封面提示词:Delicate white petals unfolding in slow motion, bathed in soft, ethereal light. The flower is set against an intense, rich red background, creating a striking contrast. The petals appear silky and translucent, with subtle shadows enhancing their depth, the flower is in semi-darkness and gives a sense as if it is about to be born, so it is to the side and hidden by a play of light and shadows. Cinematic lighting, ultra-realistic, dreamy aesthetic, with a shallow depth of field. --ar 16:9 --style raw --sref 3998011918 602153393 657518625 --profile 86gonf3 y5ycbfg --stylize 1000
上周精选✦
阿里发布 QwQ 32B 推理模型
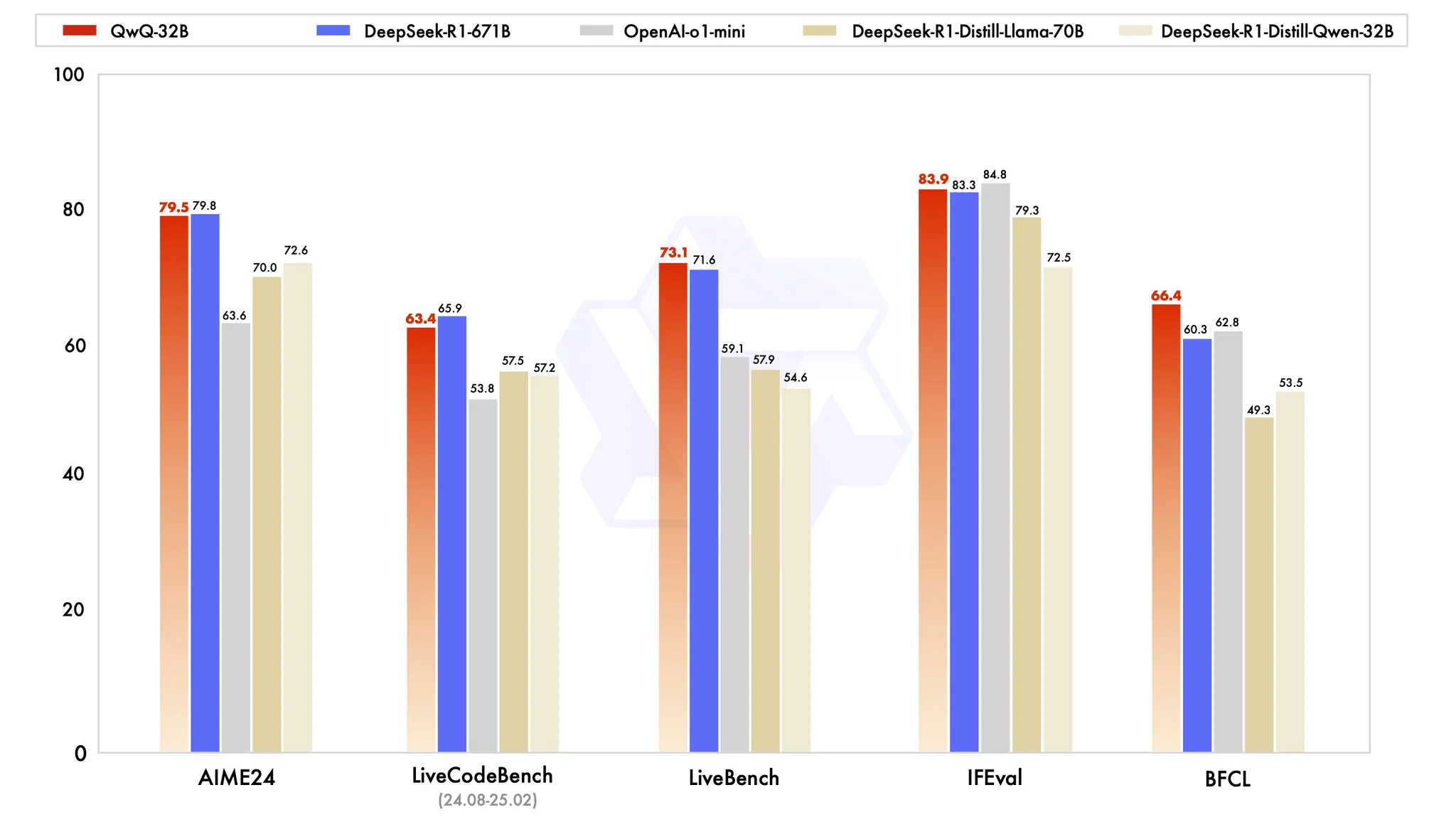
阿里在 Manus 发布的同一天发布了他们的QwQ-32B推理模型正式版,QwQ-32B在测试上的成绩可以与671B的满血Deepseek R1相同。
另外他们推理模型中集成了与 Agent 相关的能力,使其能够在使用工具的同时进行批判性思考,并根据环境反馈调整推理过程。
他们简单介绍了一下训练方式:
- 在初始阶段,我们专门针对数学和编程任务扩展了 RL(强化学习)。我们没有依赖传统的奖励模型,而是利用了一个数学问题的准确性验证器来确保最终解决方案的正确性,以及一个代码执行服务器来评估生成的代码是否成功通过预定义的测试用例。随着训练回合的推进,这两个领域的表现都显示出持续改进。
- 在第一阶段之后,我们增加了另一个阶段的 RL 以提升通用能力。它通过通用奖励模型和一些基于规则的验证器进行训练。我们发现,这一阶段的 RL 训练只需少量步骤即可提高其他通用能力,如指令遵循、与人类偏好的一致性以及代理性能,而不会显著降低数学和编码的表现。
