

# 梁维谦:深度学习技术在听力学研究中的应用初探

-
集美大学海洋信息工程学院副教授和硕士生导师
-
全国人机语音通讯学术会议常设机构委员会委员
-
清华大学电子科学与技术专业工学博士
听力受损是一种广泛的谱系性障碍,有先天失聪、中年听力突然丧失及年长听力逐渐下降。研究表明多数听力障碍与耳蜗受损有关,一般表现为较差的听阈、响度重振和频率选择性降低等。
2021年10月美国FDA发布《Medical Devices; Ear, Nose, and Throat Devices; Establishing Over-the-Counter Hearing Aids》提案,将建立一个新的OTC(Over-the-Counter)助听器类别;其目的在于采用人工智能等新技术提高美国听力下降者的助听技术使用率和满意度,降低获取听力技术的成本。
HHTF
助听技术使用率低的主要原因
目前助听技术使用率低的主要原因之一是现有助听技术未能显著提高听力受损者的听音清晰度和可懂度,主要包括:
-
在听觉模型(Auditory Model, AM)方面主要采用相对粗略的滤波器组形式的耳蜗感知模型,如Mel频标与Gammatone滤波器组等;
-
在声信号处理方面主要采用基于滤波器组分析的短时频谱的声增益“压缩与放大”控制,如宽动态范围压缩、自动增益控制、增益均衡等;
-
在听力处方(Hearing Aid Prescription, HAP)方面主要采用听力学实验总结的“从听力图到时频增益”的经验公式,如NAL-NL2/NAL-NL1 /NAL-RP、DSLv.5、CAM2、FIG6、POGO II、IHAFF等,医生或听力师还需干预“精细”调节。听觉模型是声信号处理与听力处方所依赖的基础。
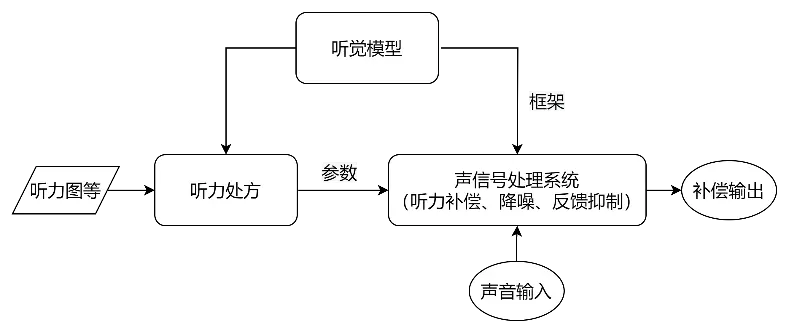
听觉是人体中最复杂的通路之一,它可以被看成是线性与非线性过程的“完美”组合。人耳听觉通路包含耳廓、耳道、鼓膜、鼓室和听小骨、耳蜗、听神经等,其中耳蜗最为复杂和重要,听力下降也多表现为耳蜗受损。
这种复杂性在很大程度上归因于内耳的耳蜗,其对特征频率的选择性、纵向耦合和声强压缩等导致了高度非线性的行为。典型的非线性表现有:
-
耳蜗兴奋模式:不同频率的声音在耳蜗上有不同的共振峰值点;
-
非线性声强响应:对强声抑制,对轻声增强等;
-
频率选择性:对低频声信号分辨率低,对高频声信号分辨率高,对轻声信号分辨率高等;
-
噪声掩蔽语音现象:噪声水平的提高会恶化感知频率选择性、时间分辨率和语音清晰度;
-
调幅现象:对瞬时快变的声音信号进行衰减。
HHTF
主流的耳蜗听觉模型
基于医学伦理要求,耳蜗听觉模型都是通过动物解剖实验与人类心理声学实验的数据总结出来的。目前,主流的耳蜗听觉模型主要有:
-
并行滤波器组,如Gammatone、Gammachirp、DRNL(Dual Resonance Nonlinear,双共振非线性)、Zilany等。
-
级联滤波器组,如CARFAC(Cascade of Asymmetric Resonators with Fast Acting Compression, 具有快速压缩的非对称谐振器级联),能基本仿真上述几乎所有的耳蜗非线性特性。
-
非线性传输线模型(Nonlinear Transmission Line,NTL),如(Verhulst et al.2018),能较好地仿真上述几乎所有耳蜗非线性特性,尤其对轻声响应预测效果好,能够模拟耳声发射现象,适用频率范围宽,计算复杂度较高。
-
生理模型,如Saremi,能将仿真结果与细胞级现象相关联,计算复杂度一般。由于计算资源的限制,现有助听技术大都基于并行滤波器组形式的耳蜗听觉模型理论。


Saremi, A., Beutelmann, R., Dietz, M., Ashida, G., Kretzberg, J., and Verhulst,S. (2016). A comparative study of seven human cochlear filter models. The Journal of the Acoustical Society of America, 140(3):1618–1634.
