
背景
在一些特殊业务场景中,前端页面可能需要承载和展示大规模数据(百万级数据),常见的问题包括:页面渲染卡顿、内存快速膨胀,以及潜在的内存泄露风险。
许多项目使用 MobX 作为状态管理方案,但如果对其机制理解不足,在处理大数据时就容易踩坑。本文将尝试分析其响应式系统在大数据场景下的表现,并给出相应的优化实践。
当我们谈 makeObservable 时我们谈些什么
class Person {
name = "John";
constructor(name) {
this.name = name;
makeObservable(this, {
name: observable,
});
}
}
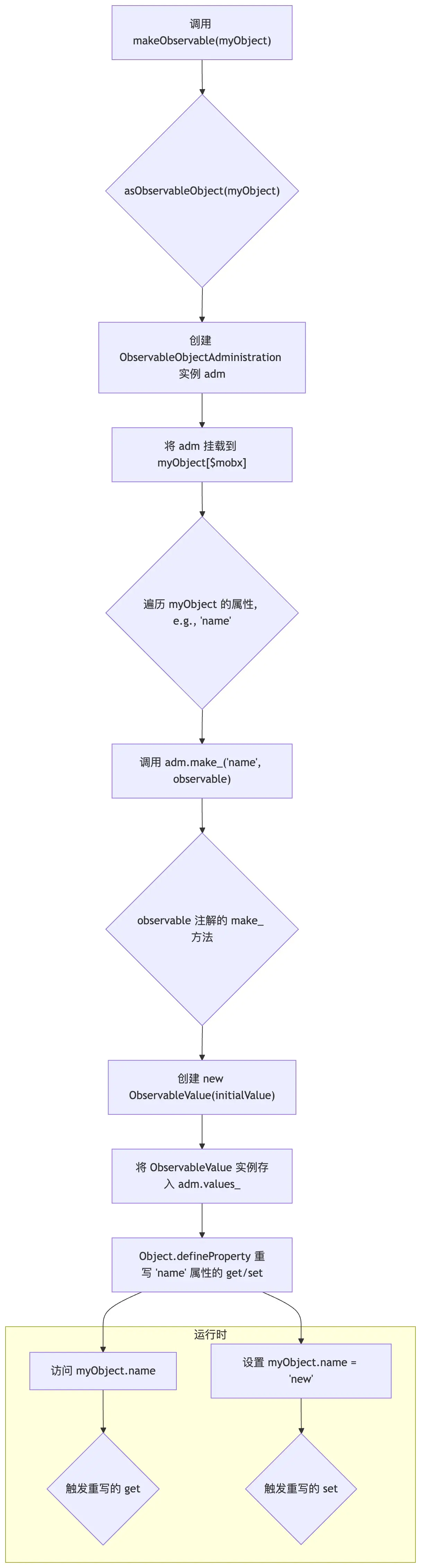
makeObservable 的作用,就是将普通对象的属性包装为响应式的 observable 属性,让它们能参与 MobX 的依赖收集和更新机制。
