
封面提示词:Blue sky, a huge cute cat, a little girl quietly reading beside the cat, the picture is warm --ar 16:9 --style raw --sref 2700920344 --stylize 250
会员群 01 上周炸了,也不知道说了啥,可能是关于俄乌的问题。目前我正在重新拉人,慢慢都会拉回去的,只是得按顺序。
傻逼微信一次只能拉 40 个,而且只有你超了点确定才告诉你,你还得像个傻子一样把多拉的数量都删掉。
上周精选✦
Claude 3.7 发布
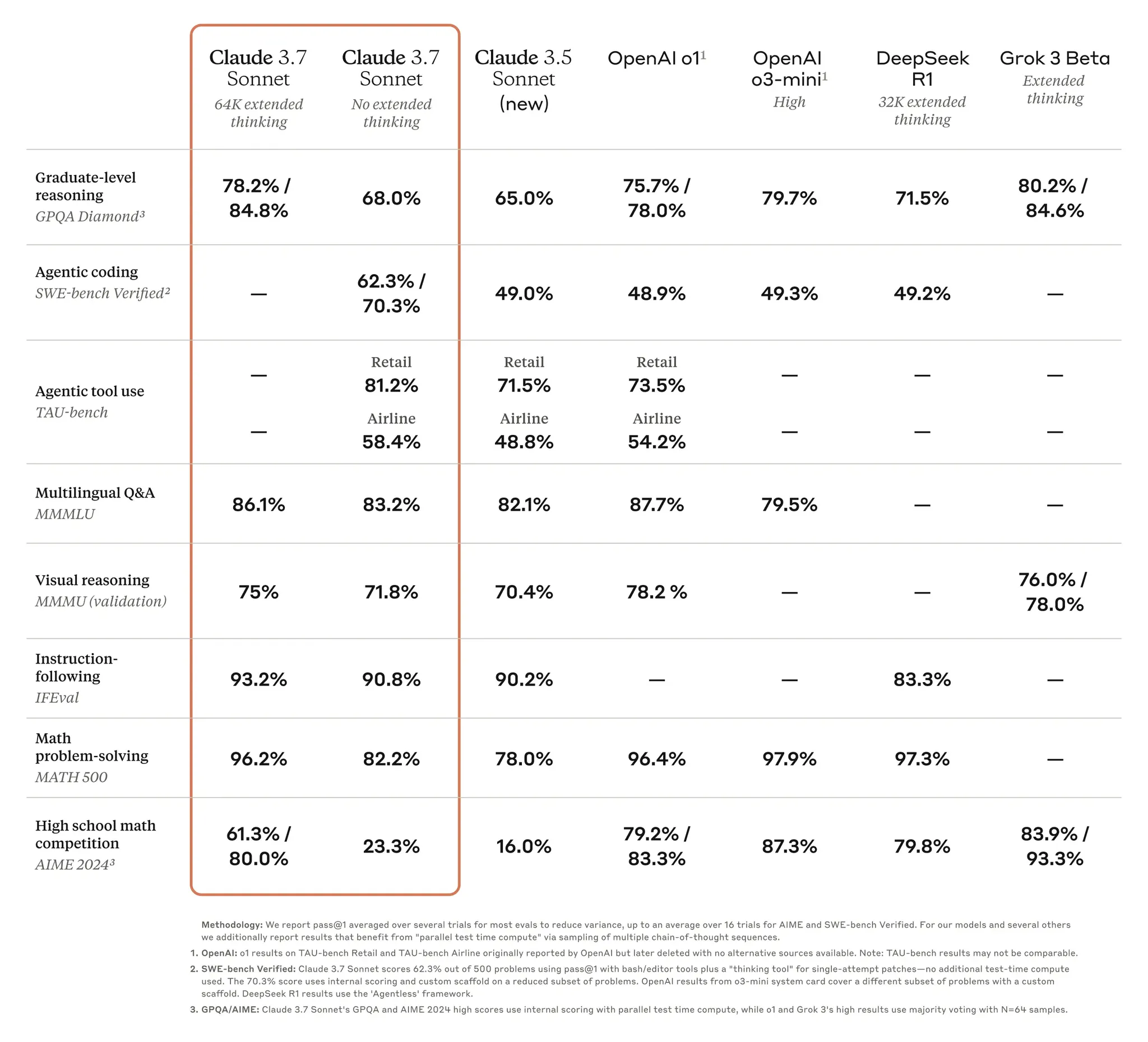
预热了很久的 Claude 3.7 也在上周发布了,支持自定义思考程度,能够生成近乎即时的响应或逐步展开的思考过程。主要模型能力上的主要改进是在编码和前端网页开发方面。
Claude 3.7 Sonnet 现已适用于所有 Claude 计划——包括 Free、Pro、Team 和 Enterprise——以及 Anthropic API、Amazon Bedrock 和 Google Cloud 的 Vertex AI。
在标准和扩展思维模式下,Claude 3.7 Sonnet 的价格与其前代相同:每百万输入 token 为 3 美元,每百万输出 token 为 15 美元,其中包括思维链 token。
Claude 3.7 Sonnet 在指令遵循、通用推理、多模态能力和代理编码方面表现出色,扩展思维在数学和科学领域提供了显著提升,在 Web Dev 的排行榜上比 3.5 还高了 100 分。
模型厂商既当裁判又当运动员的情况还在发生,跟 Claude 3.7 一起推出的还有 Claude Code 这个代理编码工具。
能够搜索和阅读代码、编辑文件、编写和运行测试、提交并推送代码到 GitHub,以及使用命令行工具。
