

# 陈霏:RNN神经网络技术在助听声景分类上的运用探讨

-
深圳清华大学研究院副教授
-
“挚听”助听器创始人
-
加拿大皇后大学电子工程硕士
-
清华大学微电子专业博士
目前,助听器的使用效果并不理想,究其原因,最主要的一点就是:当听障患者置身于复杂多样的声音环境通常会使得助听器的性能出现很大的偏差,为解决此问题,要求助听器可以实时检测周边环境变化,并根据环境变化因子,及时切换内部参数配置。
HHTF
研究背景
我们所处的周围环境声音场景非常丰富,不同环境下的人们对于声音的需求又不尽相同。
比如餐厅:用户同时对降噪、方向性、语音清晰度均有需求,不想听到太大的噪音,要求降噪深度足够高。不想周围环境声音太吵,那就要求不能把所有方向的声音全部搜集进来,只接收前向的扇形区域声音;用户同时也希望听到人的声音,但是降噪深度过高又会影响助听器对语音的增益,从而影响声音清晰度。
声音场景变化是动态的,同时噪音也是我们需要关注的一个点,其呈现非稳态的特性。
那么这样就会带来一个新的问题,目前,助听器大多是在安静环境完成验配,这样验配好的助听器,在动态变化的声场环境中使用效果可能会不尽如人意。
总而言之, 想要获取最优秀的助听效果,助听器必须能够实时检测外界环境变化,并及时改变语音处理策略, 如:降噪深度、麦克风方向性、频响特性等。
如此一来,给用户带来的利好是非常多的:如减少重新验配的次数、提高环境适应性、减少手动操作步骤、提升用户验配体验等。
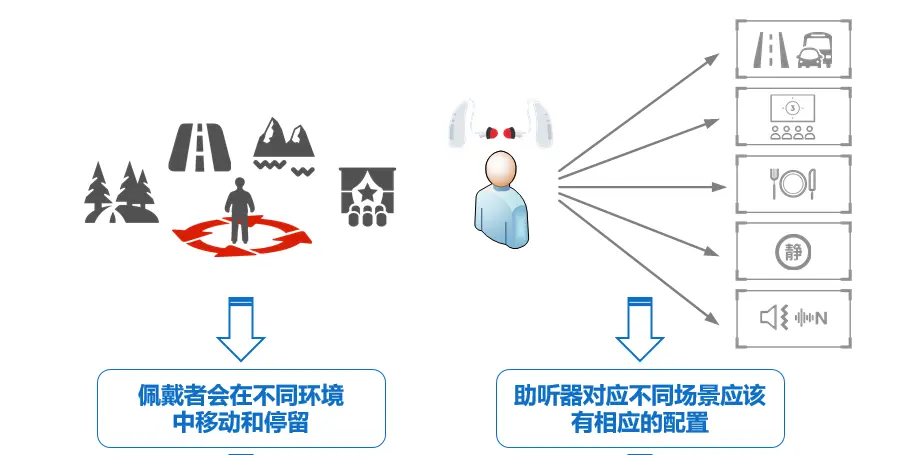
图 1 助听器智能切换场景示意图
如果可以实现实时声音检测、参数配置自动化和去人工的话,那么场景切换的适用性与便利性会大大提高,我们暂时称这种切换模式为声场智能切换模式。 通过在助听芯片中加入声场景分类算法为实现声场智能切换模式提供了可能。
HHTF
加入声场景分类算法的助听器算法整体结构概述
