
世界模型(World Models)是在通过内部模拟环境使 AI 系统能够预测未来状态、规划行动和进行推理。它们受到人类认知中"心智模型"的启发,例如棒球运动员通过直觉预测球的轨迹。Yann LeCun 提出的 Joint-Embedding Predictive Architecture (JEPA) 是构建世界模型的核心框架,通过自监督学习从高维感知数据(如视频)中提取语义信息。
继上篇文章介绍世界模型概念后,今天我们深入探讨这个被誉为"通往AGI新路径"的技术突破。从让AI学会"填空游戏",到实现62小时视频训练就能控制机器人——JEPA架构究竟有何神奇之处?
感兴趣的小伙伴请查看上一篇:
揭秘生成式3D与世界模型
第一部分:世界模型
世界模型的发展历程
世界模型的概念源于认知科学中的"心智模型",在人工智能领域经历了从符号系统到深度学习的演变。以下是其主要发展阶段:
| 阶段 | 年份 | 描述 |
|---|---|---|
| 早期符号模型 | 1950s-1960s | 早期 AI 系统(如 1966 年的 Shakey 机器人)使用基于规则的符号模型进行环境建模和导航,依赖手工设计的知识库。 |
| 现代深度学习范式 | 2018 | David Ha 和 Jürgen Schmidhuber 在论文《World Models》中提出现代世界模型,展示了 AI 代理通过无监督学习在内部"梦境"中学习和规划,利用变分自编码器(VAE)和循环神经网络(RNN)处理高维数据。 |
| Dreamer 系列 | 2019-2021 | Google DeepMind 的 Dreamer 系列模型改进了世界模型,使代理能够在潜在空间的想象轨迹中学习复杂行为,显著提高了样本效率。 |
| JEPA 框架 | 2022 | Yann LeCun 在论文《A Path Towards Autonomous Machine Intelligence》中提出 JEPA,作为构建世界模型的核心模块,强调自监督学习和抽象表示预测。 |
| 高级架构整合 | 2023-2025 | 世界模型整合了 Transformer 和扩散模型(如 Google 的 Genie、NVIDIA 的 Cosmos、Meta 的 V-JEPA、OpenAI 的 Sora),处理大规模视频数据并生成高保真模拟。 |
这些阶段反映了世界模型从静态、规则驱动的系统向动态、数据驱动的深度学习系统的转变,目标是让 AI 系统能够像人类一样通过内部模拟理解物理世界。
