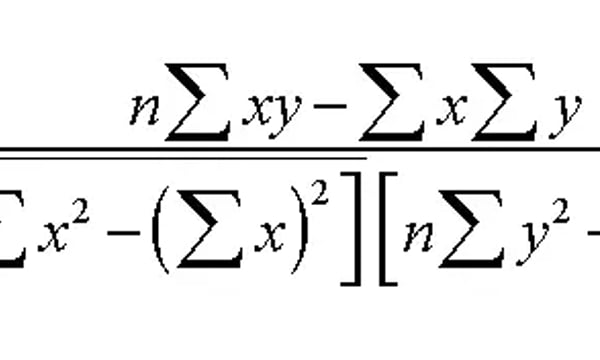
First of all, this is not only for Twitter, it is something which should work for everything.
Step 1: get all tweets and extract words for each tweets, then make them into a data table
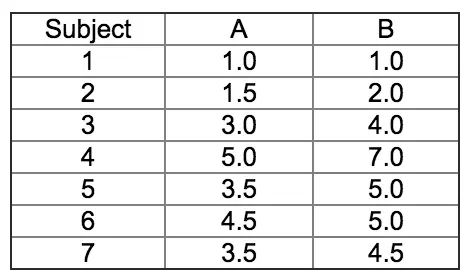
Data table will looks like

Subject can be “Tweets”
A and B are the words from each tweets.
Each line represent a tweets and the amount of the word appear in the tweet
Create the table, here is the Table object
public class TwitterTable {
private TwitterTableHeader twitterTableHeader;
private List<TwitterTableLine> twitterTableLines;
public TwitterTable(List<String> tweets) {}
}
Here is the table header object, which contain the name of the table and all the words
public class TwitterTableHeader {
private String name;
private List<String> words;
}
So after we have those 3 objects, we can get data from your data source and assemble the TwitterTable object.
Then it is time for K-Means
Step 2: create K-Means
K-Means is not that difficult in concept. take a look at this diagram first

I have 5 points which are A,B,C…E
I Randomly generate centroids which are the grey points
A,B are close to the centroid at the top and D,E and C are close to the centroid from the bottom, so right now I already have 2 clusters, one is A and B we can called it cluster 1, another one is C,D and E, and we call it cluster 2, then we move cluster 1’s centroid to the center of the first cluster, which will be in the middle between A and B, also move cluster 2’s centroid to the center of the second cluster, which will be in the center place between C,D and E
Then we do the clustering again, this time, A,B and C is close to the centroid from the top, D and E are close to the centroid from the bottom, so after this time, we cluster 1 has A,B and C, cluster 2 lot C, so only has D and E
After this, we move cluster 1’s centroid and cluster 2’s centroid again, after move, we find out there is no way to change those 2 clusters again, then we consider it is done.
First thing to do for k-means is initial the clusters
public void init(TwitterTable table, int clusters) {
this.numberOfClusters = clusters;
TwitterTableHeader twitterTableHeader =
table.getTwitterTableHeader();
Random random = new Random();
int wordsSize = twitterTableHeader.getWords().size();
List<Double> maxRanges = table.max();
List<Double> minRanges = table.min();
for (int i = 0; i < numberOfClusters; i++) {
Cluster cluster = new Cluster(i);
for (int j = 0; j < wordsSize; j++) {
Double max = maxRanges.get(j);
Double min = minRanges.get(j);
cluster.addCentroid(random.nextDouble() * (max - min) + min);
}
this.clusters.add(cluster);
}
}
For this case, we will initial 4 clusters, each cluster will have a group of centroids
Then we should do the calculation
public Map<Integer, List<Integer>> calculate(TwitterTable table) {
boolean finish = false;
List<TwitterTableLine> twitterTableLines = table.getTwitterTableLines();
Map<Integer, List<Integer>> bestMatches = new HashMap<>();
Map<Integer, List<Integer>> lasttMatches = null;
for (int k = 0; k < numberOfClusters; k++) {
bestMatches.put(k, new ArrayList<>());
}
while (!finish) {
for (int i = 0; i < twitterTableLines.size(); i++) {
TwitterTableLine twitterTableLine = twitterTableLines.get(i);
int bestmatch = 0;
for (int j = 0; j < numberOfClusters; j++) {
double distance = Pearson.pearson(clusters.get(j).getCentroid(), twitterTableLine.getAmounts());
