前段时间花了好几天把 Claude 的面向工程师文章系列 https://www.anthropic.com/engineering 阅读了一遍。现在把自己的理解整理下来,希望对大家有用,会以文章标题/链接,核心内容,我的理解三部分组成。发现如果都贴出来,会特别的长,由于篇幅问题,我把更多内容放在了自己的博客网站。感兴趣的可以移步看看。https://www.jwx.ink/issues/id/53
https://www.anthropic.com/engineering/claude-think-tool
“思考”工具:让克劳德在复杂工具使用场景中暂停思考
核心观点:
- 为 AI 提供一个思考工具,让 AI 能够在响应过程中停下来思考是否已经获取了足够的信息。
- 和 Extend thinking 区别在于,一个是“思考”之前的思考,一个是“思考”期间的思考。
- 适合在需要多工具,外部环境复杂的场景中解决问题场景中。
https://www.anthropic.com/engineering/building-effective-agents
- 构建高效智能体
- 核心观点:
- 为实际问题选择最佳的模式:智能体或者工作流,甚至简短的单次 LLM 调用。
- 工作流模式:
- 提示链:将任务分解为顺序步骤,用于可清晰分解的固定子任务
- 路由:根据输入分类导向专门化后续任务
- 并行化:同时处理独立子任务或获取多种观点
- 编排者-工作者:中央LLM动态分解任务并委托给工作LLM
- 评估者-优化器:一个LLM生成响应,另一个提供评估反馈循环