世界模型的提出者
现代世界模型的深度学习范式由 David Ha 和 Jürgen Schmidhuber 在 2018 年的论文《World Models》中正式提出。
“世界模型”的核心在于提出,人工智能系统能够开发其环境的内部表征,类似于人类的心智模型。作者通过整合变分自编码器 (VAE) 和循环神经网络 (RNN) 来实现这一点。
https://arxiv.org/pdf/1803.10122
World Models
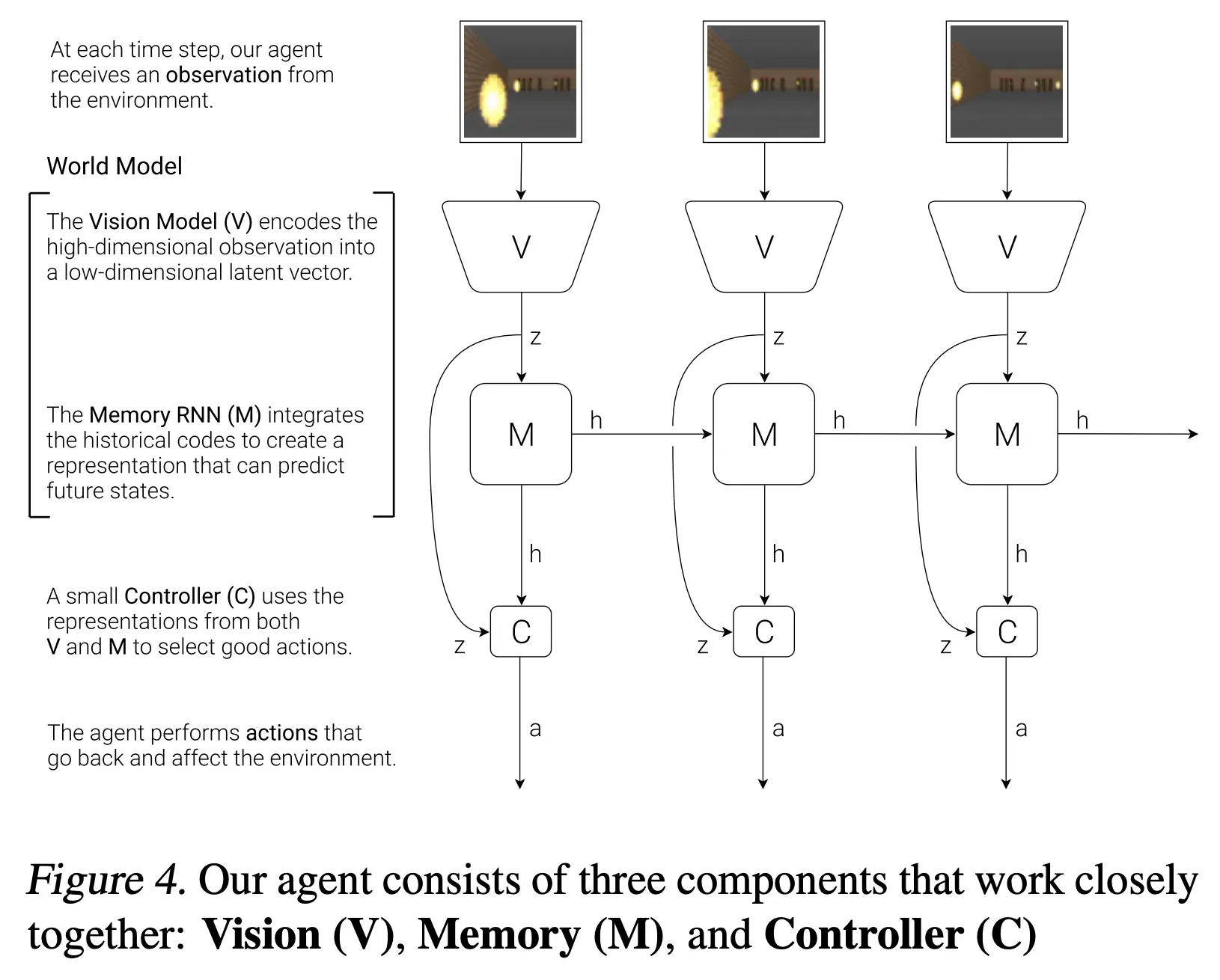
早期探索阶段(1950s-1980s):播下智能的种子
在计算机还像房间那么大的年代,就有人开始思考:能否让机器像人类一样理解世界?
1957年,Frank Rosenblatt发明了感知机,这就像是给机器装上了最原始的"眼睛"。虽然这双"眼睛"只能看懂最简单的图案,但它开启了机器理解世界的第一扇门。
1980年代,认知科学家们开始认真思考一个问题:人类是如何在脑海中构建对世界的理解的? 他们提出了"心理模型"(Mental Models)的概念——就像我们每个人脑海中都有一张"世界地图",帮助我们理解和预测周围发生的事情。
神经网络复兴(1990s-2000s):机器开始"做梦"
1997年,Jürgen Schmidhuber提出了一个大胆的想法:让AI拥有"想象力"!他设计的模型能够预测未来可能发生的事情,就像人类在做决定前会在脑海中"预演"一样。
这个时期最有趣的发现是:让机器"做梦"竟然能提高它们的智能水平!通过在虚拟环境中无数次地"试错",AI开始学会了规划和预测。
深度学习革命(2010s):AI的"大脑发育期"
2012年,AlexNet横空出世,就像给AI装上了"高清摄像头"。从此,机器视觉能力开始飞速发展。
2018年,David Ha和Jürgen Schmidhuber发表了著名的"World Models"论文,正式提出了现代世界模型的概念。他们的核心观点非常直观:
"人类通过构建关于世界的心理模型来理解和导航复杂环境。我们的大脑不断地预测未来,这种预测能力是智能的核心。"
这就像是给AI装上了一个"虚拟大脑",让它能够在行动之前先在脑海中"演练"一遍。
JEPA时代(2020s至今):AI开始真正"理解"
2022年,Yann LeCun在一次演讲中说道:
"当前的AI就像一个只会背书的学生,虽然能说出很多知识,但并不真正理解这些知识的含义。我们需要的是能够理解世界运作规律的AI。"