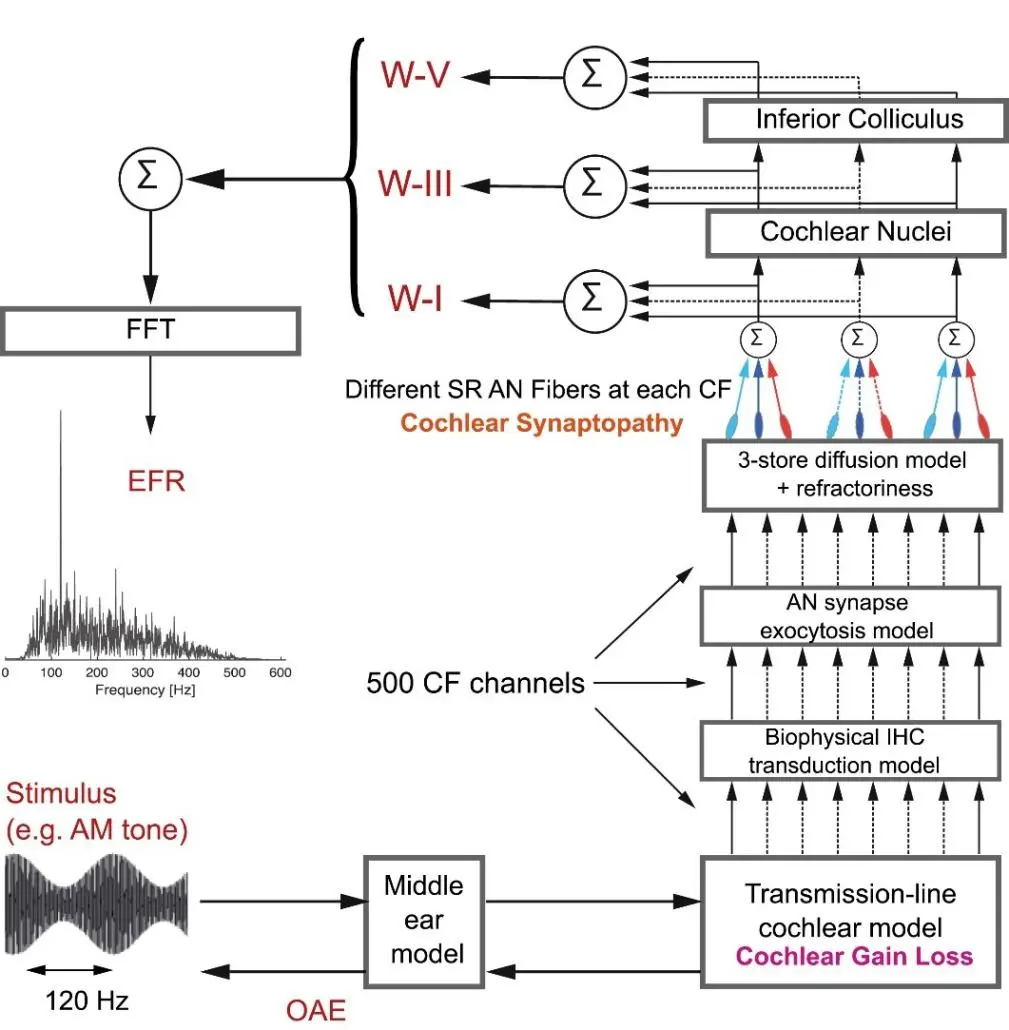
Verhulst-NTL(Verhulst et al. Nonlinear TransmissionLine)模型总结了诸多耳蜗力学研究成果,仿真了从中耳到脑干的听觉过程,考察了听觉神经、耳蜗核和下丘脑神经元以及人类外周听力的生理相关性,如听脑干反应(ABR)、包络跟随反应(EFR)和耳声发射(OAE)等。
Verhulst-NTL模型中,声信号首先通过一阶中耳带通滤波器,然后进入传输线(Transmission Line,TL)耳蜗模型,该传输线模型可模拟人类耳蜗效应:一部分信号反馈回中耳带通滤波器模拟OAE调谐,另一部分信号模拟耳蜗的非线性压缩特性后输出特征频率(Characteristic Frequency,CF)通道信号,CF信号再传递到内毛细胞(inner-hair cell,IHC)换能模型和听神经突触胞外分泌模型,再传递到3-store扩散模型、耳蜗核和下丘脑来模拟听脑干反应输出ABR波,ABR波再经过加权和傅里叶变换得到EFR激励调制频率相关的响应分量。
该模型还可以通过在传输线模型基础上改变耳蜗增益来模拟外毛细胞损伤引起的听力下降情况,通过改变内毛细胞模型和听神经模型之间的连接数量和类型来模拟耳蜗突触病变。
听力下降主要由耳蜗包细胞和听神经病变引起。相比于基于滤波器组的听觉模型,TL模型的级联结构解释了耳蜗行波中BM和周围流体耦合结构产生的现象,这些现象包括双色抑制,不对称的滤波器形状和BM响应中的相位变化等。TL模型的瞬时非线性(频域中BM导纳的极点位置移动)解释在测量的BM脉冲响应中观察到的压缩非线性行为。
Verhulst, S., Alto`e, A., and Vasilkov, V. (2018). Computational modeling of the human auditory periphery: Auditory-nerve responses, evoked potentials and hearing loss. Hearing research, 360:55–75.
