

# 周昊帅:又为智能--智能化远程验配的框架

-
又为智能高级研发工程师
-
又为智能实验室开创者
-
加州理工学院电子工程系硕士
HHTF
远程验配的背景
1
远程验配
在过去的几十年,传统的助听器验配往往采用线下的模式。然而最近的十几年内,远程验配的概念开始迅速地兴起。各大助听器品牌都纷纷推出了他们的远程验配软件,并开始提供相应的远程验配服务。这些软件虽然形态各异,但大体都支持听力师与助听器使用者间实时的视频通话,并且听力师可以实时地调节助听器。
2
混合模式
尽管远程验配正在迅速地发展着,目前对助听器使用者和听力师而言,比较好的方式还是一种混合模式,即线下验配与远程验配相结合。
线下验配有着自己独特的优势,比如助听器使用者与听力师之间更容易建立起信任,依赖关系。二者之间的沟通也更加方便。听力师也有更多的设备来完成更详尽的测试。
而远程验配它的优势则在于不受时间与空间的限制,并且助听器使用者可以处在自己日常生活的环境中让听力师来调节助听器,非常方便。
然而,考虑到初诊在助听器的整个验配过程中是一个非常重要的环节。听力师需要完成很详尽的检查,并且此时是助听器使用者与听力师建立信任的最好时机。因此,**初诊还是应该在线下完成,**而对于后续的调节过程来说,远程验配则可以很好地发挥它的优势。
HHTF
目前远程验配的痛点
尽管远程验配与线下验配正在做着很好的结合,远程验配依然存在着三大痛点:
不稳定,不高效,不便捷。
1
不稳定
听力师与助听器使用者之间的实时的视频通话是远程验配中必不可少的环节,然而视频通话对于网络的要求是较高的。一旦助听器使用者处在一个较差的网络环境内,远程验配的质量就会 大打折扣。
大打折扣。
此外,远程验配对于周围环境也是有一定要求的。**助听器使用者通常需要处在一个较为安静的环境下来完成远程验配。**如果这个条件不能满足,那么远程验配的质量也是会比较差的。
2
不高效
**就沟通效率而言,**视频通话的方式依然和线下沟通相比有较大差距。并且助听器的使用者也很难去表达自己的一些身体语言。
此外,**听力师也会比较难感知助听器的情况。**比如不是所有软件都支持听力师实时获取助听器的声音,并且想要知道具体的耳帽,动铁型号也会比较有难度。
3
不便捷
当助听器使用者的听力图发生变化后,**读图更新数据的过程依然需要由听力师来人工完成。**并且后续的远程验配也需要由听力师来人工和助听器使用者预约,不是特别方便。
HHTF
如何利用智能化技术改善远程验配
1
保证远程验配的沟通质量