于是,JEPA架构应运而生。这不仅仅是技术的进步,更是AI学习方式的根本性变革——从"死记硬背"到"理解领悟"。
第二部分:联合嵌入预测架构-JEPA
JEPA的核心理念与AMI愿景
在追求高级机器智能 (Advanced Machine Intelligence, AMI) 的过程中,Yann LeCun 和 Meta AI 团队提出了一个全新的框架——Joint-Embedding Predictive Architecture (JEPA)。这不是一个简单的技术改进,而是对AI学习方式的根本性重新思考。JEPA是基于能量函数模型(Energy-Based Models)的理论框架。其核心思想是通过联合嵌入空间进行预测,而非在原始数据空间中进行预测。通过部分信息理解整体,并进行合理预测——正是Yann LeCun希望AI掌握的核心技能。
能量模型学习的核心思想是将学习任务看作是塑造一个“能量函数”E(Y,X)的过程,该函数用于衡量变量X(如图像)与待预测变量Y(如标签)之间的“兼容性” 。学习的目标是调整模型参数,使得兼容的(正确的)输入对具有低能量,而不兼容的(错误的)输入对具有高能量 。
在这种框架下,推理(Inference)不再是简单的单向前向传播,而是通过一个搜索过程,在所有可能的输出中寻找使能量函数E(Y,X)最小化的Y。这一理念与需要计算所有可能输出的归一化概率分布的概率模型形成了根本区别。
EBMs(Energy-Based Models)的一个关键吸引力在于,它巧妙地规避了概率模型中臭名昭著的“配分函数问题”(Partition Function Problem)。在处理图像或文本等高维输出时,计算归一化常数(即配分函数)在计算上是极其困难甚至不可行的。这正是LeCun倾向于非生成式方法的一个核心动机。此外,为了处理现实世界中的不确定性和多模态输出(一个输入可能对应多个输出),EBMs引入了潜变量(Latent variable)。通过在潜变量空间中采样,模型可以生成一系列能量较低的、合理的预测结果。这一概念为后来JEPA处理世界内在不可预测性奠定了理论基础。
https://atcold.github.io/NYU-DLSP20/en/week07/07-1/
Energy-Based Models
Yann LeCun巧妙地将能量函数的概念应用到JEPA中:
- 能量 = 预测表示与目标表示之间的距离
- 学习目标 = 让正确的预测具有低能量