HHTF
深度神经网络在计算听觉领域的应用
近年来,深度神经网络(Deep Neural Network, DNN)开始在计算听觉相关领域得到成功应用,例如语音识别、语音合成、语音增强、声源分离和耳蜗听觉建模等。
-
文献1(Lei,I.M.,Jiang,C.,Lei,C.L.et al.3D printed biomimetic cochleaenand machine learning co-modeling provides clinical informatics for cochlear implant patients.Nature Communications 12,6260(2021))提出了3D打印的仿真耳蜗,采用DNN对仿真耳蜗的输入-输出的刺激电信号进行耳蜗生物电学建模,来解释人工耳蜗植入患者的电场成像剖面,预测患者体内的耳蜗组织电阻率等参数,用以指导人工耳蜗植入治疗。
-
文献2(Mondol SIMMR, Lee S. A Machine Learning Approach to Fitting Prescription for HearingAids.Electronics.2019;8(7):736 )则从听力处方角度出发,提出了以NAL-NL2为参考处方的基于DNN与迁移学习的听力验配方法;该方法可实现从听力图输入到补偿增益输出;在声信号处理方面仍然没有摆脱声增益“压缩与放大”控制的框架,但对于DNN技术应用于听力处方方面提供了启发。
-
文献3(Healy E.W., Tan K., Johnson E.M., and Wang D.L. (2021): An effectively causal deep learning algorithm to increase intelligibility in untrained noises for hearing-impaired listeners. Journal of the Acoustical Society of America, vol. 149, pp. 3943–3953)针对助听系统的实时性要求,提出一种有效因果的深度学习算法,用于分离语音和背景噪声,提高语音清晰度。该算法使用过去时间和人类感知机制可容忍的未来时间的复数频谱信息(包括声音信号的幅度和相位信息)作为声学特征,使用一种门控卷积循环网络作为深度学习模型实现从带噪语音到降噪语音的映射,通过大量的噪声数据进行训练,并使用未经训练的背景噪声进行测试,以验证算法的有效性。该方法虽未涉及听力补偿问题,但通过基于DNN的实时降噪算法探索了DNN框架下的听力补偿算法的可能性。
HHTF
设想:使用DNN建立耳蜗听觉模型
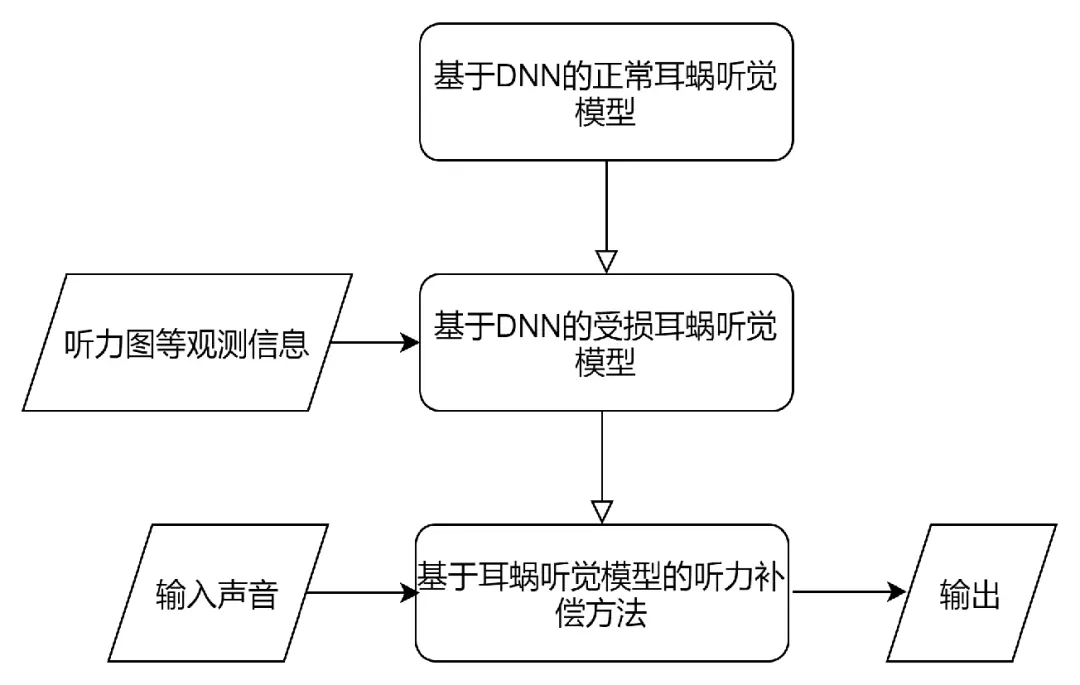
助听系统中,以耳蜗听觉模型为理论基础指导听力处方和声信号处理系统的设计。听觉模型对人耳听觉感知机理进行仿真建模。这里首先尝试使用DNN模型实现从正常耳蜗听觉仿真模型的输入到输出的建模(Normal Hearing DNN, NH-DNN)。
听力受损情况因人而异,耳蜗仿真模型,如Verhulst-NTL,也可仿真听力受损情况;参考NH-DNN,我们也可以尝试建立听觉受损DNN模型(Hearing Impaired DNN, HI-DNN);考虑到系统实时性要求,如何快速建立因人而异的HI-DNN模型呢?
目前的听力处方都是基于并行滤波器组的耳蜗听觉仿真模型,实现从听力图等的输入到时频增益的输出;人们也尝试使用DNN模型替代听力处方(如NAL-NL2)实现从听力图到时频增益的映射;能否基于其他更为合理的听觉受损仿真模型(如Verhulst-NTL)设计听力处方呢?