响应式系统的砖和瓦
核心概念
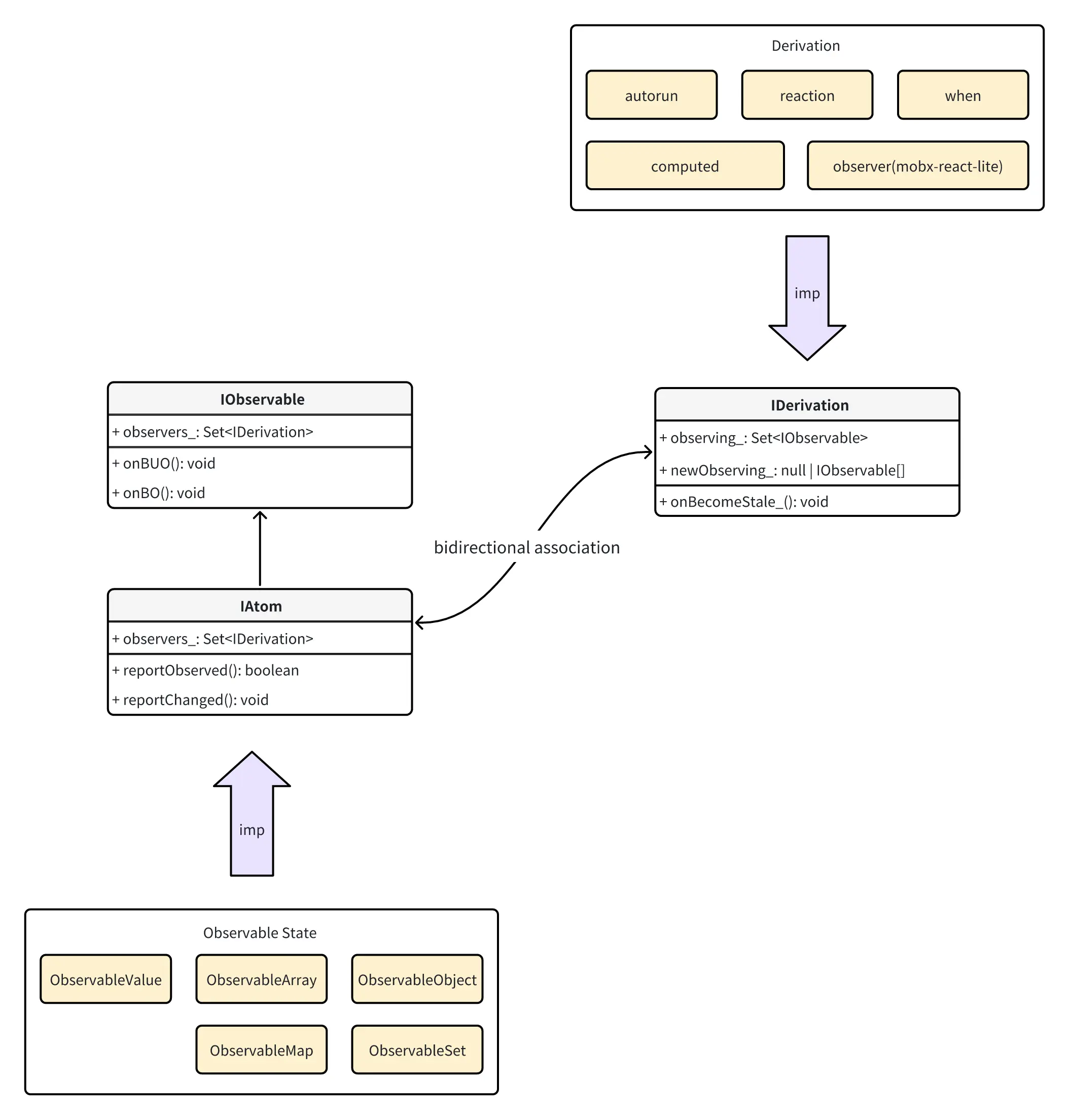
MobX 内部有几个核心角色:
- Atom:最基础的响应式单元。本身不存储值,只负责 订阅关系。
- 读取值时触发 reportObserved
- 修改值时触发 reportChanged,广播给订阅者
- Observable State:Atom 的子类,包装了实际的值,如 Primitive Values、Array、Object、Set 和 Map 等,不同数据结构会对应不同的实现。
接着,我们来看一看常用的 Observable State 是如何实现的。
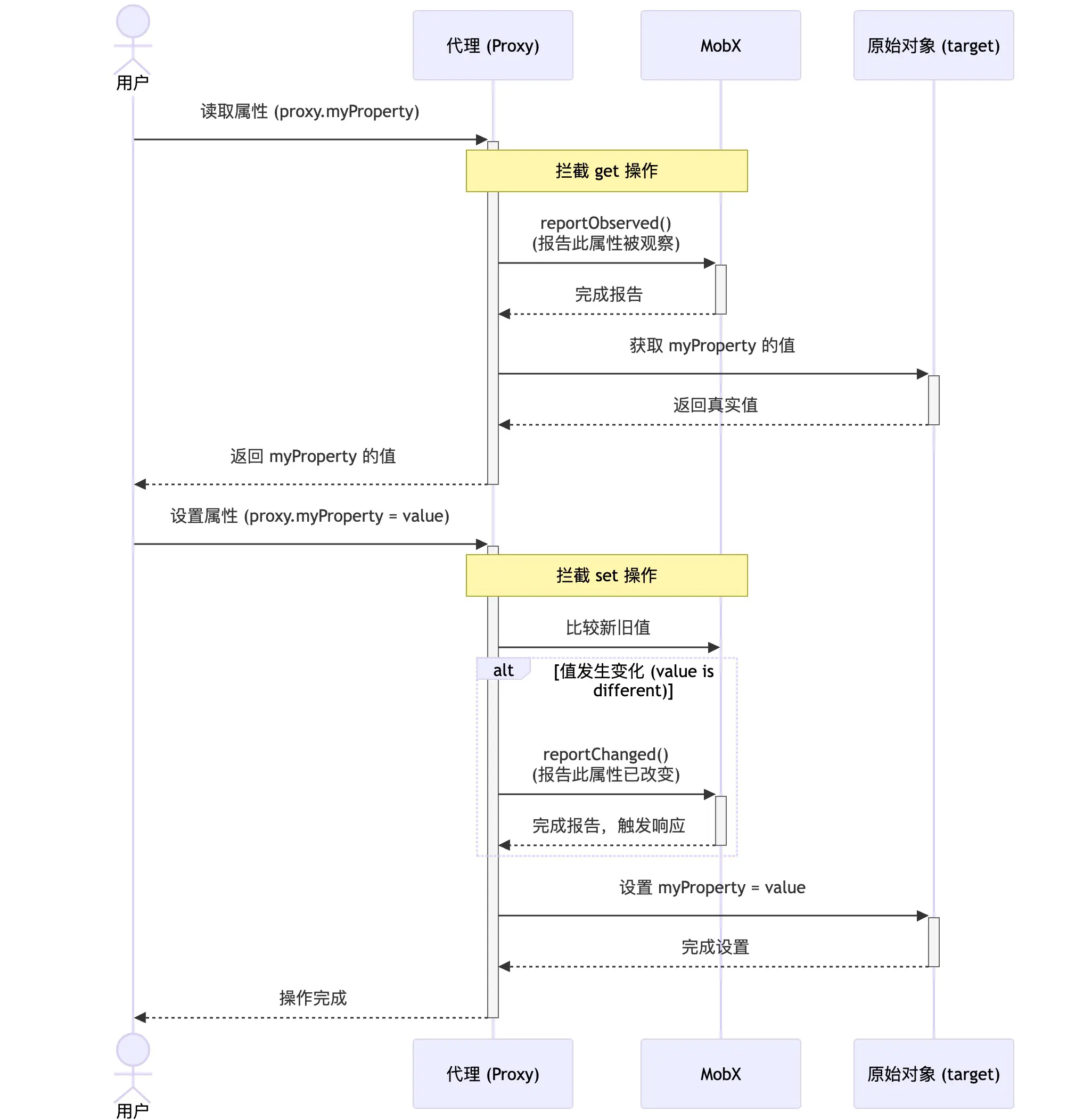
export class ObservableValue<T> extends Atom {