- 避免计算复杂性 = 在抽象空间而非像素空间进行预测
JEPA的目标是抽象预测,它学习一个从世界的一部分映射到另一部分的函数,并在这个过程中,于保留足够预测信息和丢弃足够噪声之间取得平衡,使其天然适合学习语义和构建预测模型。
JEPA到底是什么?
如果说传统AI是"完美主义者",要把每个像素都画得一模一样,那么JEPA就是一个聪明的"理解者"——它不追求完美复制,而是专注于理解事物之间的关系和规律。
JEPA的三个"不同寻常":
- 非生成性质:不像传统生成模型那样痴迷于像素级重构,JEPA避开了"完美主义陷阱"
- 非对比特性:摆脱了对比学习需要大量负样本的束缚,更像人类的自然学习方式
- 自监督学习:无需大量标注数据,就像婴儿观察世界一样自然地学习
对比学习通过推开少量负样本来近似解决此问题,但引入了新的计算和采样难题 。生成式模型虽然也是EBM的一种,却又陷入了对像素细节的过度关注 。JEPA通过转换问题范式,将预测目标从高维数据本身转移到低维的抽象表示s_y,使得学习目标变得明确且计算上易于处理。它既避免了计算配分函数,也无需负样本采样,成为了EBM哲学在现代深度学习框架下的一个高效、可行的实现。
JEPA架构建立在一个核心前提之上:预测是智能的本质,但特指对抽象信息的预测 。其架构本身——即在嵌入空间进行预测这一行为——成为一种强大的隐式正则化器。它迫使模型必须学会区分“信号”(可预测的语义精华)和“噪声”(不可预测的无关细节),并主动丢弃后者,从而内在地、自发地学习抽象表征 。这不仅是效率的提升,更是关于如何引导模型进行抽象推理的深刻论断。
JEPA的核心组件与工作机制
JEPA架构包含三个核心组件:
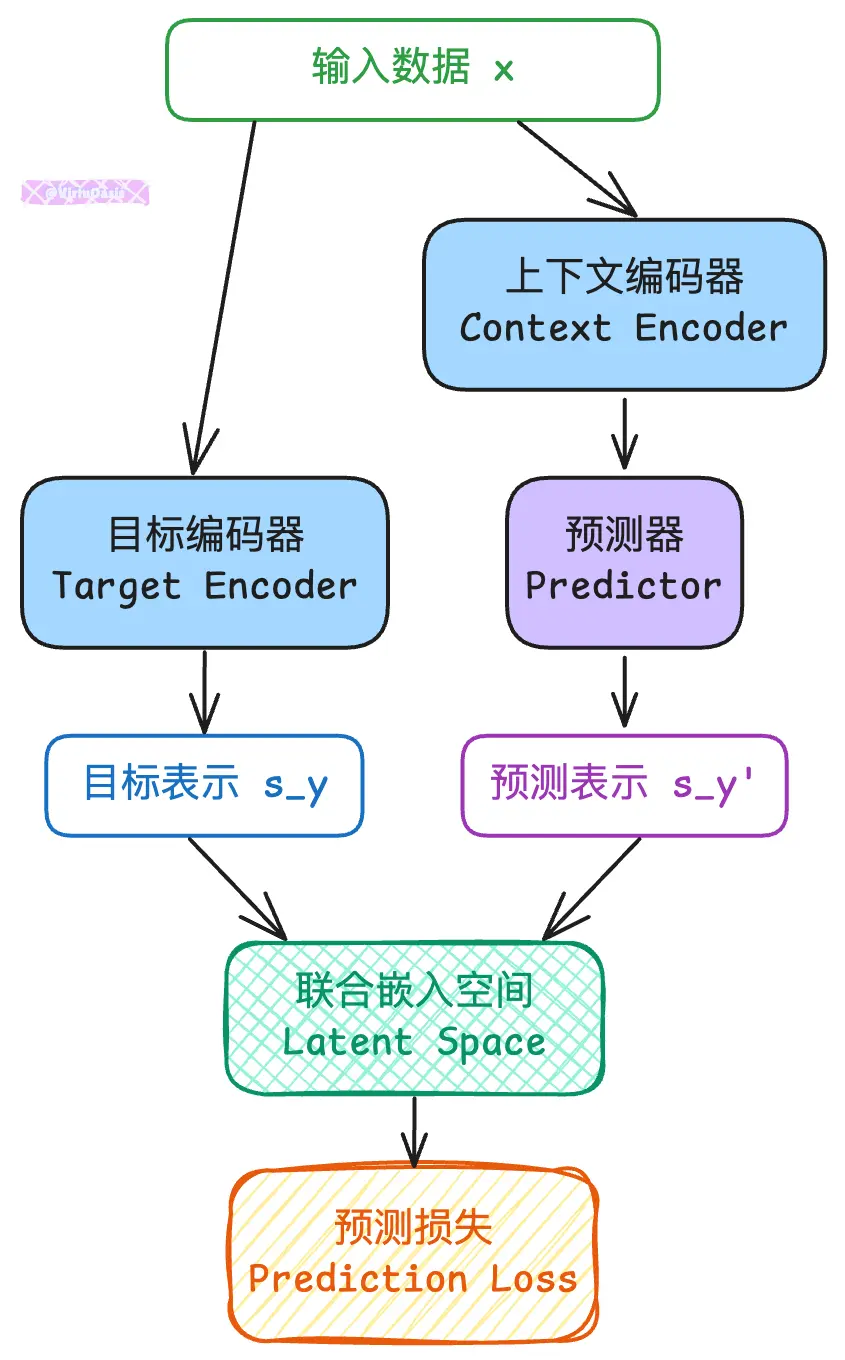
1. 上下文编码器(Context Encoder)
这就像是AI的"眼睛"和"耳朵",负责观察和理解当前的情况。它接收输入信息(比如图像的一部分),然后提取出关键特征。
工作原理:
输入图像 → 分割成小块 → 选择上下文块 → 提取特征向量
打个比方:就像你看到一张照片的左半部分,大脑会自动分析出这是什么场景、有哪些物体、它们的位置关系等信息。
2. 目标编码器(Target Encoder)
这个组件负责处理"正确答案"——也就是我们希望AI能够预测到的内容。它将目标信息编码成标准的表示形式。
工作原理:
目标图像块 → 特征提取 → 标准化表示 → 作为学习目标
这就像是给AI提供了一个"参考答案",让它知道什么样的预测是准确的。