若可行,如何使用DNN技术对上述新的听力处方建模呢?能否使用DNN模型从NH-DNN和HI-DNN生成针对个性化听力下降的听力补偿(Hearing Prescription,HP)模型(HP-DNN)呢?针对上述问题,这里进行了一些初步的实验和讨论。
1
建立NH-DNN耳蜗听觉模型
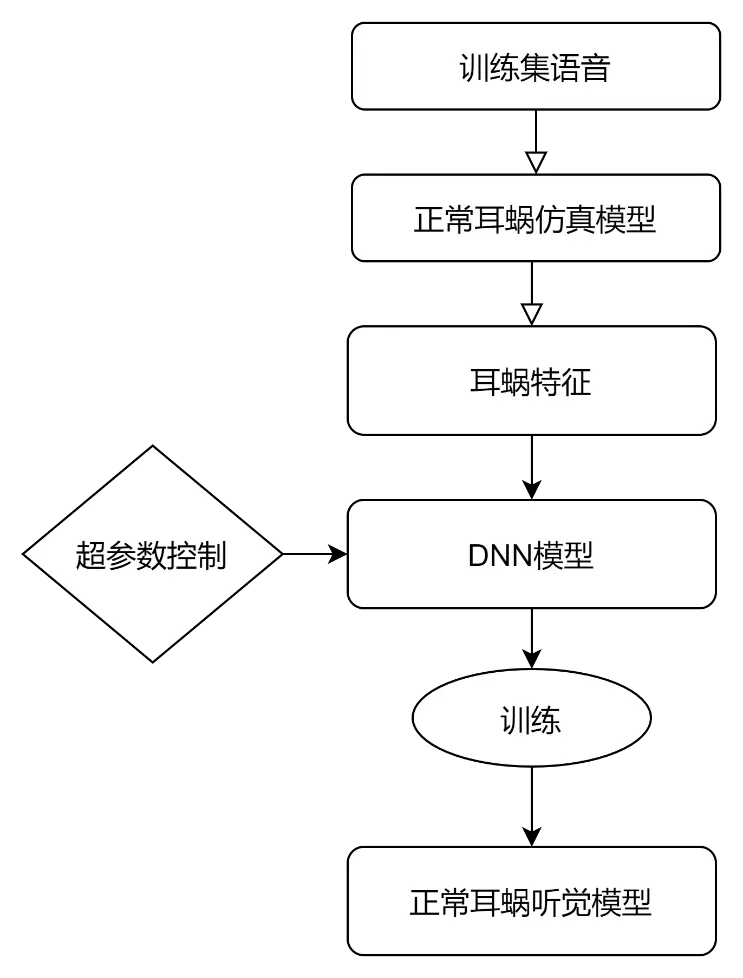
寻找一种能够解释高度非线性耳蜗的DNN表示。首先训练集语音输入Verhulst-NTL耳蜗听觉仿真模型得到耳蜗特征输出,采用DNN模型替代上述耳蜗听觉仿真模型用以训练NH-DNN模型。
NH-DNN耳蜗模型结构应能够再现参考的Verhulst-NTL模型在相同输入声音刺激时捕捉到的CF信号。这里选用在语音处理领域取得诸多成功的卷积神经网络(Convolutional Neural Networks, CNN)进行尝试。
CNN至少包含两种基本类型的层:卷积层和池层。卷积层通过类似滤波器组的卷积运算和非线性处理进行特征映射,池层合并语义上相似的特征。
一个完整的CNN架构一般由多个的卷积层、非线性层、池化层和全连接层,这些层可以看作是标准的前馈网络。可通过梯度的反向传播训练各卷积层的权值参数。
我们选择CNN仿真耳蜗建模的主要原因是CNN卷积(滤波器)架构与耳蜗基底膜滤波效应相关联;CNN的本地连接、池化、分层结构和共享参数等特点适合处理声音信号。训练集和测试集语音数据来自于测听音、MSTMs和TIMIT语料。
-
测听音包括单频纯音、窄带噪声、调幅纯音、调幅窄噪和调频纯音。
-
MSTMs(http://www.96think.com.cn/product/MSTMs.htm)作为有调语言,所有选词(句)既要符合日常生活规律,又要符合特别测听的要求和难度;符合普通话语音学规范要求,单音节和双音节词表则采用了韵母、声母和声调的三维平衡;在听力学研究中被广泛采用。
-
