🆕 专题一 产品新功能/新版本
1. Kubernetes v1.33: Octarine 发布
Kubernetes v1.33 Advances in AI, Security and the Enterprise
此版本包含 64 项增强功能。在这些增强功能中,18 个已升级为稳定版,20 个进入 Beta 版,24 个已进入 Alpha 版,2 个已弃用或撤销。
主要更新
- 稳定版:边车容器、按索引的任务回退限制、作业成功策略、绑定 ServiceAccount 令牌安全改进等。
- 测试版:用于 Pod 垂直扩展的原地资源调整大小、kubectl 的新配置选项 (.kuberc)、Windows kube-proxy 中对直接服务器返回 (DSR) 的支持等。
- Alpha 版:用于 HorizontalPodAutoscaler 的可配置容差、可配置的容器重启延迟、自定义容器停止信号、DRA 增强功能等。
弃用与移除
- Endpoint API 已弃用,建议用户迁移到 EndpointSlices。
- 节点状态中的 kube-proxy 版本信息已被删除。
- 已删除树内 gitRepo 卷驱动程序。
- 已删除对 Windows pod 的主机网络支持。
扩展阅读
Kubernetes v1.33:HorizontalPodAutoscaler 可配置容差
2. DigitalOcean Kubernetes Service 引入可扩展的相关功能
背景
Kubernetes 是许多现代应用程序的基础,可提供当今动态工作负载所需的可扩展性和弹性。但是,随着应用程序的增长,其基础设施和扩展要求也在增长。管理多个集群来处理大规模工作负载会带来运营复杂性、网络管理难度增加以及 DevOps 团队面临的挑战。这些挑战可能包括更大的资源碎片化、由于集群间通信而增加的延迟以及维护多个集群的安全性和合规性的手动负担。这些挑战对于数据密集型工作负载(如视频流、大规模数据分析和安全操作)尤其明显。
DOKS 简介
强大且经济高效的云基础设施,针对初创企业、成长型数字企业和独立软件供应商 (ISV) 进行了优化。
产品特点:
- 简化操作
DOKS 完全管理控制平面,因此您可以利用 DO API、CLI 和 UI 专注于您的业务。 - 可靠启动
提高集群的可靠性并防止容错、负载平衡和流量管理带来的扩展问题。 - 启用 AI/ML
利用高性能 NVIDIA H100 GPU 资源从初始实验扩展到全面生产部署。 - 自动缩放
使用 DigitalOcean Cluster AutoScaler 将您的集群无缝扩展到每个集群 1,000 个节点。 - 降低成本
动态地扩大或缩小您的基础设施以满足需求并最大化您的数据解决方案,而不必担心带宽成本。 - 无缝更新
轻松利用最新的 Kubernetes,并选择自动更新、维护窗口和激增升级。
新功能 & 为什么
- 将集群工作节点容量从每个集群 500 增加到 1,000 个
使企业能够轻松扩展,同时保持基础架构的精简和成本效益。有了这种增加的集群容量,您不再需要管理多个 Kubernetes 集群来扩展工作负载。这简化了操作,减少了管理开销,并确保了跨环境更一致的应用程序性能。现在,开发人员可以在单个 DOKS 集群上部署更大的数据密集型应用程序,从而简化操作并增强可扩展性。 - 使用 VPC 原生 Kubernetes 优化网络,直接从您的虚拟私有云 (VPC) 地址池分配 IP 地址
此功能支持集群和 VPC 资源之间的本机路由,将 DOKS 集群与您现有的网络架构无缝集成。这提高了网络性能,简化了集群间通信,并消除了对复杂网络配置的需求,从而使您的工作负载能够更高效地运行。 - 用 eBPF 驱动取代了 kube-proxy,提升网络性能
显著改善了数据平面处理、带宽效率和网络延迟。与传统的数据包过滤方法不同,eBPF 支持高性能内核处理,从而减少了上下文切换开销并加快了数据包处理时间。总体而言,此功能对于高容量应用程序尤其有益,例如实时分析、事务密集型工作负载以及需要服务间低延迟通信的微服务架构。 - 将 Managed Cilium 引入 DOKS,以实现高性能网络
通过在控制平面上运行完全托管的 Cilium,开发人员可以享受增强的安全性、可靠性和可扩展性。通过降低运营复杂性,企业可以专注于创新,而不是管理网络基础设施。此外,Cilium Hubble 的集成增强了网络可观察性,使故障排除和性能优化比以往任何时候都更容易。
这些更新有助于企业在单个 DOKS 集群内运行更大的工作负载,从而减少对复杂的多集群管理的需求,并实现新的性能、可靠性和简单性水平。
3. 使用 Ceph 在边缘 OpenShift 上提供 Red Hat OpenStack 服务
Red Hat OpenStack Services on OpenShift at the edge with Ceph
背景
随着便携式设备、物联网和其他分布式小型设备的兴起, 边缘计算已成为许多企业的关键领域。边缘计算将应用程序基础设施从集中式数据中心带到网络边缘,尽可能靠近消费者,以提供低延迟和近乎实时的处理。这种用例不仅限于电信,还扩展到医疗保健、能源、零售、远程办公室等。
Red Hat OpenStack Platform 13 引入了一种称为分布式计算节点 (DCN) 的边缘解决方案。这使客户能够将计算资源(计算节点)部署在靠近消费者设备的地方,同时将控制平面集中在更传统的数据中心,例如国家或地区站点。
分布式计算节点简介
分布式计算节点是 OpenShift 上的 Red Hat OpenStack 服务之一,用于解决边缘计算用例。OpenStack 控制平面在托管于常规数据中心的 OpenShift 上运行,而计算则远程分布在多个站点上。
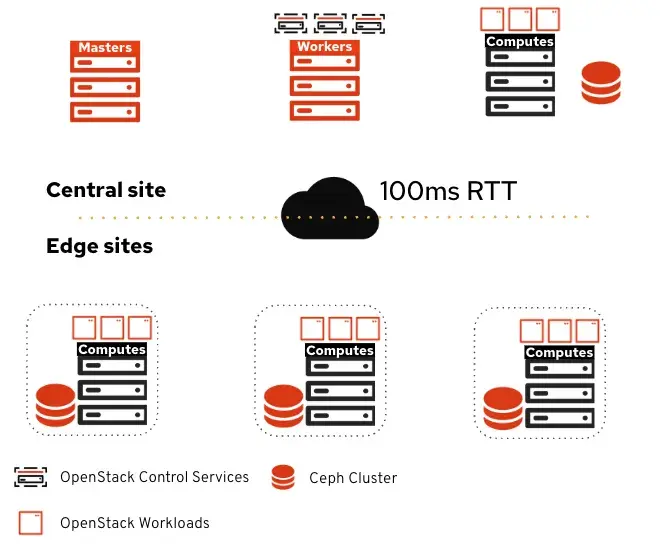
顶部是中央站点,其中包含:
- OpenShift 集群用于运行 OpenStack 控制平面服务
- 计算节点(可选)
- Ceph 集群
底部是远程边缘站点。这些站点仅包括计算节点和可选的 Ceph 集群。每个站点彼此独立,并且它们在各自的可用区域中被隔离,并带有可选的专用 Ceph 集群(如果工作负载需要持久存储)。
有所调整的地方:专用于边缘站点的存储服务
管理边缘存储访问和消耗的主要组件有三个:
-
Ceph :提供边缘存储
-
Cinder :通过卷管理持久存储
-
Glance :提供图像
扩展阅读
Moving AI to the edge: Benefits, challenges and solutions
4. Kubeflow 增强了机器学习工作流的灵活性、效率和可扩展性
Kubeflow 是什么
Kubeflow 使人工智能和机器学习变得简单、可移植且可扩展。Kubeflow 是一个基于 Kubernetes 组件的生态系统,覆盖了 AI/ML 生命周期中的每个阶段,并支持一流的开源工具和框架。
主要更新
- Trainer 2.0: 支持 JAX 分布式训练,并为 Trainer V2 奠定了基础。
- 模型注册表新界面: 提供更友好的网页界面,简化模型管理。
- Spark Operator 成为核心组件: 增强架构、安全性和性能,支持 YuniKorn 群体调度。
- Kubernetes 和容器安全增强: 提升 CISO 兼容性,推进无根容器和 Pod 安全标准。
- 大语言模型超参数优化: Katib 提供新 API,简化 LLMOps 工作流程。
- Pipelines 中的循环并行性: 增强对并行执行的控制,提高资源利用率。
- KServe 功能增强: 包括新的 Python SDK、OCI 模型存储和模型缓存功能。
5. Google Cloud Next
背景
2025 年 4 月 9 日至 11 日在拉斯维加斯曼德勒海湾会展中心举行了 Next 大会。
相关更新
- Google Kubernetes Engine 加速 AI 相关工作
- 发布了第七代 TPU 芯片 Ironwood 的新型 AI,用于提升 AI 模型 Gemini 的速度和效率
- Google 的 Agent2Agent 协议帮助 AI 代理相互通信
6. Keycloak 26.2.0 发布
Keycloak 是什么
Keycloak 提供用户联合、强身份验证、用户管理、精细授权等。以最少的工作量为应用程序添加身份验证和保护服务。无需处理存储用户或验证用户。
🎤 这个版本号有点夸张。
相关更新
- 支持标准令牌交换
- 支持细粒度管理员权限
- 指标和 Grafana 仪表盘指南
- 零配置安全集群通信
- 滚动更新优化和自定义镜像
- Admin Events API 中的附加查询参数
- 日志支持 ECS 格式
- 为 X.509 身份验证器加载的 CRL 的新缓存
- Operator 创建 NetworkPolicies 以限制流量
- 管理接口的信任和密钥材料的重载选项
- 使用客户端策略动态选择身份验证流程
- JWT 客户端身份验证与最新的 OIDC 规范一致
- 获取用户凭证时,联邦凭证现已可用
- 用于 SMTP 的基于令牌的身份验证(XOAUTH2)
- 访问令牌头类型的客户端新配置
- OpenID for Verifiable Credential Issuance 文档
7. Rook v1.17 存储增强
重要更新
- 对象存储:
- ObjectBucketClaims 默认更加安全。
- 增强 CephObjectStoreUser 凭证管理功能,支持多组凭证和轮换。
- 支持设置 Bucket Owner。
- 支持 Kafka 认证机制。
- CSI:
- 升级到 Ceph CSI 3.14,带来诸多改进。
- Ceph CSI Operator 仍在实验阶段,计划在 v1.18 版本默认启用。
- Mon Endpoints:
- 支持外部 Mons,允许在 Kubernetes 集群外部配置 Mon。
- 实现 Mons 的 DNS 解析,方便客户端在 Mon 故障转移时自动更新连接。
- Ceph Config:
- 支持节点特定的 node.conf 覆盖,实现更精细化的配置。
- 支持 Kubernetes v1.28 至 v1.33 版本。
📰 专题二 新闻
1. NVIDIA 收购 Run:ai 并将其核心调度组件 KAI Scheduler 开源
NVIDIA Open Sources KAI Scheduler To Help AI Teams Optimize GPU Utilization
Struggling with GPU Waste on Kubernetes? How KAI-Scheduler’s Sharing Unlocks Efficiency
KAI-Scheduler vs HAMi:GPU 共享的技术路线分析与协同展望
KAI Scheduler 是什么
KAI Scheduler 是一个强大、高效且可扩展的 Kubernetes 调度程序 ,旨在优化人工智能 (AI) 和机器学习 (ML) 工作负载的 GPU 资源分配。
KAI Scheduler 专为管理大规模 GPU 集群(包括数千个节点和高吞吐量工作负载)而设计,是广泛且要求苛刻的环境的理想选择。KAI Scheduler 允许 Kubernetes 集群管理员将 GPU 资源动态分配给工作负载。
KAI Scheduler 支持整个 AI 生命周期,从需要最少资源的小型交互式作业到大型训练和推理,所有这些都在同一个集群内完成。它确保最佳资源分配,同时保持不同消费者之间的资源公平性。它可以与集群上安装的其他调度程序一起运行。
KAI Scheduler 的产品核心亮点
KAI-Scheduler 通过 Reservation Pod 这种智能、非侵入式的方法做到了 GPU 资源预留。
- 预留 :在 Kubernetes 资源模型中声明整个 GPU。
- 使状态可见 :间接发出信号表明 GPU “正在使用” 以进行共享。
- 保护 :防止默认调度程序干扰。
- 链接 :通过内部跟踪和标签(如 runai-gpu-group )将物理 GPU 连接到共享它的用户 Pod。

KAI Scheduler 的主要功能
- 批量调度 :确保组内的所有 pod 都同时调度或根本不调度。
- 装箱和扩展调度:通过最小化碎片(装箱)或提高弹性和负载平衡(扩展调度)来优化节点使用率。
- 工作负载优先级 :在队列中有效地对工作负载进行优先排序。
- 分层队列 :使用两级队列层次结构管理工作负载,实现灵活的组织控制。
- 资源分配 :自定义每个队列的配额、超出配额的权重、限制和优先级。
- 公平政策 :使用主导资源公平性 (DRF) 和跨队列的资源回收确保公平的资源分配。
- 工作负载整合:智能地重新分配正在运行的工作负载,以减少碎片并提高集群利用率。
- 弹性工作负载 :在定义的最小和最大 pod 数量内动态扩展工作负载。
- 动态资源分配 (DRA):通过 Kubernetes ResourceClaims 支持特定于供应商的硬件资源(例如,NVIDIA 或 AMD 的 GPU)。
- GPU 共享 :允许多个工作负载高效共享单个或多个 GPU,最大限度地提高资源利用率。
- 云和本地支持:完全兼容动态云基础设施(包括 Karpenter 等自动扩展器)以及静态本地部署。
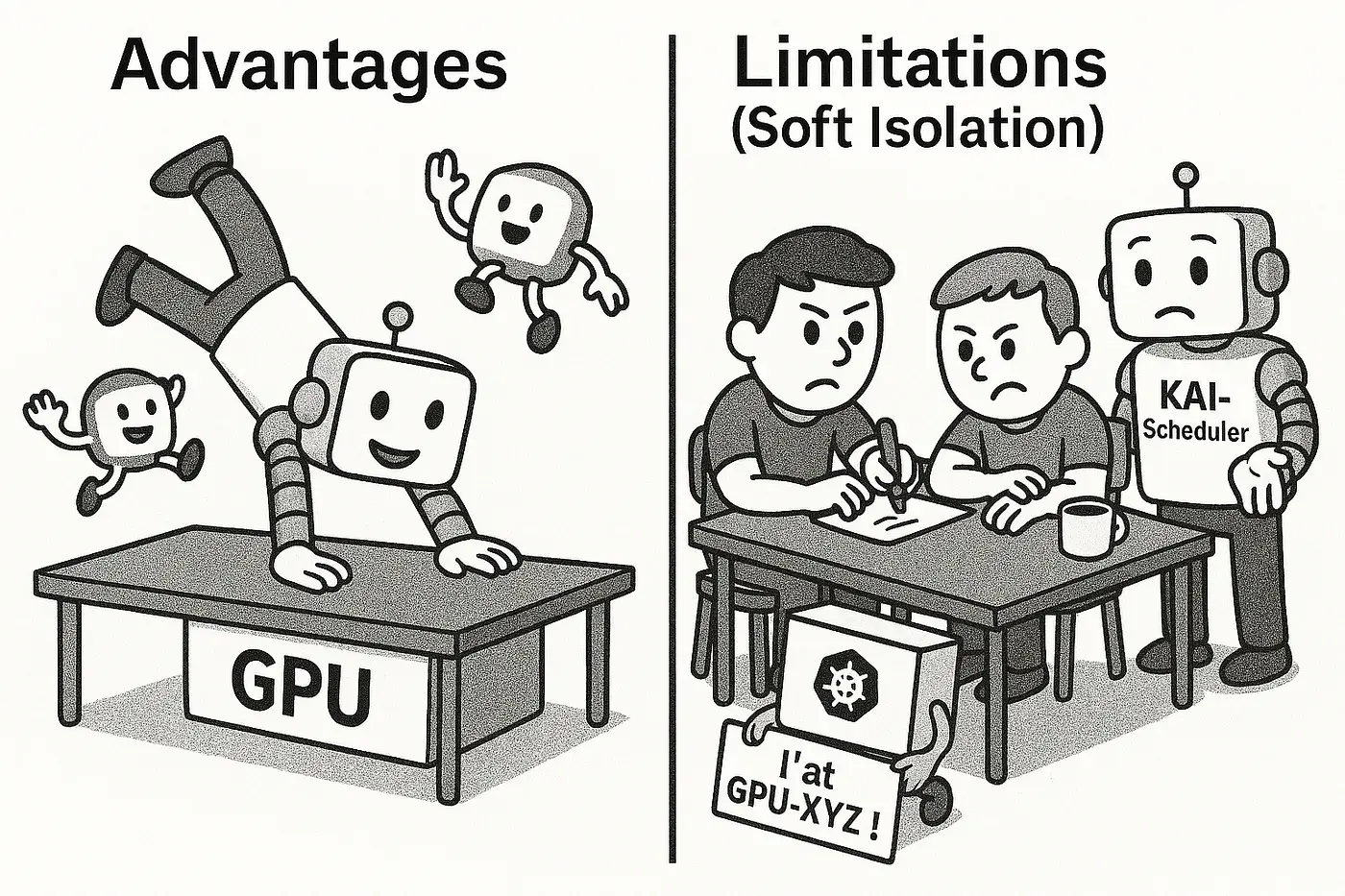
KAI Scheduler 的优点与限制
优点
- 无缝集成 :与标准 Kubernetes 组件配合使用 - 无需进行核心更改。
- 灵活的请求 :支持基于分数和基于内存的请求。
- 创新设计 :Reservation Pod 巧妙地解决了 Kubernetes 的限制。
- 提高利用率 :非常适合推理、开发/测试或任何多个任务可以共享 GPU 的工作负载,从而显著提高资源效率并降低成本。
限制
- 无强制执行 :理解这一点至关重要。KAI-Scheduler 管理逻辑分配,但不会在硬件/驱动程序级别强制限制。这称为软隔离。
- 依赖良好行为准则:某个 Pod 虽被分配了 20% 的GPU显存,但理论上仍可能尝试占用 100% 的资源。KAI 调度器不会主动阻止此类行为。
- 潜在 "噪声邻居" 问题:单个行为异常的 Pod 可能独占资源,进而影响共享同一 GPU 的其他工作负载。
- 应用调优建议:为达到最佳效果,应用程序应遵循其分配的资源限额(例如:通过框架特定的显存限制配置进行约束)。
如何使用 KAI Scheduler
使用 Pod 注释可以直接通过 KAI-Scheduler 请求共享 GPU。具体操作介绍见链接。
其他方案
原生 Kubernetes
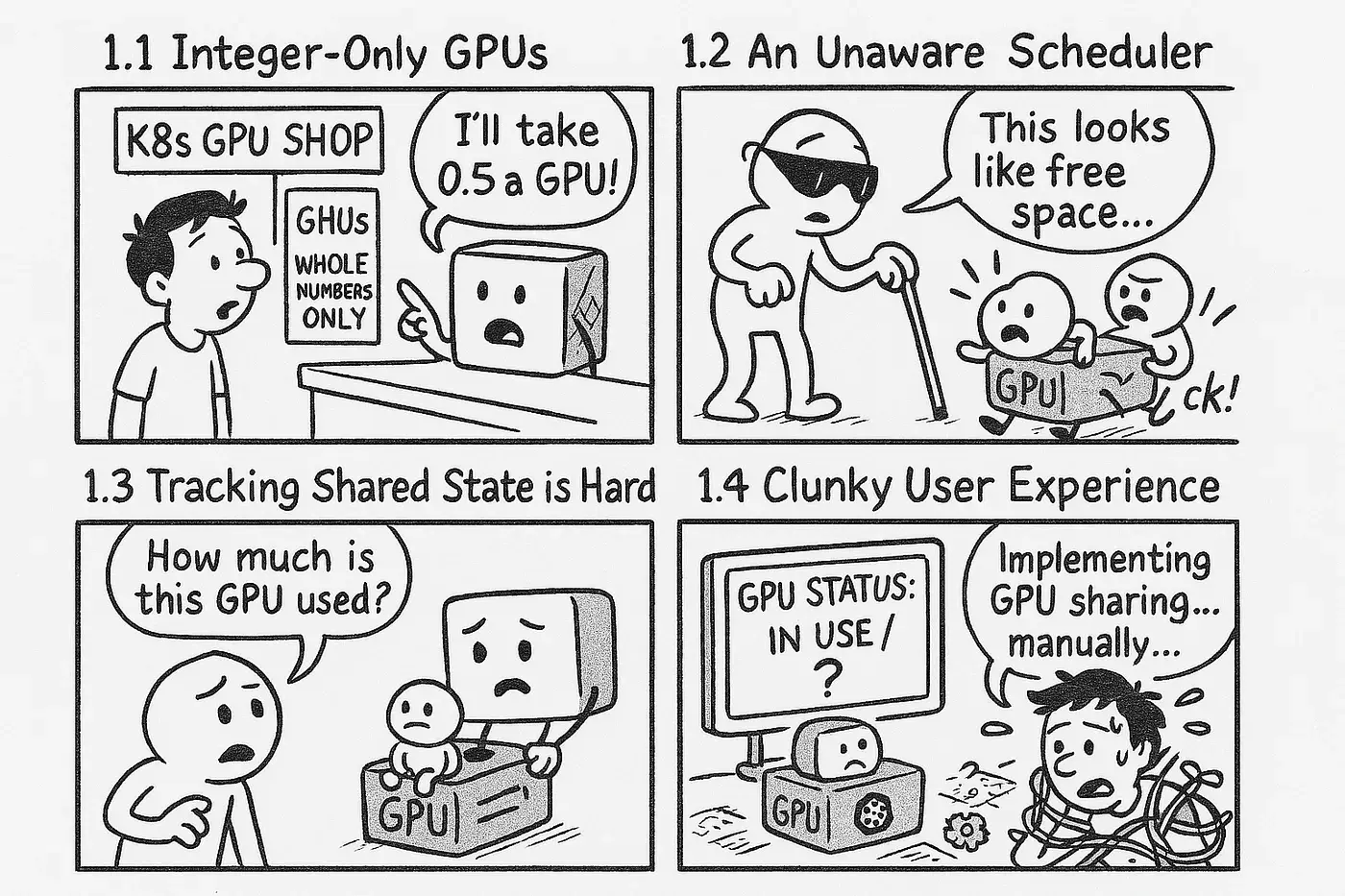
在 Kubernetes 上运行需要 GPU 的工作负载通常会导致一个令人沮丧的问题:宝贵的 GPU 处于闲置状态,因为标准 Kubernetes 调度程序只能将整个 GPU 分配给单个容器,即使该作业只需要其一小部分功能。这种低效率会增加成本并减缓创新。具体原因如下:
- Kubernetes 将 nvidia.com/gpu 视为不可分割的资源。您可以请求 1 个 GPU 或 2 个 GPU,但不能原生请求 “0.5 个 GPU” 或 “2000MiB 的 GPU 内存”。
- 默认的 kube-scheduler 没有部分 GPU 的概念。它不知道 GPU 是否被部分使用,如果它尝试将多个 Pod(一些需要部分 GPU,一些需要整个 GPU)放置到同一物理设备上,可能会导致冲突。
- Kubernetes 没有内置方法来跟踪或通告特定 GPU 是否被共享机制“部分占用”。这种缺乏可见性的情况阻碍了智能调度。
- 如果没有专门的解决方案,开发人员就需要复杂的解决方法或自定义控制器才能尝试 GPU 共享,这对于大多数团队来说都是不切实际的。
HAMi
相较于 KAI Scheduler 的软隔离,HAMi 是硬隔离:使用自定义设备插件和潜在的低级拦截(如挂钩 CUDA 调用)来强制执行资源限制(内存,有时是计算)。更复杂,但提供保证。
硬隔离通常是通过以下方式达成的:
- 定制 HMAi Device Plugin: 不仅仅是上报资源,更是在分配时注入隔离配置。
- 结合 HAMi-Core: 利用更底层的 CUDA-Runtime 和 CUDA-Driver 层之间的拦截,对每个容器的 GPU 显存资源进行强制性限制。
硬隔离带来的关键优势:
- 资源有保障: 每个容器能使用的 GPU 资源有明确的上限,无法超额占用。
- 隔离性强: 有效防止“吵闹邻居”问题,保障多租户环境下的服务质量 (QoS)。
- 应用透明: 大部分情况下,用户应用程序无需修改代码或添加额外配置。
可以看出,HAMi 更适合对资源保障和性能稳定性有严格要求的场景。
扩展阅读
Reclaiming Idle GPUs in Kubernetes: A Practical Approach (and a Call for Ideas!)