可以**运用一些智能化的手段对助听器使用者的网络环境进行检测。**比如,可以检测助听器用户的网络带宽,延时,抖动,丢包率。
一旦上述4个指标有一个不满足,可以在软件上给予用户相应的提示,建议他切换到一个更加好的网络之后再开始远程验配。这样就能很好地保证远程验配的体验。
类似地,可以**检测助听器使用者所处的环境噪音,**当发现环境噪音太大时,同样可以给予他提示,让他寻找一个更安静的环境,再开始远程验配。
2
为远程验配提供辅助文字信息
字幕对于提升言语识别率的帮助是极大的。那能不能在远程验配的过程中加上实时的字幕,来帮助助听器佩戴者更好地和听力师进行交流呢?语音识别技术可以做到这一点。在2009年深度学习兴起之后,语音识别的准确率迎来了大幅度的提升。
2016年,微软公司就宣布自己基于AI的语音识别技术达到了5.9%的词错率,首次达到了人类专业水平。此时此刻,语音识别技术已经拥有了一个比较高的准确率,完全能够很好的和远程验配做一个结合。
又为的远程验配平台就搭载了语音识别技术,能够很好地辅助助听器使用者与听力师沟通,确保远程验配的高效。
3
让听力师感知助听器的情况
**可以利用 Bluetooth + WebSocket 技术将助听器发出的声音实时传送到听力师端,**让听力师更好地和助听器使用者达成共识,方便二人的沟通。
4
完成听力图自动输入
目前,听力图都需要由听力师人工进行识别,不是特别方便。前不久,又为提出了他们的多阶段听力图识别网络(Multi-Stage Audiogram Interpretation Network, MAIN)。
**这个网络能够自动地将包含听力图的照片转换为对应的数字格式,**能够非常方便的和各种远程验配软件相结合,节省听力师的时间。
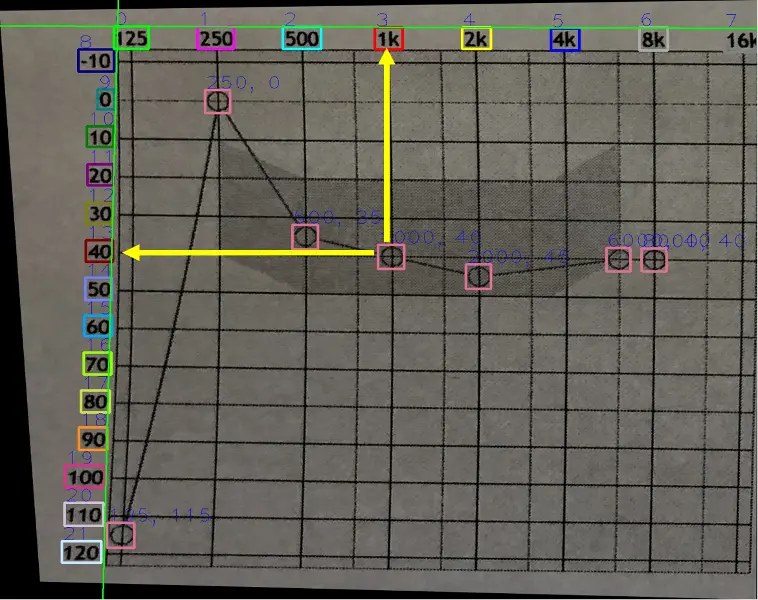
具体来说,MAIN分为三个阶段。在 第一阶段 中,MAIN先对听力图进行了精确的提取。往往听力图照片中除了包含听力图外还很有可能包含一些其他的物体,比如下图中的剃须刀,记号笔,便利贴等等。这些物体能会变成干扰项,给后续处理带来很多不便,并且极大地影响整个系统的读图精度。因此,在这一阶段中,MAIN利用Faster-RCNN对照片中的听力图部分进行更精确的提取,以简化整个系统,并且改善识别结果。

在 第二个阶段 中,MAIN对透视失真问题进行了矫正。透视失真在摄像时是一个常见的现象。以拍摄听力图为例,由于相机的畸变和视角差等原因,原本应该平行的听力图的网格线在照片中变得不再平行,这种情况会影响读图的精度。在MAIN中,作者提出了基于线条检测和基于Mask-RCNN两种方法对这一情况进行矫正。实验发现经过透视矫正后整个系统的正确率得到了大幅的上升。