TIMIT(https://catalog.ldc.upenn.edu/LDC93S1)作为无调语言(英语)代表,包含630位美式英语8种主要方言的说话人阅读10个音素丰富且上下文语义无关的句子,适合于言语测听需求。根据Verhulst-NTL模型的格式要求,对上述语料进行采样率和声压级的格式化处理。
采用Pytorch作为DNN模型开发工具。
通过实验对比Verhulst-NTL和NH-DNN模型输出的特征频率参数的误差和QERB值,讨论了NH-CNN模型的学习速率、层深度、卷积过滤长度和非线性激活函数等超参数。
在训练过程中,根据训练误差曲线控制学习速率,以免太小或者太大的学习率导致产生次优解。
权衡考虑层深度的设置,层深度增加会增加模型的表示能力,但也会明显增加模型的时间和空间成本。
权衡考虑卷积层过滤器的数量和长度的设置,增加过滤器长度将增加模型的时间和空间成本。
大多数基于神经网络的生理模型都采用修正线性单元(ReLU)作为激活函数,这里在选择激活函数时考虑到耳蜗的非线性声强响应特性,也尝试了tanh 激活函数。
通过实验,选定的NH-CNN模型参数:学习速率:0.0001,层深度:6 layers,卷积过滤长度:127,非线性激活函数:tanh。部分实验结果如下图所示:
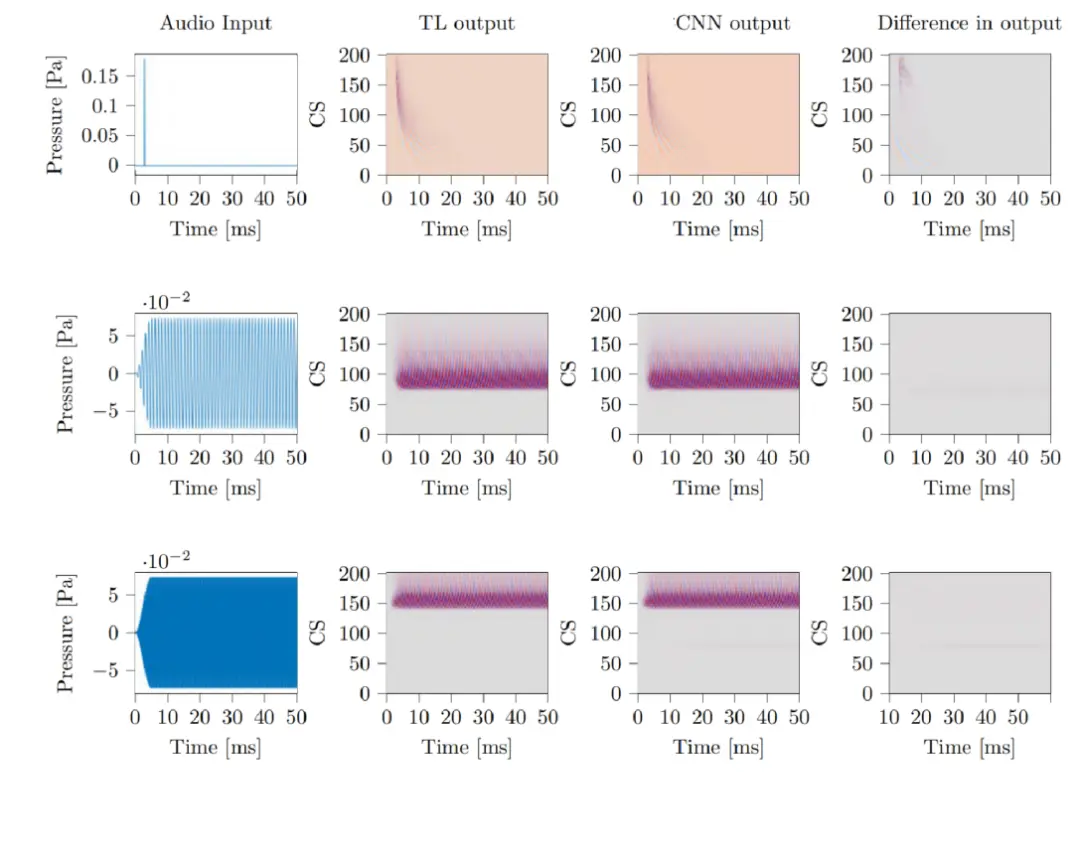
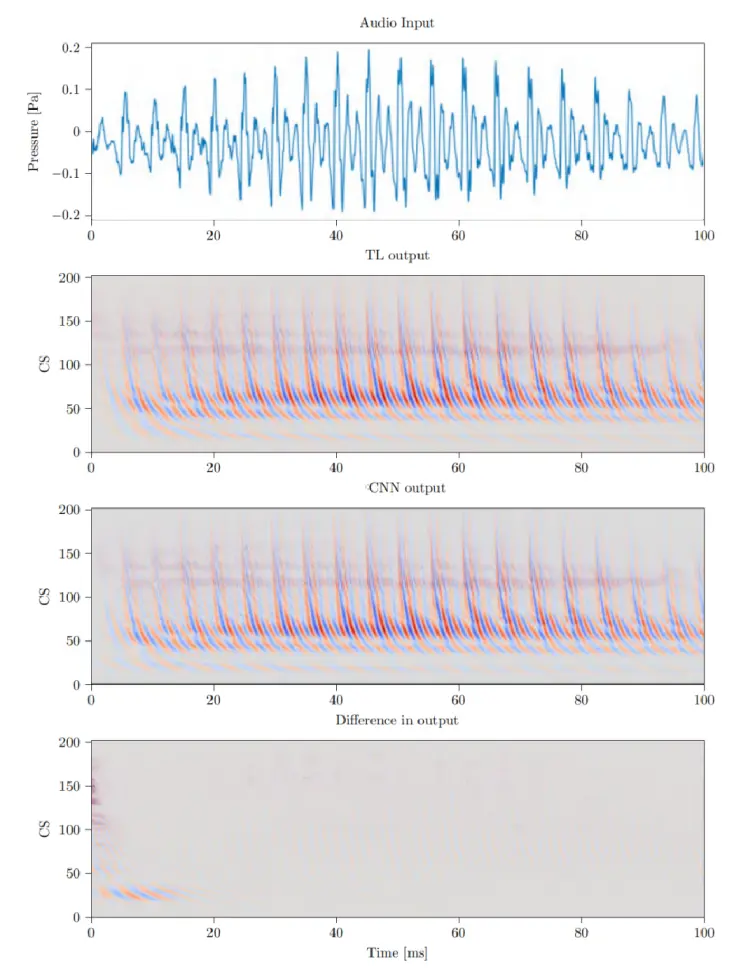
2
建立基于DNN的受损耳蜗听觉模型(HI-DNN)
对每个患者不同的听力受损情况进行实时建模分析,需要寻找一种能够“快速”解释个性化听力受损的DNN表示方法。
参考NH-DNN模型的训练过程,首先根据听力图等听损相关的观测数据调整Verhulst-NTL模型参数得到听力受损的Verhulst-NTL模型(HI-Verhulst-NTL),采用样本数较少的迁移集数据通过HI-Verhulst-NTL模型得到听力受损的特征频率信号,在NH-DNN的基础上通过迁移学习技术快速训练得到HI-DNN模型。
有关耳蜗非线性声音感知及与听力障碍相关性的听力学研究表明:外毛细胞(Outer Hair Cells,OHC)受损的人在听觉方面会出现听力阈值变差、响度重振和频率选择性降低等问题。