- 和 Agent 模式区别在于,对于 In,并不是 100% 将问题拆解为 3 个 LLM Call,简单的问题可能直接 In -> Out。
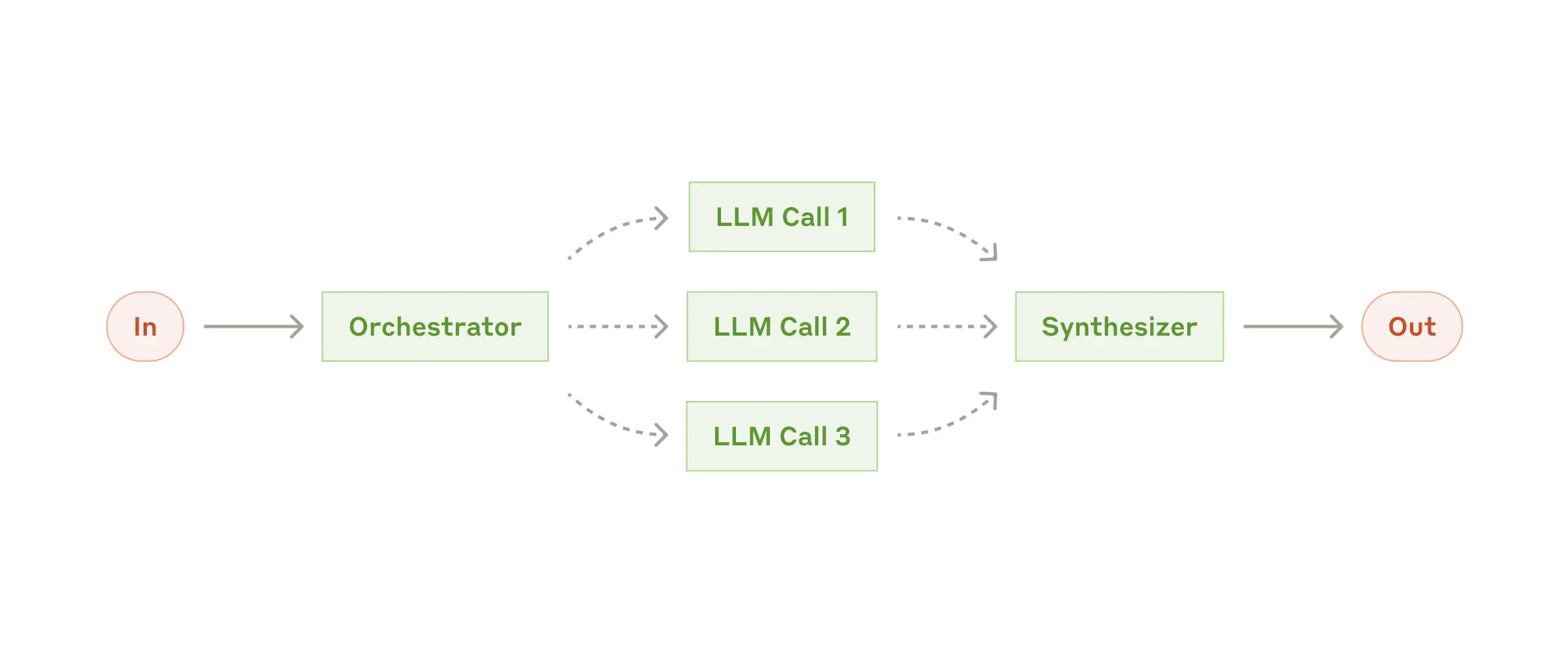
- 上下文和工具准确性和易用性十分重要
https://www.anthropic.com/engineering/contextual-retrieval
RAG != 上下文检索
核心观点:
- 传统 RAG 会导致上下文丢失,上下文检索就是为了解决 RAG 的缺点的。
- 补充上下文的方式,包括:
- 上下文嵌入
- Claude 自动生成上下文
- 缓存技术减低上下文检索过程中带来的token消耗。
- 检索之后重排序功能可以提升检索效果
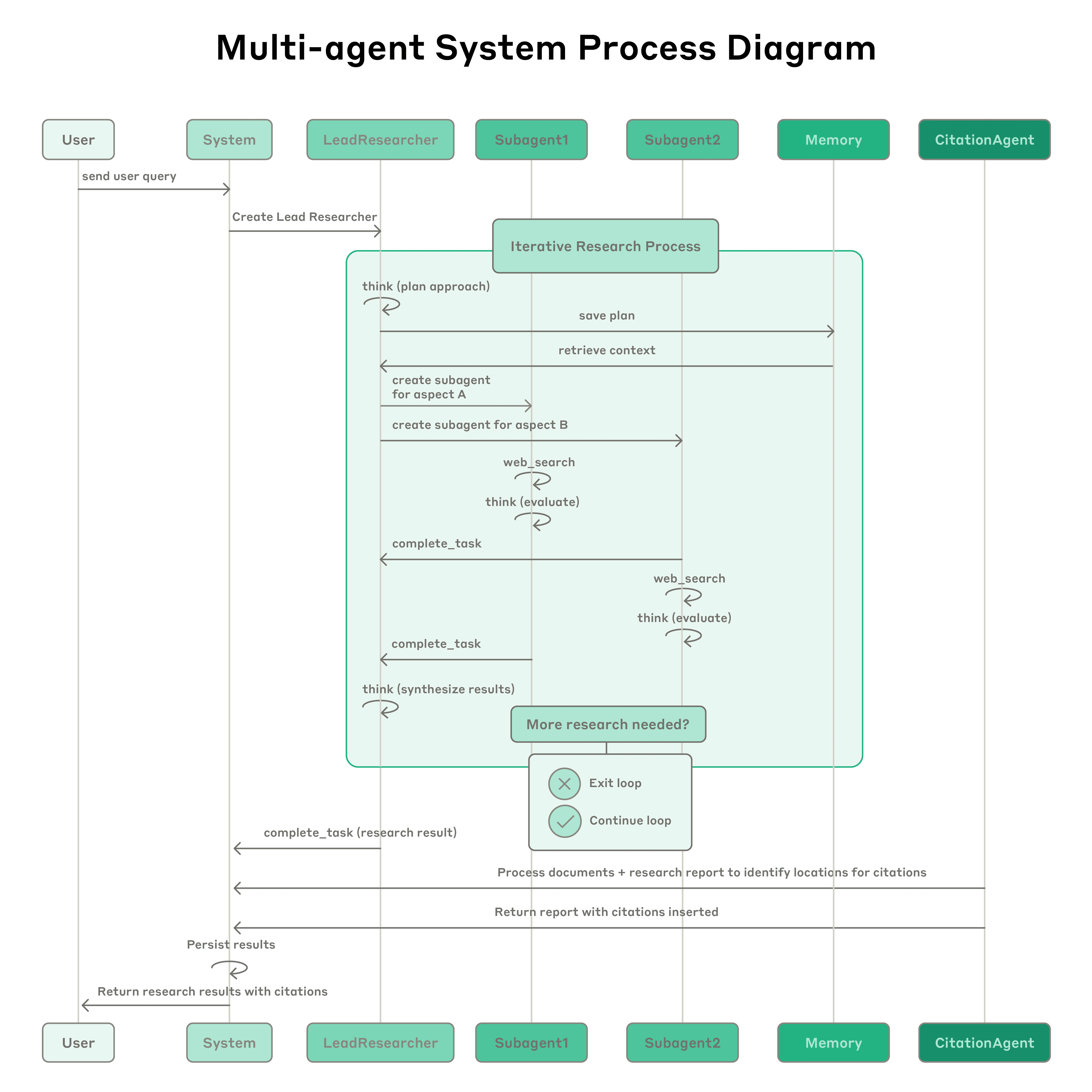
https://www.anthropic.com/engineering/multi-agent-research-system
我们如何构建了我们的多智能体研究系统,单智能体 vs 多智能体
核心观点:
- 多智能体架构带来显著性能提升
- Token 使用量是性能关键因素,多智能体之间需要信息隔离。
- 提示工程(Prompt Engineering)是核心,包括优化工具设计与选择、采用"先宽后窄"的搜索策略、利用扩展思考模式引导推理过程、并行调用工具提升 90% 的速度。
https://www.anthropic.com/engineering/writing-tools-for-agents
