在上一篇文章中,我们探讨了Anthropic多智能体系统的基本概念,回答了“它是什么”以及“我们为什么需要它”的问题。我们了解到,将复杂任务分解,并利用多个智能体并行处理,可以显著提升解决问题的广度和深度,尤其是在处理开放式研究任务时。
然而,真正的挑战在于实践——“如何”构建一个高效、可靠的多智能体系统。如果说系统架构是智能体的骨架,那么提示词工程(Prompt Engineering)就是其神经系统,精确地指挥着这个复杂系统中每一个单元的行动与交互。一个精心设计的Prompt能够让智能体协同作战、高效运转;反之,一个模糊的Prompt则可能导致任务失败、资源浪费,甚至系统崩溃。
本文将深入探讨“如何实现”这一问题。我们将聚焦于一种日益普及的架构模式:“策划者-执行者”(Orchestrator-Worker)模型。通过深度剖析Anthropic在其官方Cookbook中最新公布的、针对这两种角色的官方Prompt范例,我们将揭示其背后的设计原则与工程智慧。理解这些Prompt,就如同掌握了一把打开高效能智能体系统大门的万能钥匙。
在深入细节之前,有必要先厘清一个关键的架构理念。Anthropic的研究明确区分了“工作流”(Workflows)和“智能体”(Agents)。
工作流遵循预先定义的静态路径,例如简单的提示链(Prompt Chaining)。
而智能体则更加自主,能够根据任务动态决定自己的路径。然而,完全自主的智能体可能难以预测、成本高昂且容易出错。
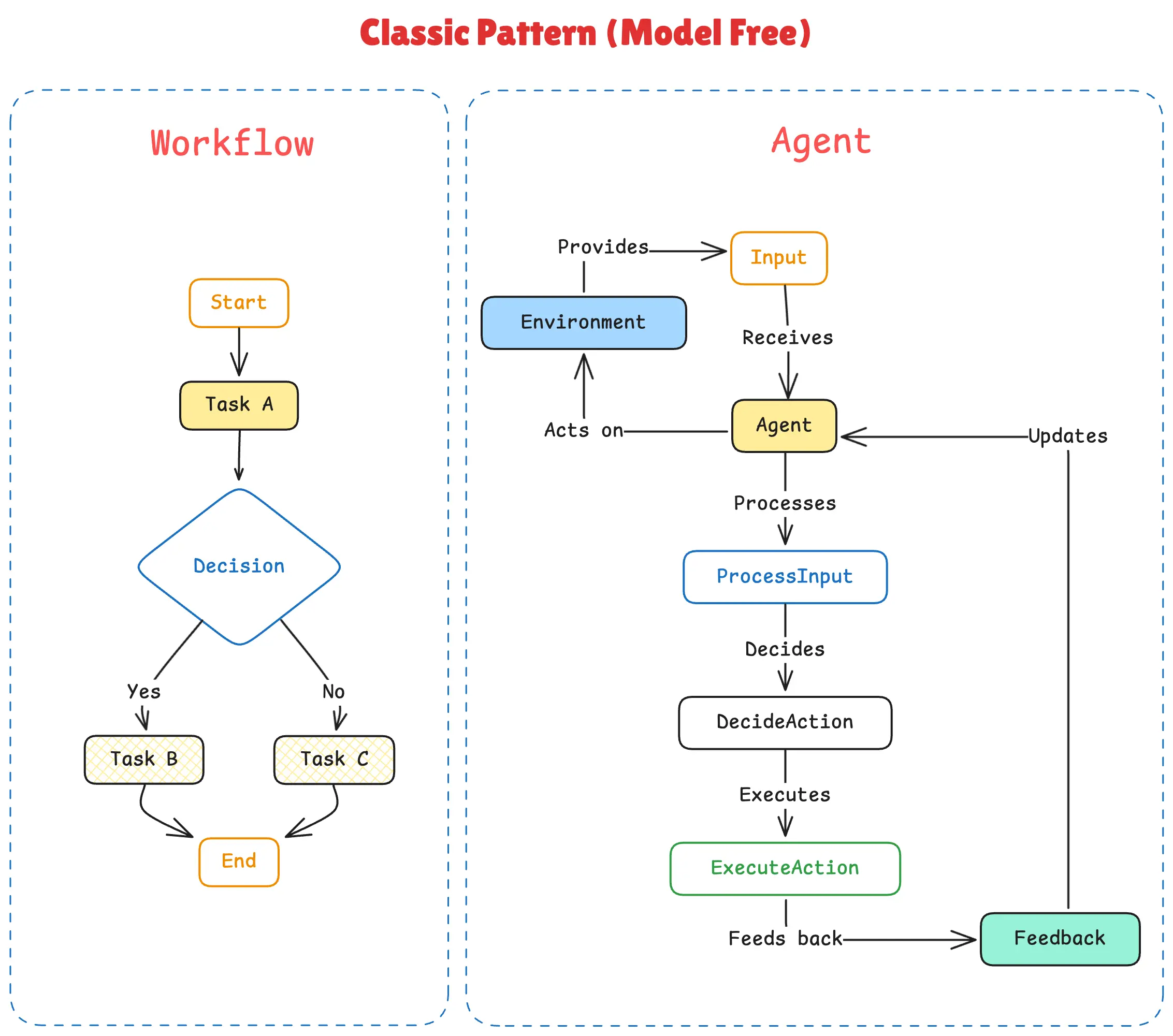
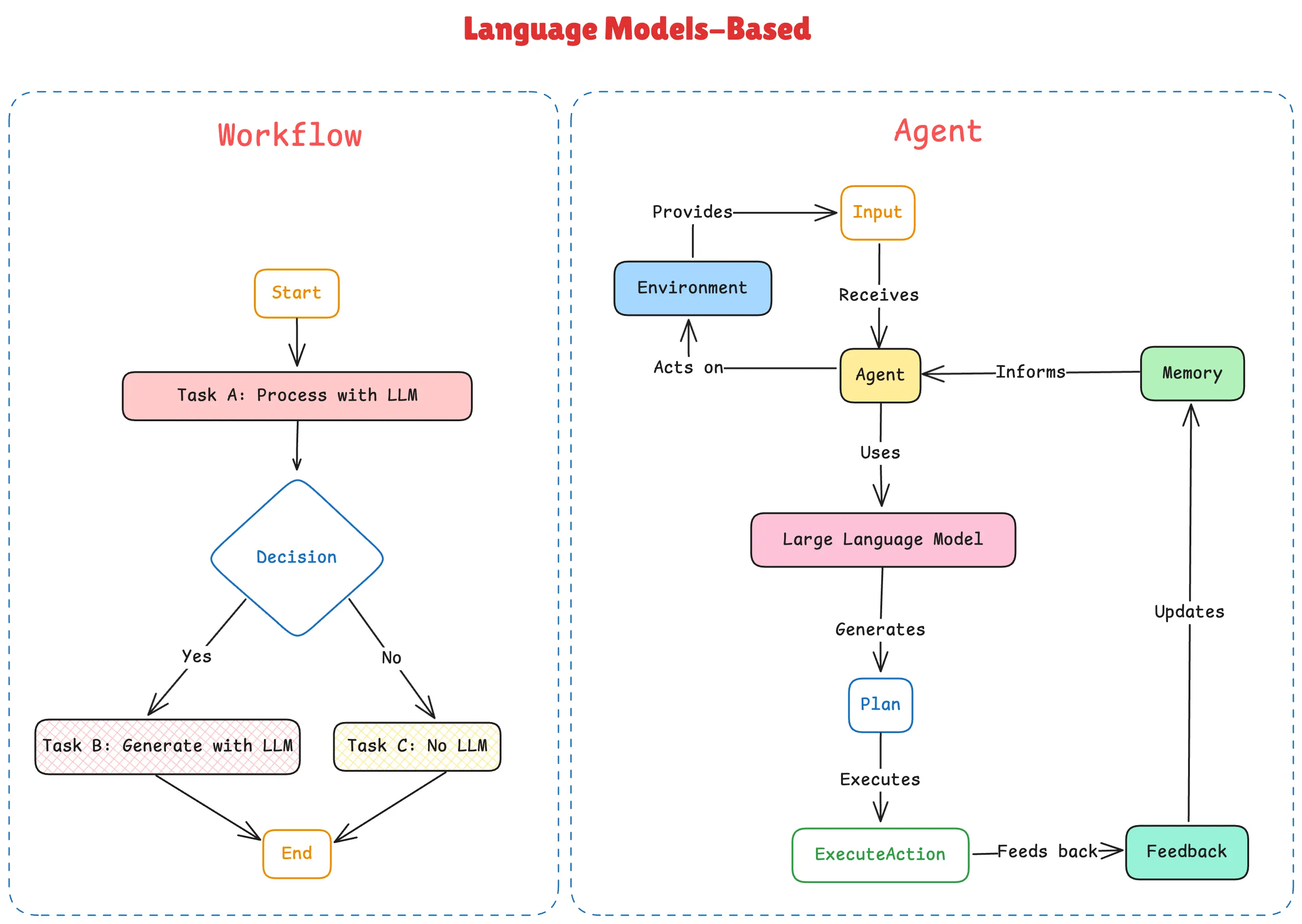
“策划者-执行者”模式为动态问题解决提供了一个结构化的框架。策划者(Orchestrator)负责进行高层次的动态规划,而执行者则在受控、可预测的工作流中完成具体任务。因此,这种架构不仅是为了实现并行化,更是一种在动态智能体行为的强大能力与工程化工作流的可靠性之间寻求平衡的关键设计选择。它是一种“被脚手架支撑的自主性”(Scaffolded Autonomy),确保系统在拥有智能的同时,依然保持稳定和高效。
层次化架构
Anthropic采用层次化的架构设计,包含以下关键角色:
- 研究主管智能体(Research Lead Agent):负责任务分析、规划和协调
- 研究子智能体(Research Subagent):执行具体的研究任务
- 引用智能体(Citations Agent):为报告添加准确的引用
- 专业化智能体:处理特定领域的任务
https://github.com/anthropics/anthropic-cookbook/tree/main/patterns/agents