OHC受损可表现为立体纤毛损伤、OHC体的实际损失或OHC增益特性的代谢减少等,这些都最终体现到耳蜗增益的下降。
Verhulst-NTL模型可以通过增加BM滤波(BM导纳极点位置)的带宽和降低耳蜗增益模拟这种OHC损失的影响,通过改变连接内毛细胞模型和听神经模型之间的听觉神经纤维的数量和类型来模拟IHC损失的影响。
对于给定的听力阈值观测数据(即听力图),如老龄人口常见的平坦型和高频陡降型听阈曲线,Verhulst-NTL模型都提供了相应的BM导纳极点配置,得到HI-Verhulst-NTL模型,用以模拟个性化的听力受损情况。
由于听力障碍者仍然具有与正常听力相似的听觉特性,因此捕捉这些特性的主要特征可以被转移。假设NH-DNN和HI-DNN是具有高度相关性的, NH-DNN模型的结构、权重和参数可用于形成一个新的预测不同听力受损情况下HI耳蜗反应的HI-DNN模型。
因此可以采用迁移学习技术以一个已经训练好的NH-DNN模型作为构建另一个DNN的基线,通过较少的迁移集数据训练得到HI-DNN模型。迁移学习还可以节省特征提取时间,只需要收集和处理有限数量的迁移训练集,同时也可以节省训练时间,因此也满足个性化听损模型的及时性要求。
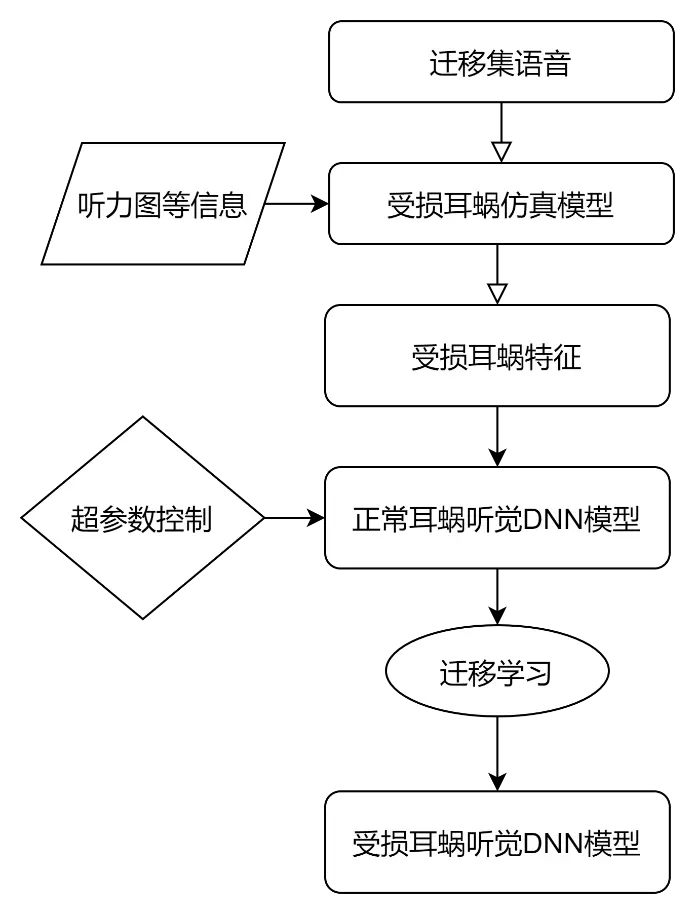
例如针对高频听力下降型 slope35的实验结果如下图所示:
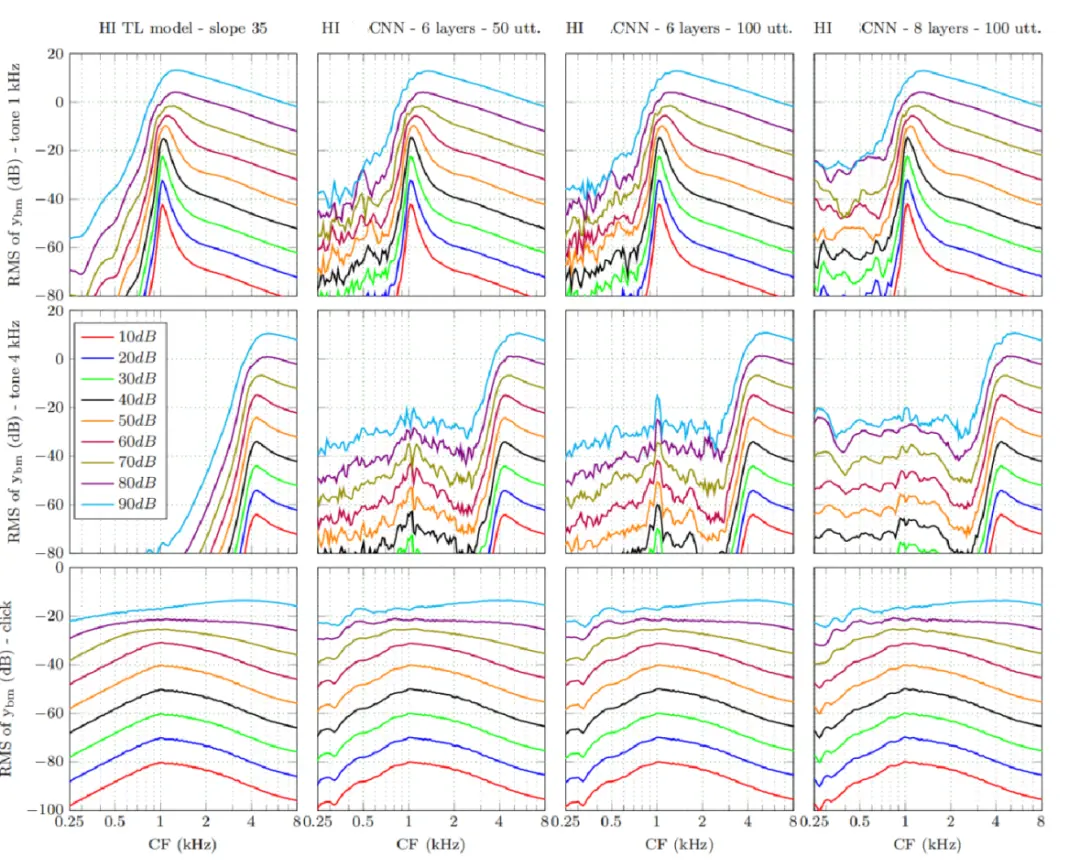
3
建立基于DNN的听力补偿模型(HP-DNN)
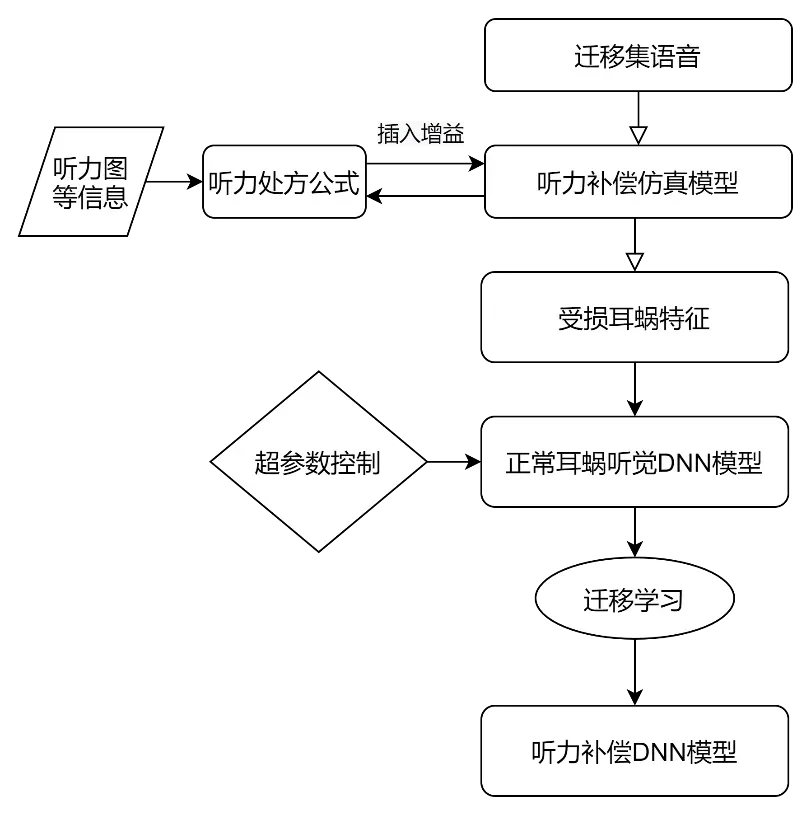
参照HI-DNN的建模过程,可否尝试在听力图和Verhulst-NTL模型之间引入听力处方公式,通过听力处方公式输出的插入增益调整Verhulst-NTL模型参数得到听力补偿模型(HP-Verhulst-NTL),同样采用迁移集数据通过HP-Verhulst-NTL模型得到听力补偿的特征频率信号(HP-CF),在NH-DNN的基础上通过迁移学习技术快速训练得到HP-DNN模型?
