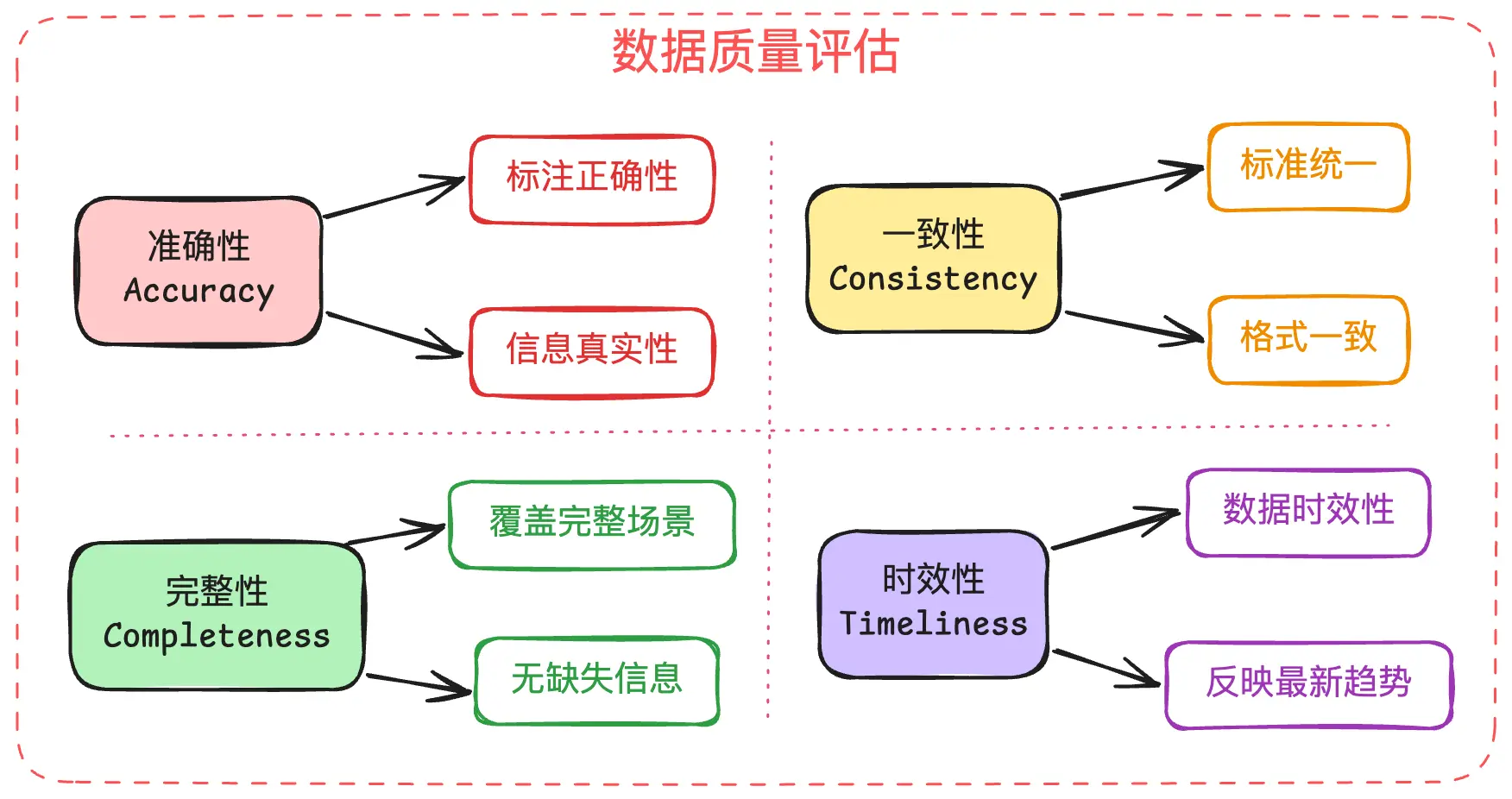
数量vs质量:更多不等于更好
2022年,特斯拉发布了FSD Beta新版本,很多用户发现自动驾驶的表现竟然变差了。这很奇怪,明明加入了更多的训练数据,为什么效果反而不好了?