在 最后一个阶段 中,MAIN对听力图的坐标轴进行了拟合并以此读取数据。具体来说,MAIN再次利用了Faster-RCNN对坐标轴的刻度和听力符号进行了检测。在得到了这些坐标轴的刻度后,MAIN利用了两次RANSAC算法对坐标轴进行拟合。
RANSAC算法是一个在拟合数据时用于排除异常值的算法。由于照片可能是在不同的光照,角度下拍摄的,因此对于坐标轴刻度值的检测不一定完全准确,需要对其中的一些异常值进行排除。MAIN先在空间域上进行了一次RANSAC。
如下图所示,五个检测框中有一个在位置上属于异常值。此时运用一次RANSAC算法,可以很好地将空间位置上的异常检测值,即800,排除掉。但是在剩下的四个检测框中,仍然有一个是明显有错误的。此时MAIN将这些检测出的坐标值投射到刚刚拟合出的直线上,并以此作为自变量,然后把对应的数值作为因变量,将空间域转换到了数值域。然后MAIN又利用了一次RANSAC算法就可以将数值上的异常值,即125,排除掉。
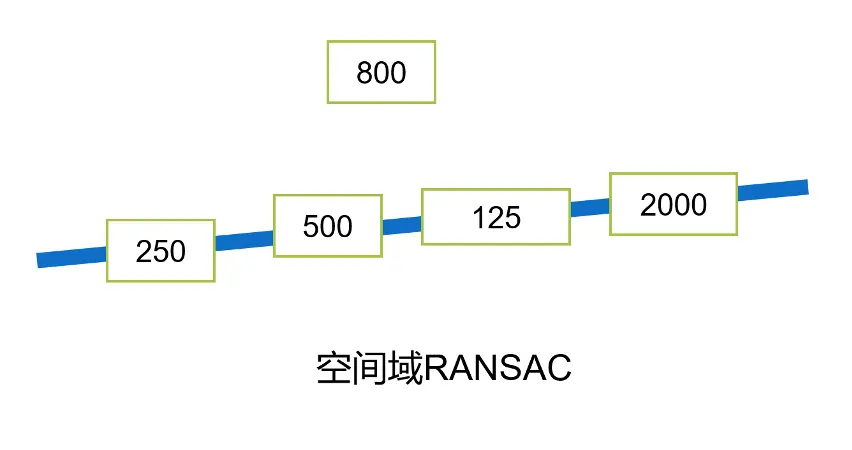
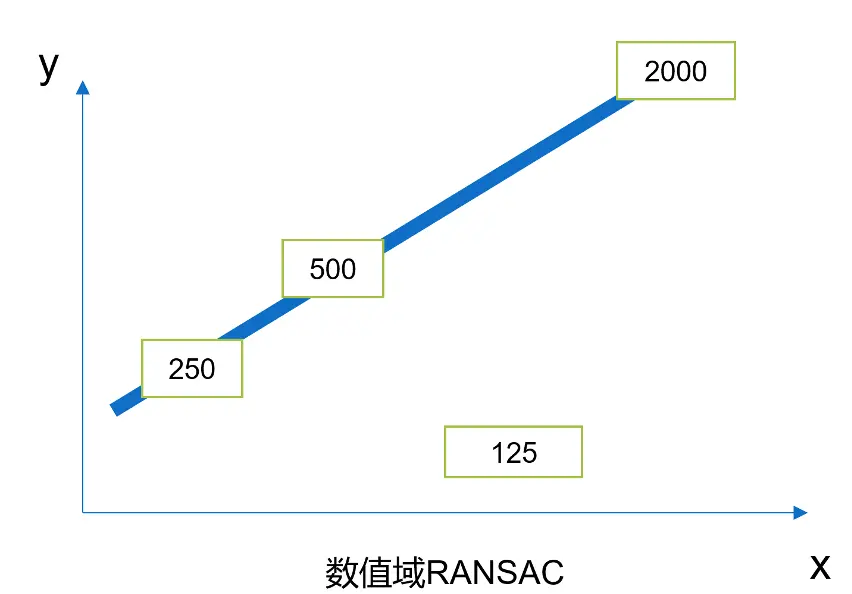
MAIN利用两次RANSAC算法,在空间域和数值域上都排除了异常值。大大增加了坐标轴拟合的精度。在得到拟合的坐标轴后,MAIN再将每个听力符号投射到坐标轴上即可进行读数。
以上就是又为的听力图识别网络的结构。
除了提出了这样一个多阶段的听力图识别网络,**又为在论文中还公开了他们所收集的听力图数据集。**他们的数据集包含约400张照片,这些照片是在各种不同的角度,光照,遮挡,折叠下拍摄的。他们为这些照片提供了必要的标注信息,并将这个数据集命名为Open Audiogram。欢迎感兴趣的朋友在又为的数据集上尝试他们的算法。
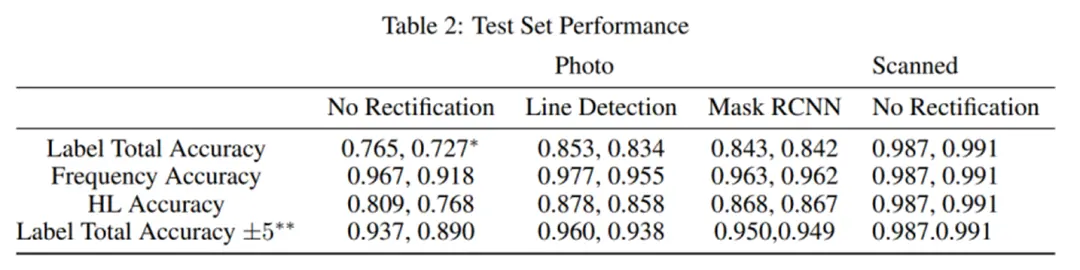
实验结果显示又为的多阶段听力图识别网络可以达到很好的效果。在经过透视矫正后,识别准确率可以接近95%,并且在扫描图片上的准确率接近99%。
5
辅助增益调节
可以利用一些聚类算法来****根据助听器佩戴者的性别、年龄、生活环境等属性生成推荐的听力补偿。