observers_: Set<IDerivation>
value: T
public enhancer: IEnhancer<T>
public set(newValue: T) {
const oldValue = this.value_
this.value_ = newValue
this.reportChanged()
}
public get(): T {
this.reportObserved()
return this.dehanceValue(this.value_)
}
}
export class ObservableObjectAdministration {
keysAtom_: IAtom
public values_ = new Map<PropertyKey, ObservableValue<any> | ComputedValue<any>>(),
private pendingKeys_: undefined | Map<PropertyKey, ObservableValue<boolean>>
keys_(): PropertyKey[] {
this.keysAtom_.reportObserved()
return Object.keys(this.target_)
}
// 代理 has/delete/ownKeys 等方法
}
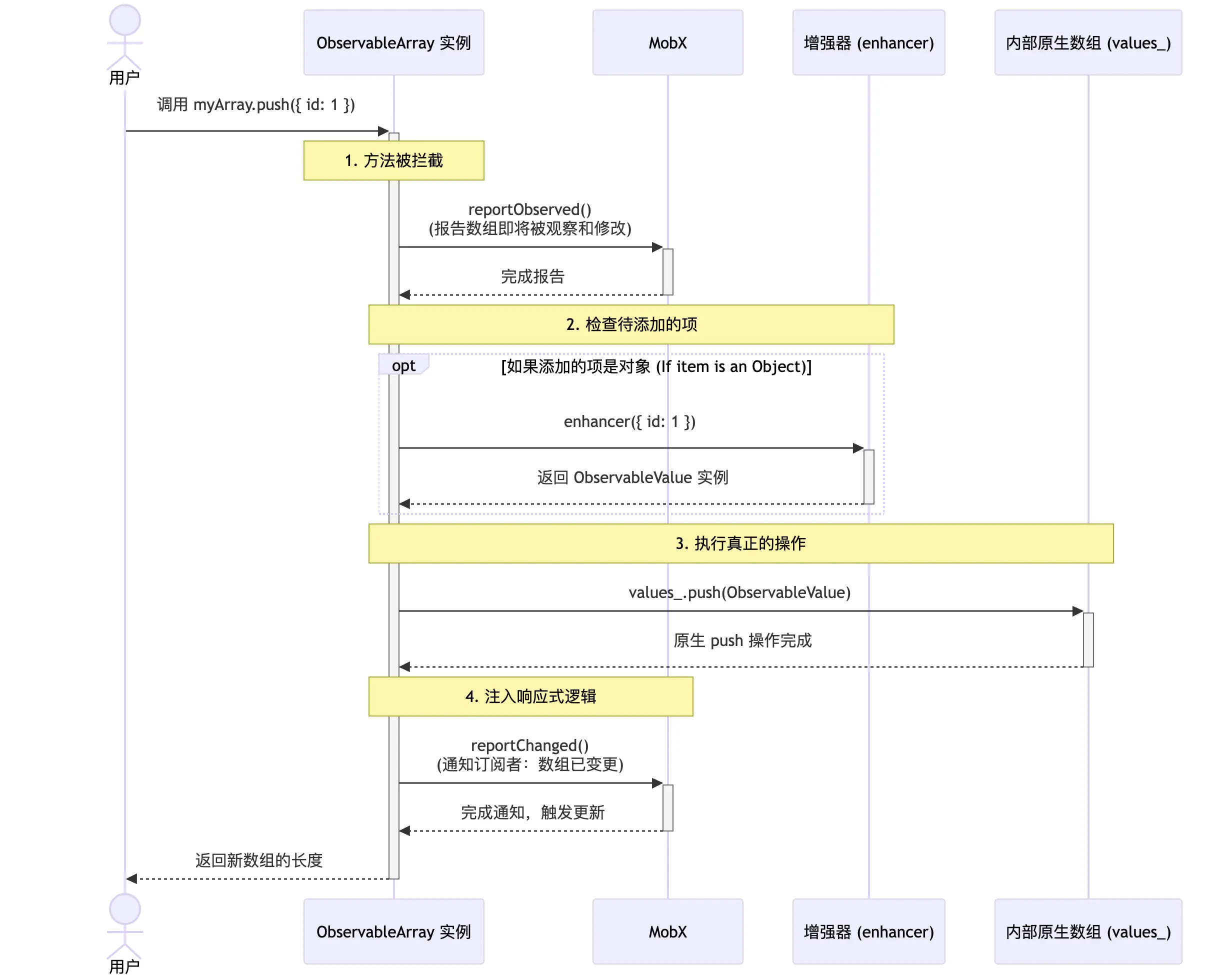
export class ObservableArrayAdministration {
atom_: IAtom;
readonly values_: any[] = [];
set_(index: number, newValue: any) {
// ...
this.atom_.reportChanged();
// ...
}
// ...