🎤 相较于前面 KAI Scheduler 和 HAMi 共享的思路,这里的思路是保证独占但赶走 Pod/主动回收空闲的 GPU。
NVIDIA 为什么要开源 KAI Scheduler
根据推测,可能有以下几个方面的原因:
- 降低使用门槛,推动 AI 应用在 Kubernetes 上的普及
- 推动生态合作、扩大影响力
- 随着 Red Hat、Google、Microsoft、OpenShift、Kubeflow 等在 AI/ML 工具链上发力,NVIDIA 也需要保持其 AI 堆栈的“不可替代性”、抢占 MLOps 和 AI Infra 领域的话语权
- 增强社区认可与开发者关系
总结一句话:NVIDIA 开源 KAI,是为了巩固其在 AI 基础设施领域的主导地位,推动其软件生态成为 Kubernetes 上部署 AI 的默认选择,从而驱动更多 GPU 的使用。
2. NVIDIA 近 20 年后对 CUDA 做出重大改变
背景
NVIDIA 正在对其 CUDA 编程工具进行重大改革,以创建一个可以在整个数据中心运行的单一运行时,而不是独立的 GPU。此举是为了应对人工智能工作负载日益增长的规模,这些工作负载现在通常跨越数十万个 GPU。
下一代产品 CUDA DTX
CUDA DTX 即 CUDA Distributed Execution 具有以下关键特性:
- 分布式执行:旨在跨越整个数据中心,而不是单个 GPU。
- 统一的机器模型:将 GPU、CPU、网络和其他加速器视为一个单一的计算资源,从而简化编程。
- 统一的运行时:管理跨分布式 GPU 网络的资源、拓扑和执行。
- 异步执行:有效管理并行操作。
目标
- 简化大规模人工智能应用程序的编程。
- 通过跨大量 GPU 实现高效的资源利用来提高性能。
- 使 CUDA 适应不断变化的人工智能计算环境。
时间计划
CUDA DTX 仍处于早期开发阶段,预计在未来两年内推出。
其他调整
NVIDIA Finally Adds Native Python Support to CUDA
根据 GitHub 的 2024 年开源调查,2024 年,Python 将成为世界上最受欢迎的编程语言,超越 JavaScript。
多年来,NVIDIA 的 CUDA 软件工具包一直没有原生 Python 支持。但这种情况现在有所改变。在 GTC(NVIDIA GPU Technology Conference,由英伟达召开,面向开发者的全球人工智能大会)上,NVIDIA 宣布其 CUDA 工具包将原生支持并全面集成 Python。开发人员将能够使用 Python 在 GPU 上直接执行算法式计算。
延伸阅读
NVIDIA GTC 2025 Wrap-Up: 18 New Products to Watch
NVIDIA GTC 2025 大会上,NVIDIA 在计算、网络和存储方面进行了创新,这些创新大多与 AI 有关。
3. Mirantis 的 k0s 和 k0smotron 加入 CNCF Sandbox
KubeCon Europe: Mirantis’ k0s and k0smotron Join CNCF Sandbox
K0s 简介
K0s 是一个轻量级的开源 Kubernetes 发行版,旨在简化 Kubernetes 集群的安装和管理。它的特点是采用单二进制架构,将多个 Kubernetes 组件整合到一个可执行文件中,从而减少依赖项和运营开销。它不需要任何外部依赖项,因此易于在不同的 Linux 操作系统上部署和维护。
K0smotron 简介
K0smotron 与 k0s 一起开发,通过 Kubernetes API 声明式地管理托管的 k0s 控制平面、工作器、集群和底层基础设施。该集群管理程序的关键创新在于它能够将 Kubernetes 控制平面作为集群内的容器进行托管和管理,与需要专用控制平面节点或虚拟机的传统方法相比,可显著降低运营开销和成本。该工具简化了大规模配置和混合部署,同时降低了运营复杂性并提高了灵活性。
虽然它主要设计用于与 k0s 配合使用,但它也可以管理任何 CNCF 认证的 Kubernetes 集群。
加入 CNCF Sandbox 的好处
Mirantis 预计 k0s 和 k0smotron 将受益于社区支持、增强的知名度以及与其他 CNCF 项目的合作机会。此举凸显了 Mirantis 对开源创新的承诺及其在推动云原生生态系统向前发展方面的作用。(K0s 已有近五年历史 ,而 k0smotron 才两年。)
插播一则 k0s 与 Kairos 集成的消息
Kairos 是一个 Linux 元发行版,现在正朝着 Kubernetes 元发行版的方向发展。
4. CloudBolt 收购 StormForge 以增强 Kubernetes 优化
CloudBolt Acquires StormForge To Enhance Kubernetes Optimization
CloudBolt 是什么
CloudBolt Software 是总部位于马里兰州北贝塞斯达的企业云管理和集成解决方案提供商(云成本管理公司)。
StormForge 是什么
StormForge 是一个由数据科学,机器学习和运维开发领域工程师在 2015 年成立的专注于云原生 Kubernetes 大规模资源管理的团队,提供以应用性能和资源利用率为牵引的运维优化解决方案。StormForge 是 CNCF 全局版图中持续优化领域的项目之一。
StormForge 的 Optimize Live 是该公司的主要服务,它使用机器学习 (ML) 分析历史使用数据,识别容器之间的复杂关系和依赖关系,并为不断变化的工作负载模式生成可靠的建议。本质上,它可以实时调整您的工作负载。
此外,StormForge 还集成了 Horizontal Pod Autoscaler (HPA) 、 KEDA 和 Karpenter 等工具,以提高资源扩展和节点管理的效率。
为什么要收购
此举旨在将 StormForge 先进的机器学习功能集成到 CloudBolt 屡获殊荣的 FinOps 平台中,打造全面的 Kubernetes 成本管理和优化解决方案。专注于 FinOps 并致力于简化云操作和最大化云价值的 CloudBolt,相信用户可以通过这种新的组合节省大量成本。
自 2024 年 1 月公布增强型 FinOps 计划以来,CloudBolt 一直处于 AI/ML 驱动的 FinOps 的前沿。收购 StormForge 进一步推动了 CloudBolt 的创新,巩固了其在智能云优化领域的领导地位。合并后的平台将为客户提供从报告到优化功能的闭环解决方案,为 FinOps 领导者提供值得信赖的工具。
CloudBolt 的其他收购行为
2020 年收购 Kumolus
3 Things to Know About Kumolus
Kumolus 是一个基于 SaaS 的云管理平台 (CMP)。
2020 年收购 SovLabs
SovLabs 是一家提供 IT 自动化和云管理解决方案的公司。他们的产品主要帮助企业简化和自动化在混合云和多云环境中的各种 IT 任务。
5. Google、字节跳动和 Red Hat 使 Kubernetes 具备生成式 AI 推理能力
Google, Bytedance, and Red Hat make Kubernetes generative AI inference aware
比较技术向。
核心的创新:
-
智能路由与高效微调支持
- Gateway API 推理扩展:支持基于 LLM 感知的智能路由(替代传统轮询),动态加载微调模型(如 LoRA 适配器),显著降低大规模参数高效微调(PEFT)的成本。
- 新增原生 API(InferencePool 和 InferenceModel)以简化 PEFT 操作。
-
推理性能基准标准
- 推出统一的性能评测工具,提供加速器性能指标和 HPA 扩缩容阈值,帮助用户量化模型服务、硬件及 Kubernetes 编排的整体表现。
-
动态资源分配(DRA)
- 与 Intel 等合作开发,自动化分配 GPU/TPU 等资源,结合 vLLM 引擎提升跨加速器的调度效率和可移植性。
6. 蚂蚁集团获得 CNCF 最佳最终用户奖
KubeCon + CloudNativeCon 欧洲,英国伦敦 — 2025 年 4 月 3 日 — 云原生计算基金会(CNCF)今天宣布,蚂蚁集团获得 CNCF 最佳最终用户奖。CNCF 每年两次表彰在推动云原生生态系统创新与合作方面表现突出的最终用户成员。
自 2019 年成为 CNCF 最终用户成员以来,蚂蚁集团始终致力于推动云原生技术的发展。在过去五年作为金牌最终用户成员期间,公司持续为 CNCF 生态系统做出贡献,获得了顶级最终用户贡献者的认可,目前在所有时间中排名第四,在过去一年中排名第三。
该公司成功将 Kubernetes 扩展至 15,000 个节点,展示了其专业知识和推动云原生基础设施边界的能力。
蚂蚁集团是 CNCF 生态系统的早期关键贡献者,早期对 Kubernetes 和 containerd 的贡献,以及 2018 年捐赠 Dragonfly——首个大型集群的高级 OCI 镜像分发加速器,使其成为 CNCF 的第 30 个项目,也是首批来自最终用户公司的捐赠项目之一。
此后,他们在 2023 年捐赠了基于约束的策略语言 KCL,并在 2024 年捐赠了意图驱动的内部开发平台编排工具 KusionStack,继续积极参与贡献。
蚂蚁集团致力于知识分享,积极参与云原生社区,组织 Kubernetes 社区日(KCD)、地方聚会,并在 KubeCon 活动中发表深刻演讲。这些举措为希望有效扩展云原生操作的组织提供了宝贵的指导。
7. 教皇对 AI 的看法
Cloud Service: What Pope Francis Thought About AI
背景
教皇方济各于 2025 年 4 月 21 日复活节星期一在梵蒂冈圣玛尔塔之家的住所去世,享年 88 岁。
文件摘要与总结
ANTIQUA ET NOVA Note on the Relationship Between Artificial Intelligence and Human Intelligence
🎤 这篇文章抛开纯宗教的论述写得很好,有些句子很美,像是在读一本哲学刊物。下面摘抄一些机翻内容:
- In the classical tradition, the concept of intelligence is often understood through the complementary concepts of “reason” (ratio) and “intellect” (intellectus). These are not separate faculties but, as Saint Thomas Aquinas explains, they are two modes in which the same intelligence operates: “The term intellect is inferred from the inward grasp of the truth, while the name reason is taken from the inquisitive and discursive process.”[18] This concise description highlights the two fundamental and complementary dimensions of human intelligence. Intellectus refers to the intuitive grasp of the truth—that is, apprehending it with the “eyes” of the mind—which precedes and grounds argumentation itself. Ratio pertains to reasoning proper: the discursive, analytical process that leads to judgment. Together, intellect and reason form the two facets of the act of intelligere, “the proper operation of the human being as such.”[19]
在古典传统中,智能的概念通常通过“理性”(ratio)和“理智”(intellectus)这两个互补的概念来理解。正如圣托马斯·阿奎那所解释的那样,它们并非是独立的官能,而是同一种智能运作的两种模式:“‘理智’一词源于对真理的内在把握,而‘理性’之名则取自探究和推论的过程。”[18] 这段简洁的描述突出了人类智能的两个基本且互补的维度。“理智”指的是对真理的直觉把握——即用心灵的“眼睛”领悟真理——它先于论证本身并为其奠定基础。“理性”则关乎恰当的推理:即引向判断的推论性的、分析性的过程。理智和理性共同构成了“理解”(intelligere)这一行为的两个方面,“理解”是“作为人类本身所特有的恰当运作”[19]。
- Describing the human person as a “rational” being does not reduce the person to a specific mode of thought; rather, it recognizes that the ability for intellectual understanding shapes and permeates all aspects of human activity. [20] Whether exercised well or poorly, this capacity is an intrinsic aspect of human nature. In this sense, the “term ‘rational’ encompasses all the capacities of the human person,” including those related to “knowing and understanding, as well as those of willing, loving, choosing, and desiring; it also includes all corporeal functions closely related to these abilities.” [21] This comprehensive perspective underscores how, in the human person, created in the “image of God,” reason is integrated in a way that elevates, shapes, and transforms both the person’s will and actions. [22]
将人描述为“理性的”存在,并非是将人简化为一种特定的思维模式;相反,它承认智性理解的能力塑造并渗透到人类活动的所有方面。[20] 无论运用得好坏,这种能力都是人类本性的内在方面。从这个意义上说,“‘理性的’一词涵盖了人类的所有能力”,包括那些与“认识和理解相关的能力,以及与意愿、爱、选择和渴望相关的能力;它还包括与这些能力密切相关的所有的身体功能。”[21] 这种全面的视角强调了,在按照“天主的肖像”创造的人身上,理性是如何被整合的,从而提升、塑造和转化人的意志和行为。[22]
- Drawing an overly close equivalence between human intelligence and AI risks succumbing to a functionalist perspective, where people are valued based on the work they can perform. However, a person’s worth does not depend on possessing specific skills, cognitive and technological achievements, or individual success, but on the person’s inherent dignity, grounded in being created in the image of God.[66] This dignity remains intact in all circumstances, including for those unable to exercise their abilities, whether it be an unborn child, an unconscious person, or an older person who is suffering. [67] It also underpins the tradition of human rights (and, in particular, what are now called “neuro-rights”), which represent “an important point of convergence in the search for common ground”[68] and can, thus, serve as a fundamental ethical guide in discussions on the responsible development and use of AI.
将人类智能与人工智能过度等同,有陷入功能主义视角的风险,在这种视角下,人的价值取决于他们能够完成的工作。然而,人的价值并不取决于拥有特定的技能、认知和技术成就或个人成功,而是取决于人固有的尊严,这种尊严根植于人是按照天主的形象创造的。[66] 这种尊严在任何情况下都保持完整,包括那些无法行使其能力的人,无论是未出生的孩子、失去意识的人,还是正在遭受痛苦的老年人。[67] 它也构成了人权传统(特别是现在所谓的“神经权利”)的基础,这些人权代表着“在寻求共同立场上的一个重要的汇合点”[68],因此,可以在负责任地开发和使用人工智能的讨论中,作为基本的伦理指南。
- Given these considerations, one can ask how AI can be understood within God’s plan. To answer this, it is important to recall that techno-scientific activity is not neutral in character but is a human endeavor that engages the humanistic and cultural dimensions of human creativity.[71]
鉴于这些考量,人们可以问,如何在天主的计划内理解人工智能。要回答这个问题,重要的是要忆及,技术科学活动本质上并非中立的,而是一种人类的努力,它涉及到人类创造力的人文和文化维度。[71]
- However, while AI holds many possibilities for promoting the good, it can also hinder or even counter human development and the common good. Pope Francis has noted that “evidence to date suggests that digital technologies have increased inequality in our world. Not just differences in material wealth, which are also significant, but also differences in access to political and social influence.”[103] In this sense, AI could be used to perpetuate marginalization and discrimination, create new forms of poverty, widen the “digital divide,” and worsen existing social inequalities.[104]
然而,虽然人工智能蕴藏着许多促进福祉的可能性,但它也可能阻碍甚至对抗/抵消/阻挠人类发展和共同利益。教宗方济各指出,“迄今为止的证据表明,数字技术加剧了我们世界的不平等。不仅是物质财富方面的差异(这也非常显著),而且还包括获得政治和社会影响力的差异。”[103] 从这个意义上说,人工智能可能被用来延续边缘化和歧视,制造新的贫困形式,扩大“数字鸿沟”,并加剧现有的社会不平等。[104]
- In this context, it is important to clarify that, despite the use of anthropomorphic language, no AI application can genuinely experience empathy. Emotions cannot be reduced to facial expressions or phrases generated in response to prompts; they reflect the way a person, as a whole, relates to the world and to his or her own life, with the body playing a central role. True empathy requires the ability to listen, recognize another’s irreducible uniqueness, welcome their otherness, and grasp the meaning behind even their silences.[121] Unlike the realm of analytical judgment in which AI excels, true empathy belongs to the relational sphere. It involves intuiting and apprehending the lived experiences of another while maintaining the distinction between self and other.[122] While AI can simulate empathetic responses, it cannot replicate the eminently personal and relational nature of authentic empathy.[123]
在这种背景下,重要的是要澄清,尽管使用了拟人化的语言,但没有任何人工智能应用能够真正体验到共情。情感不能被简化为面部表情或响应提示而生成的短语;它们反映了一个人作为一个整体,如何与世界以及他或她自己的生活相关联,而身体在其中扮演着核心角色。真正的共情需要倾听的能力,认识到他者不可化约的独特性,接纳他们的差异性,并理解他们沉默背后的含义。[121] 与人工智能擅长的分析判断领域不同,真正的共情属于关系领域。它涉及直觉地理解和领悟他人的生活经验,同时保持自我与他者之间的区分。[122] 虽然人工智能可以模拟共情反应,但它无法复制真实共情那种极度个人化和关系化的本质。[123]
- AI is currently eliminating the need for some jobs that were once performed by humans. If AI is used to replace human workers rather than complement them, there is a “substantial risk of disproportionate benefit for the few at the price of the impoverishment of many.”[126] Additionally, as AI becomes more powerful, there is an associated risk that human labor may lose its value in the economic realm. This is the logical consequence of the technocratic paradigm: a world of humanity enslaved to efficiency, where, ultimately, the cost of humanity must be cut. Yet, human lives are intrinsically valuable, independent of their economic output. Nevertheless, the “current model,” Pope Francis explains, “does not appear to favor an investment in efforts to help the slow, the weak, or the less talented to find opportunities in life.”[127] In light of this, “we cannot allow a tool as powerful and indispensable as Artificial Intelligence to reinforce such a paradigm, but rather, we must make Artificial Intelligence a bulwark against its expansion.” [128]
人工智能目前正在取代一些曾经由人类完成的工作。如果人工智能被用来取代人类工人而不是补充他们,那么“极少数人以牺牲多数人的贫困为代价而获得不成比例的利益,存在着巨大的风险。”[126] 此外,随着人工智能变得越来越强大,人类劳动在经济领域失去其价值的风险也随之增加。这是技术官僚范式的逻辑结果:一个人类被效率奴役的世界,最终,人类的成本必须被削减。然而,人类生命本身就具有内在价值,独立于其经济产出。尽管如此,教宗方济各解释说,“当前的模式似乎并不倾向于投资那些帮助行动迟缓、体弱或天赋较差的人在生活中找到机会的努力。”[127] 鉴于此,“我们不能允许像人工智能这样强大且不可或缺的工具来强化这种范式,相反,我们必须使人工智能成为抵御其扩张的堡垒。”[128]
- Since work is a “part of the meaning of life on this earth, a path to growth, human development and personal fulfillment,” “the goal should not be that technological progress increasingly replaces human work, for this would be detrimental to humanity”[132]—rather, it should promote human labor. Seen in this light, AI should assist, not replace, human judgment. Similarly, it must never degrade creativity or reduce workers to mere “cogs in a machine.” Therefore, “respect for the dignity of laborers and the importance of employment for the economic well-being of individuals, families, and societies, for job security and just wages, ought to be a high priority for the international community as these forms of technology penetrate more deeply into our workplaces.”[133]
既然工作是“今生意义的一部分,是成长、人类发展和个人成就的途径”,“目标不应该是技术进步日益取代人类工作,因为这对人类将是有害的”[132]——相反,它应该促进人类劳动。从这个角度来看,人工智能应该辅助而不是取代人类的判断。同样,它绝不能贬低创造力或将工人贬低为仅仅是“机器中的齿轮”。因此,“尊重劳动者的尊严以及就业对于个人、家庭和社会经济福祉、对于工作保障和公正工资的重要性,在这些技术更深入地渗透到我们的工作场所时,应该成为国际社会的高度优先事项。”[133]
- Humans are inherently relational, and the data each person generates in the digital world can be seen as an objectified expression of this relational nature. Data conveys not only information but also personal and relational knowledge, which, in an increasingly digitized context, can amount to power over the individual. Moreover, while some types of data may pertain to public aspects of a person’s life, others may touch upon the individual’s interiority, perhaps even their conscience. Seen in this way, privacy plays an essential role in protecting the boundaries of a person’s inner life, preserving their freedom to relate to others, express themselves, and make decisions without undue control. This protection is also tied to the defense of religious freedom, as surveillance can also be misused to exert control over the lives of believers and how they express their faith.
