封面提示词:Planet X silhouette with star ring in black and white In the center stands a small astronaut, rear view --chaos 10 --ar 16:9 --style raw --profile m6rndxx --stylize 1000
上周精选✦
老马吹了半年的 Grok3 发布
XAI 的 Grok3 终于在上周发布了,马斯克这次的准备非常充足,不止发布了模型 Grok 的网页版本 iOS 版本都非常成熟,体验很好。
Grok 3 在Colossus 超级集群上训练,计算量是之前最先进模型的 10 倍。
其中包含两款测试版推理模型,Grok 3 (Think) 和 Grok 3 mini (Think)。现在在应用上可以用到的 Think 可能是 mini。Andrej Karpathy 认为 Grok3 处于 o1 Pro 的水平。
Grok 3 拥有 100 万 tokens 的上下文窗口——比 Grok2 大 8 倍——能够处理大量文档并应对复杂提示,同时保持指令遵循的准确性。
另外他们还发布了DeepSearch,深度搜索功能,被设计用于综合关键信息,推理相互矛盾的事实与观点,并从复杂中提炼清晰。
目前可以在 X 和 Grok.com 使用 Grok3,截止目前还是免费使用的,免费用户每天可以使用 2 次 Think 模式。Grok3 语音模式、记忆功能将会在本周推出。