GitHub 集成现已适用于所有 Claude 计划,使开发者能够将他们的代码库直接连接到 Claude。
GPT-4.5 发布
Open AI 在这周发布了之前预告了很久的 GPT-4.5,没有用 RL 训练,就是 GPT-4 的常规升级版,预训练规模提高了十倍。
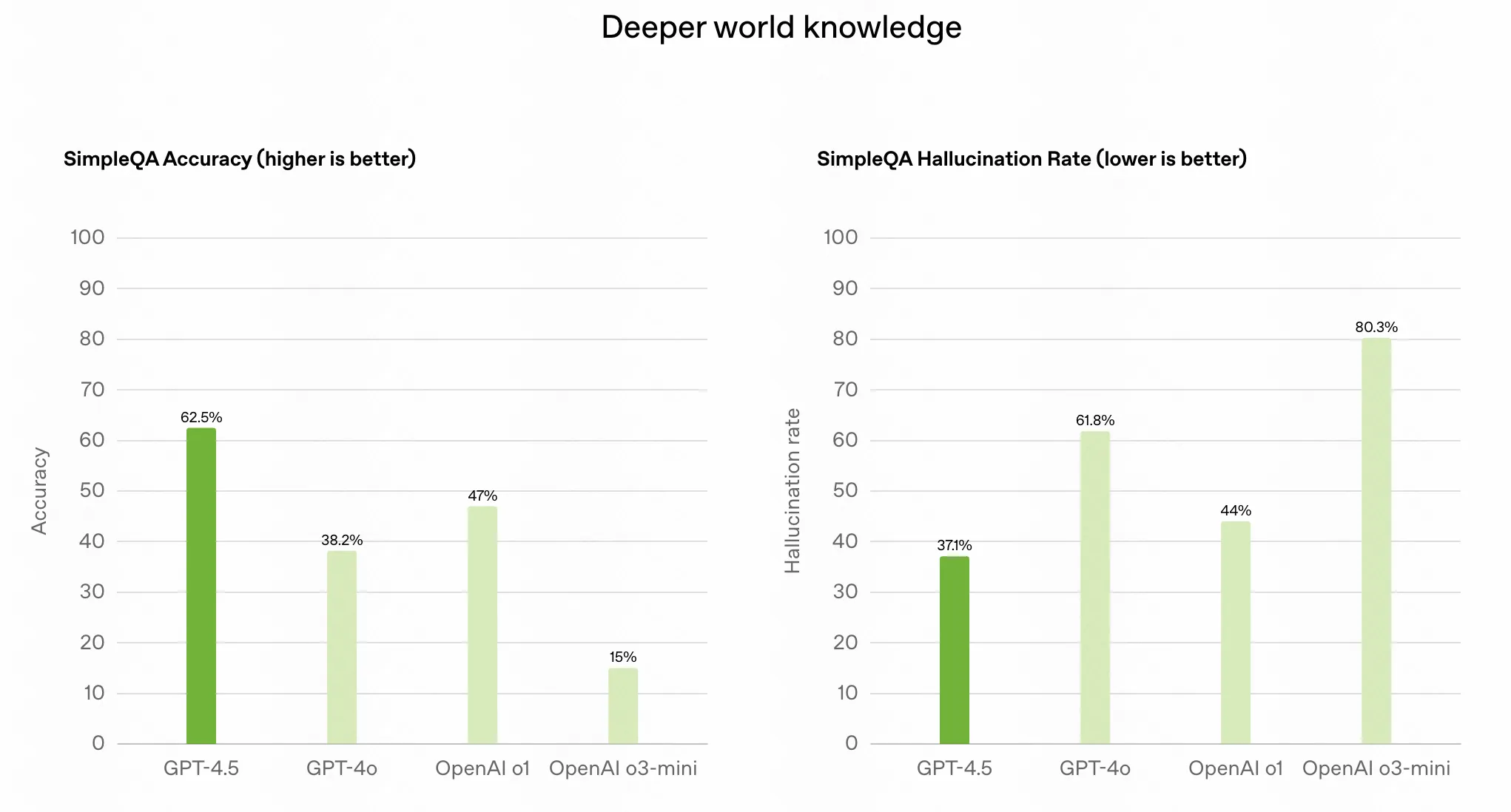
Open AI 说它有更广泛的知识库、改进的遵循用户意图的能力以及更高的“情商”,使其在提升写作、编程和解决实际问题等任务中非常有用。还预计它的幻觉现象会减少。
目前在 ChatGPT 中只有 Pro 会员才可以使用 GPT4.5,Plus 会员需要这周或者再等几周,Sam 说他们模型太多了,导致卡的分配有问题,新的集群部署需要一些时间。
从模型整体的基准评价来看,在部分基准上 GPT-4.5 是不如 Claude 3.5 的,甚至一部分基准不如 Deepseek V3。
Karpathy 关于 GPT-4 和 GPT-4.5 的写作水平投票中,GPT-4.5 完败,只有一个问题胜出。
但是在 API 上现在 GPT-4.5 的价格是 V3 的 270 倍。
预训练对于模型质量的提升真是到头了,就是不知道基于 GPT-4.5 训练的新的推理模型会从预训练规模有多大的受益。
另外还有一些常规更新:
- Deep research 向所有 ChatGPT 付费用户推出,plus 用户每月十次使用机会,Pro 用户 120 次
- 宣布推出 4o mini 驱动的高级语音,所有免费用户都可以使用
Deepseek 开源周
看完了虚假的 Open AI 再看看真正的 Open AI,Deepseek 开源周也在上周一拉开了序幕,开源的都是模型训练中非常有用的库,大部分都能提高效率节约成本,看完就知道 Deepseek 600 万美元训出 R1 真是本事。