人类本质上是关系性的,每个人在数字世界中产生的数据可以被视为这种关系本质的一种客观化表达。数据不仅传递信息,还包含个人和关系知识,在日益数字化的背景下,这可能转化为对个人的权力。此外,虽然某些类型的数据可能涉及个人生活的公开方面,但另一些数据可能触及个人的内心世界,甚至他们的良知。这样看来,隐私在保护个人内心生活的边界、维护他们与他人建立关系、表达自我和在不受过度控制的情况下做出决定的自由方面起着至关重要的作用。这种保护也与宗教自由的捍卫息息相关,因为监视也可能被滥用,以控制信徒的生活以及他们表达信仰的方式。
- At the same time, the “essential and fundamental question” remains “whether in the context of this progress man, as man, is becoming truly better, that is to say, more mature spiritually, more aware of the dignity of his humanity, more responsible, more open to others, especially the neediest and the weakest, and readier to give and to aid all.”[202]
与此同时,“至关重要且根本性的问题”依然存在,那就是“在这种进步的背景下,人作为人,是否变得真正更好,也就是说,在精神上更加成熟,更加意识到其人性的尊严,更加负责任,更加向他人开放,尤其是那些最需要帮助和最软弱的人,并且更愿意给予和帮助所有人。”[202]
🎤 感觉在“上帝已死”的当下,人还是需要某种宏大而超越的东西去崇拜,进而获得一些精神力量,可能目前最突出的就是技术吧。
8. Synadia 试图从 CNCF 手中夺回 NATS
Protecting NATS and the integrity of open source: CNCF’s commitment to the community
Looking Ahead with Clarity and Purpose for NATS.io
Synadia Attempts To Reclaim NATS Back From CNCF
Synadia and CNCF dispute over NATS
背景
Synadia,NATS 消息系统的原始创建者,希望收回在 2018 年捐赠给云原生计算基金会 (CNCF) 的项目。Synadia 计划将 NATS 的 Apache 2 开源许可证更改为商业源代码许可证(BSL),理由是需要从其开源产品中获利以实现可持续性。
NATS 是什么
NATS 是一个开源消息传递系统(有时称为面向消息的中间件)。NATS 服务器是用 Go 编程语言编写的。用于与服务器交互的客户端库可用于数十种主要编程语言。。NATS 是一个广泛使用的开源消息传递平台,适用于微服务 、物联网(IoT 和边缘 )和事件流。由 synadia 于 2018 年捐赠给云原生计算基金会(CNCF)。
双方看法与诉求
Synadia
Synadia 创始人兼首席执行官 Derek Collison 称,
- “Synadia 及其前身公司资助了大约 97% 的 NATS 服务器贡献。 因此,“要使 NATS 生态系统蓬勃发展,Synadia 也必须蓬勃发展。
- “作为开源模型的忠实信徒,我仍然认识到,可持续的 OSS 需要获得可观价值并有能力在经济上支持它的用户,”这意味着根据 BSL 重新许可 NAT 的未来版本。
因此,Synadia 正在主张其商标权以收回该项目。Synadia 首次通知 CNCF 其打算从基金会中撤回 NATS,要求控制 nats.io 域和 nats-io GitHub 组织的关键基础设施,该基础设施已由 CNCF 管理了七年。
CNCF
从 NATS 被捐赠给 CNCF 起,它在 CNCF 的管理下不断发展壮大,受益于社区贡献、财务支持和供应商中立的治理。已有 700 多个组织为 NATS 做出了贡献,基金会资助了安全审计、法律工作和广泛的营销,以帮助该项目蓬勃发展。
Synadia 没有分叉项目或以新名称推出专有版本(这是通常的行业惯例),而是寻求“夺回”原始项目、其资产和品牌。CNCF 认为,这种方法破坏了基本的开源原则,即捐赠的项目成为社区财产 ,不受供应商的单方面控制。CNCF 要求所有捐赠的项目将商标所有权转让给 Linux 基金会,以确保供应商的中立性。然而,尽管 Synadia 接受了 CNCF 的 10,000 美元商标注册费用报销,但从未完成此次转让。CNCF 已向 Synadia 提供了分叉 NATS 并以新名称构建专有产品的选择权,但坚持认为社区拥有的项目、其名称及其基础设施必须继续由 CNCF 管理。
其他影响
- NATS 用户:使用可能会受到影响,需要提前探索替代品。
- 开源治理:允许供应商“收回”捐赠的项目可能会开创一个危险的先例,破坏像 CNCF 这样的基金会提供的信任和稳定性。结果将对开源协作的未来、项目可持续性以及供应商和社区之间的权力平衡产生广泛的影响。
💬 专题三 讨论与分享
1. CVE 究竟是什么
How Linux Kernel Deals With Tracking CVE Security Issues
什么是 CVE?
CVE 简介
CVE 是通用漏洞披露(Common Vulnerabilities and Exposures)的英文缩写,列出了已公开披露的各种计算机安全缺陷。人们提到 CVE,指的都是已分配 CVE ID 编号的安全缺陷。
供应商和研究人员发布的安全公告几乎总会提到至少一个 CVE ID。CVE 可以帮助 IT 专业人员协调自己的工作,轻松地确定漏洞的优先级并加以处理,从而尽可能提高计算机系统的安全性。
CVE 由谁管理
CVE 是一个与信息安全有关的数据库,收集各种信息安全弱点及漏洞并给予编号以便于公众查阅。此数据库现由美国非营利组织 MITRE 所属的 National Cybersecurity FFRDC 所营运维护。
CVE 的工作原理
1999 年,美国政府资助的研发公司 MITRE Corporation 开发了 CVE 系统,这是报告和跟踪软件安全漏洞的统一标准。
CVE 条目非常简短。既没有技术数据,也不包含与风险、影响和修复有关的信息。这些详细信息会收录在其他数据库中,包括美国国家漏洞数据库(NVD)、CERT/CC 漏洞注释数据库以及由供应商和其他企业组织维护的各种列表。
在这些不同的系统中,用户可以利用 CVE ID 来识别独特的漏洞并协调安全工具和解决方案的开发。MITRE Corporation 维护 CVE 列表,但成为 CVE 条目的安全漏洞通常由开源社区的企业组织和成员提交。
CVE 识别号由谁编码
CVE 识别号(或 CVE ID)由 CVE 编号管理机构(CNA)分配。目前约有 100 个 CNA,包括安全公司、研究机构以及各大 IT 供应商(如红帽、IBM、思科、Oracle 和微软)。MITRE 也可以直接发放 CVE。
MITRE 会向每个 CNA 发放一系列 CVE ID,CNA 在收到这些 ID 后会将它们存储起来,用于在发现新问题时向其分配一个 CVE ID。每年,都有数以千计的 CVE ID 发放出来。单个复杂产品(如操作系统(OS))可能会累积数百个 CVE。这意味着,一旦产品进入维护终止阶段(错误修复和安全补丁停止发布)和生命周期结束阶段(所有第一方支持结束),它就会变得非常脆弱。例如,当 CentOS Linux 7 于 2024 年 7 月 1 日进入生命周期终止阶段时,一天之内就发布了一个新的 CVE。这些问题凸显了迁移到一个稳定的操作系统并定期接收安全补丁和更新的重要性。
CVE 的工作流程
任何人(供应商、研究人员或是机敏的用户)都有可能发现缺陷,并促使他人予以关注。很多供应商都会提供错误报告奖励,以鼓励相关人员负责任地披露各种安全问题。如果您发现了开源软件存在漏洞,您应该将其提交至相关社区。
该缺陷的相关信息通过种种渠道,最终会传至 CNA。CNA 进而会为这些信息分配 CVE ID。最后,新的 CVE 就会被发布到 CVE 网站上。
CNA 通常会在公开安全公告之前分配一个 CVE ID。供应商一般会对安全缺陷保密,直至相关修复已完成开发和测试,从而防止攻击者利用未修补的缺陷。
公布时,CVE 条目中会包含 CVE ID(格式为“CVE-2019-1234567”)、安全漏洞的简短描述和相关的参考资料(可能包括漏洞报告和公告的链接)。
CVE 的判定标准
根据 CVE 编号管理机构的运维规则,只有符合特定标准的缺陷才会分配 CVE ID。这些缺陷必须满足以下条件:
-
可以单独修复。
该缺陷可以独立于所有其他错误进行修复。
-
已得到相关供应商的确认或已记录在案。
软件或硬件供应商承认漏洞的存在,并确认它对安全产生了负面影响。或者,报告者本应共享一份相关漏洞报告,表明错误会造成负面影响,且有悖于受影响系统的安全策略。
-
只影响 1 个代码库。
如果一个缺陷影响多个产品,则每个产品都会获得一个单独的 CVE。对于共享的库、协议或标准,只有在使用共享代码会容易受到攻击时,该缺陷才会获得单个 CVE。否则,每个受影响的代码库或产品都会获得一个唯一的 CVE。
CVE 如何判定严重等级
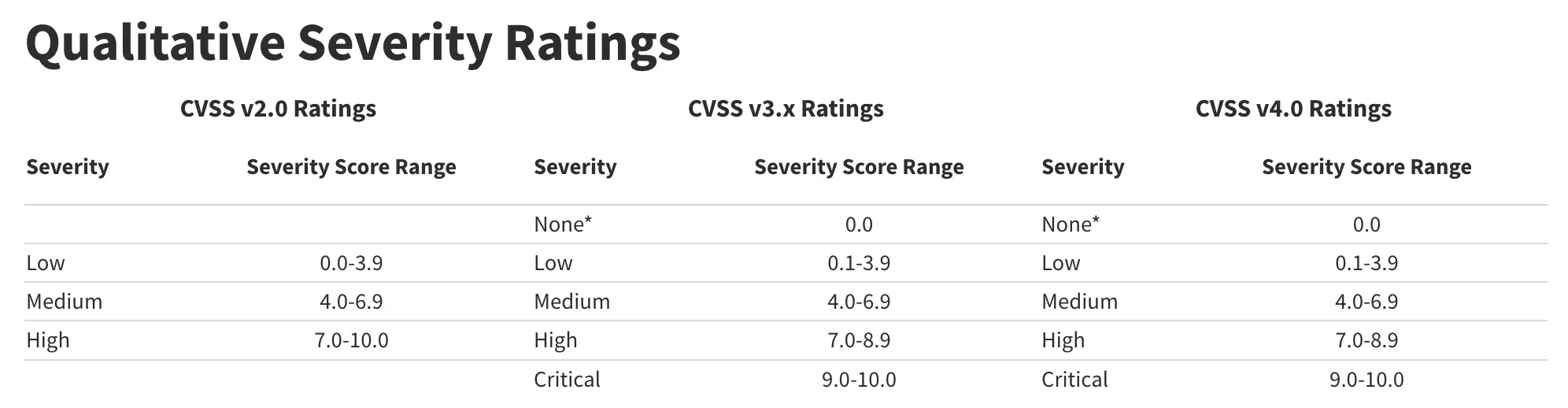
通用漏洞评分系统 (CVSS) 是一种用于定性衡量漏洞严重程度的方法。CVSS 本身并非风险衡量标准。CVSS v2.0 和 CVSS v3.x 包含三个指标组:基础指标、时间指标和环境指标。CVSS v4.0 略有不同,它包含基础指标、威胁指标、环境指标和补充指标。
这些指标会给出一个从 0 到 10 的数值分数。CVSS 评估结果也以向量字符串的形式表示,这是用于得出分数的值的压缩文本表示。因此,对于需要准确且一致的漏洞严重程度评分的行业、组织和政府而言,CVSS 非常适合用作标准衡量系统。CVSS 的两个常见用途是计算在用户系统中发现的漏洞的严重程度,以及将其作为确定漏洞修复活动优先级的因素。
目前 CVE 机制存在的问题
- 供应商(CNA)会更关注其产品的相关漏洞。“Red Hat 关注的是 Red Hat,而不是你。”
- 些安全研究人员可能会发布虚假或夸大其词的 CVE,其目的是为了增加他们个人履历(portfolio)的“亮点”。
漏洞影响公告示例
下面以 KubeSphere 近期的一篇KubeSphere 网关组件(ingress-nginx)安全漏洞公告正式发布作为示例,了解厂商应该如何对用户提供有效的信息介绍与行为指导。
整篇公告分为 8 个部分:
- 漏洞概述
- 漏洞影响分析
- 验证是否受影响
- 解决方案
- 检测方法
- 安全最佳实践
- 技术支持
- 参考信息
⚠️ 顺便插播一则 ingress-nginx 的消息:
⚠️ Ingress NGINX Project Status Update ⚠️ #13002
Kubernetes 团队创建了一个名为 InGate 的新项目,用于替代 ingress-nginx。InGate 是一个用于 Kubernetes 的 Ingress 和 Gateway API 控制器。一旦 InGate 发布稳定版本,ingress-nginx 将进入维护模式。ingress-nginx 正在逐步淘汰,并由 InGate 取代。鼓励用户开始规划迁移到 InGate。
延伸阅读
Repair the bridge before it cracks: Understanding vulnerabilities and weaknesses in modern IT
weakness(弱点)和 vulnerability(漏洞)的差别是什么?
弱点和漏洞之间的主要区别在于是否可以立即利用该问题。如果可以,那就是一个 vulnerability(漏洞)。如果不是,那就是一个 weakness(弱点)。
- vulnerability(漏洞):发现固定桥梁主缆的螺栓有缺陷,可能会使它们在压力下折断。攻击者可以利用此缺陷,从而导致灾难性的故障。
- weakness(弱点):注意到一些螺栓是由低级金属制成的,随着时间的推移可能会迅速降解。虽然没有立即失败,但这会增加未来失败的风险(或者在软件的情况下,会增加漏洞的风险)。在它们磨损之前加固或更换这些螺栓可以增强桥梁的整体安全性。这个问题的识别和解决可以在桥梁建成后进行,但理想情况下发生在设计和建造阶段。
弱点并不总是立即导致安全漏洞,但它们会为漏洞的出现创造条件。尽早解决弱点可以防止以后进行代价高昂的修复。
🎤 感觉有点类似武侠小说里,某一门派具有风格的同时也具有弱点,招式的弱点在真正过招时可能会成为漏洞,被对手发现并攻击。
2. Google 将在 AI 时代如何演进 Kubernetes
KubeCon Europe: How Google Will Evolve Kubernetes in the AI Era
演讲者:GKE 和 Kubernetes 工程总监 Jago Macleod
Kubernetes 的演变
-
2014-2017
“第一阶段实际上是颠覆性的,”麦克劳德在谈到 2014 年至 2017 年的初始阶段时表示。“这是我们(谷歌)进入公共云市场的时候。”
“我们觉得我们有机会将云的公共概念从虚拟机扩展到容器。”
-
2018-2022
“是生态系统扩张的时代。”
“生态系统项目和问题解决方案的数量呈爆炸式增长,”Macleod 继续说道。“Istio 就是那个时候诞生的,还有 OPA Gatekeeper、Argo 和 Knative 以及 OpenTelemetry 等。因此,用户越多,为这个生态系统创造的价值就越大。”
-
2023-现在
“2023 年底就出现了剧情转折,对吧?就是 ChatGPT 时刻。一夜之间,全世界都为这个想法着迷了。”
“人工智能不仅是一个重大颠覆因素,而且企业对 Kubernetes 的需求仍在自然增长。”
“需求远远超过供应。因此,我们看到了这些疯狂重叠的采用曲线。而且非常有趣的是,有些企业仍在采用云原生技术来学习容器化和微服务,而与此同时,一个完全不同的层面(人工智能)正试图颠覆这一切。”
“为了应对双倍增长曲线,我们想出了这三个故事,在谷歌内部团结一致。目标是改进 Kubernetes,以满足下一个万亿核心小时的计算需求。这三个目标是:
1. 提高升级过程中的大规模可靠性。
2. 重新定义 Kubernetes 与硬件的关系。
3. 从容器和工作负载转移到框架编排。 -
下一阶段将是“整合”
“对于所有这些生态系统项目,我们必须提供意见,而不仅仅是选择。我们从最终用户那里得到了反馈,说它太令人困惑、太复杂了。我认为它将是关于稳定性、简单性和全面性的。你需要一个完整的平台。你不只是需要一袋乐高积木中的一个零件。你想要的是玩具。所以这就是我认为未来会是的样子。”
Kubernetes 的设计理念来自沙漏模型
“Kubernetes 的理念基于沙漏模型,这是一张大概 40 年前流传的图表。整个概念是,IP 位于中心——细腰——驱动着顶层的生态系统和各种技术。因此,我们的愿景是让 Kubernetes 成为基础设施消耗沙漏模型的细腰。”

从沙漏模型中,谷歌推导出了其针对 Kubernetes 的持续战略。
“首要的是,确保 Kubernetes 持续蓬勃发展。将 Kubernetes 扩展为基础设施的事实标准,并不断扩展它——尤其是对于对每个企业都至关重要的 AI/ML 工作负载。确保它适用于这些框架以及即将到来的新工作负载。”
“总体目标是让 Kubernetes 变得‘具备 GenAI 意识’。”

作为一家在 Kubernetes 上运营的企业,谷歌希望提供差异化优势。Macleod 解释说,本质上,这一切都关乎谷歌扩展其公共云的能力。
“如果我们所有这些都在开源中进行,坦诚地说,我们的意图实际上是在性能上实现差异化——然后这为我们提供了通过性价比来创造商机的机会。你可以以更低的价格提供与开源 Kubernetes 相同的性能,或者以更高的价格提供更好的性能——就像,这里有很多选择,但实际上关键在于性能上的差异化。”
考虑到目前企业采用成熟度和生成式人工智能热潮带来的需求上升,Macleod 对 Kubernetes 的未来持乐观态度:“Kubernetes 具有声明式、可扩展性和模块化的特点。这使得它具备极佳的条件来发展以满足下一轮工作负载的需求。我们投入了大量资金,它的价值巨大。因此,我们拥有一个机会之窗。我们坚信,这是一个不断发展的机会之窗,这样我们就不会因为其他事情而被排挤。我们已经在路上了。我们正在加速前进,正在加速。实际上,我们在 Kubernetes 上的投资比一两年前要多得多。我们认为你也应该如此,并且期待看到我们能够共同创造什么。”
3. 你的 EKS 集群有多大?
Using EKS? How big are your clusters?