谷歌的 Veo2 开放使用
去年底发布的谷歌Veo2视频生成模型终于开放使用了,当时看着那些有资格的老哥使用眼馋的很。
目前可以在 POE、Fal、Freepik 上使用文生视频模式,整体的价格相当离谱,Fal刚上线的的时候5秒的视频要2.5美元,比可灵贵六七倍,周日他们将价格降低到了1.25美元5秒。
试了一下文生视频,整体来看Veo2的文生视频所有表现都很好,比现在最好的模型都好,提示词理解到位,而且也都能画出来,运动幅度很大,可惜的就是清晰度被阉割了,没有当时发布的时候好。
至于图生视频,当时在谷歌自己的平台上只能用Imagen3生成的图片,我通过一些小技巧提前测试一下图生视频,整体质量非常好,尤其是一些非写实的很难的图片内容识别,以及复杂运镜提示词。就是有的时候会频繁切镜头,但神奇的是有个镜头他切完还能切回来。
从谷歌的定价来看也暴露出目前DiT视频生成模型的一个问题,随着视频参数越来越大成本越来越高,可控性和质量也迟迟没办法到达零界点,参数量过大的话推理成本还会提高,但是边际效应也越来越明显,希望今年会在架构和成本上有一些图片。
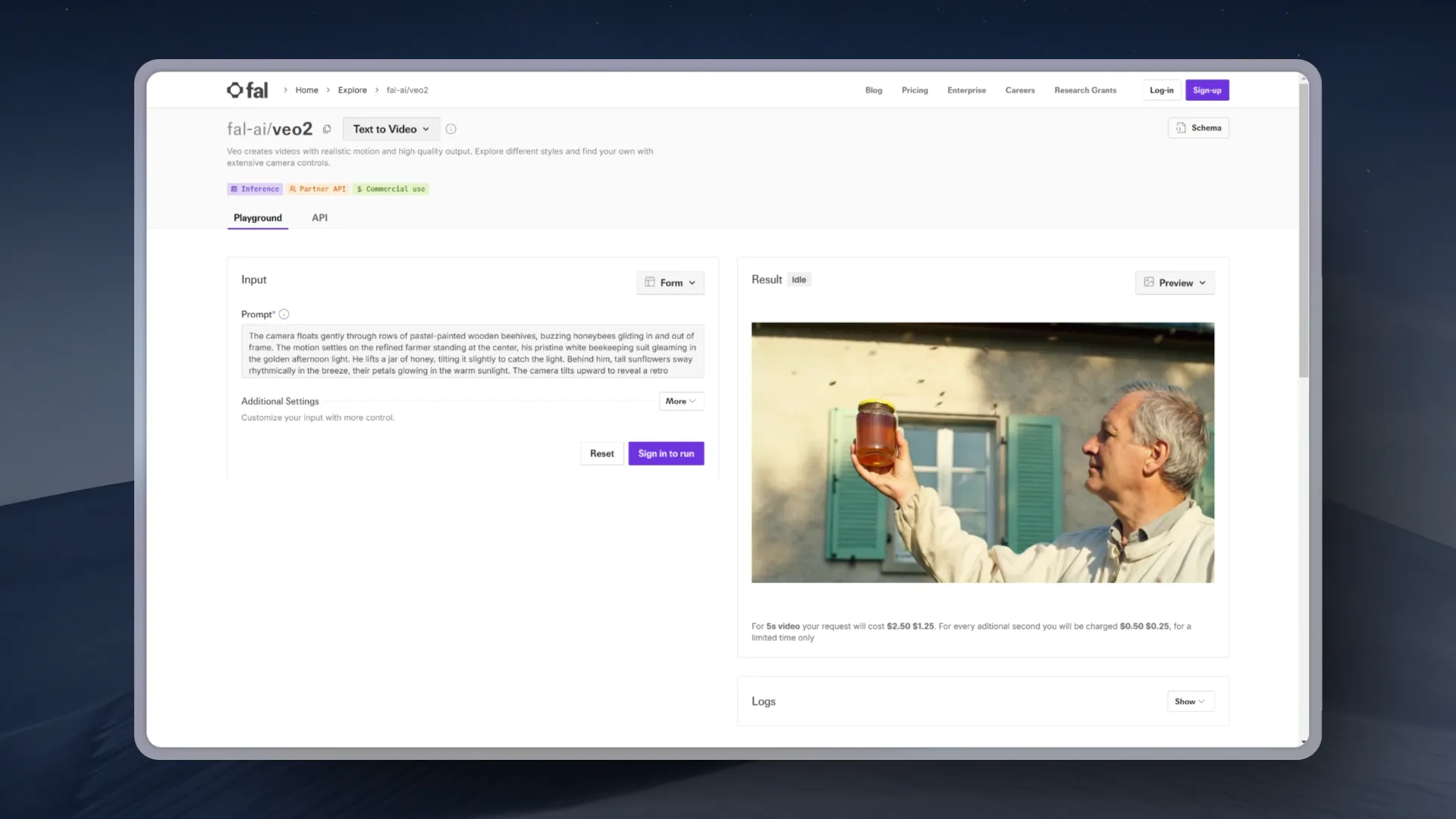
Figure 发布 Helix 机器人视觉语言行动模型
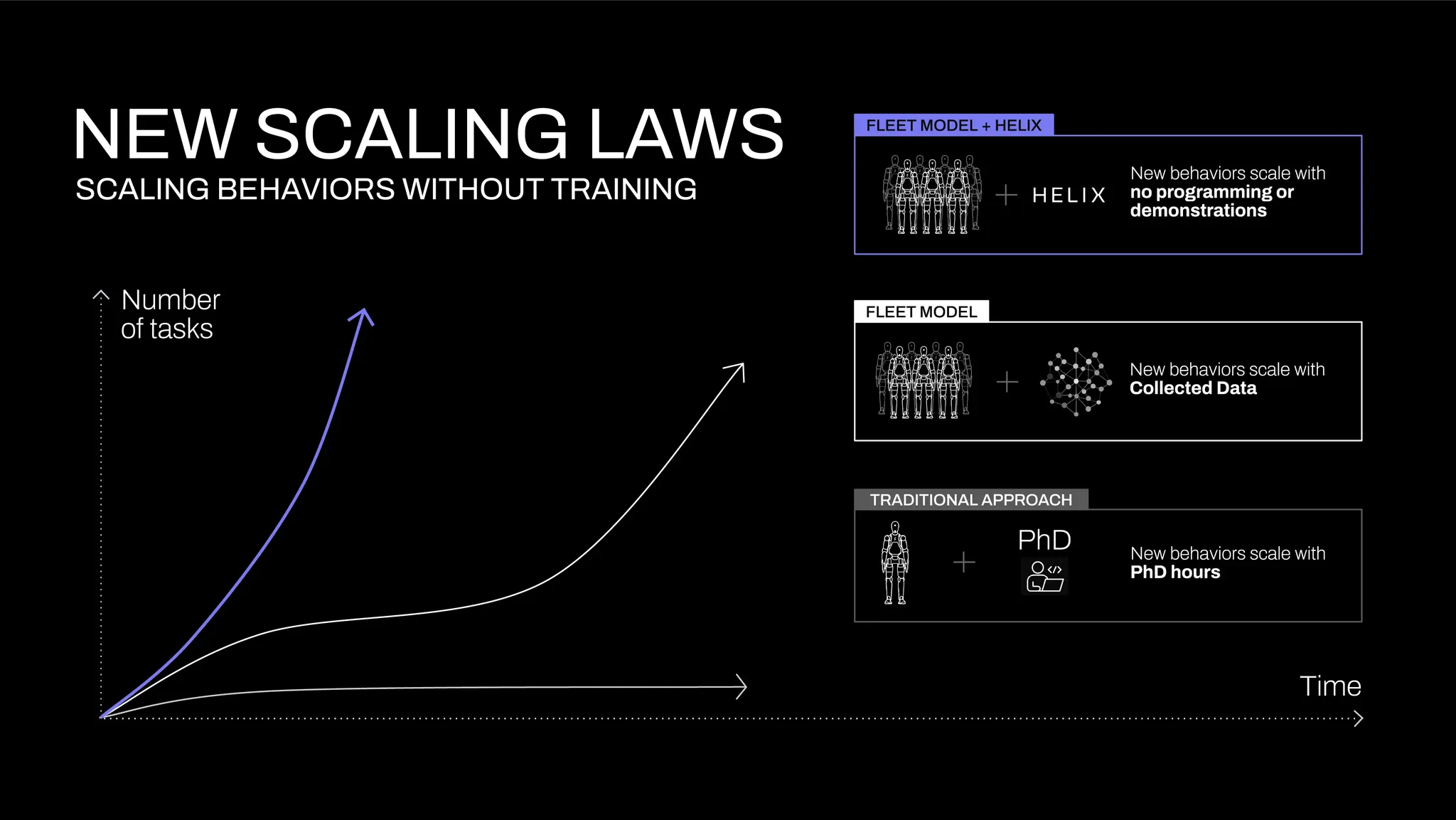