// 代理 length/map/push/splice 等方法
}
function mapLikeFunc(funcName) {
return function (callback, thisArg) {
const adm: ObservableArrayAdministration = this[$mobx];
adm.atom_.reportObserved();
const dehancedValues = adm.dehanceValues_(adm.values_);
return dehancedValues[funcName]((element, index) => {
return callback.call(thisArg, element, index, this);
});
};
}
- ObservableValue 可以看作一个 Box,它可以把任意类型的「值」包装为可观察的值。
- ObservableObject 和 ObjectArray 更多扮演的是对「结构」的观察,核心的思想就是代理 + 拦截。
Derivation
Derivation 可以理解为:任何可以从其他可观察状态(Observable State)中派生出来的值。它分为两种:
- ComputedValue :即 computed ,是纯函数式的派生。
- Reaction:即 autorun , reaction , when 以及 mobx-react-lite 中的 observer 方法。它们用来处理响应状态变化的副作用,例如状态变更同时向 LocalStorage 同步等。
Derivation 是订阅者,其中的 observing_ 是发布者,即这个派生状态依赖哪些数据源。
给 Derivation 举个 🌰
const disposer = autorun(() => {
if (user.showProfile) {
// 依赖: showProfile, name
console.log(`Name: ${user.name}`);
} else {
// 依赖: showProfile, nickname
console.log(`Nickname: ${user.nickname}`);
}
});
Failed to upload image mobx-5.jpeg
通过这种双向关联的方式,MobX 就可以实现精确、高效和无内存泄露的响应式系统。
computed 和 autorun 实现异同
computed 和 autorun 是最常用的两个方法,在依赖收集和变更触发阶段,两者的实现基本一致。
autorun 的主要目标是在状态变化时执行副作用,而 computed 的主要目标是基于已有状态派生出新状态,基于这个前提 computed 做了大量优化。
我们可以用电子表格的公式 C1 = A1 + B1 来类比:
- 惰性求值:只有真正访问 C1 时,才会触发计算
- 依赖追踪:明确知道 A1 和 B1 是 C1 结果的依赖
- 结果缓存:只要依赖没有发生变化,就不会执行计算,快速获取结果
- 自动更新:A1 或 B1 的值发生变化时会标脏,再次访问 C1 时触发计算,结果不变是不会通知订阅方
总的来说:
- autorun 是响应式系统的“终点” ,它消费数据,并将其转化为外部世界的副作用。
- computed 是响应式系统的“中间件” ,它消费数据,然后生产出新的、可被缓存的、可被其他消费者使用的新数据。
内存都被谁用了?
我们来做个实验,看看一个真实的案例中,内存到底被谁占用了。
import React from "react";
import { makeObservable, observable, action } from "mobx";
import { observer } from "mobx-react-lite";
class AppStore {
plainJsArray = [];
mobxObservableArray = [];
constructor() {