- 集群大小差异很大:许多回复说集群只有几十个节点和几百个 Pod。但也有一些回复表示他们在运行大型集群。
- 大型集群的挑战:管理大型集群会带来挑战,尤其是在 API 服务器性能、网络复杂性和升级方面。
- 拆分集群的原因:
- 提高稳定性:将工作负载隔离到较小的集群中可以限制单个故障的影响。
- 简化管理:较小的集群更易于管理和更新。
- 满足特定需求:不同的团队或应用程序可能需要不同的集群配置。
- 替代方案:一些回复建议探索 EKS 的替代方案,例如 GKE 或 AKS,或者考虑使用托管的 Kubernetes 服务,例如 Google Anthos 或 AWS EKS Anywhere。
总的来说,对于 EKS 集群应该有多大没有一个统一的答案。最佳方法取决于各种因素,包括特定工作负载、团队规模和风险承受能力。虽然运行大型集群是可行的,但重要的是要权衡这样做的好处和挑战,并考虑拆分集群或探索替代解决方案是否更有意义。("Trade-offs Are Everywhere.")
4. SaaS 已过时:为什么自带云 (BYOC) 才是未来
SaaS Is Broken: Why Bring Your Own Cloud (BYOC) Is the Future
什么是自带云
自带云 (Bring Your Own Cloud, BYOC) 是一种云计算部署模式,指企业或个人用户不使用云服务提供商(如 AWS、Azure、GCP)提供的公共云基础设施,而是使用自己已经拥有或租赁的私有基础设施(例如自己的数据中心、服务器、存储等),但仍然可以享受到某些云服务的优势和管理模式。
简单来说,BYOC 就是 “用你自己的硬件,但用上云的某些管理和技术”。
自带云和私有云之间的差别
传统的私有云通常是企业自行构建和管理的,可能不一定采用与公共云相同的技术栈和管理模式。BYOC 的核心在于采用云服务提供商的技术和管理理念来运营自己的基础设施,从而更方便地与公共云进行集成和管理,实现混合云的价值。
SaaS 存在什么问题
-
基于数据摄取的货币化模式已失效
- 虚高: 订阅成本与数据摄取量挂钩,公司为只有供应商知道的隐藏加价付费。这已经将 SaaS 市场推入恶性通货膨胀的状态。
- 不可预测: 数据是动态的。它具有季节性、尖峰性并且不断演变。当供应商基于数据摄取量收费时,公司难以估算成本,使得预算规划几乎不可能。
- 难以管理: 许多公司仅为了成本管理就浪费了过多的时间。它们投入大量精力来识别冗余的数据传输并过滤掉有价值的数据以削减成本,即使这些数据可能是有益的。
-
数据控制和访问限制
- 安全盲点: 公司投入大量资金来控制数据位置和访问,然而使用传统 SaaS,敏感数据很容易驻留在第三方供应商的场所内,超出完全的管控范围。
- 合规担忧: 公司的合规性强度取决于处理其数据的第三方供应商中合规性最弱的那一个。在 SaaS 时代,敏感数据很容易流向在合规性方面不如您严格的供应商。
- 受限的访问: 企业无法以他们喜欢的方式使用他们发送给第三方供应商的数据,这对于本地部署的 AI/ML 工作负载以及任何您想要与数据集成的内部工具来说都是一个大问题。
自带云的优势
- 结合了 SaaS 的便利性和本地部署的控制力: 在自己的云基础设施上运行 SaaS 应用程序。
- 降低成本: 避免了传统 SaaS 模式下高昂的数据摄取费用。
- 增强数据控制和安全性: 数据存储在自己的基础设施中,提高了安全性并满足合规性要求。
- 定制化和灵活性: 可以根据自身需求定制应用程序和基础设施。
5. Kubernetes 中的 OOMKilled:你遗漏的隐藏内存泄漏
OOMKilled in Kubernetes: The Hidden Memory Leaks You’re Missing
比较偏技术,大致介绍了以下内容:
- OOMKilled 错误的成因
- 识别 OOMKilled 错误
- 解决方案
- 其他关键点
6. VMware 替代方案:现代虚拟化战略指南
VMware Alternatives: A Strategic Guide to Modern Virtualization
背景
- Broadcom 收购 VMware 引发了企业虚拟化领域的重大转变。许多长期依赖 VMware 解决方案的组织正在重新评估对 VMware 的依赖,并考虑转向更具成本效益、可扩展的替代方案。
- 美国关税政策(最新原因)。
可能的方案
总的来说有以下 4 种思路:
a. 保留 VMware 并优化成本
可以通过成本控制策略优化现有的 VMware 投资:
- 重新评估 VMware 许可结构,以消除不必要的开支并优化许可证利用率,确保只有必要的工作负载保留在 VMware 上。
- 结合第三方存储解决方案,最大限度地减少对昂贵的 vSAN 扩展的依赖,同时提高数据保护、可扩展性和性能。
- 重新配置主机架构以避免过多的基于核心的许可费用,这可能会严重影响运营预算。
缺点:通过实施这些策略,企业可以缓解 VMware 许可证成本的上涨,但仍将面临更高的成本。这种方法只能推迟不可避免的事情发生,并不能解决供应商锁定、成本上涨和 VMware 未来生存能力方面的担忧。
b. 转向替代性本地虚拟化管理程序
希望摆脱 VMware 但不愿完全迁移上公有云的企业,可选择多种可行的虚拟化平台替代方案:
- Nutanix AHV—— 领先的超融合基础设施 (HCI) 平台,集成计算、网络和存储,减少对独立基础设施组件的依赖并提高运营效率。
- Microsoft Hyper-V — 嵌入在 Windows Server 中的经济高效的解决方案,使其成为以 Microsoft 为中心的环境的一个有吸引力的替代方案,但它需要额外的工具来实现高级虚拟化管理。
- OpenStack KVM — 一种灵活的开源虚拟机管理程序,提供对虚拟化环境的完全控制,但它需要强大的内部专业知识和定制集成才能实现企业级功能。
缺点:虽然这些替代方案保留了传统的虚拟化模式,但它们需要大量的迁移工作和员工再培训。成功的过渡需要全面的规划、工作负载评估和自动化投资,以简化迁移。
c. 采用基于公有云的虚拟化
公共云解决方案提供可扩展性、灵活性和运营敏捷性:
- VMware Cloud on AWS 、Azure VMware Solution 和 Google Cloud VMware Engine,为现有 VMware 工作负载提供直接迁移功能,同时减少本地基础设施维护。
- 为准备重新架构应用程序并利用云原生优势(包括自动化和成本效益)的企业提供原生公共云计算服务(AWS EC2、Azure VM、Google Compute Engine)。
缺点:基于云的虚拟化可实现更大的弹性,让企业能够按需扩展工作负载。然而,必须通过混合云或多云策略谨慎处理对长期成本、性能变化和供应商锁定的担忧。
d. 拥抱基于 Kubernetes 的虚拟化
- 开源项目 KubeVirt 及其商业支持版本(如 OpenShift Virtualization (OSV)、 Specto Cloud 和 SUSE Harvester) 使企业能够在容器中运行虚拟机工作负载,而无需重构或重写它们。
缺点:新增 Kubernetes 相关的技能学习成本。
影响决策的因素
- 迁移复杂性和潜在的业务中断
- 总拥有成本 (TCO) 和许可相关的考虑
- 自动化、可扩展性和长期运营效率
关于关税政策的延伸
IT Leaders Brace for Tariff Fallout on Infrastructure and Cloud Costs
简言之:
- 关税预计将导致 IT 基础设施和云成本大幅上升(为了抵消价格上涨,付出更多的钱只为了保证服务与产品的水平不变)。
- CIO 必须在成本压力和战略 IT 投资之间取得平衡。
- 有效的数据管理对于优化成本和为未来做好准备至关重要。
7. VMware 终于赶上 Kubernetes 了吗?
Has VMware Finally Caught Up With Kubernetes?
VMware 在 Kubernetes 方面的问题
自从容器成为“一种时尚”以来,VMware 一直是领先的 Kubernetes 管理和基础设施服务提供商之一,也是过去十年中 Kubernetes 项目的三大贡献者之一。但这还不够。
在 2023 年被博通收购之前,VMware 的大部分 Kubernetes 知识产权 (IP) 尚未被客户充分利用。VMware 当然有很多东西可以提供,但它没有一个通用平台,让处于 Kubernetes 旅程不同阶段的公司能够满足他们对虚拟机 (VM) 和 Kubernetes 容器的所有需求。
VMware 如何应对
现在 VMware Cloud Foundation (VCF) 成为虚拟机和容器的单一平台 ,并具有许多增强功能,例如多集群管理和许多其他适用于云原生环境的功能。
博通(Broadcom)的收购成为关键催化剂,推动 VMware 将全套私有云技术栈和服务整合至 VCF(VMware Cloud Foundation)平台。虽然 VMware 此前已在 VCF 技术栈中集成众多基础设施与管理组件,但博通带来的战略聚焦显著提升了平台能力——现可全面满足企业级用户对 Kubernetes 运行时环境与统一管理的各类需求。由于 Kubernetes 运行时授权已包含在 VCF 许可中,客户无需额外采购授权许可。
通过 VCF 向 Kubernetes 的转变主要涉及 Kubernetes 运行时 (vSphere Kubernetes Service(VKS),以前称为 Tanzu Kubernetes Grid) 及其著名的虚拟机和支持基础设施的更深层次集成。
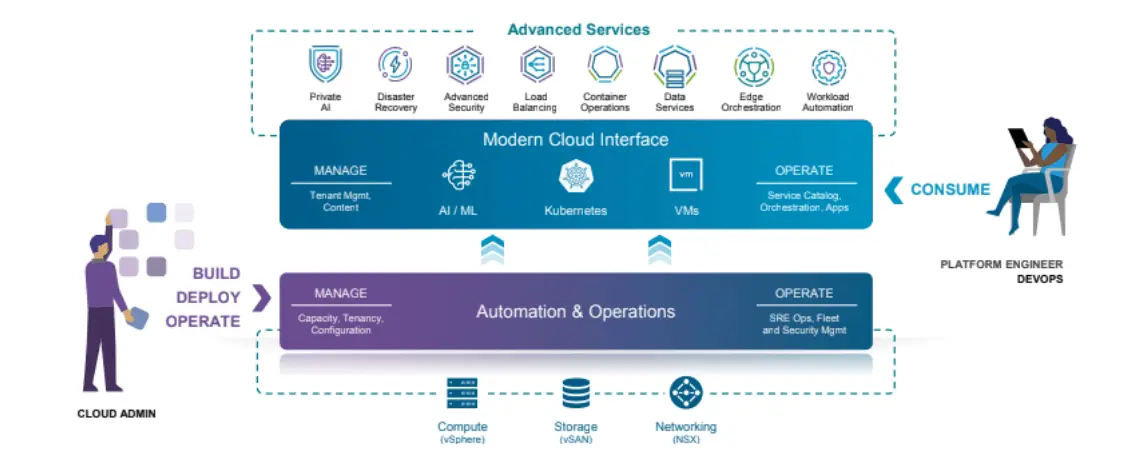
VCF 支持 Kubernetes 的一个关键组件是其 VMware vSphere Supervisor。Supervisor 充当平台和控制平面,可以在其上配置一组强大的基础架构和云服务,包括 Kubernetes 集群服务。这些包括 VKS(Kubernetes 运行时)、多集群管理、VM 服务、vSphere Pod、网络服务、存储和备份服务、身份和访问控制服务、映像注册表以及许多其他功能。
目标与计划
VMware 的工程师表示,他们已经打破了以往的做法,优先发布 Kubernetes 的最新版本,目标是在上游版本发布后两个月内完成。Carr 表示,这有助于确保与超大规模用户使用的最新版本保持一致。
目标是在 VCF 上创建一个深度集成的 Kubernetes 产品,就像超大规模企业所做的那样。“ AWS 拥有 EKS——AWS Kubernetes 集成度最高的版本。Azure 上的 AKS 和 Google Cloud 上的 GKE 也是如此,”Carr 说道。“我们通过 VKS 在 VCF 基础架构上实现了相同级别的集成,并且已经在朝着这一目标迈进。”
内置的安全功能使其成为迄今为止在公司基础架构上运行的最安全的 Kubernetes 平台。“这是其他供应商无法完全复制的。我们将继续利用这一优势,因为它在 VCF 上构建了最佳的 Kubernetes 堆栈。”
“最后,值得注意的是,这不仅仅与 Kubernetes 有关——一切都建立在公司的虚拟化平台之上,该平台已经成功运行了 20 多年。”
借助 VCF,VMware 提供了一个内置 Kubernetes 运行时和 CNCF 认证 Kubernetes 发行版的单一平台,使企业能够在同一基础架构上同时运行现代容器化应用程序和传统虚拟机。VCF 旨在简化 Kubernetes 的部署和管理,同时统一计算、存储、网络和安全——VMware 表示,这可以降低总体拥有成本和运营复杂性。VMware 大力推广 VCF,称其是收购博通后推出的一项重要产品。首席信息官和任何参与 DevOps 运营的人员都应该至少认真考虑将其作为标准化平台。
8. 边缘计算和云计算存在竞争吗?
Are Edge Computing and Cloud Computing in Competition?
背景 & 相关信息
之前关于边缘计算的一些内容:
相关报道 & 预测
- IDC - 2024 - 全球边缘计算支出预计将在 2024 年达到 2280 亿美元,比 2023 年增长 14%,全球边缘计算支出预计将在 2028 年达到 3780 亿美元
- 福布斯 - 2023 - 越来越多的企业认识到需要在边缘处理和分析数据,边缘计算将快速增长,并惠及所有公司,而不仅限于财富 500 强企业
- JLL - 2024 - 2026 年全球边缘数据中心市场规模将突破 3000 亿美元
关于边缘 AI
作为边缘计算的一个子集, 边缘 AI 是指将 AI 模型直接部署在本地设备而不是云端。通过将此处理移至边缘,其目的是减少延迟和对互联网连接的依赖。边缘 AI 还带来了一些有趣的好处,可以改善数据隐私和安全性 。
边缘计算 vs. 云计算
- 边缘计算虽然具有低延迟和更快的响应时间,但其原始计算能力却有所欠缺。
- 尽管边缘计算具有众多优势,但对于大多数应用而言,它只是其中的一部分;在许多情况下,仍然需要云计算来处理繁重的工作(例如,大规模数据处理和长期存储)。
关于雾计算
根据现任 Pure Storage 总经理、曾任思科副总裁的 Maciej Kranz 撰写的一篇思科博客文章,雾计算最初由思科提出,旨在“在终端设备与‘地面’和云计算数据中心之间提供一层计算、存储和网络服务”。
雾计算的理念是作为云计算的延伸,在数据源和云之间分配数据、存储、计算和应用程序,以获得边缘计算的快速延迟,同时又不放弃云计算的卓越处理能力。
然而,雾计算仍处于早期阶段,缺乏标准化和整体复杂性使其仍然不适合广泛部署。
关于天空计算
Sky Computing, the Next Era After Cloud Computing
加州大学伯克利分校两位杰出的计算机科学教授 Ion Stoica 和 Scott Shenker 表示,我们即将从云计算时代过渡到“ 天空计算 ”时代。
顾名思义,天空计算是云平台之上的一层,其目标是实现云平台之间的互操作性。如果您觉得这听起来像当前的行业流行词“多云”,那么您就猜对了。
本质上,天空计算是关于实现多云应用程序开发。天空计算应该由三层组成:“兼容层,用于屏蔽低级技术差异;云际层,用于将任务路由到正确的云平台;以及对等层,允许云平台之间就如何交换服务达成一致。” 这三层设计理念与互联网本身类似——例如,互联网协议 (IP) 提供了网络间兼容性。
(概念的数量快赶上问题了)
9. 如何为 AI 战略选择最佳云模型?
How To Select the Best Cloud Model for Your AI Strategy
三种云模型
- 公有
- 厂商:AWS、Google、IBM
- 特点:提供即时可扩展性和对高级服务的访问,例如无服务器计算、图形数据库和 AI 驱动的分析
- 适合 & 不适合:
- 适合旨在快速部署应用程序、进行最小可行产品 (MVP) 测试并利用尖端技术而无需投资基础设施的用户
- 不适合对数据隐私、合规性和供应商锁定有担忧的用户
- 私有
- 厂商:VMware、Nutanix、SmartX
- 特点:提供更好的环境控制和自定义能力。创新周期较慢,私有云往往落后于公共产品
- 适合 & 不适合:
- 适合存在敏感数据,希望能够更好地控制其环境并执行自定义数据隐私和合规性政策的用户
- 不适合对尖端技术、功能迭代速度有要求的用户
- 混合
- 厂商:AWS Outposts、Azure Stack、Oracle Cloud Infrastructure
- 特点:结合了公有云和私有云的优势,使企业能够在本地保留敏感数据,同时利用公有云服务来应对需求高峰和无缝集成
AI 对云模型的影响
云服务提供商越来越多地集成 AI 来简化复杂的流程,例如工作负载管理、安全监控和成本优化。
- 公有云中的 AI 。公有云提供商在提供 AI 驱动服务方面处于领先地位,这些服务使机器学习和自动化工具的访问变得民主化。公司现在可以利用预构建的 AI 模型和专用基础设施(例如图形处理单元 (GPU) 和张量处理单元 (TPU))来加速创新。这些服务可帮助组织缩短基于 AI 的解决方案的上市时间,同时使各种规模的企业都能使用高级功能。
- 私有云中的 AI。 私有云中的 AI 集成可确保敏感数据在组织边界内保持安全。对于金融和医疗保健等行业而言,遵守《通用数据保护条例》(GDPR)、《健康保险流通与责任法案》(HIPAA)和《支付卡行业数据安全标准》(PCI DSS)等法规至关重要,AI 驱动的监控工具有助于执行政策并实时检测异常。通过边缘计算进行本地化 AI 处理,通过将关键操作保留在组织的基础架构内,进一步增强了数据隐私 。
- 混合云中的人工智能 。混合云受益于人工智能编排工具,这些工具可改善公共和私有环境中的资源管理。这些工具有助于优化工作流程、平衡工作负载并自动执行事件响应。例如,人工智能驱动的预测性维护解决方案利用物联网 (IoT) 传感器数据来增强制造流程并防止物流运营停机 。
不同行业的情况简述
⚠️ 由于是外国文章,可能和本国国情存在不同。
- 金融:利用公共云平台提供个性化的金融见解并实施欺诈检测模型。银行可以使用人工智能驱动的服务检查大量交易数据,以发现欺诈活动的趋势并为消费者提供个性化建议。
- 医疗:合规性是强制性的。集成 AI 的私有云为诊断和治疗建议提供动力,并帮助医疗保健从业者安全地管理敏感的患者数据。云系统利用 AI 索引医疗保健数据并提高可访问性,帮助改善患者治疗效果并确保合规性。
- 工业:人工智能驱动的预测性维护可帮助制造商在设备出现问题之前预测到问题,从而避免昂贵的停机时间。同样,物流公司也使用人工智能来简化供应链,提高生产力并削减开支。
- 电子商务:利用公有云平台实施人工智能驱动的推荐系统,以提升客户体验。这些系统依靠用户行为分析提供定制的产品推荐,从而提高销售额和客户保留率。
关键趋势
- 云服务自动化程度提高。 云服务自动化之所以发展,是因为云提供商投资了自动化解决方案,以简化入职流程并降低云环境管理的复杂性。例如,自我修复系统可以自动识别和修复存储系统、虚拟机和容器中的问题。此功能可提高运营效率并减少停机时间。
- 人工智能驱动的成本管理工具。 随着组织越来越频繁地使用云,成本控制变得越来越重要。人工智能驱动的成本监控解决方案可确保组织通过实时跟踪和优化其云支出来有效管理资源。这些技术可以精确定位未充分利用的资源并提供削减成本的策略,而不会牺牲功能。
- 通过云服务实现人工智能的民主化。 云平台向更广泛的用户开放人工智能,从企业到初创公司。云提供商允许组织将人工智能纳入其运营,通过提供托管服务和预构建的人工智能模型,减少对大量内部专业知识的依赖。因此,公司可以在快速变化的市场中保持竞争力。
- 边缘计算和本地化 AI 处理。 边缘计算在私有云和混合云环境中越来越受欢迎 。企业可以通过在网络边缘本地处理数据来减少延迟并提高 AI 应用程序的性能。这对于依赖实时推理进行决策和运营的工业自动化和无人驾驶汽车等行业尤其重要。
- 合规性和监管准备 。 随着人工智能技术的进步,云服务提供商必须确保其产品符合不断变化的法律和监管标准。公共云提供商通过提供创新的合规性框架帮助企业满足 GDPR、SOC 和 ISO/IEC 27001 等标准。由于这种准备,组织可以放心, 云服务将满足其合规性要求。
10. 为 Pod 添加第二块网卡
使用场景
Kubernetes 的 Pod 默认只有一个网卡。假设一个场景,Pod 有管理流量和业务流量,一个网卡是没办法满足流量隔离的,这个时候就需要为 Pod 添加多个网卡实现流量的隔离。
具体内容见原文。
11. 每月 100 美元以下 Kubernetes 的最佳可观察性解决方案是什么?