Building Effective Agents Cookbook
研究主管智能体(Research Lead Agent)
策划者,或称研究主管(Research Lead),是整个多智能体系统的“大脑”和指挥中心。它的核心职责不是亲自执行任务,而是理解用户的高层意图,将其分解为一系列清晰、可执行的子任务,并分配给专门的执行者智能体。让我们逐一分析Anthropic官方 research_lead_agent.md Prompt中的关键设计。
定义使命与角色
Prompt的第一步,也是至关重要的一步,是为模型赋予一个明确的角色:“你是一位专业的研究主管……”(You are an expert research lead...)。这并非无关紧要的“客套话”。为模型设定一个角色,能够有效激活其在训练过程中学到的、与该角色相关的知识、行为模式和推理能力,使其在后续任务中表现得更加专业和专注。这直接践行了Anthropic官方文档中“赋予Claude一个角色(系统提示)”的最佳实践原则。
以下是一个策划者(Research Lead)Prompt的简化示例,它体现了角色定义、任务分解和并行化指令的核心思想:
# 中文版
你是一位专业的研究主管。你的目标是充分理解用户的请求,并制定详细的研究计划来解答。
你必须将用户的查询分解为一系列较小的、可并行执行的子任务。对于每个子任务,你将为子智能体创建一个特定的、独立的提示。
每个子智能体任务提示必须包含:
1. **目标**:为子智能体设定一个明确的目标。
2. **指导**:关于使用哪些来源(例如,“使用网络搜索并关注过去两年的学术论文”)以及应避免哪些内容的具体说明。
3. **输出格式**:对输出格式的严格要求,例如具有特定架构的 JSON 对象,以确保结果能够以编程方式解析。
<use_parallel_tool_calls>
为了实现最高效率,你必须使用并行工具调用来同时启动多个子智能体(通常为 3-5 个)。除非任务本身相互依赖,否则请勿按顺序运行它们。
</use_parallel_tool_calls>
根据子智能体的发现,你将综合最终答案。如果初始结果不充分,你将根据更新后的计划创建并调度新一轮子智能体,从而继续研究。这遵循“观察、调整、决策、行动”(OODA)进行循环优化。
# English Version
You are an expert research lead. Your goal is to fully understand a user's request and create a detailed research plan to answer it.
You must break down the user's query into a series of smaller, parallelizable sub-tasks. For each sub-task, you will create a specific, self-contained prompt for a sub-agent.
Each sub-agent task prompt must include:
1. **Objective**: A single, clear goal for the sub-agent.
2. **Guidance**: Specific instructions on what sources to use (e.g., "Use web search and focus on academic papers from the last 2 years") and what to avoid.
3. **Output Format**: A strict requirement for the output format, such as a JSON object with a specific schema, to ensure the results can be programmatically parsed.
<use_parallel_tool_calls>
For maximum efficiency, you MUST use parallel tool calls to launch multiple sub-agents (typically 3-5) at the same time. Do not run them sequentially unless the tasks are inherently dependent on each other.
</use_parallel_tool_calls>
Based on the sub-agents' findings, you will synthesize the final answer. If the initial results are insufficient, you will continue the research by creating and dispatching a new wave of sub-agents based on an updated plan. This follows an Observe, Orient, Decide, Act (OODA) loop.