if (distance < Pearson.pearson(clusters.get(bestmatch).getCentroid(), twitterTableLine.getAmounts())) {
bestmatch = j;
}
}
bestMatches.get(bestmatch).add(i);
}
if (bestMatches == lasttMatches) {
break;
}
lasttMatches = bestMatches;
for (int k = 0; k < numberOfClusters; k++) {
Map<Integer, Double> avgs = new HashMap<>();
if (bestMatches.get(k).size() > 0) {
//get all the row ids of each cluster
List<Integer> rowIds = bestMatches.get(k);
//loop through all rows of current cluster
for (Integer rowId : rowIds) {
// get the row base on the row id
TwitterTableLine row = table.getTwitterTableLines().get(rowId);
//get column amount of the row
List<Double> rowAmounts = row.getAmounts();
//loop through all columns of the row
for (int i = 0; i < rowAmounts.size(); i++) {
//get the amount of each column of this row
Double rowColumnAmount = rowAmounts.get(i);
if (avgs.containsKey(i)) {
avgs.put(i, rowColumnAmount);
} else {
avgs.put(i, rowAmounts.get(i) + rowColumnAmount);
}
}
}
Set<Map.Entry<Integer, Double>> avgEntries = avgs.entrySet();
for (Map.Entry<Integer, Double> next : avgEntries) {
Integer key = next.getKey();
double avgScore = next.getValue() / bestMatches.get(k).size();
avgs.put(key, avgScore);
}
clusters.get(k).rebuild(avgs);
}
}
}
return bestMatches;
}
In this method, For each row from the tweets table, we will use Pearson to calculate the distance between the centroids of each cluster and the words count of each row
double distance = Pearson.pearson(clusters.get(j).getCentroid(), twitterTableLine.getAmounts());
The Pearson object will looks like below, and for static method pearson, return result is
return 1-result
Which means the bigger number we get, the closer those two result set is.
public class Pearson {
public static double pearson(List<Double> v1, List<Double> v2) {
double sumV1 = sum(v1);
double sumV2 = sum(v2);
double sumSq2V1 = sumSq2(v1);
double sumSq2V2 = sumSq2(v2);
double sumOfProducts = sumOfProduct(v1,v2);
double result = (sumOfProducts - (sumV1 * sumV2 / v1.size())) / Math.sqrt((sumSq2V1 - Math.pow(sumV1, 2) / v1.size()) * (sumSq2V2 - Math.pow(sumV2, 2) / v2.size()));
return 1-result;
}
private static double sumOfProduct(List<Double> v1, List<Double> v2) {
double sum = 0;
for (int i = 0; i < v1.size(); i++) {
Double v1Value = v1.get(i);
Double v2Value = v2.get(i);
sum += v1Value * v2Value;
}
return sum;
}
private static double sumSq2(List<Double> v) {
double sum = 0;
for (Double value : v) {
sum += Math.pow(value.doubleValue(), 2);
}
return sum;
}
private static double sum(List<Double> v) {
double sum = 0;
for (Double value : v) {
sum += value;
}
return sum;
}
}
So the complete steps of this program will be
private static void kCluster(TwitterTable twitterTable, int clusters) {
KMeans kMeans = new KMeans();
kMeans.init(twitterTable,clusters);
Map<Integer, List<Integer>> result = kMeans.calculate(twitterTable);
List<Integer> resultOne = result.get(0);
twitterTable.print(resultOne);
}
and the result from KMeans.calculate() will looks like
{
0=[2, 3, 8, 13, 14, 19, 29, 30, 35, 41, 42, 46, 1, 3, 5, 6, 8, 9, 10, 15, 17, 20, 28, 32, 35, 39, 40, 41, 45, 46, 47],
1=[12, 21, 22, 32, 33, 34, 43, 0, 2, 4, 7, 14, 18, 24, 27, 29, 30, 33, 43],
2=[7, 9, 16, 18, 44, 31, 36, 37, 44],
3=[0, 5, 11, 17, 20, 23, 24, 25, 26, 31, 36, 39, 45, 48, 12, 19, 48],
4=[1, 4, 6, 10, 15, 27, 28, 37, 38, 40, 47, 49, 11, 13, 16, 21, 22, 23, 25, 26, 34, 38, 42, 49]
}
Each group will have multiply row numbers, we can use those number to retrieve the tweets we have in object TwitterTable