封面提示词:Light diffraction Rayleigh, science, Perfect wallpaper --chaos 100 --ar 16:9 --profile 1qiat9p --stylize 1000 更多提示词
上周精选✦
Deepseek R1 及 Zero 开源
好像从 Chatgpt 发布开始每年春节期间 AI 都会有一波明星应用或者研究结果爆发出圈,先是 Chatgpt,然后去年是 Sora,今年就是 Deepseek R1。
虽然大家应该都知道了但还是简单介绍一下,01月20日 Deepseek 开源了 Deepseek R1 模型,允许用户通过蒸馏技术借助 R1 训练其他模型,而且开放思维链思考过程的显示。
DeepSeek-R1 在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版,这个成绩开源社区也基本复现了。
另外他们还蒸馏了6 个小模型开源给社区,其中 32B 和 70B 模型在多项能力上实现了对标 OpenAI o1-mini 的效果。
关于 R1 模型层面的突破
这里引用一下 Andrej Karpathy 的看法吧,还是建议自己去看论文:
DeepSeek 的成功验证了算法创新与资源优化的潜力,但计算能力仍是长期智能发展的核心驱动力。
强化学习的突现能力是模型突破人类认知边界的关键,而合成数据与 RL 的结合将进一步释放深度学习的可能性。
计算资源是深度学习智能的上限:深度学习对计算资源的依赖远超其他 AI 算法,计算能力直接决定了长期可实现智能的上限。
核心论点:不仅是单次训练需要大量算力,整个算法创新的实验过程也依赖持续的计算投入。数据生成本质上也依赖计算(如合成数据、强化学习中的试错过程),计算能力间接决定了数据质量与规模。
数据与计算的深层关联:合成数据与强化学习的等价性,合成数据生成(如模型生成数据后筛选)与强化学习(试错学习)在本质上是相通的。例如:模型生成数据后通过“优势函数”筛选,等同于强化学习中的奖励机制。
模仿学习 vs. 强化学习的差异:
模仿学习(Imitation Learning):通过观察和重复(如预训练、监督微调),能力上限受限于人类标注者的认知。
强化学习(Reinforcement Learning, RL):通过试错探索(如 AlphaGo 的自我对弈),能产生突破性、超人类的表现。
强化学习的“魔法”:
RL 是深度学习突破性成果的核心驱动力(如 AlphaGo 击败李世石、模型在思维链中回溯与调整策略的能力)。这些能力是涌现(Emergent)的,无法通过模仿学习获得,因为人类无法预先标注复杂的认知策略。

关于 R1 出圈的原因可能有以下几个:
- 它击败或匹配了领先的商业大语言模型。尤其击败了 OpenAI 的 o1。
- R1 也是一种思维模型,此前只有 OpenAI 和谷歌能够开发这类模型。
- R1 不仅开放权重,还采用 MIT 许可证,任何人都可以使用。
- DeepSeek 发布了如何从头开始训练这种模型的方法,OpenAI 和 Google 在训练层面的优势被大幅削弱
- R1 的运行成本也非常低。Anthropic 每 100 万输出 token 收费 15 美元,而 R1 仅需 2 美元。
很多AI 圈子的大佬都对 R1 的发布发表了看法:
- Sam Altman 向 DeepSeek 表示祝贺,并宣布他们将提前时间表,很快发布一些新内容。
- OpenAI 首席研究官 Mark Chen 承认了 Deepseek 独立发现了某些 O1 训练的核心。
- Anthropic 的首席执行官 Dario Amodei 借此机会强调了出口管制的重要性,高赞评论都在骂,文章前后矛盾的地方挺多。
- 杨立坤转发并且夸奖了 R1 项目,并且表示开源会加速 AI 进步。
- Perplexity CEO 解释了为什么 R1 不是克隆 Open AI 的成果。
同时 Deepseek R1 给很多受制于非开源模型速度和价格的产品很多机会,这些产品终于可以摆脱昂贵和不稳定的模型给自己腾出合适的利润率,比如:
- Windsurf 和 Cursor 都接入了 R1