Figure在宣布跟Open AI分手之后,立刻在月底掏出了自己的机器人控制 LLM,他们叫 Helix,通用的视觉-语言-动作(VLA)模型,统一了感知、语言理解和学习控制,以克服机器人技术中的多个长期挑战。
具体的特点有:
- 全身控制:Helix 是首个能够输出包括手腕、躯干、头部和单个手指在内的整个人形机器人上半身高速连续控制的 VLA。
- 多机器人协作:Helix 是首个能在两台机器人上同时运行的 VLA,使它们能够解决一个共享的、长期的操作任务,处理从未见过的物品。
- 拾取任何物品:配备 Helix 的 Figure 机器人现在可以通过遵循自然语言提示,拾取几乎任何小型家用物品,包括数千种它们以前从未遇到过的物品。
- 一个神经网络:与之前的方法不同,Helix 使用单一的神经网络权重集来学习所有行为——拾取和放置物品、使用抽屉和冰箱,以及跨机器人交互——无需任何特定任务的微调。
- 商用就绪:Helix 是首个完全在嵌入式低功耗 GPU 上运行的 VLA,使其能够立即投入商业部署。
为了解决机器人模型根本性的权衡:VLM 骨干网络通用但不快速,而机器人视觉运动策略快速但不通用。他们用了两个模型联动的方案:
- 系统 2(S2):一种在 7-9 Hz 频率下运行的机载互联网预训练视觉语言模型(VLM),用于场景理解和语言理解,能够在各种对象和情境中实现广泛泛化。
- 系统 1(S1):一种快速反应的视觉运动策略,能够将 S2 生成的潜在语义表示以 200 Hz 的频率转换为精确的连续机器人动作。