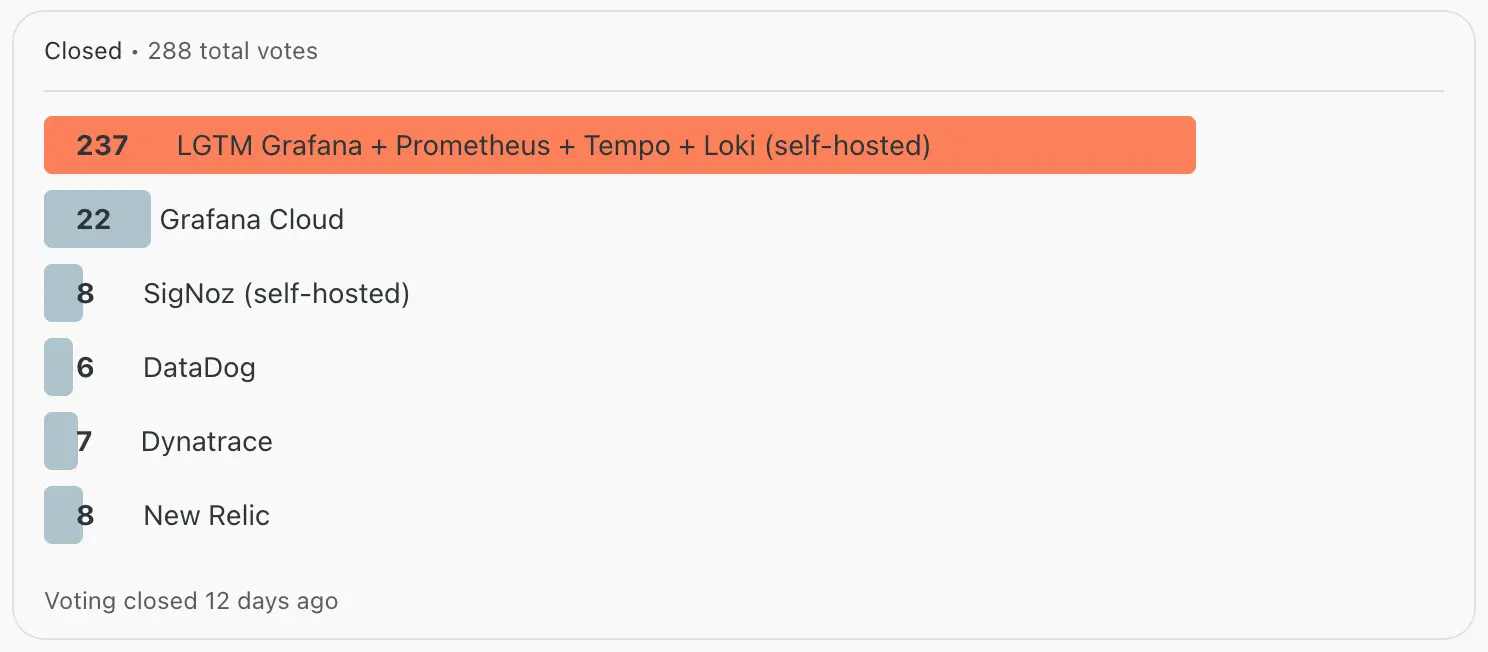
[Poll] Best observability solution for Kubernetes under $100/month?
Reddit 上一个投票,LGTM Grafana + Prometheus + Tempo + Loki (self-hosted) 遥遥领先:
集群规模
- 3 个 Control Plane
- 4 个 Worker
- 约 240 个容器
需求
- 最高预算:每月 100 美元
- 需要内置智能来识别问题的根本原因
- 偏好易于设置和维护的方案
- 强大的告警能力
- 目前仅使用 DataDog 处理日志
- 对自托管解决方案持开放态度
12. 如何将 TB 级监控指标从 InfluxDB 迁移到 Grafana Mimir
文章介绍了 CloudRaft 如何帮助一家领先的通信公司将其可观察性堆栈从 InfluxDB v1 迁移到 Grafana Mimir。
需求:
- 需要迁移 7 年的监控数据(约 100TB 未压缩数据)。
- 复杂的迁移过程,因为不支持直接从 InfluxDB 迁移到 Grafana Mimir。
- 需要将数百个使用 InfluxQL 的 Grafana 仪表板重写为 PromQL 格式。
解决方案:
- 开发了一个名为“mimircli”的自定义工具来转换和迁移数据。
- 采用分阶段方法,将数据分成几部分进行迁移。
- 使用双流方法,在迁移过程中将数据同时发送到 InfluxDB 和 Grafana Mimir。
- 使用增强版的开源工具将 Grafana 仪表板从 InfluxQL 转换为 PromQL。
🎤 一直觉得这种迁移工具或产品是为了从其他友商手上更好地获取用户。此刻用户去意已决,只是犹豫要去哪里。如果迁移做得好无疑是很加分的,在 VMware 替换场景这一点应该还蛮重要的。
13. 以数据为中心的全新 AI 治理策略
AI Data Dilemma: Balancing Innovation with Ironclad Governance
背景
任何成功的人工智能战略都需要一个安全且可管控的数据策略,并由功能强大的现代数据平台提供支持。
策略
-
构建数据所在位置
最安全的 AI 实现遵循一个基本原则:将 AI 模型直接引入数据,而不是将数据引入模型。通过将 AI 系统与数据平台的现有安全边界共置,组织可以显著降低暴露风险。
通过技术控制建立明确的边界执行可以确保人工智能模型仅在组织管理的数据生态系统内运行,为创新创建安全的基础,同时不损害保护标准。 -
了解你的工作内容
看不见摸不着的东西,保护不了。实施强大的数据发现功能,使组织能够自动识别、分类和标记其数据环境中的敏感信息。
自动分类工具可以扫描结构化和非结构化数据,识别个人身份信息 (PII)、受保护的健康信息 (PHI) 以及其他需要特殊处理的敏感元素。这些系统可以生成描述性元数据,从而提升可搜索性和治理能力,确保根据数据敏感度实施适当的控制措施。 -
实施智能治理
随着数据复杂性的增加,静态治理模型变得不合适。领先的组织正在从基于角色的访问控制 (RBAC) 转向更具情境感知的模型,例如自主访问控制 (DAC),它可以更明智地决定谁可以访问什么,例如列级屏蔽以隐藏特定列中的敏感数据或行过滤以根据用户权限管理数据可见性。
话虽如此,在隐私和数据实用性之间取得适当的平衡并非易事——过多的噪声会降低模型准确性,而过少的噪声则会暴露敏感模式。 -
保持全面的监督、合规和治理
在当今的监管环境下,记录数据流向与保护数据同等重要。实施强大的数据沿袭追踪,可以创建可审计的记录,记录信息如何在您的系统中流动并进入 AI 模型。
这种透明度不仅满足了日益增长的监管需求,还能通过清晰地展示训练数据的来源,建立组织对 AI 输出的信任。补充监控系统应持续审核访问模式,检测可能存在安全隐患的异常行为。因此,监管设计应基于具体的现代用例场景,例如安全且受管控的数据和应用程序共享,以及构建安全的 AI 应用程序。
14. 5.2k 星的 Rainbond 在海外为何无人问津
Why our 5.2k-star K8s platform struggles overseas while thriving in China? Need your brutal feedback
背景
Rainbond 成员在 Reddit 上发帖提问:为什么我们的 5.2k 星 K8s 平台在海外苦苦挣扎,而在中国蓬勃发展?
Rainbond 是什么
Rainbond 是 100% 开源的,提供无服务器体验,让您无需了解 Kubernetes 即可轻松管理容器化应用程序。它是一个适合私有部署的集成应用程序管理平台。
Rainbond = 类 Heroku 体验 + 原生 Kubernetes 支持 + 自建能力
为什么在海外无人问津
根据目前的回复,可以分为几部分:
- 政治因素
- 英文文档不够完备
- 文档质量不高
- 海外推广少
15. 关于大公司积极参与开源
A Brief History of Open Source
背景
开源的起源来自与大型供应商的斗争,开发人员不想继续为不符合其用例、存在他们无法始终修复的错误以及存在安全问题的软件付费。他们也不想等到下一次重大更新才能修复即使是最小的错误。他们甚至不要开始供应商锁定。但是目前很多大型供应商(大公司)开始积极参与开源,例如 Google、微软等。从逻辑上看,大公司对开源应当是非常抵制,但为什么会出现这种别扭的现象。
“从开源中赚钱很困难。尤其是在 CNCF 中,其参与者倾向于将项目视为可供使用的免费产品,将 GitHub/Slack/etc 项目空间视为免费的服务台,而'供应商'一词则是一种侮辱。”
大公司为什么要积极参与开源
可能有以下原因:
- 降低研发成本:通过参与和贡献开源项目,大型供应商可以利用社区的力量,共同开发和维护基础软件,从而降低自身的研发投入。
- 加速创新:开源社区汇聚了全球顶尖的开发者,他们的创新想法和贡献能够加速技术的发展,让大型供应商能够更快地采用和集成新技术。
- 吸引开发者:开发者更倾向于使用和贡献开源技术,大型供应商通过积极参与开源,能够吸引更多的优秀人才加入他们的生态系统。
- 构建生态系统和锁定用户:大型供应商往往会基于开源技术构建自己的产品和服务,例如云计算平台、大数据解决方案等。通过积极贡献和主导某些关键的开源项目,他们可以构建强大的生态系统,吸引更多的用户并形成一定的用户粘性。
- 提升品牌形象:积极参与和贡献开源社区,能够提升大型供应商的技术领导力和开放合作的形象,赢得开发者的尊重和信任。
- 影响技术方向:通过参与关键开源项目的开发和治理,大型供应商可以影响技术的发展方向,使其更符合自身的产品和战略需求。
潜在的风险
- 控制权和影响力:大型供应商可能会利用其资源优势,在某些开源项目中占据主导地位,影响项目的发展方向,甚至可能出现“垄断”的风险,这与开源的去中心化和社区驱动的理念相悖。
- 商业利益优先:大型供应商参与开源的最终目的是为了其商业利益,这可能会导致他们更关注对自身有利的功能和特性,而忽略社区的整体需求。(🎤:和 CVE 有点类似)
- 社区的可持续性:过度依赖大型供应商的贡献可能会削弱社区的自主性和活力,一旦大型供应商的战略发生变化,可能会对开源项目造成不利影响。
16. Kubernetes 中的 CPU 限制:为什么你的 Pod 空闲但仍然受到限制
一篇技术贴,具体看原文。
“想象一下,您可以每分钟喝 1 升水——但您真的很渴,想在前 10 秒内喝 1 升水。系统拍了拍你的手,说:“下次再说吧。与此同时,你仍然口渴——即使你没有超过平均水平。
这就是 Kubernetes 中低使用率、高节流的情况。”
17. VMware Tanzu Kubernetes 产品/服务发生了什么变化?
Do you have any insights on how dead vmware tanzu is?
帖子中高赞回复:
“Tanzu 一直更像是一个品牌包装,而不是一个连贯的产品。不断的更名、重叠的产品和缺乏战略方向使其令人困惑且难以信任。过去,他们提供了多种 Kubernetes 风格(TKGm、TKG 和 TKGi),但没有一种感觉是完全成熟的。过去,他们提供了多种 Kubernetes 风格(TKGm、TKG 和 TKGi),但没有一种感觉是完全成熟的。他们更广泛的 Tanzu 产品组合仍然存在,但分散且主要集中在应用程序层,几乎没有明确性或动力。”
18. Kubernetes 网络指南
The Kubernetes Networking Guide
该网站的目的是提供各种 Kubernetes 网络组件的概述,特别关注它们如何实现所需的功能。
虽然这里的信息可以用于教育目的,但其主要目标是为设计、操作和解决集群网络方案中的问题提供一个统一的参考。
📄 专题四 报告查看与分析
1. [CNCF] Kubernetes 与意外的云支出
Kubernetes and unexpected cloud spend: taming, not riding, the tiger
调查于 2023 年 6 月至 11 月期间进行,共收到 100 多份回复。
成本变化
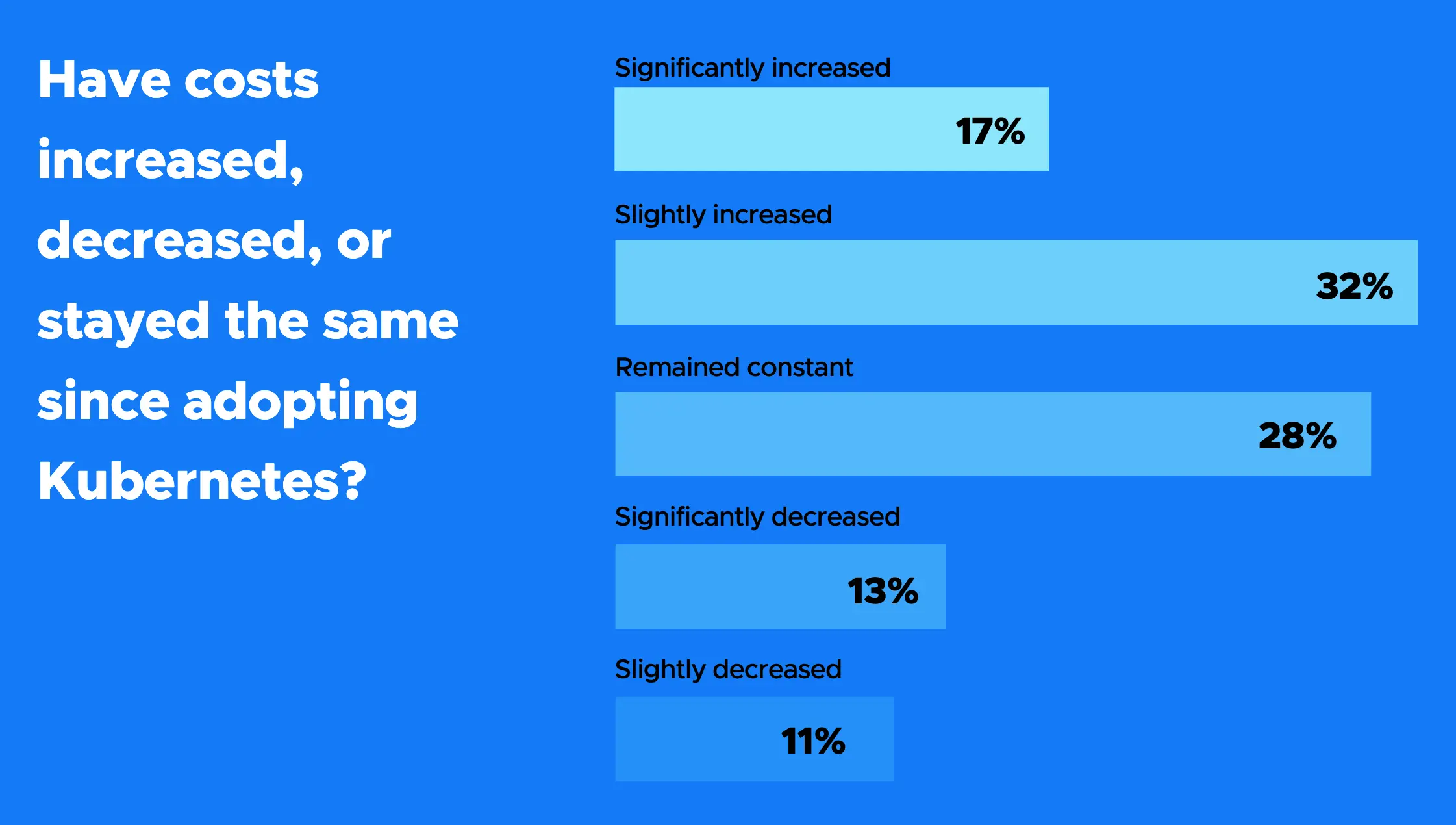
CNCF 最新关于云原生和 Kubernetes FinOps 的微调查报告中,近一半(49%)的受访者表示,Kubernetes 推动了云支出的增加,无论是由于需要更多资源还是实现更大规模的部署。受访者告诉我们,在实施流行的编排平台后,他们的成本略有或大幅增加。近三分之一(28%)的人表示,他们的成本没有变化。
Kubernetes 支出情况
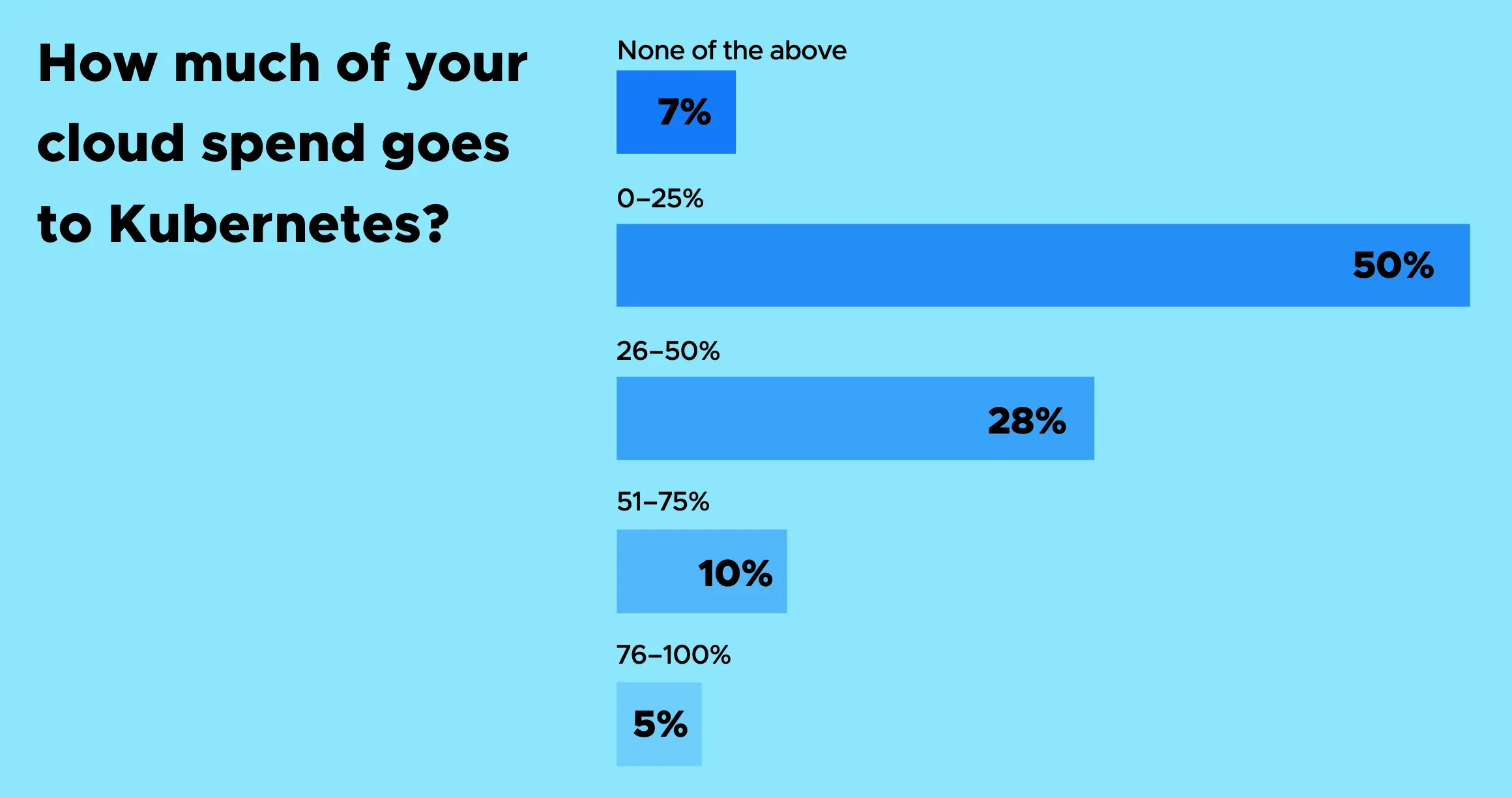
Kubernetes 正在不同程度地占用云预算。一半的受访者(占受访者总数的一半)表示,他们在 Kubernetes 上的花费高达预算的四分之一,但也有相当一部分受访者表示,这个数字更高。约 28% 的受访者表示,Kubernetes 占用了他们预算的一半,而 10% 的受访者表示,这一数字高达 75%,而只有 5% 的受访者表示,Kubernetes 占用了 76% 甚至全部预算。
云相关支出情况
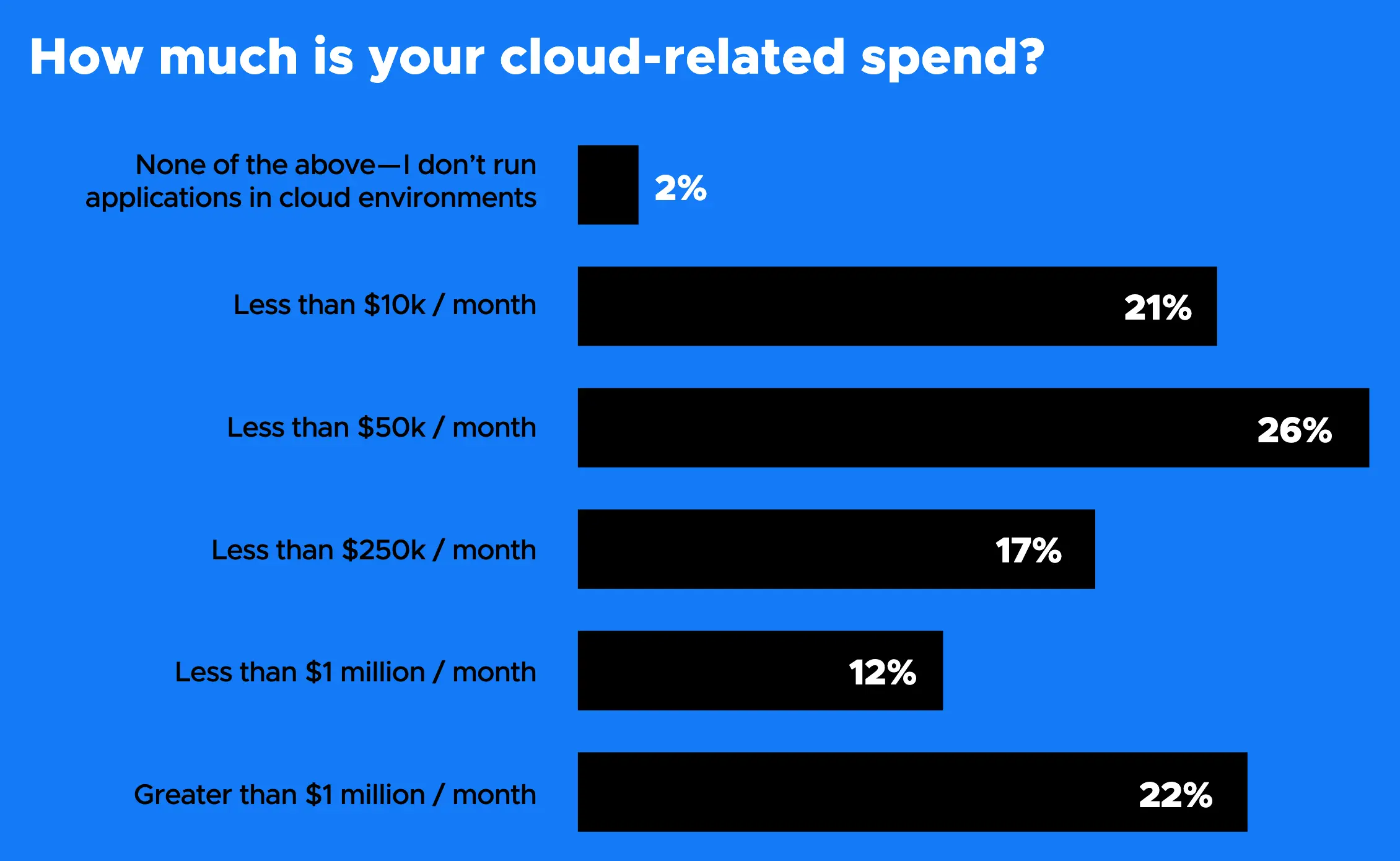
最大的群体(26%)每月在云上花费高达 50,000 美元,但第二大群体(22%)支付的费用是该数字的 20 倍,因此,每月花费超过 100 万美元,比其他任何人都多。第三大群体的这一数字大幅下降,21% 的人每月在云上花费不到 10,000 美元。
Kubernetes 集群规模
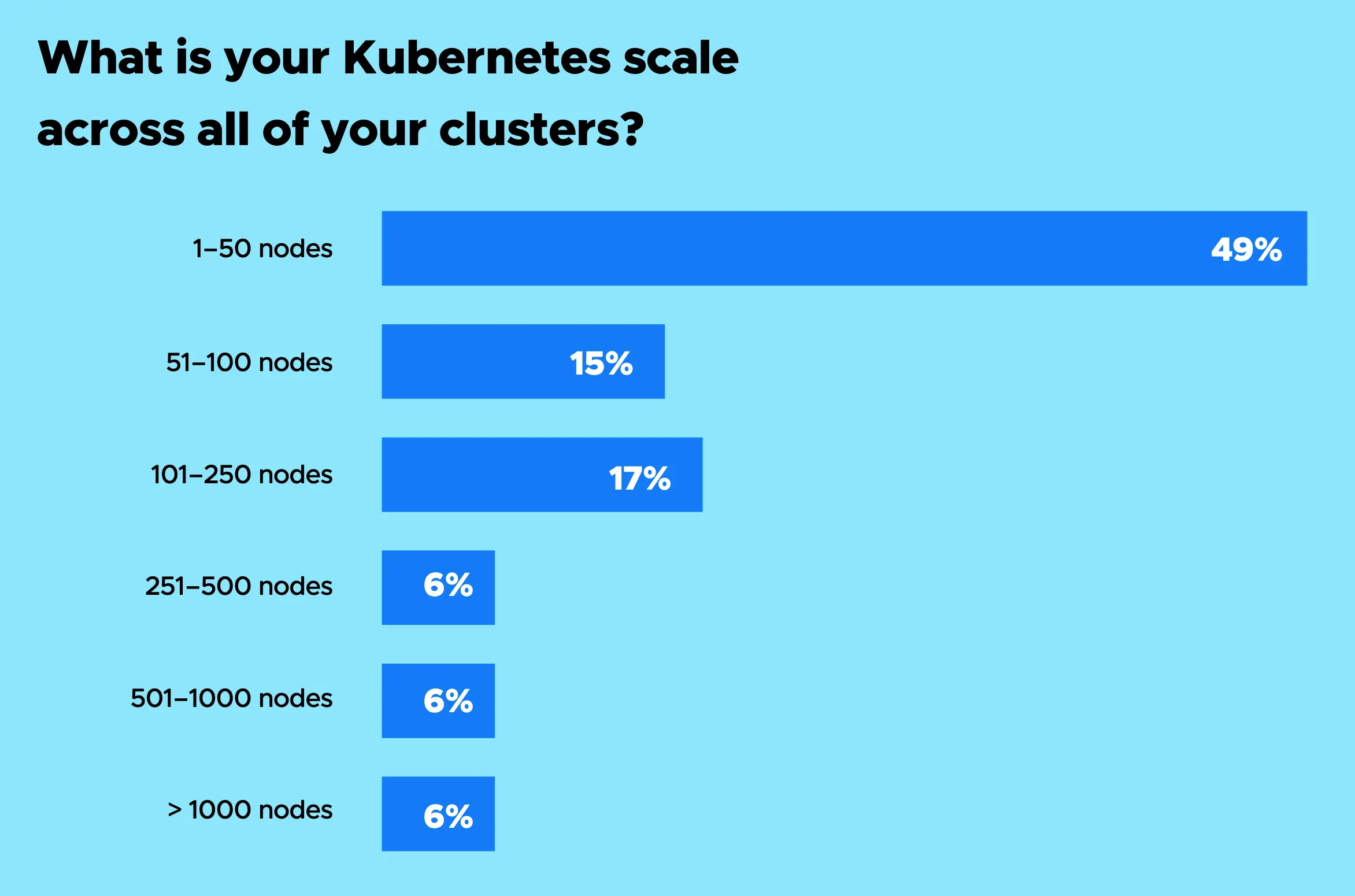
Kubernetes 基础设施的规模差异较大,最理想的分布集中在规模较小的一端,而在规模较大的区间则呈现“长尾”特征。近一半(49%)的部署规模在 50 个节点以内;而有 17% 的部署在运行 101 至 250 个节点;排名第三的群体(15%)的节点数量在 51 至 100 个之间。处于“长尾”部分的部署规模则在 251 至 1000 个节点甚至更多,加总后占受访者的 19%。
超支因素
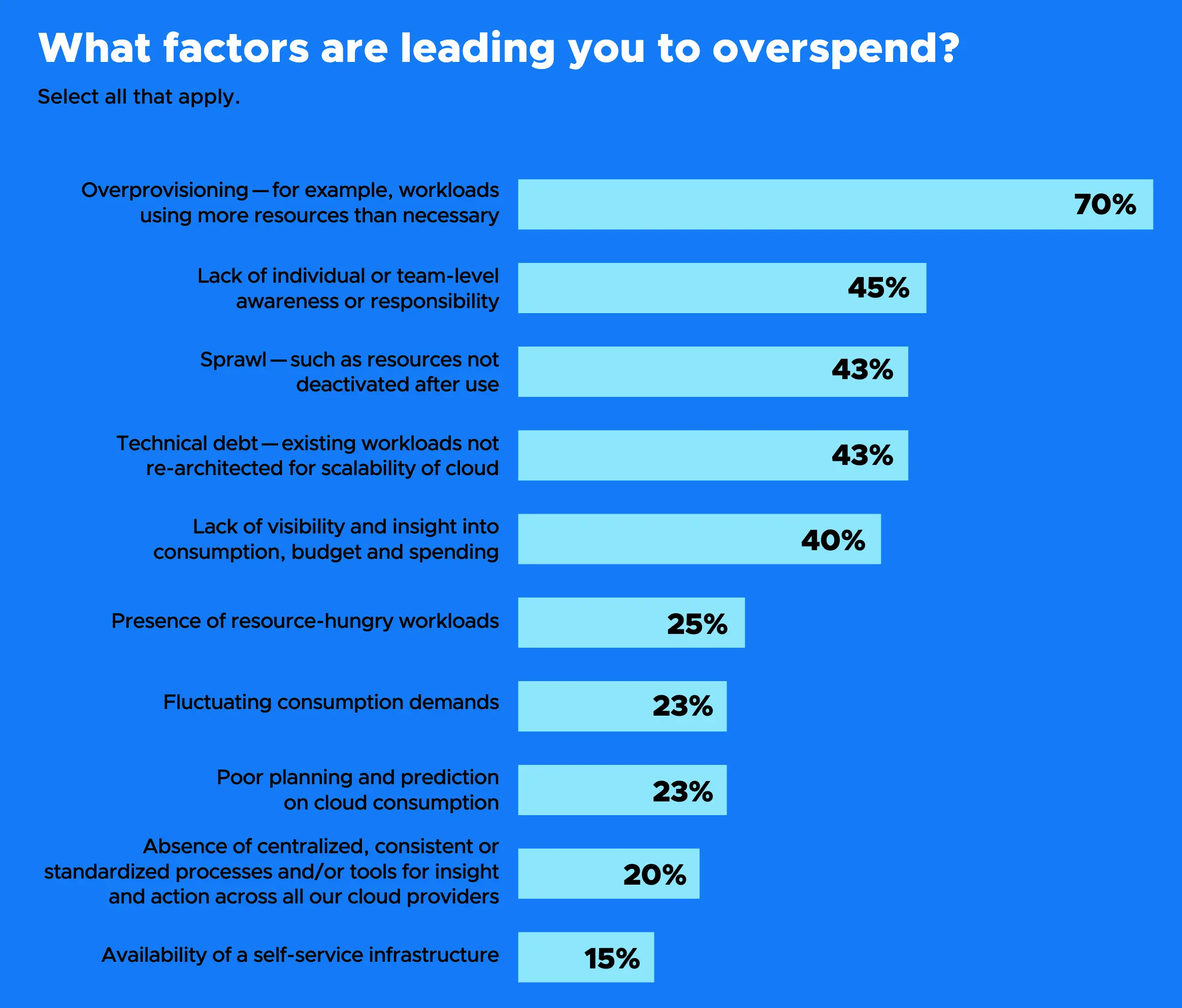
在云环境中,成本增加以及不必要和意外支出的上升,被归因于多个人为和技术因素。首当其冲的是资源超额配置,占比高达 70%;其次是个体或团队层面对成本责任缺乏认知,占比 45%。资源使用后未及时释放以及技术债务的存在(即未对工作负载进行重构以利用云原生环境的可扩展性)并列第三,分别占比 43%。
Kubernetes 成本监控情况
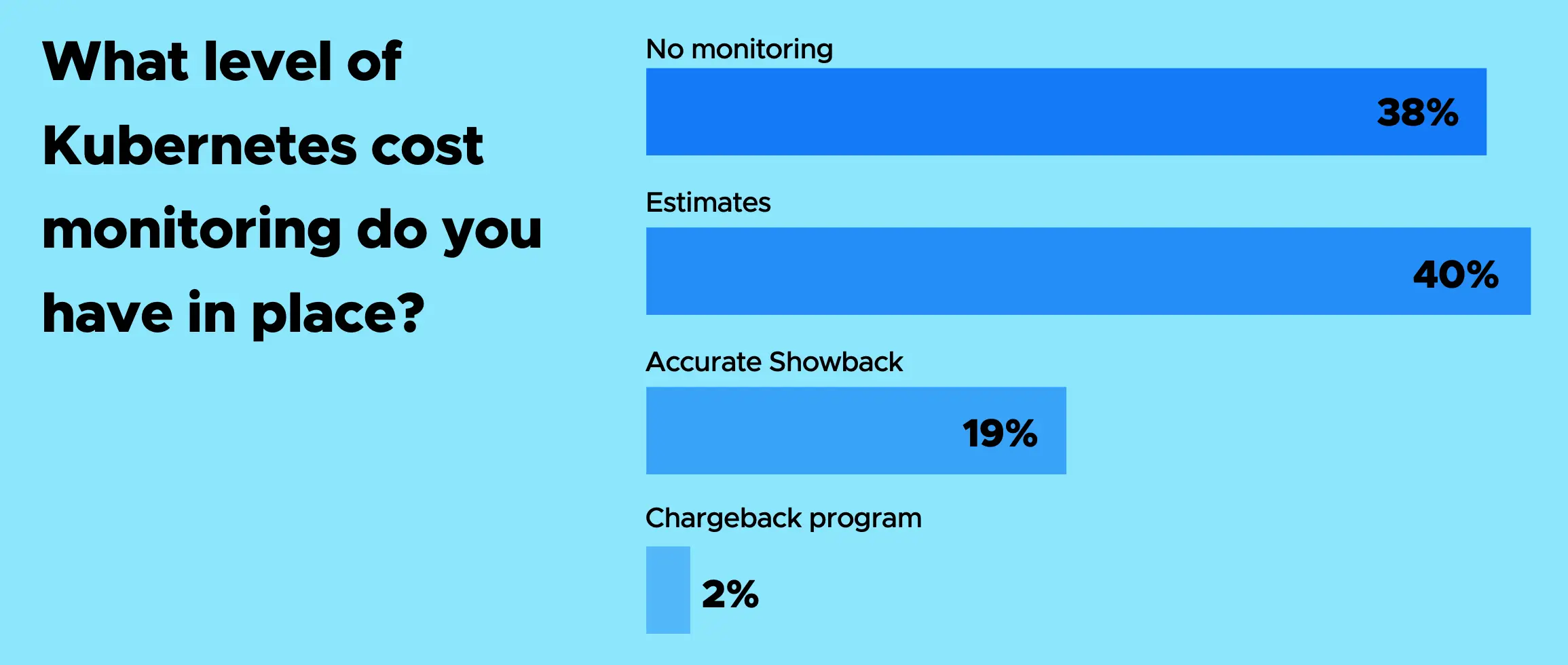