授权的艺术:策划者的核心
策划者最关键的职能是任务授权。Anthropic的博客明确指出,像“研究半导体短缺”这样模糊的指令是失败的根源,会导致多个子智能体重复同样的工作,或者遗漏关键的研究领域 。因此,策划者的Prompt必须教会它如何有效地进行任务分解和授权,其核心要素包括:
- 明确的目标(Objective):为每个子智能体设定一个单一、清晰的目标。
- 指定的输出格式(Output Format):要求子智能体以结构化格式(如JSON)返回结果,便于后续的程序解析和整合。
- 工具与信源指导(Guidance on tools and sources):指明每个子智能体应该使用哪些工具和信息来源。
- 清晰的任务边界(Task Boundaries):确保子任务之间没有重叠,避免资源浪费。
这种精细化的任务分解背后,隐藏着更深层次的工程考量:成本控制与性能保障。多智能体系统由于其并行和深度交互的特性,其Token消耗量巨大,可能是普通聊天交互的15倍之多,这直接关系到其经济可行性。同时,单个、长时运行的智能体容易遭遇“上下文退化”(Context Rot)问题,即随着上下文窗口被大量无关信息填满,其推理和输出质量会急剧下降。
采用多个并行的、拥有各自独立“干净”上下文窗口的子智能体,是解决这一问题的核心架构方案 。因此,策划者Prompt中的精细化授权指令,就不仅仅是为了保证结果的准确性,它更是一种至关重要的经济和性能调节器。通过强制策划者生成定义明确、互不重叠的子任务,Prompt直接将冗余的Token消耗降至最低,并防止了子智能体之间的互相干扰。一个设计拙劣的策划者Prompt,不仅会产出糟糕的结果,更会导致一个经济上无法为继的系统。
强制提升效率:并行化与适应性规划
为了确保系统性能,我们不能仅仅依赖模型的自发行为,而必须将关键行为模式直接“硬编码”到Prompt中。在策划者的Prompt里,可以发现类似这样的强制性指令:
<use_parallel_tool_calls>为了达到最高效率,当你需要执行多个独立操作时,应同时调用所有相关工具,而不是顺序调用。你必须使用并行工具调用来同时启动多个子智能体(通常是3个)...
这表明,对于并行化这类对性能至关重要的特性,必须通过明确的指令来强制执行,而非“建议”模型这样做。
此外,Prompt还引导策划者遵循一个结构化的思考循环,即OODA循环(观察Observe, 定向Orient, 决策Decide, 行动Act) 1。这为模型提供了一个心智模型,使其能够基于从子智能体处获取的新信息,持续地观察当前进展、调整整体方向、决策下一步行动,并最终执行。这使得策划者不仅仅是一个静态的任务分配器,更是一个能根据战况动态调整策略的指挥官。
研究子智能体(Sub-Agent)
如果说策划者是运筹帷幄的将军,那么执行者(Sub-Agent)就是令行禁止、高效执行任务的专家士兵。其Prompt(research_subagent.md)的设计目标是专注与精确,完美地接收并完成来自策划者的指令。
接收指令:智能体-计算机接口(ACI)
执行者的Prompt通常不包含开放式的规划指令,而是围绕着一个从策划者那里接收到的、明确定义的task变量展开。这体现了**智能体-计算机接口(Agent-Computer Interface, ACI)**的核心理念。执行者的Prompt,连同其可用的工具集,共同构成了这个接口。
以下是一个执行者(Sub-Agent)Prompt的简化示例,重点在于其专注的执行角色和对OODA循环的遵循:
You are a research sub-agent. You will be given a specific, self-contained task by a research lead. Your goal is to execute this task thoroughly and efficiently.
You have access to the following tools: [List of tools, e.g., web_search, read_file].
Your task is:
<task>
{{task_from_lead}}
</task>
To complete your task, you must follow an OODA loop:
1. **Observe**: Analyze the information you have and what you still need.
2. **Orient**: Decide which tool is best for the next step.
3. **Decide**: Formulate the precise input for the chosen tool.
4. **Act**: Execute the tool.
Repeat this loop until you have gathered all necessary information to complete the task.
Once you are finished, you MUST return your findings in a single JSON object, as specified in the task description. Do not add any conversational text outside of the JSON object.