3. 预测器(Predictor)
这是JEPA的"大脑",负责根据观察到的信息预测未知的内容。关键是,它预测的不是像素级的细节,而是抽象的语义表示。
工作原理:
上下文特征 → 推理计算 → 预测目标特征 → 与真实目标对比
这三个模块的协作采用了"师生模式":
- 目标编码器 = 保守的"老师",知识更新缓慢但稳定
- 上下文编码器 + 预测器 = 积极的"学生",快速学习追赶老师
学习目标与坍塌防止机制
下面的架构图展示了JEPA的所有核心组件及其相互关系:
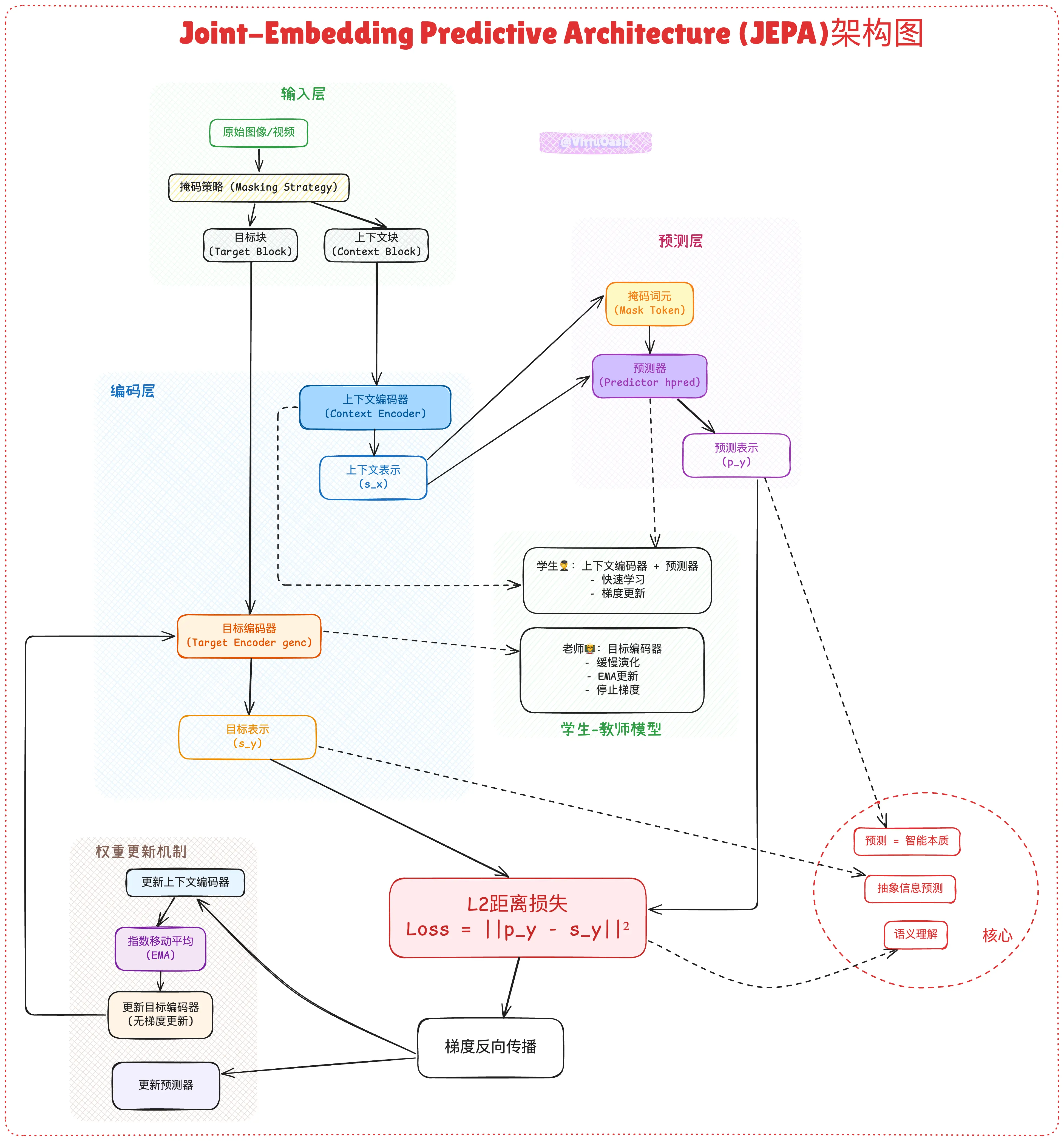
JEPA的学习过程围绕一个核心的预测损失来确保学习的有效性。
-
预测损失 (Prediction Loss): 主要的训练目标是最小化预测表示py与目标表示sy之间的距离,通常使用L2距离。这个损失函数驱动预测器去学习上下文与目标之间的语义关联。
-
防止表示坍塌 (Preventing Collapse): 如果没有特殊设计,编码器很容易学会输出一个恒定值,从而使预测任务变得微不足道,这就是所谓的“表示坍塌”。JEPA通过其非对称架构来解决这个问题。对目标编码器使用停止梯度(stop-gradient)和动量更新(momentum update, 即EMA)是防止坍塌的关键 。这使得目标编码器(教师)的演化滞后于上下文编码器(学生),形成了一个动态的的预测任务,从而替代了对比学习中的负样本或生成模型中的复杂解码器。
-
掩码策略的重要性 (The Importance of Masking): 如何定义上下文和目标块并非小事,而是JEPA的核心设计之一。目标块必须足够大,以包含有意义的语义信息;而上下文块也必须足够丰富,以提供充分的预测线索。
-
“学生-教师”学习模型。目标编码器扮演着一位“保守的教师”,其知识(权重)通过EMA平滑更新,代表了学生在过去一段时间内学习到的共识,因此能提供稳定、高质量的目标信号
s_y。而上下文编码器和预测器则共同组成了“积极的学生”,通过梯度下降快速学习,努力追赶并预测教师的输出。这种自蒸馏机制不仅提供了有效的学习信号,也从根本上保证了表示不会坍塌。
在此框架中,预测器模块本身就是一个初级的、学成的“世界模型”。它的核心任务是“填空”:根据已知信息s_x,推断未知区域可能存在什么s_y。这正是世界模型的基本功能——从当前状态预测未来或未观测到的状态。在I-JEPA中,这是空间预测;在V-JEPA中,则演变为时空预测。由于预测发生在抽象空间,预测器学习的不是如何绘制像素,而是世界在语义层面的组合规则(例如,“头部通常在肩膀上方”、“被抛出的球会遵循抛物线轨迹”)。因此,预测器是模型对“世界如何运转”的抽象理解被显式实例化和训练的地方。