整个助听器对于声音信号的处理可以简单的描述如下:声音信号通过麦克风的接收转变为电信号,然后经过芯片内部的分析滤波器组、风噪消除、环境噪声抑制、啸叫抑制、多通道范围压缩、合成滤波器组等信号处理模块后,驱动受话器进行发声。
加入声场景分类模块之后,该模块负责检测、识别声音场景信号特征,识别完成之后给各个具体执行信号处理单元下发任务,完成降噪、增益、压缩、方向性等各方面的处理,然后输出适合当前场景的声音效果。
我们可以看出, 声场分类器更像是助听器整个系统的一位高智商的“谋士”,它不直接“冲锋陷阵”,而是提前根据实际情况制定“计策”,下发给风噪消除、环境噪声抑制、啸叫抑制等“将领”去攻城略地,达到“运筹帷幄之中,决胜千里之外”的效果。
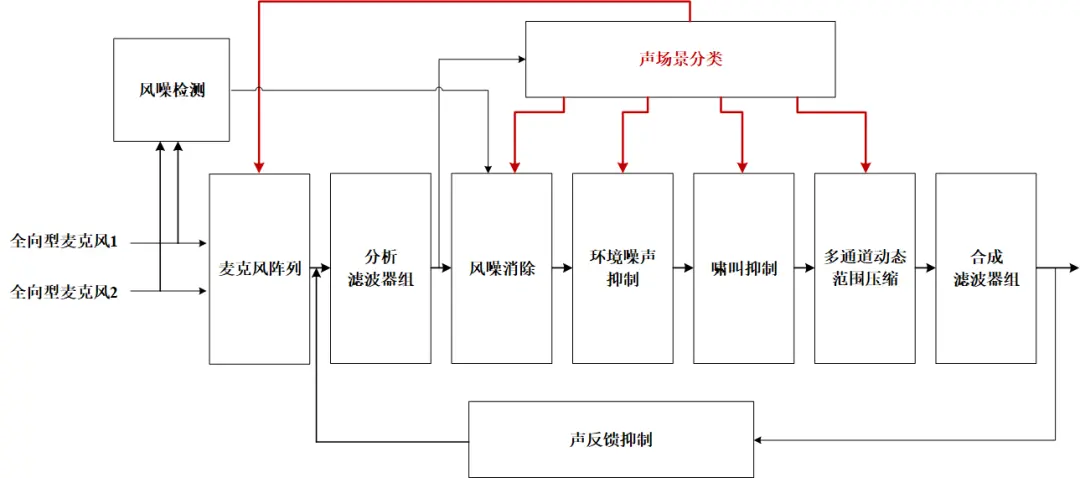
图2 加入声场景分类算法的助听器算法整体结构
HHTF
用于声场分类的几种算法
1
线性判别
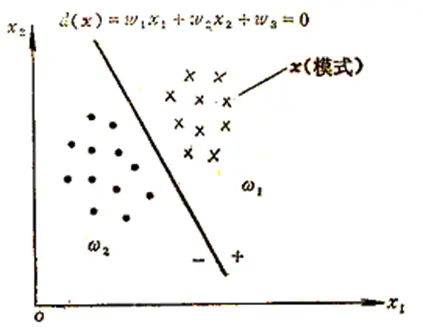
图3 线性判别示意图
如果特征向量仅由两个特征组成,那么每个特征向量就是二维平面上的一个点,墙体就是将它们隔开的一条直线。但在构建墙之前,每个特征向量必须知道正确的类。线性判别函数将直线定位在平面上,以落在直线错误一侧的特征向量最小均方差作为分类标准。
2
支持向量机
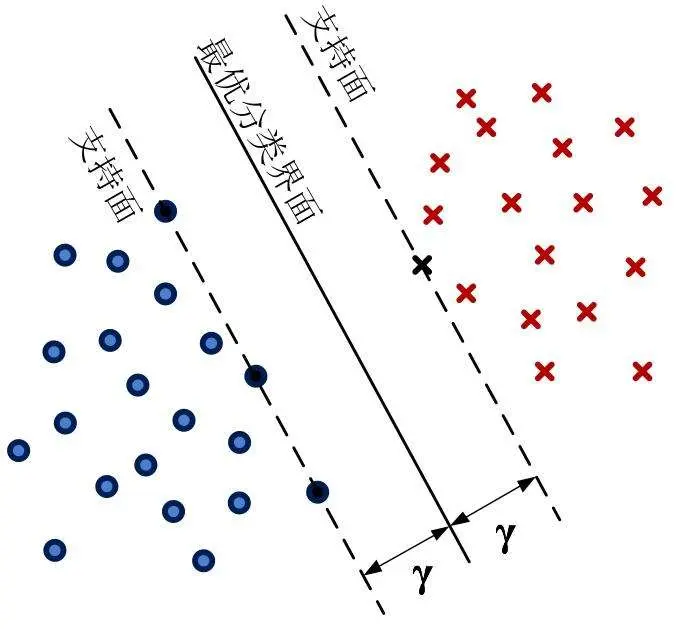
图4 支持向量机示意图
支持向量机是线性判别函数的基本思想的变体。目标是找到距离信号类边缘附近的特征向量最大的超平面,例如最大边缘。这些边向量称为支持向量,由于转换后的特征空间中建立类边界所需的计算量可能非常大,SVN分类器训练后,要求计算加权非线性组合,并将其分配给最接近的类。如果能够减少支持向量的数量,同时还能提供准确的分类,那么支持向量机可以在助听器中实现。
3
隐式马尔科夫链
图5 隐式马尔可夫链
马尔可夫模型描述了一个具有离散状态数的系统。马尔可夫模型给出了系统中保持某一状态的概率以及从该状态移动到任何其他可能状态的概率。
隐式马尔可夫模型(HMM)需要对特征向量序列及其相关的声音类进行训练。