Anthropic的研究反复强调,工具的设计和选择至关重要 。一个糟糕的工具描述会“让智能体走上完全错误的道路”。这揭示了Prompt和工具描述之间密不可分的共生关系。它们并非独立存在,而是构成了ACI的两面。执行者的Prompt告诉它“做什么”(例如,“找出净销售额”),而工具的描述则告诉它“怎么做”(例如,“使用pdf_image_extractor工具处理PDF中的表格”)。
Anthropic甚至为此创建了一个“工具测试智能体”,该智能体可以自动尝试使用有缺陷的工具,并重写其描述以避免未来的失败 。这足以证明工具描述的重要性。事实上,Anthropic官方文档指出,为工具提供“极其详尽的描述”是“迄今为止影响工具性能最重要的因素”。因此,一个优秀的执行者Prompt不仅要清晰地陈述任务,还应包含一些启发式规则,以帮助智能体更好地理解和选择工具,例如“优先使用学术来源”或“从宽泛的查询开始,然后逐步缩小范围” 。
工具使用示例
- **ALWAYS use internal tools** for tasks requiring personal data or internal context
- ALWAYS use `web_fetch` to get complete contents of websites
- Avoid using analysis tools for simple calculations
- Execute a MINIMUM of five distinct tool calls, up to ten for complex queries
<maximum_tool_call_limit>
To prevent overloading the system:
- Stay under 20 tool calls and 100 sources maximum
- When you reach 15 tool calls, stop gathering sources and compose your final report
- Avoid continuing when you see diminishing returns
</maximum_tool_call_limit>
精确执行、汇报与自我评估
执行者的另一个关键任务是精确执行并以结构化的方式汇报结果。其Prompt会强制规定一个可靠的输出格式,例如:“在你的最终答案中,提供一个包含……的JSON对象”。对于一个需要与其他程序(例如策划者)进行交互的系统而言,这种结构化的输出是保障系统稳定性的基石。
更进一步,执行者的Prompt中也内置了“批判”和“评估”的元素。例如,它会被要求在内部思考过程中评估信源的质量(<think_about_source_quality>),或者在最终输出中包含引文,这促使另一个专门的citations_agent(引文智能体)来核实信息的来源和准确性 。这种设计将质量控制的责任分散到执行的每一个环节中,而不是完全依赖一个独立的“批判者”,从而构建了一个更具韧性和可靠性的系统。
引用智能体(Citations Agent)
在任何严肃的研究中,可信度都至关重要。一个没有事实依据的结论是毫无价值的。为了解决这个问题,并系统性地对抗模型幻觉,Anthropic的架构中引入了一个至关重要的角色:引文智能体(Citations Agent)。这个智能体是整个系统的“事实核查员”,其重要性不亚于策划者和执行者。
引文智能体的核心任务是确保研究的完整性和可验证性。它并非进行宽泛的、主观的“批判”,而是执行一个非常具体、客观的任务:为最终报告中的每一项关键声明,找到其在原始资料中的确切出处。这正是Anthropic在其Citations API中所实现的功能,旨在将可验证性直接构建到AI应用的核心中。
citations_agent.md的Prompt设计会围绕以下几个核心原则展开:
- 高度专注的角色定义:Prompt会赋予其一个极其明确的角色:“你是一个一丝不苟的事实核查员。你的唯一任务是验证一个给定的声明,并在提供的源文件中找到支持该声明的、一字不差的引文。”
- 清晰的输入/输出:该智能体接收两个关键输入:一个是从报告中提取的
<statement>(待验证声明),另一个是包含所有原始研究材料的<sources>(源文件)。其输出被严格规定为一个结构化对象(如JSON),其中包含布尔值is_supported和citations数组,数组中是具体的引文文本和来源标识。 - 严格的匹配标准:Prompt会强调匹配的严格性。“不要找相似或相关的内容,必须找到能够直接、明确支持该声明的句子。” 这条指令至关重要,可以防止智能体为了“完成任务”而提供弱相关的、误导性的引文。
- 明确的失败路径:“如果在源文件中找不到任何能够直接支持该声明的引文,你必须明确报告‘无法找到支持性引文’。” 这为系统提供了一个清晰的信号,表明某条信息可能存在幻觉或来源不明,策划者可以据此决定是舍弃该信息还是启动新一轮的核查。
通过引入这样一个专门的引文智能体,整个多智能体系统建立起了一道关键的质量防线。它将“可信度”从一个模糊的概念,转化为一个可以被程序化验证、自动执行的流程,极大地提升了最终研究报告的可靠性与价值。
XML标签与时间锚定
接下来我们深入到Prompt的“微观结构”中,才能真正领会其设计的精妙之处。Prompt中反复出现的<tag></tag>结构和{{.CurrentDate}}变量,这正是Anthropic Prompt工程的两大“秘密武器”。
结构化思考的利器
XML(eXtensible Markup Language)标签是一种结构化数据格式,使用尖括号 <> 包围标签(如<task>、<research_process>)名来标记和组织内容。在Anthropic的多智能体系统中,XML标签被用作提示词的结构化组织工具。
为什么使用XML标签?