- 笔记软件Craft也可以用1.5B 的 R1 蒸馏 Qwen 模型来辅助写作
- Krea 都基于 R1 做了一个串联所有功能的 Chatbot
- Perplexity 上线了基于 R1 的深度搜索功能,可以免费试用。
- AI 搜索公司 EXA 做了一个 R1 驱动的网络研究员,还是开源的。
很多云服务都跟进部署了 Deepseek R1:
- 英伟达 Nim 微服务上线了 Deepseek R1,可以实现在 HGX H200 上每秒 3872 个 Token 的输出
- 硅基流动和上线了完全体 R1 模型,运行在华为云的昇腾显卡上
- 海外已经部署 Deepseek R1 的云服务汇总
Open AI 发布 o3-mini 模型
在 Deepseek R1 带来的模型质量和极低成本压力下,Open AI 如期发布了 o3-mini 模型。
在模型能力上
O3-mini 还一改常态的给出了低中高三个推理等级,利用低推理等级的成本将 plus 会员和 API 价格拉了下来。
O3-mini 首次推出就直接支持了完整的 API 功能,函数调用、结构化输出和开发者消息,但是不支持多模态能力。
价格上也能感受到变化,o3-mini 和 o1-mini 都大幅降价,降价幅度为 63%。
会在在 Chat Completions API、Assistants API 和 Batch API 中向 API 使用层级 3-5 的选定开发者推出。
ChatGPT Plus、Team 用户可以直接使用 o3-mini 和 O3-mini-high,而且o3-mini 的限额提高到了每天 150 次查询,o3-mini-high 的限额在每周 50 次,Pro 用户可以无限制使用 O3-mini-high。
由于看到了 Deepseek R1 上线后推理加搜索带来的成功,O3-mini 这次推出时ChatGPT 也支持搜索。
免费用户也可以试用 o3-mini,试用方法是直接选择 Reason 按钮就行,Plus 用户可以直接选择模型使用。
在模型效果上
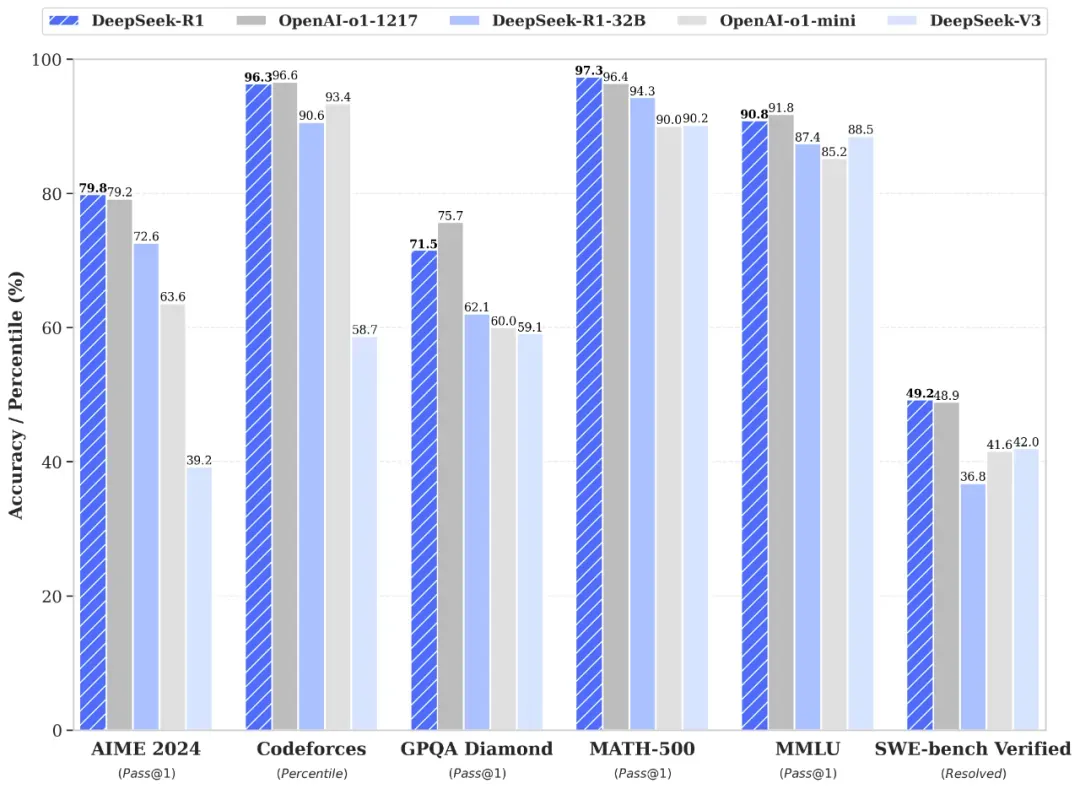