助听器佩戴者的每一个属性就对应一个维度,多个属性的集合就形成了一个高维空间,而每一个助听器使用者则对应一个高维空间内的小点。可以利用聚类算法将助听器佩戴者们按他们在高维空间中距离的远近分成不同的类别。同一类别内的佩戴者们可以认为属性都比较相近,因而他们对于增益的偏好也是有挺大概率是相近的。
所以可以对每一类佩戴者都给出一个推荐偏好,然后听力师只要在此基础上再根据每个人的个性化需求进行微调即可。
6
提醒后续远程验配
AI可以用来提醒后续远程验配。比如可以 利用基于AI关键词检测技术, 当检测到助听器佩戴者经常说出“什么?”,“啊?”,“对不起我没听清”等语句时,就可以认为此时他正在遭受听力困难。
此外,还可以 利用加速度计或者陀螺仪来检测助听器佩戴者的头部运动, 如果检测到他经常摇头,或者头前倾,也可以认为他有一定概率在遭受听力困难。一旦听力困难出现的频率超过一定阈值,就可以向助听器佩戴者发出提醒,建议他去预约远程验配。
同时还可以 利用基于AI的场景识别技术, 将听力困难发生时的场景识别出来,在助听器佩戴者同意的情况下,将相关的场景数据发送给他的听力师,这样也能帮助听力师们做更有针对性的调节。
HHTF
Orka Remote Fitting
又为的远程验配平台使用了 WebSocket + WebRTC + Bluetooth 的技术,可以支持听力师和助听器使用者之间实时的视频通话。
此外,听力师也可以实时调节助听器。并且又为的验配平台也搭载了实时的语音转文字技术**,**能够更好地方便听力师与助听器佩戴者之间的沟通。
同时,又为的平台也拥有听力图自动识别技术,能够节省听力师的时间。另外,他们的平台是基于网页的,可以直接在浏览器中打开,不需要下载任何软件,十分方便。
以下视频是又为的远程验配平台的展示。
HHTF
智能化技术正在改变远程验配
智能化技术正在改变远程验配。它可以解决远程验配的痛点,发挥远程验配的优势。此外,AI也可以更好地辅助听力师。听力师可以将更多的精力放在解决核心问题上,比如更好地和助听器佩戴者建立信任关系,更个性化的调节等等。同时听力师也可以有更多的时间去服务更多的人群,让更多的人都能享受听力服务。
现场互动Q&A
Q:
听力图上面有什么要求?气导?骨导?MCL?未来是否有机会实现评判听力损失种类的能力。
当前我们的听力图识别系统只支持气导。其实现在也有一些关于听力图分类的相关研究,不过它们分类的结果都比较粗略,实现难度也不大。相比之下,我们的听力图自动识别在技术难度上要更高,未来也能较容易地在此基础上加入听力图分类功能,应该能得到比目前方法更精准的结果。
Q:
对于自动识别听力图,你们的识别算法是open api的方式吗?