原因在于数据质量出了问题:
- 新数据包含了太多边缘案例,干扰了对常见场景的判断
- 数据标注质量参差不齐,错误的标注比没有标注更危险
- 某些特殊场景的数据过多,导致模型过度关注这些场景
最后,特斯拉不得不回滚到之前的版本。这个教训告诉我们:数据的质量永远比数量更重要。
需要警惕的风险
风险一:偏见被放大
AI会忠实地学习训练数据中的所有模式,包括人类社会的偏见。
亚马逊曾经开发过一个AI招聘工具,结果发现它对女性候选人有明显的歧视。原因是训练数据主要来自过去的简历,而过去技术岗位男性占绝大多数,AI就"学会"了认为男性更适合技术工作。
这不是技术问题,而是社会问题。AI可能会固化甚至放大现有的不公平现象。
风险二:隐私和伦理问题
随着AI对数据的依赖越来越深,隐私问题也越来越突出:
- 训练数据的来源是否合法?
- 用户是否同意自己的数据被使用?
- AI模型会不会"记住"训练数据中的敏感信息?
微软的Tay聊天机器人是个典型例子。2016年发布后,仅仅24小时就被关闭,因为它学会了发表种族主义和歧视性言论。这说明AI系统可能被恶意利用,快速传播有害内容。
🔮 数据和AI的未来
正在形成的良性循环
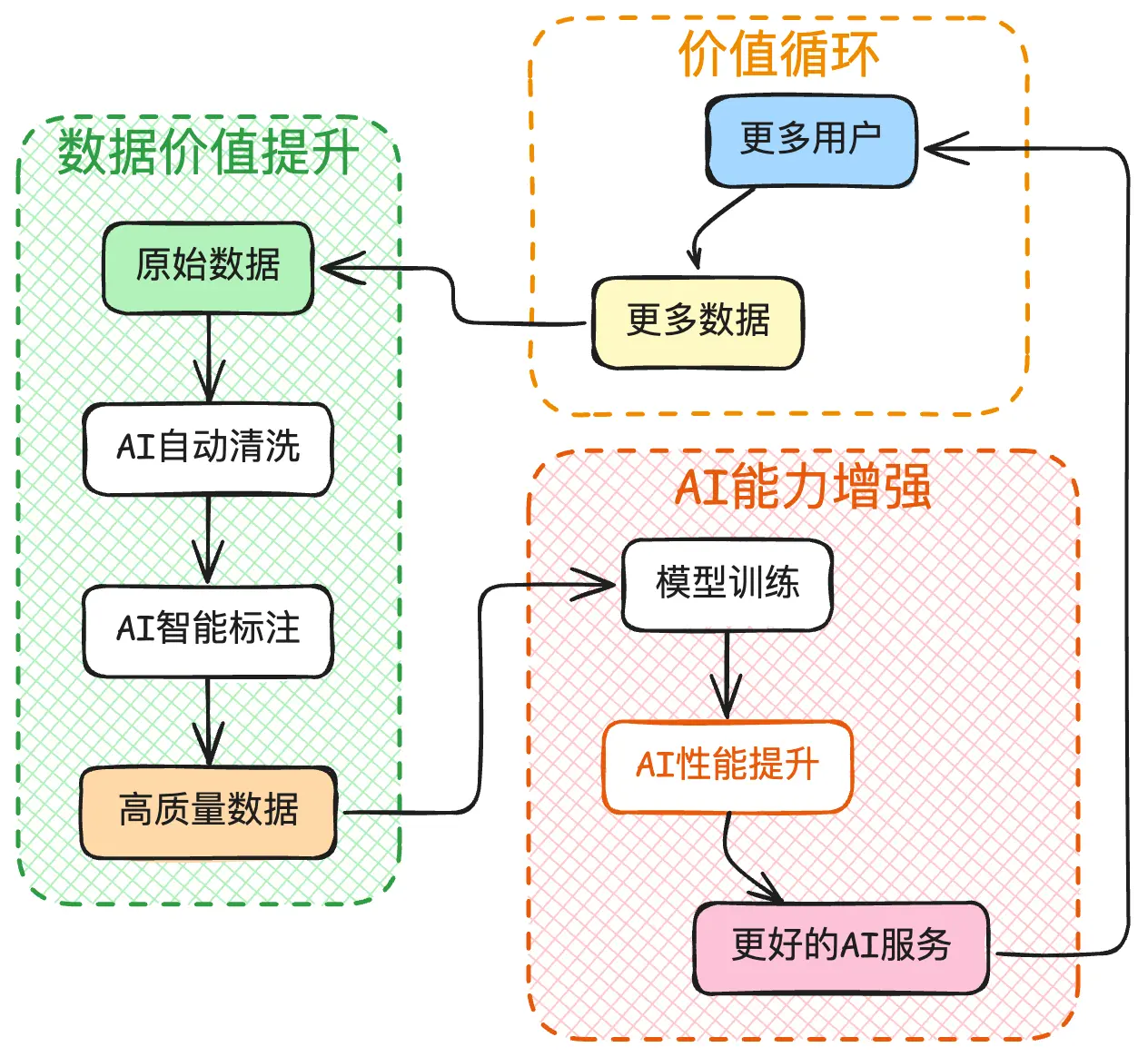
我们正在见证数据和AI之间形成一个前所未有的良性循环:
AI让数据更有价值
- AI可以自动清洗和标注数据,提高数据质量
- AI能发现数据中人类难以察觉的模式
- AI可以生成新的数据,补充现实数据的不足
数据让AI更强大
- 更多数据让AI的判断更准确
- 多样化数据让AI的应用更广泛
- 实时数据让AI能够持续改进
这种循环效应正在成为AI公司最重要的竞争优势。拥有数据优势的公司,往往能建立难以被超越的护城河。