中等推理强度下,O3-mini的数学(AIME竞赛题)、编程(Codeforces)和科研级问题(GPQA Diamond)表现已与旗舰模型o1持平,响应速度却提升24%,平均生成时间缩短至7.7秒。
当切换至高强度模式时,其PhD级科学问题准确率跃升至77%,代码生成Elo评分突破2073,甚至在部分场景(如LiveBench编码)超越o1-high版本。
第三方测试来看,Humanity's Last Exam 测试上 o3-mini (high) 表现最好,达到13.0%,o3-mini (medium) 次之,为10.5%,R1 是 9.4%。
SQL-Eval 测试中 o3-mini 的效果也是最好的领先 O1 和 R1 接近 4个百分点。
一些后续的更新
在 o3-mini 发布的时候 Open AI 几个领导又在 Reddit 做了一次 AMA(Ask Me Anything)透露了一些信息,其中比较重要的是:
- Sam 承认 R1 的发布促使他们开始展示更多的模型思考过程。
- Sam 还承认从 R1 发布的结果和带来的反响看,他们之前选择不开源的策略可能是有问题的,他们会重新考虑这个策略。
Open AI 发布 Operator & Agents
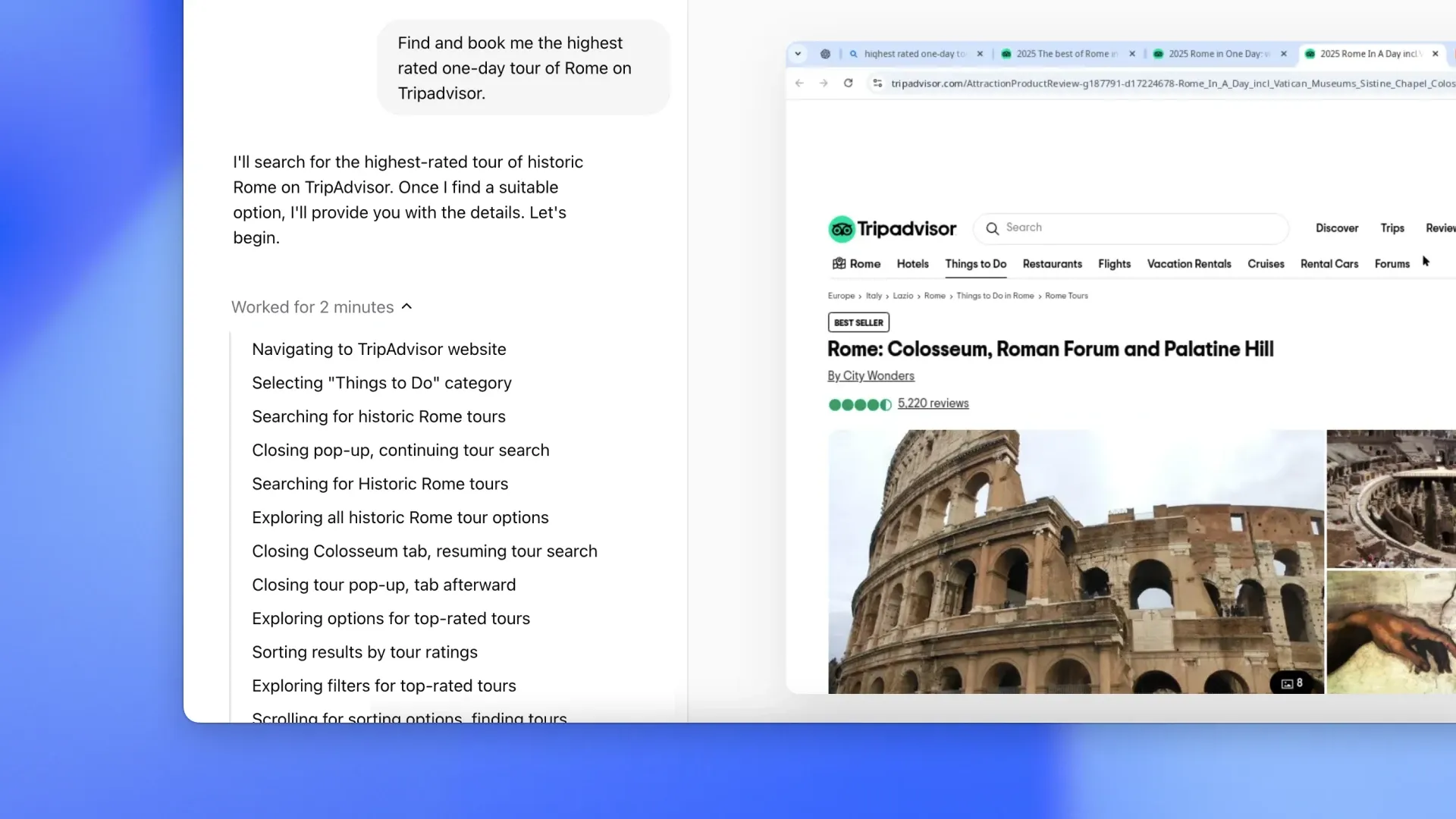
Open AI 用 Operator 的发布开启了今年的 Agents 系列发布序幕,一个可以上网为你执行任务的代理。它使用自己的浏览器,能够查看网页并通过输入、点击和滚动与之交互。
可以被要求处理各种重复性的浏览器任务,如填写表格、订购杂货,甚至制作表情包。会首先在美国的 Pro 用户开放。
Operator 由一种名为 Computer-Using Agent (CUA)的新模型驱动。CUA 结合了 GPT-4o 的视觉能力和通过强化学习实现的高级推理能力,经过训练能够与图形用户界面(GUIs)——即人们在屏幕上看到的按钮、菜单和文本字段——进行交互。