携手智能体,打造高效工具——专为智能体设计
文章主要介绍如何创建合理有效的工具,让智能体更加高效。在 https://www.anthropic.com/engineering/multi-agent-research-system 中也有部分内容和构建高效率智能体有关,我合并在一起讲。
核心观点:
- 工具开发需要评估驱动的迭代流程,采用"原型→评估→优化"的循环,Claude 优化的工具性能可超越人类专家编写的版本。
- 选择正确的工具比工具数量更重要
- 工具命名空间和返回内容设计至关重要
- 提示工程工具描述是最有效的改进方法
- 优化 Token 效率是性能关键
https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
AI 智能体的高效上下文工程
上下文工程和提示工程
- 提示工程,包括编写 System Prompt,给出合适的 User Prompt。让 LLM 可以更为高效的完成任务。
- 上下文工程,要管理整个上下文状态(系统指令、工具、MCP、外部数据、消息历史等)的策略。
- System Prompt
- Tools
- Knowledge
- Message History
- MCP
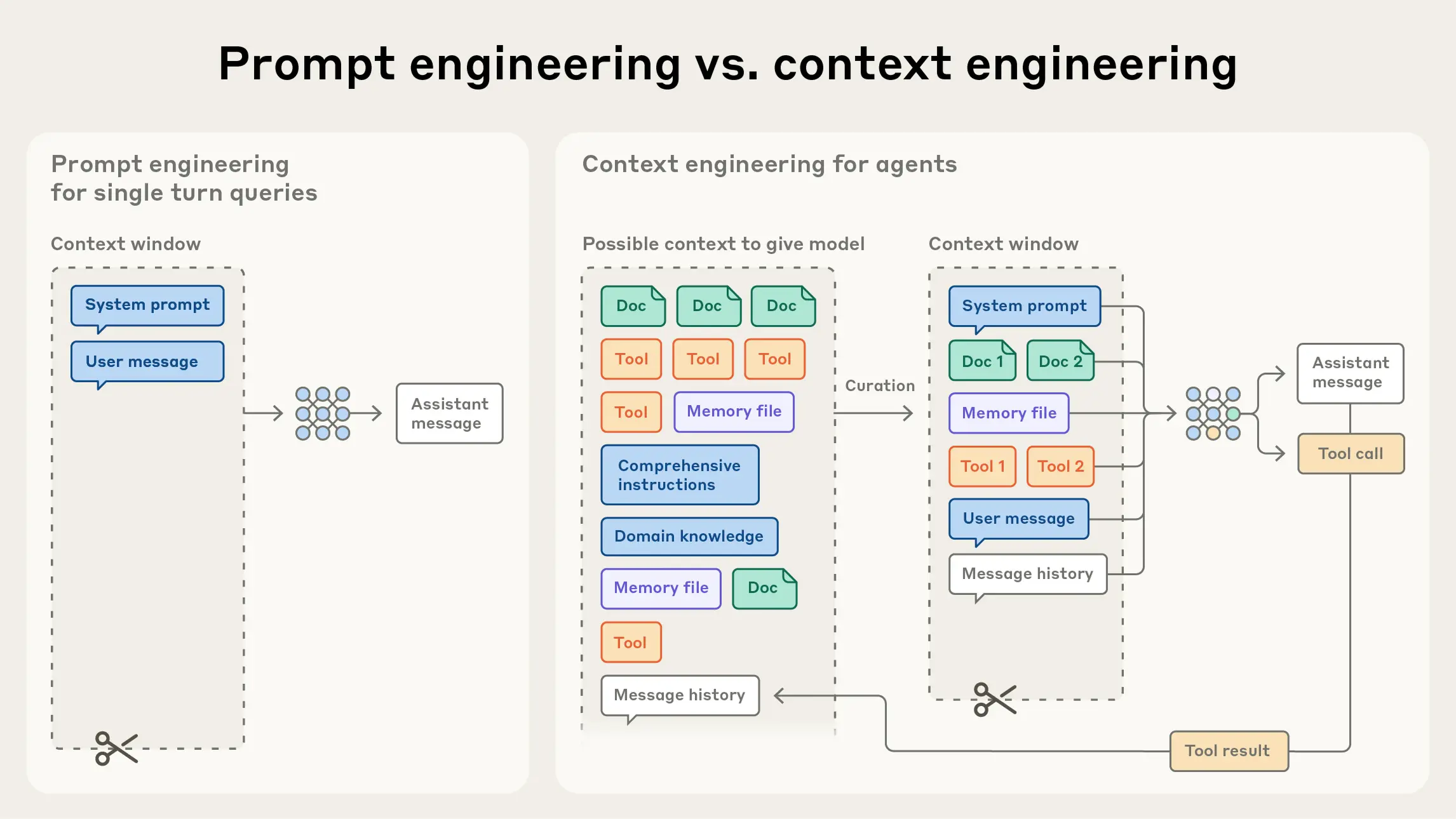
核心观点:
- 高效的模型不要预设过多的信息,即不要干预它的自主决策,不要让它工作的像一个 Workflow
- 找到能够最大化实现模型预期结果的最少 Prompt 集合(包括 System Prompt & Tools 等等)。