JEPA家族:
JEPA 家族包括多个变体,针对不同数据类型和任务进行了优化:
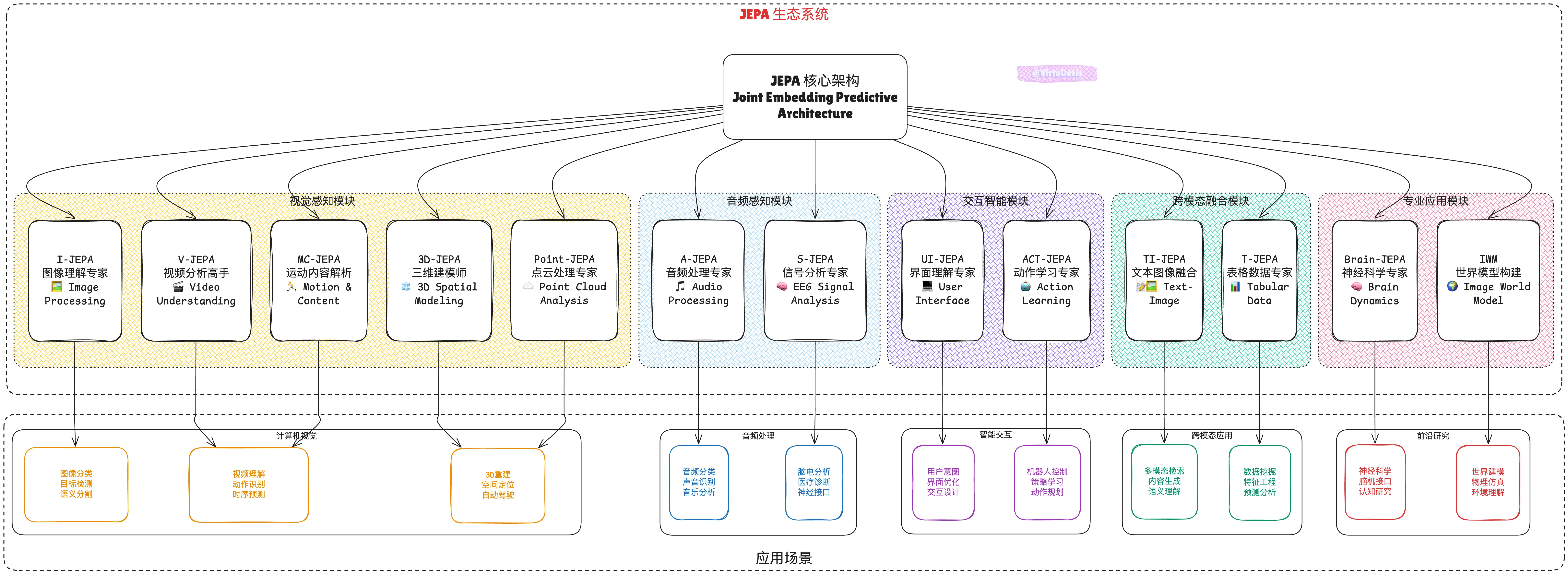
| 变体 | 完整英文名称 | 目标模态 | 核心任务/创新 | 主要应用 |
|---|---|---|---|---|
| I-JEPA | Image Joint Embedding Predictive Architecture | 图像 | 学习静态图像的语义表示 | 图像分类、语义分割 |
| V-JEPA | Video Joint Embedding Predictive Architecture | 视频 | 学习时空域中的运动和外观特征 | 视频理解、动作识别 |
| MC-JEPA | Motion and Content Joint Embedding Predictive Architecture | 视频 | 解耦视频中的运动和内容信息 | 视频运动分析 |
| A-JEPA | Audio Joint Embedding Predictive Architecture | 音频 | 从音频频谱图中学习表示 | 音频分类、声音事件检测、音乐分析 |
| S-JEPA | Signal Joint Embedding Predictive Architecture | 生物信号(EEG) | 分析脑电图等信号数据 | 脑电信号分析、神经科学研究 |
| 3D-JEPA | 3D Joint Embedding Predictive Architecture | 3D数据 | 从3D点云或体素中学习空间表示 | 3D目标检测、空间重建、自动驾驶 |
| UI-JEPA | User Interface Joint Embedding Predictive Architecture | 用户界面 | 从UI交互序列中学习用户意图 | 用户界面理解、意图预测 |
| TI-JEPA | Text-Image Joint Embedding Predictive Architecture | 文本-图像 | 学习跨模态的共享表示 | 跨模态理解、文本图像检索 |