HMM的训练可能非常耗时,但声音分类算法,一旦系统被训练,是足够高效的,可以应用在一个助听器中。
4
贝叶斯分类器
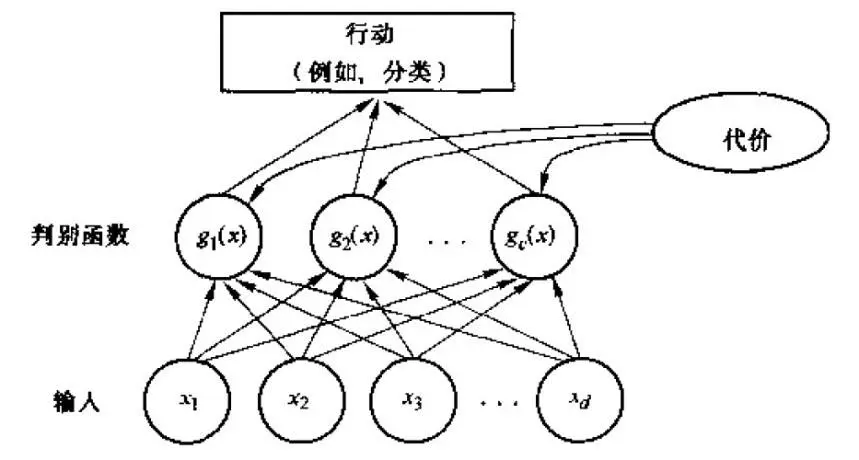
图6 贝叶斯分类器
贝叶斯分类器是从一个特征向量开始,并估计观察到的特征来自每一类的概率,然后选择概率最高的类。
贝叶斯分类器的训练包括确定与每个类相关的特征向量的概率分布,以及确定每个类出现的概率,它的最佳性能是在最准确的概率分布和先验假设下获得的。
分类器将使用从助听器用户的听力情况中获得的片段上进行训练,并且也将获得每种情况发生的概率。
5
神经网络
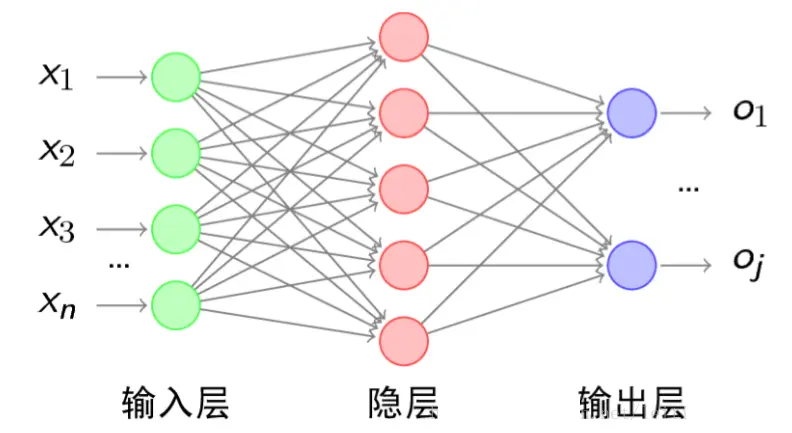
图7 神经网络示意图
神经网络的最初设计动机是参考的大脑的神经结构。大脑中有许多层神经元,其中一层神经元的输出形成下一层神经元的输入。嵌入神经网络的非线性转换允许在信号类之间形成任意边界。区分不同类的边界可以是超空间中的复杂曲线,也可以是由线性判别式产生的线性边界。
神经网络的一个优点是,训练网络的算法相当简单,非线性的形式可以从训练数据中学习,训练成功后分类算法足够高效,即可以在助听器中实现。
以上各种算法各有优缺,我们通过比对之后决定选择神经网络这一务实、可行的方法:线性判别参考特征较少,对于简单的环境判别效果,但是在复杂环境判别、多特征的条件下力不从心。
后来,支持向量机以及隐式马尔可夫链、贝叶斯分类器的模型被相继提出,相较于之前传统的模型场景的误判率都有所下降。其中隐式马尔可夫链、贝叶斯分类器采用一种理想化的模型去构造算法。预先假设我们对于每个声场的特征已了如指掌,对于特征值的概率分布,以及特征值之间的联合概率分布也相当了解,通过搜集到的声场特征参数,比对其落在哪个特定的概率范围内,从而反推具备该声场特征参数的声场属于哪种类型。这样的模型构建对于助听器声场分类算法并不合适。