- 明确的结构分离:XML标签为Prompt提供了清晰的结构,能够将指令、上下文、示例和用户输入等不同部分明确分开。这就像为模型的大脑划分了不同的功能区,防止它将指令误解为上下文,或将示例错当成需要执行的任务,从而显著提升了准确性和可靠性。
传统提示词方式的问题:
你需要做研究,然后分析结果,还要注意信息源质量,最后写报告。记住要检查数据准确性,避免偏见,确保逻辑清晰...
XML标签方式的优势:
<research_process>
1. 收集信息
2. 分析数据
3. 验证准确性
</research_process>
<quality_control>
- 检查信息源可靠性
- 避免认知偏见
- 确保逻辑一致性
</quality_control>
<output_format>
生成结构化报告
</output_format>
-
引导思维链(Chain of Thought):像
<think_about_source_quality>、<research_process>这样的标签,其作用远不止是分隔符。它们为模型创造了一个“暂存区”或“草稿纸”(Scratchpad)。通过要求模型在这些标签内先进行思考、规划和自我评估,再在<answer>或<synthesized_text>等标签中给出最终答案,我们实际上是在强制模型执行“思维链”(Chain of Thought)推理。这种“先思考,后回答”的模式,是提升复杂任务解决能力最有效的技术之一。 -
可解析的输出:当要求模型在其输出中也使用XML标签时,这使得后续的程序(如策划者智能体)可以非常方便和可靠地解析模型的响应,提取所需信息。
Anthropic通过简单的代码提取XML标签中的内容:
def extract_xml(text: str, tag: str) -> str:
"""提取XML标签中的内容"""
match = re.search(f'<{tag}>(.*?)</{tag}>', text, re.DOTALL)
return match.group(1) if match else ""
- 认知负载管理 - 帮助AI聚焦
XML标签相当于给AI提供了认知框架,让AI知道:
- 现在应该做什么(当前在哪个标签内)
- 怎么做(标签内的具体指令)
- 输出什么格式(输出标签的要求)
总而言之,XML标签是实现结构化、可控和高质量智能体行为的关键工具。
XML标签的功能分类
1. 流程控制标签
<research_process>: 定义完整的工作流程<delegation_instructions>: 任务委派指令<answer_formatting>: 答案格式化要求
2. 质量保证标签
<think_about_source_quality>: 信息源质量评估<research_guidelines>: 研究指导原则<important_guidelines>: 重要指导方针
3. 资源管理标签
<subagent_count_guidelines>: 智能体数量指导<maximum_tool_call_limit>: 工具调用限制<use_parallel_tool_calls>: 并行工具调用指导
4. 输入输出标签
<synthesized_text>: 输入的综合文本<exact_text_with_citation>: 输出的带引用文本<reasoning>: 推理过程<selection>: 选择结果
对抗知识截止的法宝:时间锚定
prompt有一行代码
The current date is {{.CurrentDate}}.