| T-JEPA | Tabular Joint Embedding Predictive Architecture | 表格数据 | 从结构化数据中学习特征表示 | 表格数据分析、特征学习 |
| ACT-JEPA | Action Joint Embedding Predictive Architecture | 动作序列 | 学习机器人或智能体的策略嵌入 | 机器人控制、动作学习 |
| Brain-JEPA | Brain Joint Embedding Predictive Architecture | 大脑动力学 | 构建大脑活动的基础模型 | 神经科学、医学诊断 |
| Point-JEPA | Point Cloud Joint Embedding Predictive Architecture | 点云 | 针对点云数据优化的JEPA | 点云处理、3D场景理解 |
| IWM | Image World Model | 图像序列 | 预测全局光度变换的影响 | 图像表示学习、任务适配 |
这些变体展示了 JEPA 的灵活性和可扩展性,已经发展成为一个涵盖12种不同模态和应用场景的完整生态系统:
- 视觉领域:I-JEPA(图像)、V-JEPA(视频)、MC-JEPA(运动内容)、3D-JEPA(三维空间)
- 音频领域:A-JEPA(音频处理)、S-JEPA(脑电信号)
- 交互领域:UI-JEPA(用户界面)、ACT-JEPA(动作学习)
- 跨模态领域:TI-JEPA(文本图像)、Point-JEPA(点云)
- 专业领域:T-JEPA(表格数据)、Brain-JEPA(神经科学)
- 世界建模:IWM(图像世界模型)
多模态JEPA(如TI-JEPA)和面向行动的JEPA(如ACT-JEPA)的出现,预示着下一个前沿方向:将不同的模态整合到一个统一的预测性世界模型中。LeCun的AMI愿景需要一个能够感知、推理并行动的智能体,这必然要求整合视觉、听觉等多种感官,并将它们与行动联系起来 。V-JEPA是朝这个方向迈出的一步,但仍是单模态的 。LeCun本人也指出,整合音频的多模态方法是“显而易见的下一步” 。TI-JEPA和A-JEPA的出现提供了构建这种统一模型所需的基础模块 。尽管目前尚未完全实现,但逻辑上的下一步是构建一个层级化、多模态的JEPA。这样的系统将能够利用视频和音频上下文,来预测未来的视频、音频乃至描述事件的文本,从而向一个更完整的世界模型迈进。
技术优势与挑战
🎯 核心优势:为什么JEPA如此特别?
