前回の記事で、「LLM 向けのソフトウェアシステムは新しいパラダイムであり、AI に対しては制約を減らし、もっと自由を与える必要がある」と書いた。そして最後にこう残した——「次回は、具体的にどのように自由を与えるかを書く」と。
その前に、ひとつ問いを立てたい。なぜ私たちは本能的に Agent に制約をかけたがるのか?
この問いに答えるには、まず理解すべきことがある。Agent の世界では、データとコードの境界が溶けつつあるということだ。
ひとつの loop から始めよう
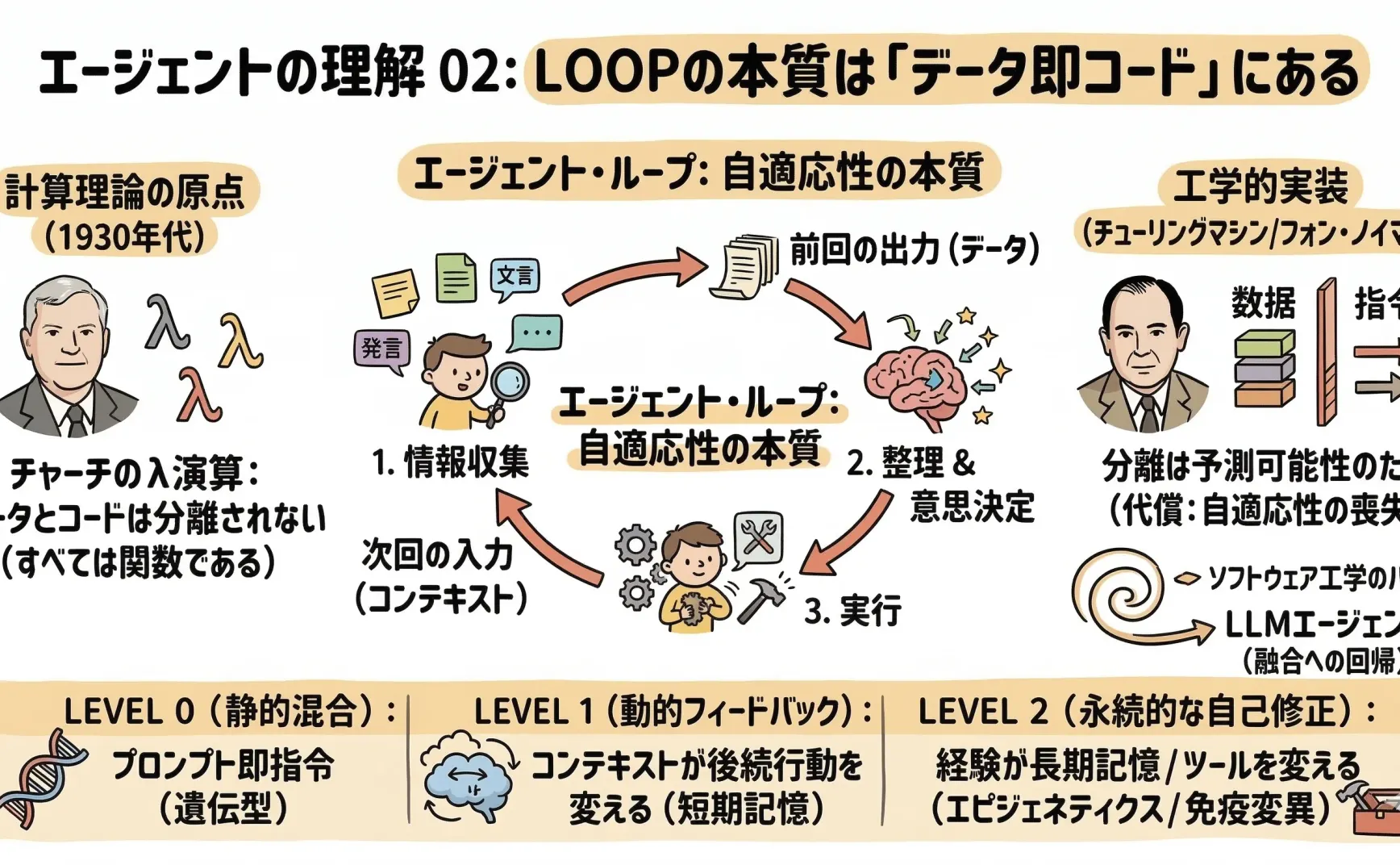
前回の記事で述べたように、Agent の基本ループは次のようなものだ:情報収集 → 整理 → 意思決定 → 実行 → 再収集。
このループをコードで表すと、中心となるのはひとつの llm.Chat 呼び出しだ。prompt を入力し、response を得る。そして次のループでは、前回の response を新しい prompt に結合して再び渡す。
とても単純に見える。しかしここに、重要で非凡な点がある。
前回の出力(データ)が、そのまま次回の入力条件(制御フローの一部)になっている。
伝統的なソフトウェア開発では、これは禁忌とされる。
では、この伝統はどこから始まったのか?