目前还不是open api的形式。不过我们的算法已经在github上开源了(https://github.com/jacklishufan/MAIN2021),并且附有很详细的readme。大家感兴趣的话可以尝试一下,很轻松地就能体验我们的算法。
Q:
终端用户只需要登入网络连接就可以实现远程验配?
对于听力师而言,只需要拥有网络连接,就可以在网页端实现远程验配。对于助听器使用者而言,需要下载我们的APP,同时手机接入网络来完成远程验配。
Q:
你们的fitting软件是基于web的吗?如果是,怎么连接本地的助听器。稳定性如何?开放的功能,是否能符合专业听力师的需求。
我们的验配软件在听力师端是基于web的,在用户端是基于APP的。在连接方面,我们是通过蓝牙进行设备与APP的连接。因为用户的助听器和手机始终是会处在一个比较近距离的环境下面,属于短距离无线通信。蓝牙不论在传输数据量,传输稳定性还是普及度方面都是一个不错的技术。同时,手机与听力师网络也需要通过联网WebSocket进行连接,我们会有一个一直进行的心跳检测和自动重连去确保整个连接的稳定性,保证连接没有中断。同时我们会对每一个数据包进行一次校验来确保它的数据包发送的内容是没有遗失的,完整的且正确的。就开放的功能而言,因为我们的算法都是自研的,所以我们的远程验配框架会把专业助听器的参数变成一个开放式的界面让听力师来调节。比如在我们的验配平台专业版中,我们会支持对压缩比,knee point等一系列参数的调节。所以不论是相对比较信赖人工智能推荐的听力师,还是想要去自己进行一些深度调节的听力师,都可以用我们的验配平台完成对助听器的全面改善。
Q:
验配的算法是自研的吗?当前用的验配算法的侧重点在哪儿?比如可懂或者音量补偿或者倍频?
我们的验配算法是自研的。目前侧重点主要在两方面。一方面是舒适性。因为对于大多数听损人士而言,他们感到舒适的声音范围相比其他人是更加狭窄的,所以声音该如何处理能够使他们感觉最舒适,这是我们的一个侧重点。另一个侧重点则是问题中提到的可懂度,如何帮助听损人士尽可能提高言语识别度也是我们验配算法努力的目标之一。


扫码查看回放
健康听力技术论坛
往期回顾

随着TWS耳机的飞速发展、辅听产品技术的日新月异,以及美国FDA发布OTC助听器草案的政策驱动下,未来五年,助听产品和辅听产品的跨界与整合将成为主流趋势。
在行业变革时代背景下,北京听力协会主办了「健康听力技术论坛」,长期为大家提供发声的平台。论坛持续以每期两位嘉宾、不固定更新上线的形式长期举办。
期待声学领域、TWS领域、辅听及助听领域的专家、学者,以及产业供应链上中下游多方代表积极参与论坛并发表演讲。我们希望通过论坛的举办,搭建行业平台,促进产品变革,推动技术发展,为轻中度听损人士及健听人士提供更合适的听力保护及听力辅助方案,实现「全民健康听力」这一终极目标。

作者:周昊帅
编辑:皇甫甜
排版:皇甫甜