1. 学习效率的革命性提升
传统方法:需要海量标注数据,就像需要老师手把手教每一个细节
JEPA方法:自监督学习,像婴儿观察世界一样自然学习
数据对比:
- 传统图像分类:需要数百万标注图片
- I-JEPA:仅需无标注图片,效果更好
- 传统机器人训练:需要数千小时专门训练
- V-JEPA 2:62小时通用视频即可
2. 计算效率的显著优化
像素级预测:就像要求AI画出照片的每一个细节
抽象表示预测:只需要理解照片的主要内容和结构
效率对比:
传统生成模型:计算复杂度 O(n²),n为像素数
JEPA架构:计算复杂度 O(d²),d为特征维度(d << n)
3. 泛化能力的质的飞跃
传统AI:在训练数据上表现很好,换个场景就"懵了"
JEPA:理解了基本规律,能够适应新环境
实际案例:
- I-JEPA在ImageNet上训练,在其他数据集上依然表现优秀
- V-JEPA 2在一个实验室训练,在另一个实验室的机器人上成功部署
四大技术挑战需要突破:
- 动态场景处理的局限性:就像人眼在快速运动中容易"跟丢"目标一样,当前JEPA在处理高速变化的复杂场景时还有待提升
- 多模态融合的挑战:如何让视觉、听觉、触觉等不同感官信息完美融合,就像人类大脑那样自然协调
- 成本函数定义的难题:如何设计合适的"评分标准"来衡量AI理解世界的好坏程度
- 计算效率优化问题:在保持理解能力的同时,如何让AI"思考"得更快更省电
通往AGI/AMI的另一条路
LeCun vs. Altman之辩
当前,关于如何实现通用人工智能,存在两种主流且相互竞争的哲学。
- 世界模型哲学 (LeCun/Meta): LeCun坚信,真正的智能必须“植根于”(grounded in)一个对物理世界丰富、可预测的内部模型,而这个模型主要通过观察视频等高带宽感官数据来学习 。他认为,仅在低带宽文本上训练的LLM缺乏这种物理世界的常识,无法进行真正的推理和规划,因此是通往AGI的一条死胡同 。他更倾向于使用“高级机器智能”(AMI)一词,因为他认为人类智能本身也是高度专业化的,而非“通用” 。
- LLM为核哲学 (Altman/OpenAI): 这一愿景则认为,通过在海量多模态数据上不断扩展LLM的规模,可以使其涌现出通用的推理能力。语言被视为人类思想最凝练、最通用的表示,智能可以由此引导和生成 。智能体的行动能力则通过为LLM配备各种工具和API接口来实现。
在这场辩论中,V-JEPA 2是Meta为“世界模型”哲学递交的最强有力的“论据”,它是一个具体的、可工作的系统,展示了这条路径的巨大潜力 。这场技术路线之争,在更深层次上是关于智能本质的哲学辩论,是人工智能领域内经验主义与理性主义两种思想的现代体现。LeCun的路径是彻底的经验主义:智能体必须通过高带宽的感官输入(观察世界)来从零开始构建其知识体系,JEPA正是这一过程的实现机制 。而LLM的路径更偏向理性主义:它试图从人类抽象思维的结晶(文本)中学习,并从中推导出通用的推理能力 。
虽然通往真正"懂世界"的AI之路依然漫长,但JEPA已经为我们点亮了前进的明灯。也许在不久的将来,我们将迎来一个AI不仅能回答问题,更能真正理解和预测世界的新时代。
你认为JEPA会成为AGI的关键突破吗?在评论区分享你的看法吧!
参考文献:
- Assran, M., et al. (2023). Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture. arXiv. https://arxiv.org/pdf/2301.08243
- Assran, M., et al. (2025). V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning. arXiv. https://arxiv.org/html/2506.09985v1
- Meta AI. (2024). V-JEPA: The next step toward Yann LeCun’s vision of advanced machine intelligence (AMI). Meta AI Blog. https://ai.meta.com/blog/v-jepa-yann-lecun-ai-model-video-joint-embedding-predictive-architecture/
- Meta AI. (2023). I-JEPA: The first AI model based on Yann LeCun’s vision for more human-like AI. Meta AI Blog. https://ai.meta.com/blog/yann-lecun-ai-model-i-jepa/
- LeCun, Y. (2007). Energy-Based Models: The Cure Against Bayesian Fundamentalism. MIT. Accessed June 16, 2025. https://www.mit.edu/~9.520/spring07/Classes/lecun-20070502-mit.pdf
- Champaign Magazine. (2025). V-JEPA vs LLMs: an AI Comparison. Accessed June 16, 2025. https://champaignmagazine.com/2025/03/02/v-jepa-vs-llms-an-ai-comparison/
- Kseniase. (2025). 12 Types of JEPA JEPA, or Joint .... Hugging Face. Accessed June 16, 2025. https://huggingface.co/posts/Kseniase/646284586461230