对于给定的听力受损情况,对比HP-DNN和HI-DNN模型输出的特征频率信号,评价听力处方公式的有效性,并尝试对听力处方公式输出的插入增益进行修正和调整。这可能是一个研究方向,还有待进一步实验讨论。
HHTF
总结:初步讨论与实验
这里只是对基于深度学习的耳蜗听觉模型进行了初步的讨论和实验。目前也没有想清楚它可能的应用场景,但觉得应该是一个可能的发展方向。
其中对于听觉仿真模型的介绍也比较粗浅,感兴趣的读者可以到https://www.amtoolbox.org/网站进行深入了解。从听觉仿真模型到基于数据的DNN模型需要一个过程。读者可以看到上述讨论所用的数据都是仿真数据,而非真实数据。真实数据很难获得。
未来随着有效的真实数据越来越多,相信基于DNN的听觉模型效果会越来越好的;基于DNN的听力处方和听力补偿方法也有可能得到应用。随着数据、算法和硬件资源的不断进步,基于DNN的助听器系统有可能在不久的将来得到应用。
现场互动Q&A
Q:
如何评价面向听障患者的语言增强的效果,一般增强算法都是面向正常听力者的?
这个问题可能无论你是做深度神经网络,还是用传统的信号处理滤波器方式,本身的语音增强,就看你的应用的目标是什么?语音增强是一个与应用目的相关的技术。是面向嘈杂环境下的语音通信军事应用,还是用于噪声环境下的语音识别,还是用户助听器的输入。应用差异决定了增强算法优化目标的差异。从原理上来讲大家所有采用的方法基本都是类似的。 但是在算法参数的细节调整上会有差别。 以助听应用举例,不能把噪声全部都抑制干净比较好,因为这种“噪声”对于助听患者来讲也是真实环境的一部分。算法把噪声都消除掉了,用户对环境音的感知能力就会降低。助听应用领域 通常会相对弱化语音增强的效果, 弱化的考虑其实也是对助听患者的一个保护,同时噪声消除效果越好,也可能意味着对语音的损伤程度也会越大,你的增强效果弱一些,你的舒适度好一些,本身它也是一个应用的平衡点。
Q:
请问利用深度学习网络来拟合耳蜗模型相比于传统方法的优点有哪些?如果传统方法是有偏的估计,如何保证拟合出来的结果是更有效的?拟合出来的结果如何应用在低功耗的芯片中?