几个值得关注的趋势
合成数据:AI造数据
我们正在进入一个新时代:AI不仅消费数据,也开始生产数据。通过生成式AI技术,我们可以创造出高质量的合成数据,用于训练新的AI模型。
这解决了很多领域数据稀缺的问题。比如医疗AI训练需要大量病例数据,但真实病例数据获取困难,合成数据就成了很好的补充。
联邦学习:数据不动,模型动
面对隐私保护的挑战,联邦学习提供了新思路:不需要收集原始数据,就可以让模型学习。
简单说就是:各方保留自己的数据,只共享学习到的模式。这样既保护了隐私,又实现了协作学习。
数据即服务:数据的新商业模式
数据正在成为一种新的服务形式。不再是简单的数据买卖,而是提供数据处理、分析、洞察的服务。这创造了全新的商业生态。
个人数据权益:你的数据你做主
随着数据价值的凸显,个人对数据控制权的意识也在增强。未来可能会有更多保护个人数据权益的技术和法律出现。
💭 一些思考
通过梳理数据与AI的关系,我想分享几个观点:
质量永远比数量重要
盲目追求数据数量可能适得其反。今年推出的很多大模型用更少的数据达到了更好的效果,训练成本更低,推理速度更快。
技术发展要与社会责任并行
AI偏见、隐私泄露这些问题提醒我们,技术进步必须考虑社会影响。我们需要在效率和伦理之间找到平衡。
理解数据与AI的关系是时代必修课
在这个数据驱动的时代,理解数据与AI的关系不仅对从业者重要,对每个人都很重要。因为我们每天都在与AI系统互动,都在产生和消费数据。
未来充满可能性
合成数据、联邦学习、数据即服务...这些新趋势告诉我们,数据与AI的故事才刚刚开始。未来会有更多令人兴奋的可能性。
数据与AI的深度融合正在重新定义我们的世界。理解这种关系,不仅能帮我们更好地使用AI工具,也能让我们更好地准备迎接即将到来的智能时代。