现在可以在Qwen Chat在线尝试QwQ-32B模型,记得在左上角选择, 大概尝试了一下模型能力确实很强,32B的模型在好一些的设备都能本地跑了,今年强化学习还会给我们带来很多的惊喜。
Manus :第一个通用 Agents系统
上周最大的热点就是这个了,Manus团队奖他介绍为真正自主的代理,它能够独立完成复杂的任务,而不仅仅是生成想法。
核心理念可以概括为:
- 自主执行力: Manus AI 不仅仅停留在生成想法的层面,它能够将指令转化为实际行动,交付最终结果。
- 类人工作模式: Manus AI 模拟人类的工作方式,例如,它可以解压缩文件、浏览网页、阅读文档,并从中提取重要信息。
- 云端异步工作: Manus AI 在云端异步运行,用户可以随时关闭电脑,任务会在后台持续执行,完成后会通知用户。
- 持续学习和记忆: Manus AI 拥有自己的知识和记忆,可以从用户的反馈中学习,并在处理类似任务时应用学到的知识,提高效率和准确性。
- 人机协作新范式: Manus AI 被视为人机协作的新范式,旨在扩展人类的能力,放大影响力,并将人类的愿景变为现实。
上周第二天就拿到了测试资格这几天也陆续试了几个任务,在考验模型能力的任务上他由于用的还是目前最好的模型,所以在比如创意写作等任务上无法超过顶尖模型。
但是在复杂多步任务的完成度上的操作成本要比现在的各类模型强很多,你真的可以把一个需要多步多种工具执行的任务扔给他,他起码会给你一个及格的结果,工作能力确实相当于一个普通应届大学生的水平。
但是给用户及分享后展示AI操作虚拟机的过程,这个交互创新确实太牛了,极大的提升了用户对软件的信任感,还让用户对AI Agents的能力有了非常直观的认识,以往的Agents流程都藏在用户看不到的地方,然后给用户一个及格的结果,用户就会有预期上的差距,这个让用户看到了AI是多努力的在学习和完成任务,好像真的有个实习生在帮你干活。
AI软件第一次的交互创新是给AI搜索结果后加上来源数字注释,第二次是DeepSeek R1完全公开的思维链过程(刚看到小红在访谈里也提到了Perplexity CEO 提到的这个说法),第三次应该就是Manus给用户展示Agents操作电脑的过程了,很快就会成为所有类似通用Agents工具的标配。
目前我观察到两个问题比较影响效果:
- 上下文长度严重制约了一些任务的成功率,因为一旦上下文超长就只能新开始一个任务,之前的工作全部浪费。
- 虚拟机的浏览器没有我的登录信息,由于人机验证的存在导致相当多的信息和网页工具他无法使用,不然的话他的能力还能再往前跨一步。