同时特征值变多之后,所需的芯片算力也因此大大增加。首先,我们无法提前准确预知各个声场的特征参数及其概率密度,其次,大量的建模、比对运算、反向溯源同样要求芯片具备极高的算力,对于目前助听器的芯片而言,这样的算力显然是无法达到的。
近年来,随着机器学习的发展,神经网络在各个领域充分应用,简单来讲,神经网络就是在模仿我们的大脑工作:不需要提前有确定的解析式、不需要提前了解各个声场环境的特征参数性质,但不影响其对于声场判别的准确性。
我们可以简单的把神经网络理解为一个黑匣子,输入和输出具备确定性的映射关系,好比我们的大脑:看见刺眼的光芒,判断眼睛会受到伤害,然后发出指令,闭上眼睛。 神经网络的构造类似于我们大脑的神经链路构造:分层多节点,节点与节点之间互联,一层可能包括多个节点,如果层与层之间的节点直接连接,那么整个神经网络就只是一个单纯的线性系统,而神经网络要处理的问题往往都是非线性问题。
因此,层与层之间需要引入一个函数,这个函数可以实现数据之间的非线性运算,也就是激活函数。
HHTF
神经网络为内核的ASC算法框架
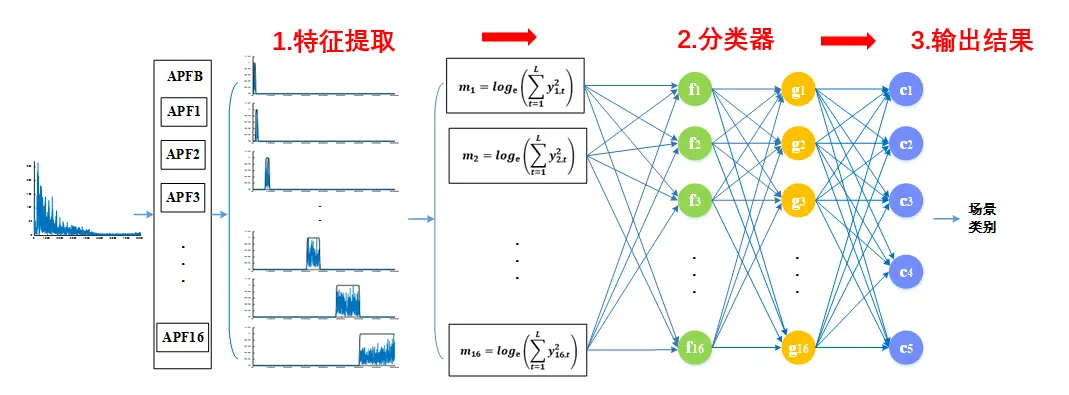
图8 神经网络为内核的ASC算法框架
想要构建以神经网络为内核的ASC算法框架,我们需要“三步走”:首先进行特征提取,将具备一定特征的声音信号输入到系统内部,给系统一个原始的有效“刺激”;然后根据信号特征进行场景分类,此时,信号进入隐藏层,隐藏层的层数根据算法精度以及算力支持的复杂度来决定,通过多层筛选判别之后,到输出层,输出判定出来的场景类别。
那么,常见的声学特征有哪些呢?大的分类可分为 三类。
-
时域特征:时域幅度谱标准差,时域通道能量和过零率等;
-
频域特征:梅尔倒谱系数(MFCC),功率谱密度和delta谱系数;
-
汉语言特有特征:基频,声韵母时长,静音段,音强以及语调短语边界等等。
神经网络类型也有许多,常见的有DNN(多层感知机)、CNN(卷积神经网络)、RNN(循环神经网络),考虑到音频信号处理的特点,RNN是最为合适的神经网络实现办法。
HHTF
RNN神经网络