計算機の起源に戻ろう。
1930年代、計算理論の源流にはほぼ同時に二つの系譜が存在した。
Church の λ 計算と Turing のチューリングマシン。
Church の λ 計算にはもともと「データ」と「コード」の区別がない(以前の記事 『Church 数と Lambda 計算』 を参照)。関数は値であり、値は関数でもある。
Church 数自体が関数であり、真偽値も関数、条件分岐も関数。すべてが λ 式であり、すべてが Apply(コードとして実行)も伝達(データとして)もできる。データとコードの融合は、新しいパラダイムではなく、むしろ計算理論の原点なのだ。
分離が生まれたのはその後だ。チューリングマシンは「テープ上の記号」と「状態遷移規則」を分離した。さらにフォン・ノイマン・アーキテクチャは、その分離をハードウェア設計として固定化した。命令とデータは同じメモリを共有しているが、論理的には区別されている。
私たちはその後、フォン・ノイマン型の体系を受け入れ、データと命令を分離した。それは真理ゆえではなく、予測可能性ゆえだった。プログラムを書くとき、それが何をするか把握したい。データとコードを分けることは、人間がシステムを理解し、制御するための工夫——不可解さへの本能的な恐れから生まれたものだ。
こうして現代のソフトウェア安全モデル全体が、「データを制御フローとして扱ってはならない」という共通認識の上に築かれた。
DEP、NX bit、サンドボックス——これらすべてがその共通認識を守るための仕組みである。
しかしその代償として、適応能力を失った。
プログラムは自分の実行結果に応じて自らの論理を変えることができない。自分で自分を修正する? 現代のシステムではそれは機能特性ではなく脆弱性だ。
だからこそ、過去数十年のソフトウェア工学は、この「欠落」を埋めるためにさまざまな補助的仕組みを発明してきた。強い型付け、バージョン管理、イテレーションモデル、A/B テスト……どれも「データがコードになれない」制約の中で、「データが行動に影響を与える」ことを不器用に、だが制御可能な範囲で模倣してきた。
より正確に言えば、この流れは次のような螺旋だった。
計算理論の起点:λ 計算 → データとコードは未分離
↓
工学的実装:チューリングマシン/フォン・ノイマン → 製造と予測可能性のために分離を導入
↓
ソフトウェア工学 → 分離の上にパッチを重ね融合を模倣
↓
LLM Agent → 再び融合へ
loop:システムは自らの出力で自らの入力を書き換える
各ループのたびに、Agent は自分の出力を使って自分の入力条件を書き換える。これは本質的に自己修正プログラムだ——ただし修正されるのはバイナリのコードではなく、意味空間のコンテキストである。
この自己参照性は λ 計算において自然に存在する。Y コンビネータは関数が自分自身を「呼び出す」仕組みであり、追加の仕掛けなしに λ 式だけで実現できる。
LLM Agent の self-bootstrap は、ある意味で Y コンビネータの意味論的再現である。ループを通して出力を再び自分に与えることで、新たな振る舞いを生み出す。
この仕組みを層で見てみると、おおよそ三段階がある。
Level 0:静的な融合。 system prompt の指示自体が「データとしてのコード」である。書いた prompt は単なるテキスト(データ)であると同時に、モデルへの指示(コード)でもある。もっとも浅い層であり、ほとんどの LLM アプリはここにある。
Level 1:動的フィードバック。 Agent の出力が context window に戻され、後続の振る舞いを変える。memory、tool results、chain-of-thought などがこれにあたる。特徴は短期的可逆性——context window に限界があるため、古い情報は切り捨てられる。
Level 2:持続的自己修正。 Agent が経験を長期記憶に書き込み、自身の prompt テンプレートやツールコードを修正する。この層こそ真の self-evolution である。不可逆あるいは巻き戻しが難しく、変更の影響は何度かのループを経て初めて現れる。

生物学の視点から見れば、データとコードの融合はむしろ常態だ。
DNA は設計図だが、転写因子自体も遺伝子がコードするタンパク質——コードが生むデータが、逆にコードの読み出しを制御する。これは Level 1 に相当する。