这是一个非常好的问题,我也在想这个问题,如果细心的朋友们在听我们汇报的过程中,会发现我们现在所用的数据都是仿真模型的输入/输出数据,并非真实耳蜗数据。换句话说,我们把仿真模型当做一个我们学习的目标了,这个事情是对的吗?就像这个朋友提的问题,如果仿真模型本身都不是一个准确的,你学它还有意义吗?为什么向仿真模型学习呢?第一步从学习仿真模型开始,目的是先建立一个耳蜗的DNN模型框架,然后,随着真实数据的不断的增加,深度学习的效果就会越来越好。不只在我们听力学领域的深度学习应用,比如在通信领域的天线电路仿真建模中,现在也都倾向于用深度学习神经网络学习并代替那些基于微分方程等复杂数学模型方式。为什么都倾向于改成深度神经网络呢?主要因为 它的扩展性和适应性会更好。 再说一下深度学习模型能否运行在低功耗的芯片中。深度学习模型的训练过程相对比较复杂的,一般都运行在高性能计算服务器端。应用训练好的深度学习模型相对复杂度较低,并且还有一些针对模型复杂度的优化算法,以及一些嵌入式芯片配置的深度学习模型的运算硬件加速器,例如安森美半导体新推出的Ezairo8300 DSP就带一个神经网络加速器。因此 针对特定应用,在嵌入式场景应用深度学习模型是完全可行的。
Q:
请问模型的输出语音有没有主客观的语音质量评价指标?
目前没有做客观语音质量评价。要不要做这个事情?其实也可以做,但它的一个问题点是 助听行业还没有相应的评价标准规范。 像语音编码领域,针对音质的主客观评价都有一套标准规范。客观语音质量就更难去做考量了,我们在汇报中给出的Q因子可能算是一个客观评价指标,还有仿真模型和DNN模型的对比误差。首先还是要先明确主观评价方法和指标,这样客观才有参照标准。以目前了解的文献来看,主观评价大多都是请较少数量的患者采样进行处理效果的对比实验等。这类主观实验方法能够在一定程度上说明问题,但是还是如前所述缺少标准流程,因而不同文献之间的实验结果也很难进行横向比较。也许在听力学领域,大家一起探讨制定一系列有针对性的主客观评价标准,是一项很有意义的工作。
Q:
助听器中的啸叫抑制算法什么方法效果比较好?
目前商用的啸叫抑制算法都是基于自适应滤波器理论框架的。啸叫处理是跟产品的应用目的、设计形态、电声指标、声学结构、器件和算法等都密切相关的,它不完全是一个算法能够解决的问题,需要系统级的设计过程。需要在实际应用中操作,去调相应的参数,才可能达到比较好的效果,至少现在是这样的一个情况。
Q:
在深度学习神经网络方面,国外的研究进展是怎么样的?
近年来,深度神经网络(Deep Neural Network, DNN)开始在计算听觉相关领域得到成功应用,例如语音识别、语音合成、语音增强、声源分离和耳蜗听觉建模等。基于DNN的助听技术的代表性工作主要有:Lei, I.M.等提出了3D打印的仿真耳蜗,采用DNN对仿真耳蜗的输入-输出的刺激电信号进行耳蜗生物电学建模,来解释人工耳蜗植入患者的电场成像剖面,预测患者体内的耳蜗组织电阻率等参数,用以指导人工耳蜗植入治疗。
Armstrong, A.G.等提出了一种卷积神经网络与计算神经科学相结合,为耳蜗力学生成实时端到端模型,并使用耳蜗力学研究中常用的声音刺激信号来评估其性能和适用性,实验表明该模型可仿真耳蜗的频率选择性及其对声音强度的非线性响应特性等。
Haro S等假设耳蜗损伤会影响言语感知,并且中枢神经系统随时间的变化可能会补偿这种损伤;基于此假设,采用DNN对Zilany滤波器组的耳蜗仿真模型进行建模,对比了该模型与正常人耳在噪声条件下的言语识别率,实验表现相当;并试图通过上述DNN模型适应仿真耳蜗退化条件下的言语识别率,但无法达到正常人耳的水平;这可能是采用Zilany作为参考仿真听觉模型的缘故。
Mondol SIMMR等则从听力处方角度出发,提出了以NAL-NL2为参考处方的基于DNN与迁移学习的听力验配方法;该方法可实现从听力图输入到补偿增益输出;在声信号处理方面仍然没有摆脱声增益“压缩与放大”控制的框架,但对于DNN技术应用于听力处方方面提供了启发。
N. Alamdari等针对现有听力处方策略都是基于听力学实验数据均值无法对特定患者优化的问题,提出了采用强化学习方法取代听力师的人工优化调节;该方法自动学习特定用户的听觉偏好,并根据用户的反馈优化增益“压缩与放大”处理。
Healy E.W.等针对助听系统的实时性要求,提出一种有效因果的深度学习算法,用于分离语音和背景噪声,提高语音清晰度。该算法使用过去时间和人类感知机制可容忍的未来时间的复数频谱信息(包括声音信号的幅度和相位信息)作为声学特征,使用一种门控卷积循环网络作为深度学习模型实现从带噪语音到降噪语音的映射,通过大量的噪声数据进行训练,并使用未经训练的背景噪声进行测试,以验证算法的有效性。


扫码查看回放
健康听力技术论坛
往期回顾

随着TWS耳机的飞速发展、辅听产品技术的日新月异,以及美国FDA发布OTC助听器草案的政策驱动下,未来五年,助听产品和辅听产品的跨界与整合将成为主流趋势。
在行业变革时代背景下,北京听力协会主办了「健康听力技术论坛」,长期为大家提供发声的平台。论坛持续以每期两位嘉宾、不固定更新上线的形式长期举办。
期待声学领域、TWS领域、辅听及助听领域的专家、学者,以及产业供应链上中下游多方代表积极参与论坛并发表演讲。我们希望通过论坛的举办,搭建行业平台,促进产品变革,推动技术发展,为轻中度听损人士及健听人士提供更合适的听力保护及听力辅助方案,实现「全民健康听力」这一终极目标。

作者:梁维谦
编辑:皇甫甜
排版:皇甫甜