我们观察到,整体上企业采用了多种工具和方法来理解和管理云支出。这些措施包括账单分析、监控以及带警报功能的仪表盘。然而,针对 Kubernetes 的成本管理方法则显得不够成熟:仅有不到五分之一(19%)的企业能获取精确数据,而 40% 的受访者表示其 Kubernetes 成本系估算得出。更有 38% 的企业完全没有实施任何监控措施。
控制超支的方式
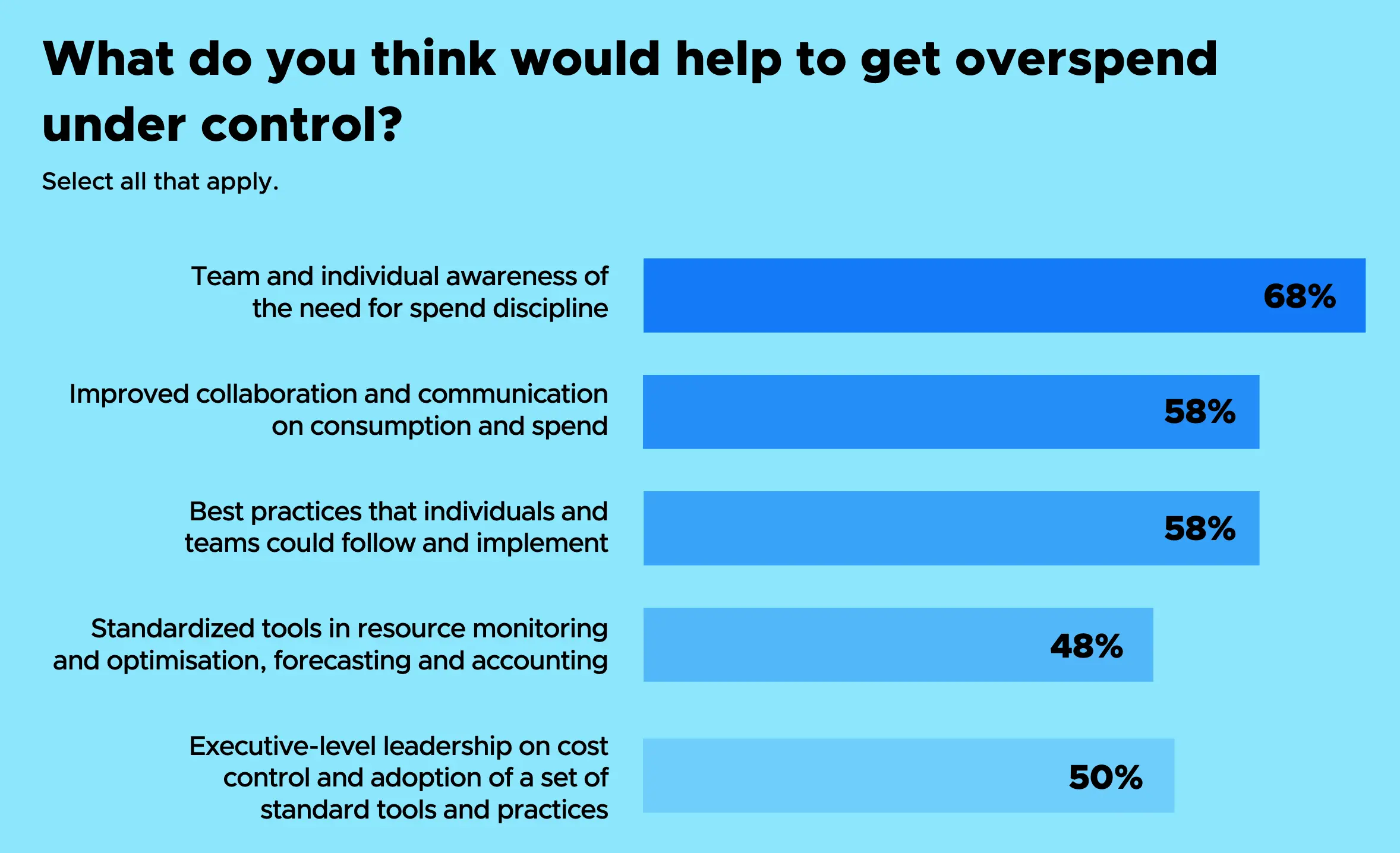
根据我们对导致支出和成本上升因素的研究结果,逐渐显现出一个有效控制这些问题的方法。多数人(68%)认为,提升个人和团队对成本责任的认知,并增强其对支出的理解,将有助于控制开销。其次是加强关于支出和资源消耗的协作与沟通,有 58% 的受访者认同这一点。同样有 58% 的人认为,在个人和团队层面遵循并落实最佳实践也能发挥作用。一半的受访者表示,企业高层的领导支持,以及采用标准化的工具与实践,将有所帮助。最后,有 48% 的人指出,应使用标准化工具来监控和优化资源、进行预测与成本核算。
2. [catchpoint] SRE Report 2025
用于为本报告提供见解的 SRE 调查于 2024 年 7 月至 8 月期间开放了六周。该调查收到了来自世界各地、各类可靠性角色和级别的 301 份回复。
可以直接看报告。
看到第一条“性能不佳和宕机或不可用一样糟糕。”随着对外界的标准不断提高,人类自身的技能并不一定跟得上这种速度,如何面对在向内看到自己远逊色于 AI 时的挫败,并且找到合适的位置自处。该不会最终人类最珍贵的是最差以及最美好的那部分特质吧。
✍️ 专题五 产品/方案介绍
1. kgateway:基于 Envoy 的网关
KubeCon Europe: Kgateway Aims To Be the Kubernetes Onramp
简介
kgateway 是目前市场上最成熟、部署最广泛的基于 Envoy 的网关。kgateway 基于开源和开放标准构建,它通过控制平面实现了 Kubernetes Gateway API,该控制平面可从服务之间的轻量级微网关部署,扩展到处理数十亿次 API 调用的大规模并行集中式网关,再到用于在提供模型或与第三方集成应用时保障安全性和治理的高级 AI 网关用例。kgateway 为任何云和任何环境提供全方位的 API 连接。
kgateway 将自己定位为“AI 网关”,以解决将应用程序与 AI 网关集成所面临的独特安全和管理挑战。Kgateway 还与 Istio Ambient 网格紧密集成,旨在完全消除 Sidecar。
kgateway 于 2018 年以 Gloo 为名推出。自那时起,该项目稳步发展,成为 Kubernetes 上最值得信赖、功能最丰富的 API 网关,为全球许多大型企业处理数十亿个 API 请求。
在去年的 KubeCon+_CloudNativeCon North America 2024 上,该公司宣布将把该软件捐赠给云原生计算基金会 (CNCF),并将该软件的名称更改为 kgateway。
3 月,CNCF 接受 kgateway 作为沙盒项目,作为早期云原生软件项目的入口点。
特点
- 高级 Ingress Controller 和下一代 API 网关
- 支持和保护 LLM 使用的 AI 网关
- 利用推理扩展项目的网关
- 本机模型上下文协议(MCP)网关
2. Giant Swarm:托管 Kubernetes 管理平台
简介
Giant Swarm 是一家专注于企业级 Kubernetes 管理平台的技术公司,提供托管的 Kubernetes 解决方案,旨在帮助企业在生产环境中高效、安全地运行和管理 Kubernetes 集群。
特点
- 云端和本地:在 AWS、Azure、Google Cloud 和本地环境中无缝部署和管理容器。
- 完全开源:利用完全开源的 Kubernetes 平台,无需许可费用。
- 企业级:体验全天候支持、快速响应时间和行业领先的正常运行时间。
- 十年以上专业经验:受益于我们十年的经验和对 Kubernetes 社区的积极贡献。
- 在您的环境中:在您需要的地方部署和管理您的容器基础设施,无论是在云端还是在本地。
- 团队的延伸:加入我们经验丰富的团队,他们将与您一起拥有、学习并专注于使您的公司与众不同的事物。
3. Gardener:另一款托管 Kubernetes 管理平台
简介
Gardener 是一个由 SAP 主导开发的开源 Kubernetes 集群生命周期管理平台,专注于为企业提供大规模、自动化、多云/混合云的 Kubernetes 集群管理能力。其核心设计理念是 "Kubernetes 管理 Kubernetes"(即通过一个中央 "Kubernetes 集群来创建和管理其他工作集群)。
特点
- 均质:在任何受支持的基础架构上进行相同的第一天和第二天的操作
- 开源成长:由 SAP 率先开发的开源 Gardener 项目提供支持
- 超可扩展:通过设计实现数千个集群的低 TCO 队列管理
- 经过认证且合规:企业级安全认证,100% 符合 CNCF Kubernetes 标准
- 无处不在:在 Amazon、Azure、Google、阿里云等平台拥有相同的体验
- 自主:自我修复、自动扩展,以及自动更新操作系统和 Kubernetes(如果您选择)
4. Freelens:免费开源的 Kubernetes UI 管理产品
简介
Freelens 是一款免费的开源用户界面,专为管理 Kubernetes 集群而设计。它提供了一个独立的应用程序,兼容 macOS、Windows 和 Linux 操作系统,方便广大用户使用。该应用程序旨在通过提供直观易用的界面,简化 Kubernetes 管理的复杂性。
5. vNode:隔离单个 Kubernetes 节点,以提高多租户安全性和资源效率
Introducing vNode: Virtual Nodes for Secure Kubernetes Multi-Tenancy
KubeCon Europe: Kubernetes vNode, From the Makers of vCluster
简介
vNode 是一种隔离 Kubernetes 集群内各个节点的功能,它延续了该公司 2021 年推出的一项名为 vCluster 的开源技术,该技术对 Kubernetes 控制平面进行了虚拟化,使多租户更容易,提高安全性并更有效地利用资源。通过将 vNode 与 vCluster 相结合,团队现在可以实现全面的 Kubernetes 多租户。vCluster 在 Kubernetes 控制平面提供隔离,而 vNode 则通过确保租户工作负载在节点级别得到安全隔离来补充这一点,从而同时优化资源利用率和安全性。
与 vCluster 不同,vNode 不会是开源的,而是仍然是一种商业产品。
工作原理
vNode 在每个物理节点上引入了一个轻量级运行时,将其拆分为独立的虚拟节点,每个虚拟节点通过 Linux 用户命名空间映射到非特权用户。这使得租户可以安全地运行特权工作负载(例如 Docker-in-Docker 甚至 Kubernetes 控制平面),而不会面临干扰或跨租户安全问题的风险。

适用场景
- 高度监管的环境 ,其中合规性和安全标准要求严格分离工作负载。
- 运行资源密集型工作负载(如人工智能和机器学习)的团队需要不受干扰的专用资源。
- 组织正在努力解决嘈杂邻居问题 ,影响共享基础设施的性能和可靠性。
- 具有特权工作负载的环境 ,其中传统的 Kubernetes 设置会产生安全漏洞或操作风险。
类似产品
-
Kata Containers
Kata Containers (通常称为“微型虚拟机”)带有自己的内核,开销可能很高。它们也不适用于每个云提供商。 -
Google 的 GVisor
gVisor 通过系统调用过滤流量,这会降低性能,并且主要限于 Google Cloud。 -
Docker 的 Sysbox
Sysbox 的工作方式与 vNode 的工作方式最为接近,主要用于 Docker Desktop。
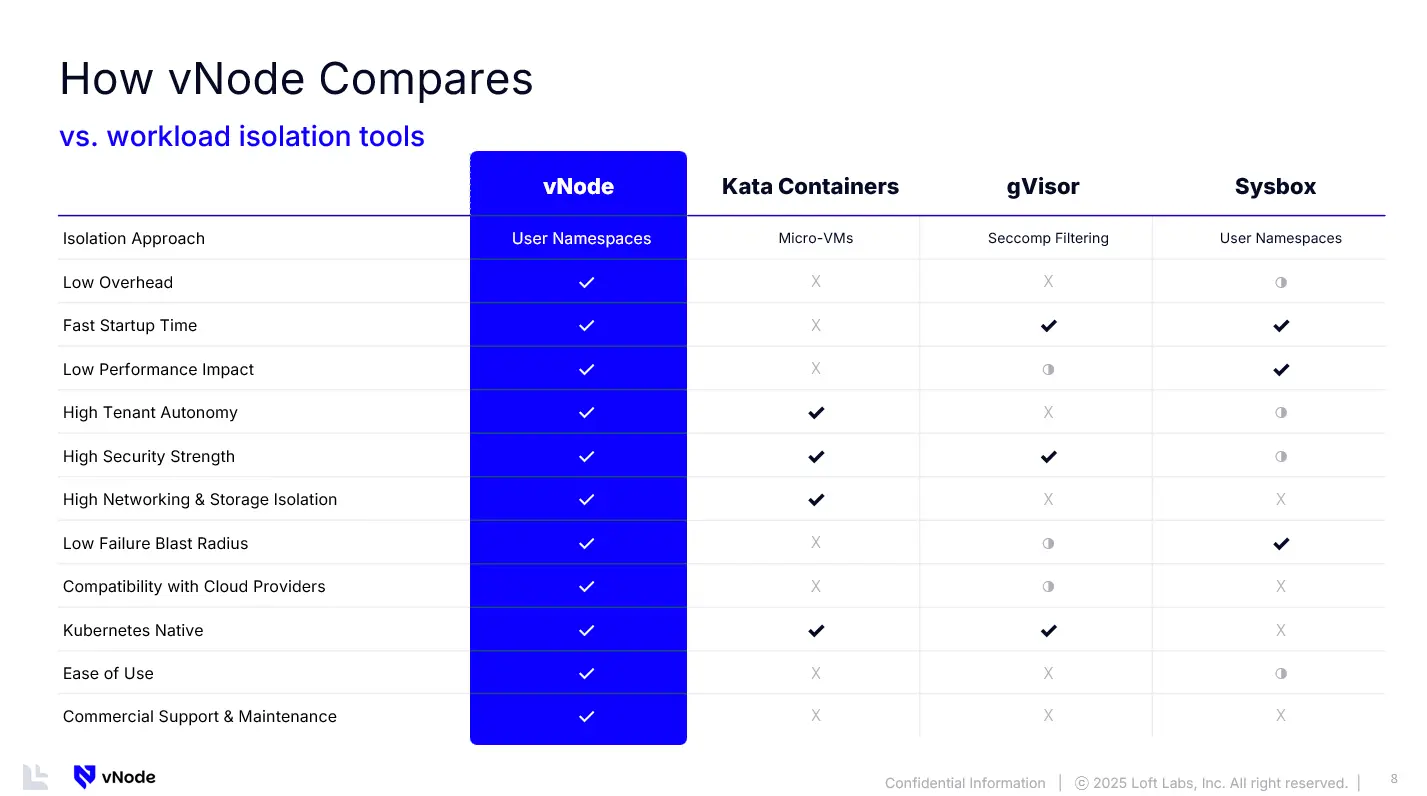
特点
- 强隔离: vNode 在共享物理节点内隔离节点级别的工作负载。
- 更低的开销和性能损失: 无需完整的虚拟机、无需系统调用转换、没有不必要的复杂性。vNode 提供严格的隔离,而不会影响性能或增加维护。
- 完全租户自主: 租户可以运行特权工作负载(如 Docker-in-Docker、Kubernetes 控制平面或系统级工具),而不会影响其他工作负载。
- Kubernetes 原生且与云平台无关: Kubernetes 原生,兼容所有主流云平台,并可在任何基于容器的集群(Linux 1.6+)上运行。无需重新架构。
拓展阅读
How We Load Test Argo CD at Scale: 1,000 vClusters with GitOps on Kubernetes
6. Perses:云原生可视化方法
Perses Closes the Observability Gap with Declarative Dashboards
简介
是一种仪表板的开放规范。适用于 Prometheus 和其他数据源的开放仪表板工具。
是一个云原生计算基金会 (CNCF) 沙盒项目,旨在简化云原生环境中的仪表板创建和管理。
设计背景 & 挑战
在 Kubernetes、微服务和 GitOps 不断发展的格局中,可观察性至关重要。虽然 OpenTelemetry 、Prometheus 和 Jaeger 等工具已经标准化了遥测数据的收集和存储,但可视化工具仍然支离破碎。基础设施和应用程序采用声明式管理,但仪表板通常仍然是手动的、不一致的,并且与 DevOps 工作流脱节。这种错位在开发人员、站点可靠性工程师 (SRE) 和依赖一致指标的业务领导者之间造成了摩擦。
可观测性仪表盘工具目前面临的挑战:
- 手动工作流程和不一致
- 造成配置漂移: 团队复制仪表板,但略有不同(例如“prod-latency”与“production-latency”),导致事故发生时产生混乱。
- 缺乏协作: 没有编纂的标准,开发人员、SRE 和业务团队可能会对指标做出不同的解读。
- 忽略 GitOps 原则: 很少在 git 中跟踪更改,这使得审计和回滚变得繁琐。
- 部分自动化,完全复杂性
一些工具通过 Terraform 提供程序或 Kubernetes 操作员提供“即代码”工作流。但是,这些通常是:- 不透明: 基于 JSON 的仪表板缺乏人类可读性和验证保障。
- 脆弱: 在环境(dev/staging/prod)之间迁移仪表板经常会破坏查询或数据源。
- 工具特定: 专有格式将团队锁定在供应商中,使多云策略变得复杂。
- 缺失的标准
业界缺乏可移植、与供应商无关的仪表板规范。这迫使团队:- 为每个工具重新设计模板(例如,Grafana、 Datadog 或 New Relic )。
- 更换供应商时维护脆弱的迁移脚本。
- 牺牲创新以避免返工。
特点
-
声明式仪表板定义
Perses 使用 Kubernetes CRD 将仪表板配置存储为代码。这可确保仪表板与 git 中的应用程序清单一起进行版本控制、可审计和管理。对于已经使用 Argo CD 等 GitOps 工具的团队,Perses 可无缝集成到现有工作流程中。 -
可移植性和灵活性
与专有仪表板工具不同,Perses 优先考虑开放标准。其轻量级架构与 Prometheus 和 Grafana Tempo 等流行数据源集成,避免供应商锁定。开发人员可以通过 npm 包将仪表板嵌入内部工具,而平台团队则在各个环境中强制一致性。 -
大规模协作
Perses 的编程 SDK(Go、Cuelang)使团队能够制作仪表板模板、重复使用组件并自动执行重复任务。这对于管理数百个仪表板的企业尤其有价值,因为手动仪表板维护很快就会变得难以为继。 -
安全与治理