さらにエピジェネティクスは興味深い。DNA 配列そのものは変えずに化学的修飾で遺伝子の発現パターンを変える。言い換えれば、system prompt を変えずに memory によって振る舞いを変える。これは Level 2 だ。
さらに免疫システムは、遺伝子断片の切断と再接続によって新しい抗体を作り出す。これは Level 2 の極端な形であり、未知の病原体に適応するためにシステムが自らのコードを積極的に書き換える。
したがって Agent の loop の本質は、おそらくソフトウェアが生物を模倣しているのではなく、システムが複雑になり自律的適応が必要になると、データと制御フローの融合が必然的に生じるということだ。
歴史的に、私たちが採用してきた「データとコードの分離」というフォン・ノイマン的語りは、工学的単純化のための便宜であり、自然法則ではなかった。λ 計算も生物学も、最初からそのことを知っていたのだ。
新しい語りとその転換
生物学において、ゲノムには二種類の領域がある。
- 高度に保存された領域:中枢代謝経路など、数十億年ほとんど変化せず、変えれば死に至る。
- 高度に可変な領域:免疫グロブリンの可変領域のように、突然変異と再結合をむしろ促す部分。変化すればより強い適応を得るかもしれない。
Agent の構造も同様であるべきだ。
- 保守領域:核心となる不変原理、安全境界、容易に変更できない部分。
- 可変領域:自由に進化する部分、行動戦略・知識記憶・ツール使用の傾向など、変化を奨励する部分。
これが、「どう自由を与えるか」という問いの前半の答えになる。与えるべきかどうかではなく、「どこに」与えるかだ。
ソフトウェア開発への含意
保守領域は徐々に縮小し、可変領域は拡大している。
- 最初は、すべてが保守的だった。 ウォーターフォールモデル、強い型付け、完全な事前設計。コードは書いたらそう簡単に変えるべきではない。これは有効だが、要件が有限な領域でのみ機能する。
- この二十年で、可変領域が導入されたが厳密に分離されている。 データベース、依存性注入、A/B テストなど。コードとデータは相互作用できるが、明示的なインターフェースを介してのみ行われる。設定を変えれば動作が変わるが、設定はコード自体を変えられない。
- そして今、境界が溶ける。 Agent の prompt はデータでありコードでもある。tool calling の結果が次の行動を直接左右する。Agent はコードを書き、実行し、その結果に基づいて戦略を変えることができる。
自由は制約の反対ではない。自由は正しい制約の中でのみ意味を持つ。
かつて私たちは「不変の理想形」が存在し、現実の要件はそれを投影したものだと信じていた。伝統的なソフトウェア開発はその思考に影響されている。たとえば、問題にまず schema や interface、型システムを定義し、実行時データをそれらの固定構造に当てはめようとする。
しかし実存主義はこの関係を反転させた。存在が本質に先立つ——定義が先にあるのではなく、行動を通じて定義が形成される。生物も人間も本質的には実存主義的であり、純粋な Agent のループもそうだ。工場出荷時に固有のモードはごくわずかで、多くの場合は環境との相互作用を通じて自らを定義し続ける。
だが純粋な実存主義は工学的には破滅的だ。そのようなシステムはデバッグ不能で信頼性もない。
だからこそ、経験に容易に上書きされない先験的構造——原則のようなもの——が必要になる。それが経験的知識を蓄積可能にする出発点となる。Agent も同じだ。自己経験では上書き困難な中核の制約を持つことで、自由な進化がランダムな漂流へ堕ちるのを防ぐ。
LLM や Agent は一種の「言語ゲーム」と言える。意味とは語そのものではなく、使用のルールと文脈の中にある。そしてこれは LLM の動作原理そのものでもある。token に本来的意味はなく、意味は context 間の関係によって決まる。
つまり関係は探究可能であり、意味は創造可能だ。もはや制御フローをハードコードせず、意味空間の中で絶えず崩壊と再構成を繰り返す状態。これは、『世界を創るとはどんな体験か』 で書いたように、私が Agent や LLM に感じる魅力そのものだと思う。
ひとまずここまで
ただしこのフレームは静的なものにすぎない。実行時において、Agent は融合をどのように扱うのか?
可変領域の境界を描くことと、システムが実行時にその境界を本当に尊重することとは別問題だ。
ちなみに、上のスクリーンショットにあるグループチャットへの参加リンクはこちら:
https://t.me/+tP06DqgNMnlmMTc1