可以“看到”(通过截图)并“交互”(使用鼠标和键盘允许的所有操作)浏览器,使其能够在网络上采取行动,而无需自定义 API 集成。
如果遇到挑战或犯错,Operator 可以利用其推理能力进行自我纠正。当它卡住并需要帮助时,它会简单地将控制权交还给用户,确保流畅且协作的体验。
从一些有权限的测试看,这个工具还很早期,存在操作时间长,频繁出错需要接管等问题,不过由于他可以并发所以这类功能还是很有前途的。
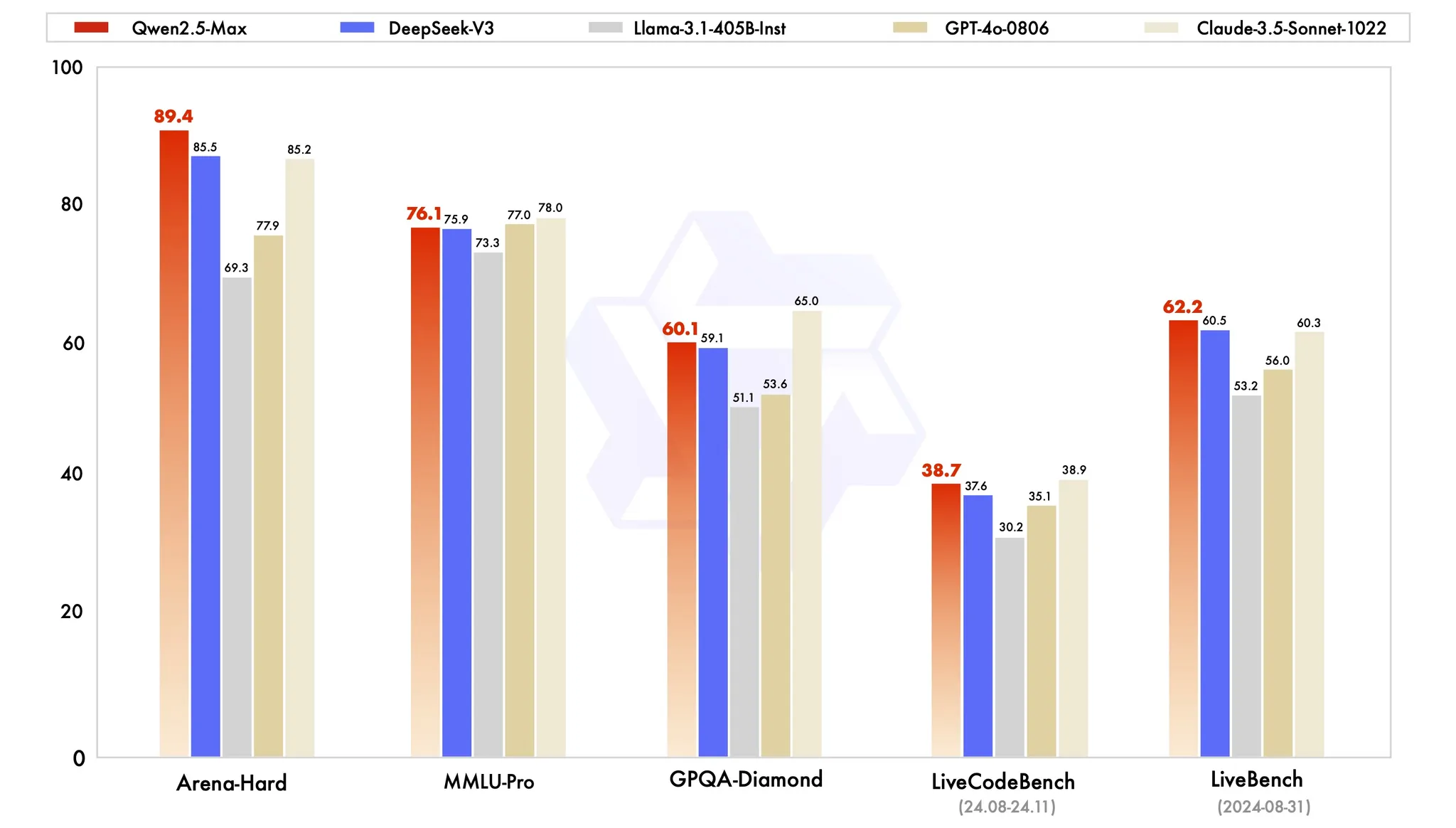
阿里开源 Qwen2.5-VL 和 Qwen2.5-Max
Deepseek 出了这么大风头阿里也没闲着,开源了两个模型 Qwen 2.5VL 和 Qwen 2.5 Max。
Qwen2.5-VL 的主要特点如下:
- 感知更丰富的世界:Qwen2.5-VL 不仅擅长识别常见物体,如花、鸟、鱼和昆虫,还能够分析图像中的文本、图表、图标、图形和布局。
- Agent:Qwen2.5-VL 直接作为一个视觉 Agent,可以推理并动态地使用工具,初步具备了使用电脑和使用手机的能力。
- 理解长视频和捕捉事件:Qwen2.5-VL 能够理解超过 1 小时的视频,并且这次它具备了通过精准定位相关视频片段来捕捉事件的新能力。
- 视觉定位:Qwen2.5-VL 可以通过生成 bounding boxes 或者 points 来准确定位图像中的物体,并能够为坐标和属性提供稳定的 JSON 输出。
- 结构化输出:对于发票、表单、表格等数据,Qwen2.5-VL 支持其内容的结构化输出,惠及金融、商业等领域的应用。
在多模态视频理解这部分可以说很厉害了,其他国产模型的多模态还在跟图片较劲呢。
至于 Qwen 2.5 Max 在非推理模型里面也很强了,这是一个大型 MoE LLM,在海量数据上进行预训练,并使用精选的 SFT 和 RLHF 配方进行后训练。它与顶级模型相比具有竞争力,并且在 Arena Hard、LiveBench、LiveCodeBench、GPQA-Diamond 等基准测试中胜过 DeepSeek V3。
这两个模型现在都可以在 Qwen Chat 里面尝试。