通过将仪表板存储在 Kubernetes 命名空间中,Perses 可与基于角色的访问控制 (RBAC) 策略保持一致,确保可见性仅限于相关团队。合规性审计变得更加简单,因为所有更改都会在 git 历史记录中进行跟踪,从而提供透明度和问责制。
7. Headlamp:专注于可扩展性的 Kubernetes UI
简介
Headlamp 是一款用户友好的 Kubernetes UI,专注于可扩展性。是 CNCF 沙盒项目。
特点
-
适应性 UI 和品牌
用最少的努力创造定制体验。 -
基于 RBAC 的控制
Headlamp 适应用户的集群权限。 -
桌面和 Web
它可以作为 Web 应用程序、桌面应用程序或两者运行。
8. KubeDiagrams:自动生成 Kubernetes 架构图
简介
从 Kubernetes 清单文件、kustomization 文件、Helm 图表和实际集群状态生成 Kubernetes 架构图。
特点
KubeDiagrams 的主要特色在于其可配置性, 例如允许处理自定义 Kubernetes 资源。
扩展阅读
Awesome Kubernetes Architecture Diagrams
9. OKE:Oracle 提供的托管式 Kubernetes 服务
简介
Oracle Cloud Infrastructure Container Engine for Kubernetes (OKE) 是一个托管式 Kubernetes 服务,可简化大规模的企业级 Kubernetes 操作。该服务可减少管理 Kubernetes 基础设施复杂性所需的时间、成本和精力。借助 Container Engine for Kubernetes ,您可以部署 Kubernetes 集群,并通过自动扩展、升级和安全打补丁功能,确保控制层和 worker 节点的可靠运行。此外,OKE 还提供带有虚拟节点的全面无服务器 Kubernetes 体验。
特点
-
性价比
OKE 是所有超大规模中成本最低的 Kubernetes 服务,尤其是对于无服务器而言。 -
自动缩放
OKE 根据需求自动调整计算资源,从而降低您的成本。 -
效率
GPU 可能很稀缺,但 OKE 作业调度可以轻松最大化资源利用率。 -
可移植性
OKE 在云端和本地保持一致,实现了可移植性并避免了供应商锁定。 -
简单
OKE 减少了管理 Kubernetes 基础设施复杂性所需的时间和成本。 -
可靠性
自动升级和安全修补提高了控制平面和工作节点的可靠性。 -
弹性
使用 OCI 全栈灾难恢复可以实现全自动、本机跨区域恢复。
使用场景
- AI 模型构建
- AI 模型训练
- AI 模型推理
- 现有应用程序迁移
- 微服务开发
10. Koreo:Kubernetes 配置管理和资源编排方法
简介
Koreo 是一个平台工程工具包,它引入了一种新的 Kubernetes 配置管理和资源编排方法。它借鉴了 Helm、Kustomize、Argo、Crossplane 和 kro 等工具的优点,同时解决了它们的一些局限性。
特点
-
可编程工作流程
定义复杂的多步骤流程,响应事件并管理 Kubernetes 资源的生命周期。Koreo 工作流支持从简单部署到整个云环境的自动化。这就像编程(或编排 )Kubernetes 控制器一样。 -
结构化配置管理
以预期的方式管理 Kubernetes 配置——将其作为结构化数据,而不仅仅是模板字符串。这使您能够以可管理且可扩展的方式轻松验证、转换和组合来自多个来源的配置。通过将一个资源的输出映射到另一个资源的输入,可以连接任何资源。 -
动态资源实现
从配置文件注入值或叠加部分定义以构建完整的资源视图。组合来自不同来源(例如安全性、合规性和 SRE)的配置,甚至应用自定义逻辑,为开发人员提供配置应用程序、资源或 Kubernetes 管理的任何内容的黄金路径。 -
配置为函数
受函数式编程原理的启发,Koreo 允许您将配置分解为函数。这些函数充当可重用的构建块,用于封装 Koreo 工作流中的常见任务和逻辑。这促进了模块化,减少了重复,并使工作流更易于维护和发展。 -
声明式运算符模型
通过工作流和函数定义您的期望状态,Koreo 将自动协调实际状态以匹配。这种声明式方法简化了管理并确保了整个基础架构的一致性。 -
一流的测试和工具
使用 Koreo 内置的测试框架和开发者工具, 将配置视为代码。为单个函数和整个工作流编写单元测试,以便及早发现错误并防止意外行为。Koreo 的 IDE 集成为您提供实时反馈、自动完成和自省功能。
11. Octopus Deploy:应用自动化部署和发布管理工具
简介
Octopus Deploy 是一个复杂的、同类最佳的持续交付 (CD) 平台,适用于现代软件团队。Octopus 提供强大的发布编排、部署自动化和 Runbook 自动化,同时处理规模、复杂性和治理期望,即使是面临最复杂部署挑战的最大组织也是如此。
特点
传统的 CI/CD 工具通常只提供简单的部署脚本功能,随着应用程序的发展,部署脚本会变得越来越复杂,难以维护。Octopus 专注于 CD 环节,与 CI 工具集成,接管构建后的工作,提供更强大、更专业的 CD 功能,让团队从繁琐的脚本维护中解放出来,专注于交付价值。
- 用户友好: 界面现代直观,团队可以轻松地自助发布应用程序,实现软件交付的民主化。
- 强大的 API: 所有 UI 操作都可以通过 API 完成。
- 全面的发布流程: 接管 CI 服务器结束后的工作,对软件的整个发布编排流程进行建模,包括版本控制、环境提升、部署自动化、渐进式交付等等。
- 广泛的适用性: 可以部署任何应用程序到任何目标环境,无论是 Kubernetes、Linux 还是 Windows 虚拟机、AWS、Azure 还是 Google Cloud。
- 安全可靠: 基于角色的访问控制、完整的审计跟踪,确保只有授权人员才能部署到生产环境。
- 灵活的部署方式: 可以自托管在您的基础设施或私有云中,也可以选择 Octopus Cloud 托管服务。
- 应对复杂部署: 使用“租户部署”等高级方式对部署进行建模,即使是跨地域分布式集群的复杂场景也能轻松应对。
- 久经考验: 由经验丰富的 DevOps 从业者开发,并经过成千上万个组织的实战检验,从小型团队到财富 100 强企业。
12. Omni:基于 Talos 构建的 Kubernetes 管理 SaaS 平台
简介
Omni 在裸机、虚拟机或云中管理 Kubernetes。由 Sidero 的人们在 Talos Linux 上构建。
特点
- 在您的机器上并由您控制的 Vanilla Kubernetes
- 用于管理和操作的优雅 UI
- 安全得到妥善处理并与您的 Enterprise ID 提供商相关联
- 内置高可用性 Kubernetes API 端点
- 防火墙友好,可实现安全的边缘节点管理
- 从单节点集群到最大规模工作
- 支持 GPU 和大多数 CSI
扩展阅读
13. Sail Operator:使用 Operator 管理 Istio
Sail Operator 1.0.0 发布:使用 Operator 管理 Istio
简介
Sail Operator 管理 Istio 控制平面的生命周期。它为您提供自定义资源来部署和管理 control plane 组件。
Sail Operator 旨在降低安装和运行 Istio 的复杂性。 它可以自动执行手动任务,确保从初始安装到集群中 Istio 版本的持续维护和升级, 都能获得一致、可靠且简单的体验。Sail Operator API 是围绕 Istio 的 Helm Chart API 构建的, 这意味着所有 Istio 配置都可以通过 Sail Operator CRD 的值获得。
14. Karpenter:节点自动扩缩控制器
简介
Karpenter 是一种现代的 Kubernetes 原生自动扩展程序,旨在满足容器化工作负载的动态需求。与传统的自动扩展工具不同,Karpenter 旨在根据集群的需求自动快速预置节点。它的实时响应能力有助于确保您的应用程序在需要时拥有所需的资源,从而减少延迟和开销。
如何工作
Karpenter 是一种 Kubernetes 原生自动扩展程序,旨在根据实时工作负载需求动态调整 Kubernetes 集群的大小。Karpenter 的核心是持续监控集群的状态,包括来自 Pod 和节点的指标。这种监控使 Karpenter 能够就扩展作做出明智的决策。当它检测到当前资源不足以处理工作负载时,Karpenter 会启动扩展过程。这涉及使用最符合待处理 Pod 的资源要求的适当实例类型和大小预置新节点。相反,当工作负载减少且节点未得到充分利用时,Karpenter 会通过取消预置这些节点来安全地缩减集群,确保正在运行的工作负载不会中断。
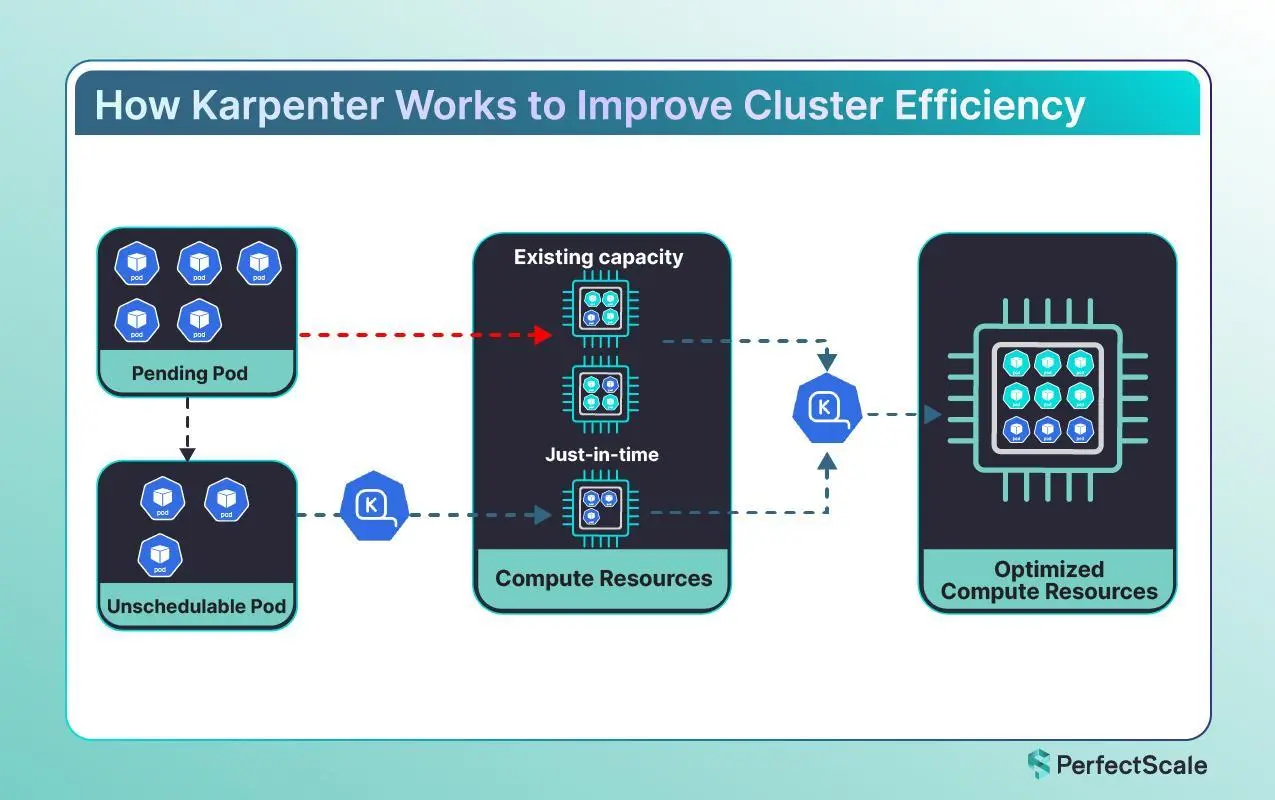
特点
- 快速节点配置 :Karpenter 的突出特点之一是它能够快速启动新节点。它会持续监控您的集群,识别何时由于缺乏资源而等待调度 Pod。通过按需预置节点,它可以最大限度地减少等待时间并保持您的应用程序平稳运行。
- 工作负载感知实例选择: Karpenter 不仅增加了计算容量;它添加了正确的计算类型。它会动态评估传入工作负载的资源需求(例如 CPU、内存甚至 GPU 需求),并选择云环境中可用的最合适的实例类型。这种工作负载感知方法可确保您不会为不必要的容量多付费用,并为特定应用程序获得最佳性能。
- 云原生集成:Karpenter 在设计时充分考虑了现代云基础设施,与主要云提供商无缝集成。它使用本机 API 根据当前定价、可用实例类型和区域容量做出智能决策。
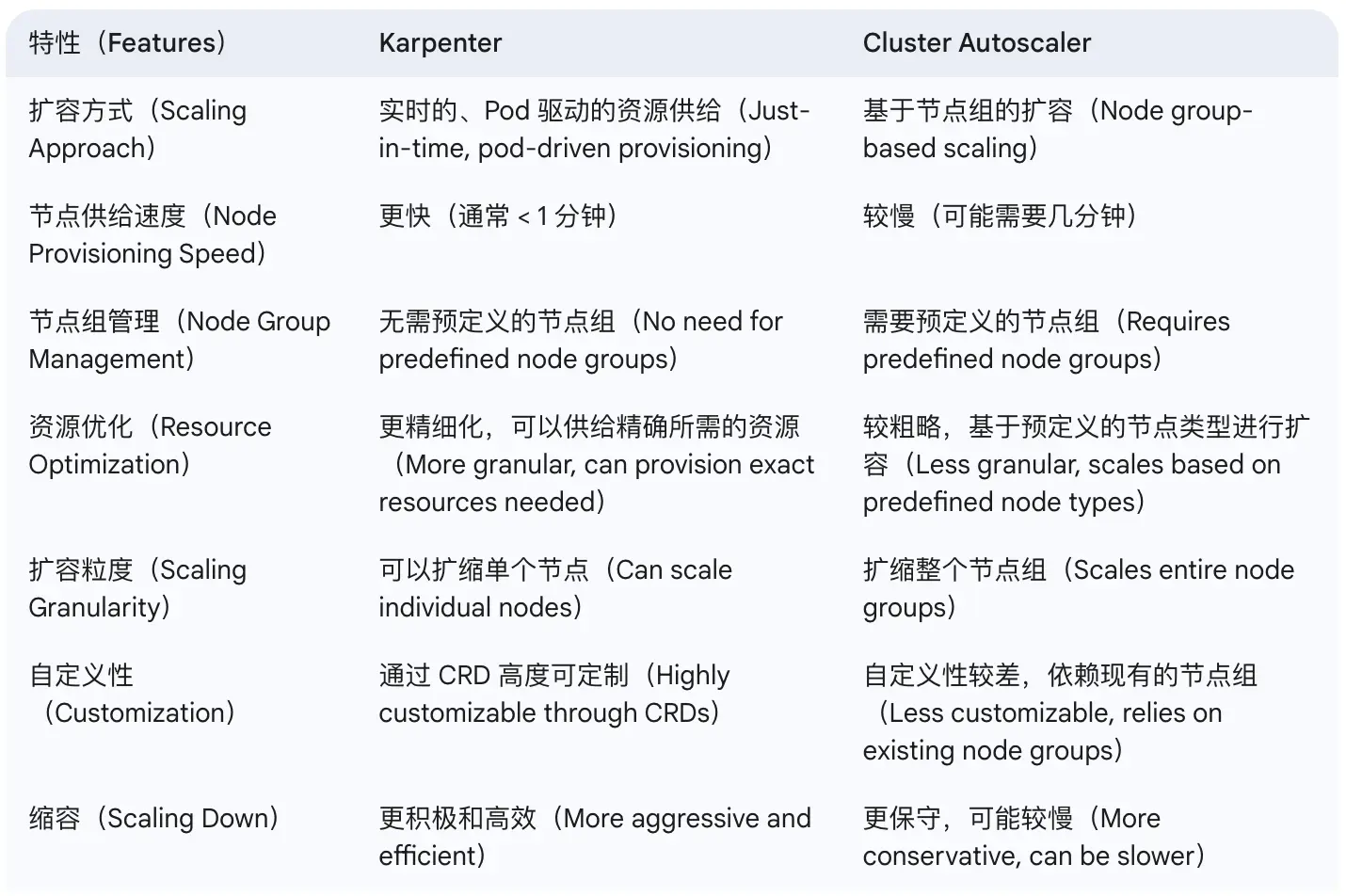
Karpeneter 与 Cluster Autoscaler 的对比
Karpenter 的最佳实践
How to Optimize Karpenter for Efficiency and Cost
- 配置节点过期时间: 您应该设置 expireAfter 参数以确保定期更换节点,并结合最新的安全补丁和性能改进。这种主动的方法降低了长期漂移和潜在漏洞的风险。必须根据您的工作负载类型设置适当的过期时间,以平衡安全性和成本效益。
- 设置终止宽限期:terminationGracePeriod 参数定义 Karpenter 在强制终止节点之前等待节点耗尽的最长持续时间。配置良好的终止宽限期可以平衡为 Pod 提供足够的时间来优雅退出,并确保节点及时循环以节省成本。如果此时间段设置得太短,可能会导致突然终止,从而导致工作负载不稳定,而过长的时间段可能会延迟成本节省。建议根据您的环境计算宽限期。
- 使用 karpenter.sh/do-not-disrupt Annotation:您应该将此 Comments 应用于关键 Pod,以防止它们在整合活动期间被驱逐。虽然它可以保护基本工作负载,但过度使用此注释可能会阻止在计划刷新期间删除节点,从而导致资源效率低下。您应该将此注解保留给真正关键的、短期的进程或交互式作业,除非绝对必要,否则应避免将其应用于长时间运行的有状态服务。
- 应用 Pod 中断预算 (PDB):PDB 通过指定中断期间必须保持可用的 Pod 的最小数量来确保应用程序在节点中断事件期间的可用性。配置 PDB 时,需要根据工作负载的服务等级协议 (SLA) 在 minAvailable 和 maxUnavailable 设置之间进行选择。您应该将 PDB 与 Karpenter 集成,以实现正常的节点耗尽并最大限度地减少停机时间。您还应定期更新 PDB 以反映自动扩展动态,以保持其有效性。
- 节点池配置和分层约束: 您可以针对不同的工作负载设计节点池,从而提高资源利用率和弹性。例如,为有状态和无状态工作负载提供单独的 NodePools,以便优化实例类型选择等。您还可以利用节点选择器、关联性和容忍度来进一步优化调度,确保将工作负载放置在适当的节点上,而不会影响弹性。