makeObservable(this, {
mobxObservableArray: observable,
createMobxArray: action,
});
}
generateLogData = (count) => {
const data = [];
for (let i = 0; i < count; i++) {
data.push({
Host: "www.google.com",
count: "279",
time: "2025-07-23 15:35:00.000",
});
}
return data;
};
createPlainArray = () => {
console.log("Creating plain JS array...");
this.plainJsArray = this.generateLogData(100000);
console.log("Plain JS array created.", this.plainJsArray);
};
createMobxArray = () => {
console.log("Creating MobX observable array...");
const data = this.generateLogData(100000);
this.mobxObservableArray = observable(data);
console.log("MobX observable array created.", this.mobxObservableArray);
};
}
const store = new AppStore();
const App = observer(() => {
return (
<div>
<h1>MobX Memory Experiment</h1>
<button onClick={store.createPlainArray}>Create Plain JS Array</button>
<button onClick={store.createMobxArray}>
Create MobX Observable Array
</button>
</div>
);
});
export default App;
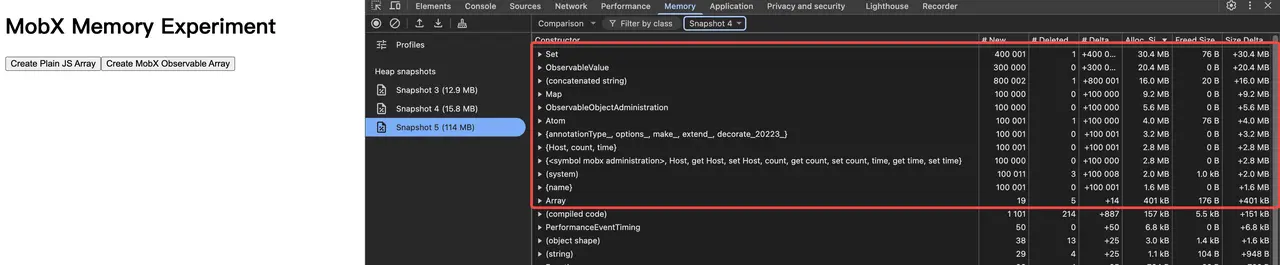
我们先创建 Plain Object,发现内存增加了约 3MB。
我们再创建相同内容的 Observable Object,内存增加了近 100MB。
这里先解释一个概念:Alloc. Size 是 Allocation Size 的缩写,表示的是:在快照 1 和快照 2 之间,新创建的该类型(Constructor)所有对象的 Shallow Size (自身大小) 的总和。Shallow Size 是实际占用的内存大小。
我们先把不太重要的内容厘清:
- {Host, count, time} 是新创建的 Plain Object
- {annotationType*, options*, make*, extend*, decorate20223} 是 Annotation 的实例
- (concatenated string) 是在 dev 模式下给每个 ObservableValue 生成的 name
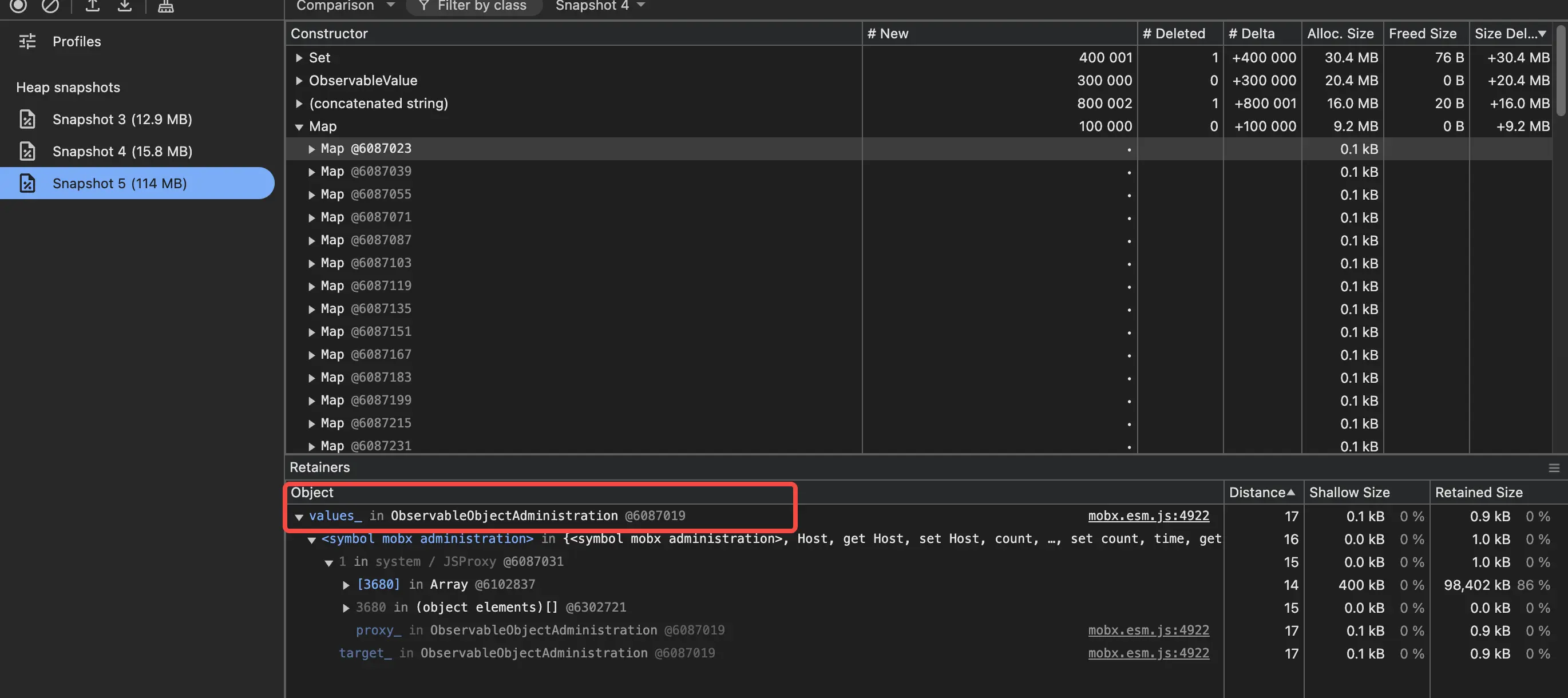
真正的重点在:
- ObservableObjectAdministration:每一个 ObservableObject 都需要一个 adm 来管理,负责“结构”
<symbol mobx administration>:ObservableObjectAdministration 的“钥匙”,用来快速访问到对应的 adm- ObservableValue:来源于每一个属性的 deep Observable,负责“值”
- Atom:响应式的最小单元,每一个 ObservableValue 都需要