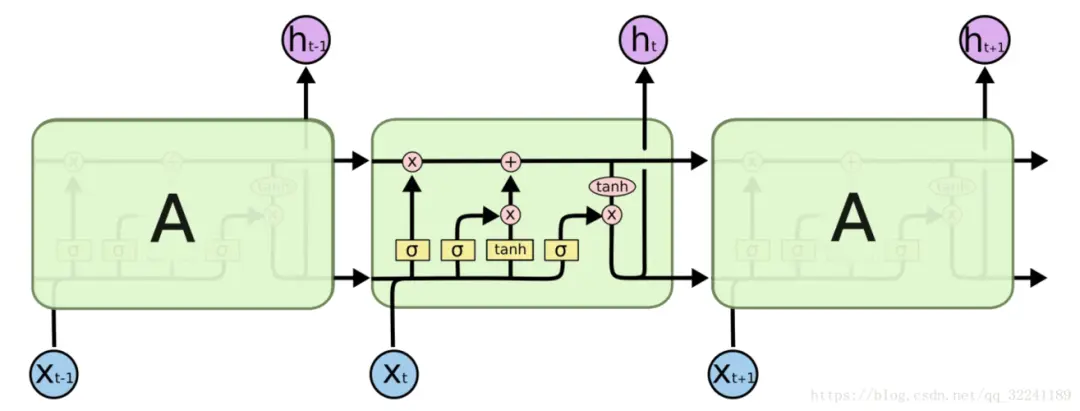
图9 RNN神经网络示意图
循环神经网络(Recurrent Neural Network,RNN)是一种特殊的神经网络结构, 它是根据 “人的认知是基于过往的经验和记忆” 这一观点提出的。它不仅考虑本时刻的输入,而且具有对前面时刻内容的 “记忆”功能。
循环神经网络(RNN)的特点是擅长处理类似时间序列这类数据,可以应对DNN所没法解决的自然语言处理、语音识别以及手写体识别等问题,是一种专门处理序列数据的深度学习网络模型。
对于助听器而言,输入都是音频数据,这种声学参数都具有一定的时间序列相关性,数据中的上下文特征是其中包含的一个重要信息,因此使用RNN去处理助听器的输入进行声音场景分类是一个合理的选择。
神经网络构建完成之后,我们需要对其进行训练,使其可用。训练流程如下:首先,选择收集常见场景中的随机音频,切分成等时长的音频切片,作为原始的训练数据。(安静、户外、交通、餐厅、音乐五种场景。);将不同场景的音频输入神经网络,这些音频都具备特定的声学特征,神经网络的输入实际上是将音频数据经过特征提取算法得到的数据,送入到神经网络后最终输出识别结果。
对于每一次的神经网络的输出,我们通过设定一个损失函数,这个损失函数可以表示输出值和理想值之间的差异,这个差异结果将作为完善网络参数的参考标准,通过这个步骤不断完善网络参数,直到这个损失函数不再减小或趋于平稳,这样我们就完成了对神经网络的训练; 网络参数优化和确定后,最为固定的参数将被写入到硬件中,数据保持不变;最后,不断让输入音频数据送入到已经写好的网络中,网络的最终输出节点会给出相应分类的结果,这样就完成了神经网络的推理。
HHTF
通过智能手机辅助实现的神经网络内核ASC
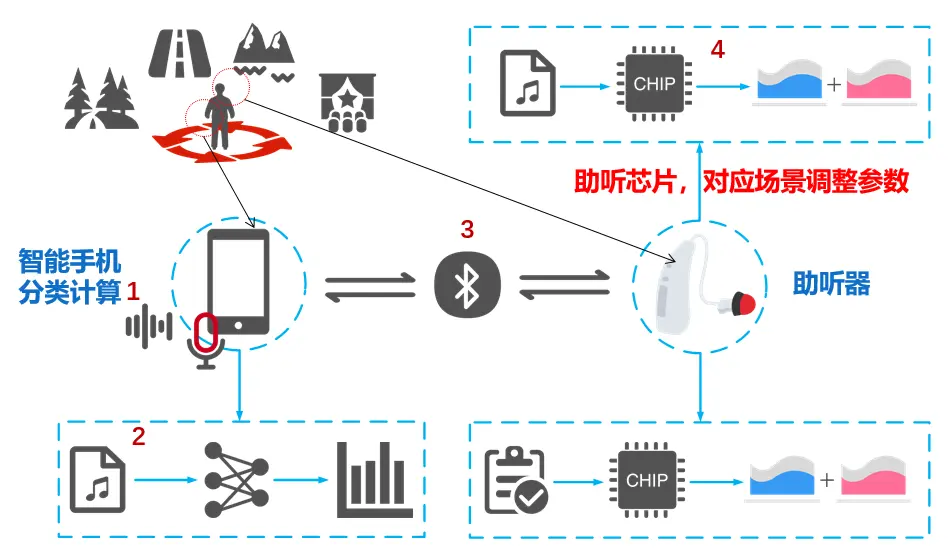
图10 智能手机辅助实现的神经网络内核ASC