这行指令,虽然简短,却至关重要。所有的大语言模型都有一个“知识截止日期”,即它们的训练数据只包含截止到某个时间点的信息。这导致模型本身对“此时此刻”是没有概念的。
通过在Prompt中明确注入当前日期,我们为模型提供了一个时间锚点(Temporal Anchor)。这赋予了模型关键的时间感知能力,使其能够:
- 正确理解相对时间:当指令中包含“过去两年”、“上个季度”或“最近”等词语时,模型能够基于给定的当前日期进行准确计算。
- 获取最新的信息:在执行网页搜索等任务时,模型会更有意识地去寻找和优先处理最新的信息,而不是依赖其过时的内部知识。
如果缺失这个时间锚点,智能体在处理任何与时间相关的研究时,会默认成他由训练数据所产生的当下的幻觉时间, 而这个幻觉时间和实际时间之间会有不同程度延迟(6-12个月), 因此会影响其研究结果,甚至得出完全错误的结论。
案例实战 - 多智能体分析财务报告
理论的价值最终要在实践中体现。现在,让我们看这个“策划者-执行者”系统是如何协同工作的。
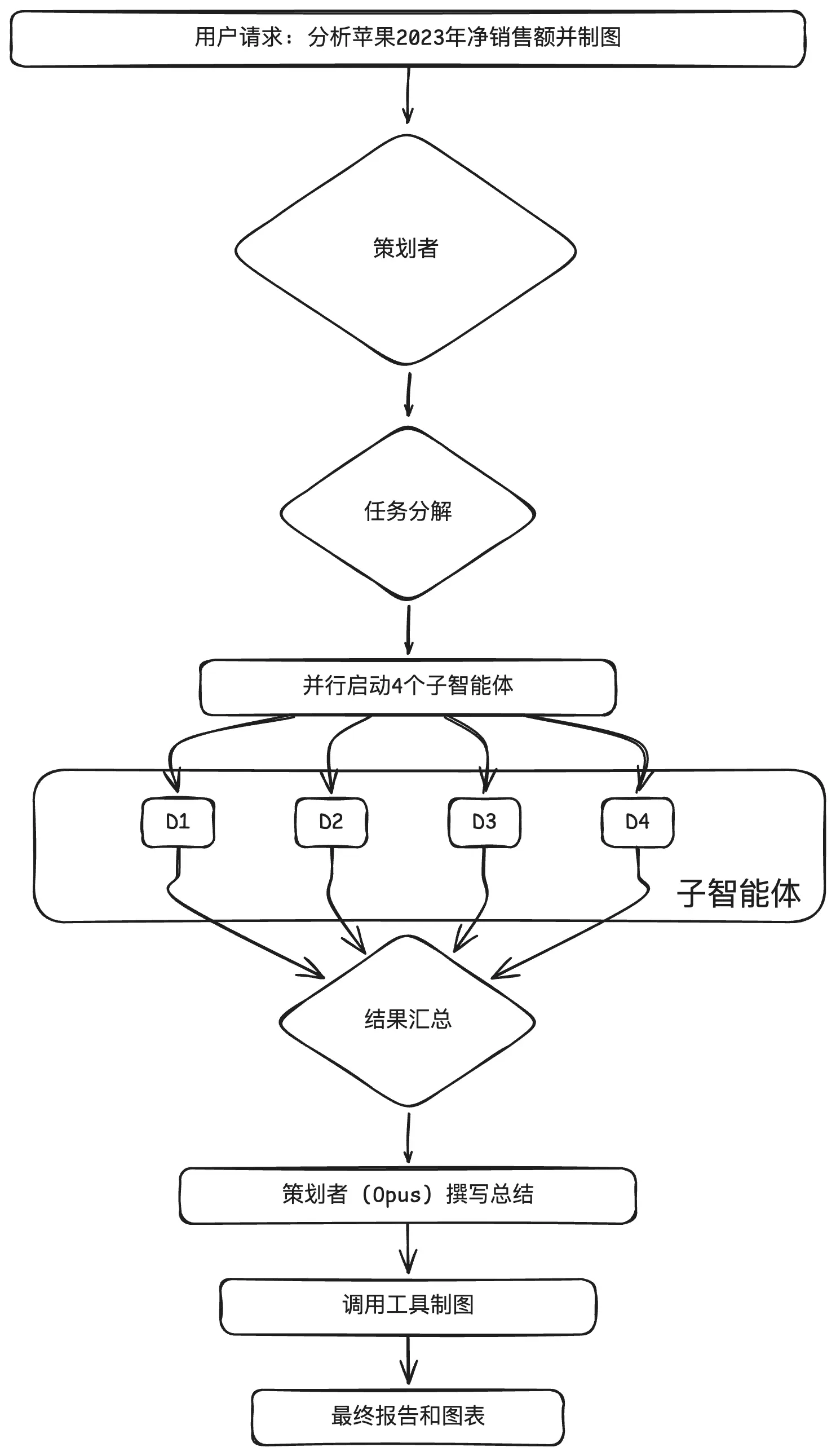
第一步:环境设置与客户端初始化
在任何操作开始之前,需要安装必要的库并初始化Anthropic客户端。
# 安装必要的库
# %pip install anthropic IPython PyMuPDF matplotlib
# 导入库并设置客户端
import fitz # PyMuPDF
import base64
from PIL import Image
import io
from concurrent.futures import ThreadPoolExecutor
from anthropic import Anthropic
import requests
import os
# 设置Anthropic API客户端
client = Anthropic()
# 为子智能体选择一个快速且成本效益高的模型
SUB_AGENT_MODEL = "claude-3-haiku-20240307"
# 为策划者选择一个更强大的模型
ORCHESTRATOR_MODEL = "claude-3-opus-20240229"
第二步:定义子智能体任务
策划者需要将高层级任务分解为可以分配给子智能体的具体、独立的任务。在这个案例中,核心任务是从单个PDF文件中提取财务数据。由于PDF中的表格难以直接解析,代码选择将PDF页面转换为图像,利用Claude 3的多模态能力来“读取”图像。
# 定义一个函数,让子智能体处理单个PDF
def process_pdf_task(pdf_path):
"""
一个子智能体任务:接收PDF路径,将其转换为图像,
并调用Claude Haiku提取净销售额。
"""
# 将PDF页面转换为Base64编码的PNG图像列表
base64_images = pdf_to_base64_pngs(pdf_path)
# 构建发送给子智能体(Haiku)的消息
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/png",
"data": image,
},
}
for image in base64_images
]
}
]
# 调用Haiku模型执行任务
response = client.messages.create(
model=SUB_AGENT_MODEL,
max_tokens=1024,
messages=messages
)
return response.content.text
第三步:并行执行
这是多智能体架构效率优势的核心体现。策划者使用Python的ThreadPoolExecutor来同时启动多个子智能体,每个智能体处理一个季度的财报。
# pdf_paths 是一个包含4个季度财报PDF文件路径的列表
#...