- Map:ObservableObject 中 _values 的容器,内容是 ObservableValue 的引用
- Set:ObservableValue 中的 observers_ 订阅者列表(Derivation ),在这个 case 中,是经过 observer 包装的 render 函数,每一个 ObservableValue 都会订阅一次
uploading mobx-8.png...
总的来说, Derivation 观察一个大数组的内存开销可以概括为:
- 一个 Derivation 对象的固定开销。
- 一个与 被访问元素数量 成正比的 observing_ 数组的开销。
- 一个与 被访问元素数量 成正比的 observers_ 反向链接开销。
如果 10 万个对象 + 每个属性都有响应式双向关联开销,内存自然暴涨。
在这种情况下,如果 Derivation 内存没有被正确释放,就非常容易导致内存泄露。
因此,对于 Array<Object> 结构的数据,一定要谨慎。使用 makeAutoObservable 或者是 autorun 较多时,就非常容易中招。
讲到这里,还是有点抽象,那么我们来看一个真实的 case:
class DemoStore {
rawData = [];
dataAfterTransform = [];
constructor() {
makeAutoObservable(this);
autorun(() => {
const rawDataSlice = this.rawData.map(e => {
return {
...e,
name: e.name,
};
});
const output = this.transformData(rawDataSlice);
this.dataAfterTransform = output;
this.onDataAfterTransformChange(output);
});
}
}
让我们假设 rawData 会有 10W 条数据,并且结构会比示例更复杂。
以上的实现有哪些问题?
- 数据派生和副作用都在 autorun 中实现
- map 操作实际读取了数组项的所有属性,会极大的增加内存开销
- autorun 不会缓存,任意数组项的任意属性变动都会导致 autorun 重新触发
- autorun 没有处理 disposer,会导致内存泄露
- dataAfterTransform 是外界实际消费的数据,可能会内存开销翻倍
最佳实践
class DemoStore {
rawData = [];
constructor() {
makeObservable(this, {
rawData: observable.ref,
});
// 如果一定要用...
autorun(() => {
if (this.dataAfterTransform.length > 0) {
// ...
}
});
}
@computed
get dataAfterTransform() {
const rawDataSlice = this.rawData.map(e => {
return {
...e,
name: e.name,
};
});
return this.transformData(rawDataFrame);
}
}
核心思路:最小化数据访问,避免无谓的响应式依赖关系。
- 复杂结构 → observable.ref
- 派生数据 → computed
- 副作用 → autorun(必须手动释放)
总结
为了降低使用 MobX 的复杂度,可以遵循以下基本原则,这些实践足以覆盖大多数场景:
- 保持单一数据源:通过依赖注入来实现不同模块之间的引用,避免冗余状态。
- 复杂数据结构 → 优先使用 observable.ref
- 若确实需要追踪其中的属性,应为其单独创建 Model,只让必要的属性参与依赖收集。
- 派生状态 → 优先使用 computed:确保结果可缓存、可复用。
- 副作用 → 谨慎使用 autorun 等方法:仅在无法避免时使用,并显式释放内存,避免泄露。