当下,智能手机的算力足够强大,足以支撑整个神经网络的运算包括特征的提取和分类。 通过手机采集周围声场环境声音,手机APP通过神经网络代码运算,输出声场判断结果,并且根据事先对该场景下参数配置情况,通过BLE将该指令下发到助听器端,改变助听器内参数配置,实现了智能化的场景识别与切换。表7-1为不同场景下的参数配置方案。
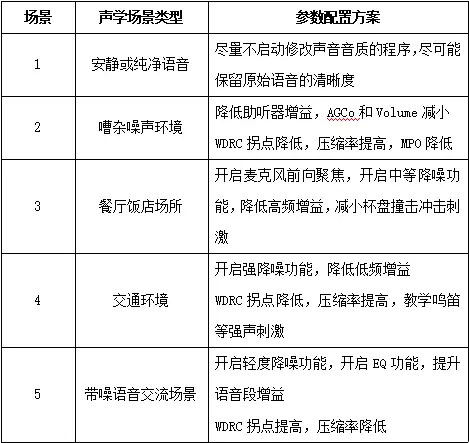
表1 不同场景下参数配置情况
HHTF
未来——基于嵌入式芯片的声音场景分类
我们已经实现了利用手机辅助的神经网络内核ASC,验证了智能场景切换的可行性,但是,如果沿用这个方法,用户在使用助听器时就不可以脱离手机了,这显然不是一个最优的解决方案。 最优方案是在助听器芯片进行声场分析判别,并自主配置不同参数。
深圳市智听科技实验室承接了政府的用于神经网络加速核芯片项目。该项目主旨就是解决嵌入式系统算力不够的问题, 创造出低功耗、低延时的嵌入式芯片系统。目前,可行的一个办法是 做加速核,把算法做固化成为芯片的一部分。 这样一来,数据集、算法训练、算法固化、推理都有一个个算子进行运算,这些复杂的运算就不需要在CPU内进行,大幅提高芯片的运算速度,同时降低功耗、延时,让基于嵌入式芯片的声音场景分类成为可能。
HHTF
总结
不同声音场景下语音处理策略的挑战是确定何时以及如何调整助听器声电处理参数,以优化清晰度或音质,基于神经网络的分类方法提供了一种智能化的可行解决方案,未来的研究方向是将声音客观分类与用户主观偏好的自适应学习结合起来,创造出高可用,高品质的助听器,造福更多的听损人群。
HHTF
智听科技简介
深圳市智听科技成立于2017年, 是一家 致力于智能听力检测和智能化助听系统研发、制造和服务的医疗器械公司。 公司在清华大学和业界知名专家教授支持下,多年在芯片技术、语音信号处理算法、人工智能学习等方面进行工程化探索。目前有团队成员40多人,拥有自己独立的研发基地与工程生产部门。
旗下品牌“挚听”以“让挚爱的人听见”为愿景,通过自主研发创新型助听器,开创性地实现“智能化自主验配”技术,用户仅需要手机App即可自行完成在线“验听验配”,制定个性化助听方案。