# 使用ThreadPoolExecutor并行处理所有PDF
with ThreadPoolExecutor() as executor:
# 将process_pdf_task函数映射到每个PDF路径上
results = list(executor.map(process_pdf_task, pdf_paths))
# `results` 将会是一个包含4个JSON字符串的列表,
# 每个字符串都是一个子智能体的输出
# e.g., ['{"net_sales": 94836}', '{"net_sales": 89498}',...]
第四步:结果汇总与最终输出
所有子智能体完成任务后,策划者(Opus模型)接收这些结构化的JSON结果。它的最终任务是汇总这些分散的数据点,形成一个连贯的分析报告,并根据用户的原始请求生成图表。
# 假设 `results` 是从子智能体收集到的JSON字符串列表
#...
# 构建发送给策划者(Opus)的最终Prompt
final_prompt = f"""
You are a senior financial analyst. You have received the following quarterly net sales data from your team of junior analysts:
<quarterly_data>
{results}
</quarterly_data>
Your task is to:
1. Synthesize these findings into a brief summary of Apple's net sales for the 2023 fiscal year.
2. Analyze any notable trends or patterns across the quarters.
3. Based on the data, generate Python code using the matplotlib library to create a bar chart visualizing the net sales for each quarter. Enclose the Python code in <python_code></python_code> tags.
"""
# 调用Opus模型进行最终的分析和代码生成
final_response = client.messages.create(
model=ORCHESTRATOR_MODEL,
max_tokens=4096,
messages=[{"role": "user", "content": final_prompt}]
)
# 提取分析文本和Python代码,并执行代码以生成图表
#...
构建卓越智能体
我们可以总结出构建高效、可靠智能体系统的几条核心设计原则:
- 由策划者统筹:使用一个领导者智能体进行战略分解、任务分配和成本控制。
- 由执行者专攻:为执行者设计专注、边界清晰的任务,使其高效完成单一目标。
- 由引文核查员保障事实:引入一个专门的引文智能体,将可信度验证流程化、自动化,以确保最终输出的准确性和可靠性。
- 精心设计接口(ACI):将Prompt设计与详尽的工具描述共同作为智能体与环境交互的接口进行协同设计。
- 强制而非建议:将并行化、结构化输出等对系统性能至关重要的行为,通过明确的指令硬编码到Prompt中。
最后,为开发者提供一份可直接应用的实践清单,用以审视和改进自己的智能体项目:
- 角色定义:是否为系统中的每一个智能体都定义了清晰的角色和使命?
- 授权明确性:策划者的授权Prompt是否足够具体,能够完全消除歧义,防止子智能体任务重叠?
- 工具描述完备性:工具的描述是否详尽、清晰,包含了用途、参数、限制和使用范例?
- 数据交换结构化:智能体之间的信息交换是否强制使用了可靠的结构化数据格式(如JSON)
- 思维链引导:是否使用了XML标签等技术引导模型进行“先思考、后回答”的结构化推理?
- 时间感知:对于需要处理时效性信息的任务,是否向模型注入了当前的日期信息?
- 事实核查:系统中是否有专门的流程或智能体来核实关键信息的来源,以防止幻觉?
随着大语言模型能力的不断增强,智能体架构的演进也将日新月异。然而,无论技术如何发展,结构化的设计思想和精益求精的Prompt工程,将永远是构建可靠、高效、真正智能的系统的基石。