- Deepseek 开源周第一天:FlashMLA项目,让H800的计算性能翻了两倍,为Hopper架构GPU开发的高效MLA解码内核,专门针对可变长度序列进行了优化。H800上可以达到 3000 GB/s的内存带宽和580 TFLOPS的计算性能
- Deepseek 开源周第二发,DeepEP :首个面向MoE模型的开源EP通信库,支持实现了混合专家模型训练推理的全栈优化。具体包括:高效且优化的全到全通信;支持节点内和节点间通信,兼容 NVLink 和 RDMA;用于训练和推理预填充的高吞吐量内核;用于推理解码的低延迟内核;原生 FP8 调度支持;灵活的 GPU 资源控制,实现计算与通信的重叠
- Deepseek 开源周第三发,DeepGEMM:一个支持密集型和 MoE GEMM 的 FP8 GEMM 库
,核心逻辑仅约300行代码,极限情况下可以将 NVIDIA H800 的计算性能提高 2.7 倍,他们真的把显卡的性能压榨到了极限。 - 第四天开源了DualPipe:一种创新的双向流水线并行算法,它实现了前向和后向计算-通信阶段的全重叠,同时减少了流水线气泡。还有EPLB - 适用于 V3/R1 的专家并行负载均衡器,采用了冗余专家策略,复制负载较重的专家。然后,我们启发式地将复制的专家打包到 GPU 上,以确保不同 GPU 之间的负载平衡。
- 开源 3FS 高性能分布式文件系统,旨在应对 AI 训练和推理工作负载的挑战。它利用现代 SSD 和 RDMA 网络,提供一个共享存储层,简化了分布式应用程序的开发。
- 没想到 Deepseek 周六还有货,分享了DeepSeek-V3/R1 的推理系统概述,他们的在线服务通过这个系统每个 h800 节点每秒达到了离谱的 1.4 万 Token 输出,成本利润率545%!还记得当时 Deepseek R1 火的时候英伟达自己把推理速度推到 3800 Token 每秒都拿出来吹。就可以对比 Deepseek 自己优化到的 1.4 万 Token 有多离谱。