联系人:张建军 18610022299 。
现场互动Q&A
Q:
您觉得最后多大的模型可以做到RNN在耳机端实现,MB?KB?
这个跟耳机端所使用的芯片平台算力和存储能力相关,规模越大越吃资源,但场景类型会更多、识别准确率会更好。
Q:
如何理解现代助听器的参数信息——每秒500次扫描。实现的难度有多大?
如果按照16kHz的采样率,每种采样1万6千次,如果把32个采样点形成一个语音处理帧,那么一秒钟可处理500帧,所以在语音分帧的这个尺度级别,一秒钟扫描是能够实现500次。
Q:
目前场景识别的正确率是无法实现100%的,场景识别出现错误时有何应对方案?
在识别出新场景后,不进行声电参数的立即完全切换,而是等第二次或第三次的识别的结果出来后进行多次联合确认,大幅降低错误判断概率。
Q:
助听器因为要考虑功耗问题,计算速度比不上Linux等电脑,有没有这样的考虑:用Linux等高性能电脑实现语音的处理,然后通过无线发送到助听器或耳机;助听器,耳机只做语音的无线接收和播放即可。
我们在中央设备处理和耳侧声电响应方面也有发明专利。但目前业界技术水平的限制是中央设备和耳侧设备在无线音频通信中会带来的延时问题和功耗问题。


扫码查看回放
健康听力技术论坛
往期回顾

随着TWS耳机的飞速发展、辅听产品技术的日新月异,以及美国FDA发布OTC助听器草案的政策驱动下,未来五年,助听产品和辅听产品的跨界与整合将成为主流趋势。
在行业变革时代背景下,北京听力协会主办了「健康听力技术论坛」,长期为大家提供发声的平台。论坛持续以每期两位嘉宾、不固定更新上线的形式长期举办。
期待声学领域、TWS领域、辅听及助听领域的专家、学者,以及产业供应链上中下游多方代表积极参与论坛并发表演讲。我们希望通过论坛的举办,搭建行业平台,促进产品变革,推动技术发展,为轻中度听损人士及健听人士提供更合适的听力保护及听力辅助方案,实现「全民健康听力」这一终极目标。

作者:陈霏
编辑:皇甫甜
排版:皇甫甜