- 成本优化的整合策略:Karpenter 的整合功能通过识别未充分利用的节点并将工作负载整合到更少的节点上来优化资源使用。此过程可以通过高效的 bin 打包和资源聚合来节省成本。但是,必须平衡整合过程中的潜在中断与成本节约和运营效率提高的好处。
- 平衡 Spot 实例和按需实例: 您可以混合使用 Spot 实例和按需实例,这样您就可以利用成本优势,同时确保关键组件的稳定性。您应该为节点池配置适当的权重和实例限制,以与您的 Savings Plan 承诺保持一致。此策略使您能够在不影响基本工作负载的可靠性的情况下优化成本
15. OpenCost:Kubernetes 和云支出成本监控工具
简介
OpenCost 使团队能够了解当前和历史的 Kubernetes 和云支出以及资源分配。这些模型在支持多个应用程序、团队、部门等的 Kubernetes 环境中提供了成本透明度。它还提供对多个提供商的云成本的可见性。
OpenCost 最初由 Kubecost 开发和开源。该项目结合了这些详细要求的规范和 Golang 实现。Web UI 位于 opencost/opencost-ui 存储库中。
功能
- 按 Kubernetes 集群、节点、命名空间、控制器类型、控制器、服务或 Pod 进行实时成本分配
- 对 AWS、Azure、GCP 上的所有云服务进行多云成本监控
- 通过与 AWS、Azure 和 GCP 计费 API 的集成实现动态按需 k8s 资产定价
- 支持具有自定义 CSV 定价的本地 k8s 集群
- 分配集群内 K8s 资源,如 CPU、GPU、内存和持久卷
- 使用 /metrics 终端节点轻松将定价数据导出到 Prometheus
- 云资源的碳成本
- 通过 OpenCost 插件支持 Datadog 等外部成本
- 免费和开源分发(Apache2 许可证 )
16. Nix:声明式构建和部署工具,替代部分 Docker 能力
简介
Nix 是一种工具,它采用独特的方法来进行包管理和系统配置。了解如何制作可重现、声明性和可靠的系统。
特点
- 重现:Nix 彼此隔离地构建软件包。这确保了它们是可重现的,并且没有未声明的依赖项,因此如果一个包在一台机器上工作,它也将在另一台机器上工作。
- 声明:Nix 使共享项目的开发和构建环境变得轻而易举,无论您使用何种编程语言和工具。
- 可靠:Nix 确保安装或升级一个软件包不会破坏其他软件包 。它允许您回滚到以前的版本 ,并确保在升级期间没有软件包处于不一致状态。
17. Kagent:用于构建 AI 代理的 Kubernetes 原生框架
简介
kagent 是用于构建 AI 代理的 Kubernetes 原生框架。Kubernetes 是运行工作负载的最流行的编排平台, 而 kagent 可以轻松地在 Kubernetes 中构建、部署和管理 AI 代理。kagent 框架旨在易于理解和使用,并提供一种灵活而强大的方法来构建和管理 AI 代理。
ChatGPT 是一个提供自然语言响应的 AI 聊天机器人。 然而,Agentic AI 超越了简单的聊天交互——它利用高级推理和迭代规划,自主解决复杂、非确定性的多步骤问题,将洞察转化为提高生产力的行动。如果我们将 Agentic AI 应用于云原生工程师日常面临的运维挑战呢? 这就是 Kagent 的用武之地。
特点
- Kubernetes 原生 :Kagent 旨在易于理解和使用,并提供一种灵活而强大的方法来构建和管理 AI 代理。
- 可扩展 :Kagent 设计为可扩展,因此您可以添加自己的代理和工具。
- 灵活 :Kagent 的设计非常灵活,适合任何 AI 代理用例。
- 可观察 :Kagent 设计为可观察的,因此您可以使用所有常见的监控框架来监控代理和工具。
- 声明式 :Kagent 设计为声明式,因此您可以在 yaml 文件中定义代理和工具。
- 可测试 :Kagent 旨在轻松进行测试和调试。这对于 AI 代理应用程序尤其重要。
18. Kubetail:实时 Kubernetes 日志记录仪表盘
简介
Kubetail 是 Kubernetes 的通用日志记录仪表板,针对跨多容器工作负载的实时跟踪进行了优化。使用 Kubetail,您可以查看工作负载中所有容器(例如 Deployment 或 DaemonSet)的日志,这些日志合并到一个按时间顺序排列的时间线中,并传送到您的浏览器或终端。
Kubetail 的主要入口点是 kubetail CLI 工具,它可以在桌面上启动本地 Web 仪表板或将原始日志直接流式传输到终端。在幕后,Kubetail 使用集群的 Kubernetes API 直接从集群获取日志,因此它开箱即用,无需先将日志转发到外部服务。Kubetail 还使用 Kubernetes API 来跟踪容器生命周期事件,以便在容器启动、停止或被替换时保持日志时间线同步。这使得在用户请求跨服务从一个临时容器移动到另一个临时容器时,可以轻松无缝地跟踪日志。
特点
- 干净、易于使用的界面
- 实时查看日志消息
- 支持按以下条件筛选日志:
- 工作负载(例如 Deployment、CronJob、StatefulSet)
- 绝对或相对时间范围
- 节点属性(例如可用区、CPU 架构、节点 ID)
- Grep
- 使用 Kubernetes API 检索日志消息,以便数据永远不会离开您的财产(默认为私有)
- Web 仪表板可以安装在桌面或集群中
- 在多个集群之间切换(仅限 Desktop)
19. kube-scheduler-simulator:Kubernetes 调度器的模拟器
简介
kube-scheduler-simulator 是一个 Kubernetes 调度器的模拟器,最初是作为 Google Summer of Code 2021 项目由我(Kensei Nakada)开发的,后来收到了许多贡献。
该工具允许用户深入检查调度器的行为和决策。
对于使用调度约束(例如, Pod 间亲和性) 的普通用户和通过自定义插件扩展调度器的专家来说,它都是非常有用的。
它使用户能够在检查调度决策每一个细节的同时,测试他们的调度约束、调度器配置和自定义插件。它还允许用户创建一个模拟集群环境,在该环境中,他们可以使用与生产集群相同的资源来测试其调度器, 而不会影响实际的工作负载。
使用场景
- 集群用户:检查调度约束(例如,PodAffinity、PodTopologySpread)是否按预期工作。
- 集群管理员:评估在调度器配置更改后集群的行为表现。
- 调度器插件开发者:测试自定义调度器插件或扩展器,在集成测试或开发集群中使用可调试调度器, 或利用同步 功能在类似生产环境的环境中进行测试。
20. yoke:Kubernetes 的 IaC 包部署器
简介
Yoke 是一个受 Helm 启发的基础设施即代码 (IaC) 包部署程序,旨在提供更强大、更安全和编程的方式来定义和部署包。虽然 Helm 严重依赖静态 YAML 模板,但 Yoke 允许您利用通用编程语言来定义软件包,使其比其前身更安全、更强大,从而将 IaC 提升到一个新的水平。
Kubernetes 包应该通过代码来描述。编程环境包括控制流、测试框架、静态类型、文档、错误管理和版本控制。它们是构建合同和执行合同的理想选择。
21. Reloader:根据 Secret/ConfigMap 的更新自动重启或重新部署工作负载
简介
Reloader 是一个 Kubernetes 控制器,当引用的 Secrets 或 ConfigMaps 更新时,它会自动触发工作负载(例如 Deployments、StatefulSets 等)的滚动更新。
在传统的 Kubernetes 设置中,更新 Secret 或 ConfigMap 不会自动重启或重新部署工作负载。这可能会导致配置在生产环境中运行过时,尤其是在处理动态值(如凭证、功能标志或环境配置)时。Reloader 通过确保您的工作负载与配置更改保持同步 - 自动且安全地弥合了这一差距。
特点
- 零手动重启:Secret 或 ConfigMap 更改后无需手动滚动更新工作负载。
- 安全设计:确保应用程序始终使用最新的凭据或令牌。
- 灵活:适用于所有主要工作负载类型,包括 Deployment、StatefulSet、Daemonset、ArgoRollout 等。
- 快速反馈循环:非常适合 Secret 或 ConfigMap 频繁更改的 CI/CD 管道。
- 开箱即用的集成:只需标记工作负载,让 Reloader 完成其余工作。
22. OpenTofu:一个 IaC 工具,Terraform 的一个分支
OpenTofu Joins CNCF: New Home for Open Source IaC Project
简介
OpenTofu 是一种基础设施即代码工具,可让您在人类可读的配置文件中定义云和本地资源,您可以对其进行版本控制、重用和共享。然后,您可以使用一致的工作流程在基础设施的整个生命周期内预置和管理所有基础设施。OpenTofu 可以管理计算、存储和网络资源等低级组件,也可以管理 DNS 条目和 SaaS 功能等高级组件。
OpenTofu 是一个开源的 Terraform 分支,旨在应对 HashiCorp 将 Terraform 许可证从开源改为 BUSL 的行为。
和 Terraform 的对比
- 在技术层面,OpenTofu 1.6.x 在功能上与 Terraform 1.6.x 非常相似。将来,项目功能集将有所不同。
- 另一个主要区别是 OpenTofu 是开源的,它的目标是以协作的方式驱动,没有一家公司能够决定路线图。
- 使用场景:
- 个人使用:OpenTofu 或 Terraform 用于个人用途,因为 BUSL 许可证对非商业用例没有限制。随着 Terraform 生态系统变得越来越不稳定,这种情况可能会发生变化,并且可能会切换到另一个许可证。熟悉 Terraform 的人在个人使用中使用 OpenTofu 不会有问题,因此至少在开始时不会有知识差距。
- 公司:公司在这种情况下会遇到更多困难。切换到一个新项目存在风险,但继续使用一个在没有警告的情况下更改许可证的项目风险更大。将 OpenTofu 移交给 Linux 基金会可以最大限度地降低这种风险,并且 OpenTofu 旨在在未来的版本中保持与 Terraform 的功能对等,这降低了技术风险。
23. LaunchDarkly:功能管理平台,不重新部署代码即可发布、控制和优化功能
简介
LaunchDarkly 是一款功能强大的特性管理平台,让开发团队能够在不重新部署代码的情况下安全地发布、控制和优化软件特性。LaunchDarkly 提供了一整套特性管理和控制的功能,帮助团队在软件开发生命周期的各个阶段更好地管理特性的发布和迭代。
功能管理是什么
从本质上讲, 功能管理允许开发团队实施功能标志:控制代码在生产中的行为方式的条件语句,而无需新的部署。 功能标志是“在运行时打开/关闭功能,而无需部署新代码”,可提供更好的控制并支持试验。
在最简单的形式中,功能管理允许公司将部署与发布分开。在功能管理之前,当公司部署软件更改时,他们的整个客户群都会立即看到最新版本。如果出现问题,影响可能是广泛且具有破坏性的。
使用 feature flags,公司可以部署软件,但逐渐增加其发布量,从只有 1% 的用户开始,然后是 2%,然后是 5%。如果出现问题,错误的“爆炸半径”会显著减少,只影响一小部分用户,而不是整个客户群。
特点
- 特性开关 (Feature Flags/Toggles)
- 渐进式发布 (Gradual Rollout)
- A/B 测试和实验 (A/B Testing and Experimentation)
- 组织和协作 (Organization and Collaboration)
- 集成 (Integrations)